
programa
Ingeniero de Datos Profesional en Python
40 h
Los flujos de trabajo y las canalizaciones de datos a menudo requieren una coordinación precisa para garantizar que las tareas se ejecutan en el orden correcto. El Grafo Acíclico Dirigido (GAD) es una potente herramienta para gestionar estos flujos de trabajo con eficacia y evitar errores.
En este artículo, exploraremos los DAG y su importancia en la ingeniería de datos, repasaremos algunas de sus aplicaciones y comprenderemos cómo utilizarlos mediante un ejemplo práctico con Airflow.
Para entender qué es un DAG, definamos primero algunos conceptos clave. En informática, ungrafo es una estructura de datos no lineal formada por nodos y aristas. Los nodos representan entidades u objetos individuales, mientras que las aristas conectan esos nodos y representan relaciones o conexiones entre ellos.
En un grafo dirigido, esas aristas tienen una dirección concreta, lo que indica una relación unidireccional entre nodos. Esto significa que si hay una arista del nodo A al nodo B, implica una conexión de A a B, pero no necesariamente de B a A.
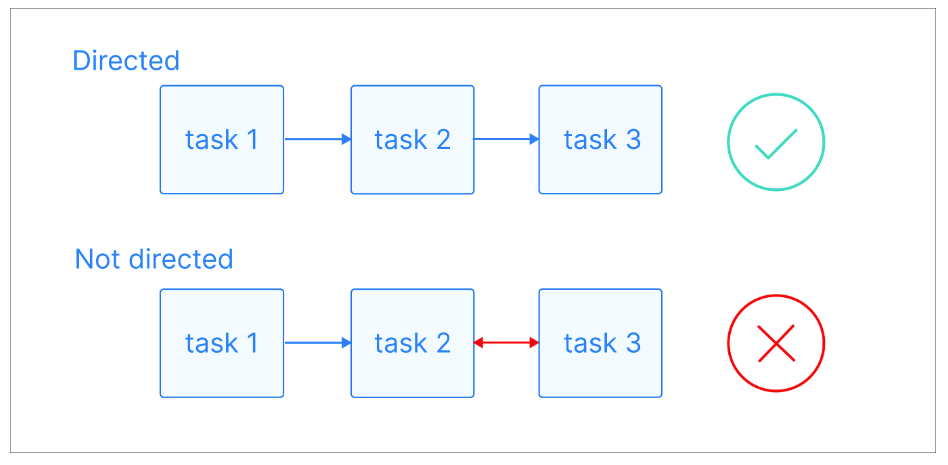
Explicación visual de los gráficos dirigidos. Fuente de la imagen: Astrónomo
Una trayectoria es una secuencia de nodos conectados por aristas dirigidas. Empieza en un nodo concreto y sigue la dirección de las aristas para llegar a otro nodo. Un camino puede tener cualquier longitud, desde un único nodo hasta una secuencia de muchos nodos, siempre que la dirección de las aristas se siga de forma coherente.
Ahora que tenemos algunas definiciones básicas, veamos qué es un DAG: Un DAG es un grafo dirigido sin ciclos dirigidos, en el que cada nodo representa una tarea concreta, y cada arista indica la dependencia entre ellas.
