
Cours
Bases de données vectorielles pour les intégrations avec Pinecone
3 h
9.6K
Bien que les systèmes RAG traditionnels soient efficaces, ils présentent un défaut majeur : ils divisent souvent les documents en petits morceaux pour faciliter la recherche, mais cela peut supprimer un contexte important.
Par exemple, un morceau peut dire "Ses plus de 3,85 millions d'habitants en font la ville la plus peuplée de l'Union européenne" sans mentionner de quelle ville ou de quel pays il s'agit. Ce manque de contexte peut conduire à des résultats incomplets ou non pertinents, en particulier lorsque des détails spécifiques sont nécessaires.
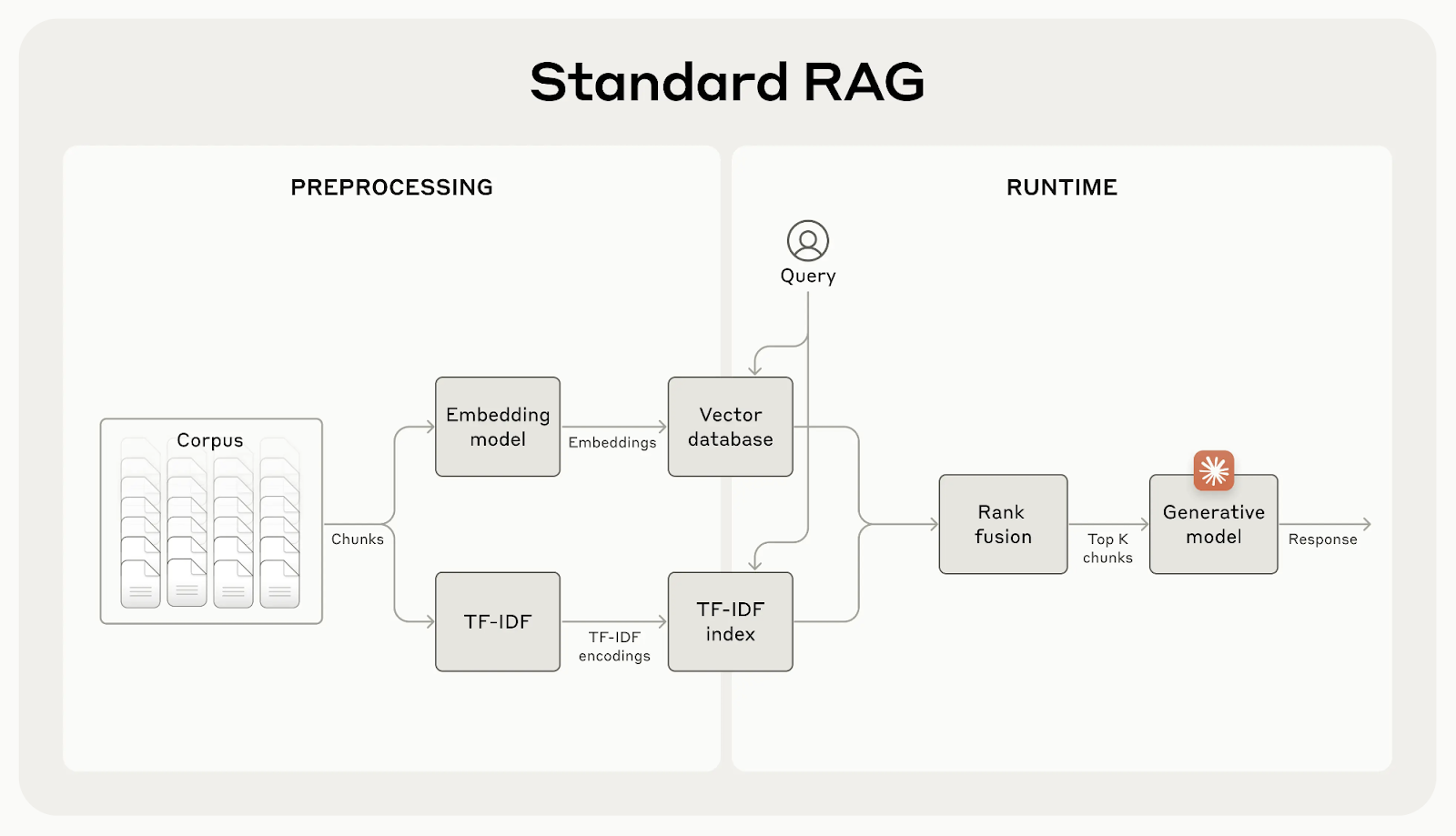
Source : Introduction à la recherche contextuelle
L'extraction contextuelle corrige ce problème en générant et en ajoutant une brève explication contextuelle à chaque élément avant de l'intégrer. Dans l'exemple ci-dessus, le morceau serait transformé comme suit :
contextualized_chunk = """Berlin is the capital and largest city of Germany, known for being the EU's most populous city within its limits.
Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.
"""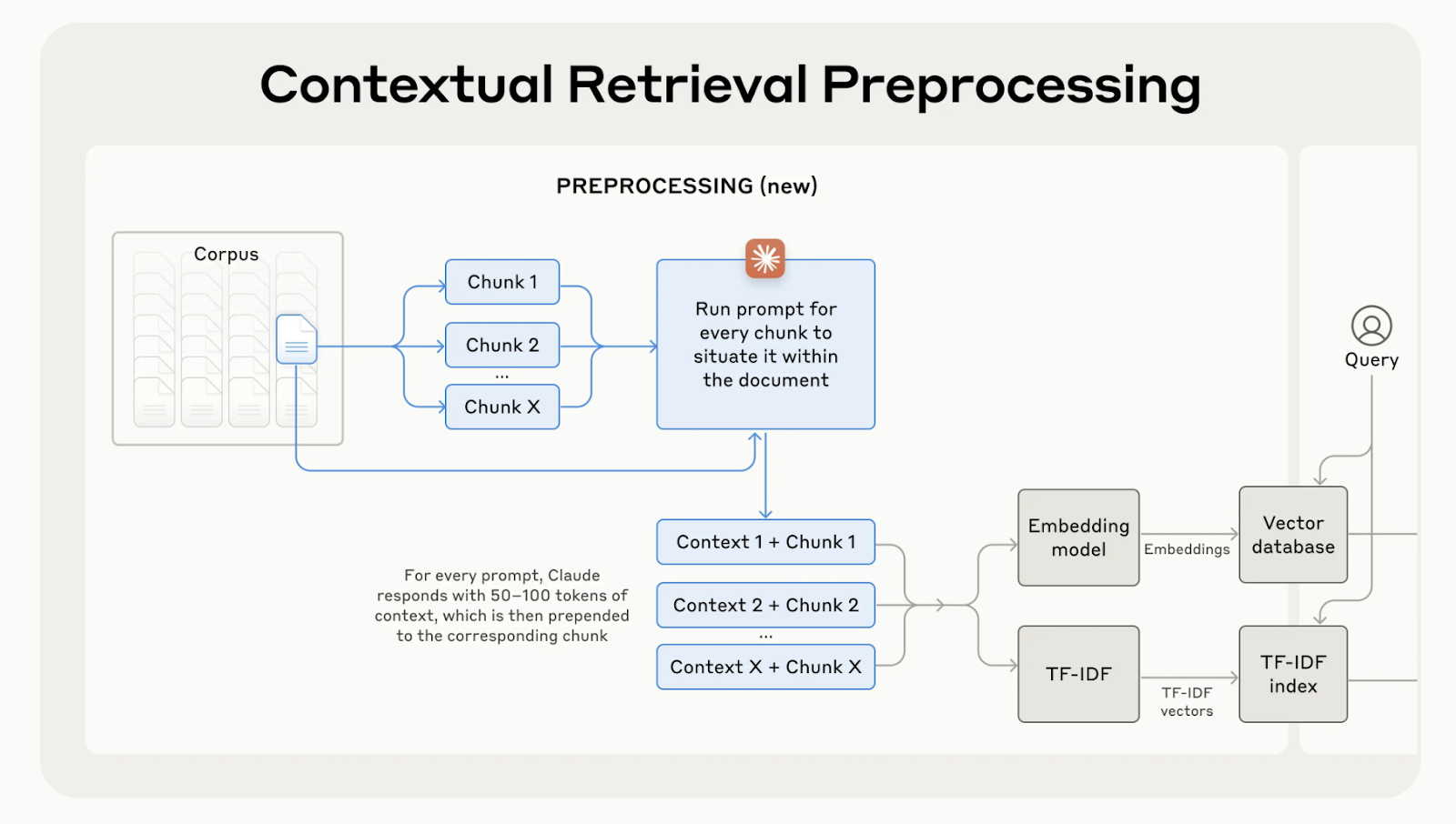
Source : Introduction à la recherche contextuelle
Dans l'ensemble, les tests internes d'Anthropic dans différents domaines, y compris les bases de code, les articles scientifiques et la fiction, montrent que la recherche contextuelle réduit les erreurs de recherche de 49% lorsqu'elle est utilisée avec des modèles d'intégration contextuelle et Contextual BM25.
