
Curso
Conceptos de Databricks
4 h
22.1K
Databricks sirve como plataforma analítica unificada, permitiendo la integración de la ingeniería de datos, el aprendizaje automático y la analítica empresarial. En el núcleo de este ecosistema están los Cuadernos Databricks, espacios de trabajo interactivos diseñados para la exploración de datos, el desarrollo de modelos y los flujos de trabajo de producción.
En este artículo, te mostraré cómo empezar a utilizar los Cuadernos Databrick. Si eres totalmente nuevo, quizá quieras empezar por inscribirte en nuestro curso Introducción a Databricks para que puedas comprender los entresijos de Databricks y cómo moderniza la arquitectura de datos. Nuestro curso es muy completo y enseña muchas cosas, como la gestión de catálogos y la ingestión de datos, así que pruébalo.
Los cuadernos Databricks son espacios de trabajo interactivos basados en la nube que permiten a los usuarios realizar exploración de datos, ingeniería, aprendizaje automático y análisis en un entorno colaborativo. Utilizan un modelo de ejecución basado en celdas, en el que los usuarios pueden escribir y ejecutar código en bloques discretos o celdas.
Los cuadernos Databricks son compatibles con varios idiomas, por lo que no sólo puedes elegir tu idioma favorito, sino también cambiar de idioma dentro del mismo cuaderno. Los lenguajes incluyen Python, SQL, Scala y R, para todos los cuales ofrecemos cursos introductorios.
Ahora, para facilitar la interoperabilidad multilingüe, Databricks proporciona lo que se conoce como comandos mágicos:
%python: Ejecuta una célula utilizando Python.
%sql: Ejecuta consultas SQL.
%scala: Procesa comandos basados en Scala.
%r: Ejecuta el código R.
Los Cuadernos Databricks van más allá de los entornos de codificación tradicionales al ofrecer las siguientes capacidades clave:
Una cosa es leer sobre las características, pero otra cosa es verlo por ti mismo. La mejor forma de apreciar Databricks es empezar a hacer cosas por ti mismo. Así que, en esta sección, te ayudaré a empezar a crear, gestionar y navegar por blocs de notas en el espacio de trabajo de Databricks. Entonces, estoy seguro de que empezarás a ver por ti mismo lo útil que es.
En el espacio de trabajo de Databricks, puedes crear nuevas libretas o gestionar las existentes. Veamos estos métodos a continuación.
Para crear una nueva libreta en Databricks:
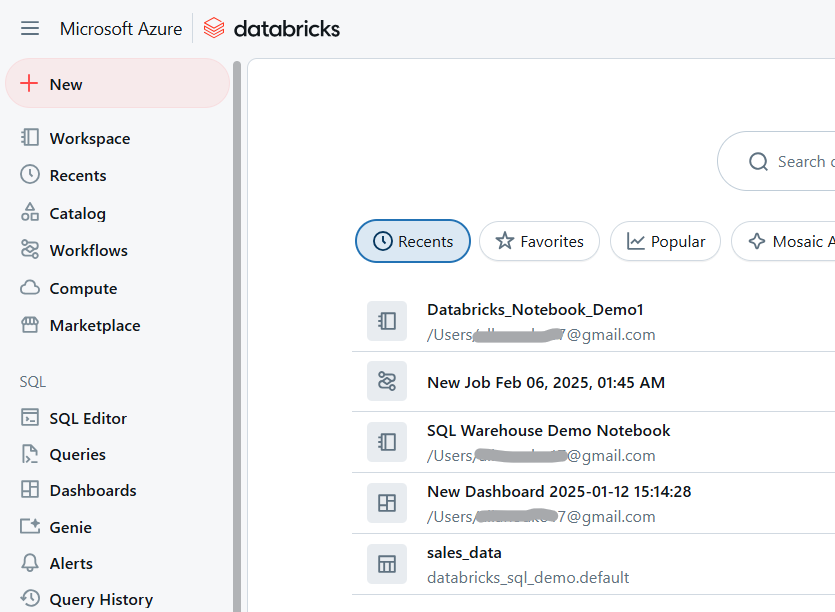
Espacio de trabajo Databricks. Imagen del autor.
Crea un cuaderno Databricks. Imagen del autor.
Selecciona el nombre y el idioma por defecto para Databricks Notebook. Imagen del autor.
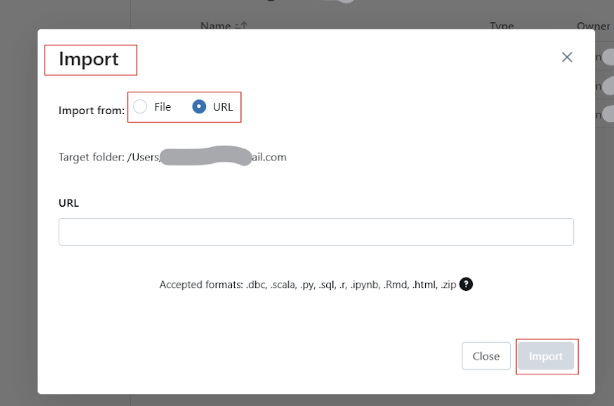
Databricks permite a los usuarios importar cuadernos desde múltiples fuentes, como GitHub y repositorios Git, URL externas o archivos locales cargados como archivos .dbc (archivo Databricks) o .ipynb (Jupyter).
Sigue los pasos siguientes para importar las libretas existentes al Espacio de Trabajo Databricks:
Importa el bloc de notas existente al Espacio de Trabajo Databricks. Imagen del autor.
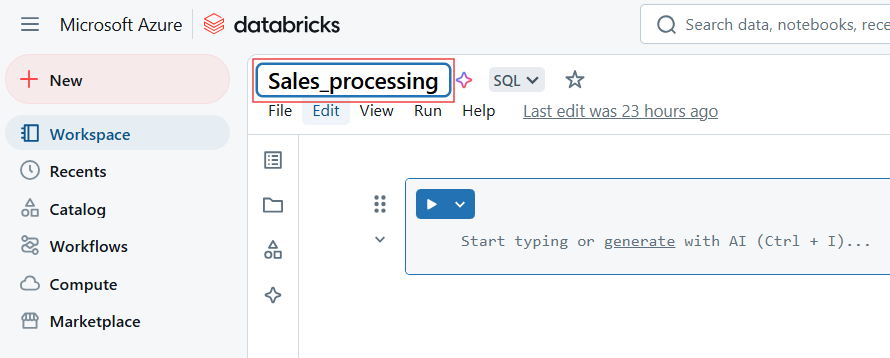
Para cambiar el nombre del bloc de notas Databricks, haz clic en el título del bloc de notas y edita el nombre.
También puedes mover las libretas a carpetas para estructurarlas mejor.
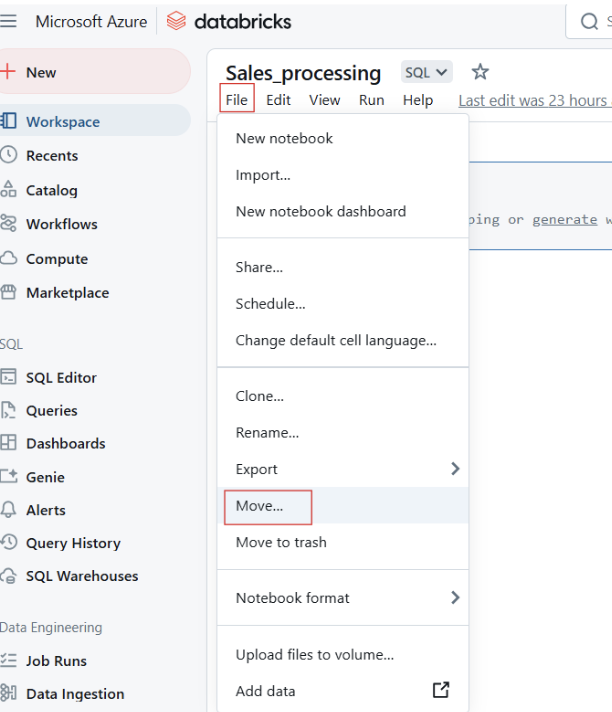
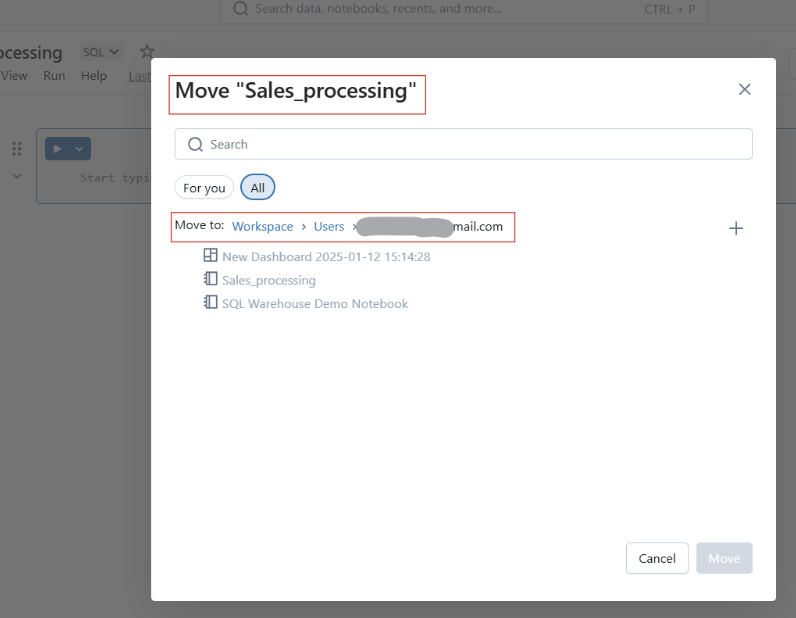
Mover cuadernos Databricks a carpeta. Imagen del autor.
