
Curso
Conceptos de Databricks
4 h
22K
Las API de Databricks permiten la interacción programática con Databricks, permitiendo a los usuarios automatizar flujos de trabajo, gestionar clusters, ejecutar trabajos y acceder a los datos. Estas API admiten la autenticación mediante tokens de acceso personales, OAuth o Azure Active Directory.
En este artículo, te guiaré a través de un viaje práctico y en profundidad por la API REST de Databricks. Tanto si eres nuevo en Databricks como si quieres optimizar tus flujos de trabajo actuales, esta guía te ayudará a dominar las operaciones clave, como la autenticación, la gestión de trabajos y la integración con sistemas externos.
Al final de este artículo, tendrás un plan claro para:
Si eres totalmente nuevo en Databricks y quieres aprenderlo rápidamente, lee nuestra entrada del blog, Cómo aprender Databricks: Guía para principiantes de la Plataforma Unificada de Datos, que te ayudará a comprender las principales características y aplicaciones de Databricks, y también te proporcionará un camino estructurado para iniciar tu aprendizaje.
La API REST de Databricks desbloquea potentes capacidades para desarrolladores e ingenieros de datos, permitiéndoles gestionar recursos mediante programación y agilizar los flujos de trabajo. He aquí cómo la API de Databricks puede marcar una gran diferencia:
La API de Databricks permite a los usuarios automatizar tareas como la programación de trabajos y la gestión de clusters. Esto reduce el esfuerzo manual necesario para gestionar estos procesos, liberando tiempo para actividades más estratégicas. Al automatizar las tareas repetitivas, las organizaciones pueden mejorar la eficacia y reducir la probabilidad de errores humanos, que pueden provocar costosos errores o tiempos de inactividad.
La API de Databricks está diseñada para ser flexible y permitir la integración con plataformas externas, como herramientas de orquestación como Apache Airflow o Azure Data Factory.
También puedes utilizar la API de Databricks para sistemas de supervisión y alerta como Prometheus o Datadog. La API de Databricks también se utiliza en canalizaciones de ingestión de datos desde herramientas como Kafka o servicios de datos RESTful. Estas integraciones ayudan a crear flujos de trabajo integrales que unen la ingeniería de datos y la analítica a través de múltiples sistemas.
La API de Databricks admite la creación y gestión de miles de canalizaciones automatizadas. Se escala sin esfuerzo para gestionar miles de trabajos que se ejecutan en paralelo y un escalado dinámico del clúster basado en la demanda de cargas de trabajo. Esta escalabilidad garantiza que tu infraestructura se adapte perfectamente a las necesidades del negocio, incluso a escala empresarial.
La API REST de Databricks ofrece una amplia gama de operaciones para gestionar trabajos, clusters, archivos y permisos de acceso. A continuación, exploraré las operaciones clave de la API con ejemplos prácticos para ayudarte a construir y automatizar flujos de trabajo sólidos.
Los trabajos son la columna vertebral de los flujos de trabajo automatizados en Databricks. La API te permite crear, gestionar y supervisar trabajos sin problemas.
Utiliza el punto final POST /API/2.1/jobs/create para definir un nuevo trabajo. Por ejemplo, la siguiente carga JSON crea un nuevo trabajo Databricks llamado My Job y ejecuta un bloc de notas ubicado en /path/to/notebook. La carga útil utiliza entonces un cluster existente con el ID cluster-id, evitando la necesidad de crear uno nuevo. Si el trabajo falla, la carga útil enviará una notificación por correo electrónico a user@example.com.
{
"name": "My Job",
"existing_cluster_id": "cluster-id",
"notebook_task": {
"notebook_path": "/path/to/notebook"
},
"email_notifications": {
"on_failure": ["user@example.com"]
}
}Puedes utilizar el punto final GET /api/2.1/jobs/list para recuperar una lista de todos los trabajos de tu espacio de trabajo. Por ejemplo, el siguiente comando de ejemplo listará todos los trabajos:
curl -n -X GET \
https://<databricks-instance>.cloud.databricks.com/api/2.1/jobs/listUtiliza el punto final POST /api/2.1/jobs/run-now para activar la ejecución inmediata de un trabajo.
curl -n -X POST \
https://<databricks-instance>.cloud.databricks.com/api/2.1/jobs/run-now?job_id=123456789Aunque la última versión de la API no tiene un punto final directo para eliminar trabajos, puedes gestionar las ejecuciones de trabajos y su ciclo de vida a través de otros puntos finales. Utiliza el punto final Eliminar un trabajo: POST /api/2.1/jobs/delete para eliminar un trabajo y POST /api/2.1/jobs/runs/cancel para cancelar una ejecución.
