
Curso
Conceitos de Databricks
4 h
22K
A Databricks funciona como uma plataforma analítica unificada, permitindo a integração de engenharia de dados, aprendizado de máquina e análise de negócios. No centro desse ecossistema estão os Databricks Notebooks, espaços de trabalho interativos projetados para exploração de dados, desenvolvimento de modelos e fluxos de trabalho de produção.
Neste artigo, mostrarei a você como começar a usar o Databrick Notebooks. Se você for totalmente novo, talvez queira começar inscrevendo-se em nosso curso Introdução à Databricks para entender os prós e contras da Databricks e como ela moderniza a arquitetura de dados. Nosso curso é muito completo e ensina muitas coisas, inclusive o gerenciamento de catálogos e a ingestão de dados, portanto, experimente.
Os Databricks Notebooks são espaços de trabalho interativos e baseados na nuvem que permitem aos usuários realizar exploração de dados, engenharia, aprendizado de máquina e análise em um ambiente colaborativo. Eles usam um modelo de execução baseado em células, em que os usuários podem escrever e executar códigos em blocos ou células discretos.
O Databricks Notebooks tem suporte a vários idiomas, de modo que você pode não apenas escolher seu idioma favorito, mas também alternar entre idiomas dentro do mesmo notebook. As linguagens incluem Python, SQL, Scala e R, para as quais oferecemos cursos introdutórios.
Agora, para facilitar a interoperabilidade em vários idiomas, o Databricks fornece o que é conhecido como comandos mágicos:
%python: Executa uma célula usando Python.
%sql: Executa consultas SQL.
%scala: Processa comandos baseados em Scala.
%r: Executa o código R.
Os notebooks da Databricks vão além dos ambientes de codificação tradicionais, oferecendo os seguintes recursos principais:
Uma coisa é você ler sobre os recursos, mas outra coisa é ver com seus próprios olhos. A melhor maneira de apreciar a Databricks é começar a fazer as coisas por você mesmo. Portanto, nesta seção, ajudarei você a começar a criar, gerenciar e navegar pelos notebooks no espaço de trabalho do Databricks. Então, tenho certeza de que você começará a ver por si mesmo como ele é útil.
No espaço de trabalho do Databricks, você pode criar novos notebooks ou gerenciar notebooks existentes. Vamos examinar esses métodos a seguir.
Para criar um novo notebook no Databricks, você deve criar um novo notebook:
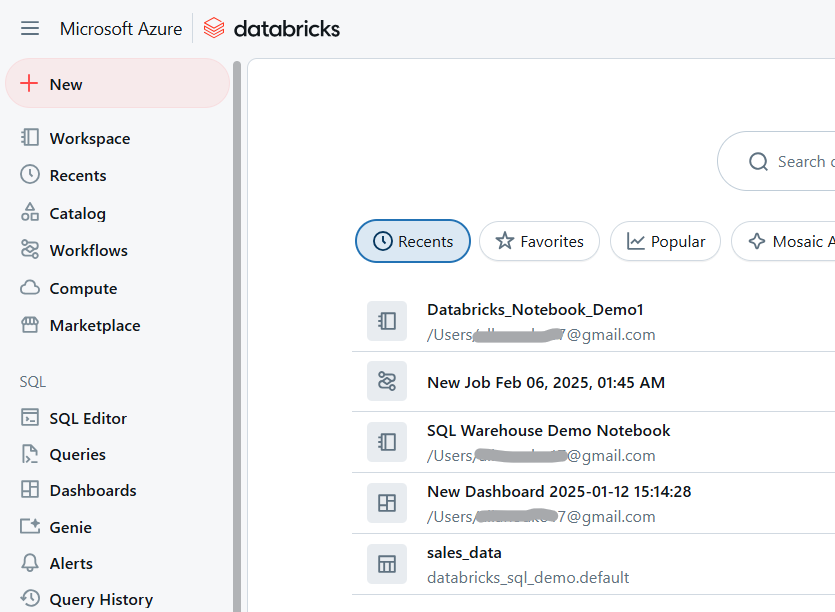
Espaço de trabalho do Databricks. Imagem do autor.
Criar o Databricks Notebook. Imagem do autor.
Selecione o nome e o idioma padrão do Databricks Notebook. Imagem do autor.
A Databricks permite que os usuários importem notebooks de várias fontes, como GitHub e Git Repositories, URLs externos ou arquivos locais carregados como .dbc (arquivo da Databricks) ou .ipynb (Jupyter).
Siga as etapas a seguir para importar notebooks existentes para o Databricks Workspace:
Importe o notebook existente para o Databricks Workspace. Imagem do autor.
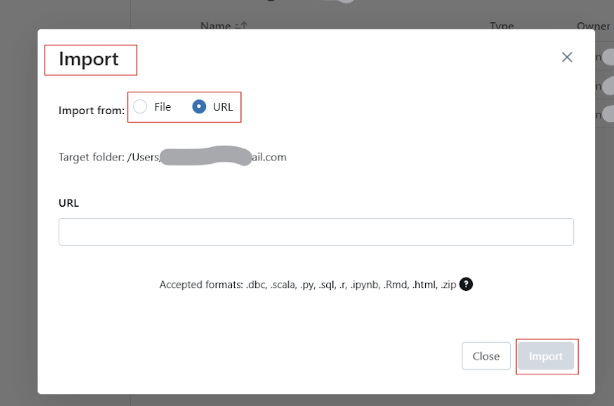
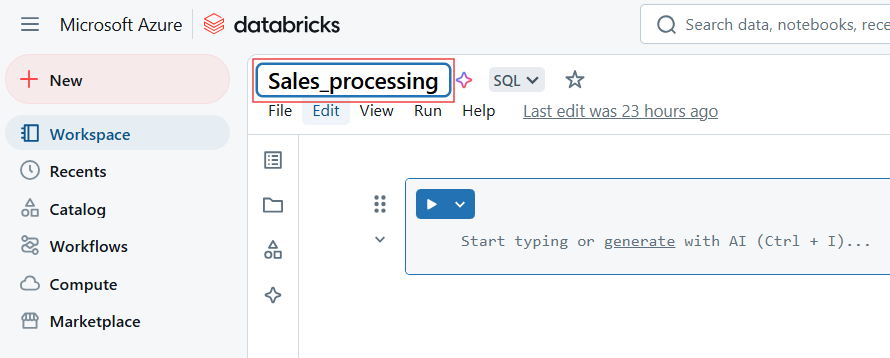
Para renomear o Databricks Notebook, clique no título do notebook e edite o nome.
Você também pode mover cadernos para pastas para melhor estruturação.