Antes de compartir tu Cuaderno Datbricks, puedes gestionar el acceso y los permisos para controlar quién puede ver, editar o gestionar el cuaderno.
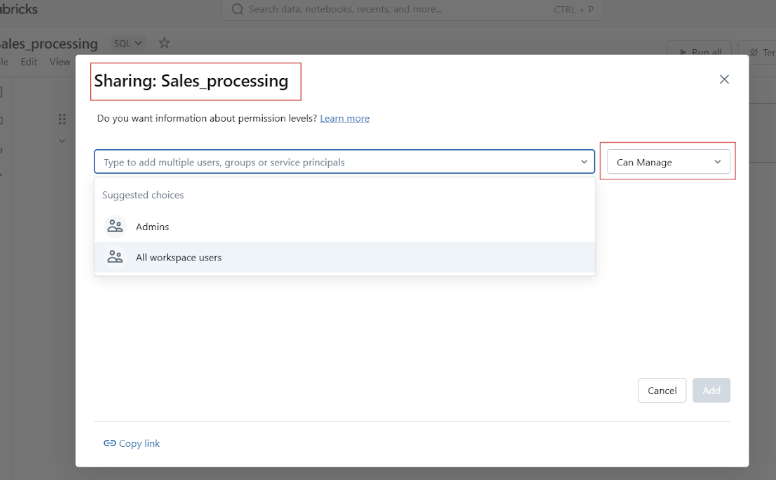
Antes de pasar a los ejemplos prácticos de uso de los Cuadernos de Databricks, permíteme que te guíe por la interfaz de usuario y la navegación de la plataforma.
La barra de herramientas de Databricks Notebook proporciona acceso rápido a las siguientes acciones:
Ejecutar, editar, borrar o mover la celda.
Cambiar los tipos de celda, como código, markdown, SQL o Scala.
Establecer comandos mágicos como %python o %sql.
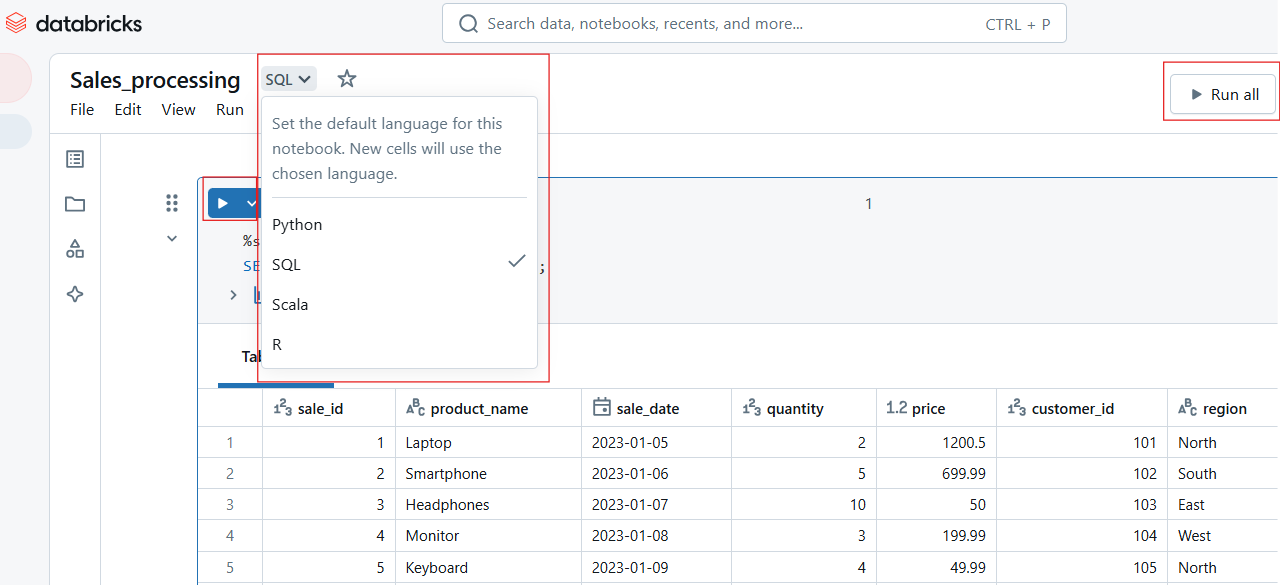
Ejecutar una célula en Databricks Notebook. Imagen del autor.
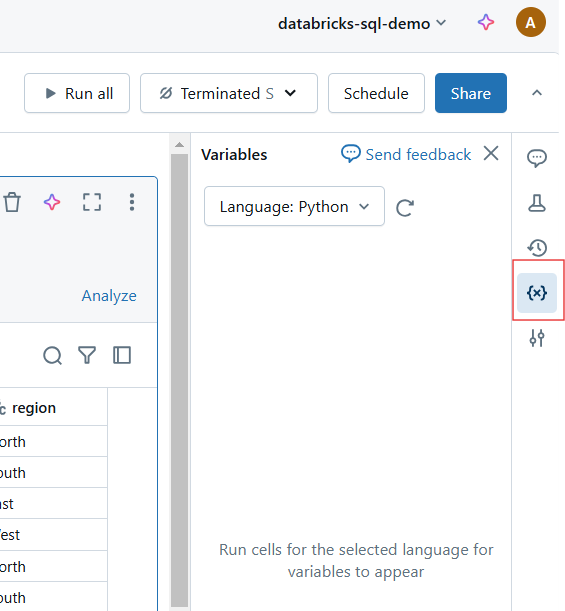
Restablecer variables y estado de ejecución en el Cuaderno Databricks. Imagen del autor.
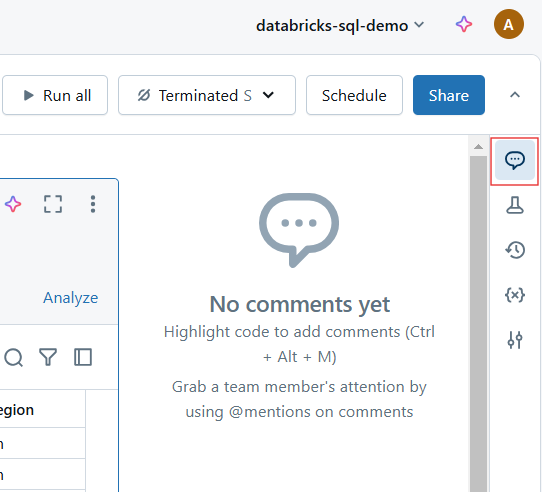
Comentarios en el Cuaderno Databricks. Imagen del autor.
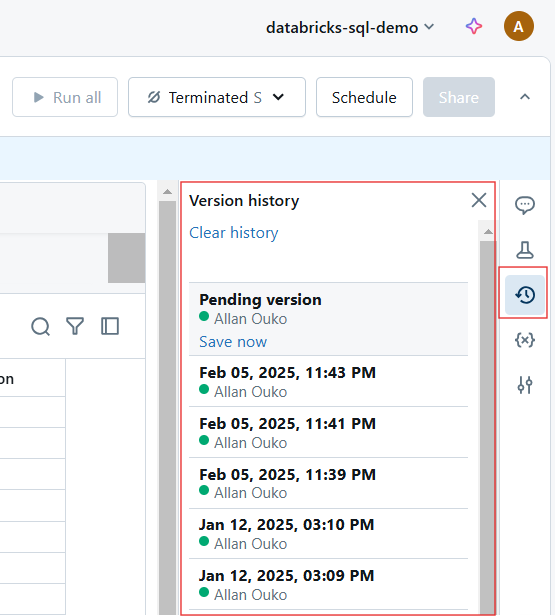
Historial de versiones en Databricks Notebook. Imagen del autor.
