
Kurs
Vektordatenbanken für Einbettungen mit Pinecone
3 Std.
9.6K
Herkömmliche RAG-Systeme sind zwar effektiv, haben aber einen großen Fehler: Sie teilen die Dokumente oft in kleine Teile auf, um das Auffinden zu erleichtern, aber dadurch kann wichtiger Kontext verloren gehen.
Zum Beispiel könnte es heißen : "Mit mehr als 3,85 Millionen Einwohnern ist sie die bevölkerungsreichste Stadt der Europäischen Union", ohne zu erwähnen, welche Stadt oder welches Land gemeint ist. Dieser fehlende Kontext kann zu unvollständigen oder irrelevanten Ergebnissen führen, vor allem wenn spezifische Details benötigt werden.
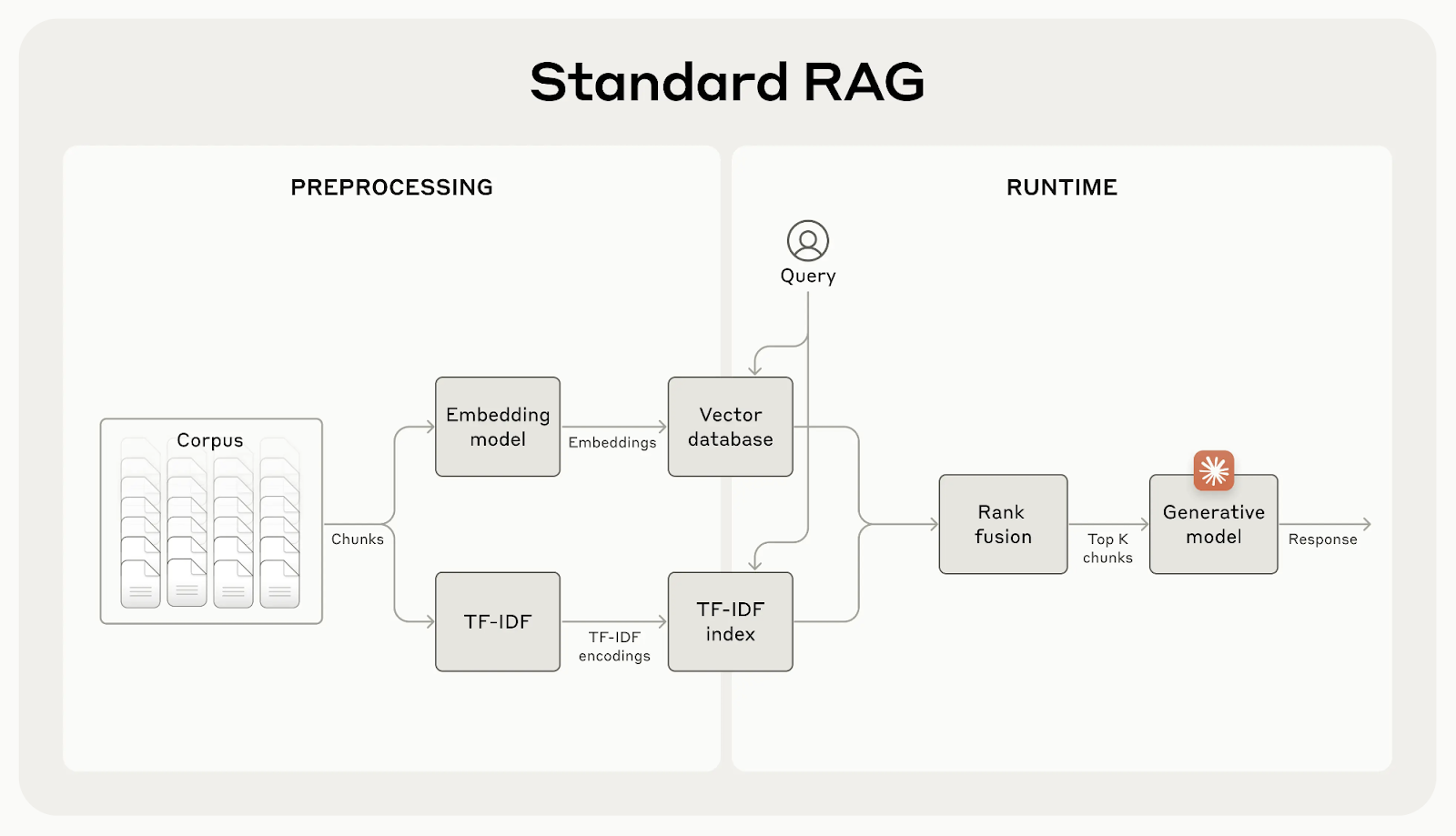
Quelle: Introducing Contextual Retrieval
Die kontextbezogene Suche behebt dieses Problem, indem sie eine kurze, kontextspezifische Erklärung zu jedem Chunk erstellt und hinzufügt, bevor sie ihn einbettet. Im obigen Beispiel würde der Chunk wie folgt umgewandelt werden:
contextualized_chunk = """Berlin is the capital and largest city of Germany, known for being the EU's most populous city within its limits.
Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.
"""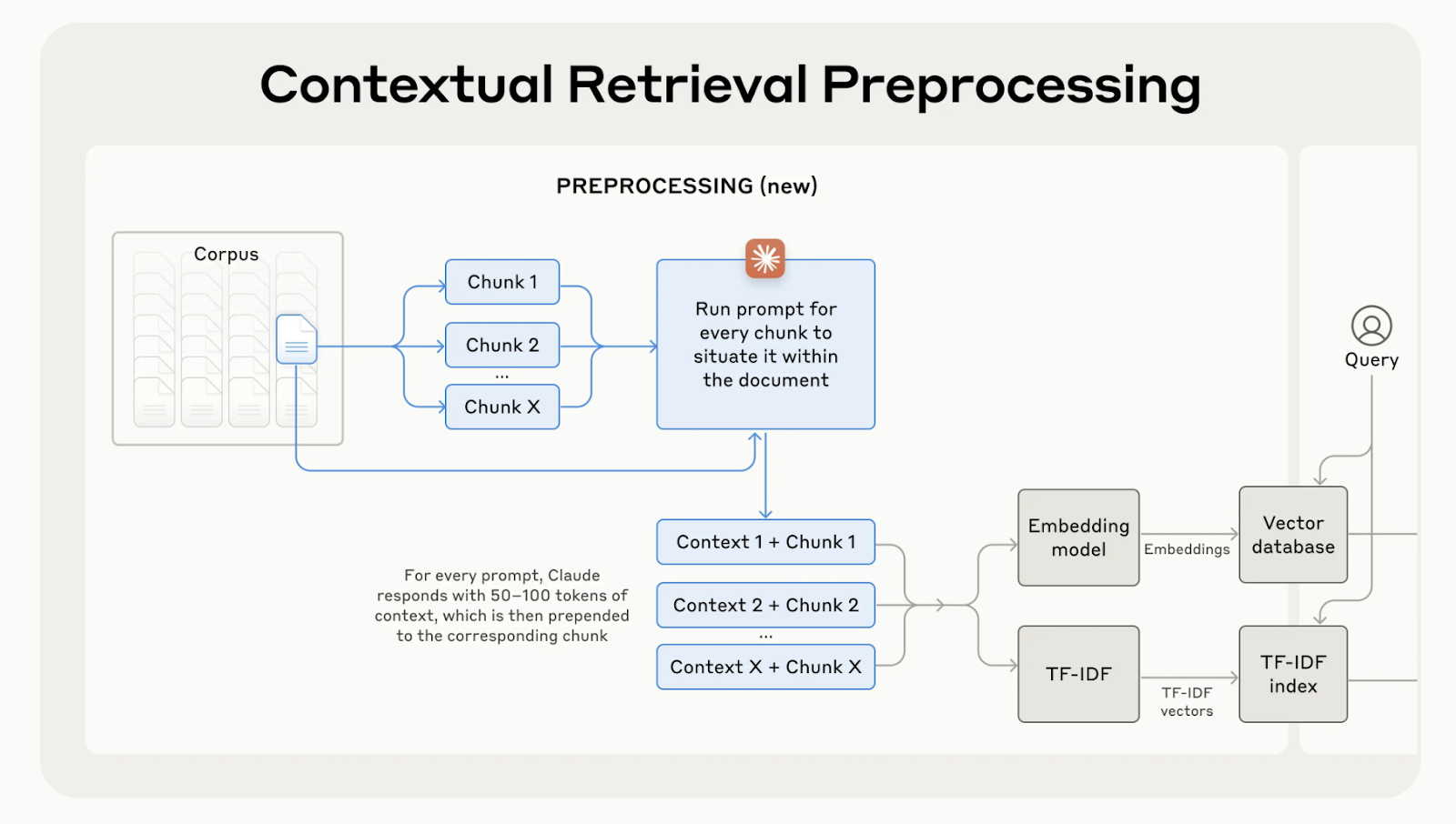
Quelle: Introducing Contextual Retrieval
Insgesamt zeigen die internen Tests von Anthropic in verschiedenen Bereichen, darunter Codebases, wissenschaftliche Arbeiten und Belletristik, dass die kontextuelle Suche die Suchfehler um 49 % reduziert, wenn sie mit kontextuellen Einbettungsmodellen und Contextual BM25 verwendet wird.
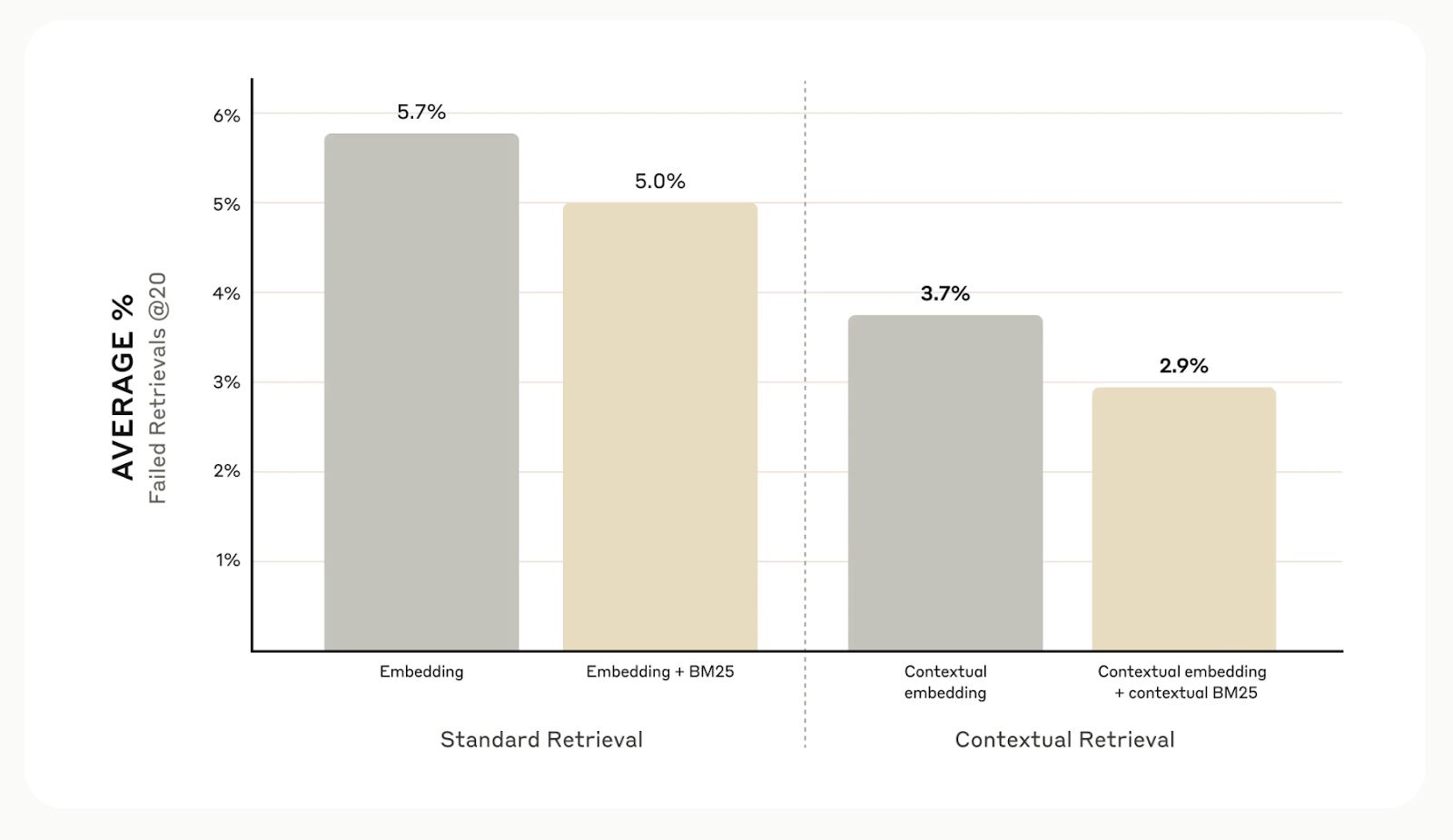
Quelle: Introducing Contextual Retrieval
Ich erkläre dir jetzt Schritt für Schritt, wie du die kontextbezogene Suche implementierst. Wir verwenden das folgende Beispieldokument als Beispiel:
# Input text for the knowledge base
input_text = """Berlin is the capital and largest city of Germany, both by area and by population.
Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.
The city is also one of the states of Germany and is the third smallest state in the country in terms of area.
