
Kurs
Databricks-Konzepte
4 Std.
22.1K
Databricks dient als einheitliche Analyseplattform, die die Integration von Data Engineering, maschinellem Lernen und Business Analytics ermöglicht. Das Herzstück dieses Ökosystems sind Databricks Notebooks, interaktive Arbeitsbereiche für die Datenexploration, Modellentwicklung und Produktionsworkflows.
In diesem Artikel zeige ich dir, wie du mit Databrick Notebooks loslegen kannst. Wenn du ein absoluter Neuling bist, solltest du dich zunächst für unseren Kurs Einführung in Databricks anmelden, damit du weißt, was Databricks ist und wie es die Datenarchitektur modernisiert. Unser Kurs ist sehr gründlich und lehrt viele Dinge, einschließlich Katalogmanagement und Dateneingabe, also probiere es aus.
Databricks Notebooks sind interaktive, cloudbasierte Arbeitsumgebungen, die es Nutzern ermöglichen, Datenexploration, Engineering, maschinelles Lernen und Analysen in einer kollaborativen Umgebung durchzuführen. Sie verwenden ein zellenbasiertes Ausführungsmodell, bei dem die Nutzer/innen Code in einzelnen Blöcken oder Zellen schreiben und ausführen können.
Databricks Notebooks unterstützt mehrere Sprachen, sodass du nicht nur deine Lieblingssprache auswählen, sondern auch innerhalb desselben Notizbuchs zwischen den Sprachen wechseln kannst. Zu den Sprachen gehören Python, SQL, Scala und R, für die wir alle Einführungskurse anbieten.
Um die mehrsprachige Interoperabilität zu erleichtern, bietet Databricks sogenannte magische Befehle:
%python: Führt eine Zelle mit Python aus.
%sql: Führt SQL-Abfragen aus.
%scala: Verarbeitet Scala-basierte Befehle.
%r: Führt R-Code aus.
Databricks Notebooks gehen über herkömmliche Codierungsumgebungen hinaus, indem sie die folgenden Hauptfunktionen bieten:
Es ist eine Sache, über die Funktionen zu lesen, aber es ist eine andere Sache, sie mit eigenen Augen zu sehen. Der beste Weg, um Databricks zu schätzen, ist, wenn du selbst anfängst, Dinge zu tun. In diesem Abschnitt helfe ich dir dabei, Notizbücher im Databricks-Arbeitsbereich zu erstellen, zu verwalten und zu navigieren. Dann wirst du sicher selbst sehen, wie nützlich es ist.
Im Databricks-Arbeitsbereich kannst du neue Notizbücher erstellen oder bestehende Notizbücher verwalten. Im Folgenden wollen wir uns diese Methoden ansehen.
Um ein neues Notizbuch in Databricks zu erstellen:
Databricks Arbeitsbereich. Bild vom Autor.
Databricks Notebook erstellen. Bild vom Autor.
Wähle den Namen und die Standardsprache für Databricks Notebook. Bild vom Autor.
Mit Databricks kannst du Notizbücher aus verschiedenen Quellen importieren, z.B. aus GitHub und Git Repositories, externen URLs oder lokalen Dateien, die als .dbc (Databricks-Archiv) oder .ipynb (Jupyter) hochgeladen werden.
Befolge die folgenden Schritte, um bestehende Notizbücher in Databricks Workspace zu importieren:
Importiere ein bestehendes Notizbuch in Databricks Arbeitsbereich. Bild vom Autor.
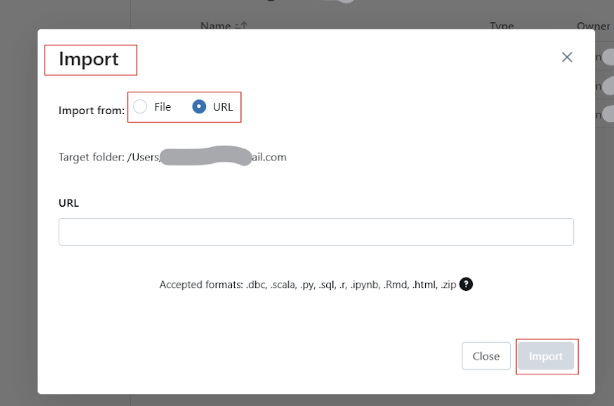
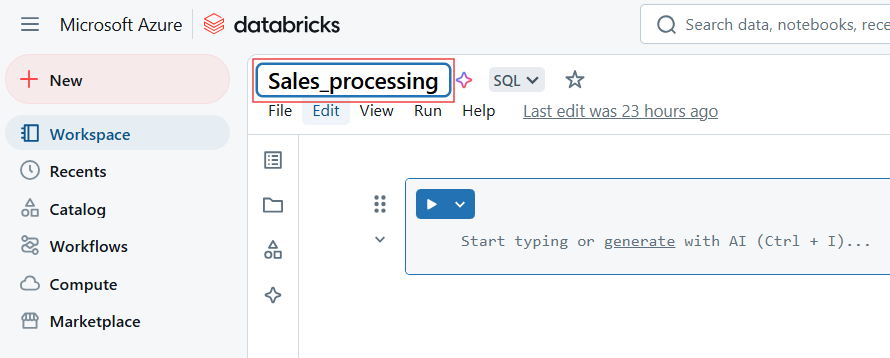
Um Databricks Notizbuch umzubenennen, klicke auf den Titel des Notizbuchs und bearbeite den Namen.
Du kannst die Notizbücher auch in Ordner verschieben, um sie besser zu strukturieren.
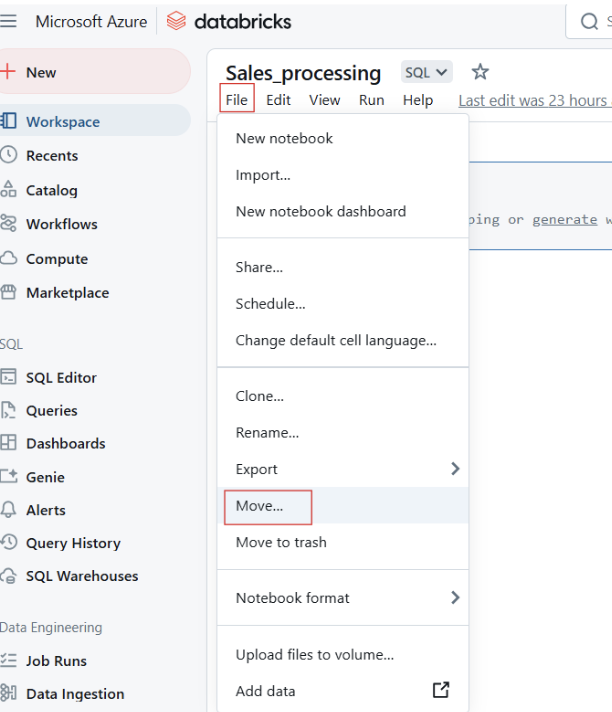
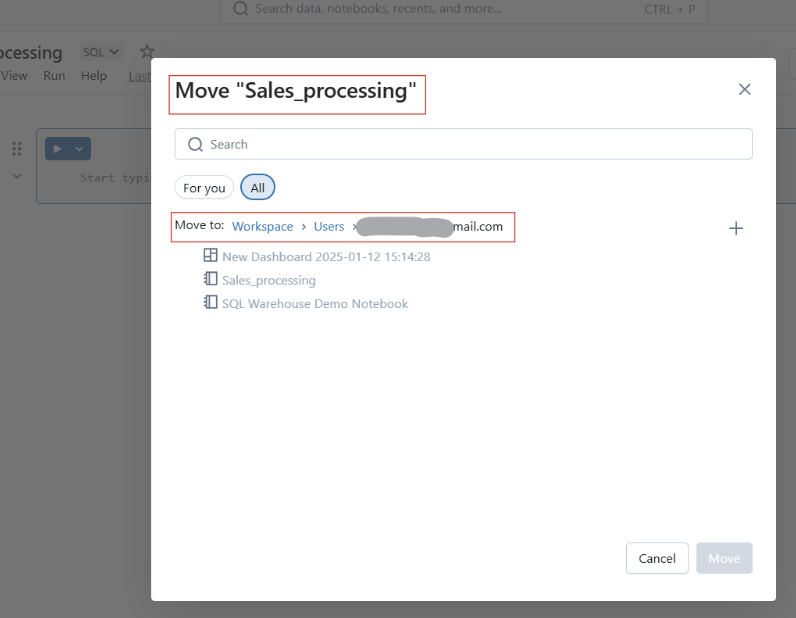
Databricks Notebooks in einen Ordner verschieben. Bild vom Autor.
