
Cours
Concepts Databricks
4 h
22K
Databricks sert de plateforme analytique unifiée, permettant l'intégration de l'ingénierie des données, de l'apprentissage automatique et de l'analyse commerciale. Au cœur de cet écosystème se trouvent les Databricks Notebooks, des espaces de travail interactifs conçus pour l'exploration des données, le développement de modèles et les flux de production.
Dans cet article, je vous montrerai comment démarrer avec les Databrick Notebooks. Si vous êtes totalement novice, vous pouvez commencer par vous inscrire à notre cours Introduction à Databricks afin de comprendre les tenants et les aboutissants de Databricks et la façon dont il modernise l'architecture des données. Notre cours est très complet et aborde de nombreux sujets, notamment la gestion des catalogues et l'ingestion de données, alors essayez-le.
Les Databricks Notebooks sont des espaces de travail interactifs, basés sur le cloud, qui permettent aux utilisateurs d'effectuer de l'exploration de données, de l'ingénierie, de l'apprentissage automatique et de l'analytique dans un environnement collaboratif. Ils utilisent un modèle d'exécution basé sur des cellules, où les utilisateurs peuvent écrire et exécuter du code dans des blocs discrets ou des cellules.
Databricks Notebooks prend en charge plusieurs langues, ce qui vous permet non seulement de choisir votre langue préférée, mais aussi de passer d'une langue à l'autre au sein d'un même carnet. Ces langages sont notamment Python, SQL, Scala et R, pour lesquels nous proposons des cours d'introduction.
Désormais, pour faciliter l'interopérabilité multilingue, Databricks fournit ce que l'on appelle des commandes magiques :
%python: Exécute une cellule en utilisant Python.
%sql: Exécute des requêtes SQL.
%scala: Traite les commandes basées sur Scala.
%r: Exécute le code R.
Les ordinateurs portables Databricks vont au-delà des environnements de codage traditionnels en offrant les fonctionnalités clés suivantes :
C'est une chose de lire sur les caractéristiques, mais c'en est une autre de les voir de ses propres yeux. La meilleure façon d'apprécier Databricks est de commencer à faire les choses par vous-même. Dans cette section, je vais vous aider à créer, gérer et naviguer dans l'espace de travail Databricks. Ensuite, je suis sûr que vous commencerez à voir par vous-même à quel point il est utile.
Dans l'espace de travail Databricks, vous pouvez créer de nouveaux carnets ou gérer les carnets existants. Examinons ces méthodes ci-dessous.
Pour créer un nouveau carnet dans Databricks :
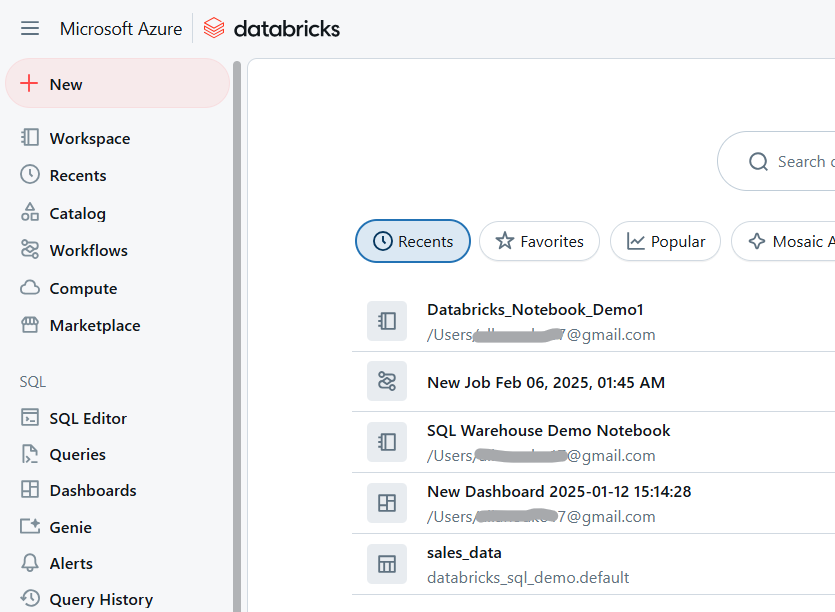
Espace de travail Databricks. Image par l'auteur.
Créez un carnet de notes Databricks. Image par l'auteur.
Sélectionnez le nom et la langue par défaut du Databricks Notebook. Image par l'auteur.
Databricks permet aux utilisateurs d'importer des carnets de notes à partir de plusieurs sources, telles que GitHub et les dépôts Git, des URL externes ou des fichiers locaux téléchargés en tant que fichiers .dbc (archive Databricks) ou .ipynb (Jupyter).
Suivez les étapes suivantes pour importer des carnets de notes existants dans Databricks Workspace :
Importez un carnet de notes existant dans l'espace de travail Databricks. Image par l'auteur.
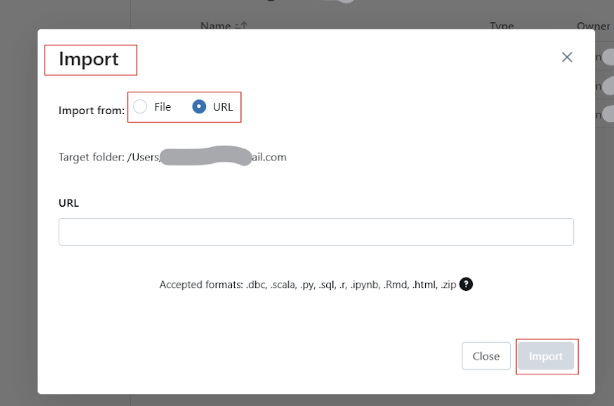
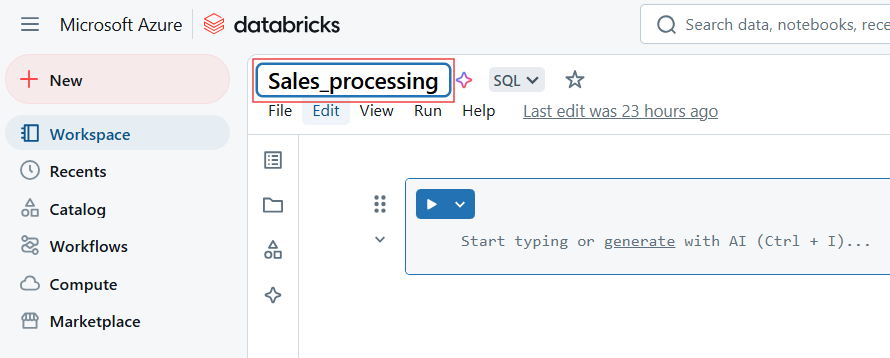
Pour renommer le carnet de notes Databricks, cliquez sur le titre du carnet et modifiez le nom.
Vous pouvez également déplacer des carnets dans des dossiers pour mieux les structurer.