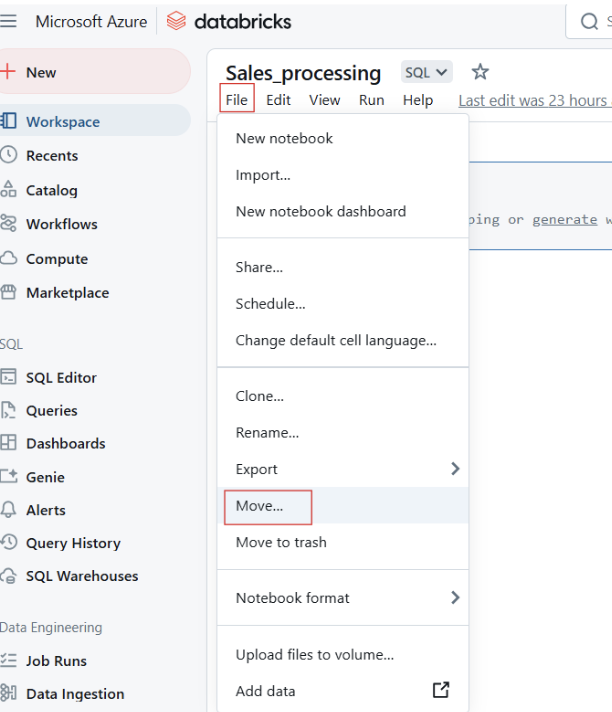
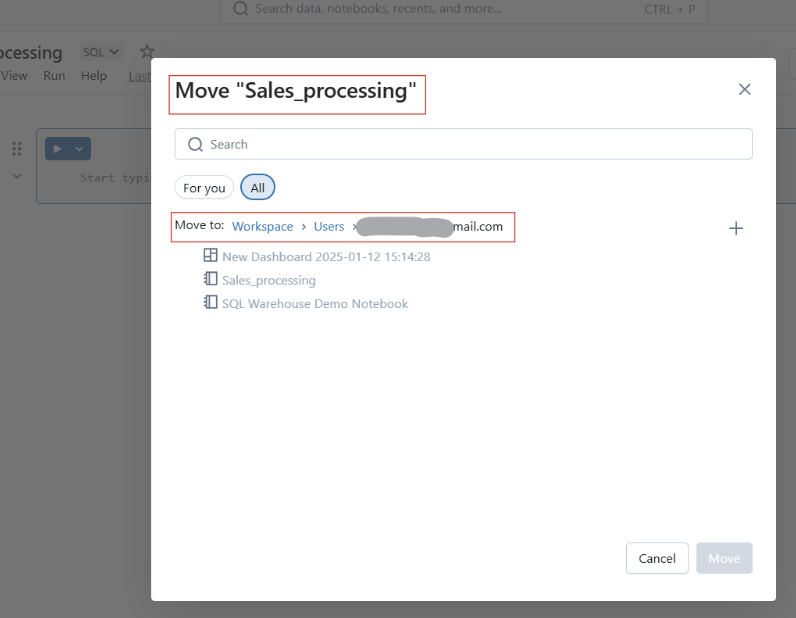
Movendo o Databricks Notebooks para a pasta. Imagem do autor.
Antes de compartilhar o Notebook do Datbricks, você pode gerenciar o acesso e as permissões para controlar quem pode visualizar, editar ou gerenciar o notebook.
Antes de prosseguirmos com os exemplos práticos de uso do Databricks Notebooks, deixe-me mostrar a você a interface do usuário e a navegação da plataforma.
A barra de ferramentas do Databricks Notebook oferece acesso rápido às seguintes ações:
Executar, editar, excluir ou mover a célula.
Alterar os tipos de células, como código, markdown, SQL ou Scala.
Definir comandos mágicos como %python ou %sql.
Executar uma célula no Databricks Notebook. Imagem do autor.
Redefinir variáveis e estado de execução no Databricks Notebook. Imagem do autor.
Comentários no Databricks Notebook. Imagem do autor.
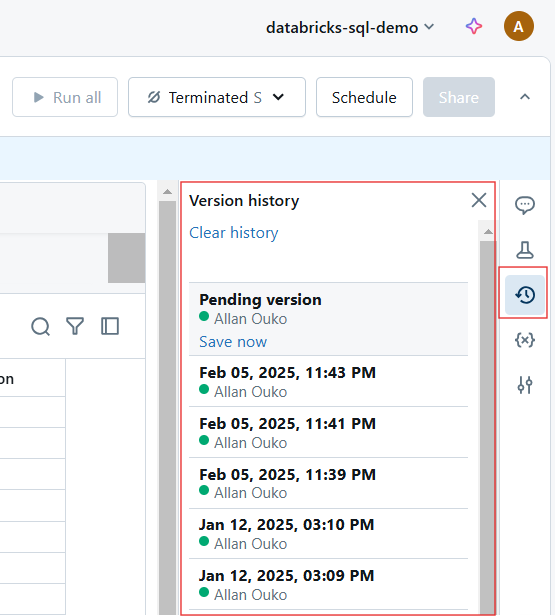
Histórico de versões no Databricks Notebook. Imagem do autor.
A Databricks introduziu várias melhorias na interface do usuário para que você tenha uma experiência mais intuitiva. Com esses aprimoramentos, o Databricks Notebooks oferece um ambiente de desenvolvimento ainda mais simplificado e avançado para profissionais de dados. Eles incluem o seguinte:
Os Databricks Notebooks oferecem um ambiente de codificação interativo no qual os usuários podem escrever, executar e documentar seu código. Nesta seção, abordarei o trabalho com células de código, Markdown e a execução eficiente de código.
Os Databricks Notebooks suportam várias linguagens, incluindo Python, SQL, Scala e R, dentro do mesmo notebook.
Use o comando mágico %python para escrever código Python em uma célula do Databricks Notebook.
%python
import pandas as pd
# Load sample data and display the first few rows
df = spark.read.format("csv").option("header", "true").load("/databricks-datasets/airlines/part-00000")
pd_df = df.limit(5).toPandas() # Convert to Pandas DataFrame
display(pd_df) # Works in Databricks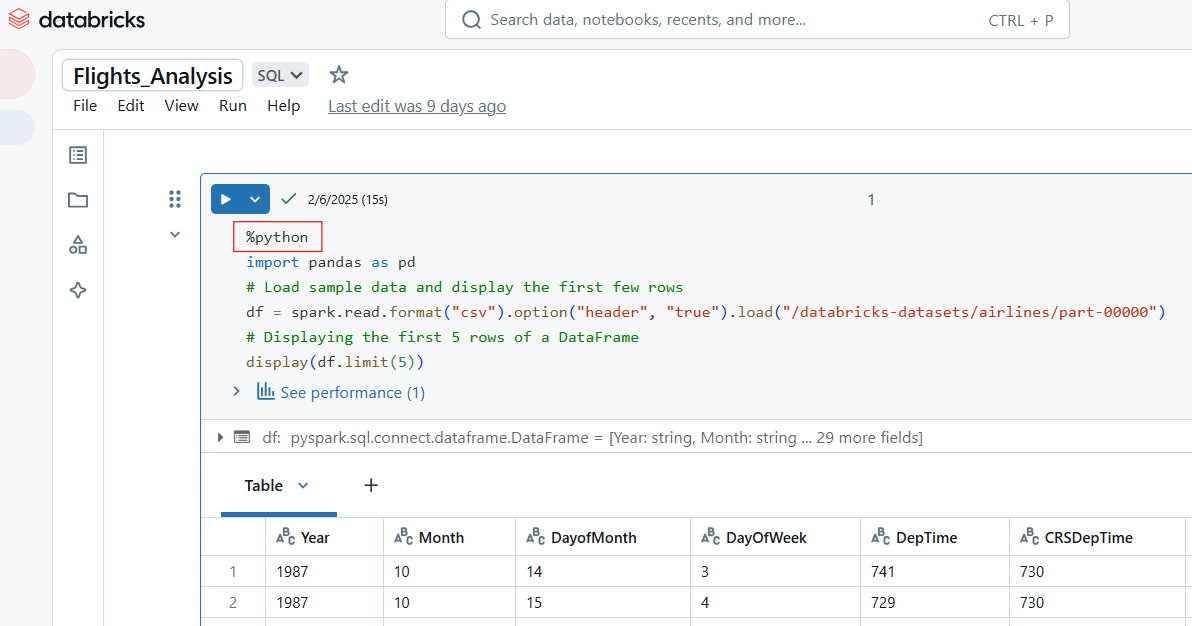
Exemplo de código Python no Databricks Notebook. Imagem do autor.
Para escrever código SQL no Databricks Notebook, use o comando mágico %sql. Se você tiver definido o SQL como o idioma padrão do notebook, poderá executar a célula sem incluir o comando mágico %sql.
-- Querying a dataset in SQL
SELECT origin, dest, COUNT(*) AS flight_count
FROM flights_table
GROUP BY origin, dest
ORDER BY flight_count DESC
LIMIT 10;
Código SQL no Databricks Notebook. Imagem do autor.
Use o comando mágico %scala para escrever código Scala em uma célula do Databricks Notebook.