Databricks ha introducido varias mejoras en la interfaz de usuario para una experiencia más intuitiva. Con estas mejoras, los Cuadernos de Databricks ofrecen un entorno de desarrollo aún más ágil y potente para los profesionales de los datos. Incluyen lo siguiente:
Los Cuadernos de Databricks proporcionan un entorno de codificación interactivo en el que los usuarios pueden escribir, ejecutar y documentar su código. En esta sección, cubriré el trabajo con celdas de código, Markdown y la ejecución eficiente del código.
Los cuadernos Databricks admiten varios lenguajes, como Python, SQL, Scala y R, dentro del mismo cuaderno.
Utiliza el comando mágico %python para escribir código Python en una celda dentro de Databricks Notebook.
%python
import pandas as pd
# Load sample data and display the first few rows
df = spark.read.format("csv").option("header", "true").load("/databricks-datasets/airlines/part-00000")
pd_df = df.limit(5).toPandas() # Convert to Pandas DataFrame
display(pd_df) # Works in Databricks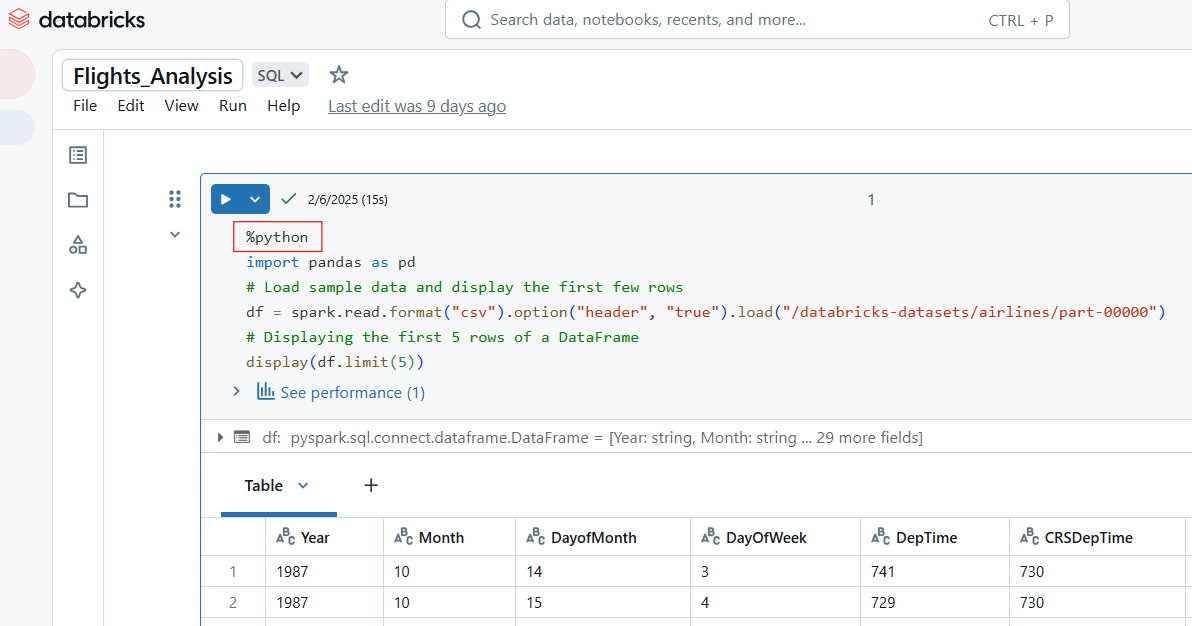
Ejemplo de código Python en Databricks Notebook. Imagen del autor.
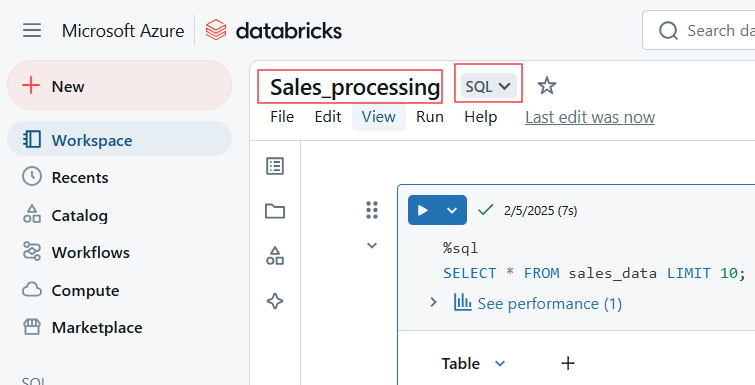
Para escribir código SQL en Databricks Notebook, utiliza el comando mágico %sql. Si has establecido SQL como lenguaje por defecto del bloc de notas, puedes ejecutar la celda sin incluir el comando mágico %sql.
-- Querying a dataset in SQL
SELECT origin, dest, COUNT(*) AS flight_count
FROM flights_table
GROUP BY origin, dest
ORDER BY flight_count DESC
LIMIT 10;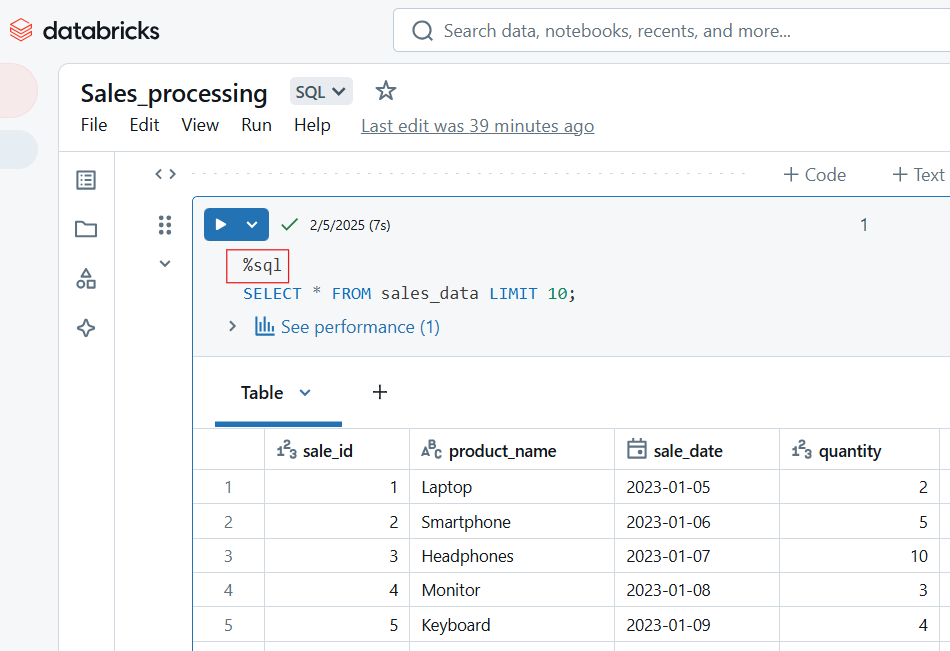
Código SQL en Databricks Notebook. Imagen del autor.
Utiliza el comando mágico %scala para escribir código Scala en una celda dentro de Databricks Notebook.
%scala
// Reading and displaying data in Scala
val data = spark.read.option("header", "true").csv("/databricks-datasets/airlines/part-00000")
// Display as a table in Databricks
display(data)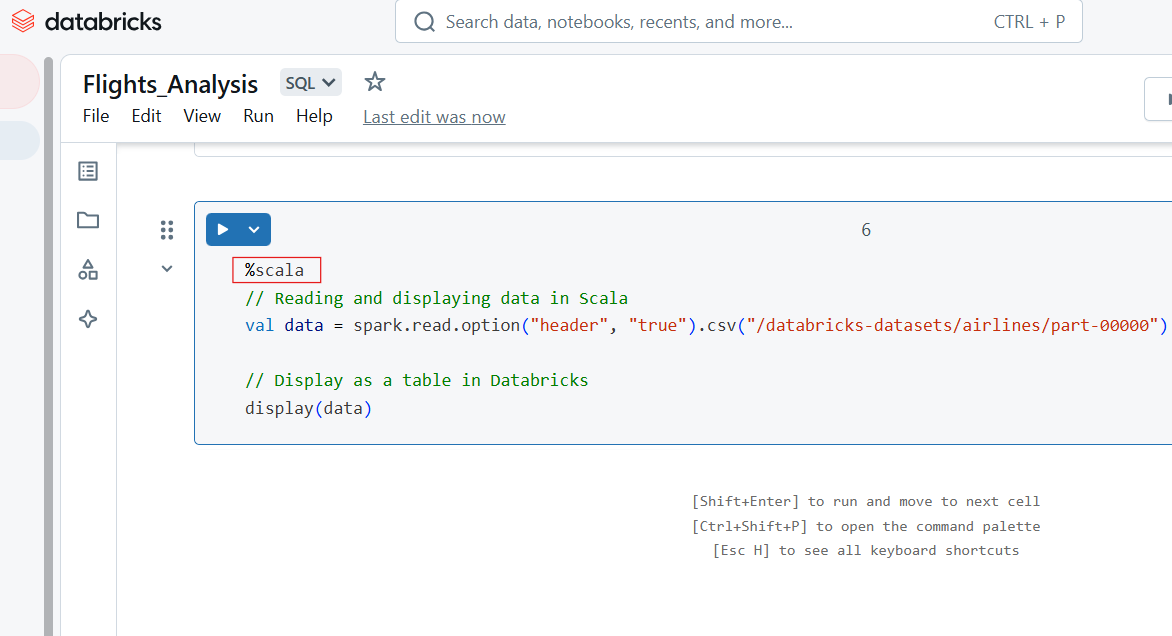
Código Scala en Databricks Notebook. Imagen del autor.
