
programa
Desarrollo de aplicaciones de IA
21 h
Generación aumentada por recuperación (RAG) mejora grandes modelos lingüísticos recuperando documentos relevantes de una fuente externa para apoyar la generación de texto. Sin embargo, la GAR no es perfecta: puede producir contenidos engañosos si los documentos recuperados no son precisos o pertinentes.
Para superar estos problemas, se propuso la recuperación correctiva-generación aumentada (CRAG). El CRAG funciona añadiendo un paso para comprobar y refinar la información recuperada antes de utilizarla para generar texto. Esto hace que los modelos lingüísticos sean más precisos y reduce la posibilidad de generar contenidos engañosos.
En este artículo, presentaré CRAG y te guiaré paso a paso en su implementación utilizando LangGraph.
La generación aumentada por recuperación correctiva (CRAG) es una versión mejorada de la RAG que pretende hacer más precisos los modelos lingüísticos.
Mientras que el RAG tradicional se limita a utilizar los documentos recuperados para ayudar a generar texto, el CRAG da un paso más al comprobar y refinar activamente estos documentos para garantizar que son pertinentes y precisos. Esto ayuda a reducir los errores o alucinaciones en los que el modelo podría producir información incorrecta o engañosa.
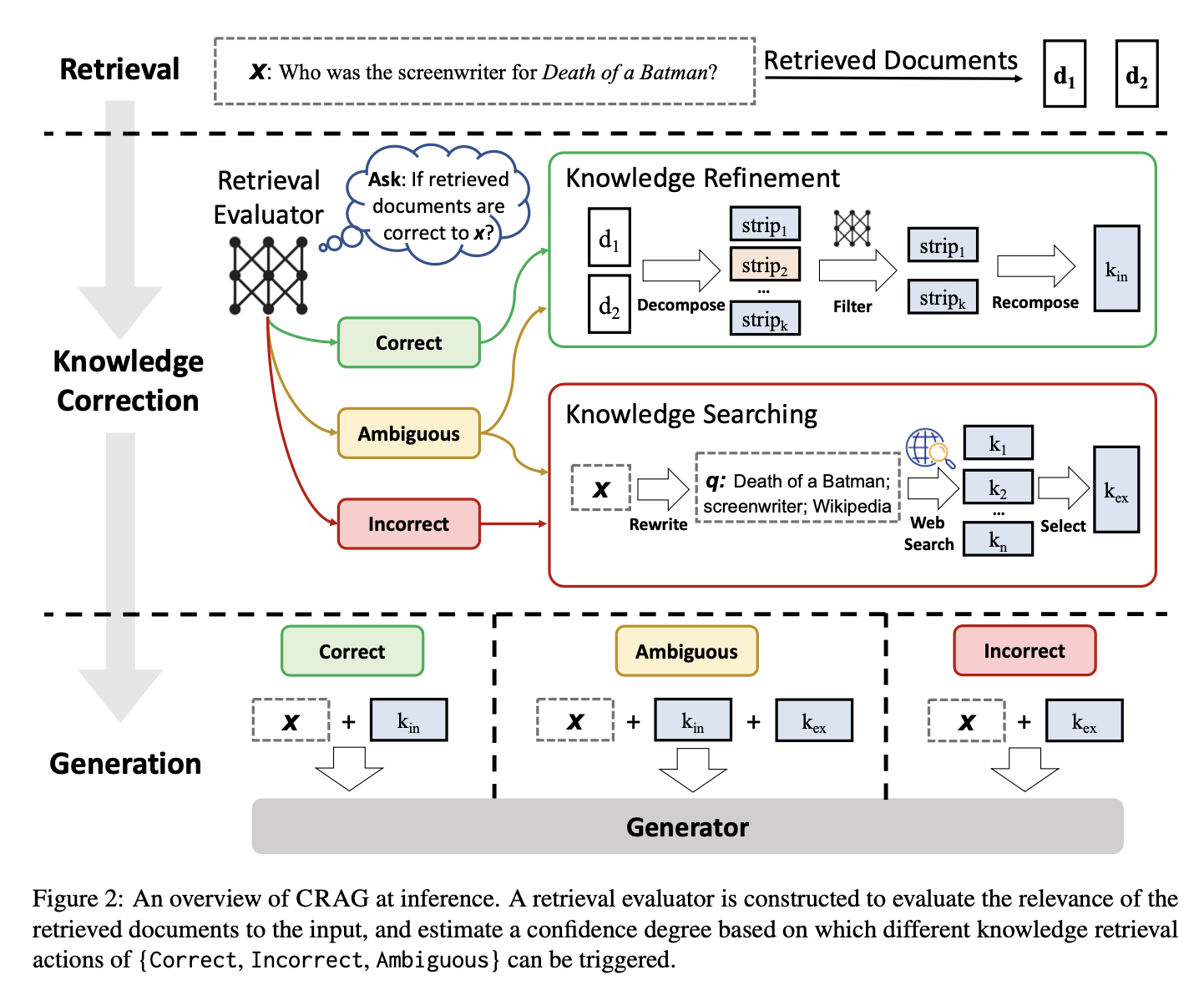
Fuente: Shi-Qi Yan et al., 2024
El marco CRAG funciona a través de unos pasos clave, que implican a un evaluador de la recuperación y acciones correctoras específicas.