Bevor du dein Datbricks-Notizbuch freigibst, kannst du den Zugriff und die Berechtigungen verwalten, um zu kontrollieren, wer das Notizbuch ansehen, bearbeiten oder verwalten kann.
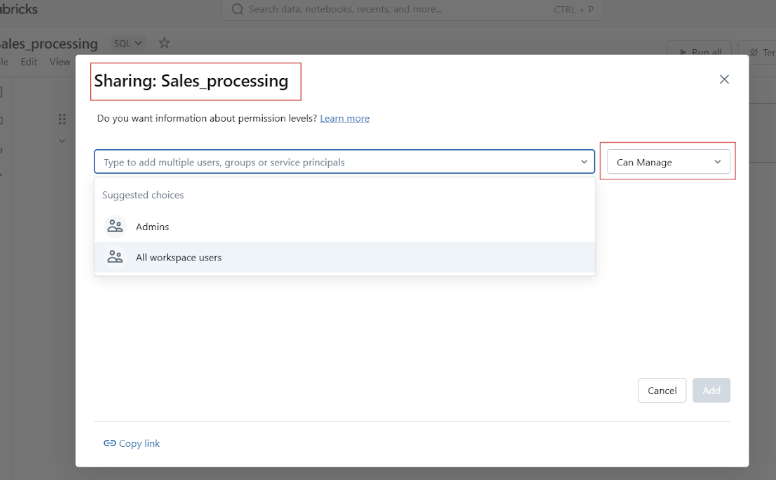
Bevor wir zu den praktischen Beispielen für die Verwendung von Databricks Notebooks kommen, möchte ich dir die Benutzeroberfläche und die Navigation der Plattform vorstellen.
Die Symbolleiste von Databricks Notebook bietet schnellen Zugriff auf die folgenden Aktionen:
Ausführen, Bearbeiten, Löschen oder Verschieben der Zelle.
Ändern von Zelltypen wie Code, Markdown, SQL oder Scala.
Magische Befehle wie %python oder %sql einstellen.
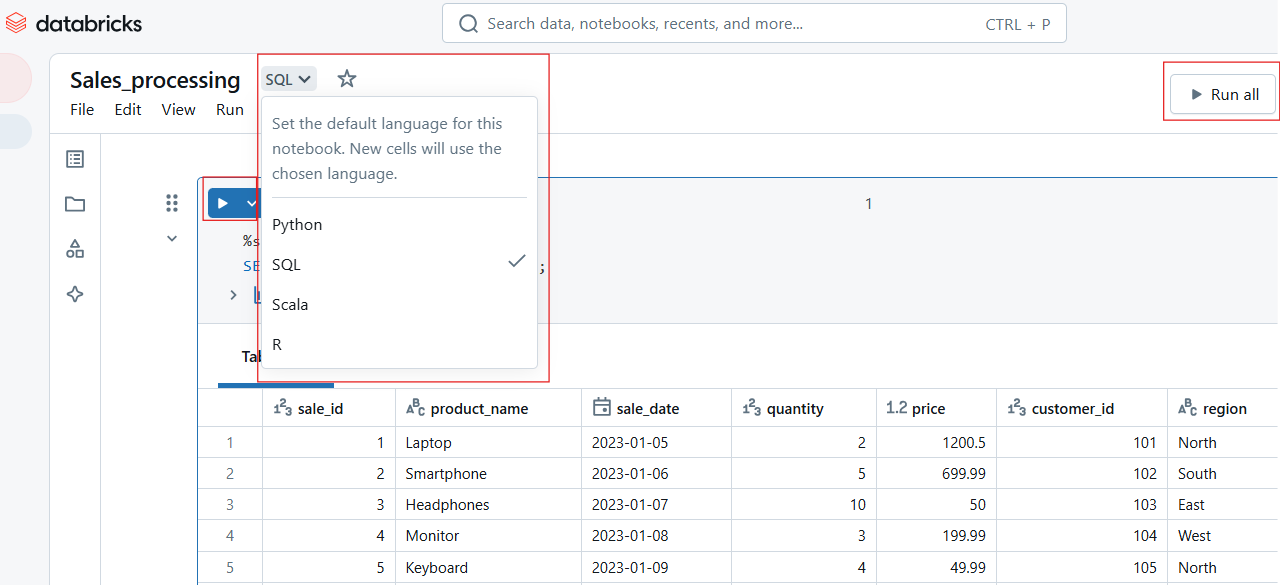
Ausführen einer Zelle in Databricks Notebook. Bild vom Autor.
Variablen und Ausführungsstatus in Databricks Notebook zurücksetzen. Bild vom Autor.
Kommentare in Databricks Notebook. Bild vom Autor.
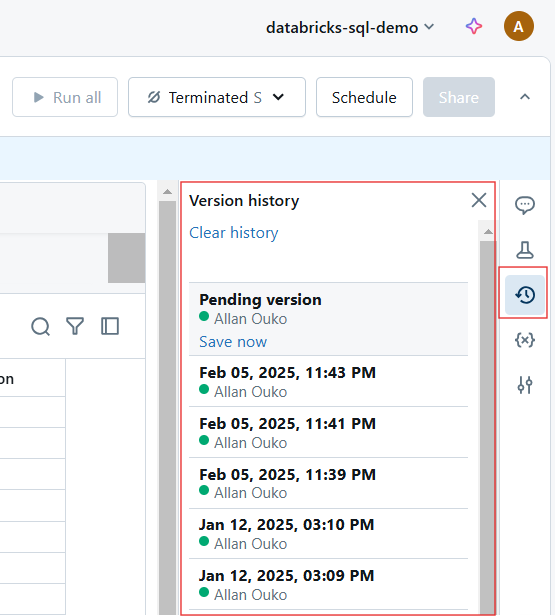
Versionsverlauf in Databricks Notebook. Bild vom Autor.
Databricks hat mehrere Verbesserungen an der Benutzeroberfläche vorgenommen, um das Erlebnis noch intuitiver zu gestalten. Mit diesen Erweiterungen bieten Databricks Notebooks eine noch schlankere und leistungsfähigere Entwicklungsumgebung für Datenexperten. Sie umfassen die folgenden Punkte:
Databricks Notebooks bieten eine interaktive Programmierumgebung, in der Nutzer ihren Code schreiben, ausführen und dokumentieren können. In diesem Abschnitt gehe ich auf die Arbeit mit Codezellen, Markdown und die effiziente Ausführung von Code ein.
Databricks Notebooks unterstützen mehrere Sprachen, darunter Python, SQL, Scala und R, innerhalb desselben Notebooks.
Verwende den magischen Befehl %python, um Python-Code in einer Zelle in Databricks Notebook zu schreiben.
%python
import pandas as pd
# Load sample data and display the first few rows
df = spark.read.format("csv").option("header", "true").load("/databricks-datasets/airlines/part-00000")
pd_df = df.limit(5).toPandas() # Convert to Pandas DataFrame
display(pd_df) # Works in Databricks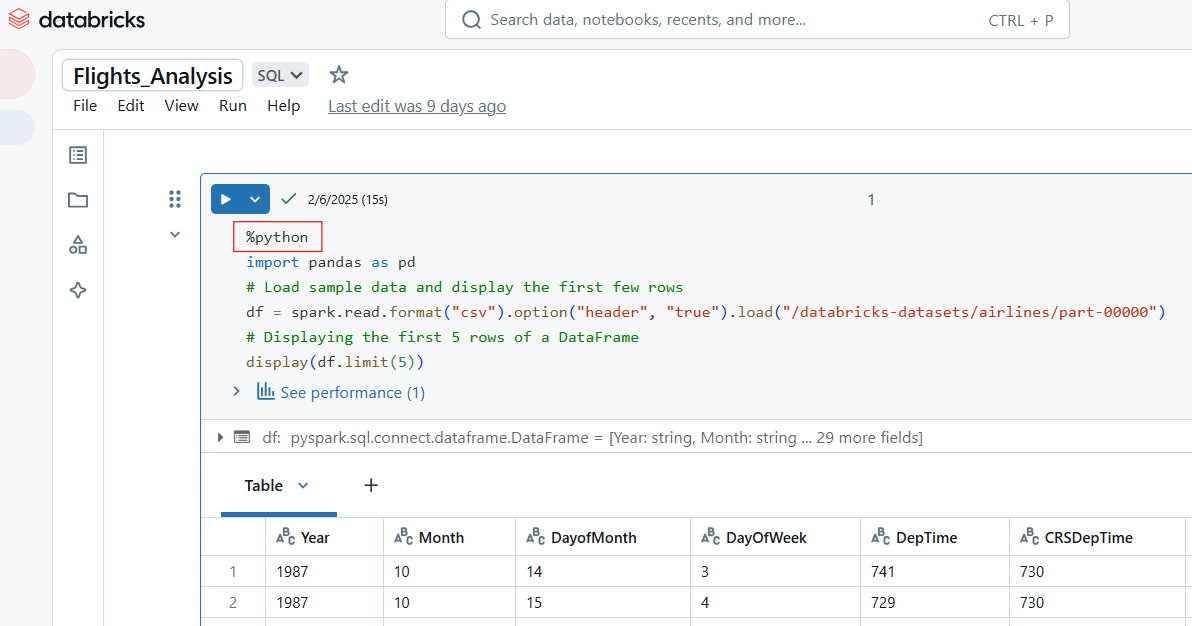
Beispiel für Python-Code in Databricks Notebook. Bild vom Autor.