%scala
// Reading and displaying data in Scala
val data = spark.read.option("header", "true").csv("/databricks-datasets/airlines/part-00000")
// Display as a table in Databricks
display(data)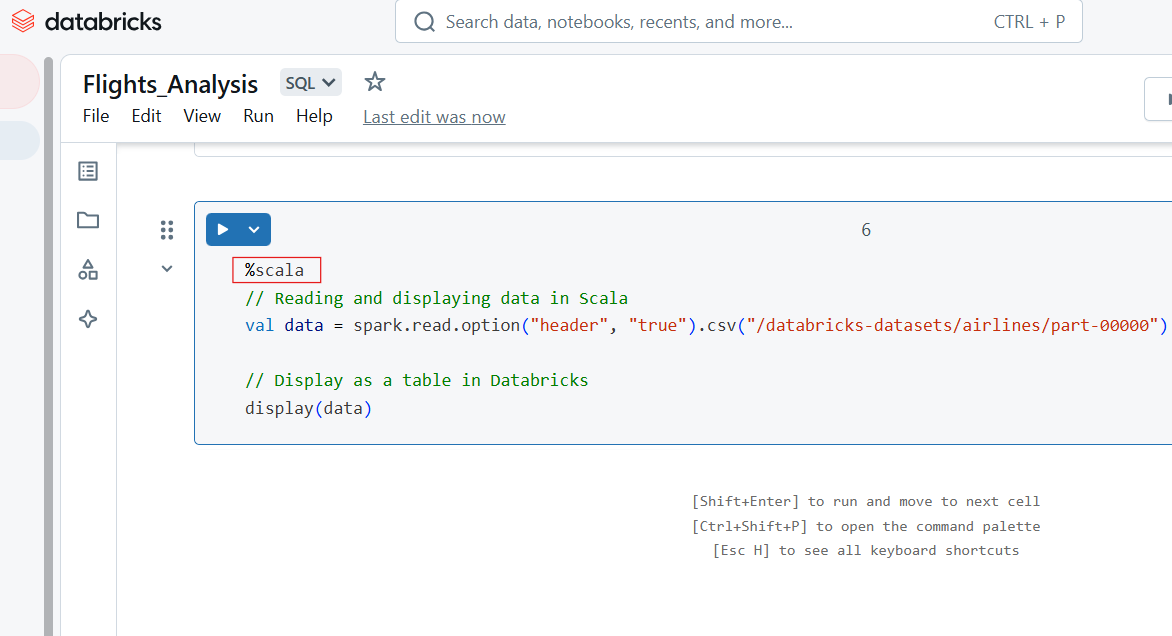
Código Scala no Databricks Notebook. Imagem do autor.
Você também pode escrever código R na célula do Databricks Notebook usando o comando mágico %r.
%r
# Load a sample dataset in R
library(SparkR)
df <- read.df("/databricks-datasets/airlines/part-00000", source = "csv", header = "true")
head(df)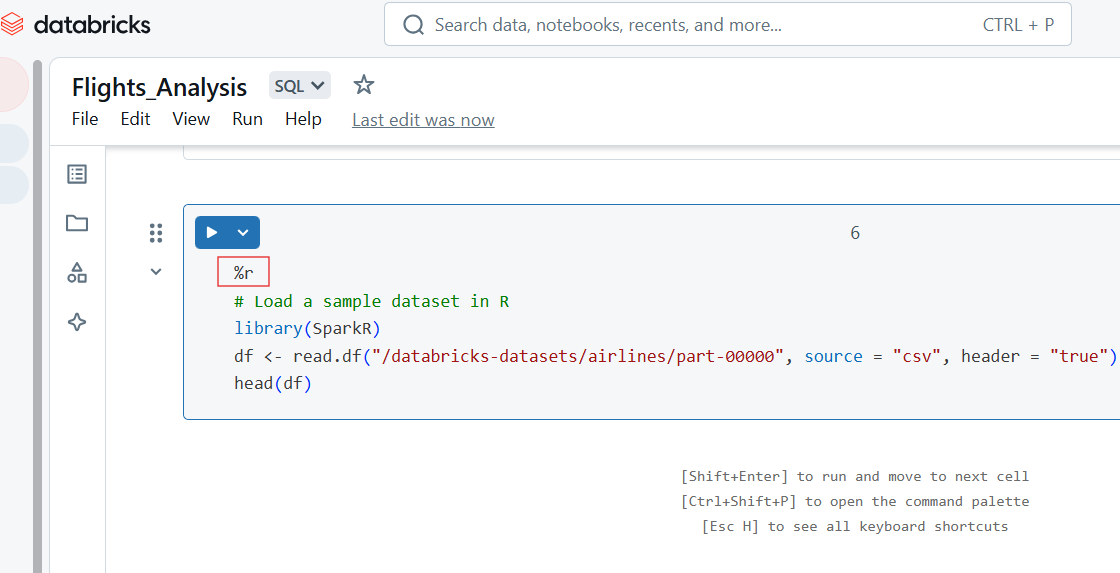
Código R no Databricks Notebook. Imagem do autor.
As células Markdown são usadas para adicionar texto, cabeçalhos, listas e outras documentações. O exemplo a seguir mostra como você pode escrever uma célula Markdown e como os resultados são exibidos no Databricks Notebook.
%md
# Data Exploration Notebook
This notebook explores airline flight data, providing insights into flight frequency and destinations.
## **Steps:**
1. Load and display the dataset
2. Query data using SQL
3. Generate visualizations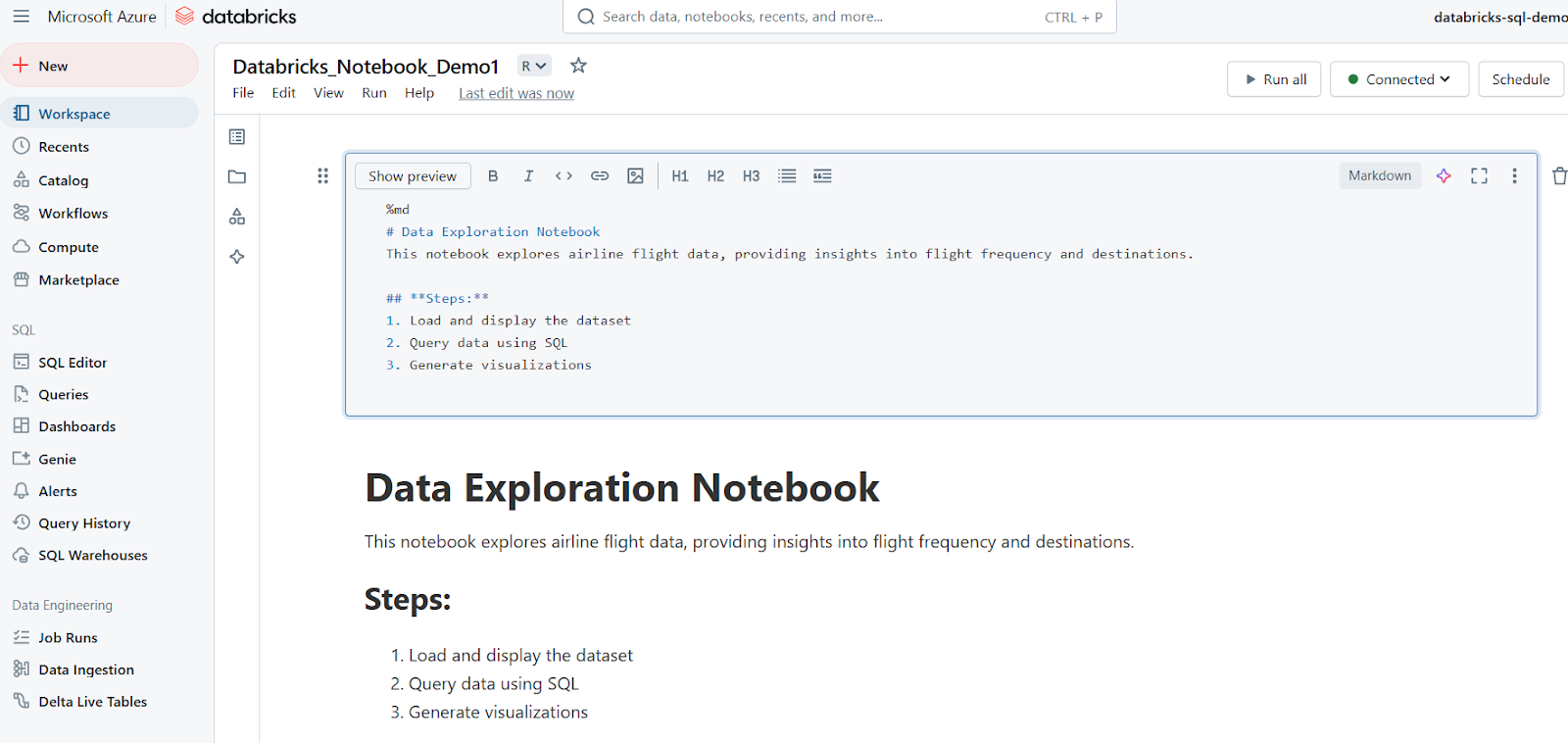
Os Databricks Notebooks permitem a execução flexível do código por meio de execuções de células individuais ou em lote.