También puedes escribir código R en la celda de Databricks Notebook utilizando el comando %r magic.
%r
# Load a sample dataset in R
library(SparkR)
df <- read.df("/databricks-datasets/airlines/part-00000", source = "csv", header = "true")
head(df)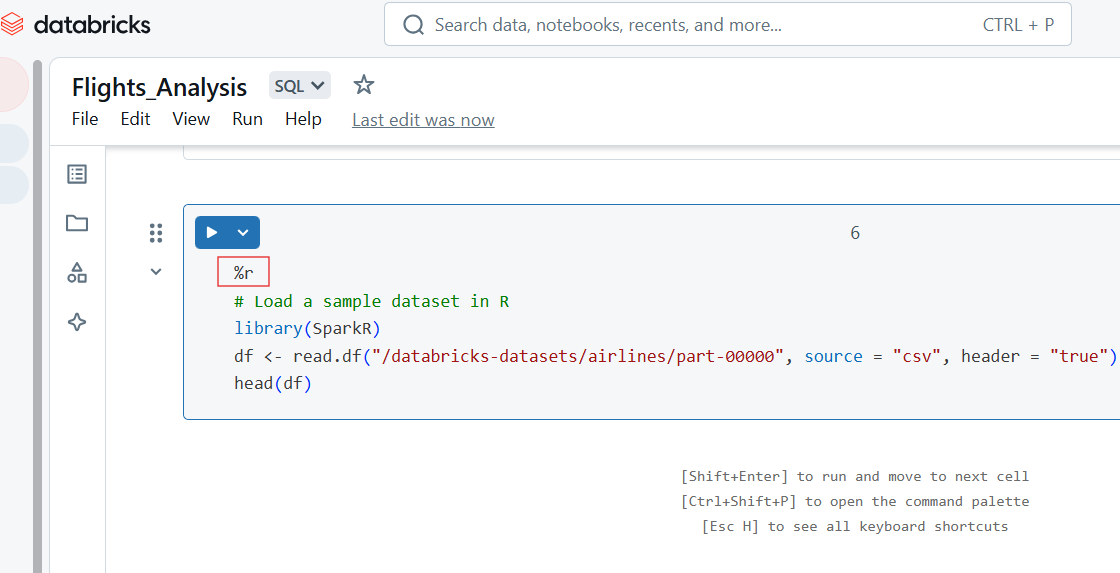
Código R en Databricks Notebook. Imagen del autor.
Las celdas Markdown se utilizan para añadir texto, encabezados, listas y otra documentación. El siguiente ejemplo muestra cómo escribir una celda Markdown y cómo se muestran los resultados en Databricks Notebook.
%md
# Data Exploration Notebook
This notebook explores airline flight data, providing insights into flight frequency and destinations.
## **Steps:**
1. Load and display the dataset
2. Query data using SQL
3. Generate visualizations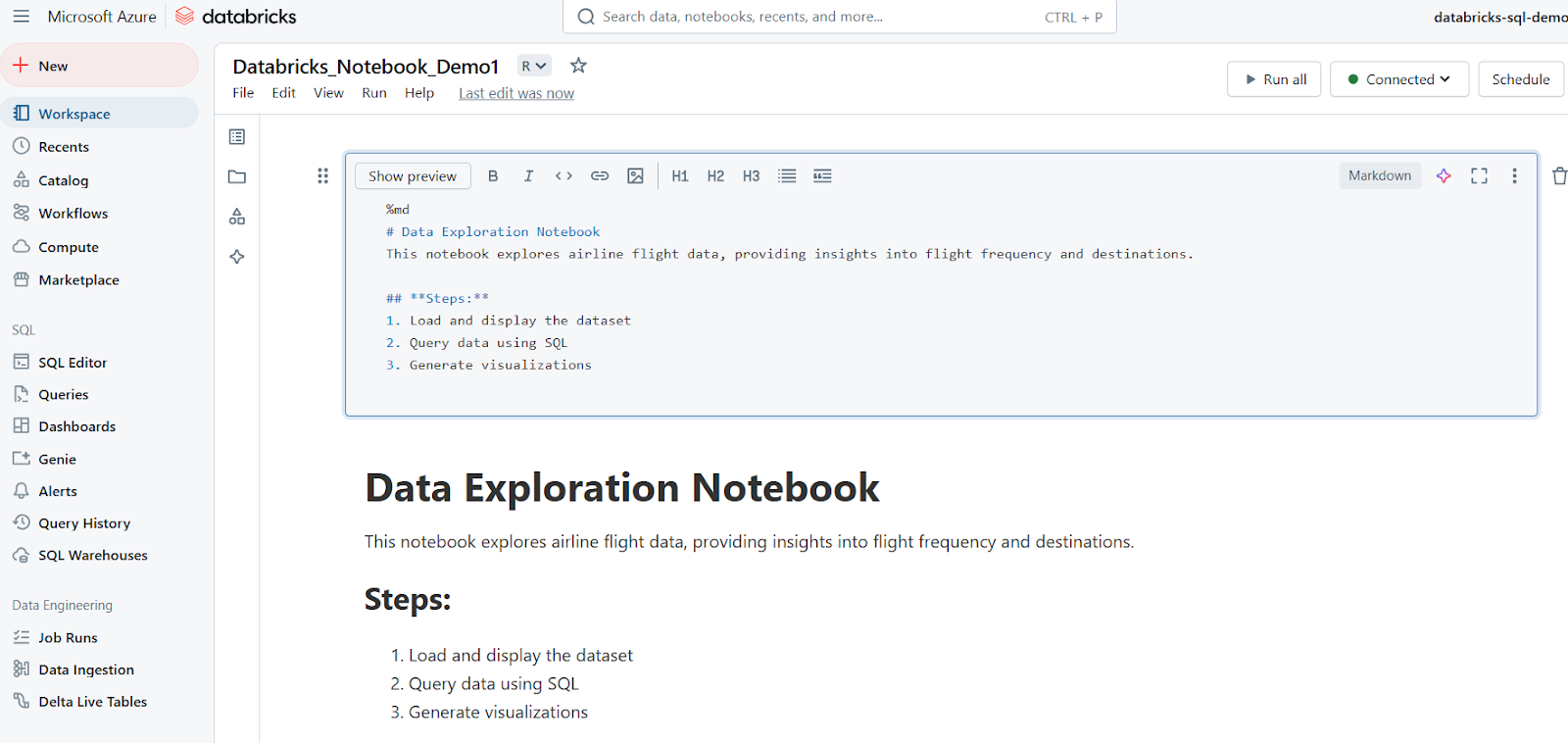
Los Cuadernos Databricks permiten una ejecución flexible del código mediante ejecuciones de celdas individuales o por lotes.
