
Curso
Bancos de dados vetoriais para incorporações com Pinecone
3 h
9.6K
Embora os sistemas RAG tradicionais sejam eficazes, eles têm uma falha importante: geralmente dividem os documentos em pequenos pedaços para facilitar a recuperação, mas isso pode remover um contexto importante.
Por exemplo, um trecho pode dizer "Seus mais de 3,85 milhões de habitantes fazem dela a cidade mais populosa da União Europeia" sem mencionar de qual cidade ou país você está falando. Essa falta de contexto pode levar a resultados incompletos ou irrelevantes, especialmente quando são necessários detalhes específicos.
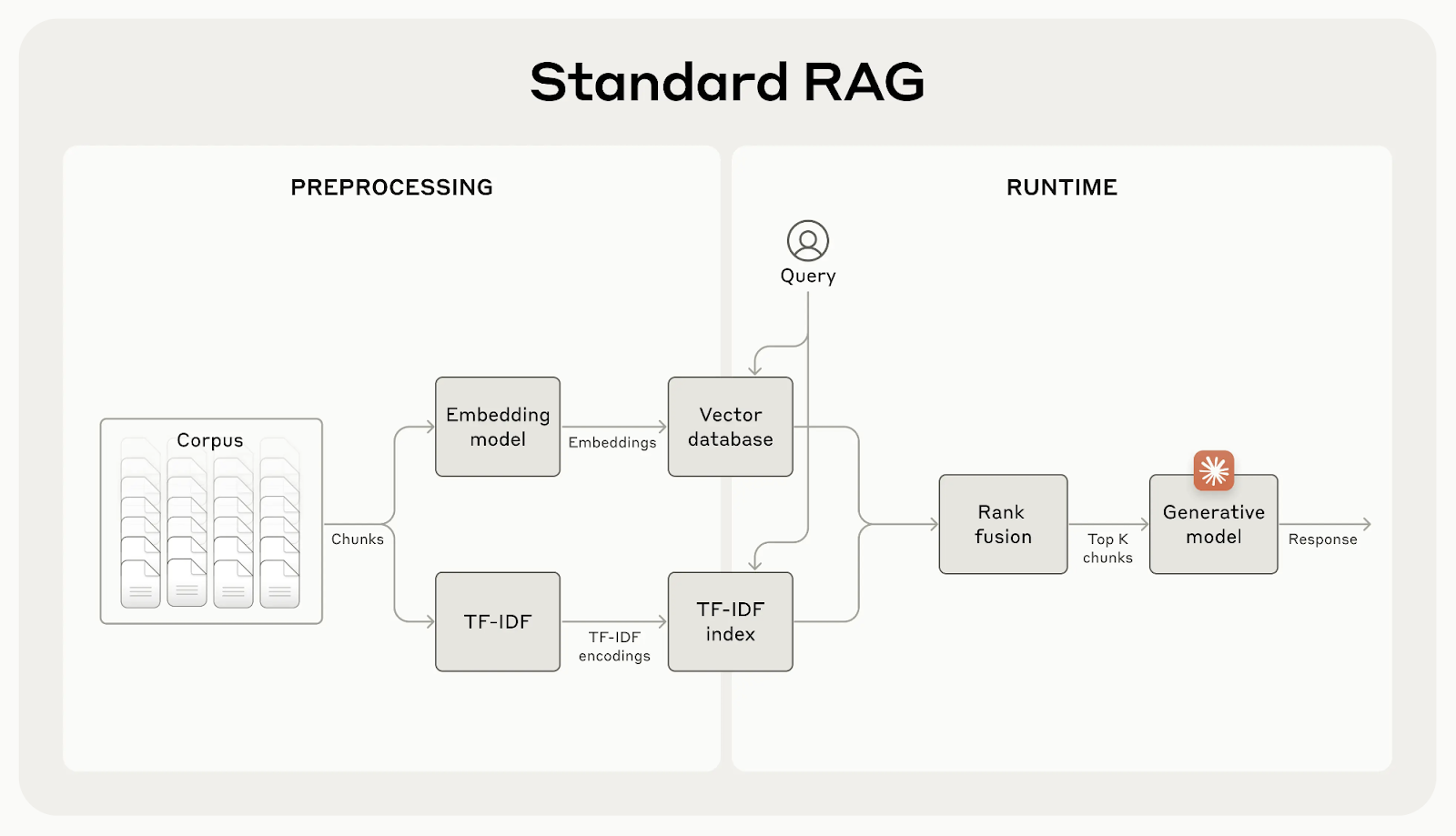
Fonte: Apresentando a recuperação contextual
A recuperação contextual corrige isso gerando e adicionando uma breve explicação específica do contexto a cada bloco antes de incorporá-lo. No exemplo acima, o bloco seria transformado da seguinte forma:
contextualized_chunk = """Berlin is the capital and largest city of Germany, known for being the EU's most populous city within its limits.
Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.
"""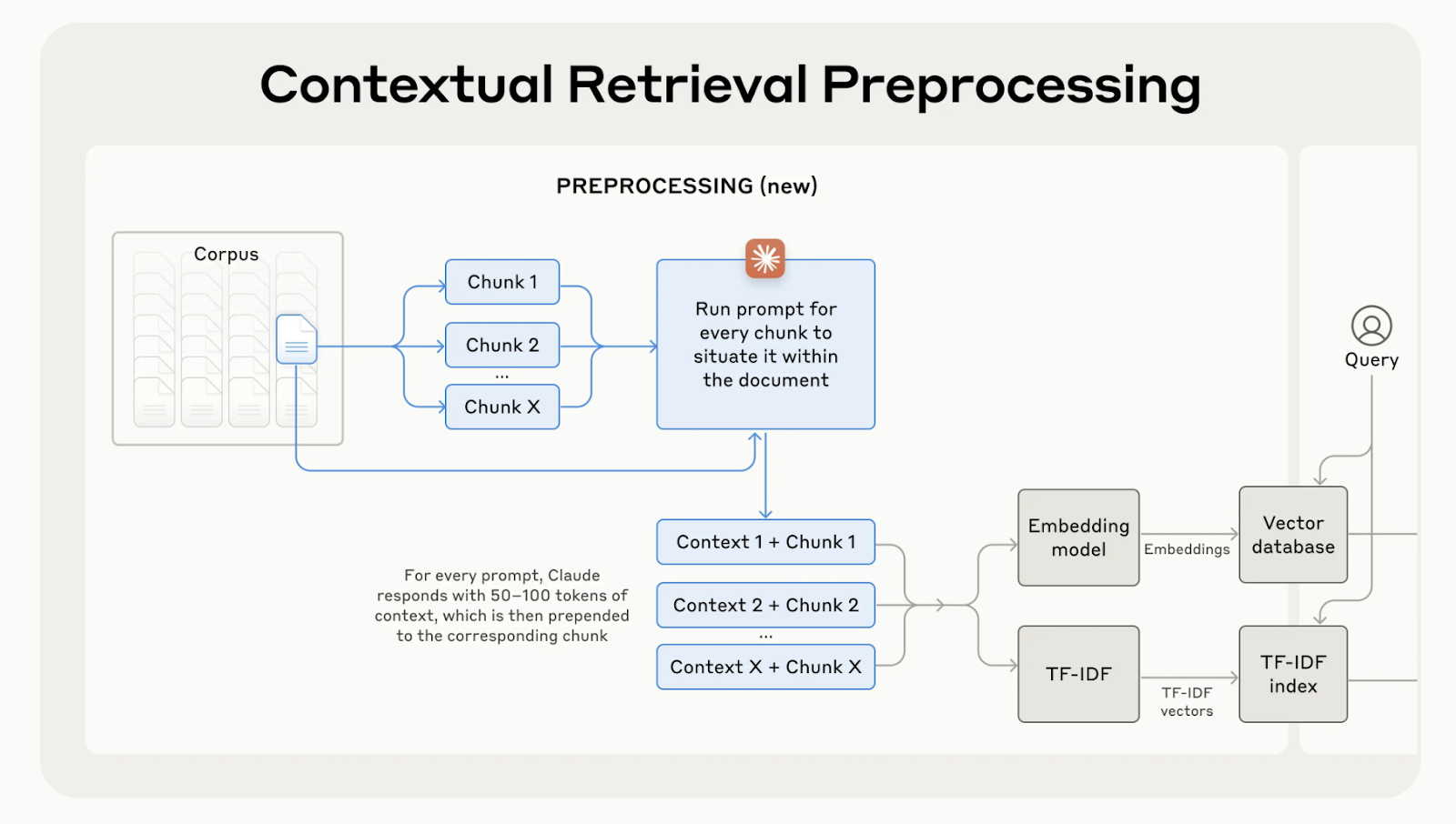
Fonte: Apresentando a recuperação contextual
No geral, os testes internos da Anthropic em diferentes campos, incluindo bases de código, artigos científicos e ficção, mostram que a recuperação contextual reduz os erros de recuperação em 49% quando usada com modelos de incorporação contextual e Contextual BM25.