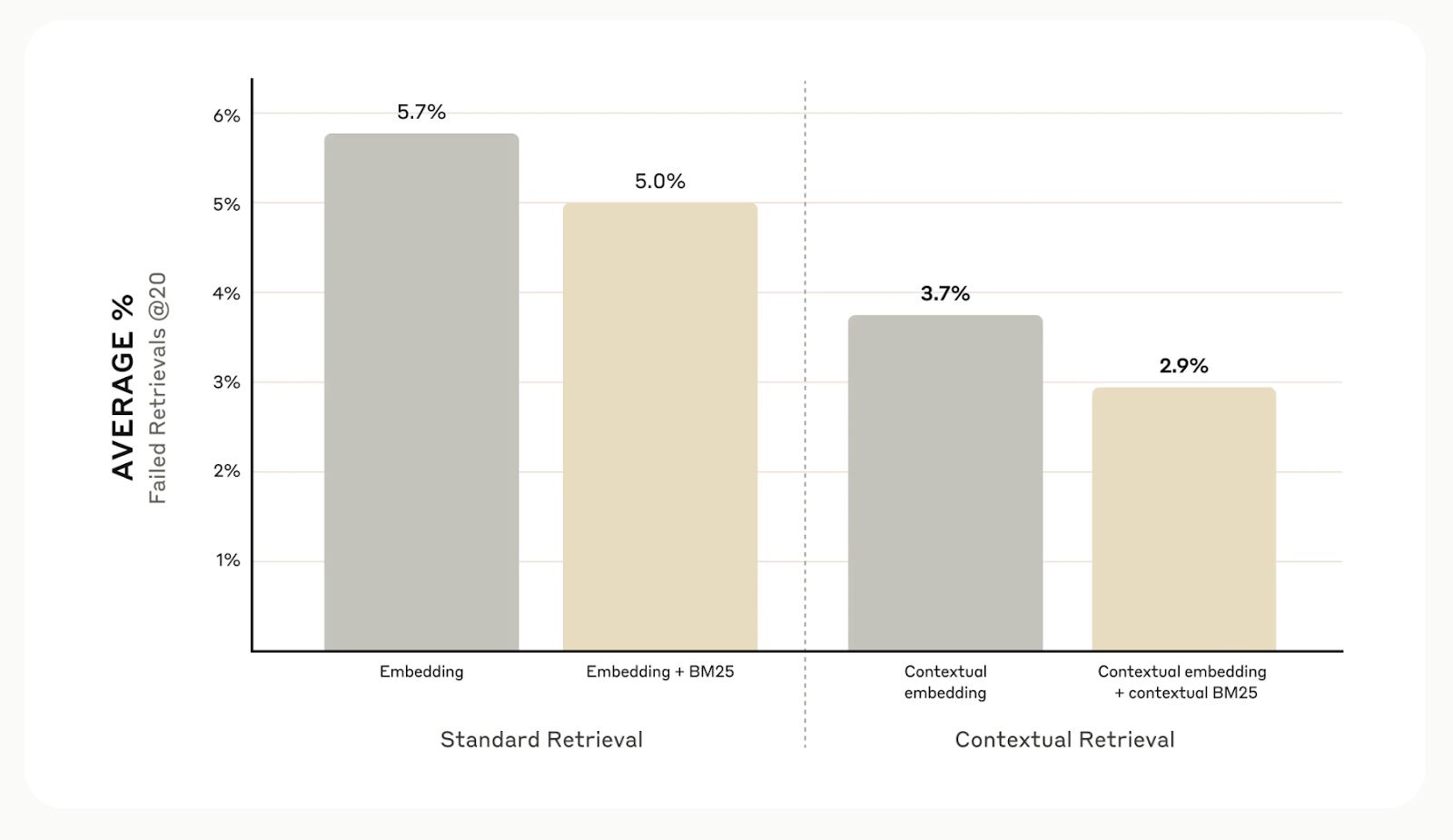
Source : Introduction à la recherche contextuelle
Je vais maintenant vous expliquer, étape par étape, comment mettre en œuvre la recherche contextuelle. Nous utiliserons le document suivant comme exemple :
# Input text for the knowledge base
input_text = """Berlin is the capital and largest city of Germany, both by area and by population.
Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.
The city is also one of the states of Germany and is the third smallest state in the country in terms of area.
Paris is the capital and most populous city of France.
It is situated along the Seine River in the north-central part of the country.
The city has a population of over 2.1 million residents within its administrative limits, making it one of Europe's major population centers."""La première étape consiste à diviser le document modèle en morceaux plus petits et indépendants. Dans ce cas, nous le diviserons en phrases individuelles.