Para ejecutar una sola celda, haz clic en el botón Ejecutar (▶) de la celda o utiliza el atajo de teclado:
Para ejecutar todas las celdas del bloc de notas:
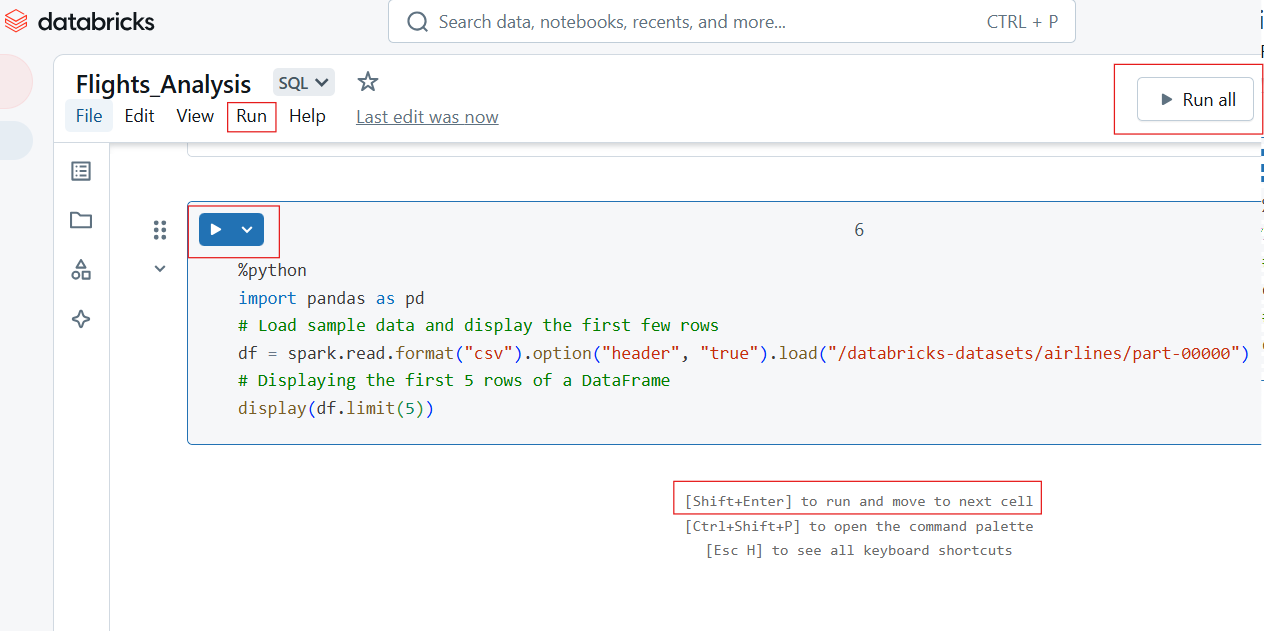
Ejecutando individualmente y ejecutando todas las celdas en Databricks Notebook. Imagen del autor.
Los Cuadernos de Databricks admiten múltiples formatos de salida, como tablas, gráficos y registros. Por ejemplo, el siguiente código Python muestra las 5 primeras filas del conjunto de datos "líneas aéreas".
%python
import pandas as pd
# Load sample data and display the first few rows
df = spark.read.format("csv").option("header", "true").load("/databricks-datasets/airlines/part-00000")
# Displaying the first 5 rows of a DataFrame
display(df.limit(5))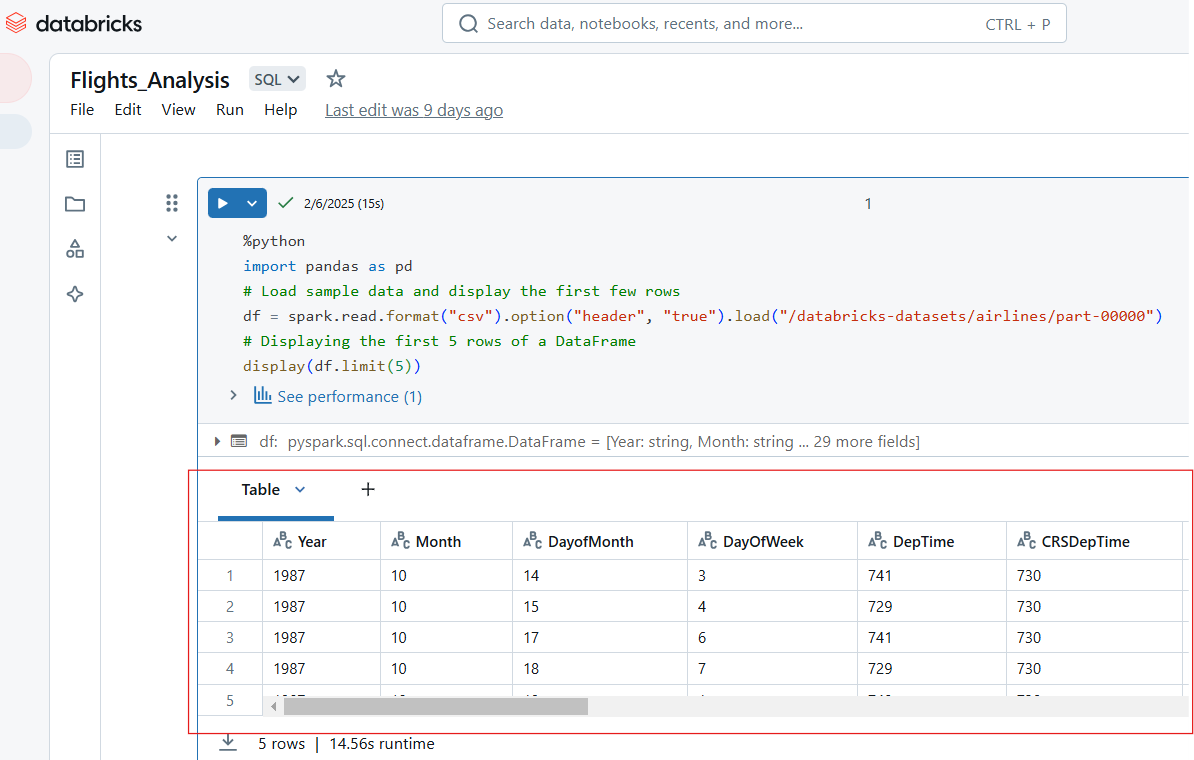
Visualiza las entradas en el Cuaderno Databricks. Imagen del autor.
También podemos utilizar los Cuadernos de Databricks para visualizar la salida de las celdas. Por ejemplo, el siguiente código Python selecciona las 10 compañías aéreas más frecuentes, convierte los datos de PySpark a Pandas y, a continuación, utiliza Matplotlib para crear un gráfico de barras.
%python
# Import necessary libraries
import matplotlib.pyplot as plt
import pandas as pd
# Load the dataset using PySpark
df = spark.read.option("header", "true").csv("/databricks-datasets/airlines/part-00000")
# Select the top 10 most frequent airlines (carrier column)
top_airlines = df.groupBy("UniqueCarrier").count().orderBy("count", ascending=False).limit(10)
# Convert PySpark DataFrame to Pandas DataFrame
pd_df = top_airlines.toPandas()
# Convert count column to integer (since it's a string in CSV)
pd_df["count"] = pd_df["count"].astype(int)
# Plot a bar chart
plt.figure(figsize=(10, 6))
plt.bar(pd_df["UniqueCarrier"], pd_df["count"], color="#ac4ce4")
# Add titles and labels
plt.xlabel("Airline Carrier", fontsize=12)
plt.ylabel("Flight Count", fontsize=12)
plt.title("Top 10 Most Frequent Airline Carriers", fontsize=14)
plt.xticks(rotation=45) # Rotate x-axis labels for better readability
# Show the plot
plt.show()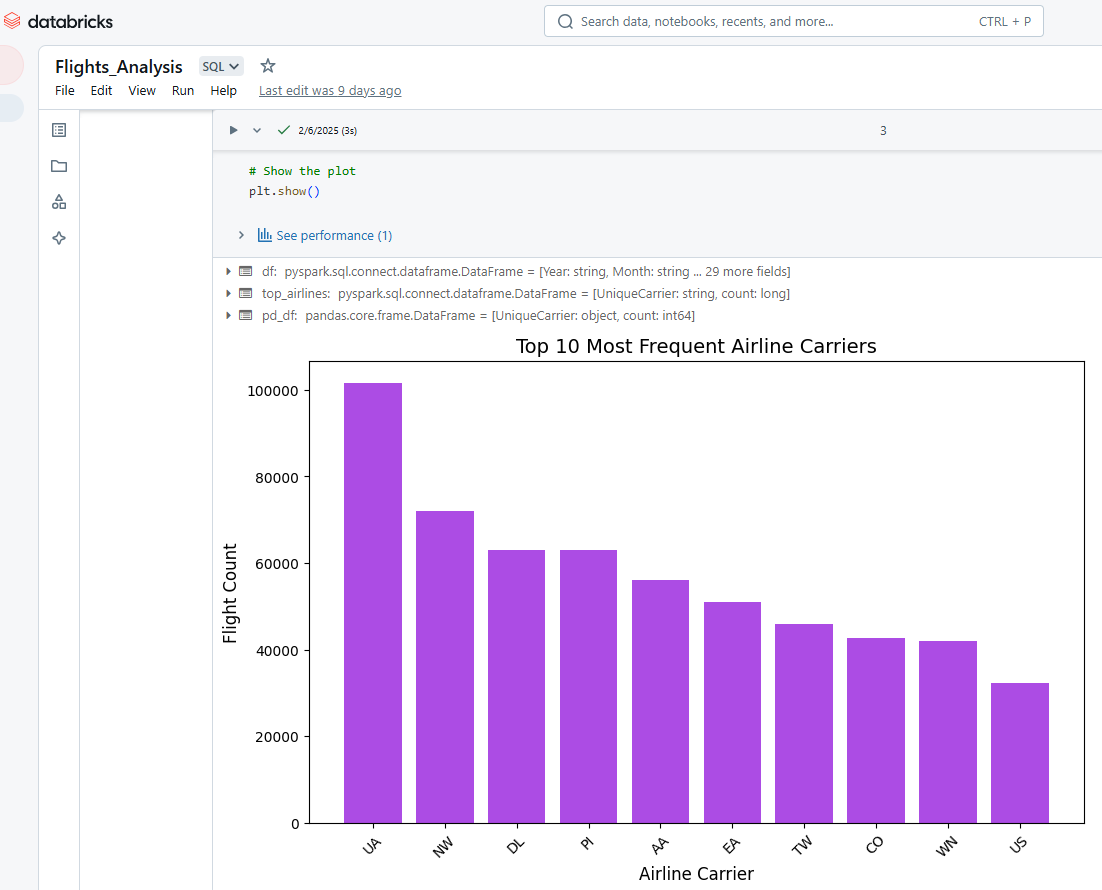
Visualizar los resultados en el Cuaderno Databricks. Imagen del autor.