Para executar uma única célula, clique no botão Executar (▶) na célula ou use o atalho de teclado:
Para executar todas as células do notebook:
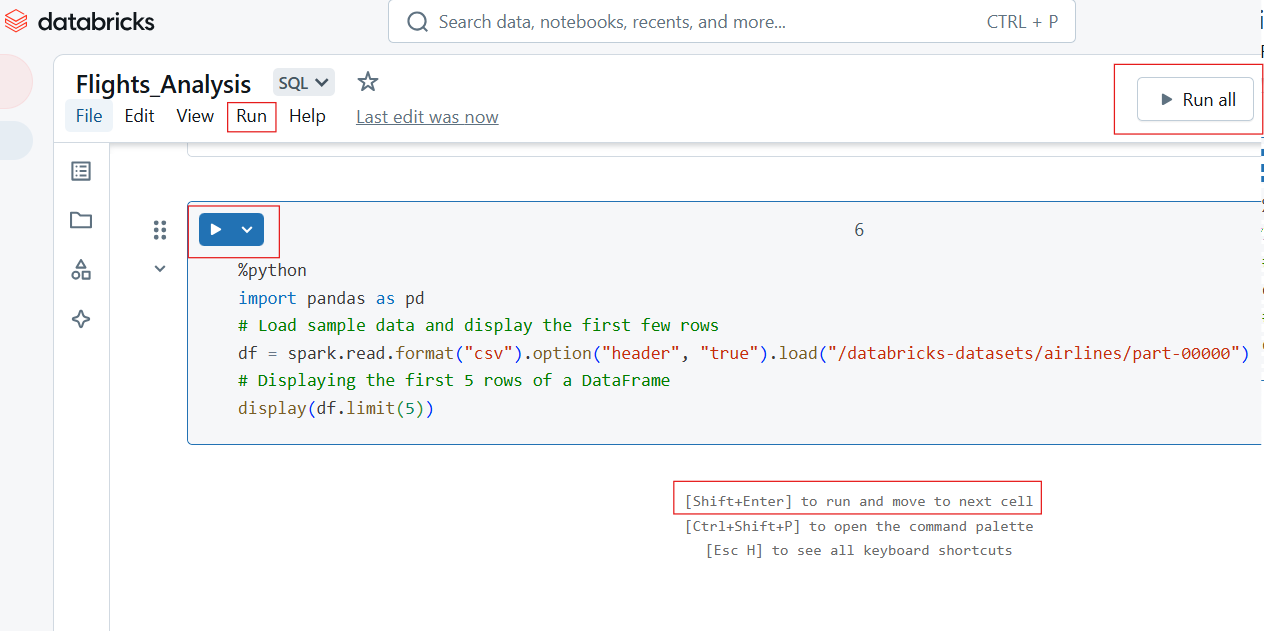
Execução individual e execução de todas as células no Databricks Notebook. Imagem do autor.
Os Databricks Notebooks suportam vários formatos de saída, incluindo tabelas, gráficos e registros. Por exemplo, o código Python a seguir exibe as primeiras 5 linhas do conjunto de dados "airlines".
%python
import pandas as pd
# Load sample data and display the first few rows
df = spark.read.format("csv").option("header", "true").load("/databricks-datasets/airlines/part-00000")
# Displaying the first 5 rows of a DataFrame
display(df.limit(5))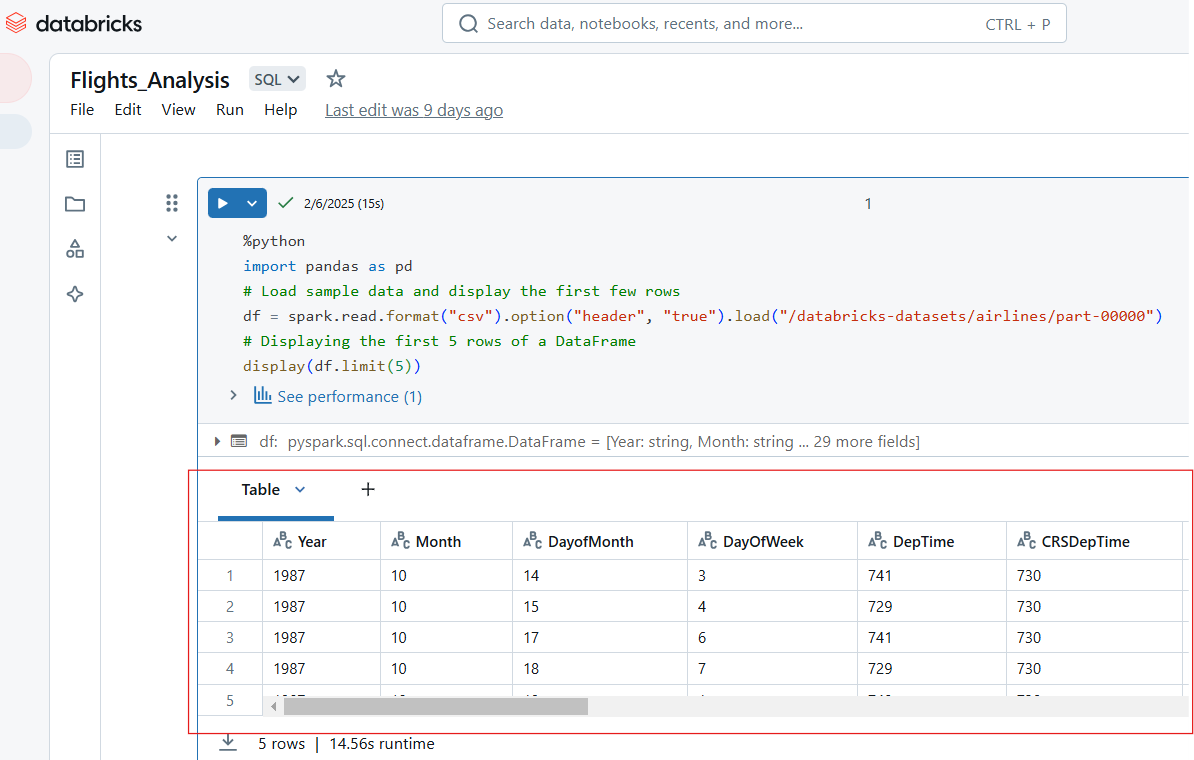
Visualize as entradas no Databricks Notebook. Imagem do autor.
Também podemos usar o Databricks Notebooks para visualizar o resultado das células. Por exemplo, o código Python abaixo seleciona as 10 companhias aéreas mais frequentes, converte os dados do PySpark para o Pandas e, em seguida, usa o Matplotlib para criar um gráfico de barras.