Paris is the capital and most populous city of France.
It is situated along the Seine River in the north-central part of the country.
The city has a population of over 2.1 million residents within its administrative limits, making it one of Europe's major population centers."""Der erste Schritt besteht darin, das Musterdokument in kleinere, unabhängige Teile zu zerlegen. In diesem Fall werden wir ihn in einzelne Sätze aufteilen.
# Splitting the input text into smaller chunks
test_chunks = [
'Berlin is the capital and largest city of Germany, both by area and by population.',
"\\n\\nIts more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.",
'\\n\\nThe city is also one of the states of Germany and is the third smallest state in the country in terms of area.',
'\\n\\n# Paris is the capital and most populous city of France.',
'\\n\\n# It is situated along the Seine River in the north-central part of the country.',
"\\n\\n# The city has a population of over 2.1 million residents within its administrative limits, making it one of Europe's major population centers."
]Als Nächstes richten wir die Eingabeaufforderung ein, die unser Modell verwenden wird, um Kontext für jeden Chunk zu erzeugen. Anthropic hat dafür eine nützliche Vorlage geliefert. Die Eingabeaufforderung nimmt zwei Eingaben entgegen: das gesamte Dokument und den bestimmten Textabschnitt, den wir einordnen wollen.
from langchain.prompts import ChatPromptTemplate, PromptTemplate, HumanMessagePromptTemplate
# Define the prompt for generating contextual information
anthropic_contextual_retrieval_system_prompt = """<document>
{WHOLE_DOCUMENT}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{CHUNK_CONTENT}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else."""
# Create a PromptTemplate for WHOLE_DOCUMENT and CHUNK_CONTENT
anthropic_prompt_template = PromptTemplate(
input_variables=['WHOLE_DOCUMENT', 'CHUNK_CONTENT'],
template=anthropic_contextual_retrieval_system_prompt
)
# Wrap the prompt in a HumanMessagePromptTemplate
human_message_prompt = HumanMessagePromptTemplate(prompt=anthropic_prompt_template)
# Create the final ChatPromptTemplate
anthropic_contextual_retrieval_final_prompt = ChatPromptTemplate(
input_variables=['WHOLE_DOCUMENT', 'CHUNK_CONTENT'],
messages=[human_message_prompt]
)Hier kannst du ein beliebiges LLM auswählen, um Kontext für jeden Chunk zu erzeugen. Für unser Beispiel werden wir die OpenAI's GPT-4o Modell.
import os
from langchain_openai import ChatOpenAI
# Load environment variables
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# Initialize the model instance
llm_model_instance = ChatOpenAI(
model="gpt-4o",
)Wir werden die Prompt-Vorlage mit dem Sprachmodell verbinden, um eine LLM-Kette zu erstellen, die bereit ist, die zuvor erstellten Chunks zu verarbeiten.
from langchain.output_parsers import StrOutputParser
# Chain the prompt with the model instance
contextual_chunk_creation = anthropic_contextual_retrieval_final_prompt | llm_model_instance | StrOutputParser()Wir werden nun eine Schleife durch unsere Chunks ziehen, die Kontextinformationen für jeden einzelnen generieren und die Ergebnisse mit der contextual_chunk_creation LLM-Kette ausdrucken.
# Process each chunk and generate contextual information
for test_chunk in test_chunks:
res = contextual_chunk_creation.invoke({
"WHOLE_DOCUMENT": input_text,
"CHUNK_CONTENT": test_chunk
})
print(res)
print('-----')The document compares Berlin and Paris, highlighting Berlin as Germany's capital and largest city by area and population, and noting its significance within the European Union.
-----
Berlin is the capital and largest city of Germany, known for being the EU's most populous city within its limits.
-----
Berlin is the capital and largest city of Germany, both by area and by population.
-----