Um SQL-Code in Databricks Notebook zu schreiben, verwendest du den magischen Befehl %sql. Wenn du SQL als Standardsprache des Notebooks eingestellt hast, kannst du die Zelle ausführen, ohne den Befehl %sql magic einzuschließen.
-- Querying a dataset in SQL
SELECT origin, dest, COUNT(*) AS flight_count
FROM flights_table
GROUP BY origin, dest
ORDER BY flight_count DESC
LIMIT 10;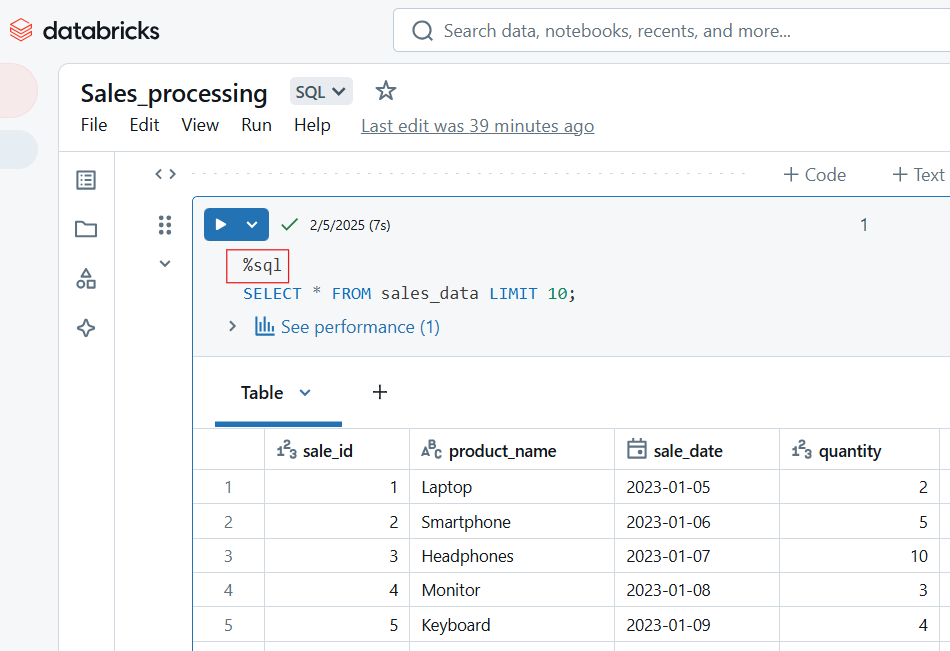
SQL-Code in Databricks Notebook. Bild vom Autor.
Verwende den magischen Befehl %scala, um Scala-Code in einer Zelle in Databricks Notebook zu schreiben.
%scala
// Reading and displaying data in Scala
val data = spark.read.option("header", "true").csv("/databricks-datasets/airlines/part-00000")
// Display as a table in Databricks
display(data)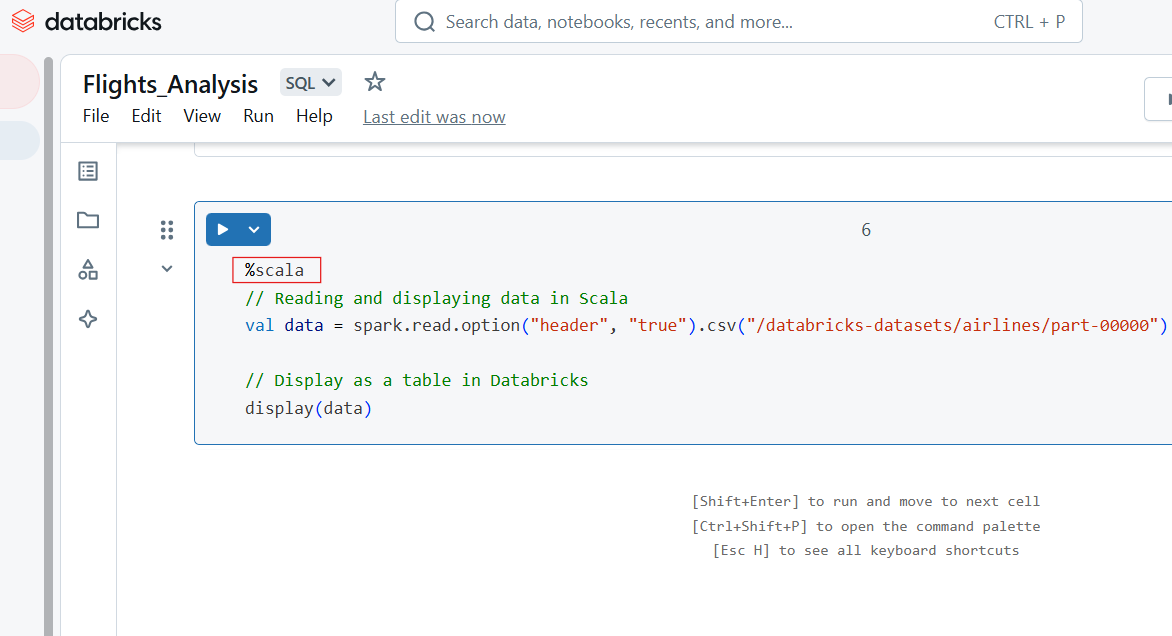
Scala-Code in Databricks Notebook. Bild vom Autor.
Du kannst auch R-Code in der Zelle von Databricks Notebook schreiben, indem du den Befehl %r magic verwendest.
%r
# Load a sample dataset in R
library(SparkR)
df <- read.df("/databricks-datasets/airlines/part-00000", source = "csv", header = "true")
head(df)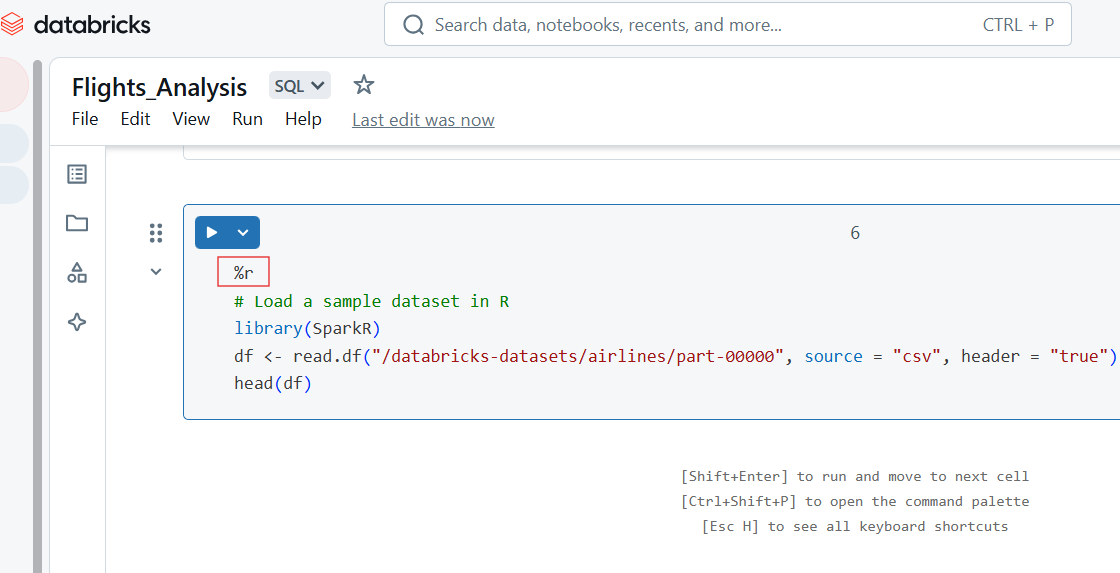
R-Code in Databricks Notebook. Bild vom Autor.