Utiliza GET /api/2.1/jobs/runs/get para controlar el estado de un trabajo. Recupera registros o gestiona errores utilizando el campo run_state.
Los clusters proporcionan los recursos informáticos para ejecutar los trabajos. La API simplifica la gestión del ciclo de vida del clúster.
Crea un clúster con POST /api/2.1/clusters/create. Por ejemplo, puedes tener lo siguiente en el cuerpo de la solicitud.
{
"cluster_name": "Example Cluster",
"spark_version": "12.2.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 4
}A continuación, ejecuta el comando de ejemplo que aparece a continuación para crear este clúster.
curl -n -X POST \
-H 'Content-Type: application/json' \
-d '{"cluster_name": "My Cluster", "spark_version": "7.3.x-scala2.12", "node_type_id": "i3.xlarge", "num_workers": 2}' \
https://<databricks-instance>.cloud.databricks.com/api/2.1/clusters/createUtiliza las siguientes API para:
Iniciar Clúster: POST /api/2.1/clusters/start
Reinicia el Cluster: POST /api/2.1/clusters/restart
Redimensiona el Cluster: PATCH /api/2.1/clusters/edit
Finaliza el Cluster: POST /api/2.1/clusters/delete
Considera las siguientes buenas prácticas para:
DBFS permite almacenar y recuperar archivos en Databricks.
Puedes utilizar la API POST /api/2.1/dbfs/upload para subir archivos a DBFS en trozos (multiparte) o cuando manejes archivos grandes (>1MB). La API GET /api/2.1/dbfs/read se utiliza para descargar archivos.
Utiliza GET /api/2.1/dbfs/list para explorar directorios y gestionar archivos mediante programación. Para subir archivos grandes, utiliza subidas por trozos con POST /api/2.1/dbfs/put y el parámetro overwrite.
La API Secretos garantiza el almacenamiento y la recuperación seguros de información sensible.
Utiliza el punto final POST /api/2.1/secrets/create para crear un nuevo secreto para almacenar información sensible.
Por ejemplo, puedes crear el cuerpo de la petición en JSON de la siguiente manera:
{
"scope": "my-scope",
"key": "my-key",
"string_value": "my-secret-value"
}A continuación, crea el secreto utilizando el siguiente comando:
curl -n -X POST \
-H 'Content-Type: application/json' \
-d '{"scope": "my-scope", "key": "my-key", "string_value": "my-secret-value"}' \
https://<databricks-instance>.cloud.databricks.com/api/2.1/secrets/createUtiliza el punto final GET /API/2.1/secrets/get para recuperar secretos de integraciones externas.
La plataforma Databricks permite un control granular del acceso a los trabajos y recursos.
Utiliza el punto final POST /api/2.1/permissions/jobs/update para asignar funciones como propietarios o espectadores. Por ejemplo, la siguiente carga útil se utiliza para actualizar los permisos:
{
"access_control_list": [
{
"user_name": "user@example.com",
"permission_level": "CAN_MANAGE"
}
]
}Utiliza el control de acceso basado en roles (RBAC) integrado de Databricks para gestionar los permisos de los distintos roles de tu organización.
Cuando trabajes con la API REST de Databricks, es importante tener en cuenta los límites de velocidad, gestionar los errores con elegancia y afrontar los retos habituales para garantizar un rendimiento fiable y unas operaciones fluidas. En esta sección, trataré las estrategias para optimizar el uso de la API y solucionar los problemas de forma eficaz.
La API de Databricks aplica límites de tarifa para garantizar un uso justo y mantener la fiabilidad del servicio.
A continuación se indican los problemas habituales que puedes experimentar con las API de Databricks y cómo resolverlos.
Si te encuentras con cuellos de botella en el rendimiento, debes considerar las siguientes soluciones:
La API REST de Databricks es muy versátil, ya que admite tanto flujos de trabajo sencillos de un solo hilo como complejos procesamientos en paralelo. Aprovechando los flujos de trabajo avanzados, puedes optimizar la eficacia e integrarte sin problemas con sistemas externos. Veamos cómo aplicar estas funciones.
Como nota, configura siempre tus variables de entorno utilizando:
DATABRICKS_HOST: Esta variable almacena la URL de tu instancia de Databricks, que es necesaria para construir peticiones API.
