
programa
Fundamentos de agentes de IA
6 h
I analyzed hundreds of GitHub repositories to understand why AI coding agents often feel much more capable in software engineering than they do in data science work. What I found suggests this is not just a tooling gap. It reflects a deeper difference in where meaning lives in each kind of code.
If you have used an AI coding agent in a software engineering codebase, you have probably seen how effective it can be. The agent navigates architecture, follows abstractions, and makes changes that fit surprisingly well with the rest of the system.
Then you open a data science notebook, and the experience often changes.
The agent can still write valid code. It can still follow instructions. But it often does not fully understand what matters: why this dataset, why this filter, why this time window, why this output changed the direction of the analysis.
It treats the notebook like a software project, and that is only part of what it is.
I wanted to understand why. So I analyzed hundreds of GitHub repositories across data science and software engineering, measuring entropy, reference patterns, and coupling behavior.
What I found surprised me, and I think it has real implications for anyone building or using AI agents in analytical work.
I measured Shannon entropy at three levels of abstraction for each repository: character-level, token-level, and AST-level. Each captures a different dimension of variation in code.
Code Entropy Distribution: Data Science vs Software Engineering violin plots
The pattern that emerged was what I think of as an entropy inversion.
At the character level, data science code tends to have higher entropy than software engineering code. That makes intuitive sense. Data science work is full of varied column names, dataset labels, ad hoc variables, and domain-specific identifiers that make the code look noisy and irregular.
At the token level, the two domains are much closer. They rely on many of the same syntactic building blocks.
But at the AST level, where we look at structural diversity, the picture flips.
Software engineering code tends to encode much more variation in structure. It creates more distinct behaviors through abstractions, interfaces, modules, and internal logic.
Data science code, by contrast, often reuses a smaller set of operations across changing context: load, filter, group, aggregate, visualize, inspect, adjust.
Put simply, data science code often looks more complex at the surface, while software engineering code often carries more complexity in structure.
This is not just a stylistic difference. It points to a deeper difference in how the two kinds of work store meaning.
The entropy inversion becomes easier to understand when you think about what each type of code is actually doing.
In software engineering, meaning is often compressed into structure. Functions, interfaces, modules, types, and class boundaries do a great deal of the work. Once those abstractions are established, they stabilize behavior and reduce future uncertainty.
Much of the meaning is inside the code itself.
In data science, meaning stays much more closely tied to external context. It depends on the dataset, the columns, the intermediate outputs, the assumptions behind a transformation, and the evolving question the analyst is trying to answer. The code is not just expressing logic. It is pointing to a specific analytical situation.
That difference is one of the most useful ways to understand why agents often behave so differently in the two domains.
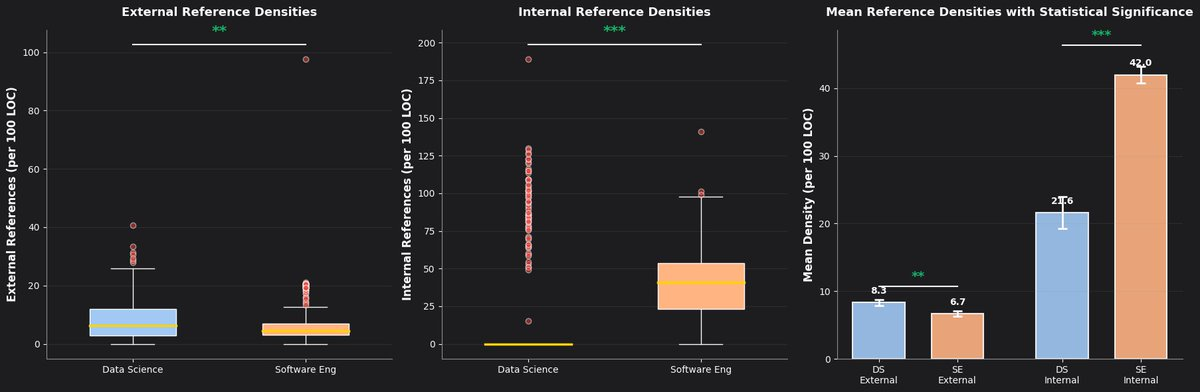
I also measured external and internal reference densities per 100 lines of code across both groups.