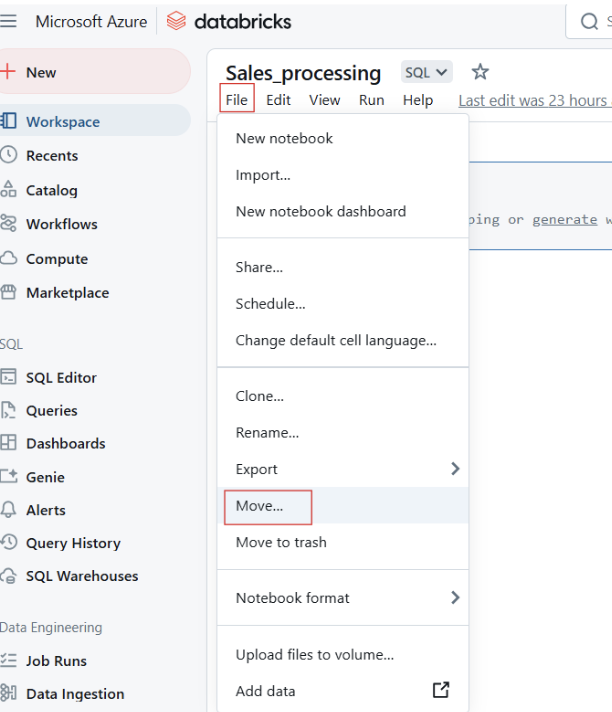
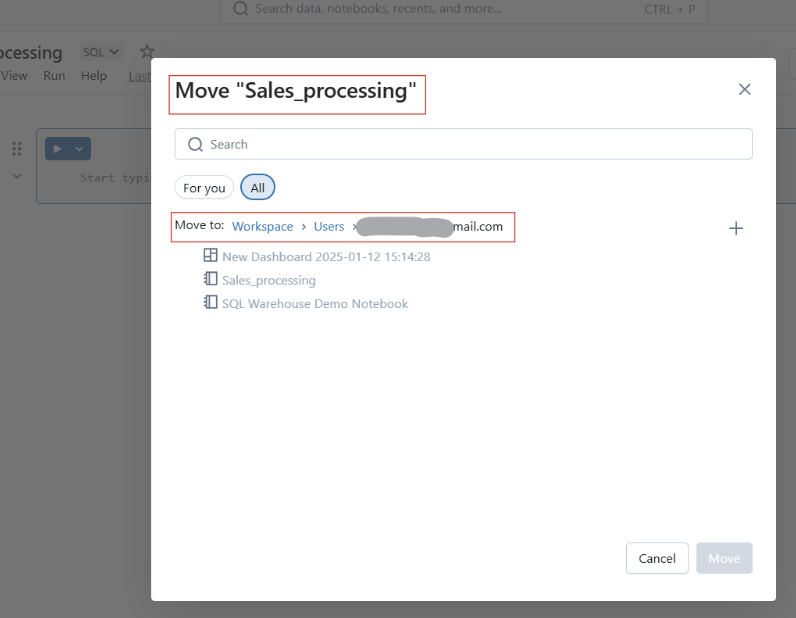
Déplacement des Databricks Notebooks vers un dossier. Image par l'auteur.
Avant de partager votre carnet de notes Datbricks, vous pouvez gérer l'accès et les autorisations afin de contrôler qui peut consulter, modifier ou gérer le carnet de notes.
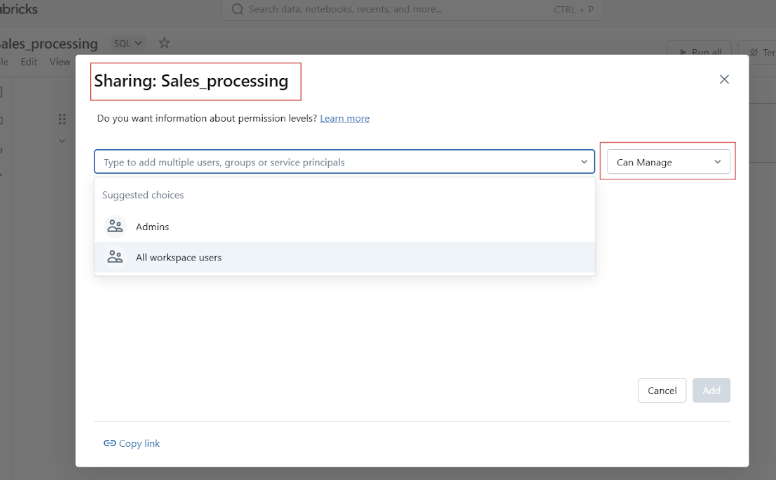
Avant de passer aux exemples pratiques d'utilisation des Notebooks Databricks, permettez-moi de vous présenter l'interface utilisateur et la navigation de la plateforme.
La barre d'outils Databricks Notebook permet d'accéder rapidement aux actions suivantes :
Exécuter, modifier, supprimer ou déplacer la cellule.
Modification des types de cellules tels que code, markdown, SQL ou Scala.
Définir des commandes magiques comme %python ou %sql.
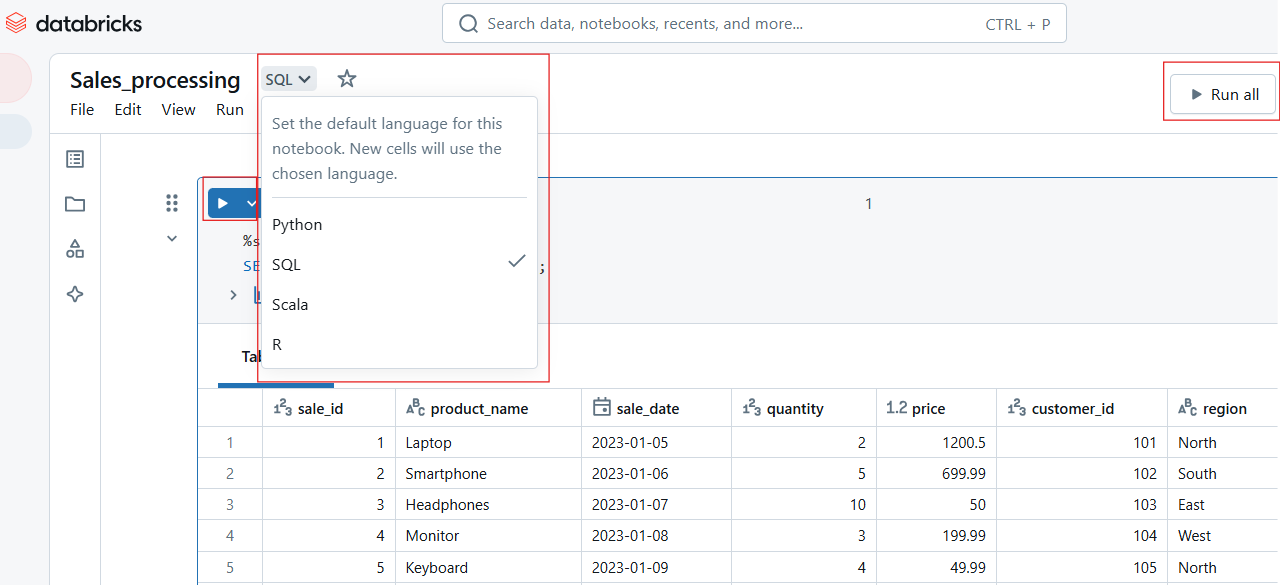
Exécuter une cellule dans Databricks Notebook. Image par l'auteur.
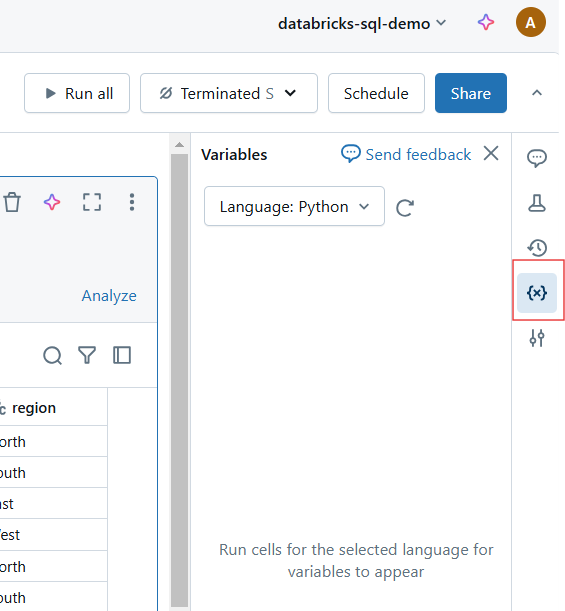
Réinitialiser les variables et l'état d'exécution dans le carnet de notes Databricks. Image par l'auteur.