DATABRICKS_TOKEN: Esta variable contiene tu token de acceso, simplificando el proceso de incluirlo en las llamadas a la API.
Llamar secuencialmente a un único punto final de la API es eficaz para tareas más pequeñas o automatizaciones sencillas. A continuación se muestra un ejemplo práctico utilizando la biblioteca requests en Python.
import requests
import os
# Set up environment variables
DATABRICKS_HOST = os.getenv("DATABRICKS_HOST")
DATABRICKS_TOKEN = os.getenv("DATABRICKS_TOKEN")
# API request to list jobs
url = f"{DATABRICKS_HOST}/api/2.1/jobs/list"
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}
response = requests.get(url, headers=headers)
if response.status_code == 200:
jobs = response.json().get("jobs", [])
for job in jobs:
print(f"Job ID: {job['job_id']}, Name: {job['settings']['name']}")
else:
print(f"Error: {response.status_code} - {response.text}")El procesamiento paralelo puede mejorar significativamente la eficiencia de la ingestión de datos a gran escala o cuando se trata de múltiples puntos finales. El siguiente ejemplo muestra cómo utilizar Apache Spark para distribuir llamadas a la API de forma concurrente.
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
import requests
# Initialize Spark session
spark = SparkSession.builder.appName("ParallelAPI").getOrCreate()
# Sample data for parallel calls
data = [{"job_id": 123}, {"job_id": 456}, {"job_id": 789}]
df = spark.createDataFrame(data)
# Define API call function
def fetch_job_details(job_id):
url = f"{DATABRICKS_HOST}/api/2.1/jobs/get"
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}
response = requests.get(url, headers=headers, params={"job_id": job_id})
if response.status_code == 200:
return response.json().get("settings", {}).get("name", "Unknown")
return f"Error: {response.status_code}"
# Register UDF
fetch_job_details_udf = udf(fetch_job_details)
# Apply UDF to DataFrame
results_df = df.withColumn("job_name", fetch_job_details_udf("job_id"))
results_df.show()Ten en cuenta los siguientes consejos para compensar la escalabilidad y los costes.
Integrar Databricks con orquestadores externos como Airflow o Dagster te permite gestionar flujos de trabajo complejos y automatizar la ejecución de trabajos en distintos sistemas. El siguiente ejemplo muestra cómo utilizar Airflow para activar un trabajo Databricks.
from airflow import DAG
from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator
from datetime import datetime
# Define default arguments for the DAG
default_args = {
"owner": "airflow", # Owner of the DAG
"depends_on_past": False, # Do not depend on past DAG runs
"retries": 1, # Number of retry attempts in case of failure
}
# Define the DAG
with DAG(
dag_id="databricks_job_trigger", # Unique DAG ID
default_args=default_args, # Apply default arguments
schedule_interval=None, # Manually triggered DAG (no schedule)
start_date=datetime(2023, 1, 1), # DAG start date
) as dag:
# Task to trigger a Databricks job
run_job = DatabricksRunNowOperator(
task_id="run_databricks_job", # Unique task ID
databricks_conn_id="databricks_default", # Connection ID for Databricks
job_id=12345, # Replace with the actual Databricks job ID
)
# Set task dependencies (if needed)
run_jobPara las canalizaciones CI/CD, herramientas como la integración de Git con Databricks pueden automatizar el despliegue de código y activos en distintos entornos. Esto garantiza que los cambios se prueben y validen antes de pasar a producción.
# Example of using Databricks REST API in a CI/CD pipeline
import requests
def deploy_to_production():
# Assuming you have a personal access token
token = "your_token_here"
headers = {"Authorization": f"Bearer {token}"}
# Update job or cluster configurations as needed
url = "https://your-databricks-instance.cloud.databricks.com/api/2.1/jobs/update"
payload = {"job_id": "123456789", "new_settings": {"key": "value"}}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
print("Deployment successful.")
else:
print(f"Deployment failed. Status code: {response.status_code}")Ahora que hemos visto las diferentes aplicaciones de la API de Databricks, déjame que te guíe a través de un ejemplo de canalización automatizada. Esta canalización ingiere datos de una API externa, los transforma en Databricks y, a continuación, escribe los resultados en una tabla de Databricks. Este escenario es un flujo de trabajo típico de principio a fin para las tareas modernas de ingeniería de datos. Si necesitas refrescar tus conocimientos sobre las principales funciones de Databricks, incluida la ingesta de datos, te recomiendo que consultes nuestro tutorial sobre los 7 conceptos que todo especialista en datos debe conocer.
