
Course
Vector Databases for Embeddings with Pinecone
3 hr
9.6K
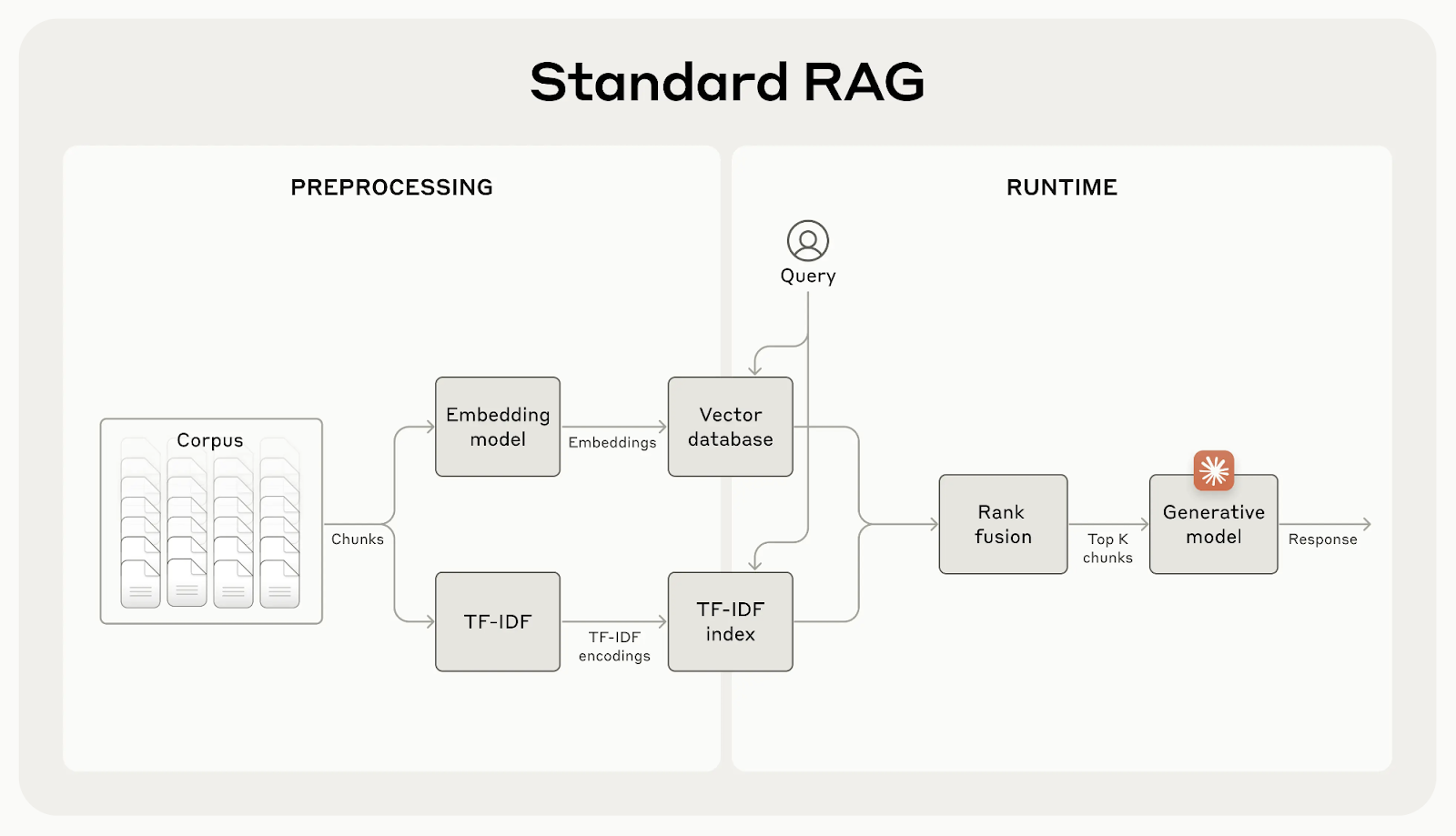
While traditional RAG systems are effective, they have a major flaw: they often split documents into small chunks to make retrieval easier, but this can remove important context.
For example, a chunk might say “Its more than 3.85 million inhabitants make it the European Union's most populous city” without mentioning which city or country it's talking about. This lack of context can lead to incomplete or irrelevant results, especially when specific details are needed.