Para cualquier consulta de entrada, un recuperador estándar extrae primero un conjunto de documentos de una base de conocimientos. A continuación, estos documentos son revisados por un evaluador de recuperación para determinar la relevancia de cada documento con respecto a la consulta.
En el CRAG, el evaluador de la recuperación es un modelo T5-grande afinado. El evaluador asigna una puntuación de confianza a cada documento, clasificándolos en tres niveles de confianza:
Después de realizar una de estas acciones, se utiliza el conocimiento refinado para generar la respuesta final.
El CRAG introduce varias mejoras clave respecto al RAG tradicional. Una de sus mayores ventajas es su capacidad para corregir errores en la información que recupera. El evaluador de recuperación del CRAG ayuda a detectar cuándo la información es errónea o irrelevante, para que pueda corregirse antes de que afecte al resultado final. Esto significa que el CRAG proporciona información más precisa y fiable, reduciendo los errores y la desinformación.
El CRAG también destaca por asegurarse de que la información es pertinente y exacta. Mientras que el RAG tradicional sólo comprueba las puntuaciones de relevancia, el CRAG va más allá, refinando los documentos para asegurarse de que no sólo son relevantes, sino también precisos. Filtra los detalles irrelevantes y se centra en los puntos más importantes, de modo que el texto generado se basa en información precisa.
En esta sección, veremos paso a paso cómo poner en práctica el CRAG utilizando LangGraph. Aprenderás a configurar tu entorno, a crear un almacén básico de vectores de conocimiento y a configurar los componentes clave necesarios para el CRAG, como el evaluador de recuperación, el reescribidor de preguntas y la herramienta de búsqueda web.
También aprenderemos a construir un flujo de trabajo LangGraph que reúna todas estas partes, demostrando cómo el CRAG puede gestionar varios tipos de consultas para obtener resultados más precisos y fiables.
Primero, instala los paquetes necesarios. Este paso configura el entorno para ejecutar el conducto CRAG.
pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain langgraph tavily-pythonA continuación, configura tus claves API para Tavily y OpenAI:
import os
os.environ["TAVILY_API_KEY"] = "YOUR_TAVILY_API_KEY"
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"Para realizar el GAR, primero necesitamos una base de conocimientos llena de documentos. En este paso, extraeremos algunos documentos de muestra de un boletín de Substack para crear un almacén vectorial, que actuará como nuestra base de conocimientos proxy. Este almacén vectorial nos ayuda a encontrar documentos relevantes en función de las consultas de los usuarios.
Empezamos cargando documentos desde las URL proporcionadas y dividiéndolos en secciones más pequeñas mediante un divisor de texto. Estas secciones se incrustadas utilizando OpenAIEmbeddings y se almacenan en una base de datos vectorial (Chroma) para una recuperación eficaz de los documentos.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
urls = [
"<https://ryanocm.substack.com/p/mystery-gift-box-049-law-1-fill-your>",
"<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>",
"<https://ryanocm.substack.com/p/098-i-have-read-100-productivity>",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()En este paso, creamos una cadena RAG básica que toma la pregunta de un usuario y un conjunto de documentos para generar una respuesta.
La cadena RAG utiliza un indicador predefinido y un modelo lingüístico (GPT 4-o mini) para crear respuestas basadas en los documentos recuperados. A continuación, un analizador sintáctico de salida formatea el texto generado para facilitar su lectura.
