
Programa
Fundamentos da IA
10 h
Você já ouviu falar que, de acordo com dados coletados nos EUA, o consumo de sorvete está ligado a ataques de tubarão?
Por mais maluco que pareça, esse tipo de correlação ocorre quando duas variáveis parecem estar relacionadas, mas, na verdade, ambas são influenciadas por uma terceira variável. Nesse caso, a temperatura é o fator provável. Durante o verão, o consumo de sorvete aumenta por causa do calor. Ao mesmo tempo, os ataques de tubarão também aumentam porque mais pessoas estão nadando no oceano.
Embora esse padrão mostre uma correlação nos dados, isso não implica que um cause o outro. É aqui que entra o CausalAI. Ele ajuda a identificar as verdadeiras relações de causa e efeito nos dados, o que nos permite evitar correlações espúrias.
Neste artigo, exploraremos o conceito de IA causal, sua importância e como aplicá-lo na prática.
A IA causal é um ramo da Inteligência Artificial (IA) que se concentra em compreensão e modelagem de relações de causa e efeitoem vez de apenas identificar padrões ou correlações, como fazem outros sistemas tradicionais de aprendizado de máquina.
A IA causal ajuda a melhorar a confiabilidade, a explicabilidade e a robustez dos sistemas de IA, especialmente em cenários do mundo real, como saúde e economia, que são mais complexos por natureza.
A essa altura, você deve estar se perguntando:
Por que os métodos tradicionais de IA não levam em conta a causalidade?
Os sistemas tradicionais de IA se concentram em identificar padrões, correlações e fazer previsões com base em dados. Para isso, eles contam com técnicas estatísticas e de aprendizado de máquina (ML) para encontrar associações nos dados.
De fato, durante o treinamento, eles são projetados para otimizar a precisão da previsão usando grandes conjuntos de dados. Esses conjuntos de dados são os que contêm correlações e os algoritmos perceberão essas correlações, mas as informações causais explícitas podem não estar presentes.
Além disso, os sistemas tradicionais de IA são muitas vezes criticados por sua capacidade limitada de explicação e são frequentemente chamados de "caixa preta". Nesse contexto,a CausalAI ajuda a criar modelos mais transparentes e interpretáveis, raciocinando explicitamente sobre causas e efeitos.
Por fim, embora os métodos tradicionais (não causais) de IA tenham muitas aplicações, a principal conclusão desta seção é: A correlação não implica em causalidade.
Voltando ao exemplo do sorvete versus ataques de tubarão da introdução, podemos ver que as vendas de sorvete e os incidentes de ataques de tubarão estão correlacionados (ambos aumentam no verão), mas o sorvete não causa ataques de tubarão.
Como vimos, no centro da IA causal está o objetivo de estabelecer relações de causa e efeito entre as variáveis. No entanto, há também dois conceitos fundamentais que são essenciais para a compreensão e a manipulação dessas relações em um sistema:
O raciocínio contrafatual envolve a consideração de cenários hipotéticos para entender como as mudanças em determinadas variáveis podem alterar os resultados.
Gosto de ver o Raciocínio contrafatual como uma pergunta do tipo: "O que teria acontecido se a variável X tivesse assumido um valor diferente?". Isso é um "E se" pergunta.
Em nosso exemplo de sorvete versus ataques de tubarão, poderíamos nos perguntar:"E se as vendas de sorvete tivessem sido menores? Teria havido menos ataques de tubarão?"
Nesse cenário contrafatual, imaginamos uma versão alternativa da realidade em que as vendas de sorvete diminuem e tudo o mais permanece igual. Como tanto as vendas de sorvete quanto os ataques de tubarão aumentam no verão devido ao clima mais quente (uma causa comum), a redução das vendas de sorvete não afetaria os ataques de tubarão. Isso demonstra correlação, não causalidade.
As intervenções referem-se à manipulação deliberada de variáveis em um sistema para observar mudanças em outras variáveis. Nesse caso, as intervenções envolvem a alteração ativa de uma variável para um valor específico, o que nos permite estudar seus efeitos diretos no sistema.
Em nosso exemplo, uma intervenção poderia ser:
"Vamos proibir a venda de sorvete em dias quentes (definindo a venda de sorvete como 0). Isso reduzirá os ataques de tubarão?"
Aqui, estamos deliberadamente alterando o sistema ao remover as vendas de sorvete. O resultado mais provável é que não haja mudança nos ataques de tubarão, já que proibir o sorvete não impede as pessoas de nadar. Esse exemplo simples ilustra que a intervenção nas vendas de sorvete não tem efeito causal sobre os ataques de tubarão.