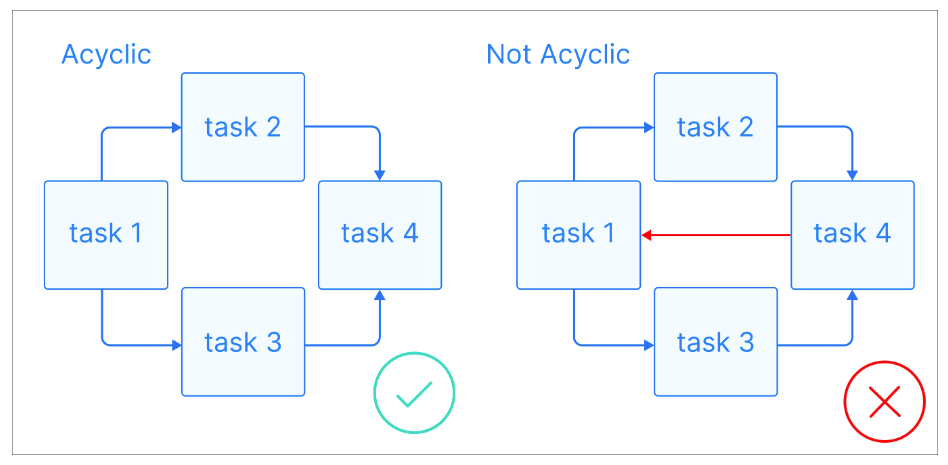 Explicación visual de los grafos acíclicos. Fuente de la imagen: Astronomer
Explicación visual de los grafos acíclicos. Fuente de la imagen: Astronomer
La clave de los DAG es que son acíclicos, lo que significa que una vez que empiezas en un nodo, sólo puedes avanzar, sin volver nunca a un nodo anterior. Esto garantiza que las tareas puedan ejecutarse en orden sin dar lugar a bucles infinitos. Los DAG suelen tener una estructura jerárquica, en la que las tareas se organizan en niveles o capas. Las tareas de un nivel superior suelen depender de la realización de tareas de niveles inferiores.
Como ingeniero de datos o alguien que realiza tareas de ingeniería de datos, a menudo te enfrentas al reto de construir canalizaciones de datos complejas que requieren ejecutar pasos, cada uno de los cuales depende del anterior. Ahí es donde entran en juego los DAG.
Al poder representar las tareas como nodos y las dependencias como aristas, los DAG imponen un orden lógico de ejecución, garantizando que las tareas se ejecuten secuencialmente en función de sus dependencias. Esto evita errores e incoherencias al ejecutar tareas fuera de orden. Además, si falla un paso, los DAG pueden identificar y volver a ejecutar las tareas afectadas, ahorrando tiempo y esfuerzo.
Si eres nuevo en la construcción de canalizaciones de datos o quieres reforzar tus cimientos, el curso Comprender la Ingeniería de Datos proporciona un excelente punto de partida.
La naturaleza acíclica de los DAGs es una de las características clave que los hace ideales para las canalizaciones de datos. Garantizan que las tareas puedan ejecutarse sin bucles infinitos ni dependencias recursivas que puedan provocar la inestabilidad del sistema.
Veamos un ejemplo sencillo de canalización de datos:
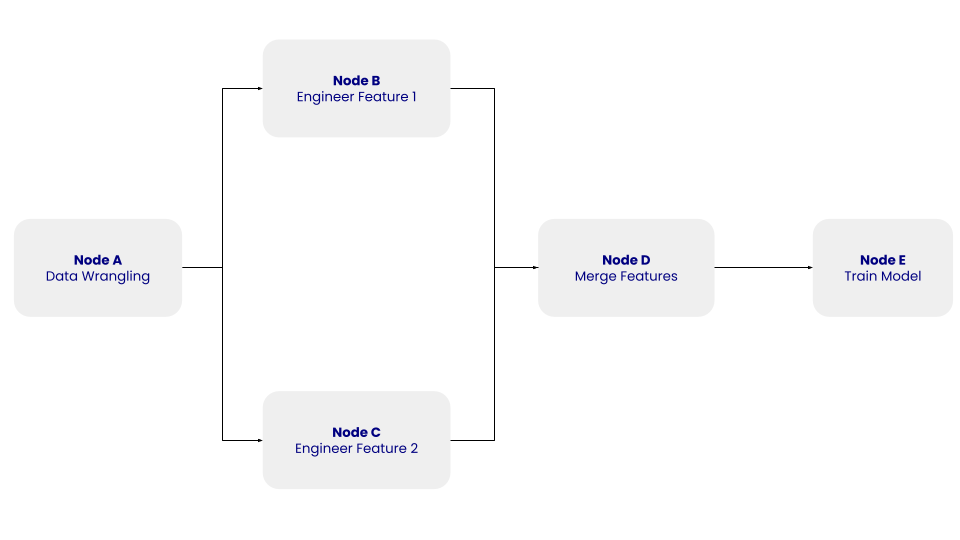 DAG La estructura de este DAG simple con los nodos A, B, C, D y E y sus dependencias. Imagen del autor.
