
Curso
Bases de datos vectoriales para incrustaciones con Pinecone
3 h
9.6K
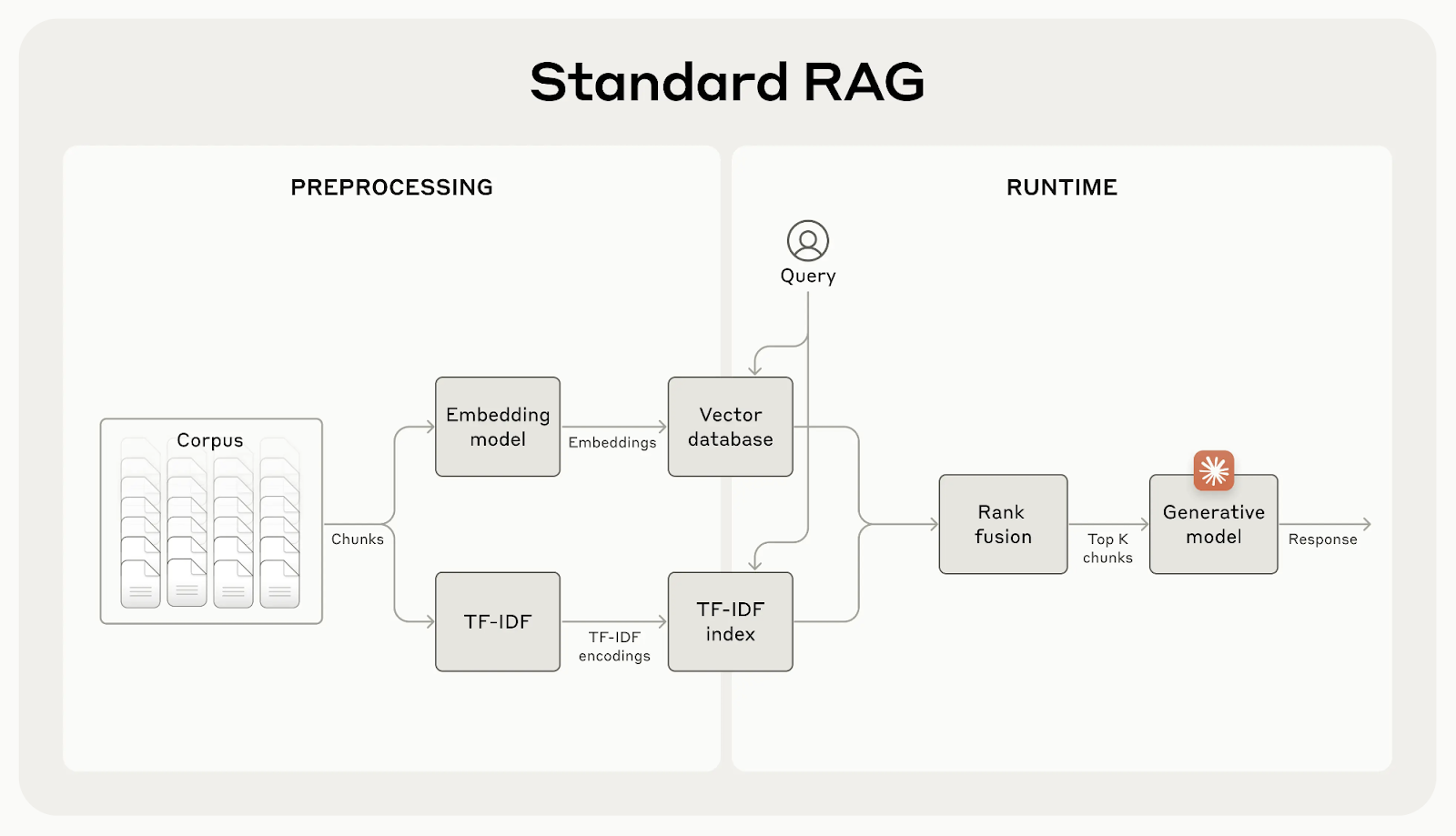
Aunque los sistemas tradicionales de GAR son eficaces, tienen un fallo importante: suelen dividir los documentos en trozos pequeños para facilitar la recuperación, pero esto puede eliminar el contexto importante.
Por ejemplo, un trozo puede decir "Sus más de 3,85 millones de habitantes la convierten en la ciudad más poblada de la Unión Europea" sin mencionar de qué ciudad o país está hablando. Esta falta de contexto puede dar lugar a resultados incompletos o irrelevantes, sobre todo cuando se necesitan detalles específicos.