### Generate
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
# Prompt
rag_prompt = hub.pull("rlm/rag-prompt")
# LLM
rag_llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
# Post-processing
def format_docs(docs):
return "\\n\\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = rag_prompt | rag_llm | StrOutputParser()
print(rag_prompt.messages[0].prompt.template)You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:generation = rag_chain.invoke({"context": docs, "question": question})
print("Question: %s" % question)
print("----")
print("Documents:\\n")
print('\\n\\n'.join(['- %s' % x.page_content for x in docs]))
print("----")
print("Final answer: %s" % generation)Question: what is the bagel method
----
Documents:
- the book was called The Bagel Method.The Bagel Method is designed to help partners be on the same team when dealing with differences and trying to find a compromise.The idea behind the method is that, to truly compromise, we need to figure out a way to include both partners’ dreams and core needs; things that are super important to us that giving up on them is too much.Let’s dive into the bagel 😜🚀 If you are new here…Hi, I’m Ryan 👋� I am passionate about lifestyle gamification � and I am obsesssssssss with learning things that can help me live a happy and fulfilling life.And so, with The Limitless Playbook newsletter, I will share with you 1 actionable idea from the world's top thinkers every Sunday �So visit us weekly for highly actionable insights :)…or even better, subscribe below and have all these information send straight to your inbox every Sunday 🥳Subscribe🥯
- #105 | The Bagel Method in Relationships 🥯
- The Limitless Playbook 🧬SubscribeSign inShare this post#105 | The Bagel Method in Relationships 🥯ryanocm.substack.comCopy linkFacebookEmailNoteOther#105 | The Bagel Method in Relationships 🥯A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��Ryan Ong �Feb 25, 2024Share this post#105 | The Bagel Method in Relationships 🥯ryanocm.substack.comCopy linkFacebookEmailNoteOtherShareHello curious minds 🧠I recently finished the book Fight Right: How Successful Couples Turn Conflict into Connection and oh my days, I love every chapter of it!There were many repeating concepts but this time, it was applied in the context of conflicts in relationships. As usual with the Gottman’s books, I highlighted the hell out of the entire book 😄One of the cool exercises in
- The Bagel MethodThe Bagel Method involves mapping out your core needs and areas of flexibility so that you and your partner understand what's important and where there's room for flexibility.It’s called The Bagel Method because, just like a bagel, it has both the inner and outer circles representing your needs.Here are the steps:In the inner circle, list all the aspects of an issue that you can’t give in on. These are your non-negotiables that are usually very closely related to your core needs and dreams.In the outer circle, list all the aspects of an issue that you are able to compromise on IF you are able to have what’s in your inner circle.Now, talk to your partners about your inner and outer circle. Ask each other:Why are the things in your inner circle so important to you?How can I support your core needs here?Tell me more about your areas of flexibility. What does it look like to be flexible?Compare both your “bagel� of needsWhat do we agree on?What feelings do we have in common?What shared goals do we have?How might we accomplish these goals
----
Final answer: The Bagel Method is a relationship strategy that helps partners identify their core needs and areas where they can be flexible. It involves mapping out non-negotiables in the inner circle and compromise areas in the outer circle, facilitating open communication about each partner's priorities. This method aims to foster understanding and collaboration in resolving differences.Para mejorar la precisión del contenido generado, creamos un evaluador de recuperación. Esta herramienta comprueba la relevancia de cada documento recuperado para asegurarse de que sólo se utiliza la información más útil.
El evaluador de recuperación está configurado con un indicador y un modelo lingüístico. Determina si los documentos son relevantes o no, filtrando cualquier contenido irrelevante antes de generar una respuesta.
### Retrieval Evaluator
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
# Data model
class RetrievalEvaluator(BaseModel):
"""Classify retrieved documents based on how relevant it is to the user's question."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# LLM with function call
retrieval_evaluator_llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
structured_llm_evaluator = retrieval_evaluator_llm.with_structured_output(RetrievalEvaluator)
# Prompt
system = """You are a document retrieval evaluator that's responsible for checking the relevancy of a retrieved document to the user's question. \\n
If the document contains keyword(s) or semantic meaning related to the question, grade it as relevant. \\n
Output a binary score 'yes' or 'no' to indicate whether the document is relevant to the question."""
retrieval_evaluator_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \\n\\n {document} \\n\\n User question: {question}"),
]
)
retrieval_grader = retrieval_evaluator_prompt | structured_llm_evaluatorAñadiremos un reescribidor de preguntas para que las consultas de los usuarios sean más claras y específicas, lo que ayuda a mejorar el proceso de búsqueda.
La reescritura refina la consulta original para que la búsqueda esté más centrada, lo que conduce a resultados mejores y más relevantes.
### Question Re-writer
# LLM
question_rewriter_llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Prompt
system = """You are a question re-writer that converts an input question to a better version that is optimized \\n
for web search. Look at the input and try to reason about the underlying semantic intent / meaning."""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"Here is the initial question: \\n\\n {question} \\n Formulate an improved question.",
),
]
)
question_rewriter = re_write_prompt | question_rewriter_llm | StrOutputParser()Si la base de conocimientos no tiene suficiente información, el CRAG recurre a la búsqueda en la web para rellenar los huecos. Esto amplía el abanico de posibles fuentes de información. En este paso, utilizamos la API de Tavily para buscar en la web y encontrar documentos adicionales.
### Search
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(k=3)Para construir el flujo de trabajo CRAG con LangGraph, sigue estos tres pasos principales:
Crea un estado compartido para almacenar los datos a medida que se mueven entre los nodos durante el flujo de trabajo. Este estado contendrá todas las variables, como la pregunta del usuario, los documentos recuperados y las respuestas generadas.