Del mismo modo, puedes mostrar varias salidas de la ejecución de una única celda en el Cuaderno de Databricks. Por ejemplo, la salida del código siguiente mostrará las 5 primeras filas del conjunto de datos de aerolíneas y el recuento de las 10 aerolíneas más frecuentes.
%python
# Show the top 5 rows in an interactive table
display(df.limit(5))
# Show the top 10 most frequent airline carriers
top_carriers = df.groupBy("UniqueCarrier").count().orderBy("count", ascending=False).limit(10)
display(top_carriers)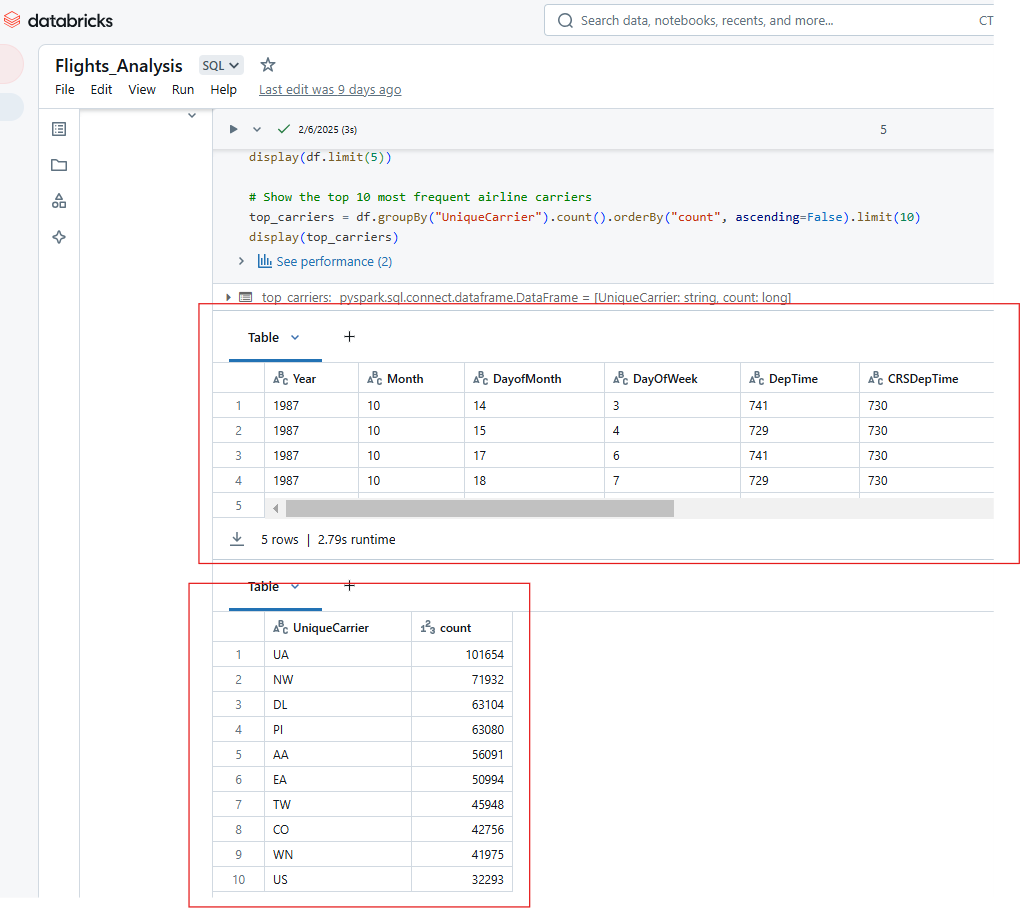
Visualización de varias salidas a partir de la ejecución de una única celda en el Cuaderno Databricks. Imagen del autor.
Los Cuadernos de Databricks ofrecen potentes capacidades de automatización, versionado e integración que mejoran la productividad, la colaboración y la eficacia operativa. En esta sección, exploraré las principales funciones avanzadas y las mejores prácticas para maximizar el potencial de los Cuadernos de Databricks.
Databricks permite a los usuarios automatizar la ejecución de cuadernos programándolos como trabajos y parametrizando las entradas para una ejecución dinámica.
Los usuarios pueden programar cuadernos para que se ejecuten a intervalos especificados, garantizando flujos de trabajo automatizados para ETL, informes y formación de modelos. Sigue los siguientes pasos para programar un trabajo de bloc de notas:
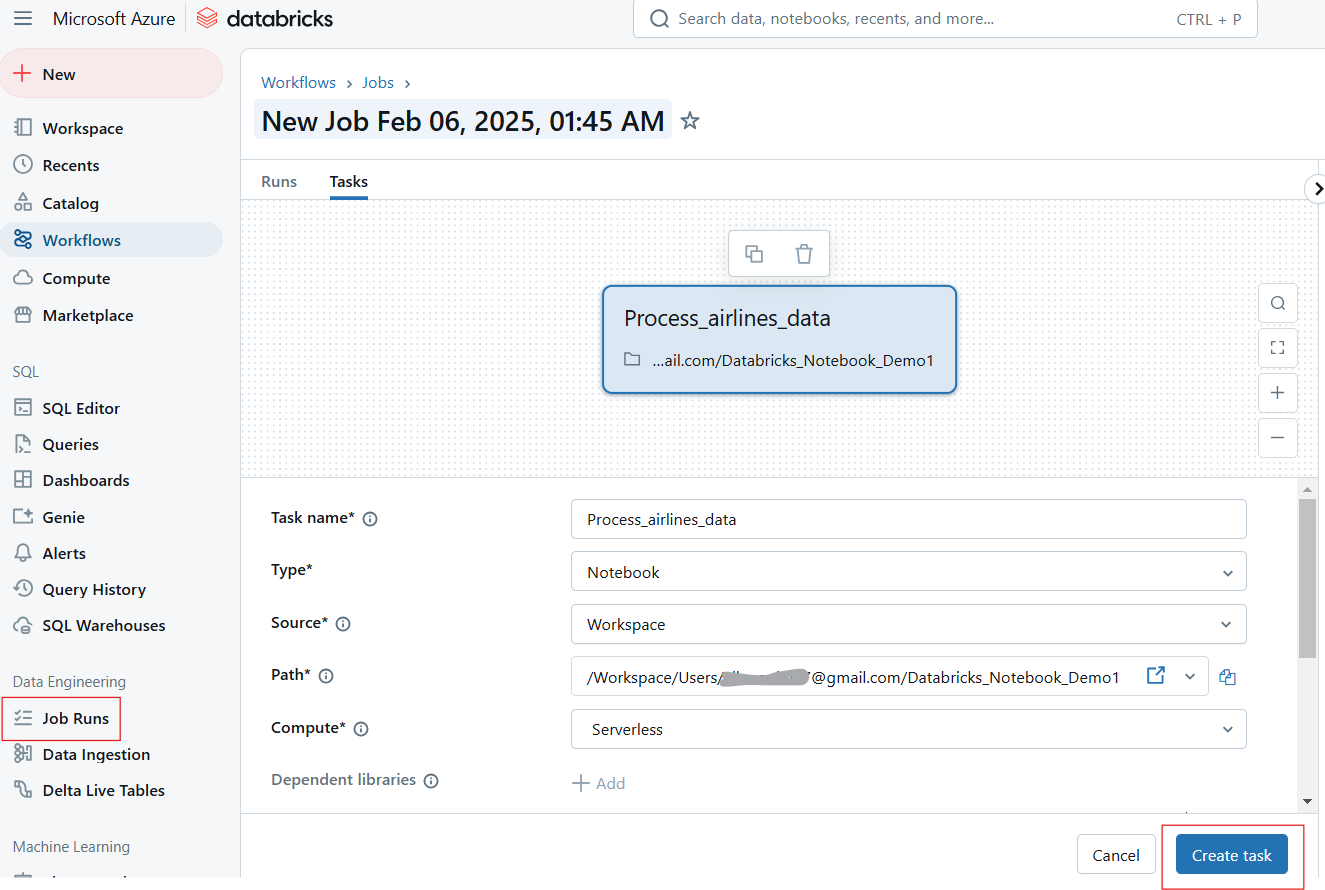
Crear Ejecución de Trabajo en Cuaderno Databricks. Imagen del autor.