Fuente: Presentación de la recuperación contextual
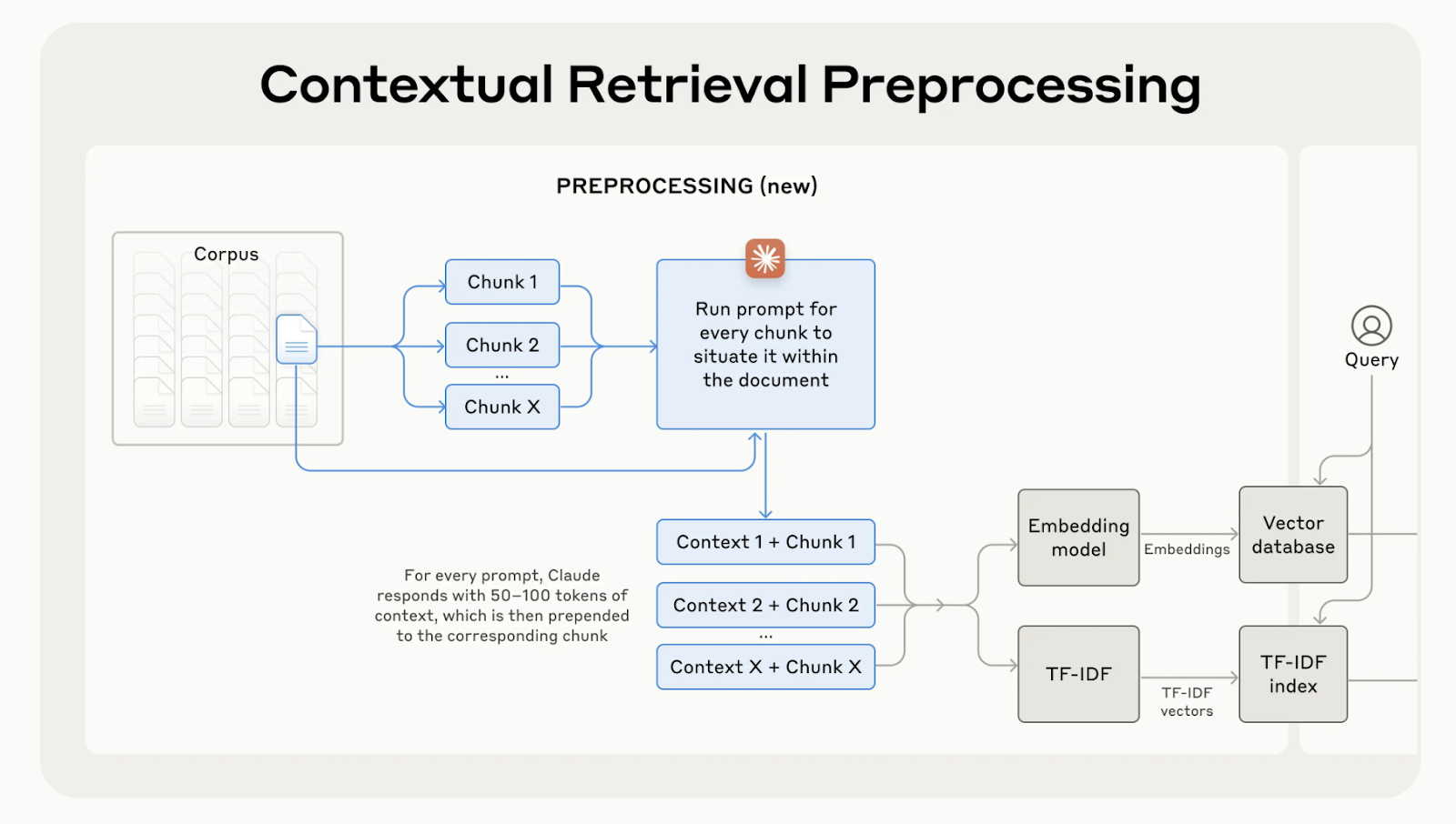
La recuperación contextual lo soluciona generando y añadiendo una breve explicación específica del contexto a cada trozo antes de incrustarlo. En el ejemplo anterior, el trozo se transformaría de la siguiente manera:
contextualized_chunk = """Berlin is the capital and largest city of Germany, known for being the EU's most populous city within its limits.
Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.