Source: Introducing Contextual Retrieval
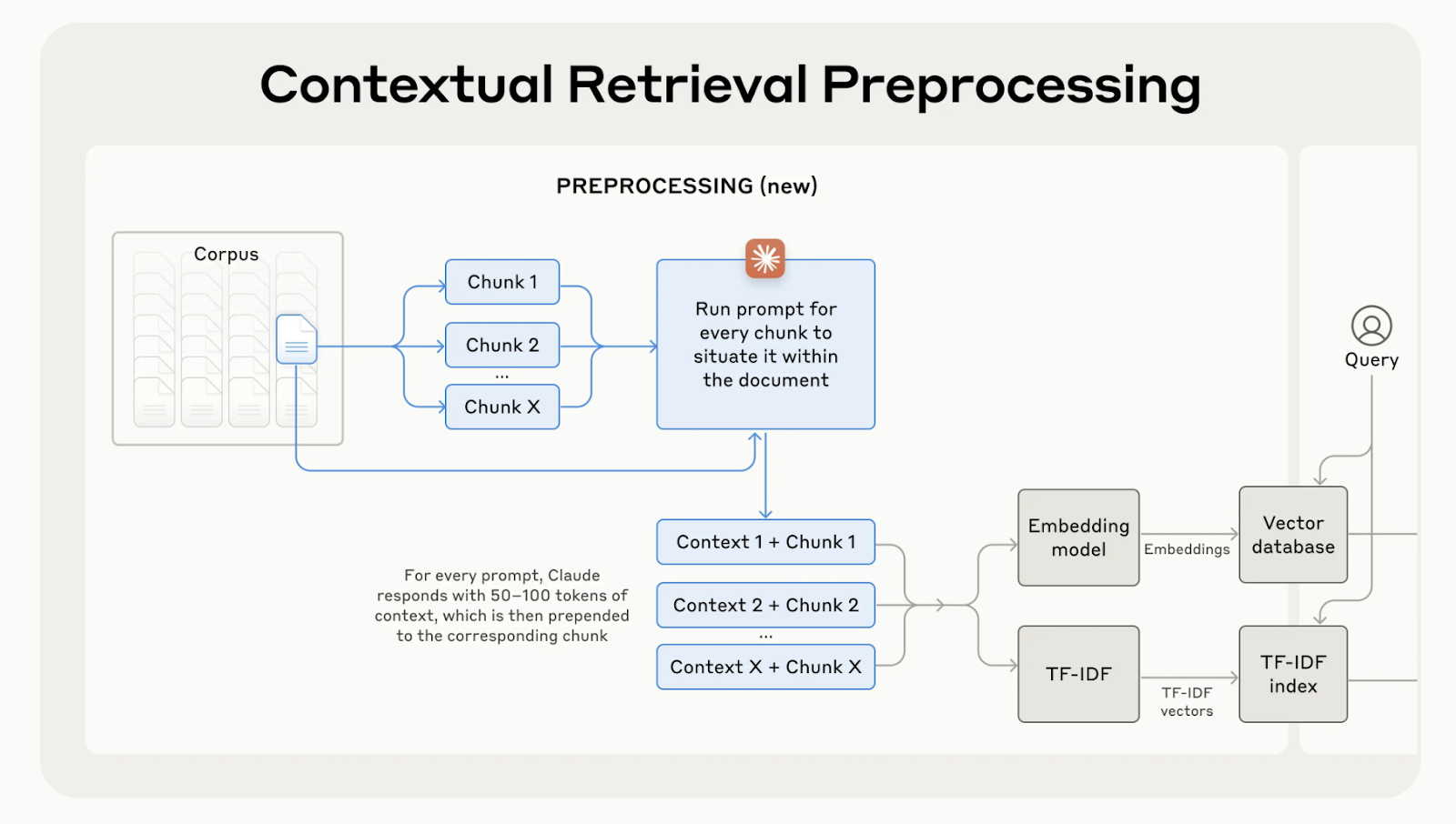
Contextual retrieval fixes this by generating and adding a short, context-specific explanation to each chunk before embedding it. In the example above, the chunk would be transformed as follows:
contextualized_chunk = """Berlin is the capital and largest city of Germany, known for being the EU's most populous city within its limits.
Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.