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
web_search: whether to add search
documents: list of documents
"""
question: str
generation: str
web_search: str
documents: List[str]En el flujo de trabajo LangGraph, cada nodo de función se encarga de una tarea específica en la cadena CRAG, como recuperar documentos, generar respuestas, evaluar la relevancia, transformar consultas y buscar en la web. Aquí tienes un desglose de cada función:
La función retrieve encuentra documentos de la base de conocimientos que son relevantes para la pregunta del usuario. Utiliza un objeto recuperador, que suele ser un almacén vectorial creado a partir de documentos preprocesados. Esta función toma el estado actual, incluida la pregunta del usuario, y utiliza el recuperador para obtener los documentos relevantes. A continuación, añade estos documentos al estado.
from langchain.schema import Document
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.get_relevant_documents(question)
return {"documents": documents, "question": question}La función generate crea una respuesta a la pregunta del usuario utilizando los documentos recuperados. Funciona con la cadena RAG, que combina un indicador con un modelo lingüístico. Esta función toma los documentos recuperados y la pregunta del usuario, los procesa a través de la cadena RAG y, a continuación, añade la respuesta al estado.
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}La función evaluate_documents comprueba lo relevante que es cada documento recuperado para la pregunta del usuario utilizando el evaluador de recuperación. Esto ayuda a garantizar que sólo se utiliza información útil para la respuesta final. Esta función valora la relevancia de cada documento y filtra los que no son útiles. También actualiza el estado con una bandera web_search para mostrar si es necesaria una búsqueda web cuando la mayoría de los documentos no son relevantes.
def evaluate_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
web_search = "No"
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
if len(filtered_docs) / len(documents) <= 0.7:
web_search = "Yes"
return {"documents": filtered_docs, "question": question, "web_search": web_search}La función transform_query mejora la pregunta del usuario para obtener mejores resultados de búsqueda, sobre todo si la consulta original no encuentra documentos relevantes. Utiliza un reescritor de preguntas para que la pregunta sea más clara y específica. Una pregunta mejor aumenta las posibilidades de encontrar documentos útiles tanto en la base de conocimientos como en las búsquedas web.
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
return {"documents": documents, "question": better_question}La función web_search busca información adicional en Internet utilizando la consulta refinada. Se utiliza cuando la base de conocimientos no tiene suficiente información, ayudando a reunir más contenido. Esta función utiliza la herramienta de búsqueda web Tavily para encontrar documentos adicionales en la web, que luego se añaden a los documentos existentes para mejorar la base de conocimientos.
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("---WEB SEARCH---")
question = state["question"]
documents = state["documents"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
documents.append(web_results)
return {"documents": documents, "question": question}La función decide_to_generate decide qué hacer a continuación: generar una respuesta con los documentos actuales o refinar la consulta y volver a buscar. Realiza esta elección en función de la relevancia de los documentos (como se ha evaluado anteriormente).
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
web_search = state["web_search"]
state["documents"]
if web_search == "Yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"Una vez definidos todos los nodos de función, ya podemos enlazar todos los nodos de función en el flujo de trabajo LangGraph para construir el conducto CRAG. Esto significa conectar los nodos con aristas para gestionar el flujo de información y decisiones, asegurándose de que el flujo de trabajo se ejecuta correctamente en función de los resultados de cada paso.
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", evaluate_documents) # evaluate documents
workflow.add_node("generate", generate) # generate
workflow.add_node("transform_query", transform_query) # transform_query
workflow.add_node("web_search_node", web_search) # web search
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "web_search_node")
workflow.add_edge("web_search_node", "generate")
workflow.add_edge("generate", END)
# Compile
app = workflow.compile()from IPython.display import Image, display
try:
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass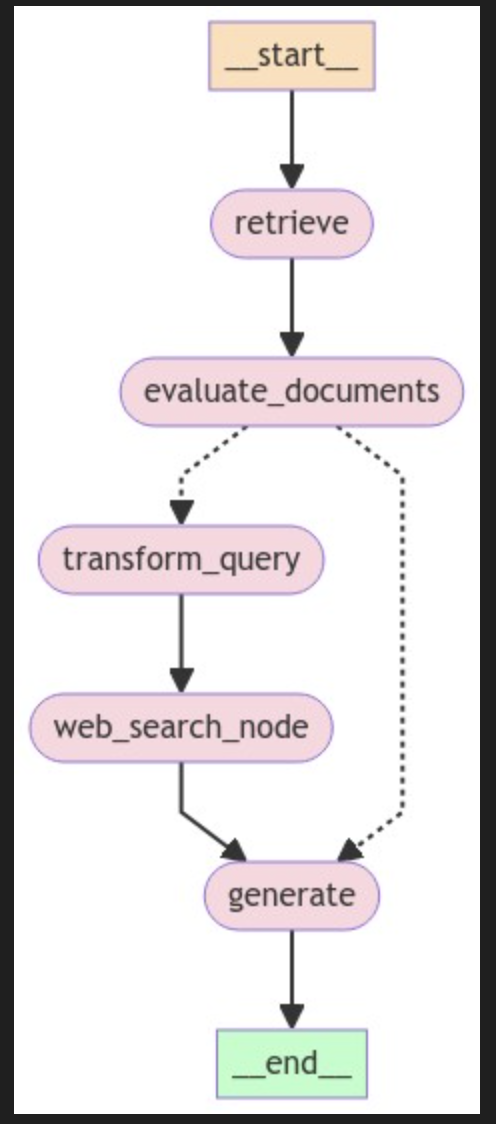
Para probar nuestra configuración, ejecutamos el flujo de trabajo con consultas de ejemplo para comprobar cómo recupera la información, evalúa la relevancia de los documentos y genera respuestas.
La primera consulta comprueba lo bien que el CRAG encuentra respuestas dentro de su base de conocimientos.
from pprint import pprint
# Run
inputs = {"question": "What's the bagel method?"}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
pprint(value, indent=2, width=80, depth=None)
pprint("\\n---\\n")
# Final generation
pprint(value["generation"])---RETRIEVE---
"Node 'retrieve':"
{ 'documents': [ Document(page_content="the book was called The Bagel Method.The Bagel Method is designed to help partners be on the same team when dealing with differences and trying to find a compromise.The idea behind the method is that, to truly compromise, we need to figure out a way to include both partners’ dreams and core needs; things that are super important to us that giving up on them is too much.Let’s dive into the bagel 😜🚀 If you are new here…Hi, I’m Ryan 👋� I am passionate about lifestyle gamification � and I am obsesssssssss with learning things that can help me live a happy and fulfilling life.And so, with The Limitless Playbook newsletter, I will share with you 1 actionable idea from the world's top thinkers every Sunday �So visit us weekly for highly actionable insights :)…or even better, subscribe below and have all these information send straight to your inbox every Sunday 🥳Subscribe🥯", metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'}),
Document(page_content='#105 | The Bagel Method in Relationships 🥯', metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'}),
Document(page_content='The Limitless Playbook 🧬SubscribeSign inShare this post#105 | The Bagel Method in Relationships 🥯ryanocm.substack.comCopy linkFacebookEmailNoteOther#105 | The Bagel Method in Relationships 🥯A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life â�¤ï¸�Ryan Ong ğŸ�®Feb 25, 2024Share this post#105 | The Bagel Method in Relationships 🥯ryanocm.substack.comCopy linkFacebookEmailNoteOtherShareHello curious minds ğŸ§\\xa0I recently finished the book Fight Right: How Successful Couples Turn Conflict into Connection and oh my days, I love every chapter of it!There were many repeating concepts but this time, it was applied in the context of conflicts in relationships. As usual with the Gottman’s books, I highlighted the hell out of the entire book 😄One of the cool exercises in', metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life â�¤ï¸�', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'}),
Document(page_content="The Bagel MethodThe Bagel Method involves mapping out your core needs and areas of flexibility so that you and your partner understand what's important and where there's room for flexibility.It’s called The Bagel Method because, just like a bagel, it has both the inner and outer circles representing your needs.Here are the steps:In the inner circle, list all the aspects of an issue that you can’t give in on. These are your non-negotiables that are usually very closely related to your core needs and dreams.In the outer circle, list all the aspects of an issue that you are able to compromise on IF you are able to have what’s in your inner circle.Now, talk to your partners about your inner and outer circle. Ask each other:Why are the things in your inner circle so important to you?How can I support your core needs here?Tell me more about your areas of flexibility. What does it look like to be flexible?Compare both your “bagel� of needsWhat do we agree on?What feelings do we have in common?What shared goals do we have?How might we accomplish these goals", metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'})],
'question': "What's the bagel method?"}
'\\n---\\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
"Node 'evaluate_documents':"
{ 'documents': [ Document(page_content="the book was called The Bagel Method.The Bagel Method is designed to help partners be on the same team when dealing with differences and trying to find a compromise.The idea behind the method is that, to truly compromise, we need to figure out a way to include both partners’ dreams and core needs; things that are super important to us that giving up on them is too much.Let’s dive into the bagel 😜🚀 If you are new here…Hi, I’m Ryan 👋� I am passionate about lifestyle gamification � and I am obsesssssssss with learning things that can help me live a happy and fulfilling life.And so, with The Limitless Playbook newsletter, I will share with you 1 actionable idea from the world's top thinkers every Sunday �So visit us weekly for highly actionable insights :)…or even better, subscribe below and have all these information send straight to your inbox every Sunday 🥳Subscribe🥯", metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'}),
Document(page_content='#105 | The Bagel Method in Relationships 🥯', metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'}),
Document(page_content="The Bagel MethodThe Bagel Method involves mapping out your core needs and areas of flexibility so that you and your partner understand what's important and where there's room for flexibility.It’s called The Bagel Method because, just like a bagel, it has both the inner and outer circles representing your needs.Here are the steps:In the inner circle, list all the aspects of an issue that you can’t give in on. These are your non-negotiables that are usually very closely related to your core needs and dreams.In the outer circle, list all the aspects of an issue that you are able to compromise on IF you are able to have what’s in your inner circle.Now, talk to your partners about your inner and outer circle. Ask each other:Why are the things in your inner circle so important to you?How can I support your core needs here?Tell me more about your areas of flexibility. What does it look like to be flexible?Compare both your “bagel� of needsWhat do we agree on?What feelings do we have in common?What shared goals do we have?How might we accomplish these goals", metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'})],