"""
Fuente: Presentación de la recuperación contextual
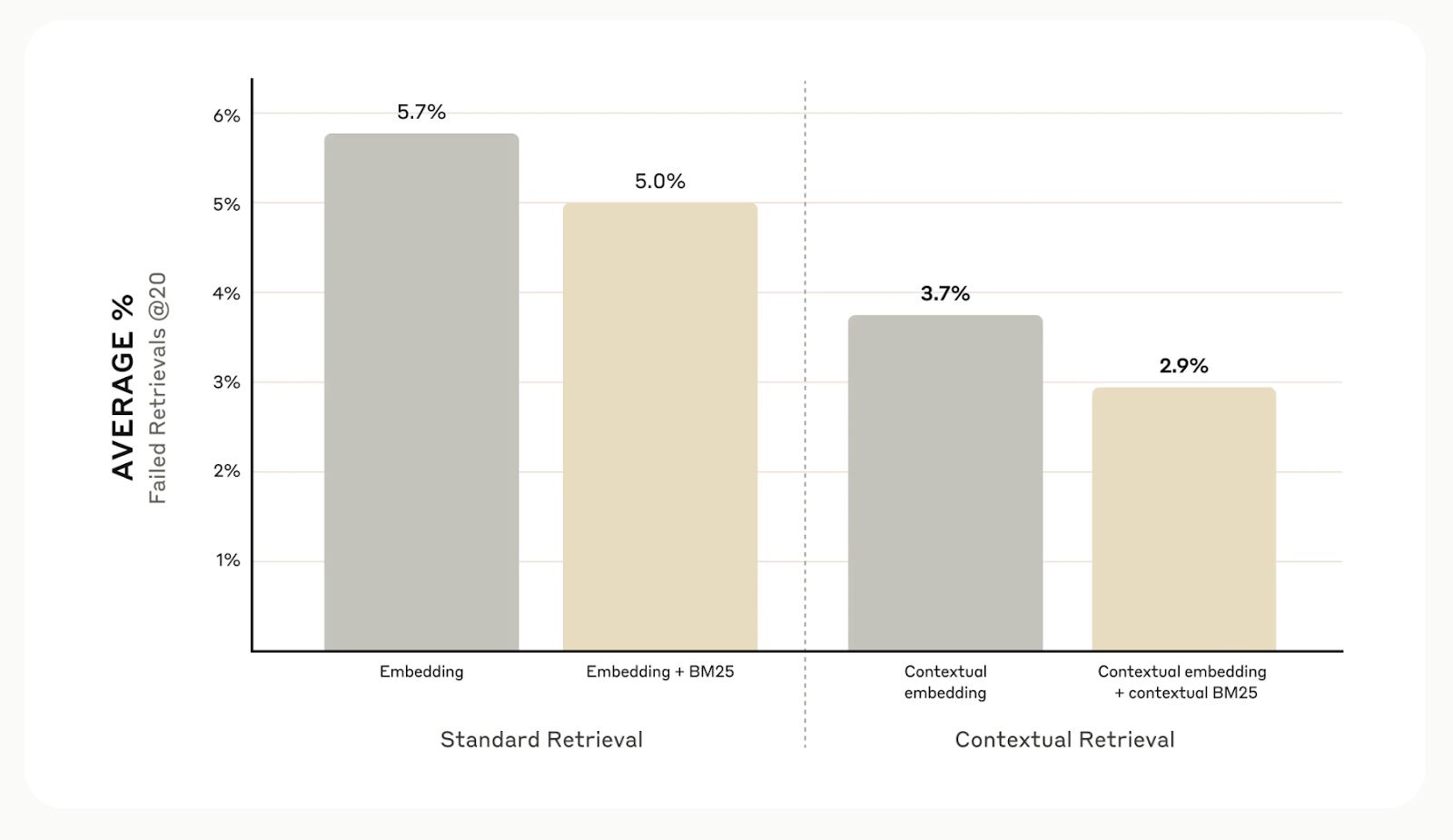
En general, las pruebas internas de Anthropic en distintos campos, como bases de código, artículos científicos y ficción, demuestran que la recuperación contextual reduce los errores de recuperación en un 49% cuando se utiliza con modelos de incrustación contextual y BM contextual25.
Fuente: Presentación de la recuperación contextual
A continuación te explicaré paso a paso cómo poner en práctica la recuperación contextual. Utilizaremos como ejemplo el siguiente documento de muestra:
# Input text for the knowledge base
input_text = """Berlin is the capital and largest city of Germany, both by area and by population.
Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.
The city is also one of the states of Germany and is the third smallest state in the country in terms of area.
Paris is the capital and most populous city of France.
It is situated along the Seine River in the north-central part of the country.
The city has a population of over 2.1 million residents within its administrative limits, making it one of Europe's major population centers."""El primer paso es dividir el documento de muestra en trozos más pequeños e independientes. En este caso, lo dividiremos en frases individuales.