Markdown-Zellen werden zum Hinzufügen von Text, Überschriften, Listen und anderen Dokumenten verwendet. Das folgende Beispiel zeigt, wie du eine Markdown-Zelle schreibst und wie die Ergebnisse in Databricks Notebook angezeigt werden.
%md
# Data Exploration Notebook
This notebook explores airline flight data, providing insights into flight frequency and destinations.
## **Steps:**
1. Load and display the dataset
2. Query data using SQL
3. Generate visualizations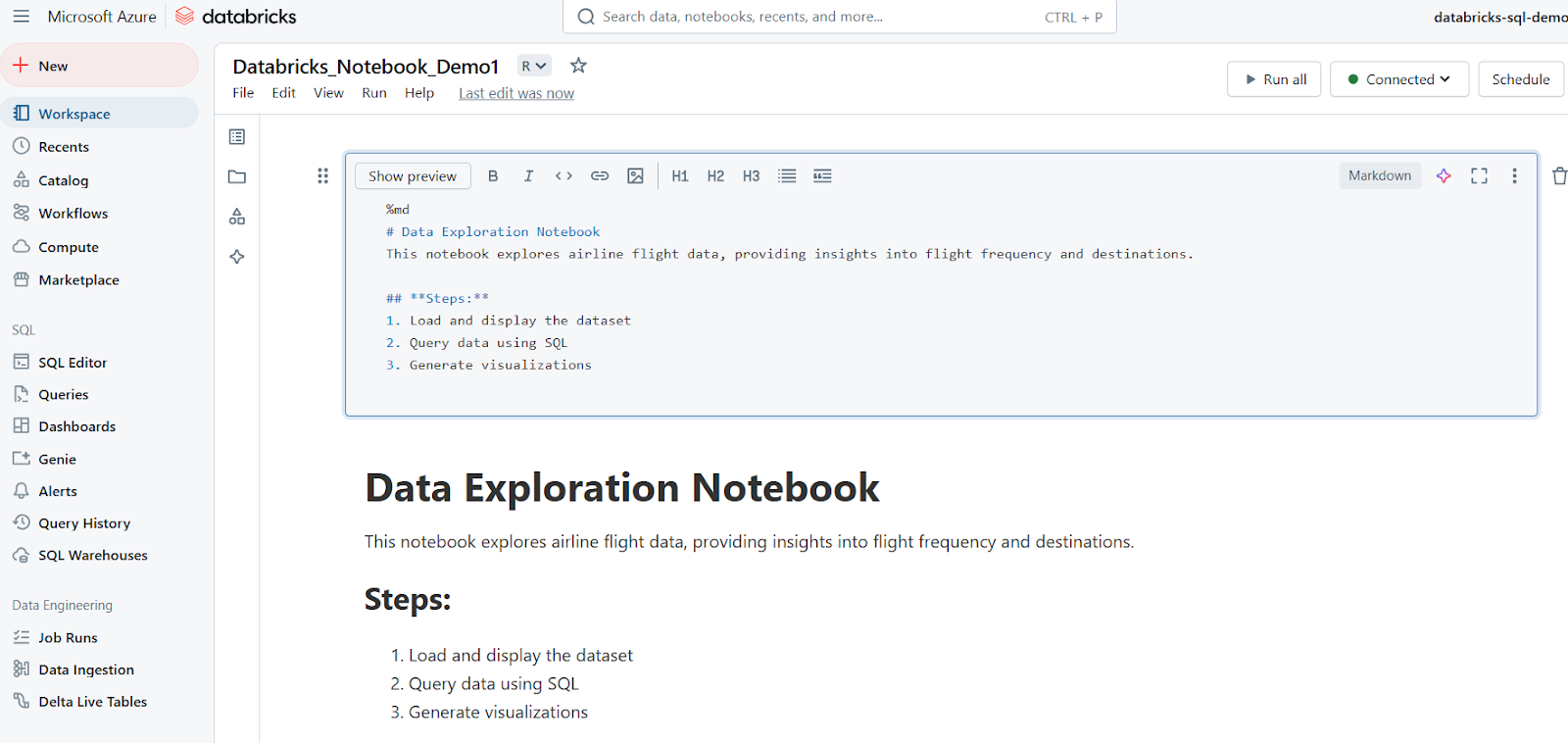
Databricks Notebooks ermöglichen die flexible Ausführung von Code durch Einzel- oder Batch-Zellenläufe.
Um eine einzelne Zelle auszuführen, klicke auf die Schaltfläche Ausführen (▶) in der Zelle oder verwende das Tastaturkürzel:
Um alle Zellen im Notizbuch auszuführen:
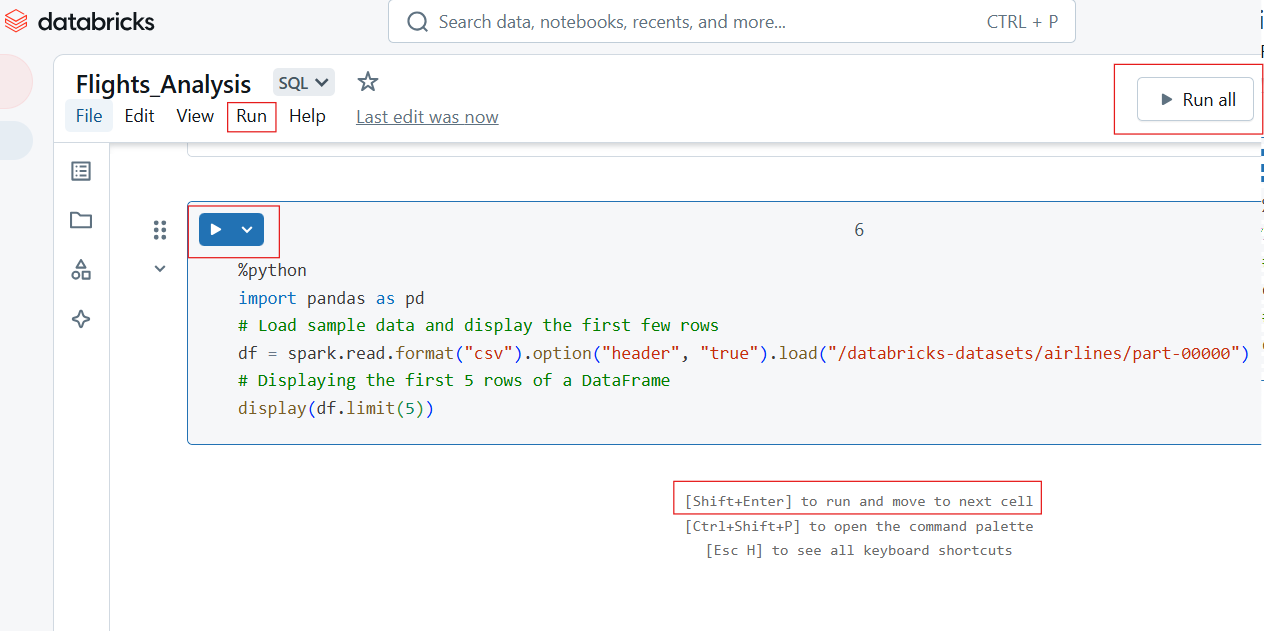
Ausführen von einzelnen und Ausführen aller Zellen in Databricks Notebook. Bild vom Autor.
Databricks Notebooks unterstützen mehrere Ausgabeformate, darunter Tabellen, Diagramme und Protokolle. Der folgende Python-Code zeigt zum Beispiel die ersten 5 Zeilen des Datensatzes "Fluggesellschaften" an.