'question': "What's the bagel method?",
'web_search': 'No'}
'\\n---\\n'
---GENERATE---
"Node 'generate':"
{ 'documents': [ Document(page_content="the book was called The Bagel Method.The Bagel Method is designed to help partners be on the same team when dealing with differences and trying to find a compromise.The idea behind the method is that, to truly compromise, we need to figure out a way to include both partners’ dreams and core needs; things that are super important to us that giving up on them is too much.Let’s dive into the bagel 😜🚀 If you are new here…Hi, I’m Ryan 👋� I am passionate about lifestyle gamification � and I am obsesssssssss with learning things that can help me live a happy and fulfilling life.And so, with The Limitless Playbook newsletter, I will share with you 1 actionable idea from the world's top thinkers every Sunday �So visit us weekly for highly actionable insights :)…or even better, subscribe below and have all these information send straight to your inbox every Sunday 🥳Subscribe🥯", metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'}),
Document(page_content='#105 | The Bagel Method in Relationships 🥯', metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'}),
Document(page_content="The Bagel MethodThe Bagel Method involves mapping out your core needs and areas of flexibility so that you and your partner understand what's important and where there's room for flexibility.It’s called The Bagel Method because, just like a bagel, it has both the inner and outer circles representing your needs.Here are the steps:In the inner circle, list all the aspects of an issue that you can’t give in on. These are your non-negotiables that are usually very closely related to your core needs and dreams.In the outer circle, list all the aspects of an issue that you are able to compromise on IF you are able to have what’s in your inner circle.Now, talk to your partners about your inner and outer circle. Ask each other:Why are the things in your inner circle so important to you?How can I support your core needs here?Tell me more about your areas of flexibility. What does it look like to be flexible?Compare both your “bagel� of needsWhat do we agree on?What feelings do we have in common?What shared goals do we have?How might we accomplish these goals", metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'})],
'generation': 'The Bagel Method is a framework designed to help partners '
'navigate differences and find compromises by mapping out '
'their core needs and areas of flexibility. It involves '
'creating two circles: the inner circle for non-negotiable '
'needs and the outer circle for aspects where compromise is '
'possible. This method encourages open communication about '
"each partner's priorities and shared goals.",
'question': "What's the bagel method?"}
'\\n---\\n'
('The Bagel Method is a framework designed to help partners navigate '
'differences and find compromises by mapping out their core needs and areas '
'of flexibility. It involves creating two circles: the inner circle for '
'non-negotiable needs and the outer circle for aspects where compromise is '
"possible. This method encourages open communication about each partner's "
'priorities and shared goals.')Y la segunda consulta pone a prueba la capacidad del CRAG para buscar información adicional en la web cuando la base de conocimientos no tiene los documentos pertinentes.
from pprint import pprint
# Run
inputs = {"question": "What is prompt engineering?"}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
pprint(value, indent=2, width=80, depth=None)
pprint("\\n---\\n")
# Final generation
pprint(value["generation"])---RETRIEVE---
"Node 'retrieve':"
{ 'documents': [ Document(page_content='Mystery Gift Box #049 | Law 1: Fill your Five Buckets in the Right Order (The Diary of a CEO)', metadata={'description': "The best hidden gems I've found; interesting ideas and concepts, thought-provoking questions, mind-blowing books/podcasts, cool animes/films, and other mysteries ��", 'language': 'en', 'source': '<https://ryanocm.substack.com/p/mystery-gift-box-049-law-1-fill-your>', 'title': 'Mystery Gift Box #049 | Law 1: Fill your Five Buckets in the Right Order (The Diary of a CEO)'}),
Document(page_content='ğŸ�¦Â\\xa0Twitter, 👨ğŸ�»â€�💻Â\\xa0LinkedIn, ğŸŒ�Â\\xa0Personal Website, and 📸Â\\xa0InstagramShare this postMystery Gift Box #049 | Law 1: Fill your Five Buckets in the Right Order (The Diary of a CEO)ryanocm.substack.comCopy linkFacebookEmailNoteOtherSharePreviousNextCommentsTopLatestDiscussionsNo postsReady for more?Subscribe© 2024 Ryan Ong ğŸ�®Privacy ∙ Terms ∙ Collection notice Start WritingGet the appSubstack is the home for great cultureShareCopy linkFacebookEmailNoteOther', metadata={'description': "The best hidden gems I've found; interesting ideas and concepts, thought-provoking questions, mind-blowing books/podcasts, cool animes/films, and other mysteries â�¤ï¸�", 'language': 'en', 'source': '<https://ryanocm.substack.com/p/mystery-gift-box-049-law-1-fill-your>', 'title': 'Mystery Gift Box #049 | Law 1: Fill your Five Buckets in the Right Order (The Diary of a CEO)'}),