DAG La estructura de este DAG simple con los nodos A, B, C, D y E y sus dependencias. Imagen del autor.
En el DAG anterior, el nodo A representa el paso de manipulación de datos, que implica el paso de limpieza de datos, en el que se limpian y preprocesan los datos extraídos. Los nodos B y C representan los pasos de ingeniería de rasgos, en los que los datos depurados se transforman independientemente en dos rasgos. El nodo D consiste en fusionar las características. Por último, el Nodo E representa el paso de entrenamiento del modelo, en el que se entrena un modelo de aprendizaje automático con los datos transformados.
Al DAG no le importa lo que ocurre dentro de las tareas, sino el orden en que deben ejecutarse.
Además, los DAG te permiten crear flujos de trabajo de datos automatizados y escalables, especialmente en sistemas distribuidos y entornos en la nube. Desglosan las tareas complejas de procesamiento de datos en subtareas más pequeñas, independientes y manejables, que permiten a los DAG realizar una ejecución paralela y una utilización eficiente de los recursos. Esta escalabilidad es especialmente importante cuando se trata de grandes conjuntos de datos y complejas canalizaciones de datos, ya que permite un procesamiento de datos rentable.
Por último, los DAG pueden proporcionar una representación visual de cualquier canalización de datos, lo que te ayuda a comprender y comunicar el flujo de trabajo. Esta claridad visual es importante cuando se colabora con otros miembros del equipo o con partes interesadas no técnicas. Si puedes comprender el flujo de datos y las dependencias entre las tareas, es más fácil identificar y solucionar problemas, optimizar la utilización de los recursos y tomar decisiones informadas sobre las mejoras del pipeline.
El curso sobre ETL y ELT en Python es un gran recurso para practicar la creación y optimización de canalizaciones de datos.
Los DAG se han adoptado ampliamente y tienen distintas aplicaciones en la ingeniería de datos. Ya hemos hablado de algunos de ellos en la sección anterior. Ahora vamos a explorar algunas de ellas con más detalle.
Una de las aplicaciones más comunes de los DAG es la orquestación de procesos de Extracción, Transformación y Carga (ETL). Las canalizaciones ETL implican extraer datos de diversas fuentes, transformarlos en un formato adecuado y cargarlos en un sistema de destino.
Por ejemplo, herramientas como Apache Airflow y Luigi utilizan DAGs para orquestar eficientemente los pipelines ETL. Un caso de uso práctico podría consistir en integrar datos de un sistema CRM, transformarlos para alinearlos con tus necesidades empresariales y cargarlos en un almacén de datos Snowflake para su análisis.
También puedes aprovechar los DAG para supervisar y registrar los tiempos de ejecución de las tareas en tus procesos ETL. Esto puede ayudar a identificar cuellos de botella o tareas que requieren optimización.
Los DAG también son estupendos para gestionar flujos de trabajo de datos complejos que implican múltiples tareas y dependencias. Por ejemplo, un flujo de trabajo de aprendizaje automático puede incluir tareas como ingeniería de características, entrenamiento de modelos y despliegue de modelos.
Por ejemplo, un DAG en Apache Airflow podría ejecutar scripts de selección de características y activar el entrenamiento del modelo sólo después de procesar las características, garantizando la gestión de dependencias y la reproducibilidad.
Los DAG se utilizan ampliamente en las cadenas de procesamiento de datos para gestionar el flujo de datos de múltiples fuentes y transformarlos en información valiosa. Por ejemplo, un DAG en Apache Spark podría procesar los datos de clics de un sitio web, realizar una agregación para calcular la duración de las sesiones e introducir los datos en un panel de control.
Los DAG en Spark no son definidos explícitamente por los usuarios, sino que son creados internamente por el marco para optimizar la ejecución de las transformaciones.