"""
Source: Introducing Contextual Retrieval
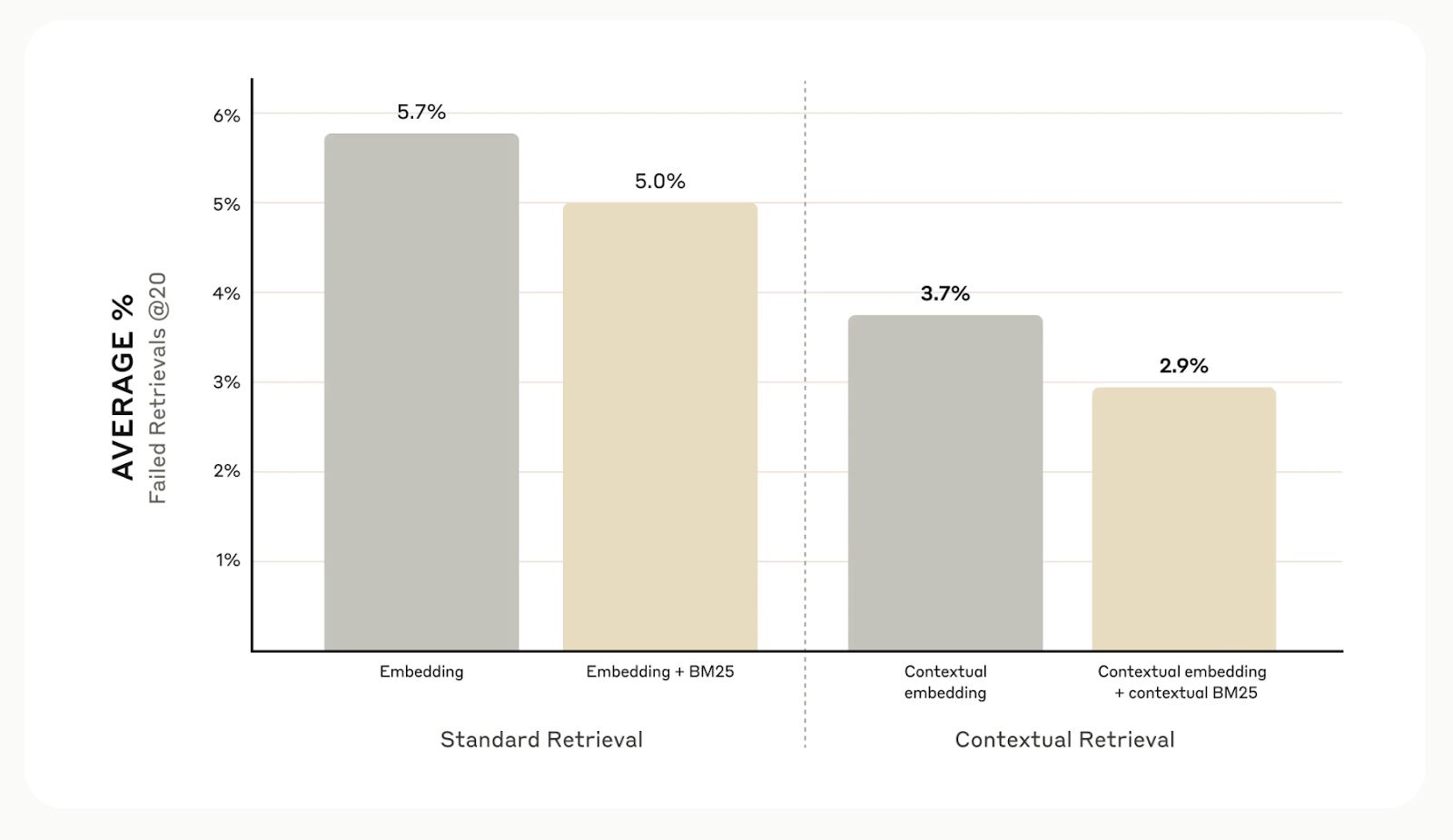
Overall, Anthropic's internal tests across different fields, including codebases, scientific papers, and fiction, show that contextual retrieval reduces retrieval errors by 49% when used with contextual embedding models and Contextual BM25.
Source: Introducing Contextual Retrieval
I’ll now explain step-by-step how to implement contextual retrieval. We’ll use the following sample document as our example:
# Input text for the knowledge base
input_text = """Berlin is the capital and largest city of Germany, both by area and by population.
Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.
The city is also one of the states of Germany and is the third smallest state in the country in terms of area.
Paris is the capital and most populous city of France.
It is situated along the Seine River in the north-central part of the country.