%python
import pandas as pd
# Load sample data and display the first few rows
df = spark.read.format("csv").option("header", "true").load("/databricks-datasets/airlines/part-00000")
# Displaying the first 5 rows of a DataFrame
display(df.limit(5))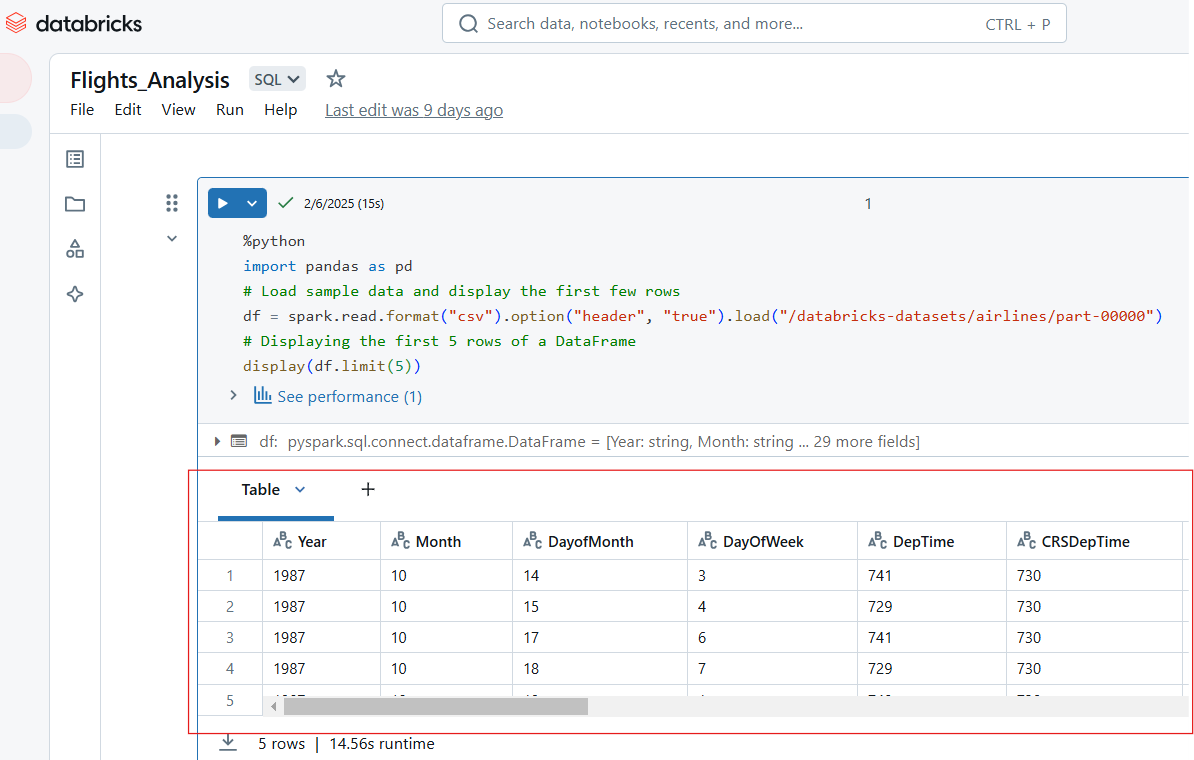
Zeige die Eingaben in Databricks Notebook an. Bild vom Autor.
Wir können auch Databricks Notebooks verwenden, um die Ausgabe der Zellen zu visualisieren. Der folgende Python-Code wählt zum Beispiel die 10 häufigsten Fluggesellschaften aus, konvertiert die Daten von PySpark nach Pandas und erstellt dann mit Matplotlib ein Balkendiagramm.
%python
# Import necessary libraries
import matplotlib.pyplot as plt
import pandas as pd
# Load the dataset using PySpark
df = spark.read.option("header", "true").csv("/databricks-datasets/airlines/part-00000")
# Select the top 10 most frequent airlines (carrier column)
top_airlines = df.groupBy("UniqueCarrier").count().orderBy("count", ascending=False).limit(10)
# Convert PySpark DataFrame to Pandas DataFrame
pd_df = top_airlines.toPandas()
# Convert count column to integer (since it's a string in CSV)
pd_df["count"] = pd_df["count"].astype(int)
# Plot a bar chart
plt.figure(figsize=(10, 6))
plt.bar(pd_df["UniqueCarrier"], pd_df["count"], color="#ac4ce4")
# Add titles and labels
plt.xlabel("Airline Carrier", fontsize=12)
plt.ylabel("Flight Count", fontsize=12)
plt.title("Top 10 Most Frequent Airline Carriers", fontsize=14)
plt.xticks(rotation=45) # Rotate x-axis labels for better readability
# Show the plot
plt.show()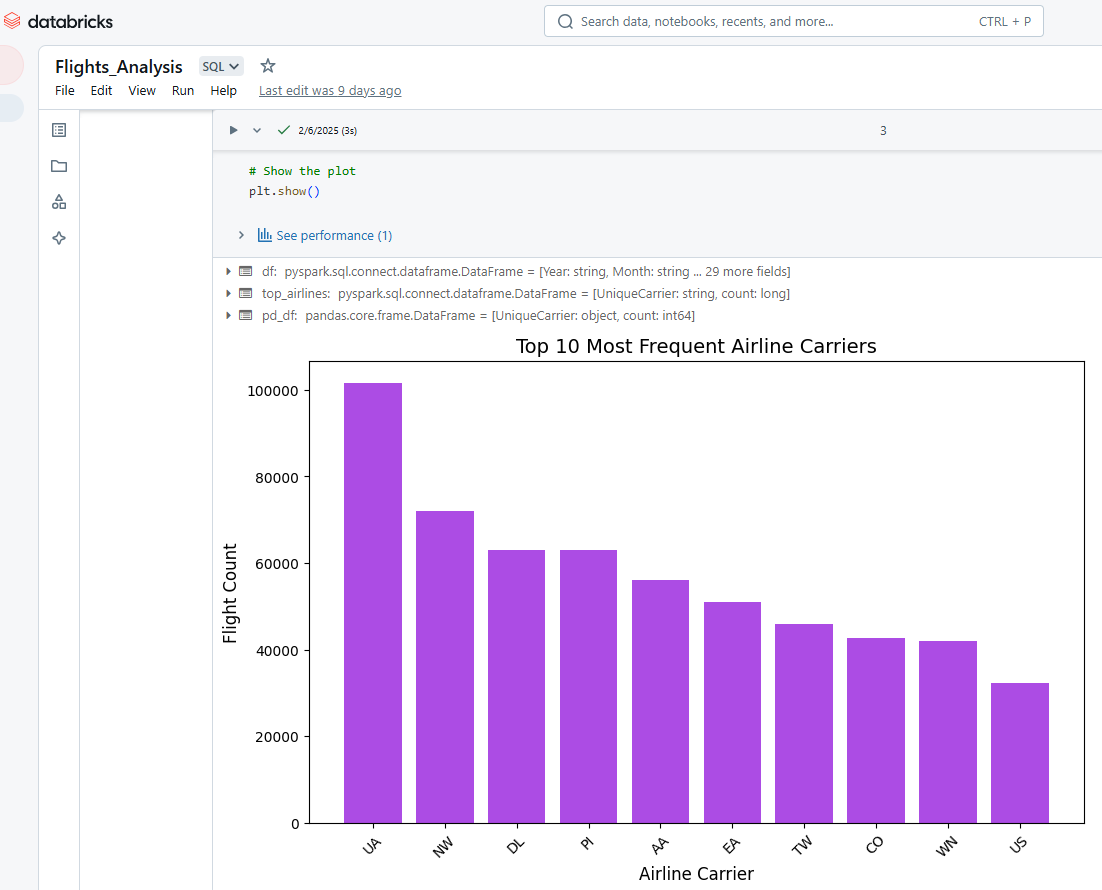
Visualisierung der Ergebnisse in Databricks Notebook. Bild vom Autor.
Auf ähnliche Weise kannst du mehrere Ausgaben aus der Ausführung einer einzelnen Zelle in Databricks Notebook anzeigen. Die Ausgabe des folgenden Codes zeigt zum Beispiel die ersten 5 Zeilen des Datensatzes Fluggesellschaften und die Anzahl der 10 häufigsten Fluggesellschaften.