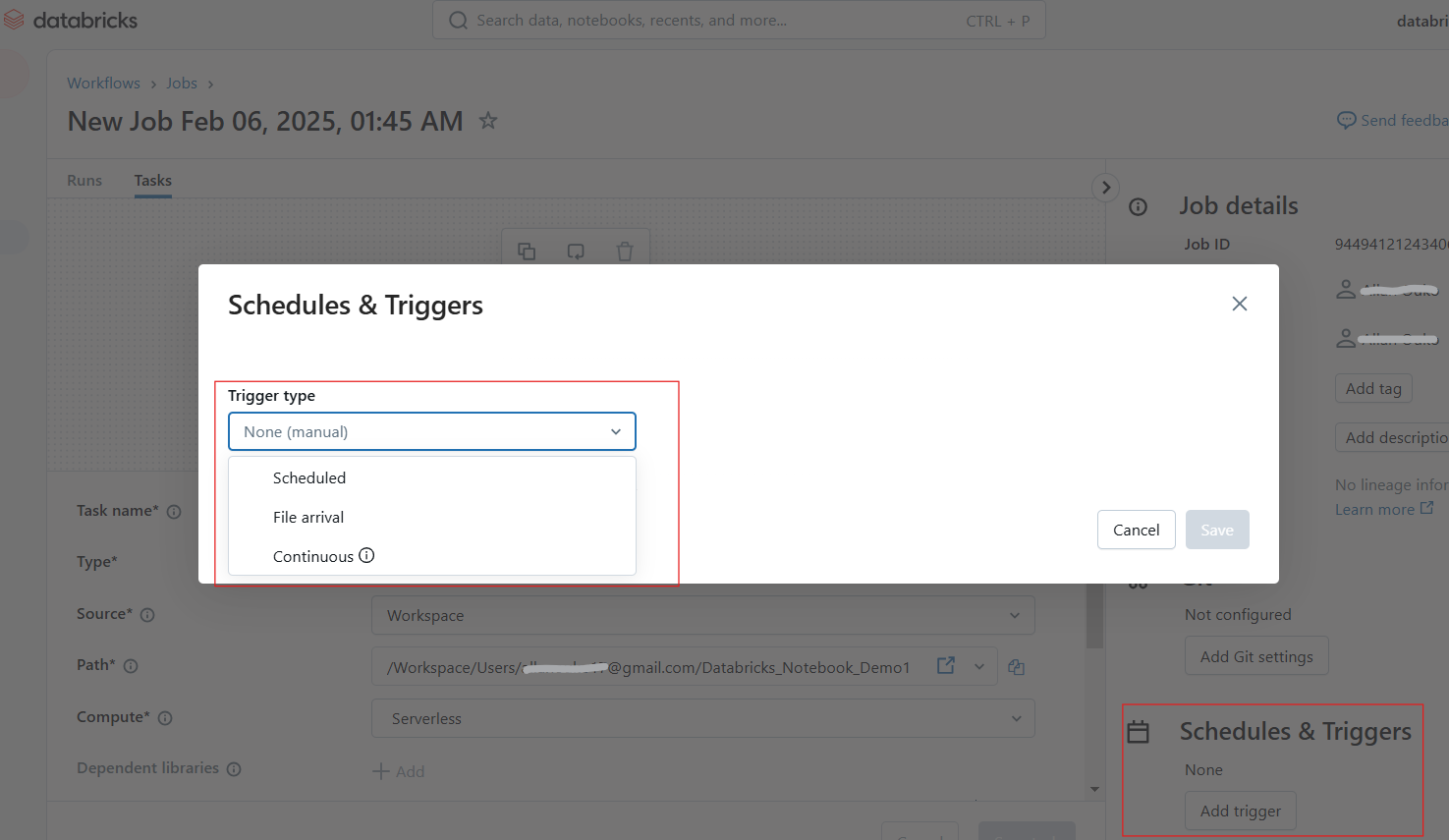
Configurar programaciones y disparadores en Databricks Notebook. Imagen del autor.
Ejecutar ejecuciones de trabajo en Databricks Notebook. Imagen del autor.
Los widgets de Databricks te permiten definir parámetros de forma dinámica, permitiendo que el mismo bloc de notas se ejecute con diferentes entradas. Por ejemplo, el siguiente widget dbutils.widgets.text() crea un widget de entrada de texto interactivo denominado "Introducir parámetro" con un valor por defecto de default_value. A continuación, recupera del widget el valor introducido por el usuario y lo imprime.
dbutils.widgets.text("input_param", "default_value", "Enter Parameter")
param_value = dbutils.widgets.get("input_param")
print(f"User Input: {param_value}")Del mismo modo, el código siguiente genera un menú desplegable etiquetado dataset con las opciones sales, marketing, y finance, por defecto sales. Recupera la opción seleccionada por el usuario e imprime el conjunto de datos elegido.
dbutils.widgets.dropdown("dataset", "sales", ["sales", "marketing", "finance"])
selected_dataset = dbutils.widgets.get("dataset")
print(f"Processing {selected_dataset} dataset")Databricks ofrece funciones integradas de versionado y colaboración, que facilitan el seguimiento de los cambios, la restauración de versiones anteriores y el trabajo con equipos en tiempo real.
Cada cambio en un cuaderno Databricks se versiona automáticamente. Puedes hacer lo siguiente para el historial de versiones:
Ver el historial de versiones en Databricks Notebook. Imagen del autor.
Los Cuadernos de Databricks permiten a los equipos ser coautores, comentar y compartir ideas mediante las siguientes funciones:
Los Cuadernos Databricks se integran con Delta Live Tables, MLflow, Almacenes SQL y pipelines CI/CD para ampliar la funcionalidad.
Delta Live Tables (DLT) simplifica la automatización de la canalización de datos con ETL declarativo. La siguiente consulta crea una Tubería de Tabla Delta Live en SQL.
-- Creating a live table called 'sales_cleaned' that stores cleaned data
CREATE LIVE TABLE sales_cleaned AS
-- Selecting all columns where the 'order_status' is 'completed'
SELECT *
FROM raw_sales
WHERE order_status = 'completed'; MLflow, integrado con Databricks, permite hacer un seguimiento de los experimentos de aprendizaje automático. Por ejemplo, el código siguiente registra la tasa de aprendizaje y la precisión de un modelo de aprendizaje automático en MLflow como parte de un experimento rastreado. Tras el registro, finaliza la sesión del experimento. Esto te permite hacer un seguimiento de los hiperparámetros y del rendimiento del modelo a lo largo del tiempo y comparar distintas ejecuciones.
# Import the MLflow library for experiment tracking
import mlflow
mlflow.start_run()
mlflow.log_param("learning_rate", 0.01)
mlflow.log_metric("accuracy", 0.95)
mlflow.end_run()Los Cuadernos de Databricks pueden exportarse en varios formatos, incluidos los siguientes:
.html: Compartir informes de sólo lectura.
.ipynb: Convertir a Jupyter Notebooks.
.dbc: Archivo Databricks para portabilidad.
Por ejemplo, puedes exportar un bloc de notas a través de la CLI utilizando el siguiente comando.
databricks workspace export /Users/my_notebook /local/path/my_notebook.ipynbLos Cuadernos Databricks ofrecen una serie de potentes funciones para agilizar los flujos de trabajo, aumentar la productividad y mejorar la colaboración. En esta sección, te mostraré comandos mágicos, mejoras de la interfaz de usuario, técnicas de exploración de datos y estrategias de gestión de código que me han resultado útiles al navegar por la plataforma de Cuadernos de Databricks.
Databricks proporciona comandos mágicos que simplifican tareas, como ejecutar guiones, gestionar archivos e instalar paquetes.
Para ejecutar otro cuaderno dentro del actual para modularizar los flujos de trabajo, puedes utilizar el comando %run. También puedes utilizar %run para dividir grandes proyectos en cuadernos reutilizables. Por ejemplo, el siguiente comando ejecuta el cuaderno data_preprocessing para que las variables, funciones y salidas estén disponibles en el cuaderno actual.
%run /Users/john.doe/notebooks/data_preprocessingEl comando %sh te permite ejecutar comandos del shell de Linux directamente en un bloc de notas. En el ejemplo siguiente, el comando mostrará el contenido de /dbfs/data/ DBFS.
%sh ls -lh /dbfs/data/Del mismo modo, el comando %fs te permite interactuar con el Sistema de Archivos Databricks (DBFS) para realizar operaciones con archivos. Por ejemplo, el comando siguiente enumera todos los archivos y directorios dentro de /databricks-datasets/, que contiene conjuntos de datos públicos proporcionados por Databricks.