External and Internal Reference Densities with statistical significance
The distinction is clear. Data science code refers outward more often: to datasets, tables, columns, temporary objects, and states that exist outside the code itself.
Software engineering code is more internally self-referential. It builds meaning more often by pointing to functions, classes, modules, and abstractions defined elsewhere in the codebase.
Data code points outward. Software code points inward.
That matters for agents. In one case, much of the relevant context is in the codebase. In the other, much of it sits in the surrounding analytical state.
One of the more interesting findings was around coupling. Notebook-style workflows showed much tighter coupling per 100 lines of code than software engineering codebases.
That is not necessarily bad design. It reflects something fundamental about exploratory analysis: the question itself is often still moving. You are testing assumptions, following odd results, checking edge cases, and changing direction as you learn.
In that setting, abstraction often does not pay off in the same way it does in software engineering. Premature structure can reduce optionality before you understand what matters. Tighter coupling is often a consequence of exploration, not simply poor engineering.
There is also an important difference in how the two domains explain themselves.
In software engineering, code often explains itself through structure. Types, interfaces, and abstractions carry much of the meaning, and comments are usually secondary.
In data science, comments, outputs, and state often carry part of the meaning. A note like “removed outliers above the 99th percentile, confirmed this does not affect the main cohort” is not just extra documentation.
It captures an analytical decision that may not be recoverable from the code alone. A table or plot halfway through the notebook may explain why the next part of the analysis exists at all.
This matters for agents. An agent that ignores comments, inline results, and evolving state in a notebook is missing part of the analysis. In a software engineering codebase, that information is often supplementary. In data science work, it often is not.
The practical implication is this: agents work best when their tools match where the meaning lives.
In software engineering, an effective agent navigates architecture. It follows the call graph, respects interfaces, and keeps changes consistent across a codebase. That works because much of the meaning is encoded in structure.
In data science, an effective agent needs to do more than navigate code. It needs to understand what the data actually contains, track state across steps, follow the provenance of variables, and reason about why a transformation or filter was applied several steps earlier.
An agent built for software engineering will not automatically transfer well to data science work. The issue is not just syntax. It is that the underlying information structure is different.
This also helps explain something that often puzzles engineers: why notebooks remain so central despite their obvious limitations.
The answer is that notebooks keep meaning close to the data while the analytical question is still evolving. A notebook is not just a badly structured Python module. It is a different artifact built for a different stage of work. It keeps code, outputs, and decisions close together while the analysis is still taking shape.
That is why a notebook can feel intuitive to the analyst who has been living inside the context, and awkward to an agent that only sees the code.
Refactoring a notebook into clean, modular code before the analytical question is settled is often not an improvement. It can separate the logic from the context that gave it meaning in the first place.
The real opportunity for AI agents in data science is not simply to copy what already works in software engineering. It is to help close the production gap: the distance between an insight found in exploration and a reproducible, deployable workflow.
That gap exists because notebooks preserve analytical context at the cost of structural cleanliness. An agent that can understand both the analytical context and the structural requirements of production systems could help bridge that gap without forcing the human analyst to leave exploratory mode too early.
That is a harder problem than navigating a codebase. But it is also the more important one.
To summarize what the analysis suggests across the repositories studied:
When I started this analysis, I expected to find that data science code was simply less well-structured than software engineering code. What I found instead was that it is differently structured for good reasons, with meaning often living in a different place.
That has practical consequences for anyone building or evaluating AI agents for analytical work. The real question is not whether an agent can write correct Python. It is whether it understands what the data is, why the analysis takes the shape it does, and what decisions were made along the way that are not visible in code alone.
Data science code is not immature software engineering. It is a different optimization entirely: more dependent on external state, less reliant on durable internal structure during exploration, and shaped by context as much as by code.
Once you see that, notebooks stop looking like failed software projects and start looking more like what they really are: working surfaces for reasoning over changing data.
I'm continuing this analysis with a larger dataset of 1,000 or more repositories and additional metrics. If you want to go deeper on how AI agents are being built to work with data in context (including persistent execution architectures that maintain data state across sessions), DataCamp's AI agent fundamentals track is a solid place to start.
Top DataCamp Courses
programa
Curso
Curso
blog
Austin Chia
12 min
blog
Vikash Singh
13 min
blog
Javier Canales Luna
15 min
podcast
cheat-sheet
Alex Olteanu
code-along
Joe Franklin