%python
# Import necessary libraries
import matplotlib.pyplot as plt
import pandas as pd
# Load the dataset using PySpark
df = spark.read.option("header", "true").csv("/databricks-datasets/airlines/part-00000")
# Select the top 10 most frequent airlines (carrier column)
top_airlines = df.groupBy("UniqueCarrier").count().orderBy("count", ascending=False).limit(10)
# Convert PySpark DataFrame to Pandas DataFrame
pd_df = top_airlines.toPandas()
# Convert count column to integer (since it's a string in CSV)
pd_df["count"] = pd_df["count"].astype(int)
# Plot a bar chart
plt.figure(figsize=(10, 6))
plt.bar(pd_df["UniqueCarrier"], pd_df["count"], color="#ac4ce4")
# Add titles and labels
plt.xlabel("Airline Carrier", fontsize=12)
plt.ylabel("Flight Count", fontsize=12)
plt.title("Top 10 Most Frequent Airline Carriers", fontsize=14)
plt.xticks(rotation=45) # Rotate x-axis labels for better readability
# Show the plot
plt.show()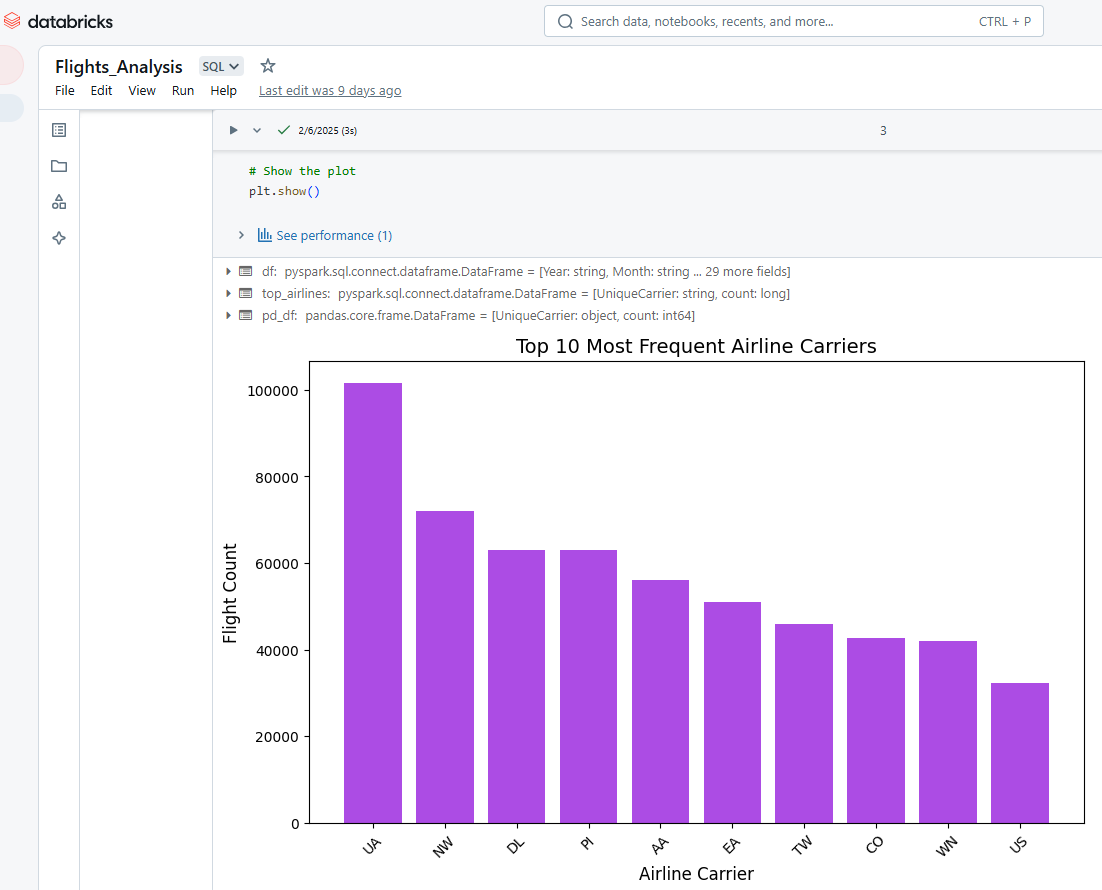
Visualização de resultados no Databricks Notebook. Imagem do autor.
Da mesma forma, você pode exibir várias saídas da execução de uma única célula no Databricks Notebook. Por exemplo, a saída do código abaixo mostrará as 5 primeiras linhas do conjunto de dados de companhias aéreas e a contagem das 10 companhias aéreas mais frequentes.
%python
# Show the top 5 rows in an interactive table
display(df.limit(5))
# Show the top 10 most frequent airline carriers
top_carriers = df.groupBy("UniqueCarrier").count().orderBy("count", ascending=False).limit(10)
display(top_carriers)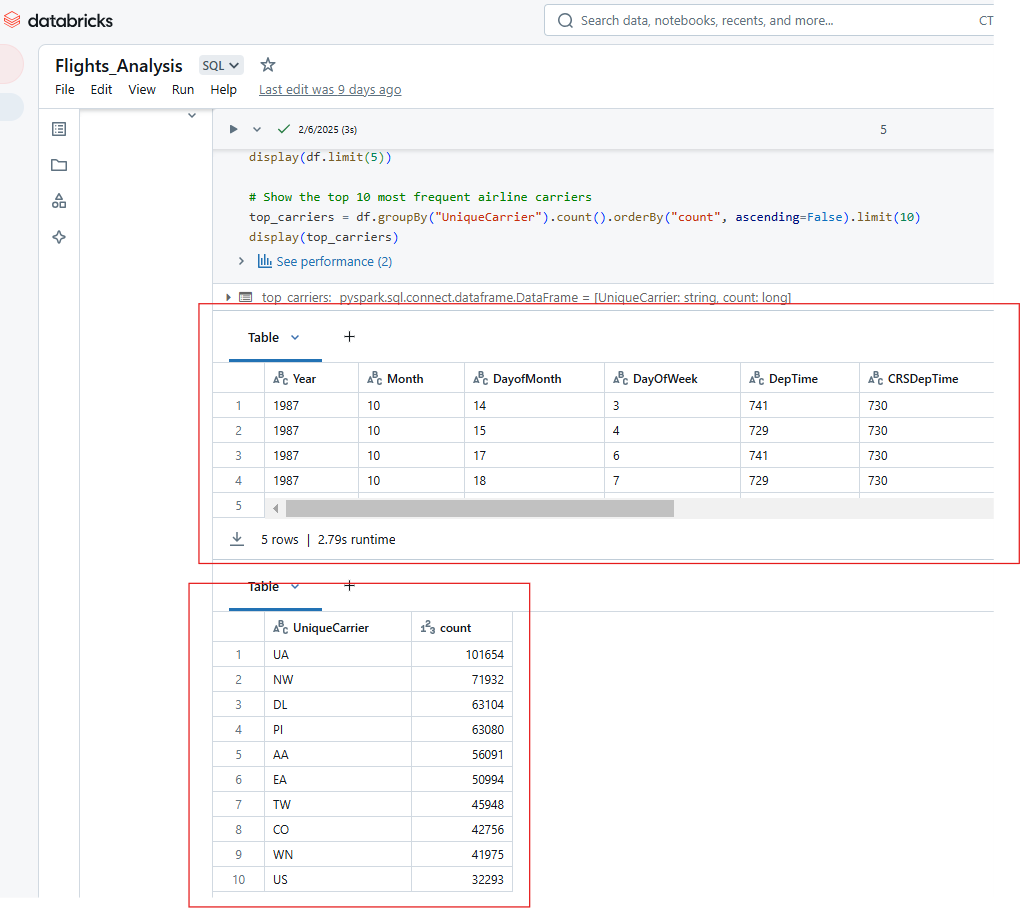
Exibindo várias saídas da execução de uma única célula no Databricks Notebook. Imagem do autor.
Os notebooks da Databricks oferecem recursos avançados de automação, controle de versão e integração que aumentam a produtividade, a colaboração e a eficiência operacional. Nesta seção, explorarei os principais recursos avançados e as práticas recomendadas para maximizar o potencial do Databricks Notebooks.
O Databricks permite que os usuários automatizem a execução de notebooks agendando-os como trabalhos e parametrizando entradas para execução dinâmica.