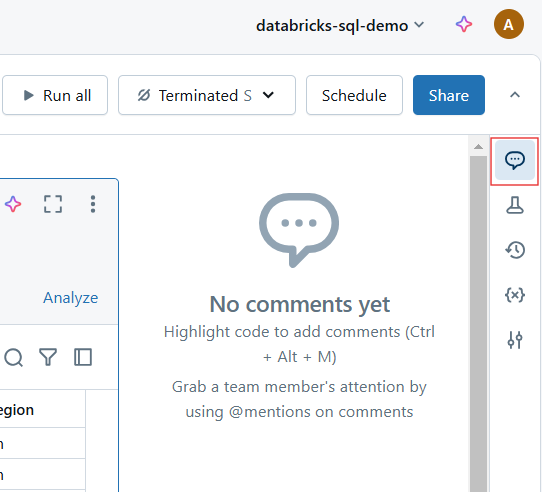
Commentaires dans le carnet de notes Databricks. Image par l'auteur.
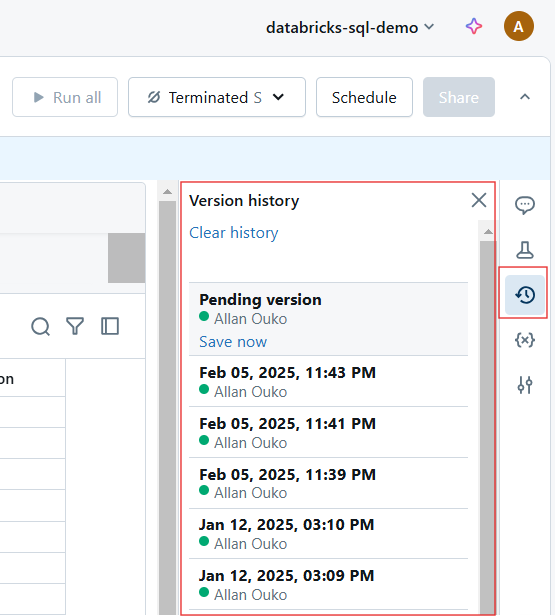
Historique des versions dans Databricks Notebook. Image par l'auteur.
Databricks a apporté plusieurs améliorations à l'interface utilisateur pour une expérience plus intuitive. Grâce à ces améliorations, les Notebooks Databricks offrent un environnement de développement encore plus rationalisé et puissant pour les professionnels des données. Il s'agit notamment des éléments suivants :
Les Databricks Notebooks fournissent un environnement de codage interactif où les utilisateurs peuvent écrire, exécuter et documenter leur code. Dans cette section, j'aborderai le travail avec les cellules de code, le Markdown et l'exécution efficace du code.
Les Notebooks Databricks prennent en charge plusieurs langages, notamment Python, SQL, Scala et R, au sein d'un même notebook.
Utilisez la commande magique %python pour écrire du code Python dans une cellule du carnet de notes Databricks.
%python
import pandas as pd
# Load sample data and display the first few rows
df = spark.read.format("csv").option("header", "true").load("/databricks-datasets/airlines/part-00000")
pd_df = df.limit(5).toPandas() # Convert to Pandas DataFrame
display(pd_df) # Works in Databricks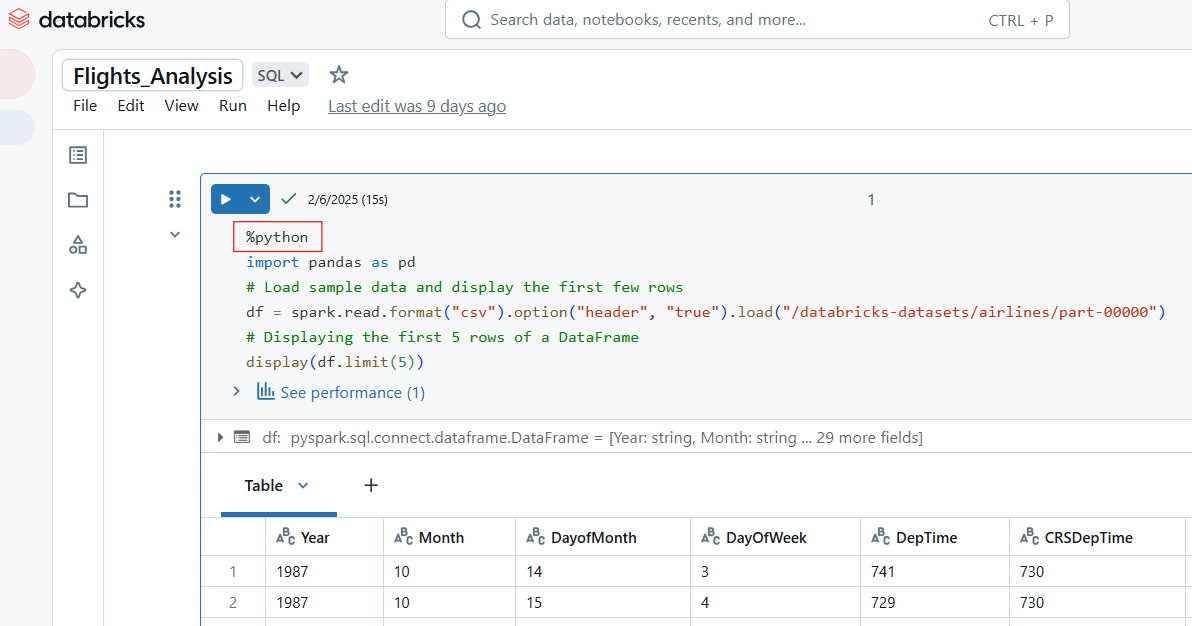
Exemple de code Python dans le carnet de notes Databricks. Image par l'auteur.
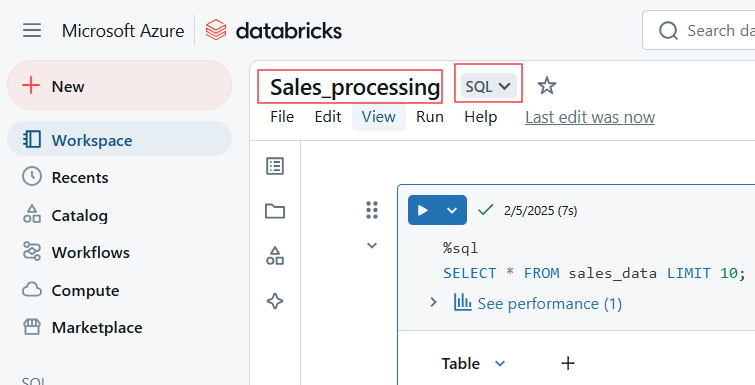
Pour écrire du code SQL dans le Databricks Notebook, utilisez la commande magique %sql. Si vous avez défini SQL comme le langage par défaut de l'ordinateur portable, vous pouvez exécuter la cellule sans inclure la commande magique %sql.
-- Querying a dataset in SQL
SELECT origin, dest, COUNT(*) AS flight_count
FROM flights_table
GROUP BY origin, dest
ORDER BY flight_count DESC
LIMIT 10;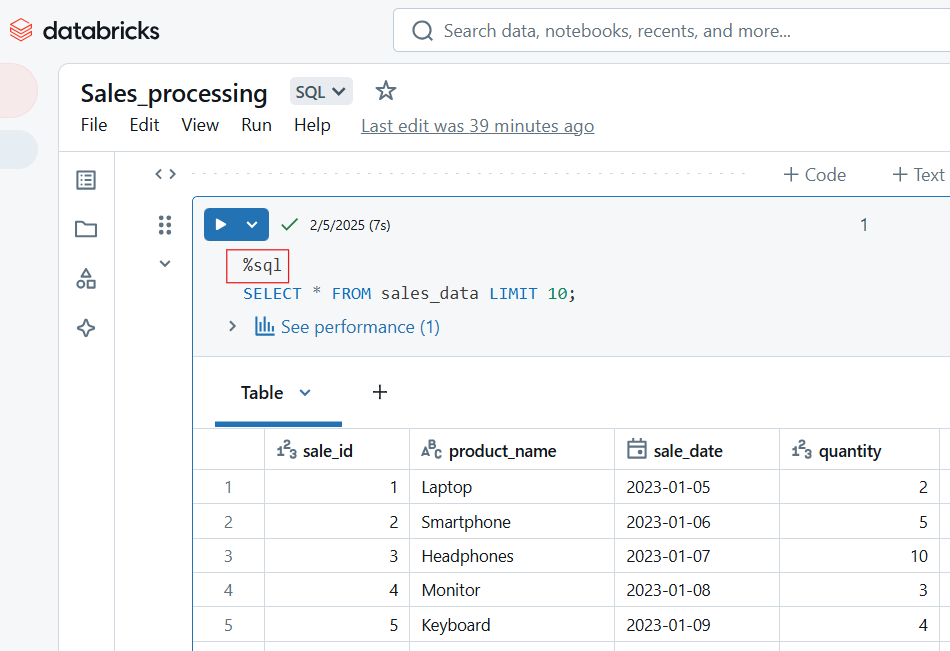
Code SQL dans le carnet de notes Databricks. Image par l'auteur.