Document(page_content='skills are the foundation of which you build your life and career and it’s truly yours to own; you can lose your network, resources, and reputation but you will never lose your knowledge and skills.Never try to skip the first two buckets. If you try to jump straight to network, resources, and / or reputation bucket, you might “succeed� in the short-run but in the long run, your lack of knowledge and skill will catch on to you.There is no skipping the first two buckets of knowledge and skills if you’re playing long-term sustainable results. Any attempt to do so is equivalent to building your house on sand.💥 Key takeawayFocus on using your knowledge and skills to create lots of values in the world and the world will reward you with growing network (people will come to you), resources (people will pay for your services), and reputation (people will know what you are capable of).⛰ 4-4-4 Exploration ProjectEach month, I would explore one new thing; a skill, a subject, or an experience.January 2023: Writing and Storytelling (Subject)', metadata={'description': "The best hidden gems I've found; interesting ideas and concepts, thought-provoking questions, mind-blowing books/podcasts, cool animes/films, and other mysteries ��", 'language': 'en', 'source': '<https://ryanocm.substack.com/p/mystery-gift-box-049-law-1-fill-your>', 'title': 'Mystery Gift Box #049 | Law 1: Fill your Five Buckets in the Right Order (The Diary of a CEO)'}),
Document(page_content='This site requires JavaScript to run correctly. Please turn on JavaScript or unblock scripts', metadata={'description': 'A collection of the best hidden gems, mental models, and frameworks from the world’s top thinkers; to help you become 1% better and live a happier life ��', 'language': 'en', 'source': '<https://ryanocm.substack.com/p/105-the-bagel-method-in-relationships>', 'title': '#105 | The Bagel Method in Relationships 🥯'})],
'question': 'What is prompt engineering?'}
'\\n---\\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
"Node 'evaluate_documents':"
{ 'documents': [],
'question': 'What is prompt engineering?',
'web_search': 'Yes'}
'\\n---\\n'
---TRANSFORM QUERY---
"Node 'transform_query':"
{ 'documents': [],
'question': 'What is the concept of prompt engineering and how is it applied '
'in artificial intelligence?'}
'\\n---\\n'
---WEB SEARCH---
"Node 'web_search_node':"
{ 'documents': [ Document(page_content="Prompt engineering is the method to ask generative AI to produce what the individual needs. There are two main principles of building a successful prompt for any AI, specificity and iteration. The box below includes one example of a framework that can be applied when prompting any generative AI.\\nPrompt Engineering is the process of designing and refining text inputs (prompts) to achieve specific application objectives with AI models. Think of it as a two-step journey: Designing the Initial Prompt: Creating the initial input for the model to achieve the desired result. Refining the Prompt: Continuously adjusting the prompt to enhance ...\\nPrompt engineering is the process of designing and refining the inputs given to language models, like those in AI, to achieve desired outputs more effectively. It involves creatively crafting prompts that guide the model in generating responses that are accurate, relevant, and aligned with the user's intentions.. For students and researchers in higher education, mastering prompt engineering is ...\\nJune 25, 2024. Prompt engineering means writing precise instructions for AI models. These instructions are different from coding because they use natural language. And today, everybody does it—from software developers to artists and content creators. Prompt engineering can help you improve productivity and save time by automating repetitive ...\\nMaster Prompt Engineering - The (AI) Prompt\\nAI Takes Wall Street by Storm: C3.ai's Strong Forecast Sparks a Surge in AI Stocks\\nAsk Me Anything (AMA) Prompting\\nHow Self-Critique Improves Logic and Reasoning in LLMs Like ChatGPT\\nOptimizing Large Language Models to Maximize Performance\\nThe Black Box Problem: Opaque Inner Workings of Large Language Models\\nHow to Evaluate Large Language Models for Business Tasks\\nIntroduction to the AI Prompt Development Process\\nSubscribe to new posts\\nThe Official Source For Everything Prompt Engineering & Generative AI Defining Prompt Engineering\\nGiven that the prompt is the singular input channel to large language models, prompt engineering can be defined as:\\nPrompt Engineering can be thought of as any process that contributes to the development of a well-crafted prompt to generate quality, useful outputs from an AI system.\\n A Simplified Approach to Defining Prompt Engineering\\nThe Prompt is the Sole Input\\nWhen interacting with Generative AI Models such as large language models (LLMs), the prompt is the only thing that gets input into the AI system. Its applications cut across diverse sectors, from healthcare and education to business, securing its place as a cornerstone of our interactions with AI.\\nExploration of Essential Prompt Engineering Techniques and Concepts\\nIn the rapidly evolving landscape of Artificial Intelligence (AI), mastering key techniques of Prompt Engineering has become increasingly vital. The key concepts of Prompt Engineering include prompts and prompting the AI, training the AI, developing and maintaining a prompt library, and testing, evaluation, and categorization.\\n")],
'question': 'What is the concept of prompt engineering and how is it applied '
'in artificial intelligence?'}
'\\n---\\n'
---GENERATE---
"Node 'generate':"