Os usuários podem programar notebooks para serem executados em intervalos específicos, garantindo fluxos de trabalho automatizados para ETL, relatórios e treinamento de modelos. Siga as etapas a seguir para agendar um trabalho de notebook:
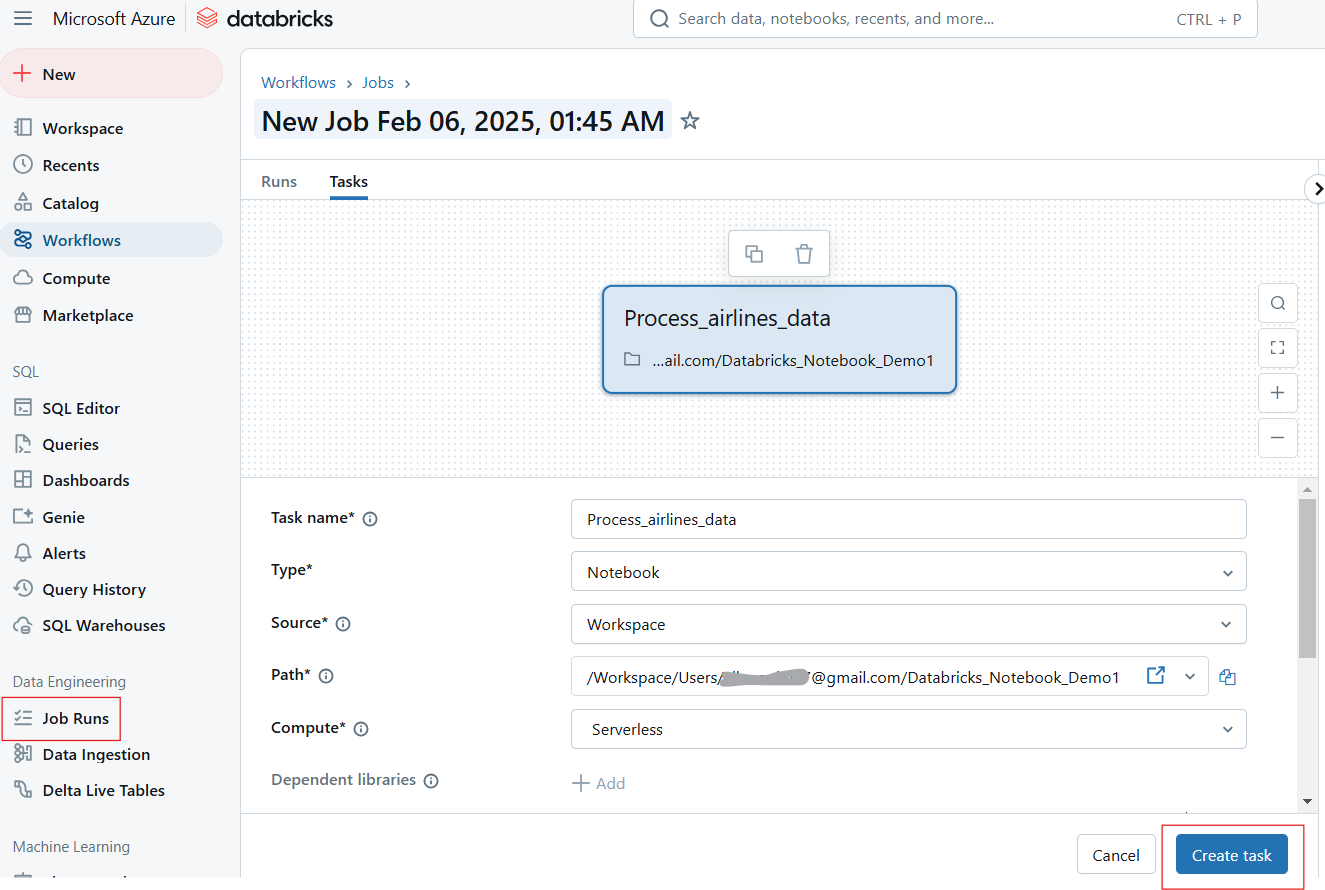
Criação de execução de trabalho no Databricks Notebook. Imagem do autor.
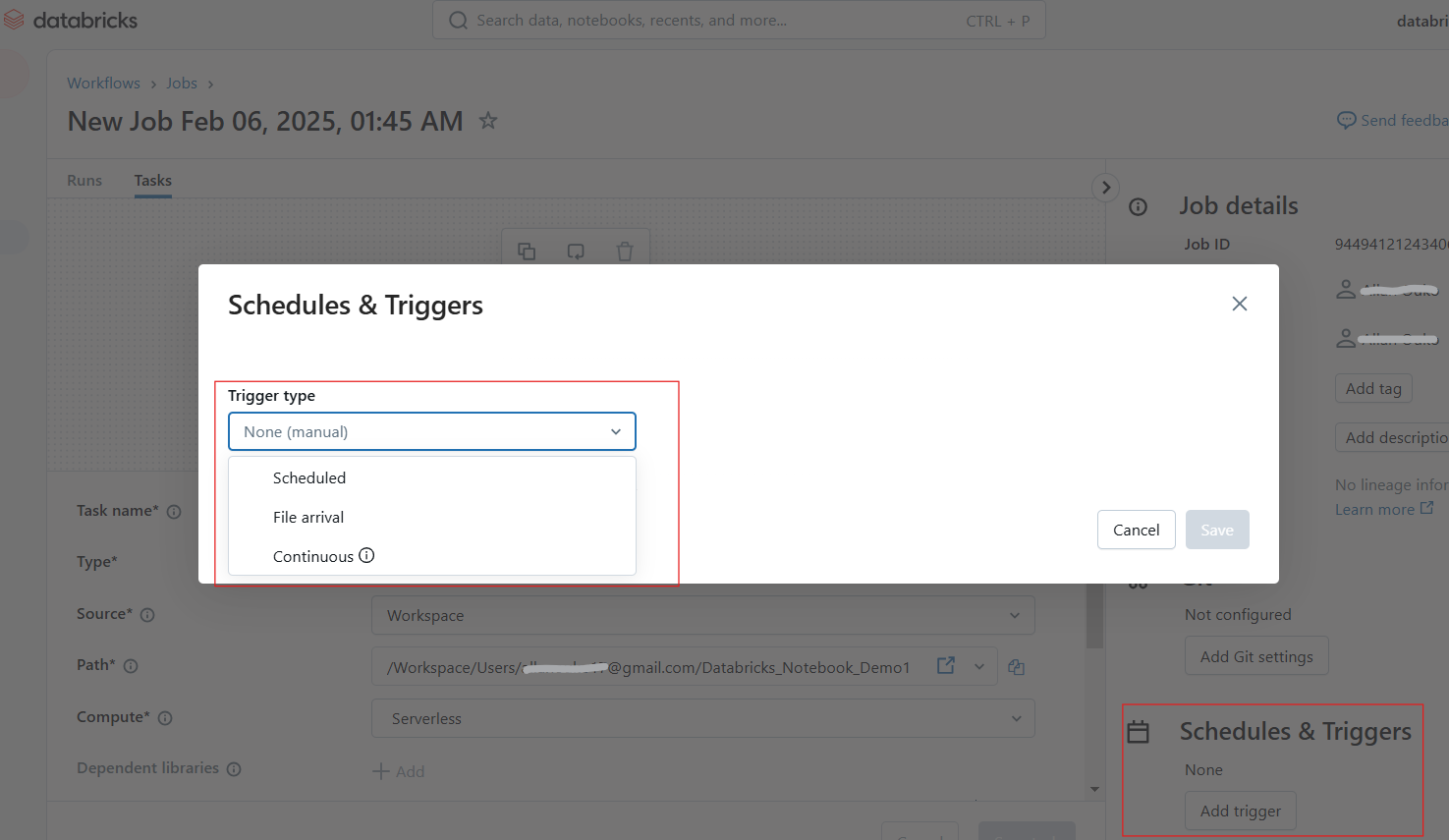
Configuração de programações e acionadores no Databricks Notebook. Imagem do autor.