# Splitting the input text into smaller chunks
test_chunks = [
'Berlin is the capital and largest city of Germany, both by area and by population.',
"\\n\\nIts more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.",
'\\n\\nThe city is also one of the states of Germany and is the third smallest state in the country in terms of area.',
'\\n\\n# Paris is the capital and most populous city of France.',
'\\n\\n# It is situated along the Seine River in the north-central part of the country.',
"\\n\\n# The city has a population of over 2.1 million residents within its administrative limits, making it one of Europe's major population centers."
]Ensuite, nous configurerons l'invite que notre modèle utilisera pour générer le contexte de chaque morceau. Anthropic a fourni un modèle utile à cet effet. L'invite prendra deux entrées : le document entier et le morceau de texte spécifique que nous voulons situer.
from langchain.prompts import ChatPromptTemplate, PromptTemplate, HumanMessagePromptTemplate
# Define the prompt for generating contextual information
anthropic_contextual_retrieval_system_prompt = """<document>
{WHOLE_DOCUMENT}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{CHUNK_CONTENT}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else."""
# Create a PromptTemplate for WHOLE_DOCUMENT and CHUNK_CONTENT
anthropic_prompt_template = PromptTemplate(
input_variables=['WHOLE_DOCUMENT', 'CHUNK_CONTENT'],
template=anthropic_contextual_retrieval_system_prompt
)
# Wrap the prompt in a HumanMessagePromptTemplate
human_message_prompt = HumanMessagePromptTemplate(prompt=anthropic_prompt_template)
# Create the final ChatPromptTemplate
anthropic_contextual_retrieval_final_prompt = ChatPromptTemplate(
input_variables=['WHOLE_DOCUMENT', 'CHUNK_CONTENT'],
messages=[human_message_prompt]
)Ici, vous pouvez choisir n'importe quel LLM pour générer le contexte de chaque morceau. Pour notre exemple, nous utiliserons le logiciel OpenAI GPT-4o de l'OpenAI.
import os
from langchain_openai import ChatOpenAI
# Load environment variables
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# Initialize the model instance
llm_model_instance = ChatOpenAI(
model="gpt-4o",
)Nous allons relier le modèle d'invite au modèle de langue pour créer une chaîne LLM prête à traiter les morceaux que nous avons créés précédemment.
from langchain.output_parsers import StrOutputParser
# Chain the prompt with the model instance
contextual_chunk_creation = anthropic_contextual_retrieval_final_prompt | llm_model_instance | StrOutputParser()Nous allons maintenant parcourir nos morceaux, générer les informations contextuelles pour chacun d'entre eux et imprimer les résultats à l'aide de la chaîne LLM contextual_chunk_creation.
# Process each chunk and generate contextual information
for test_chunk in test_chunks:
res = contextual_chunk_creation.invoke({
"WHOLE_DOCUMENT": input_text,
"CHUNK_CONTENT": test_chunk
})
print(res)
print('-----')The document compares Berlin and Paris, highlighting Berlin as Germany's capital and largest city by area and population, and noting its significance within the European Union.
-----
Berlin is the capital and largest city of Germany, known for being the EU's most populous city within its limits.
-----
Berlin is the capital and largest city of Germany, both by area and by population.
-----
Paris, the capital of France, is a major population center in Europe with over 2.1 million residents.
-----
Paris is the capital and most populous city of France.
-----
Paris is the capital and most populous city of France, with a population of over 2.1 million residents within its administrative limits.
-----Si la recherche contextuelle améliore la précision de la recherche, vous pouvez aller encore plus loin avec le reranking. Cette technique de filtrage garantit que seuls les éléments les plus pertinents sont envoyés au modèle, ce qui améliore la qualité des réponses et réduit les coûts et le temps de traitement.
Le reclassement consiste à évaluer les morceaux récupérés lors de la première étape et à ne conserver que les meilleurs. Lors de nos tests, le reranking a permis de réduire les erreurs de recherche de 5,7 % à seulement 1,9 %, améliorant ainsi la précision de 67 % par rapport aux méthodes traditionnelles.