%python
# Show the top 5 rows in an interactive table
display(df.limit(5))
# Show the top 10 most frequent airline carriers
top_carriers = df.groupBy("UniqueCarrier").count().orderBy("count", ascending=False).limit(10)
display(top_carriers)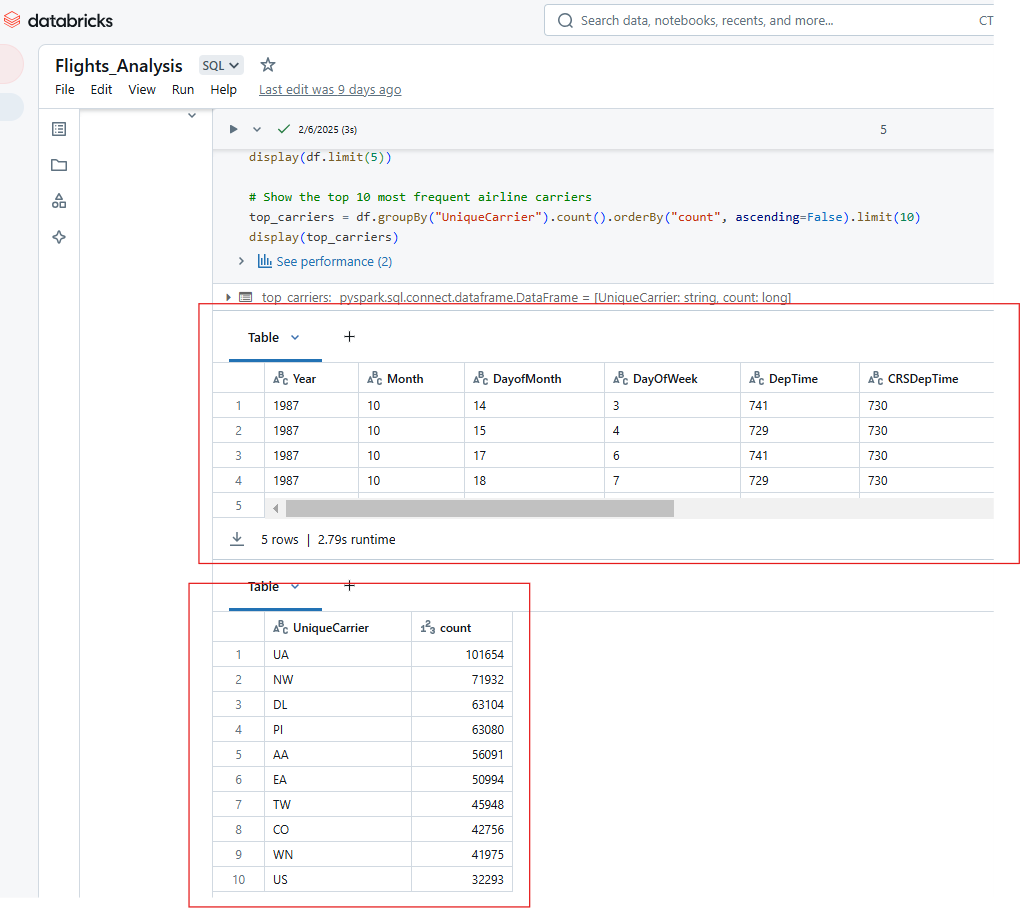
Anzeige von mehreren Ausgaben bei der Ausführung einer einzelnen Zelle in Databricks Notebook. Bild vom Autor.
Databricks Notebooks bieten leistungsstarke Funktionen zur Automatisierung, Versionierung und Integration, die die Produktivität, Zusammenarbeit und betriebliche Effizienz verbessern. In diesem Abschnitt gehe ich auf die wichtigsten fortgeschrittenen Funktionen und Best Practices ein, um das Potenzial von Databricks Notebooks zu maximieren.
Mit Databricks kannst du die Ausführung von Notebooks automatisieren, indem du sie als Jobs planst und die Eingaben für die dynamische Ausführung parametrierst.
Die Nutzer können die Ausführung von Notebooks in bestimmten Intervallen planen und so automatisierte Arbeitsabläufe für ETL, Berichte und Modellschulungen sicherstellen. Befolge die folgenden Schritte, um einen Notizbuchauftrag zu planen:
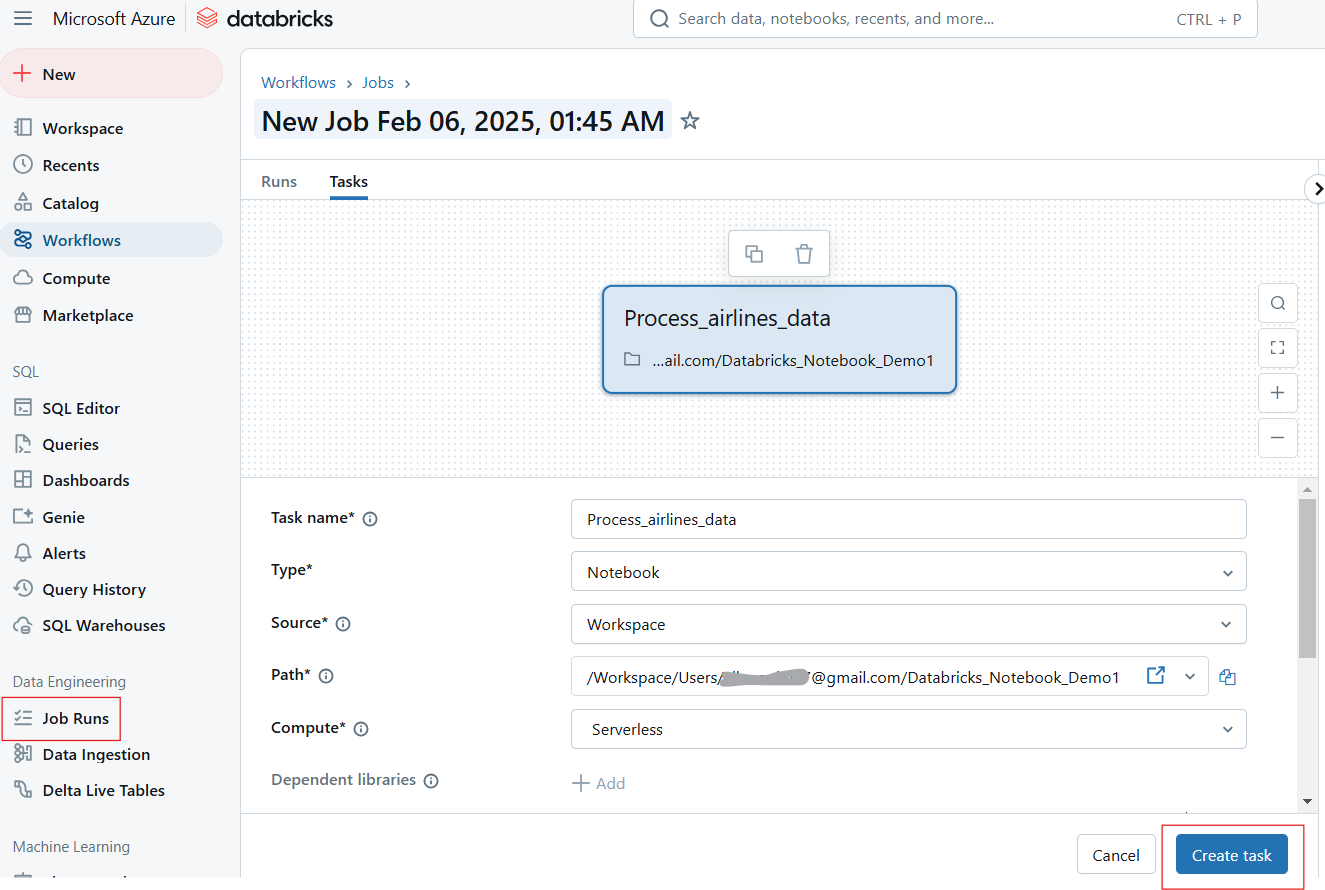
Joblauf in Databricks Notebook erstellen. Bild vom Autor.