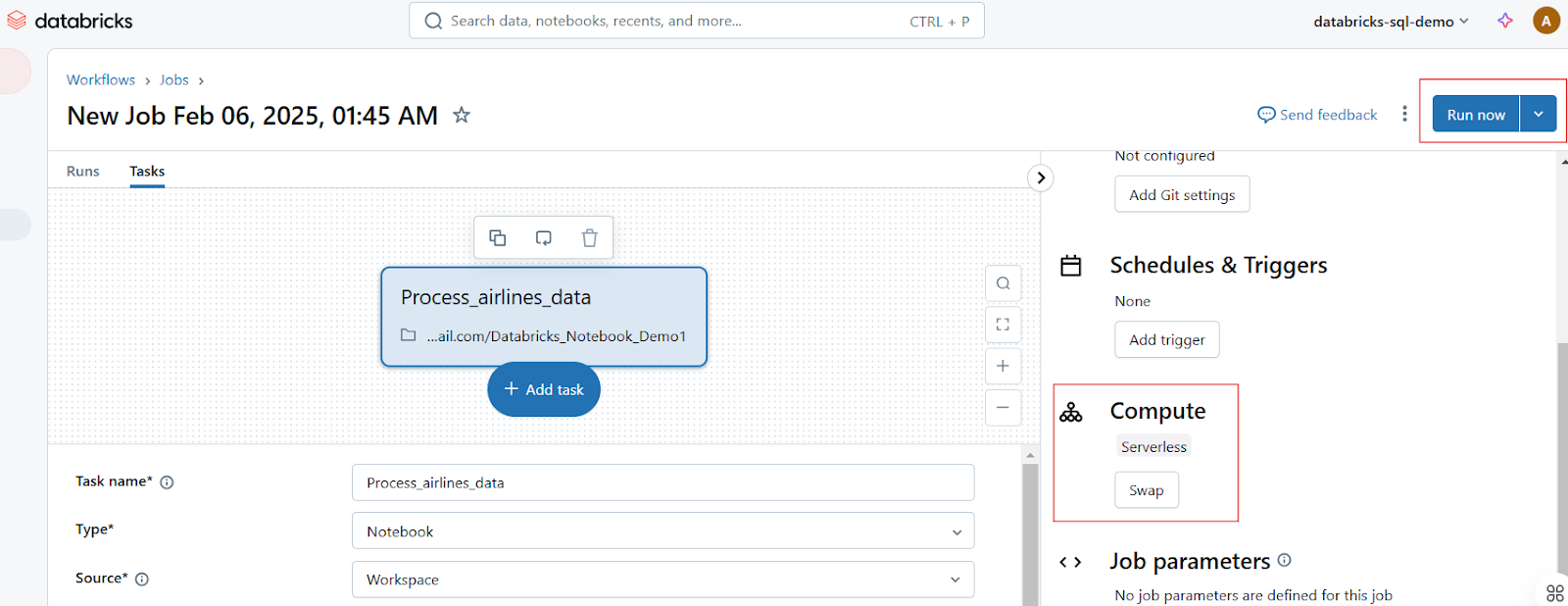
Execução de trabalhos no Databricks Notebook. Imagem do autor.
Os widgets do Databricks permitem que você defina parâmetros dinamicamente, possibilitando que o mesmo notebook seja executado com diferentes entradas. Por exemplo, o widget dbutils.widgets.text() a seguir cria um widget de entrada de texto interativo chamado "Enter Parameter" (Inserir parâmetro) com um valor padrão de default_value. Em seguida, ele recupera o valor inserido pelo usuário no widget e o imprime.
dbutils.widgets.text("input_param", "default_value", "Enter Parameter")
param_value = dbutils.widgets.get("input_param")
print(f"User Input: {param_value}")Da mesma forma, o código abaixo gera um menu suspenso denominado dataset com as opções sales, marketing e finance, tendo como padrão sales. Ele recupera a opção selecionada pelo usuário e imprime o conjunto de dados escolhido.
dbutils.widgets.dropdown("dataset", "sales", ["sales", "marketing", "finance"])
selected_dataset = dbutils.widgets.get("dataset")
print(f"Processing {selected_dataset} dataset")O Databricks oferece recursos integrados de controle de versão e colaboração, facilitando o rastreamento de alterações, a restauração de versões anteriores e o trabalho com equipes em tempo real.
Cada alteração em um Databricks Notebook é automaticamente versionada. Você pode fazer o seguinte para o histórico de versões:
Visualização do histórico de versões no Databricks Notebook. Imagem do autor.
Os Databricks Notebooks permitem que as equipes sejam coautoras, comentem e compartilhem insights usando os seguintes recursos:
O Databricks Notebooks se integra ao Delta Live Tables, MLflow, SQL Warehouses e pipelines de CI/CD para ampliar a funcionalidade.
As Delta Live Tables (DLT) simplificam a automação do pipeline de dados com ETL declarativo. A consulta a seguir cria um pipeline de tabela Delta Live no SQL.
-- Creating a live table called 'sales_cleaned' that stores cleaned data
CREATE LIVE TABLE sales_cleaned AS
-- Selecting all columns where the 'order_status' is 'completed'
SELECT *
FROM raw_sales
WHERE order_status = 'completed'; O MLflow, integrado ao Databricks, permite o rastreamento de experimentos de aprendizado de máquina. Por exemplo, o código abaixo registra a taxa de aprendizado e a precisão de um modelo de aprendizado de máquina no MLflow como parte de um experimento rastreado. Após o registro, ele encerra a sessão do experimento. Isso permite que você acompanhe os hiperparâmetros e o desempenho do modelo ao longo do tempo e compare diferentes execuções.
# Import the MLflow library for experiment tracking
import mlflow
mlflow.start_run()
mlflow.log_param("learning_rate", 0.01)
mlflow.log_metric("accuracy", 0.95)
mlflow.end_run()Os Databricks Notebooks podem ser exportados em vários formatos, incluindo os seguintes:
.html: Compartilhe relatórios somente de leitura.
.ipynb: Converta para o Jupyter Notebooks.
.dbc: Databricks Archive para portabilidade.
Por exemplo, você pode exportar um notebook por meio da CLI usando o seguinte comando.
databricks workspace export /Users/my_notebook /local/path/my_notebook.ipynbOs notebooks da Databricks oferecem uma gama de recursos avançados para simplificar os fluxos de trabalho, aumentar a produtividade e melhorar a colaboração. Nesta seção, mostrarei a você comandos mágicos, aprimoramentos da interface do usuário, técnicas de exploração de dados e estratégias de gerenciamento de código que considerei úteis ao navegar na plataforma Databricks Notebooks.
O Databricks fornece comandos mágicos que simplificam as tarefas, como a execução de scripts, o gerenciamento de arquivos e a instalação de pacotes.
Para executar outro notebook dentro do atual para modularizar os fluxos de trabalho, você pode usar o comando %run. Você também pode usar o site %run para dividir grandes projetos em cadernos reutilizáveis. Por exemplo, o comando a seguir executa o notebook data_preprocessing para que as variáveis, as funções e as saídas fiquem disponíveis no notebook atual.
%run /Users/john.doe/notebooks/data_preprocessingO comando %sh permite que você execute comandos do shell do Linux diretamente em um notebook. No exemplo abaixo, o comando listará o conteúdo de /dbfs/data/ DBFS.
%sh ls -lh /dbfs/data/Da mesma forma, o comando %fs permite que você interaja com o Databricks File System (DBFS) para operações de arquivo. Por exemplo, o comando abaixo lista todos os arquivos e diretórios dentro de /databricks-datasets/, que contém conjuntos de dados públicos fornecidos pela Databricks.
%fs ls /databricks-datasets/Da mesma forma, você pode usar %fs cp para cópia de arquivos, %fs rm para remoção de arquivos e %fs head para visualização de arquivos.
O comando %pip instala pacotes Python no ambiente do notebook. O comando a seguir instalará o pacote matplotlib na sessão atual do notebook.
%pip install pandas matplotlibO comando %pip freeze é usado para listar os pacotes instalados e garantir a reprodutibilidade.