Antes de prosseguir, se você estiver interessado em aspectos mais básicos da IA, a trilha de habilidades Fundamentos de IA é para você!
Nesta seção, exploraremos três modelos de IA causal que nos ajudarão a entender como trabalhar com causalidade.
Vamos começar com o modelo mais simples e avançar para os mais complexos.
Gráficos acíclicos direcionados (DAGs) codificam as relações direcionais entre variáveis sem ciclos, o que significa que não há loops em que uma variável possa causar indiretamente a si mesma. Eles são usados para representar relações causais de forma binária: Ou há uma relação de causa e efeito entre duas variáveis e, nesse caso, há uma borda direcionada da causa ao efeito no gráfico, ou não há nenhuma e, portanto, também não há borda.
Por exemplo, o DAG do nosso exemplo original de consumo de sorvete e ataques de tubarão mostra os seguintes caminhos causais:
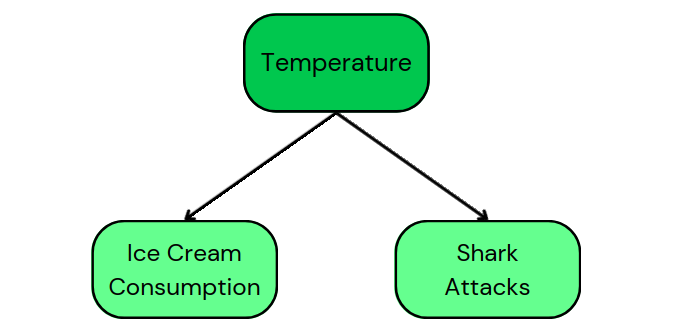
Esse DAG nos diz que a temperatura é uma causa comum tanto para o consumo de sorvete quanto para ataques de tubarão. Além disso, ele mostra que não há causalidade entre o consumo de sorvete e os ataques de tubarão.
Os DAGs são representações simples, mas podem se tornar mais complexos ao adicionar mais informações aos caminhos, como veremos nas seções a seguir.
Os Modelos Causais Estruturais (SCMs) incluem equações que modelam como as variáveis são influenciadas por outras. Para passar de um DAG para um SCM, precisamos especificar um sistema de equações estruturais que descreva quantitativamente como cada variável é gerada.
Concretamente, uma equação estrutural nesse contexto é uma equação matemática que expressa uma variável (resultado) como uma função de uma ou mais variáveis (causas) mais um termo de perturbação que representa todas as outras influências sobre esse resultado. Em nosso exemplo:
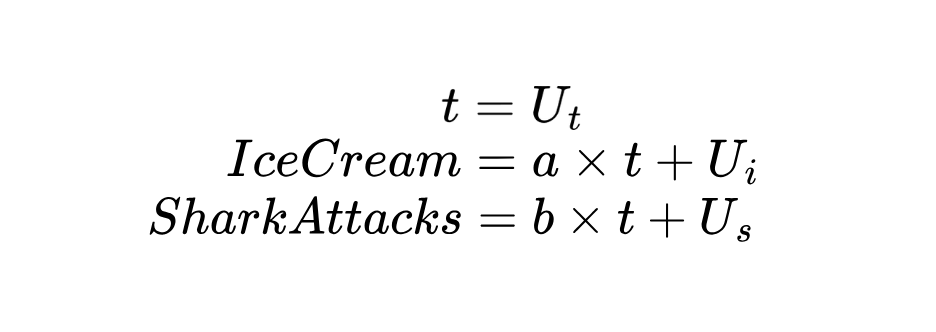
Como a temperatura (t) é uma variável exógena, o que significa que não é causada pelas outras duas, presumimos que ela seja determinada por fatores externos.
Nas equações acima, tanto o consumo de sorvete quanto os ataques de tubarão seguem um modelo linear sobre a temperatura, mostrando como uma mudança na temperatura se propaga para ambos os resultados.
Você pode dar um passo adiante e adicionar probabilidades ao jogo!
As redes bayesianas (BNs) podem ser vistas como uma instanciação específica de SCMs em que as equações estruturais são expressas de forma probabilística.
Um BN usa a mesma estrutura de causa e efeito, mas em vez de escrever fórmulas exatas (como um modelo linear), ele descreve as probabilidades ou chances de resultados diferentes. Em outras palavras, em vez de termos uma equação, expressamos a probabilidade de Y acontecer, uma vez que X tem um determinado valor: P(Y | X). Essa probabilidade condicional substitui uma equação fixa em um SCM por uma descrição da incerteza.