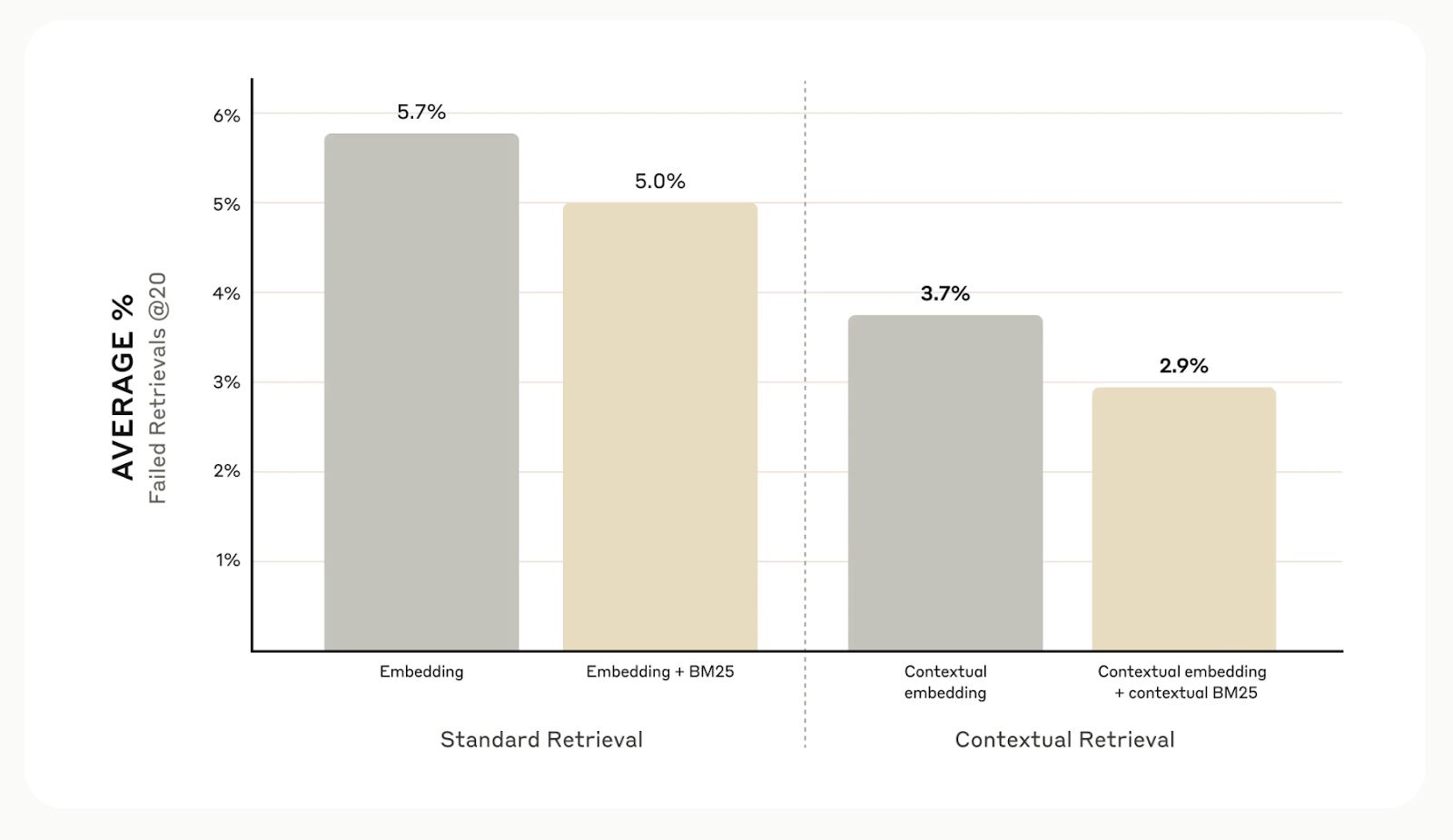
Fonte: Apresentando a recuperação contextual
Agora explicarei passo a passo como implementar a recuperação contextual. Usaremos o seguinte documento de amostra como exemplo:
# Input text for the knowledge base
input_text = """Berlin is the capital and largest city of Germany, both by area and by population.
Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.
The city is also one of the states of Germany and is the third smallest state in the country in terms of area.
Paris is the capital and most populous city of France.
It is situated along the Seine River in the north-central part of the country.
The city has a population of over 2.1 million residents within its administrative limits, making it one of Europe's major population centers."""A primeira etapa é dividir o documento de amostra em partes menores e independentes. Nesse caso, vamos dividi-lo em frases individuais.