# Splitting the input text into smaller chunks
test_chunks = [
'Berlin is the capital and largest city of Germany, both by area and by population.',
"\\n\\nIts more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.",
'\\n\\nThe city is also one of the states of Germany and is the third smallest state in the country in terms of area.',
'\\n\\n# Paris is the capital and most populous city of France.',
'\\n\\n# It is situated along the Seine River in the north-central part of the country.',
"\\n\\n# The city has a population of over 2.1 million residents within its administrative limits, making it one of Europe's major population centers."
]A continuación, configuraremos el indicador que nuestro modelo utilizará para generar el contexto de cada trozo. Anthropic ha proporcionado una plantilla útil para ello. La consulta tomará dos entradas: el documento completo y el trozo concreto de texto que queremos situar.
from langchain.prompts import ChatPromptTemplate, PromptTemplate, HumanMessagePromptTemplate
# Define the prompt for generating contextual information
anthropic_contextual_retrieval_system_prompt = """<document>
{WHOLE_DOCUMENT}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{CHUNK_CONTENT}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else."""
# Create a PromptTemplate for WHOLE_DOCUMENT and CHUNK_CONTENT
anthropic_prompt_template = PromptTemplate(
input_variables=['WHOLE_DOCUMENT', 'CHUNK_CONTENT'],
template=anthropic_contextual_retrieval_system_prompt
)
# Wrap the prompt in a HumanMessagePromptTemplate
human_message_prompt = HumanMessagePromptTemplate(prompt=anthropic_prompt_template)
# Create the final ChatPromptTemplate
anthropic_contextual_retrieval_final_prompt = ChatPromptTemplate(
input_variables=['WHOLE_DOCUMENT', 'CHUNK_CONTENT'],
messages=[human_message_prompt]
)Aquí puedes elegir el LLM que quieras para generar el contexto de cada trozo. Para nuestro ejemplo, utilizaremos la GPT-4o de OpenAI GPT-4o de OpenAI.
import os
from langchain_openai import ChatOpenAI
# Load environment variables
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# Initialize the model instance
llm_model_instance = ChatOpenAI(
model="gpt-4o",
)Conectaremos la plantilla de avisos con el modelo de lenguaje para crear una cadena LLM que esté lista para procesar los trozos que hemos creado antes.
from langchain.output_parsers import StrOutputParser
# Chain the prompt with the model instance
contextual_chunk_creation = anthropic_contextual_retrieval_final_prompt | llm_model_instance | StrOutputParser()Ahora recorreremos nuestros trozos, generaremos la información contextual de cada uno e imprimiremos los resultados utilizando la cadena LLM contextual_chunk_creation.
# Process each chunk and generate contextual information
for test_chunk in test_chunks:
res = contextual_chunk_creation.invoke({
"WHOLE_DOCUMENT": input_text,
"CHUNK_CONTENT": test_chunk
})
print(res)
print('-----')The document compares Berlin and Paris, highlighting Berlin as Germany's capital and largest city by area and population, and noting its significance within the European Union.
-----
Berlin is the capital and largest city of Germany, known for being the EU's most populous city within its limits.
-----
Berlin is the capital and largest city of Germany, both by area and by population.
-----
Paris, the capital of France, is a major population center in Europe with over 2.1 million residents.
-----
Paris is the capital and most populous city of France.
-----
Paris is the capital and most populous city of France, with a population of over 2.1 million residents within its administrative limits.