{ 'documents': [ Document(page_content="Prompt engineering is the method to ask generative AI to produce what the individual needs. There are two main principles of building a successful prompt for any AI, specificity and iteration. The box below includes one example of a framework that can be applied when prompting any generative AI.\\nPrompt Engineering is the process of designing and refining text inputs (prompts) to achieve specific application objectives with AI models. Think of it as a two-step journey: Designing the Initial Prompt: Creating the initial input for the model to achieve the desired result. Refining the Prompt: Continuously adjusting the prompt to enhance ...\\nPrompt engineering is the process of designing and refining the inputs given to language models, like those in AI, to achieve desired outputs more effectively. It involves creatively crafting prompts that guide the model in generating responses that are accurate, relevant, and aligned with the user's intentions.. For students and researchers in higher education, mastering prompt engineering is ...\\nJune 25, 2024. Prompt engineering means writing precise instructions for AI models. These instructions are different from coding because they use natural language. And today, everybody does it—from software developers to artists and content creators. Prompt engineering can help you improve productivity and save time by automating repetitive ...\\nMaster Prompt Engineering - The (AI) Prompt\\nAI Takes Wall Street by Storm: C3.ai's Strong Forecast Sparks a Surge in AI Stocks\\nAsk Me Anything (AMA) Prompting\\nHow Self-Critique Improves Logic and Reasoning in LLMs Like ChatGPT\\nOptimizing Large Language Models to Maximize Performance\\nThe Black Box Problem: Opaque Inner Workings of Large Language Models\\nHow to Evaluate Large Language Models for Business Tasks\\nIntroduction to the AI Prompt Development Process\\nSubscribe to new posts\\nThe Official Source For Everything Prompt Engineering & Generative AI Defining Prompt Engineering\\nGiven that the prompt is the singular input channel to large language models, prompt engineering can be defined as:\\nPrompt Engineering can be thought of as any process that contributes to the development of a well-crafted prompt to generate quality, useful outputs from an AI system.\\n A Simplified Approach to Defining Prompt Engineering\\nThe Prompt is the Sole Input\\nWhen interacting with Generative AI Models such as large language models (LLMs), the prompt is the only thing that gets input into the AI system. Its applications cut across diverse sectors, from healthcare and education to business, securing its place as a cornerstone of our interactions with AI.\\nExploration of Essential Prompt Engineering Techniques and Concepts\\nIn the rapidly evolving landscape of Artificial Intelligence (AI), mastering key techniques of Prompt Engineering has become increasingly vital. The key concepts of Prompt Engineering include prompts and prompting the AI, training the AI, developing and maintaining a prompt library, and testing, evaluation, and categorization.\\n")],
'generation': 'Prompt engineering is the process of designing and refining '
'text inputs to guide AI models in generating desired outputs. '
'It focuses on specificity and iteration to create effective '
'prompts that align with user intentions. This technique is '
'widely applicable across various sectors, enhancing '
'productivity and automating tasks.',
'question': 'What is the concept of prompt engineering and how is it applied '
'in artificial intelligence?'}
'\\n---\\n'
('Prompt engineering is the process of designing and refining text inputs to '
'guide AI models in generating desired outputs. It focuses on specificity and '
'iteration to create effective prompts that align with user intentions. This '
'technique is widely applicable across various sectors, enhancing '
'productivity and automating tasks.')Aunque el CRAG mejora al GAR tradicional, tiene algunas limitaciones que requieren atención.
Un problema importante es su dependencia de la calidad del evaluador de la recuperación. Este evaluador es esencial para juzgar si los documentos recuperados son pertinentes y precisos. Sin embargo, el entrenamiento y ajuste fino el evaluador puede ser exigente, ya que requiere muchos datos de alta calidad y potencia de cálculo. Mantener actualizado el evaluador con nuevos tipos de consultas y fuentes de datos aumenta la complejidad y el coste.
Otra limitación es el uso que hace el CRAG de las búsquedas en Internet para encontrar o sustituir documentos incorrectos o ambiguos. Aunque este enfoque puede proporcionar información más reciente y diversa, también corre el riesgo de introducir datos sesgados o poco fiables. La calidad de los contenidos web varía mucho, y clasificarlos para encontrar la información más precisa puede ser todo un reto. Esto significa que ni siquiera un evaluador bien formado puede evitar por completo la inclusión de información de mala calidad o sesgada.
Estos retos ponen de manifiesto la necesidad de investigación y desarrollo continuos.
En general, el CRAG mejora los sistemas RAG tradicionales añadiendo funciones que comprueban y refinan la información recuperada, haciendo que los modelos lingüísticos sean más precisos y fiables. Esto hace que el CRAG sea una herramienta útil para muchas aplicaciones diferentes.
Para saber más sobre el CRAG, consulta el documento original aquí.
Si buscas más recursos de aprendizaje sobre el GAR, te recomiendo estos blogs:
¡Desarrolla aplicaciones de IA!
programa
programa
Curso
blog
Stanislav Karzhev
9 min
Tutorial
Ryan Ong
Tutorial
Ryan Ong
Tutorial
DataCamp Team
Tutorial
Josep Ferrer
Tutorial
Arunn Thevapalan