%fs ls /databricks-datasets/Del mismo modo, puedes utilizar %fs cp para copiar archivos, %fs rm para eliminarlos y %fs head para previsualizarlos.
El comando %pip instala paquetes de Python en el entorno del bloc de notas. El siguiente comando instalará el paquete matplotlib en la sesión actual del bloc de notas.
%pip install pandas matplotlibEl comando %pip freeze se utiliza para listar los paquetes instalados y garantizar la reproducibilidad.
Databricks ha introducido las siguientes mejoras en la interfaz de usuario que mejoran la navegación, la depuración y la experiencia general del usuario:
Siempre recomiendo activar el Modo Enfoque(Ver → Modo Enfoque ) para minimizar las distracciones.
Databricks proporciona herramientas integradas para explorar conjuntos de datos, comprender esquemas y crear perfiles de datos directamente dentro de los cuadernos.
Para examinar conjuntos de datos en DBFS, utiliza %fs ls o display(dbutils.fs.ls()) para inspeccionar los conjuntos de datos disponibles.
display(dbutils.fs.ls("/databricks-datasets/"))También puedes explorar esquemas de tablas directamente en la barra lateral de la interfaz de usuario siguiendo los pasos que se indican a continuación:
Para perfilar los datos, puedes resumirlos utilizando display() o consultas SQL.
df.describe().show()%sql
SELECT COUNT(*), AVG(salary), MAX(age) FROM employees;Utiliza las siguientes técnicas para gestionar tu código en los Cuadernos de Databricks. Por un lado, asegúrate de almacenar fragmentos de código reutilizables en cuadernos separados y llámalos utilizando %run. Utiliza también las Utilidades Databricks (dbutils) para la transformación. Además, para facilitar la lectura, es una buena idea seguir las mejores prácticas PEP 8 (Python) o SQL. Utiliza siempre celdas markdown para los comentarios.
-- Select customer_id and calculate total revenue per customer
SELECT customer_id, SUM(total_amount) AS revenue
FROM sales_data
-- Group results by customer to get total revenue per customer
GROUP BY customer_id
-- Order customers by revenue in descending order (highest first)
ORDER BY revenue DESC
-- Return only the top 10 customers by revenue
LIMIT 10;Si te encuentras con problemas al trabajar con los Cuadernos de Databricks, puedes solucionarlos utilizando los métodos siguientes:
¿Cúmulo atascado? Reinicia el núcleo(Ejecutar → Borrar estado y reiniciar).
¿Lenta ejecución? Comprueba si hay cuellos de botella en Spark UI(Cluster → Spark UI).
¿Conflictos de versión? Utiliza %pip list para comprobar las dependencias.
Utiliza los siguientes atajos de teclado para una codificación más rápida:
Los cuadernos Databricks se utilizan ampliamente en ingeniería de datos, aprendizaje automático e inteligencia empresarial. En esta sección, destacaré casos prácticos del mundo real y fragmentos de código para ilustrar cómo aprovechan los equipos los Cuadernos de Databricks para los flujos de trabajo de producción.
Considera un escenario en el que una empresa minorista ingiere datos de ventas sin procesar, los limpia y los almacena en un Delta Lake para la elaboración de informes. El proceso será el siguiente:
Este proceso mejorará la fiabilidad de los datos y el rendimiento de las consultas para la elaboración de informes. El fragmento de código siguiente es un ejemplo de cómo aplicar la solución anterior:
# Read raw sales data from cloud storage
df = spark.read.format("csv").option("header", "true").load("s3://sales-data/raw/")
# Data cleaning and transformation
df_cleaned = df.filter(df["status"] == "completed").dropDuplicates()
# Save to Delta Table for analysis
df_cleaned.write.format("delta").mode("overwrite").saveAsTable("sales_cleaned")Considera otro escenario en el que una institución financiera predice los impagos de préstamos utilizando un modelo de aprendizaje automático. Para implementar este flujo de trabajo en Databricks Notebook, seguirás los pasos que se indican a continuación. Dará lugar a un seguimiento y despliegue automatizados del modelo con MLflow.
# import libraries
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import mlflow
# Load and prepare data
df = spark.read.table("loan_data").toPandas()
X_train, X_test, y_train, y_test = train_test_split(df.drop("default", axis=1), df["default"])
# Train model
model = LogisticRegression()
model.fit(X_train, y_train)
# Log model in MLflow
mlflow.sklearn.log_model(model, "loan_default_model")En un escenario en el que un equipo de marketing analiza las tendencias de captación de clientes, aplicarás la solución en los siguientes pasos:
El proceso conducirá a una toma de decisiones más rápida con cuadros de mando interactivos.
%sql
-- Count the number of interactions per customer segment
SELECT customer_segment, COUNT(*) AS interactions
FROM user_activity
-- Group by customer segment to aggregate interaction counts
GROUP BY customer_segment
-- Order results by interaction count in descending order
ORDER BY interactions DESC;Si necesitas refrescar tus conocimientos sobre SQL de Databricks, te recomiendo que leas nuestro tutorial sobre SQL de Databricks para aprender a configurar SQL Warehouse desde la interfaz web de Databricks.
Cuando se ejecutan cuadernos Databricks simultáneamente, la depuración y el mantenimiento del rendimiento pueden presentar retos únicos. Aquí tienes algunas ideas que te ayudarán a mantener tu cuaderno libre de errores en entornos de producción.
Aquí tienes algunos problemas y soluciones recomendadas:
Un cuaderno que funciona bien individualmente falla cuando varios usuarios o trabajos lo ejecutan simultáneamente: Este problema puede deberse a variables compartidas. Además, un único clúster puede no admitir ejecuciones múltiples. Para resolver este problema, utiliza widgets para la parametrización o utiliza el autoescalado de clústeres para asegurarte de que tienes suficientes recursos para las ejecuciones concurrentes.
Un portátil que antes funcionaba rápido ahora tarda bastante más: El problema podría deberse a transformaciones Spark ineficaces que causan problemas de barajado o a demasiadas cachés/conjuntos de datos persistentes que consumen memoria. Para resolver este problema, realiza operaciones utilizando .persist() y .unpersist(). Además, supervisa la interfaz de usuario de Spark en busca de particiones sesgadas y optimiza las consultas con tablas Delta.
%run falla al intentar ejecutar otro cuaderno: Esto puede ocurrir si la ruta de la libreta es incorrecta o la libreta referenciada depende de un cluster no disponible. Para solucionar este problema, utiliza rutas absolutas para las importaciones de Libretas o comprueba la disponibilidad del clúster para asegurarte de que las libretas referenciadas utilizan un clúster compatible.
Falla un trabajo de bloc de notas programado: Esto puede ocurrir si el clúster se terminó antes de la ejecución o si falló una dependencia externa, como una conexión a la base de datos o una llamada a la API. Para resolver este problema, activa el reinicio del clúster en caso de fallo. En la configuración del trabajo, activa Reintentar en casode fallo . Utiliza también Bloques Try-Except para las llamadas externas.
Lee nuestro tutorial Dominar la API de Databricks para aprender a utilizar la API REST de Databricks para programar trabajos y escalar canalizaciones automatizadas.
Utiliza las siguientes técnicas para mantener los Cuadernos Databricks cuando estén en producción:
Modular el código en cuadernos reutilizables: Divide los cuadernos grandes en unidades más pequeñas y reutilizables y utiliza %run para llamarlas. Almacena las funciones de ayuda en cuadernos de utilidades separados.
Utiliza el control de versiones (integración con Git): Activa Databricks Repos para realizar un seguimiento de los cambios y revertir versiones.
Optimizar la selección de clústeres para los trabajos: Utiliza clusters de trabajos en lugar de clusters interactivos para las ejecuciones programadas.
Implementa el registro y las alertas: Utiliza dbutils.notebook.exit() para registrar el estado del trabajo. También puedes configurar alertas por correo electrónico en la interfaz de Jobs para notificar los fallos a los equipos.
Documenta el código y utiliza Markdown para mayor claridad: Utiliza celdas de marcado para describir los pasos y la lógica del flujo de trabajo.
Si quieres explorar los conceptos fundamentales de Databricks, te recomiendo encarecidamente que sigas nuestro curso Introducción a Databricks. Este curso establece la comprensión adecuada que necesitas para luego experimentar con funciones avanzadas como comandos mágicos, parametrización y optimizaciones del rendimiento. Como última cosa, también creo que deberías aprender a obtener una Certificación Databricks. Nuestro post te ayuda a explorar las ventajas profesionales y a elegir la certificación adecuada para tus objetivos profesionales.
Aprende Databricks con DataCamp
Curso
Curso
Curso
blog
Gus Frazer
14 min
Tutorial
Adam Shafi
Tutorial
Maarten Van den Broeck
Tutorial
Anneleen Rummens
Tutorial
Joleen Bothma