Utilisez la commande magique %scala pour écrire du code Scala dans une cellule du carnet de notes Databricks.
%scala
// Reading and displaying data in Scala
val data = spark.read.option("header", "true").csv("/databricks-datasets/airlines/part-00000")
// Display as a table in Databricks
display(data)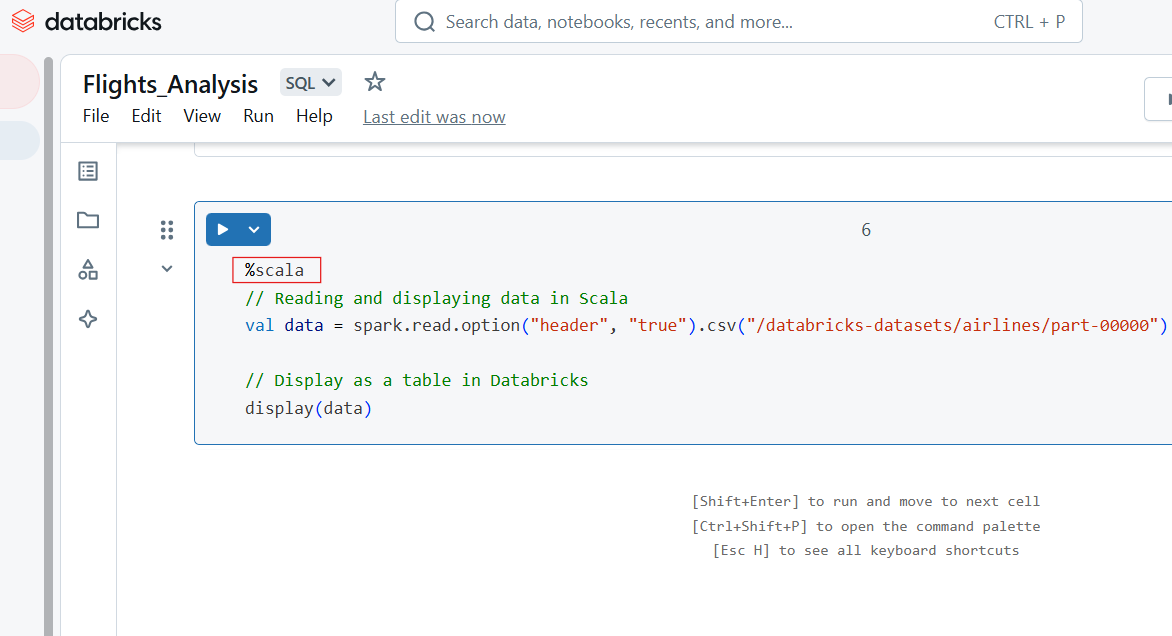
Code Scala dans Databricks Notebook. Image par l'auteur.
Vous pouvez également écrire du code R dans la cellule du carnet de notes Databricks à l'aide de la commande magique %r.
%r
# Load a sample dataset in R
library(SparkR)
df <- read.df("/databricks-datasets/airlines/part-00000", source = "csv", header = "true")
head(df)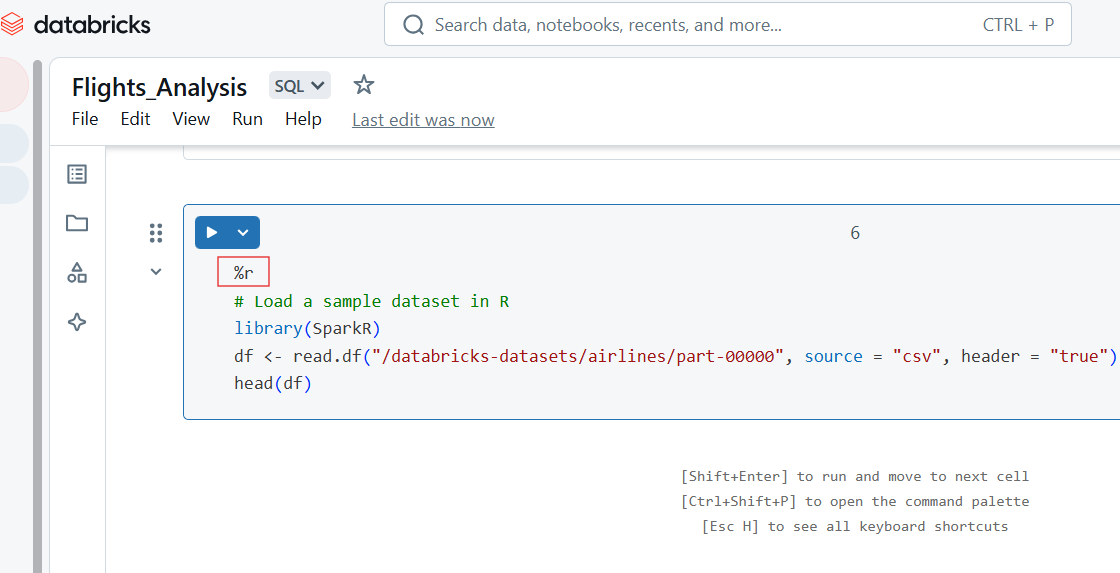
Code R dans Databricks Notebook. Image par l'auteur.
Les cellules Markdown sont utilisées pour ajouter du texte, des titres, des listes et d'autres documents. L'exemple suivant montre comment écrire une cellule Markdown et comment les résultats sont affichés dans Databricks Notebook.
%md
# Data Exploration Notebook
This notebook explores airline flight data, providing insights into flight frequency and destinations.