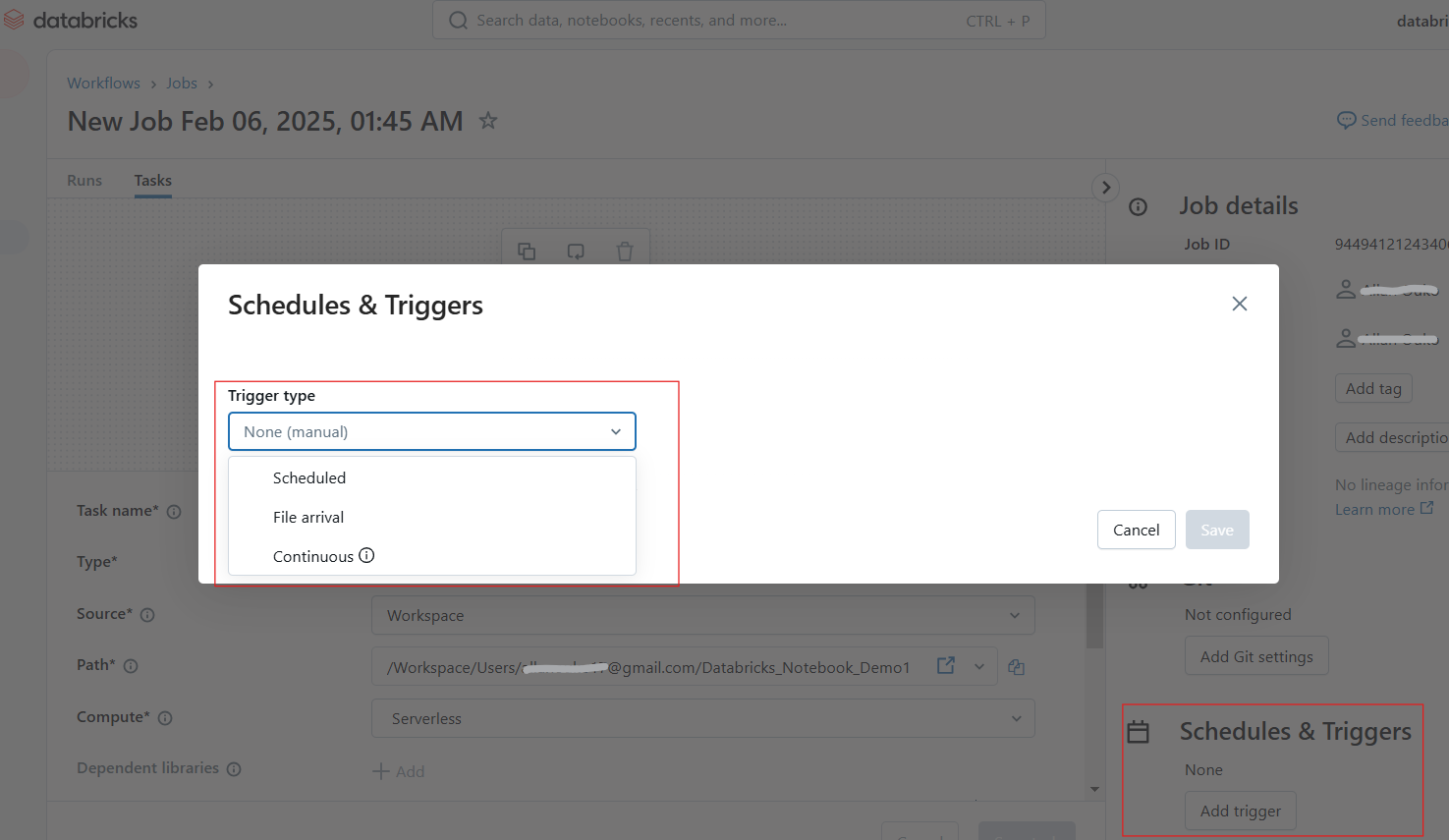
Konfigurieren von Zeitplänen und Auslösern in Databricks Notebook. Bild vom Autor.
Ausführen von Auftragsläufen in Databricks Notebook. Bild vom Autor.
Mit Databricks Widgets kannst du Parameter dynamisch definieren, sodass dasselbe Notebook mit unterschiedlichen Eingaben ausgeführt werden kann. Das folgende dbutils.widgets.text() Widget erstellt zum Beispiel ein interaktives Texteingabe-Widget mit der Bezeichnung "Parameter eingeben" und dem Standardwert default_value. Dann holt es den vom Benutzer eingegebenen Wert aus dem Widget und druckt ihn aus.
dbutils.widgets.text("input_param", "default_value", "Enter Parameter")
param_value = dbutils.widgets.get("input_param")
print(f"User Input: {param_value}")In ähnlicher Weise erzeugt der folgende Code ein Dropdown-Menü mit der Bezeichnung dataset und den Optionen sales, marketing und finance, wobei die Voreinstellung sales ist. Sie ruft die vom Benutzer gewählte Option ab und druckt den gewählten Datensatz aus.
dbutils.widgets.dropdown("dataset", "sales", ["sales", "marketing", "finance"])
selected_dataset = dbutils.widgets.get("dataset")
print(f"Processing {selected_dataset} dataset")Databricks bietet integrierte Versionierungs- und Kollaborationsfunktionen, die es einfach machen, Änderungen zu verfolgen, frühere Versionen wiederherzustellen und mit Teams in Echtzeit zusammenzuarbeiten.
Jede Änderung in einem Databricks Notebook wird automatisch versioniert. Für den Versionsverlauf kannst du Folgendes tun:
Anzeige des Versionsverlaufs in Databricks Notebook. Bild vom Autor.
Databricks Notebooks ermöglichen es Teams, gemeinsam zu schreiben, zu kommentieren und Erkenntnisse auszutauschen, indem sie die folgenden Funktionen nutzen:
Databricks Notebooks lässt sich mit Delta Live Tables, MLflow, SQL Warehouses und CI/CD-Pipelines integrieren, um die Funktionalität zu erweitern.
Delta Live Tables (DLT) vereinfachen die Automatisierung von Datenpipelines mit deklarativem ETL. Die folgende Abfrage erstellt eine Delta Live Table Pipeline in SQL.
-- Creating a live table called 'sales_cleaned' that stores cleaned data
CREATE LIVE TABLE sales_cleaned AS
-- Selecting all columns where the 'order_status' is 'completed'
SELECT *
FROM raw_sales
WHERE order_status = 'completed'; Mit MLflow, das in Databricks integriert ist, kannst du Experimente zum maschinellen Lernen verfolgen. Der folgende Code protokolliert zum Beispiel die Lernrate und Genauigkeit eines maschinellen Lernmodells in MLflow als Teil eines verfolgten Experiments. Nach der Protokollierung wird die Experimentiersitzung beendet. So kannst du die Hyperparameter und die Leistung des Modells im Laufe der Zeit verfolgen und verschiedene Läufe vergleichen.
# Import the MLflow library for experiment tracking
import mlflow
mlflow.start_run()
mlflow.log_param("learning_rate", 0.01)
mlflow.log_metric("accuracy", 0.95)
mlflow.end_run()Databricks Notebooks können in verschiedenen Formaten exportiert werden, darunter die folgenden:
.html: Teile schreibgeschützte Berichte.
.ipynb: Konvertiere zu Jupyter Notebooks.
.dbc: Databricks Archiv für Portabilität.
Du kannst zum Beispiel ein Notizbuch über die CLI mit dem folgenden Befehl exportieren.
databricks workspace export /Users/my_notebook /local/path/my_notebook.ipynbDatabricks Notebooks bieten eine Reihe von leistungsstarken Funktionen, um Arbeitsabläufe zu optimieren, die Produktivität zu steigern und die Zusammenarbeit zu verbessern. In diesem Abschnitt zeige ich dir magische Befehle, UI-Verbesserungen, Datenexplorationstechniken und Code-Management-Strategien, die ich beim Navigieren auf der Databricks Notebooks-Plattform als nützlich empfunden habe.
Databricks bietet magische Befehle, die Aufgaben wie die Ausführung von Skripten, die Verwaltung von Dateien und die Installation von Paketen vereinfachen.
Um ein anderes Notizbuch innerhalb des aktuellen auszuführen, um Arbeitsabläufe zu modularisieren, kannst du den Befehl %run verwenden. Du kannst %run auch nutzen, um große Projekte in wiederverwendbare Notizbücher zu unterteilen. Der folgende Befehl führt zum Beispiel das data_preprocessing Notebook aus, damit die Variablen, Funktionen und Ausgaben im aktuellen Notebook verfügbar werden.
%run /Users/john.doe/notebooks/data_preprocessingMit dem Befehl %sh kannst du Linux-Shell-Befehle direkt in einem Notizbuch ausführen. In dem folgenden Beispiel listet der Befehl den Inhalt von /dbfs/data/ DBFS auf.
%sh ls -lh /dbfs/data/Mit dem Befehl %fs kannst du mit dem Databricks File System (DBFS) interagieren, um Dateioperationen durchzuführen. Der folgende Befehl listet zum Beispiel alle Dateien und Verzeichnisse innerhalb von /databricks-datasets/ auf, die von Databricks bereitgestellte öffentliche Datensätze enthalten.
%fs ls /databricks-datasets/Ebenso kannst du %fs cp zum Kopieren von Dateien, %fs rm zum Entfernen von Dateien und %fs head für die Dateivorschau verwenden.
Der Befehl %pip installiert die Python-Pakete in der Notebook-Umgebung. Mit dem folgenden Befehl wird das Paket matplotlib in der aktuellen Notebook-Sitzung installiert.
%pip install pandas matplotlibDer Befehl %pip freeze wird verwendet, um die installierten Pakete aufzulisten und die Reproduzierbarkeit sicherzustellen.
Databricks hat die folgenden UI-Verbesserungen eingeführt, die die Navigation, das Debugging und die allgemeine Benutzerfreundlichkeit verbessern:
Ich empfehle immer die Aktivierung des Fokus-Modus(Ansicht → Fokusmodus), um Ablenkungen zu minimieren.
Databricks bietet integrierte Tools zum Durchsuchen von Datensätzen, zum Verstehen von Schemata und zum Erstellen von Profilen direkt in Notebooks.