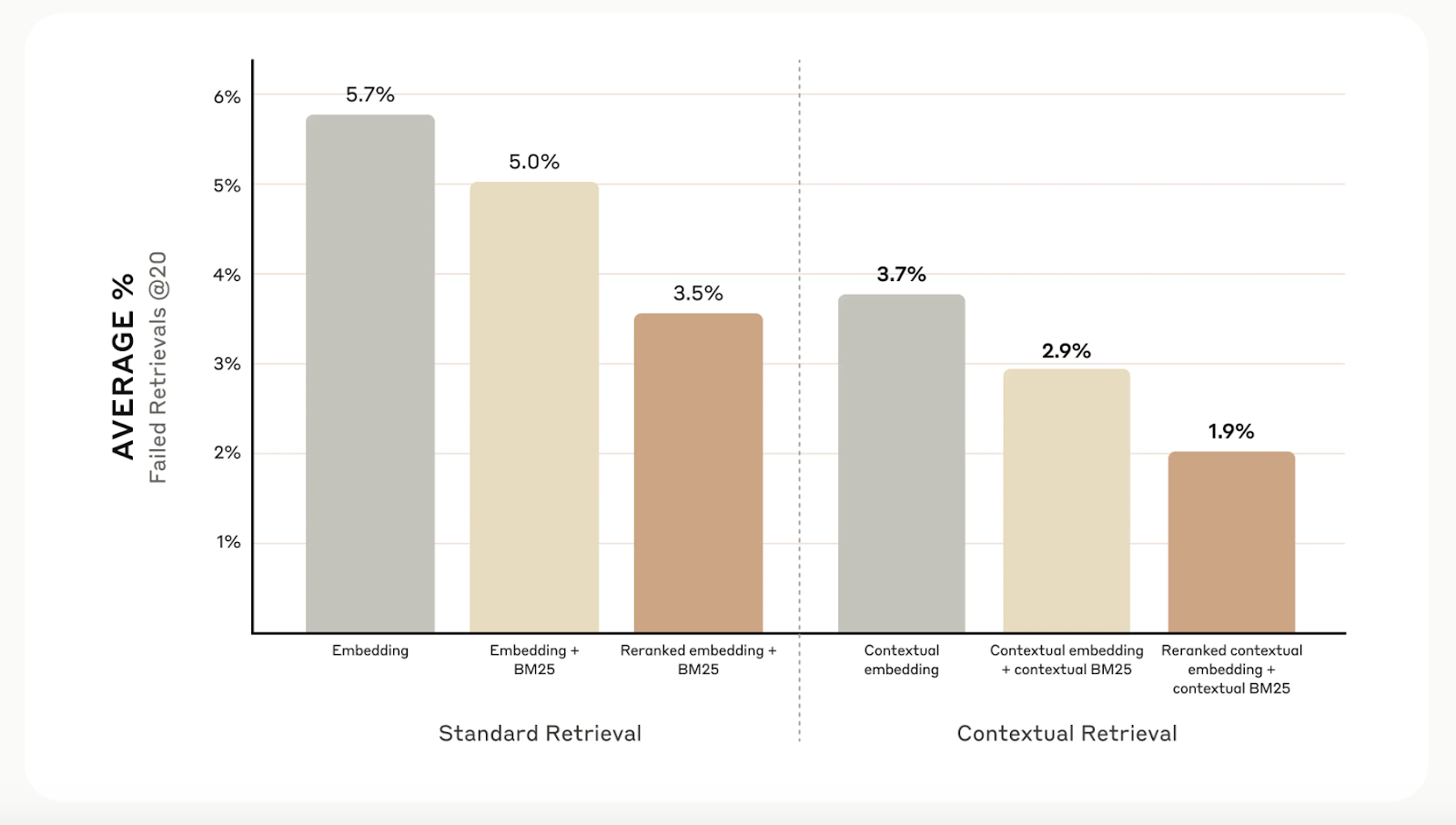
-----Aunque la recuperación contextual aumenta la precisión de la recuperación, puedes llevarla aún más lejos con reranking. Esta técnica de filtrado garantiza que sólo se envíen al modelo los trozos más relevantes, mejorando la calidad de la respuesta y reduciendo el coste y el tiempo de procesamiento.
La reordenación funciona puntuando los trozos recuperados en el primer paso y quedándose sólo con los mejores. En nuestras pruebas, el reranking redujo los errores de recuperación del 5,7% a sólo el 1,9%, mejorando la precisión en un 67% en comparación con los métodos tradicionales.
Fuente: Presentación de la recuperación contextual
La investigación antrópica ha descubierto que no todas las situaciones requieren la complejidad de la recuperación contextual. Para las bases de conocimientos más pequeñas, de menos de 200.000 tokens (unas 500 páginas), una opción mejor podría ser incluir toda la base de conocimientos directamente en la consulta del modelo, omitiendo por completo la necesidad de sistemas de recuperación.
También sugieren aprovechar caché rápidauna función introducida para Claude. Al almacenar en caché los avisos de uso frecuente entre las llamadas a la API, los desarrolladores pueden reducir los costes hasta un 90% y acelerar los tiempos de respuesta más del doble. Este libro de cocina de caché rápida proporciona una guía paso a paso para ponerlo en práctica.
La recuperación contextual de Anthropic es un método sencillo pero eficaz para mejorar los sistemas de recuperación. La combinación de incrustaciones contextuales, BM25 y reordenación mejora significativamente la precisión de estos sistemas.
Para saber más sobre las distintas técnicas de recuperación, te recomiendo los siguientes blogs:
Aprende IA con estos cursos
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita