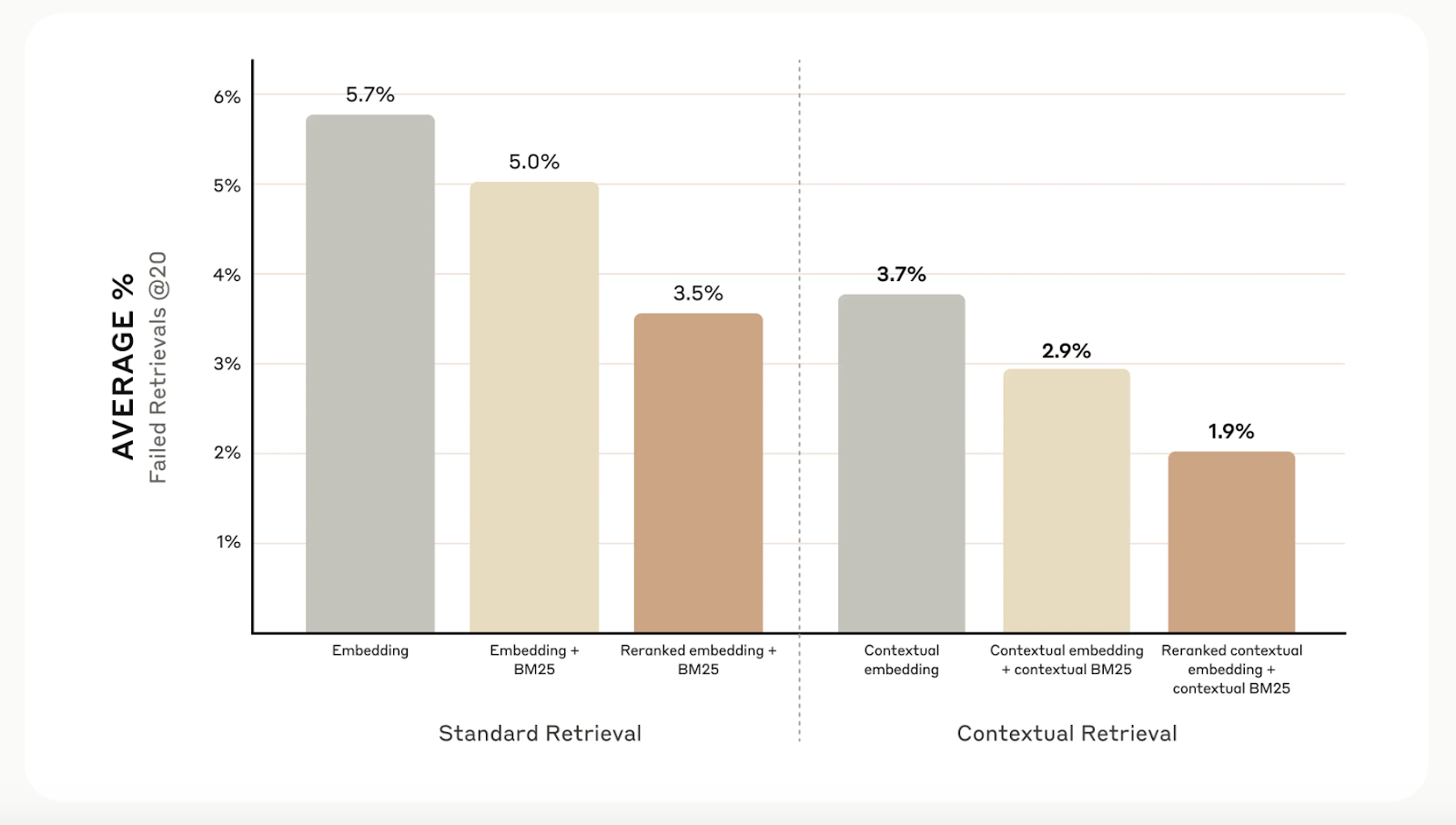
Source : Introduction à la recherche contextuelle
La recherche anthropique a montré que toutes les situations ne requièrent pas la complexité de la recherche contextuelle. Pour les petites bases de connaissances de moins de 200 000 tokens (environ 500 pages), une meilleure option consisterait à inclure l'ensemble de la base de connaissances directement dans l'invite du modèle, ce qui éviterait d'avoir à recourir à des systèmes de recherche.
Ils suggèrent également de tirer parti de mise en cache de l'inviteune fonctionnalité introduite pour Claude. En mettant en cache les invites fréquemment utilisées entre les appels d'API, les développeurs peuvent réduire les coûts jusqu'à 90 % et accélérer les temps de réponse de plus de deux fois. Ce livre de recettes pour la mise en cache de l'invite livre de recettes sur la mise en cache rapide fournit des conseils étape par étape pour la mise en œuvre de cette méthode.
La recherche contextuelle d'Anthropic est une méthode simple mais efficace pour améliorer les systèmes de recherche. La combinaison d'enchâssements contextuels, de BM25 et de reranking améliore considérablement la précision de ces systèmes.
Pour en savoir plus sur les différentes techniques de recherche, je vous recommande les blogs suivants :
Apprenez l'IA avec ces cours !
Cours
Cours
Cours