En el aprendizaje automático, los DAG ayudan a la naturaleza iterativa y modular de los flujos de trabajo. Te permiten experimentar con distintos pasos de preprocesamiento, algoritmos e hiperparámetros, a la vez que mantienes organizado el pipeline.
Herramientas como Kubeflow Pipelines y MLflow utilizan DAGs para gestionar los flujos de trabajo de aprendizaje automático, permitiendo una experimentación y despliegue sin fisuras. Por ejemplo, puedes utilizar los DAG para habilitar tuberías de reentrenamiento activadas por la detección de desviación de datos, garantizando que tus modelos sigan siendo precisos y relevantes a lo largo del tiempo.
Dispones de varias herramientas que te ayudan a gestionar y orquestar DAGs con eficacia. Exploremos algunas de las opciones más populares:
Apache Airflow es una plataforma muy utilizada para crear, programar y supervisar flujos de trabajo. Destaca en la definición de canalizaciones de datos complejas como DAGs. Airflow proporciona una interfaz fácil de usar para visualizar y gestionar estos DAG, facilitando la comprensión y la resolución de problemas en los flujos de trabajo de datos. Su flexibilidad y escalabilidad lo han convertido en la opción preferida de muchos equipos de ingeniería de datos.
Prefect es una moderna herramienta de orquestación que simplifica la creación y gestión de flujos de trabajo de datos. Ofrece una API basada en Python para definir DAGs, lo que facilita la integración con el código Python existente. Prefect da prioridad a la fiabilidad y la observabilidad, proporcionando funciones como reintentos automáticos, rellenos y una sólida supervisión.
Dashk es una biblioteca de computación paralela para Python que gestiona flujos de trabajo de datos distribuidos. Puede paralelizar cálculos en varios núcleos o máquinas, lo que lo hace ideal para tareas de procesamiento de datos a gran escala. Dask utiliza un modelo de ejecución basado en DAG para programar y coordinar las tareas, garantizando una utilización eficiente de los recursos.
Kubeflow Pipelines es una plataforma de código abierto para construir y desplegar flujos de trabajo de aprendizaje automático escalables. Utiliza DAGs para definir flujos de trabajo de principio a fin, desde el preprocesamiento de datos hasta el despliegue de modelos. Su estrecha integración con Kubernetes lo convierte en una opción sólida para ejecutar flujos de trabajo en entornos de nube. Kubeflow también proporciona una interfaz visual para gestionar y supervisar los flujos de trabajo, ofreciendo transparencia y control.
Dagster es una plataforma de orquestación diseñada para los flujos de trabajo de datos modernos. Hace hincapié en la modularidad y la seguridad de tipos, lo que facilita las pruebas y el mantenimiento de los DAG. Dagster se integra con herramientas populares como Apache Spark, Snowflake y dbt, por lo que es una opción excelente para equipos de ingeniería de datos con diversas tecnologías.
Antes de crear un DAG, tienes que configurar Apache Airflow. Puedes instalarlo utilizando Docker o un gestor de paquetes como pip:
pip install apache-airflowUna vez instalado, tendrás que configurar el servidor web y el programador de Airflow. Esto implica configurar e inicializar las conexiones a la base de datos e iniciar el servidor web:
airflow db init
airflow webserver --port 8080Con Airflow configurado, puedes crear tu DAG. Puedes utilizar Python para definir el DAG y sus tareas como se indica a continuación:
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG(
'simple_dag',
start_date=datetime(2023, 1, 1),
schedule_interval=None,
catchup=False
) as dag:
task1 = BashOperator(
task_id='task_1',
bash_command='echo "Hello, World!"'
)
task2 = BashOperator(
task_id='task_2',
bash_command='echo "This is task 2"'
)
task1 >> task2En este ejemplo, el DAG simple contiene dos tareas: task_1 y task_2. El operador >> establece una dependencia entre las tareas, asegurando que task_2 sólo se ejecute después de que task_1 se haya completado.