Um die Datensätze im DBFS zu durchsuchen, verwende %fs ls oder display(dbutils.fs.ls()), um die verfügbaren Datensätze zu prüfen.
display(dbutils.fs.ls("/databricks-datasets/"))Du kannst Tabellenschemata auch direkt in der UI-Seitenleiste erkunden, indem du die folgenden Schritte befolgst:
Für das Datenprofiling kannst du Daten mit display() oder SQL-Abfragen zusammenfassen.
df.describe().show()%sql
SELECT COUNT(*), AVG(salary), MAX(age) FROM employees;Verwende die folgenden Techniken, um deinen Code in Databricks Notebooks zu verwalten. Achte zum einen darauf, dass du wiederverwendbare Codeschnipsel in separaten Notizbüchern speicherst und sie mit %run aufrufst. Verwende außerdem Databricks Utilities (dbutils) für die Transformation. Außerdem ist es aus Gründen der Lesbarkeit ratsam, PEP 8 (Python) oder SQL Best Practices zu befolgen. Verwende immer Markdown-Zellen für Kommentare.
-- Select customer_id and calculate total revenue per customer
SELECT customer_id, SUM(total_amount) AS revenue
FROM sales_data
-- Group results by customer to get total revenue per customer
GROUP BY customer_id
-- Order customers by revenue in descending order (highest first)
ORDER BY revenue DESC
-- Return only the top 10 customers by revenue
LIMIT 10;Wenn du bei der Arbeit mit Databricks Notebooks auf Probleme stößt, kannst du die folgenden Methoden zur Fehlerbehebung anwenden:
Steckengebliebene Cluster? Starte den Kernel neu(Ausführen → Status löschen & neu starten).
Langsame Ausführung? Überprüfe die Spark UI(Cluster → Spark UI) auf Engpässe.
Versionskonflikte? Verwende %pip list, um Abhängigkeiten zu prüfen.
Verwende die folgenden Tastenkombinationen, um schneller zu programmieren:
Databricks Notebooks werden häufig in den Bereichen Data Engineering, maschinelles Lernen und Business Intelligence eingesetzt. In diesem Abschnitt zeige ich anhand von Fallstudien und Codeschnipseln aus der Praxis, wie Teams Databricks Notebooks für Produktionsworkflows nutzen.
Stellen Sie sich ein Szenario vor, in dem ein Einzelhandelsunternehmen Verkaufsrohdaten aufnimmt, bereinigt und für die Berichterstattung in einem Delta Lake speichert. Das Verfahren läuft folgendermaßen ab:
Dieser Prozess verbessert die Zuverlässigkeit der Daten und die Abfrageleistung für die Berichterstattung. Der folgende Codeschnipsel ist ein Beispiel dafür, wie die oben genannte Lösung umgesetzt werden kann:
# Read raw sales data from cloud storage
df = spark.read.format("csv").option("header", "true").load("s3://sales-data/raw/")
# Data cleaning and transformation
df_cleaned = df.filter(df["status"] == "completed").dropDuplicates()
# Save to Delta Table for analysis
df_cleaned.write.format("delta").mode("overwrite").saveAsTable("sales_cleaned")Nehmen wir ein anderes Szenario, in dem ein Finanzinstitut mithilfe eines maschinellen Lernmodells Kreditausfälle vorhersagt. Um diesen Workflow in Databricks Notebook zu implementieren, befolgst du die folgenden Schritte. Das Ergebnis ist eine automatisierte Modellverfolgung und -bereitstellung mit MLflow.
# import libraries
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import mlflow
# Load and prepare data
df = spark.read.table("loan_data").toPandas()
X_train, X_test, y_train, y_test = train_test_split(df.drop("default", axis=1), df["default"])
# Train model
model = LogisticRegression()
model.fit(X_train, y_train)
# Log model in MLflow
mlflow.sklearn.log_model(model, "loan_default_model")In einem Szenario, in dem ein Marketingteam Trends zur Kundenbindung analysiert, wirst du die Lösung in den folgenden Schritten implementieren:
Der Prozess wird zu einer schnelleren Entscheidungsfindung mit interaktiven Dashboards führen.
%sql
-- Count the number of interactions per customer segment
SELECT customer_segment, COUNT(*) AS interactions
FROM user_activity
-- Group by customer segment to aggregate interaction counts
GROUP BY customer_segment
-- Order results by interaction count in descending order
ORDER BY interactions DESC;Wenn du dein Wissen über Databricks SQL auffrischen musst, empfehle ich dir, unser Databricks SQL-Tutorial zu lesen, um zu erfahren, wie du das SQL Warehouse über die Databricks-Weboberfläche einrichtest.
Wenn Databricks-Notebooks gleichzeitig ausgeführt werden, kann das Debuggen und die Aufrechterhaltung der Leistung eine besondere Herausforderung darstellen. Hier sind einige Ideen, die dir helfen, dein Notebook in Produktionsumgebungen fehlerfrei zu halten.
Hier sind einige Probleme und empfohlene Lösungen:
Ein Notebook, das einzeln gut läuft, schlägt fehl, wenn mehrere Benutzer oder Jobs es gleichzeitig ausführen: Dieses Problem könnte durch gemeinsam genutzte Variablen verursacht werden. Außerdem kann es sein, dass ein einzelner Cluster keine Mehrfachausführungen unterstützt. Um dieses Problem zu lösen, verwende Widgets für die Parametrisierung oder nutze die automatische Skalierung des Clusters, um sicherzustellen, dass du genügend Ressourcen für gleichzeitige Ausführungen hast.
Ein Notebook, das früher schnell lief, braucht jetzt deutlich länger: Das Problem könnte auf ineffiziente Spark-Transformationen zurückzuführen sein, die Shuffle-Probleme verursachen, oder auf zu viele Caches/persistente Datensätze, die Speicher verbrauchen. Um dieses Problem zu lösen, führe Operationen mit .persist() und .unpersist() durch. Überprüfe außerdem die Spark-Benutzeroberfläche auf schiefe Partitionen und optimiere Abfragen mit Delta-Tabellen.
%run schlägt fehl, wenn du versuchst, ein anderes Notebook auszuführen: Das kann passieren, wenn der Notebook-Pfad falsch ist oder das referenzierte Notebook von einem nicht verfügbaren Cluster abhängt. Um dieses Problem zu lösen, verwende absolute Pfade für Notebook-Importe oder prüfe die Verfügbarkeit von Clustern, um sicherzustellen, dass referenzierte Notebooks einen kompatiblen Cluster verwenden.
Ein geplanter Notebook-Job schlägt fehl: Das kann passieren, wenn der Cluster vor der Ausführung beendet wurde oder wenn eine externe Abhängigkeit fehlgeschlagen ist, z. B. eine Datenbankverbindung oder ein API-Aufruf. Um dieses Problem zu lösen, aktiviere den Neustart des Clusters bei Ausfall. Aktiviere in den Auftragseinstellungen Wiederholung bei Fehlschlag. Verwende außerdem Try-Except-Blöcke für externe Aufrufe.
In unserem Tutorial Mastering the Databricks API erfährst du, wie du Databricks REST API für die Auftragsplanung und die Skalierung automatisierter Pipelines nutzen kannst.
Verwende die folgenden Techniken, um Databricks Notebooks in der Produktion zu warten:
Modularisiere den Code in wiederverwendbare Notizbücher: Unterteile große Notizbücher in kleinere, wiederverwendbare Einheiten und benutze %run, um sie aufzurufen. Speichere Hilfsfunktionen in separaten Utility-Notebooks.
Nutze die Versionskontrolle (Git-Integration): Aktiviere Databricks Repos, um Änderungen und Rollback-Versionen zu verfolgen.
Optimiere die Clusterauswahl für Jobs: Verwende Job-Cluster anstelle von interaktiven Clustern für geplante Läufe.
Protokollierung und Warnungen implementieren: Verwende dbutils.notebook.exit(), um den Auftragsstatus zu protokollieren. Du kannst in der Jobs UI auch E-Mail-Benachrichtigungen konfigurieren, um Teams über Fehlschläge zu informieren.
Dokumentiere den Code und verwende Markdown für mehr Klarheit: Verwende Markdown-Zellen, um Arbeitsschritte und Logik zu beschreiben.
Wenn du die grundlegenden Konzepte von Databricks kennenlernen möchtest, empfehle ich dir unseren Kurs Einführung in Databricks. Dieser Kurs vermittelt dir das richtige Verständnis, das du brauchst, um dann mit fortgeschrittenen Funktionen wie magischen Befehlen, Parametrisierung und Leistungsoptimierung zu experimentieren. Zu guter Letzt solltest du auch lernen, wie du eine Databricks-Zertifizierung erhältst. Unser Beitrag hilft dir, die Vorteile für deine Karriere zu erkunden und die richtige Zertifizierung für deine Karriereziele auszuwählen.
Databricks lernen mit DataCamp
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