Para interactuar con la API REST de Databricks, necesitas autenticarte utilizando un Token de Acceso Personal (PAT). Sigue estos pasos para generar el PAT.
Espacio de trabajo Databricks. Imagen del autor.
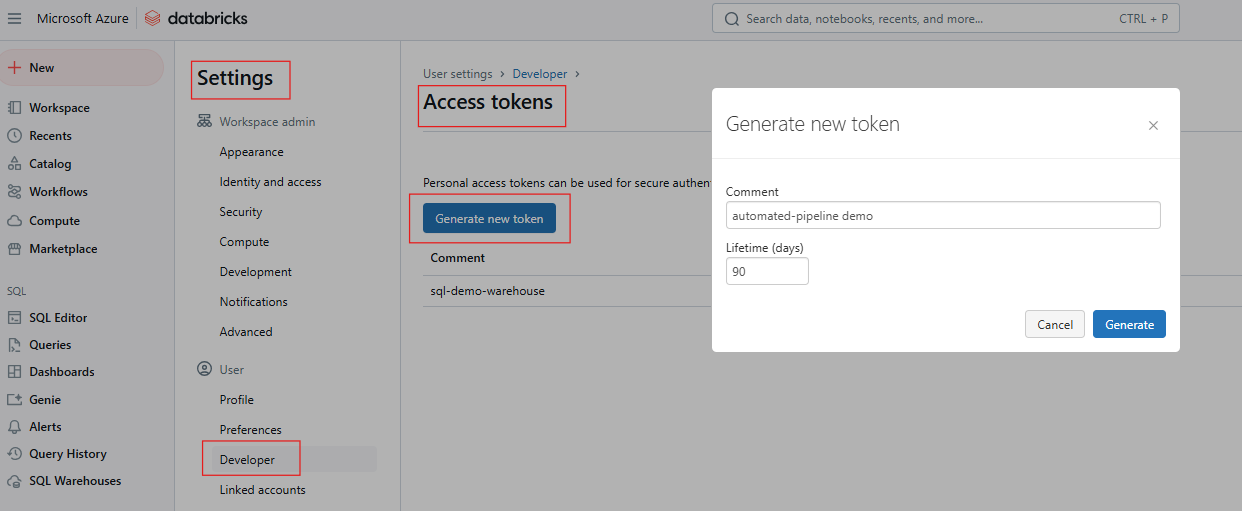
Generar token de acceso en Databricks. Imagen del autor.
Si necesitas refrescar tus conocimientos sobre SQL de Databricks, te recomiendo que leas nuestro tutorial sobre SQL de Databricks para aprender a configurar SQL Warehouse desde la interfaz web de Databricks.
Configura las variables de entorno utilizando una de las siguientes opciones:
export DATABRICKS_HOST=https://<your-databricks-instance>
export DATABRICKS_TOKEN=<your-access-token>import os
import requests
DATABRICKS_HOST = os.getenv("DATABRICKS_HOST")
DATABRICKS_TOKEN = os.getenv("DATABRICKS_TOKEN")
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}Un trabajo Databricks puede constar de varias tareas, cada una de las cuales realiza un paso en el pipeline. Para este ejemplo, considera lo siguiente:
El siguiente ejemplo utiliza el endpoint POST /api/2.1/jobs/create para crear el trabajo.
{
"name": "Multi-Step Pipeline",
"tasks": [
{
"task_key": "fetch_data",
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/fetch_data"
}
},
{
"task_key": "transform_data",
"depends_on": [{"task_key": "fetch_data"}],
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/transform_data"
}
},
{
"task_key": "write_results",
"depends_on": [{"task_key": "transform_data"}],
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/write_results"
}
}
]
}Activa el trabajo con POST /api/2.1/jobs/run-now
curl -n -X POST \
https://$DATABRICKS_HOST/api/2.1/jobs/run-now?job_id=your_job_idSupervisa el estado del trabajo utilizando GET /api/2.1/jobs/runs/get con el run_id para seguir el progreso.
response = requests.get(f"{DATABRICKS_HOST}/api/2.1/jobs/runs/get", headers=headers, params={"run_id": run_id})
print(response.json())Accede a los registros de salida, o a los resultados de las tareas utilizando GET /api/2.1/jobs/runs/get-output.