# Splitting the input text into smaller chunks
test_chunks = [
'Berlin is the capital and largest city of Germany, both by area and by population.',
"\\n\\nIts more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.",
'\\n\\nThe city is also one of the states of Germany and is the third smallest state in the country in terms of area.',
'\\n\\n# Paris is the capital and most populous city of France.',
'\\n\\n# It is situated along the Seine River in the north-central part of the country.',
"\\n\\n# The city has a population of over 2.1 million residents within its administrative limits, making it one of Europe's major population centers."
]Em seguida, configuraremos o prompt que nosso modelo usará para gerar contexto para cada bloco. O Anthropic forneceu um modelo útil para isso. O prompt receberá duas entradas: o documento inteiro e a parte específica do texto que você deseja situar.
from langchain.prompts import ChatPromptTemplate, PromptTemplate, HumanMessagePromptTemplate
# Define the prompt for generating contextual information
anthropic_contextual_retrieval_system_prompt = """<document>
{WHOLE_DOCUMENT}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{CHUNK_CONTENT}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else."""
# Create a PromptTemplate for WHOLE_DOCUMENT and CHUNK_CONTENT
anthropic_prompt_template = PromptTemplate(
input_variables=['WHOLE_DOCUMENT', 'CHUNK_CONTENT'],
template=anthropic_contextual_retrieval_system_prompt
)
# Wrap the prompt in a HumanMessagePromptTemplate
human_message_prompt = HumanMessagePromptTemplate(prompt=anthropic_prompt_template)
# Create the final ChatPromptTemplate
anthropic_contextual_retrieval_final_prompt = ChatPromptTemplate(
input_variables=['WHOLE_DOCUMENT', 'CHUNK_CONTENT'],
messages=[human_message_prompt]
)Aqui, você pode escolher qualquer LLM que desejar para gerar contexto para cada bloco. Em nosso exemplo, usaremos o GPT-4o da OpenAI.
import os
from langchain_openai import ChatOpenAI
# Load environment variables
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# Initialize the model instance
llm_model_instance = ChatOpenAI(
model="gpt-4o",
)Conectaremos o modelo de prompt ao modelo de linguagem para criar uma cadeia LLM pronta para processar os blocos que criamos anteriormente.
from langchain.output_parsers import StrOutputParser
# Chain the prompt with the model instance
contextual_chunk_creation = anthropic_contextual_retrieval_final_prompt | llm_model_instance | StrOutputParser()Agora, percorreremos nossos blocos, geraremos as informações contextuais para cada um deles e imprimiremos os resultados usando a cadeia contextual_chunk_creation LLM.
# Process each chunk and generate contextual information
for test_chunk in test_chunks:
res = contextual_chunk_creation.invoke({
"WHOLE_DOCUMENT": input_text,
"CHUNK_CONTENT": test_chunk
})
print(res)
print('-----')The document compares Berlin and Paris, highlighting Berlin as Germany's capital and largest city by area and population, and noting its significance within the European Union.
-----
Berlin is the capital and largest city of Germany, known for being the EU's most populous city within its limits.
-----
Berlin is the capital and largest city of Germany, both by area and by population.
-----
Paris, the capital of France, is a major population center in Europe with over 2.1 million residents.
-----
Paris is the capital and most populous city of France.
-----
Paris is the capital and most populous city of France, with a population of over 2.1 million residents within its administrative limits.
-----Embora a recuperação contextual aumente a precisão da recuperação, você pode ir ainda mais longe com reranking. Essa técnica de filtragem garante que apenas os blocos mais relevantes sejam enviados ao modelo, melhorando a qualidade da resposta e reduzindo o custo e o tempo de processamento.
O ranqueamento funciona pontuando os blocos recuperados na primeira etapa e mantendo apenas os melhores. Em nossos testes, o reranking reduziu os erros de recuperação de 5,7% para apenas 1,9%, melhorando a precisão em 67% em comparação com os métodos tradicionais.