Paris, the capital of France, is a major population center in Europe with over 2.1 million residents.
-----
Paris is the capital and most populous city of France.
-----
Paris is the capital and most populous city of France, with a population of over 2.1 million residents within its administrative limits.
-----Das kontextbezogene Retrieval erhöht zwar die Abrufgenauigkeit, aber du kannst noch weiter gehen mit reranking. Diese Filtertechnik stellt sicher, dass nur die relevantesten Chunks an das Modell gesendet werden, was die Antwortqualität verbessert und die Kosten und die Bearbeitungszeit senkt.
Beim Reranking werden die im ersten Schritt gefundenen Chunks bewertet und nur die besten behalten. In unseren Tests reduzierte das Reranking die Suchfehler von 5,7 % auf nur 1,9 % und verbesserte die Genauigkeit um 67 % im Vergleich zu herkömmlichen Methoden.
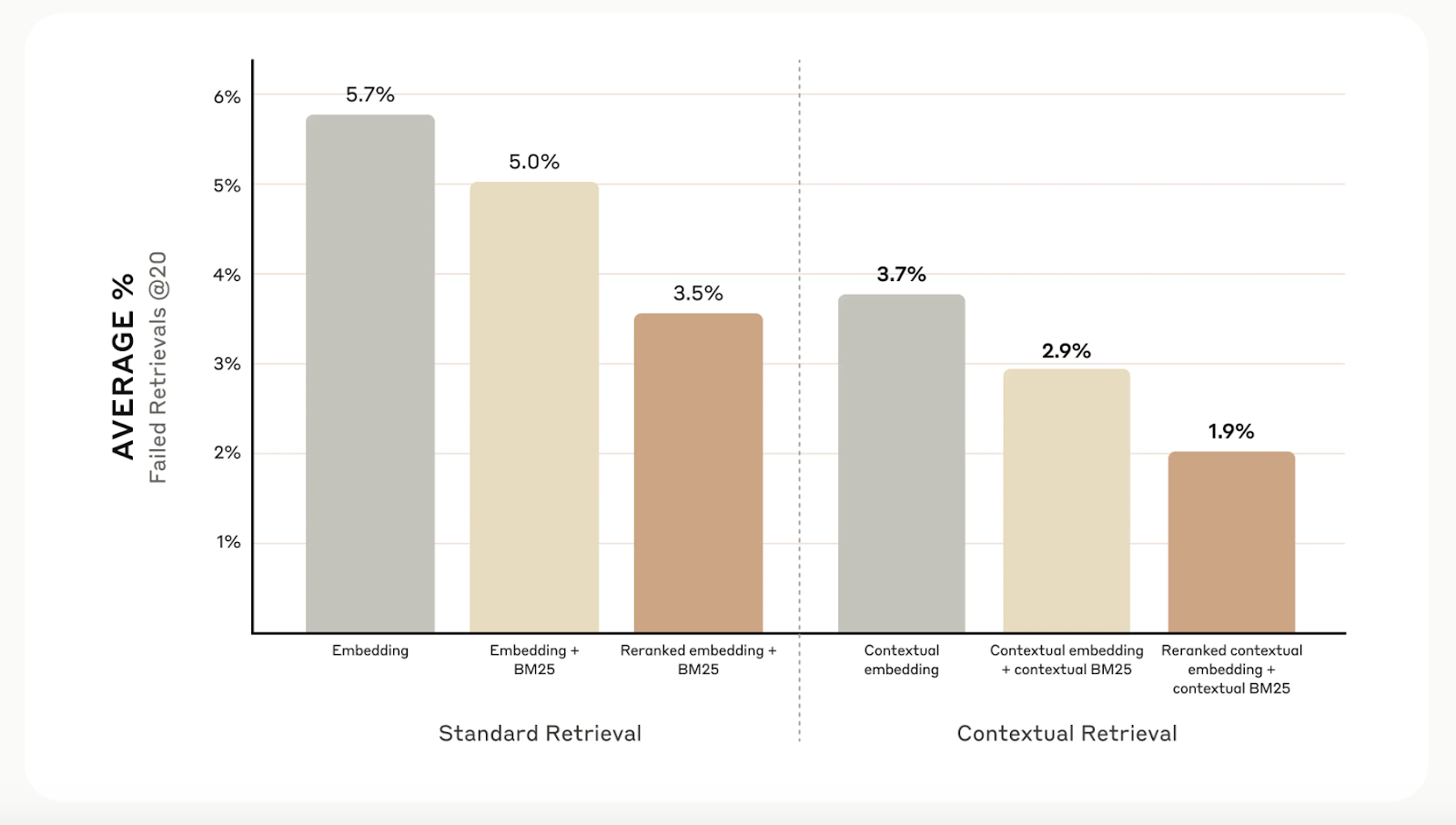
Quelle: Introducing Contextual Retrieval
Die anthropologische Forschung hat herausgefunden, dass nicht jede Situation die Komplexität des Kontextabrufs erfordert. Bei kleineren Wissensdatenbanken mit weniger als 200.000 Token (ca. 500 Seiten) könnte es besser sein, die gesamte Wissensdatenbank direkt in die Eingabeaufforderung des Modells einzubeziehen und auf Retrievalsysteme zu verzichten.
Sie empfehlen außerdem, die Vorteile des Prompt-Cachingzu nutzen, eine Funktion, die für Claude eingeführt wurde. Durch das Zwischenspeichern häufig genutzter Prompts zwischen API-Aufrufen können Entwickler die Kosten um bis zu 90 % senken und die Antwortzeiten um mehr als das Doppelte beschleunigen. Dieses Prompt-Caching-Kochbuch bietet eine Schritt-für-Schritt-Anleitung für die Implementierung.
Das kontextbezogene Retrieval von Anthropic ist eine einfache, aber effektive Methode zur Verbesserung von Retrievalsystemen. Die Kombination von kontextuellen Einbettungen, BM25 und Reranking verbessert die Genauigkeit dieser Systeme erheblich.
Um mehr über verschiedene Suchtechniken zu erfahren, empfehle ich die folgenden Blogs:
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.