The city has a population of over 2.1 million residents within its administrative limits, making it one of Europe's major population centers."""The first step is to break the sample document into smaller, independent chunks. In this instance, we will divide it into individual sentences.
# Splitting the input text into smaller chunks
test_chunks = [
'Berlin is the capital and largest city of Germany, both by area and by population.',
"\\n\\nIts more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.",
'\\n\\nThe city is also one of the states of Germany and is the third smallest state in the country in terms of area.',
'\\n\\n# Paris is the capital and most populous city of France.',
'\\n\\n# It is situated along the Seine River in the north-central part of the country.',
"\\n\\n# The city has a population of over 2.1 million residents within its administrative limits, making it one of Europe's major population centers."
]Next, we will set up the prompt that our model will use to generate context for each chunk. Anthropic has provided a useful template for this. The prompt will take two inputs: the entire document and the specific chunk of text we want to situate.
from langchain.prompts import ChatPromptTemplate, PromptTemplate, HumanMessagePromptTemplate
# Define the prompt for generating contextual information
anthropic_contextual_retrieval_system_prompt = """<document>
{WHOLE_DOCUMENT}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{CHUNK_CONTENT}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else."""
# Create a PromptTemplate for WHOLE_DOCUMENT and CHUNK_CONTENT
anthropic_prompt_template = PromptTemplate(
input_variables=['WHOLE_DOCUMENT', 'CHUNK_CONTENT'],
template=anthropic_contextual_retrieval_system_prompt
)
# Wrap the prompt in a HumanMessagePromptTemplate
human_message_prompt = HumanMessagePromptTemplate(prompt=anthropic_prompt_template)
# Create the final ChatPromptTemplate
anthropic_contextual_retrieval_final_prompt = ChatPromptTemplate(
input_variables=['WHOLE_DOCUMENT', 'CHUNK_CONTENT'],
messages=[human_message_prompt]
)Here, you can choose any LLM you like to generate context for each chunk. For our example, we will use the OpenAI’s GPT-4o model.
import os
from langchain_openai import ChatOpenAI
# Load environment variables
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# Initialize the model instance
llm_model_instance = ChatOpenAI(
model="gpt-4o",
)We will connect the prompt template with the language model to create an LLM chain that’s ready to process the chunks we created earlier.
from langchain.output_parsers import StrOutputParser
# Chain the prompt with the model instance
contextual_chunk_creation = anthropic_contextual_retrieval_final_prompt | llm_model_instance | StrOutputParser()We will now loop through our chunks, generate the contextual information for each one, and print out the results using the contextual_chunk_creation LLM chain.
# Process each chunk and generate contextual information
for test_chunk in test_chunks:
res = contextual_chunk_creation.invoke({
"WHOLE_DOCUMENT": input_text,
"CHUNK_CONTENT": test_chunk
})
print(res)
print('-----')The document compares Berlin and Paris, highlighting Berlin as Germany's capital and largest city by area and population, and noting its significance within the European Union.
-----
Berlin is the capital and largest city of Germany, known for being the EU's most populous city within its limits.
-----
Berlin is the capital and largest city of Germany, both by area and by population.
-----
Paris, the capital of France, is a major population center in Europe with over 2.1 million residents.
-----
Paris is the capital and most populous city of France.
-----
Paris is the capital and most populous city of France, with a population of over 2.1 million residents within its administrative limits.