## **Steps:**
1. Load and display the dataset
2. Query data using SQL
3. Generate visualizations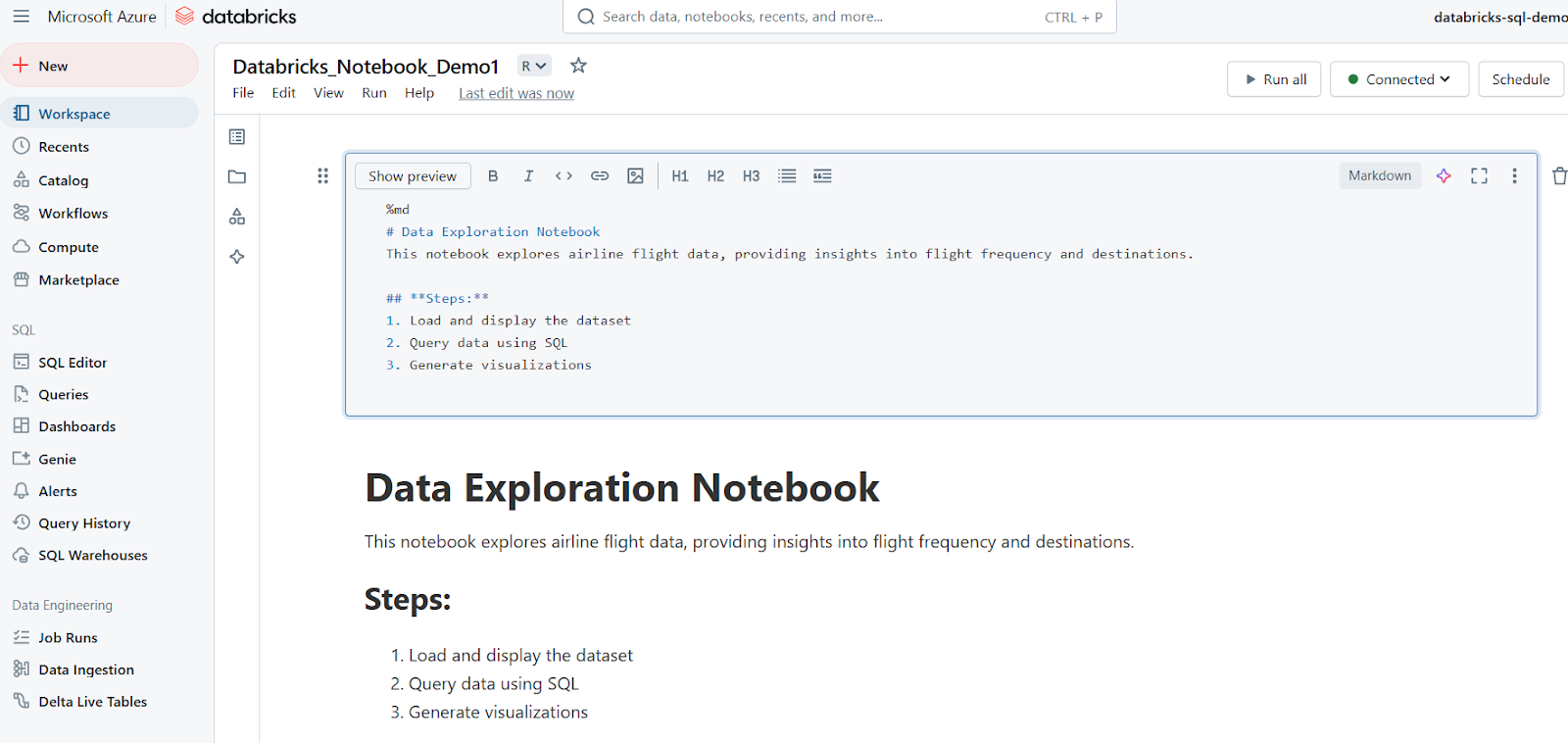
Les ordinateurs portables Databricks permettent une exécution flexible du code par le biais de cellules individuelles ou par lots.
Pour exécuter une seule cellule, cliquez sur le bouton Exécuter (▶) dans la cellule ou utilisez le raccourci clavier :
Pour exécuter toutes les cellules du carnet :
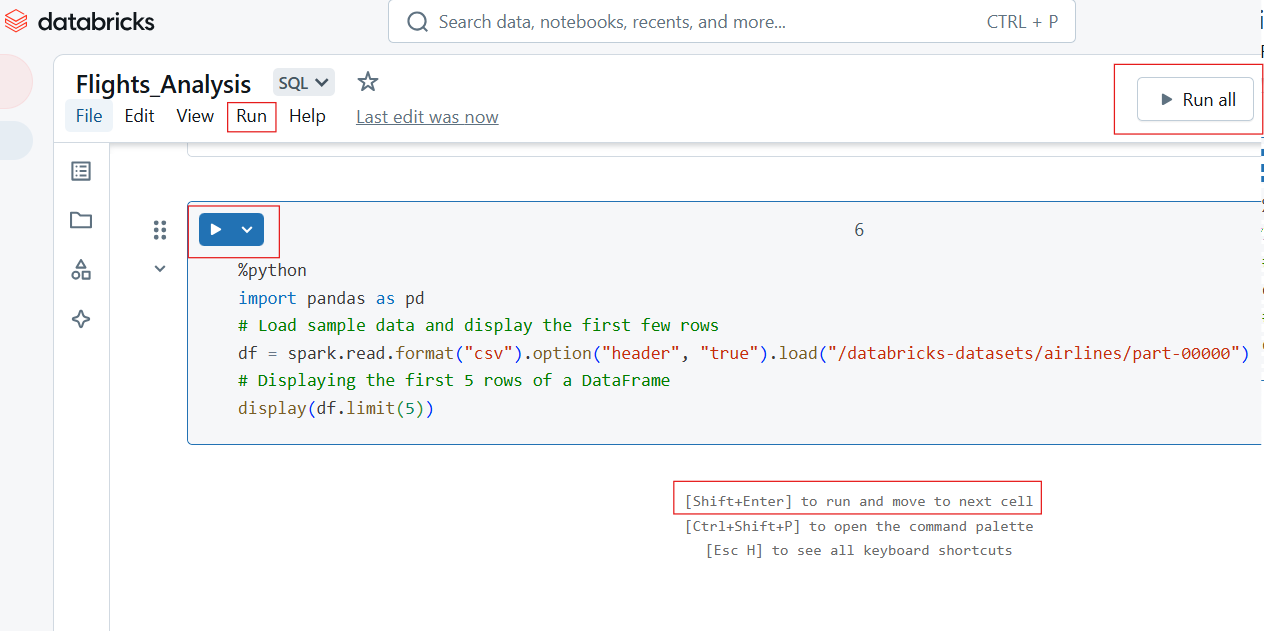
Exécution individuelle et exécution de toutes les cellules dans le carnet de notes Databricks. Image par l'auteur.
Les blocs-notes Databricks prennent en charge plusieurs formats de sortie, notamment des tableaux, des graphiques et des journaux. Par exemple, le code Python suivant affiche les 5 premières lignes de l'ensemble de données "compagnies aériennes".
%python
import pandas as pd
# Load sample data and display the first few rows
df = spark.read.format("csv").option("header", "true").load("/databricks-datasets/airlines/part-00000")
# Displaying the first 5 rows of a DataFrame
display(df.limit(5))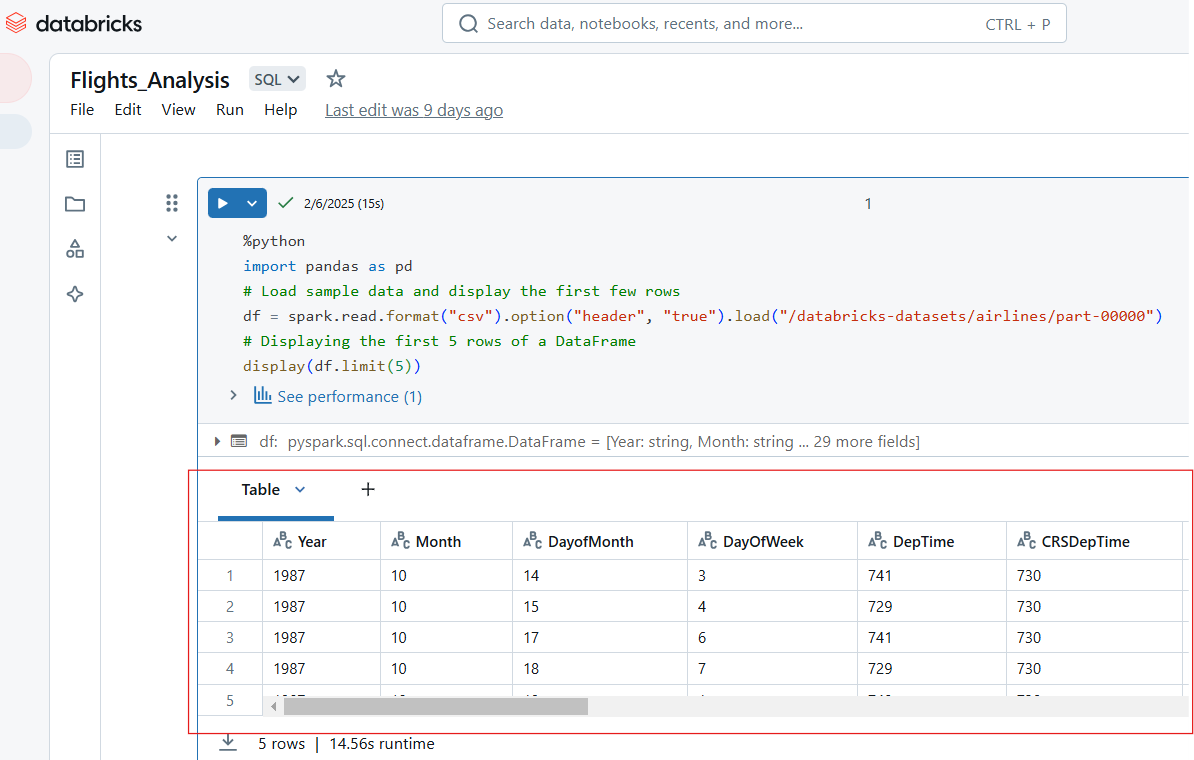
Visualisez les entrées dans le carnet de notes Databricks. Image par l'auteur.