No contexto da IA causal, a inferência causal refere-se às técnicas para descobrir relações de causa e efeito a partir dos dados. Nesse caso, em vez de nos concentrarmos nos modelos para entender as relações, já estamos começando com um conjunto de dados e aplicando métodos diferentes para discernir essas relações. Vamos analisá-los aplicando cada método ao nosso exemplo original:
Os Ensaios Clínicos Controlados Aleatórios (ECRs) ajudam a determinar relações causais atribuindo aleatoriamente participantes a diferentes grupos e comparando os resultados.
Por exemplo, ao responder à nossa pergunta, "Comer sorvete causa mais ataques de tubarão?" distribuiríamos as pessoas aleatoriamente em dois grupos:
Depois, compararíamos as taxas de ataque de tubarão entre os grupos. Idealmente, não deveríamos encontrar nenhuma diferença significativa nas taxas de ataques de tubarão porque o consumo de sorvete não causa ataques de tubarão. A causa real, nesse caso, é provavelmente a temperatura, que não foi manipulada no experimento.
De maneira mais formal, diríamos que a randomização isola o efeito do consumo de sorvetee, como não foi encontrado nenhum vínculo causal, isso sugere que o consumo de sorvete não causa diretamente ataques de tubarão.
Em cenários em que a randomização não é possível, podemos nos basear em dados observacionais e aplicar o Propensity Score Matching (PSM).
Na verdade, em situações do mundo real, não podemos aplicar RCTs e randomizar o consumo de sorvete porque as pessoas decidem se querem ou não comê-lo. Entretanto, podemos usar dados observacionais para inferir relações causais seguindo as etapas do PSM:
Idealmente, as taxas de ataque de tubarão deveriam ser semelhantes para ambos os grupos, o que sugeriria que o consumo de sorvete não é a causa dos ataques de tubarão. Qualquer diferença observada provavelmente se deve a outros fatores, como a temperatura.
Digamos que suspeitamos que a temperatura seja uma variável oculta (um fator de confusão) que afeta o consumo de sorvete e os ataques de tubarão. A técnica de Variáveis Instrumentais (IV) ajuda a resolver esse problema ao usar uma variável adicional (um instrumento) - como o horário do caminhão de sorvete - que influencia o consumo de sorvete, mas não está relacionada aos ataques de tubarão.
Se o horário do caminhão afetar apenas as vendas de sorvete e não o comportamento de natação das pessoas, poderemos usá-lo como um instrumento para isolar o efeito causal do consumo de sorvete nos ataques de tubarão. Ao aplicar o IV, provavelmente descobriríamos que, após a contabilização desse instrumento, o consumo de sorvete não causa ataques de tubarão, e a correlação observada se deve ao fator de confusão oculto: a temperatura.
Se você estiver curioso sobre outros tipos de inferências, considere dar uma olhada no artigo "O que é inferência de aprendizado de máquina? Uma introdução às abordagens de inferência".
Nesta seção, exploraremos duas estruturas diferentes para trabalhar com IA causal na prática usando Python.
O DoWhy é uma ferramenta muito interessante porque oferece uma estrutura completa para o raciocínio causal, enfatizando a transparência e a interpretabilidade.
Ele é altamente abrangente e oferece uma ampla variedade de algoritmos para estimativa de efeitos, análise de causa raiz, intervenções e contrafactuais. Ele é especialmente útil para fluxos de trabalho de inferência causal baseados em gráficos. Não vou entrar em muitos detalhes sobre essa ferramenta, pois já existe um tutorial completo disponível no DataCamp: Introdução à IA causal usando a biblioteca DoWhy.
O Pyro é uma estrutura de programação probabilística cujo foco principal é a modelagem estrutural e bayesiana. Um dos principais benefícios do Pyro é que ele se integra perfeitamente ao PyTorch para aceleração de GPU e aplicativos de aprendizagem profunda.
Se você estiver interessado, o Pyro tem uma extensa documentação com muitos exemplos disponíveis.
Se você estiver ansioso para começar a usar estruturas de IA, como as discutidas nesta seção, recomendo o curso do DataCamp sobre Desenvolvimento de aplicativos de IA.
Até agora, analisamos os fundamentos da IA causal, os modelos por trás dela, diferentes abordagens para a inferência causal e duas estruturas Python para trabalhar com ela. No entanto, todos nós sabemos que mergulhar em uma nova disciplina pode ser difícil. Portanto, nesta seção, analisaremos as cinco etapas principais para implementar a IA causal:
A qualidade dos dados que temos é fundamental, pois a inferência causal depende muito de dados que representem com precisão o sistema que está sendo estudado. É importante ter em mente que qualquer tipo de erro, valor ausente ou tendência pode distorcer as relações causais.