Para el registro, configura los registros de trabajo para que se escriban en DBFS o en una herramienta de supervisión como Datadog o Splunk. Además, incluye un registro detallado en el cuaderno de cada tarea para una mejor trazabilidad.
Del mismo modo, implementa bloques try-except en los cuadernos para capturar y registrar excepciones. Utiliza la API de trabajos de Databricks para recuperar los registros de trabajos para depurar las ejecuciones fallidas. El siguiente ejemplo muestra el tratamiento de errores en un bloc de notas.
try:
# Code to fetch data from API
response = requests.get(api_url)
# Process data
except Exception as e:
print(f"An error occurred: {e}")
# Log error and exitTambién puedes integrarlo con notificaciones por correo electrónico o Slack utilizando la API de Alertas de Databricks o herramientas de terceros.
La aplicación de las mejores prácticas en Databricks puede aumentar significativamente la seguridad, reducir los costes y mejorar la fiabilidad general del sistema. A continuación se indican las estrategias clave que debes tener en cuenta al utilizar la API de Databricks y las áreas críticas.
Evita almacenar fichas simples en código o cuadernos. En su lugar, utiliza Databricks Secret para almacenar información sensible como claves API o credenciales de forma segura utilizando la API Databricks Secrets. Esto garantiza que los datos sensibles no queden expuestos en texto plano dentro del código o de los cuadernos. Utiliza siempre variables de entorno para pasar tokens o secretos a los scripts, pero asegúrate de que estas variables se gestionan de forma segura y no se envían al control de versiones.
Utiliza el Control de Acceso Basado en Funciones (RBAC) para definir los permisos a nivel de espacio de trabajo, clúster y trabajo, y limita el acceso a las API sensibles sólo a los usuarios o cuentas de servicio necesarios.
Para una gestión eficaz de los costes, considera la posibilidad de utilizar Clusters de un solo nodo para tareas continuas y de baja carga. Sin embargo, pueden ser rentables si no se utilizan plenamente. Además, los clusters de trabajos efímeros se crean y finalizan automáticamente para los trabajos, garantizando que los recursos no estén ociosos.
Debido a los precios dinámicos de los recursos de la nube, la programación fuera de horas punta puede reducir significativamente los costes. Utiliza la API de Trabajos para definir programaciones de trabajos durante ventanas de tiempo rentables.
Por último, supervisa el uso del clúster comprobando regularmente su utilización para asegurarte de que no se desperdician recursos. Configura los clusters para que finalicen automáticamente tras un tiempo de inactividad especificado, para evitar costes innecesarios.
Para las pruebas automatizadas y las definiciones de trabajo, utiliza pruebas unitarias para implementar pruebas unitarias para la lógica del trabajo, con el fin de detectar errores a tiempo. Supervisa las ejecuciones de los trabajos y registra las métricas de rendimiento para aprovechar la API de Trabajos para realizar un seguimiento programático de las ejecuciones de los trabajos y analizar los datos históricos de las ejecuciones:
El uso de la API REST de Databricks permite a los equipos automatizar los flujos de trabajo, optimizar los costes e integrarse a la perfección con sistemas externos, transformando el modo en que se gestionan las canalizaciones de datos y los análisis. Te animo a que empieces probando una llamada básica a la API, como crear un trabajo, para coger confianza con la plataforma. También puedes explorar otros temas avanzados como el Catálogo de Unity para una gobernanza detallada o sumergirte en casos de uso de streaming en tiempo real.
Además, te recomiendo que consultes los documentos oficiales de la API REST de Databricks para que te ayuden a responder a las preguntas pendientes, y que explores los repositorios de GitHub sobre la CLI de Databricks y el SDK de Databricks para Python para aprender más sobre el desarrollo optimizado.
Si quieres explorar los conceptos fundamentales de Databricks, te recomiendo encarecidamente que sigas nuestro curso Introducción a Databricks. Este curso te enseña Databricks como solución de almacenamiento de datos para Business Intelligence. También te recomiendo que eches un vistazo a nuestra entrada del blog Certificaciones Dat abricks En 2024 para saber cómo obtener certificaciones Databricks, explorar las ventajas profesionales y elegir la certificación adecuada para tus objetivos profesionales.
Aprende Cloud con DataCamp
Curso
Curso
Curso
blog
Gus Frazer
14 min
blog
Mike Shakhomirov
11 min
blog
Joleen Bothma
12 min
blog
Abid Ali Awan
15 min
Tutorial
Natassha Selvaraj