A Databricks introduziu os seguintes aprimoramentos na interface do usuário que melhoram a navegação, a depuração e a experiência geral do usuário:
Eu sempre recomendo que você ative o Modo de foco(Exibir → Modo de foco ) para minimizar as distrações.
O Databricks oferece ferramentas integradas para navegar em conjuntos de dados, entender o esquema e criar perfis de dados diretamente nos notebooks.
Para navegar pelos conjuntos de dados no DBFS, use %fs ls ou display(dbutils.fs.ls()) para inspecionar os conjuntos de dados disponíveis.
display(dbutils.fs.ls("/databricks-datasets/"))Você também pode explorar os esquemas de tabela diretamente na barra lateral da interface do usuário seguindo as etapas abaixo:
Para a criação de perfis de dados, você pode resumir os dados usando display() ou consultas SQL.
df.describe().show()%sql
SELECT COUNT(*), AVG(salary), MAX(age) FROM employees;Use as seguintes técnicas para gerenciar seu código no Databricks Notebooks. Para começar, certifique-se de armazenar trechos de código reutilizáveis em notebooks separados e chamá-los usando %run. Além disso, use o Databricks Utilities (dbutils) para transformação. Além disso, para facilitar a leitura, é uma boa ideia que você siga as práticas recomendadas PEP 8 (Python) ou SQL. Sempre use células markdown para comentários.
-- Select customer_id and calculate total revenue per customer
SELECT customer_id, SUM(total_amount) AS revenue
FROM sales_data
-- Group results by customer to get total revenue per customer
GROUP BY customer_id
-- Order customers by revenue in descending order (highest first)
ORDER BY revenue DESC
-- Return only the top 10 customers by revenue
LIMIT 10;Se você encontrar problemas ao trabalhar com o Databricks Notebooks, poderá solucioná-los usando os seguintes métodos:
O cluster está preso? Reinicie o kernel(Executar → Limpar estado e reiniciar).
Execução lenta? Verifique se há gargalos na interface do Spark(Cluster → Spark UI).
Conflitos de versão? Use o site %pip list para verificar as dependências.
Use os atalhos de teclado a seguir para codificar mais rapidamente:
Os notebooks da Databricks são amplamente utilizados em engenharia de dados, aprendizado de máquina e business intelligence. Nesta seção, destacarei estudos de caso reais e trechos de código para ilustrar como as equipes aproveitam o Databricks Notebooks para fluxos de trabalho de produção.
Considere um cenário em que uma empresa de varejo ingere dados brutos de vendas, limpa-os e os armazena em um Delta Lake para geração de relatórios. O processo será o seguinte:
Esse processo melhorará a confiabilidade dos dados e o desempenho da consulta para a geração de relatórios. O trecho de código abaixo é um exemplo de como você pode implementar a solução acima:
# Read raw sales data from cloud storage
df = spark.read.format("csv").option("header", "true").load("s3://sales-data/raw/")
# Data cleaning and transformation
df_cleaned = df.filter(df["status"] == "completed").dropDuplicates()
# Save to Delta Table for analysis
df_cleaned.write.format("delta").mode("overwrite").saveAsTable("sales_cleaned")Considere outro cenário em que uma instituição financeira prevê a inadimplência de empréstimos usando um modelo de aprendizado de máquina. Para implementar esse fluxo de trabalho no Databricks Notebook, você seguirá as etapas abaixo. Isso resultará em rastreamento e implementação automatizados de modelos com o MLflow.
# import libraries
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import mlflow
# Load and prepare data
df = spark.read.table("loan_data").toPandas()
X_train, X_test, y_train, y_test = train_test_split(df.drop("default", axis=1), df["default"])
# Train model
model = LogisticRegression()
model.fit(X_train, y_train)
# Log model in MLflow
mlflow.sklearn.log_model(model, "loan_default_model")Em um cenário em que uma equipe de marketing analisa as tendências de envolvimento do cliente, você implementará a solução nas etapas a seguir:
O processo levará a uma tomada de decisão mais rápida com painéis interativos.
%sql
-- Count the number of interactions per customer segment
SELECT customer_segment, COUNT(*) AS interactions
FROM user_activity
-- Group by customer segment to aggregate interaction counts
GROUP BY customer_segment
-- Order results by interaction count in descending order
ORDER BY interactions DESC;Se você precisar atualizar seus conhecimentos sobre o SQL do Databricks, recomendo a leitura do nosso tutorial do SQL do Databricks para saber como configurar o SQL Warehouse na interface da Web do Databricks.
Ao executar notebooks do Databricks simultaneamente, a depuração e a manutenção do desempenho podem apresentar desafios únicos. Aqui estão algumas ideias para ajudar você a manter seu notebook livre de erros em ambientes de produção.
Aqui estão alguns problemas e soluções recomendadas:
Um notebook que funciona bem individualmente falha quando vários usuários ou trabalhos o executam simultaneamente: Esse problema pode ser causado por variáveis compartilhadas. Além disso, um único cluster pode não suportar várias execuções. Para resolver esse problema, use widgets para parametrização ou use o dimensionamento automático do cluster para garantir que você tenha recursos suficientes para execuções simultâneas.
Um notebook que costumava ser executado rapidamente agora leva muito mais tempo: O problema pode ser devido a transformações ineficientes do Spark que causam problemas de embaralhamento ou muitos caches/conjuntos de dados persistentes que consomem memória. Para resolver esse problema, realize operações usando .persist() e .unpersist(). Além disso, monitore a IU do Spark em busca de partições distorcidas e otimize as consultas com tabelas Delta.
%run falha ao tentar executar outro notebook: Isso pode ocorrer se o caminho do notebook estiver incorreto ou se o notebook referenciado depender de um cluster indisponível. Para resolver esse problema, use caminhos absolutos para importações de notebooks ou verifique a disponibilidade do cluster para garantir que os notebooks referenciados usem um cluster compatível.
Um trabalho de notebook agendado falha: Isso pode ocorrer se o cluster tiver sido encerrado antes da execução ou se uma dependência externa tiver falhado, como uma conexão de banco de dados ou uma chamada de API. Para resolver esse problema, ative a reinicialização do cluster em caso de falha. Nas configurações do trabalho, ative Retry on Failure. Além disso, use blocos Try-Except para chamadas externas.
Leia nosso tutorial Dominando a API do Databricks para saber como usar a API REST do Databricks para agendamento de tarefas e dimensionamento de pipelines automatizados.
Use as técnicas a seguir para manter os Databricks Notebooks em produção:
Modularize o código em notebooks reutilizáveis: Divida cadernos grandes em unidades menores e reutilizáveis e use o site %run para chamá-los. Armazene as funções auxiliares em notebooks de utilitários separados.
Use o controle de versão (integração com o Git): Ative o Databricks Repos para rastrear alterações e reverter versões.
Otimizar a seleção de clusters para trabalhos: Use clusters de trabalho em vez de clusters interativos para execuções agendadas.
Implemente registros e alertas: Use dbutils.notebook.exit() para registrar o status do trabalho. Você também pode configurar alertas de e-mail na interface do usuário do Jobs para notificar as equipes sobre falhas.
Documentar o código e usar Markdown para maior clareza: Use células markdown para descrever as etapas e a lógica do fluxo de trabalho.
Se você quiser explorar os conceitos básicos da Databricks, recomendo fortemente que faça nosso curso Introduction to Databricks. Este curso estabelece o entendimento correto de que você precisa para experimentar recursos avançados, como comandos mágicos, parametrização e otimizações de desempenho. Por fim, também acho que você deveria aprender a obter uma certificação da Databricks. Nossa publicação ajuda você a explorar os benefícios da carreira e a escolher a certificação certa para seus objetivos profissionais.
Aprenda Databricks com o DataCamp
Curso
Curso
Curso
blog
Karlijn Willems
15 min
blog
Wendy Gittleson
15 min
Tutorial
Adam Shafi
Tutorial
Olivia Smith
Tutorial
Javier Canales Luna