A inferência causal também exige dados ricos, como a garantia de que todos os fatores de confusão relevantes sejam observados e incluídos nos dados, que as intervenções sejam bem definidas e consistentes entre as observações e que os grupos sejam comparáveis ao aplicar técnicas que exigem essa divisão.
Como conselho final, se você puder escolher seus dados, os dados temporais (séries temporais ou dados longitudinais) geralmente são muito úteis para estabelecer a causalidade, pois ajudam a determinar a ordem dos eventos.
Essa etapa envolve a criação de um modelo conceitual que representa as relações entre as variáveis. Ferramentas como DAGs ou SCMs são frequentemente usadas nesse ponto para formalizar suposições sobre causalidade.
Vimos que os fatores de confusão são possíveis variáveis ocultas que podem estar influenciando nossas variáveis observadas. Há também dois outros tipos de variáveis:
É interessante identificar esses três tipos de variáveis e suas possíveis interações durante a modelagem e definir claramente a direção da causalidade.
O objetivo da identificação é determinar se o efeito causal de interesse pode ser estimado a partir dos dados observados, considerando o modelo. Portanto, essa etapa envolve verificar se o efeito causal é identificável usando métodos de inferência causal, como a identificação de variáveis.
Depois que o efeito causal é identificado, esta etapa se concentra na quantificação do efeito causal usando métodos estatísticos. Esse é um bom momento para você aplicar o Propensity Score Matching, por exemplo.
Essa fase testa se suas conclusões causais se sustentam, desafiando as suposições e explorando explicações alternativas. Os métodos dessa etapa incluem raciocínio contrafactual e intervenções. Enquanto os contrafactuais examinam se o resultado mudaria em condições diferentes, as intervenções testam a solidez das relações causais alterando ativamente as variáveis e observando os efeitos.
Agora que sabemos como funciona a IA causal, vamos ver alguns exemplos de domínios em que podemos aplicá-la.
Um bom exemplo de um sistema de IA causal do mundo real em funcionamento está no domínio da saúde, onde ele é usado para determinar a eficácia dos tratamentos estimando, por exemplo, o impacto causal das intervenções médicas. Além disso, as relações causais são usadas para adaptar os tratamentos a pacientes individuais com base em sua situação específica.
O marketing é outra área que se beneficia da IA causal. Por exemplo, o Causal AI ajuda a medir o verdadeiro impacto das campanhas de marketing, distinguindo entre correlação e causalidade. Ele fornece insights mais profundos sobre o que impulsiona as decisões dos clientes, permitindo estratégias de marketing mais direcionadas e eficazes. Da mesma forma, áreas como economia, negóciose gerenciamento da cadeia de suprimentos também dependem da compreensão da causalidade.
Neste artigo, exploramos como a IA causal nos ajuda a ir além das simples correlações nos dados para descobrir verdadeiras relações de causa e efeito. Examinamos como Gráficos Acíclicos Direcionados, Modelos Causais Estruturais e Redes Bayesianas servem como ferramentas de modelagem causal para representar e raciocinar sobre sistemas complexos.
Além disso, discutimos como aplicar a IA causal aos dados, em que os ensaios clínicos randomizados controlados e a correspondência de pontuação de propensão ajudam na estimativa do efeito causal. Quando há suspeita de confusão não mensurada, as variáveis instrumentais ajudam a identificar influências ocultas.
Por fim, delineamos as etapas para implementar a IA causal na prática, com ênfase especial no raciocínio contrafatual e nas intervenções como ferramentas essenciais na fase de refutação da análise causal.
Como a IA causal continua a evoluir, ela desempenhará uma função cada vez mais vital não apenas na distinção entre a simples correlação e a causalidade, mas também no aproveitamento da causalidade para uma melhor tomada de decisões.
Se você quiser saber mais sobre a IA causal e como ela ajuda as empresas a tomar decisões melhores, confira nosso episódio do DataFramed sobre IA causal nos negócios. Você também pode ler nosso guia prático para IA causal usando a biblioteca DoWhy para que você tenha um exemplo prático.
Principais cursos da DataCamp
Programa
Curso
Curso
blog
Matt Crabtree
15 min
blog
Austin Chia
blog
Matt Crabtree
11 min
blog
Maria Eugenia Inzaugarat
12 min
blog
Javier Canales Luna
14 min
Tutorial
Zoumana Keita