Nous pouvons également utiliser les Databricks Notebooks pour visualiser les résultats des cellules. Par exemple, le code Python ci-dessous sélectionne les 10 compagnies aériennes les plus fréquentes, convertit les données de PySpark à Pandas, puis utilise Matplotlib pour créer un diagramme à barres.
%python
# Import necessary libraries
import matplotlib.pyplot as plt
import pandas as pd
# Load the dataset using PySpark
df = spark.read.option("header", "true").csv("/databricks-datasets/airlines/part-00000")
# Select the top 10 most frequent airlines (carrier column)
top_airlines = df.groupBy("UniqueCarrier").count().orderBy("count", ascending=False).limit(10)
# Convert PySpark DataFrame to Pandas DataFrame
pd_df = top_airlines.toPandas()
# Convert count column to integer (since it's a string in CSV)
pd_df["count"] = pd_df["count"].astype(int)
# Plot a bar chart
plt.figure(figsize=(10, 6))
plt.bar(pd_df["UniqueCarrier"], pd_df["count"], color="#ac4ce4")
# Add titles and labels
plt.xlabel("Airline Carrier", fontsize=12)
plt.ylabel("Flight Count", fontsize=12)
plt.title("Top 10 Most Frequent Airline Carriers", fontsize=14)
plt.xticks(rotation=45) # Rotate x-axis labels for better readability
# Show the plot
plt.show()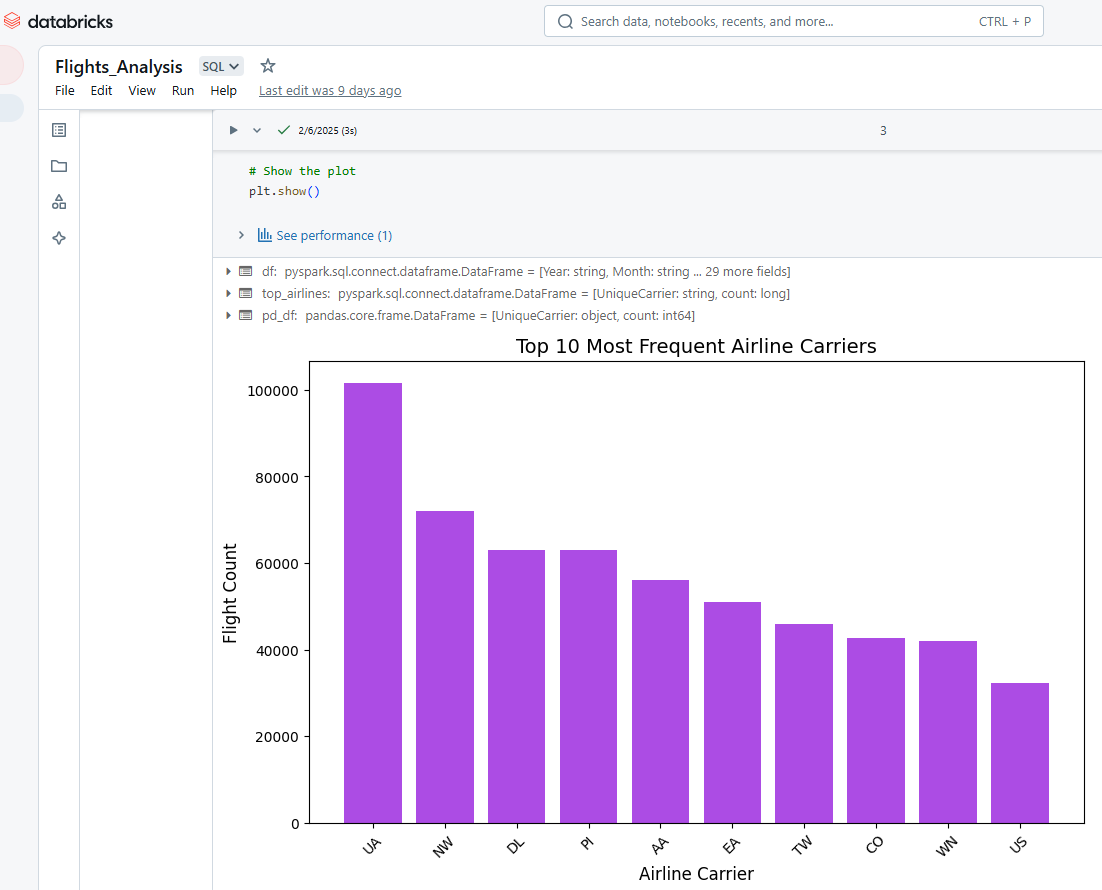
Visualisation des résultats dans Databricks Notebook. Image par l'auteur.
De même, vous pouvez afficher plusieurs résultats de l'exécution d'une seule cellule dans Databricks Notebook. Par exemple, le code ci-dessous affichera les 5 premières lignes de l'ensemble de données sur les compagnies aériennes et le nombre des 10 compagnies aériennes les plus fréquentes.
%python
# Show the top 5 rows in an interactive table
display(df.limit(5))
# Show the top 10 most frequent airline carriers
top_carriers = df.groupBy("UniqueCarrier").count().orderBy("count", ascending=False).limit(10)
display(top_carriers)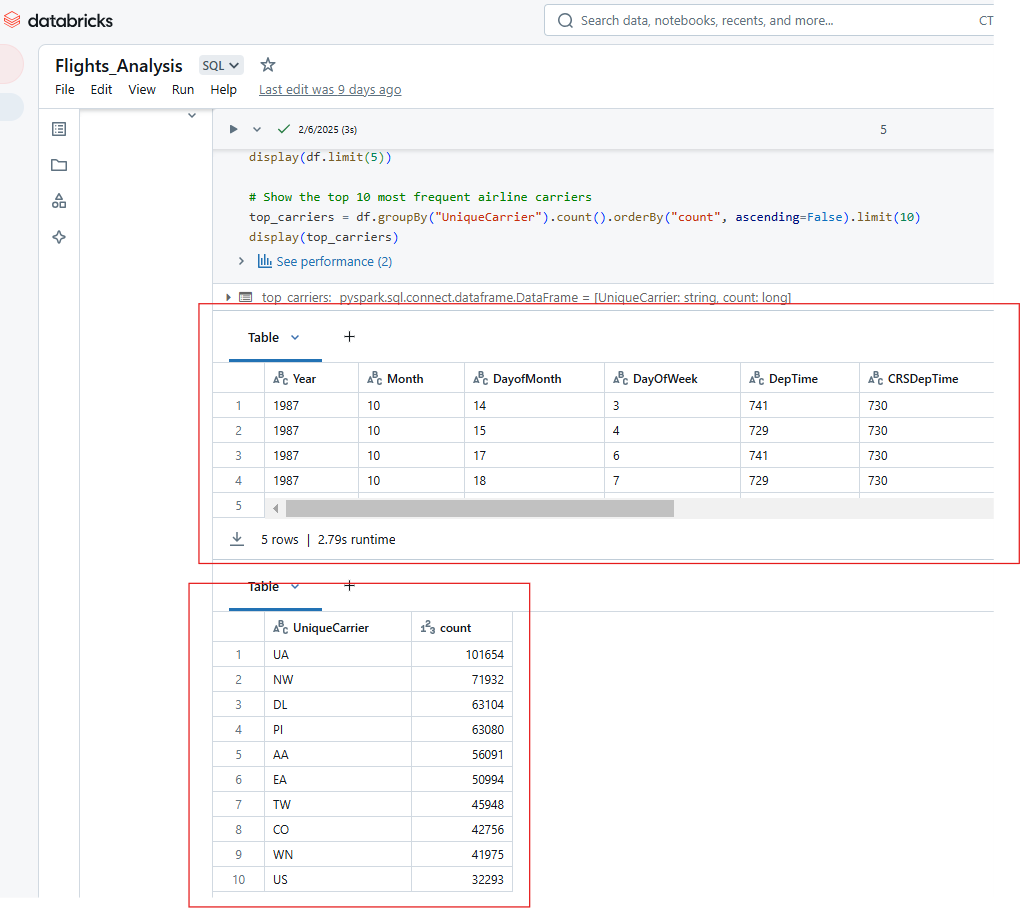
Affichage de plusieurs sorties à partir de l'exécution d'une seule cellule dans Databricks Notebook. Image par l'auteur.