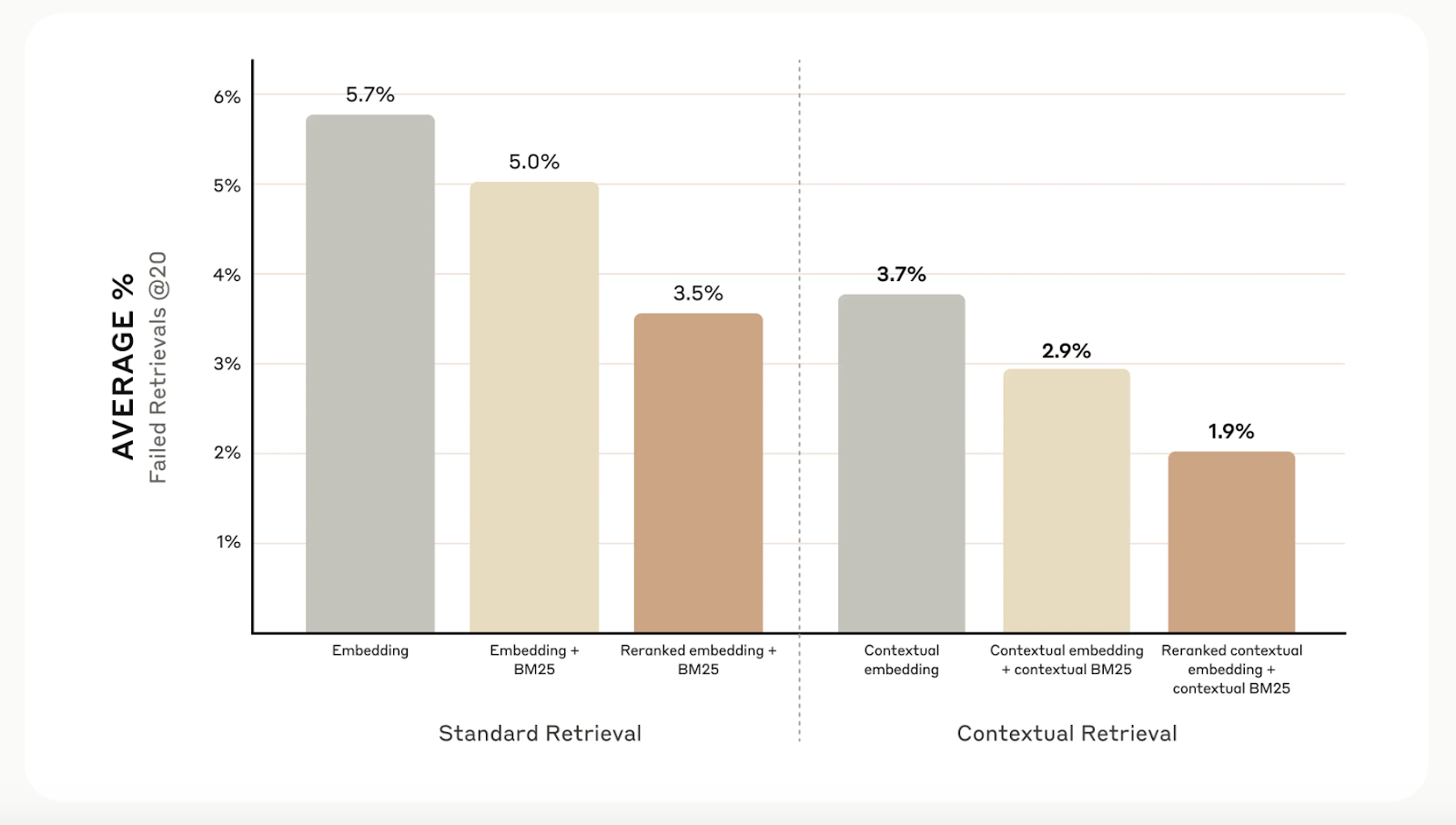
-----While contextual retrieval boosts retrieval accuracy, you can take it even further with reranking. This filtering technique ensures that only the most relevant chunks are sent to the model, improving response quality and cutting down on cost and processing time.
Reranking works by scoring the chunks retrieved in the first step and keeping only the best ones. In our tests, reranking reduced retrieval errors from 5.7% to just 1.9%, improving accuracy by 67% compared to traditional methods.
Source: Introducing Contextual Retrieval
Anthropic research has found that not every situation requires the complexity of contextual retrieval. For smaller knowledge bases under 200,000 tokens (roughly 500 pages), a better option might be to include the entire knowledge base directly in the model’s prompt, skipping the need for retrieval systems entirely.
They also suggest taking advantage of prompt caching, a feature introduced for Claude. By caching frequently used prompts between API calls, developers can cut costs by up to 90% and speed up response times by more than two times. This prompt caching cookbook provides step-by-step guidance for implementing this.
Anthropic’s contextual retrieval is a simple yet effective method to improve retrieval systems. Combining contextual embeddings, BM25, and reranking significantly improves these systems' accuracy.
To learn more about different retrieval techniques, I recommend the following blogs:
Learn AI with these courses!
Course
Course
Course
blog
Stanislav Karzhev
12 min
blog
Abid Ali Awan
9 min
blog
Natassha Selvaraj
10 min
Tutorial
Ryan Ong
Tutorial
Iván Palomares Carrascosa
Tutorial
Ryan Ong