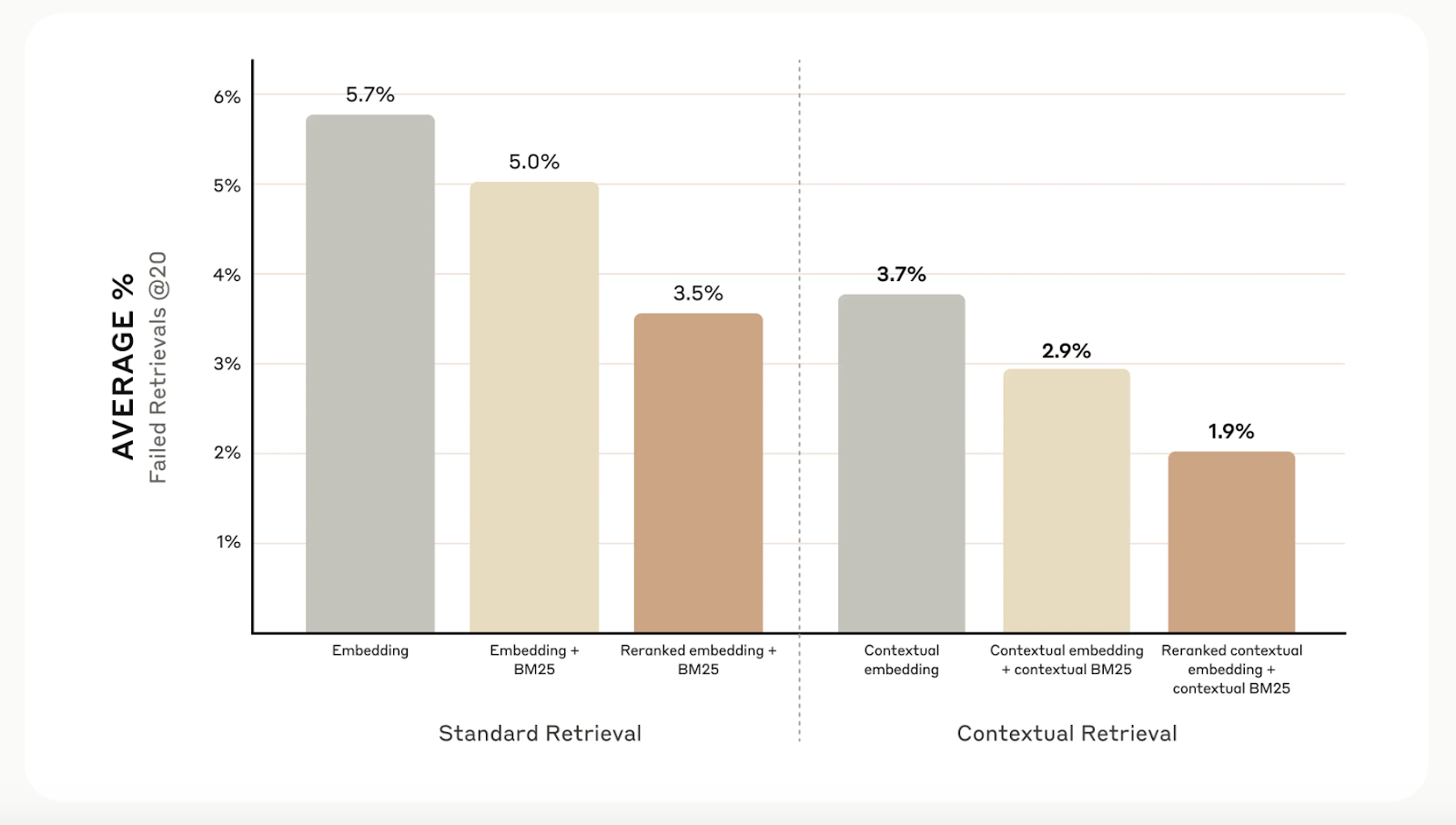
Fonte: Apresentando a recuperação contextual
A pesquisa antrópica descobriu que nem todas as situações exigem a complexidade da recuperação contextual. Para bases de conhecimento menores, com menos de 200.000 tokens (cerca de 500 páginas), uma opção melhor pode ser incluir toda a base de conhecimento diretamente no prompt do modelo, ignorando totalmente a necessidade de sistemas de recuperação.
Eles também sugerem que você aproveite as vantagens do prompt cachingum recurso introduzido para o Claude. Ao armazenar em cache os prompts usados com frequência entre as chamadas de API, os desenvolvedores podem reduzir os custos em até 90% e acelerar os tempos de resposta em mais de duas vezes. Este livro de receitas de cache imediato fornece orientação passo a passo para você implementar isso.
A recuperação contextual do Anthropic é um método simples, mas eficaz, para aprimorar os sistemas de recuperação. A combinação de embeddings contextuais, BM25 e reranking melhora significativamente a precisão desses sistemas.
Para saber mais sobre diferentes técnicas de recuperação, recomendo os seguintes blogs:
Aprenda IA com estes cursos!
Curso
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Zoumana Keita