Les Notebooks Databricks offrent de puissantes capacités d'automatisation, de versionnage et d'intégration qui améliorent la productivité, la collaboration et l'efficacité opérationnelle. Dans cette section, je vais explorer les principales fonctionnalités avancées et les meilleures pratiques pour maximiser le potentiel des Databricks Notebooks.
Databricks permet aux utilisateurs d'automatiser l'exécution des ordinateurs portables en les programmant comme des tâches et en paramétrant les entrées pour une exécution dynamique.
Les utilisateurs peuvent programmer l'exécution des blocs-notes à des intervalles spécifiques, ce qui permet d'automatiser les flux de travail pour l'ETL, la création de rapports et la formation aux modèles. Suivez les étapes suivantes pour planifier un travail sur ordinateur portable :
Création d'un Job Run dans Databricks Notebook. Image par l'auteur.
Configuration des horaires et des déclencheurs dans Databricks Notebook. Image par l'auteur.
Exécution de travaux dans Databricks Notebook. Image par l'auteur.
Les widgets Databricks vous permettent de définir des paramètres de manière dynamique, ce qui permet d'exécuter le même bloc-notes avec différentes entrées. Par exemple, le widget dbutils.widgets.text() suivant crée un widget de saisie de texte interactif intitulé "Enter Parameter" avec une valeur par défaut de default_value. Il récupère ensuite la valeur saisie par l'utilisateur dans le widget et l'imprime.
dbutils.widgets.text("input_param", "default_value", "Enter Parameter")
param_value = dbutils.widgets.get("input_param")
print(f"User Input: {param_value}")De même, le code ci-dessous génère un menu déroulant intitulé dataset avec les options sales, marketing et finance, la valeur par défaut étant sales. Il récupère l'option sélectionnée par l'utilisateur et imprime l'ensemble de données choisi.
dbutils.widgets.dropdown("dataset", "sales", ["sales", "marketing", "finance"])
selected_dataset = dbutils.widgets.get("dataset")
print(f"Processing {selected_dataset} dataset")Databricks offre des fonctions intégrées de versionnage et de collaboration, ce qui facilite le suivi des modifications, la restauration des versions précédentes et le travail en équipe en temps réel.
Chaque modification dans un carnet de notes Databricks est automatiquement versionnée. Vous pouvez procéder comme suit pour l'historique des versions :
Consulter l'historique des versions dans le Databricks Notebook. Image par l'auteur.
Les Notebooks de Databricks permettent aux équipes de co-écrire, de commenter et de partager des informations en utilisant les fonctionnalités suivantes :
Databricks Notebooks s'intègre aux tableaux Delta Live, à MLflow, aux entrepôts SQL et aux pipelines CI/CD pour étendre les fonctionnalités.
Les tableaux Delta Live (DLT) simplifient l'automatisation du pipeline de données grâce à l'ETL déclaratif. La requête suivante crée un pipeline de tableaux Delta Live en SQL.
-- Creating a live table called 'sales_cleaned' that stores cleaned data
CREATE LIVE TABLE sales_cleaned AS
-- Selecting all columns where the 'order_status' is 'completed'
SELECT *
FROM raw_sales
WHERE order_status = 'completed'; MLflow, intégré à Databricks, permet de faire le cursus des expériences d'apprentissage automatique. Par exemple, le code ci-dessous enregistre le taux d'apprentissage et la précision d'un modèle d'apprentissage automatique dans MLflow dans le cadre d'une expérience suivie. Après l'enregistrement, il met fin à la session d'expérimentation. Cela vous permet de suivre l'évolution des hyperparamètres et des performances du modèle dans le temps et de comparer différents cursus.
# Import the MLflow library for experiment tracking
import mlflow
mlflow.start_run()
mlflow.log_param("learning_rate", 0.01)
mlflow.log_metric("accuracy", 0.95)
mlflow.end_run()Les Databricks Notebooks peuvent être exportés dans différents formats, dont les suivants :
.html: Partager des rapports en lecture seule.
.ipynb: Convertir en Jupyter Notebooks.
.dbc: Databricks Archive pour la portabilité.
Par exemple, vous pouvez exporter un carnet de notes via l'interface de gestion en utilisant la commande suivante.
databricks workspace export /Users/my_notebook /local/path/my_notebook.ipynbLes ordinateurs portables Databricks offrent une gamme de fonctionnalités puissantes pour rationaliser les flux de travail, améliorer la productivité et la collaboration. Dans cette section, je vous montrerai les commandes magiques, les améliorations de l'interface utilisateur, les techniques d'exploration des données et les stratégies de gestion du code que j'ai trouvées utiles en naviguant sur la plateforme Databricks Notebooks.
Databricks fournit des commandes magiques qui simplifient les tâches, telles que l'exécution de scripts, la gestion de fichiers et l'installation de paquets.
Pour exécuter un autre carnet à l'intérieur du carnet actuel afin de modulariser les flux de travail, vous pouvez utiliser la commande %run. Vous pouvez également utiliser %run pour diviser les grands projets en carnets réutilisables. Par exemple, la commande suivante exécute le carnet data_preprocessing pour que les variables, les fonctions et les sorties soient disponibles dans le carnet actuel.
%run /Users/john.doe/notebooks/data_preprocessingLa commande %sh vous permet d'exécuter des commandes shell Linux directement dans un carnet. Dans l'exemple ci-dessous, la commande énumère le contenu de /dbfs/data/ DBFS.
%sh ls -lh /dbfs/data/De même, la commande %fs vous permet d'interagir avec le système de fichiers Databricks (DBFS) pour les opérations sur les fichiers. Par exemple, la commande ci-dessous répertorie tous les fichiers et répertoires contenus dans /databricks-datasets/, qui contient des jeux de données publics fournis par Databricks.
%fs ls /databricks-datasets/De même, vous pouvez utiliser %fs cp pour la copie de fichiers, %fs rm pour la suppression de fichiers et %fs head pour la prévisualisation de fichiers.
La commande %pip installe les paquets Python dans l'environnement du notebook. La commande suivante installera le paquet matplotlib dans la session courante du notebook.
%pip install pandas matplotlibLa commande %pip freeze est utilisée pour lister les paquets installés et assurer la reproductibilité.
Databricks a introduit les améliorations suivantes de l'interface utilisateur qui améliorent la navigation, le débogage et l'expérience globale de l'utilisateur :
Je recommande toujours d'activer la fonction mode Focus(Affichage → Mode Focus ) pour minimiser les distractions.
Databricks fournit des outils intégrés pour parcourir les ensembles de données, comprendre les schémas et profiler les données directement dans les carnets.