Una vez que tu DAG está definido y desplegado en Airflow, puedes interactuar con él a través de la interfaz web.
Los DAGs funcionarán de dos maneras:
schedule es muy habitual.Cada vez que ejecutas un DAG, se crea una nueva instancia de ese DAG, llamada DAG ejecutado. Las Ejecuciones DAG pueden ejecutarse en paralelo para el mismo DAG, y cada una tiene un intervalo de datos definido, que identifica el periodo de datos sobre el que deben operar las tareas.
Tras activarlo, puedes supervisar su progreso en la vista DAG, que representa visualmente el flujo de trabajo.
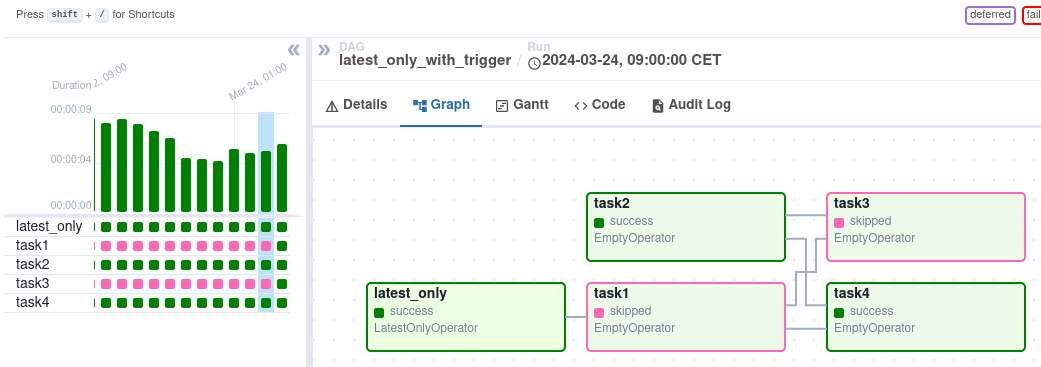 Vista DAG en la interfaz Vista DAG en la interfaz Airflow. Fuente de la imagen: Flujo de aire
Vista DAG en la interfaz Vista DAG en la interfaz Airflow. Fuente de la imagen: Flujo de aire
La vistaGráfico ofrece una visión detallada de una ejecución DAG concreta, mostrando las dependencias de las tareas y los tiempos de ejecución. La vista Tarea Instancias proporciona información granular sobre tareas individuales, incluyendo su estado, horas de inicio y fin, y registros. Puedes examinar los registros de tareas para solucionar errores y comprender la causa raíz de los fallos. La vista Instancias de tareas también muestra la duración de las tareas, lo que te ayuda a identificar posibles problemas de rendimiento.
Los DAG son un concepto fundamental en la ingeniería de datos, ya que proporcionan una forma visual y estructurada de representar flujos de trabajo complejos. Comprender los nodos, las aristas y las dependencias te ayuda a diseñar y gestionar eficazmente los conductos de datos.
Los DAG se utilizan ampliamente para orquestar procesos ETL, gestionar pipelines de procesamiento de datos y automatizar flujos de trabajo de aprendizaje automático. Puedes aprovechar herramientas como Apache Airflow, Prefect y Dask para crear y gestionar DAGs con eficacia. Estas herramientas proporcionan interfaces fáciles de usar, capacidades de programación y funciones avanzadas de supervisión, gestión de errores y escalado.
Para adquirir experiencia práctica, este curso introductorio sobre Airflow en Python puede ayudarte a aprender a crear y gestionar DAGs con eficacia. Para una comprensión más amplia de los conceptos y flujos de trabajo de la ingeniería de datos, ¡este curso sobre la comprensión de la ingeniería de datos proporciona una base excelente!
¡Aprende más sobre ingeniería de datos con estos cursos!
programa
Curso
Curso
blog
Kurtis Pykes
11 min
blog
Tim Lu
12 min
blog
Matt Crabtree
10 min
blog
DataCamp Team
11 min
Tutorial
Nic Raboy
Tutorial
Abid Ali Awan