Pour parcourir les ensembles de données dans DBFS, utilisez %fs ls ou display(dbutils.fs.ls()) pour inspecter les ensembles de données disponibles.
display(dbutils.fs.ls("/databricks-datasets/"))Vous pouvez également explorer les schémas de tableaux directement dans la barre latérale de l'interface utilisateur en suivant les étapes ci-dessous :
Pour le profilage des données, vous pouvez résumer les données à l'aide de display() ou de requêtes SQL.
df.describe().show()%sql
SELECT COUNT(*), AVG(salary), MAX(age) FROM employees;Utilisez les techniques suivantes pour gérer votre code dans les Databricks Notebooks. D'une part, veillez à stocker les extraits de code réutilisables dans des carnets distincts et appelez-les en utilisant %run. Utilisez également les utilitaires Databricks (dbutils) pour la transformation. De plus, pour la lisibilité, il est bon de suivre les bonnes pratiques PEP 8 (Python) ou SQL. Utilisez toujours des cellules markdown pour les commentaires.
-- Select customer_id and calculate total revenue per customer
SELECT customer_id, SUM(total_amount) AS revenue
FROM sales_data
-- Group results by customer to get total revenue per customer
GROUP BY customer_id
-- Order customers by revenue in descending order (highest first)
ORDER BY revenue DESC
-- Return only the top 10 customers by revenue
LIMIT 10;Si vous rencontrez des problèmes lorsque vous travaillez avec Databricks Notebooks, vous pouvez les résoudre en utilisant les méthodes suivantes :
Cluster bloqué ? Redémarrez le noyau(Run → Clear State & Restart).
Une exécution lente ? Vérifiez l'interface utilisateur de Spark(Cluster → Spark UI) à la recherche de goulots d'étranglement.
Conflits de versions ? Utilisez %pip list pour vérifier les dépendances.
Utilisez les raccourcis clavier suivants pour coder plus rapidement :
Les Notebooks Databricks sont largement utilisés dans les domaines de l'ingénierie des données, de l'apprentissage automatique et de l'intelligence économique. Dans cette section, je mettrai en évidence des études de cas réels et des extraits de code pour illustrer comment les équipes utilisent les Notebooks Databricks pour les flux de travail de production.
Prenons l'exemple d'une entreprise de vente au détail qui ingère des données brutes sur les ventes, les nettoie et les stocke dans un lac Delta en vue de l'établissement de rapports. La procédure sera la suivante :
Ce processus améliorera la fiabilité des données et la performance des requêtes pour l'établissement des rapports. L'extrait de code ci-dessous est un exemple de mise en œuvre de la solution ci-dessus :
# Read raw sales data from cloud storage
df = spark.read.format("csv").option("header", "true").load("s3://sales-data/raw/")
# Data cleaning and transformation
df_cleaned = df.filter(df["status"] == "completed").dropDuplicates()
# Save to Delta Table for analysis
df_cleaned.write.format("delta").mode("overwrite").saveAsTable("sales_cleaned")Prenons un autre scénario dans lequel une institution financière prédit les défaillances de prêts à l'aide d'un modèle d'apprentissage automatique. Pour mettre en œuvre ce flux de travail dans Databricks Notebook, vous devez suivre les étapes ci-dessous. Il permettra d'automatiser le suivi et le déploiement des modèles avec MLflow.
# import libraries
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import mlflow
# Load and prepare data
df = spark.read.table("loan_data").toPandas()
X_train, X_test, y_train, y_test = train_test_split(df.drop("default", axis=1), df["default"])
# Train model
model = LogisticRegression()
model.fit(X_train, y_train)
# Log model in MLflow
mlflow.sklearn.log_model(model, "loan_default_model")Dans un scénario où une équipe de marketing analyse les tendances en matière d'engagement des clients, vous mettrez en œuvre la solution en suivant les étapes suivantes :
Le processus conduira à une prise de décision plus rapide grâce à des tableaux de bord interactifs.
%sql
-- Count the number of interactions per customer segment
SELECT customer_segment, COUNT(*) AS interactions
FROM user_activity
-- Group by customer segment to aggregate interaction counts
GROUP BY customer_segment
-- Order results by interaction count in descending order
ORDER BY interactions DESC;Si vous avez besoin de rafraîchir vos connaissances sur Databricks SQL, je vous recommande de lire notre tutoriel Databricks SQL pour apprendre à configurer SQL Warehouse à partir de l'interface web de Databricks.
Lors de l'exécution simultanée de notebooks Databricks, le débogage et le maintien des performances peuvent présenter des défis uniques. Voici quelques idées pour vous aider à maintenir votre carnet de notes sans erreur dans les environnements de production.
Voici quelques problèmes et les solutions recommandées :
Un bloc-notes qui fonctionne bien individuellement échoue lorsque plusieurs utilisateurs ou travaux l'exécutent simultanément : Ce problème peut être causé par des variables partagées. En outre, une seule grappe ne peut pas prendre en charge des exécutions multiples. Pour résoudre ce problème, utilisez des widgets pour le paramétrage ou utilisez le cluster autoscaling pour vous assurer que vous disposez de suffisamment de ressources pour les exécutions simultanées.
Un ordinateur portable qui s'exécutait rapidement prend maintenant beaucoup plus de temps : Le problème pourrait être dû à des transformations Spark inefficaces causant des problèmes de brassage ou à un trop grand nombre de caches/ensembles de données persistants consommant de la mémoire. Pour résoudre ce problème, effectuez des opérations en utilisant .persist() et .unpersist(). De plus, surveillez l'interface utilisateur de Spark pour détecter les partitions asymétriques et optimisez les requêtes avec les tableaux Delta.
%run échoue lors de l'exécution d'un autre cahier : Cela peut se produire si le chemin d'accès au carnet de notes est incorrect ou si le carnet de notes référencé dépend d'un cluster indisponible. Pour résoudre ce problème, utilisez des chemins absolus pour les importations d'ordinateurs portables ou vérifiez la disponibilité des clusters pour vous assurer que les ordinateurs portables référencés utilisent un cluster compatible.
Un travail programmé sur l'ordinateur portable échoue : Cela peut se produire si le cluster a été interrompu avant l'exécution ou si une dépendance externe a échoué, comme une connexion à une base de données ou un appel à une API. Pour résoudre ce problème, activez le redémarrage du cluster en cas d'échec. Dans les paramètres du travail, activez l'option Retry on Failure. Utilisez également des blocs Try-Except pour les appels externes.
Lisez notre tutoriel Maîtriser l'API Dat abricks pour apprendre à utiliser l'API REST Databricks pour la planification des tâches et la mise à l'échelle des pipelines automatisés.
Utilisez les techniques suivantes pour maintenir les carnets de notes Databricks lorsqu'ils sont en production :
Modulariser le code en carnets de notes réutilisables : Divisez les grands carnets en unités plus petites et réutilisables et utilisez %run pour les appeler. Stockez les fonctions d'assistance dans des carnets d'utilité distincts.
Utilisez le contrôle de version (intégration Git) : Activez Databricks Repos pour suivre les modifications et revenir en arrière sur les versions.
Optimisez la sélection des clusters pour les emplois : Utilisez des clusters de tâches au lieu de clusters interactifs pour les exécutions planifiées.
Mettre en œuvre la journalisation et les alertes : Utilisez dbutils.notebook.exit() pour enregistrer l'état d'un travail. Vous pouvez également configurer des alertes par courrier électronique dans l'interface Jobs pour informer les équipes des échecs.
Documentez le code et utilisez Markdown pour plus de clarté : Utilisez des cellules markdown pour décrire les étapes et la logique du flux de travail.
Si vous souhaitez explorer les concepts fondamentaux de Databricks, je vous recommande vivement de suivre notre cours Introduction à Databricks. Ce cours vous permet d'acquérir les connaissances nécessaires pour expérimenter des fonctionnalités avancées telles que les commandes magiques, la paramétrisation et l'optimisation des performances. Enfin, je pense que vous devriez apprendre à obtenir une certification Databricks. Notre article vous aide à explorer les avantages professionnels et à choisir la bonne certification en fonction de vos objectifs de carrière.
Apprenez Databricks avec DataCamp
Cours
Cours
Cours