
programa
Desarrollo de aplicaciones de IA
21 h
Gemma 3n es la última familia de modelos multimodales de peso abierto de Google AI, diseñados para funcionar eficazmente en dispositivos cotidianos como teléfonos, tabletas y ordenadores portátiles. Construido sobre una novela MatFormer con soporte para el almacenamiento en caché de parámetros Per-Layer Embedding (PLE), Gemma 3n ofrece rendimiento en el dispositivo al tiempo que minimiza los costes de memoria y computación.
Aunque son similares a los modelos de visión-lenguaje (VLM) tradicionalesGemma 3n admite las modalidades de texto, imagen y audio. Su variante "3n" está optimizada específicamente para el despliegue en el borde, con una ejecución ligera en CPUs, NPUs o GPUs móviles a través del SDK AI Edge de Google.
Estas son las principales características de Gemma 3n:
Nota importante: aunque Gemma 3n admite entradas de audio en su arquitectura completa, las capacidades de audio aún no están disponibles en la vista previa pública.
Puedes probar Gemma 3n utilizando uno de estos tres métodos:
.task de Gemma 3n está publicado en el formato ai-edge-litert de Google. Puedes solicitar acceso a la página de modelos de Hugging Face y descargar el modelo localmente para su inferencia. Un archivo .task es un paquete compacto y fácil de ejecutar que contiene una versión precompilada del modelo, sus metadatos y todas las configuraciones necesarias, diseñado específicamente para una ejecución rápida y segura en el dispositivo mediante el SDK AI Edge de Google.A continuación, te guiaré en la construcción de una aplicación Android que funcione y que utilice el modelo Gemma 3n para procesar indicaciones de imagen y texto. Utilizaremos el repositorio oficial de la Galería de Google como base y lo personalizaremos para que se abra directamente en la pantalla de Preguntar Imagen sin distracciones.
Empecemos creando un nuevo proyecto y clonando el repositorio original de Google.
En tu portátil, empieza abriendo el proyecto como un nuevo proyecto en Android Studio y selecciona una Actividad vacía.
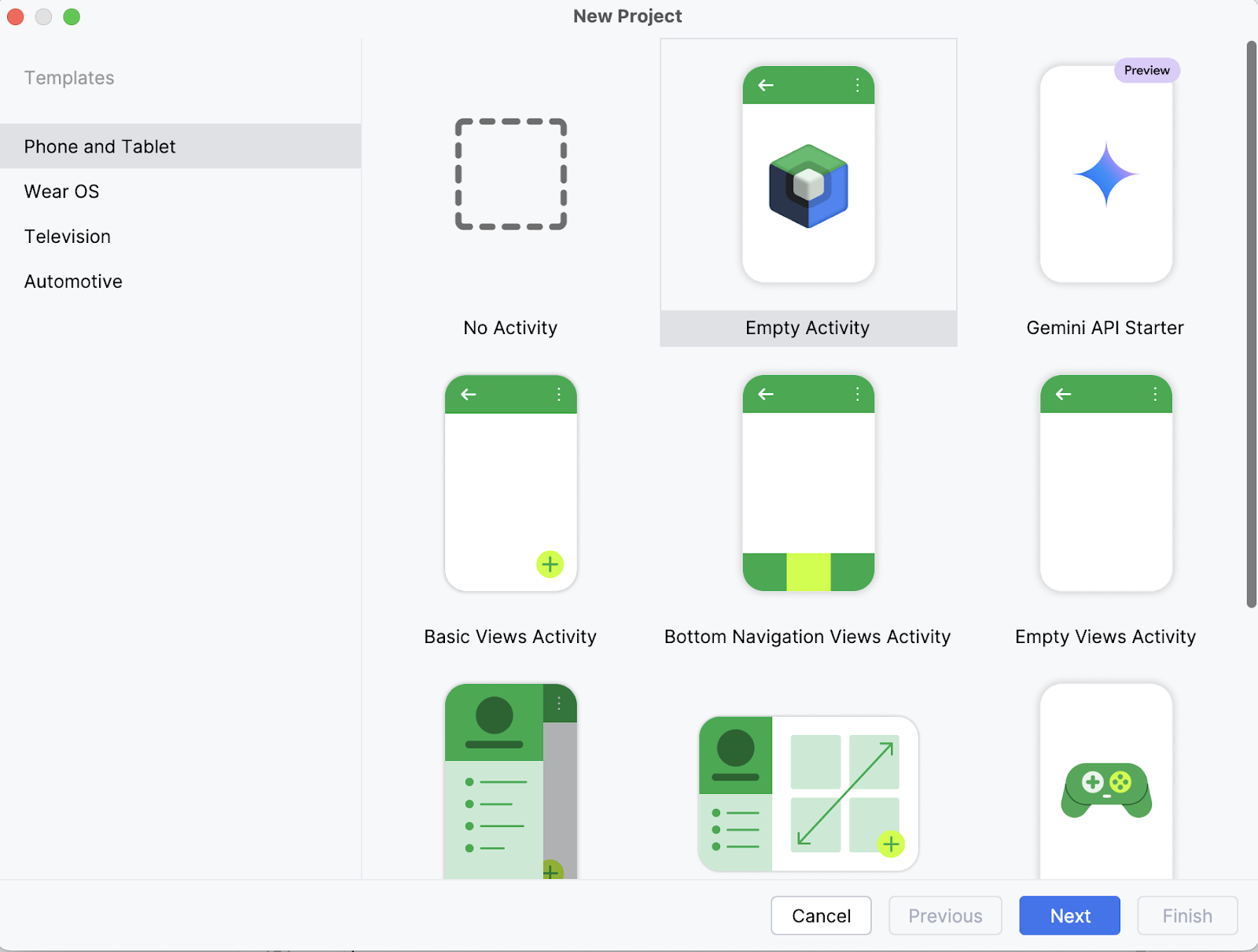
A continuación, rellena el nombre de tu actividad (por ejemplo, "Pregunta_Imagen_Demo") y mantén el resto tal cual. Luego, haz clic en Finalizar.
Ahora, abre el terminal dentro de Android Studio (esquina inferior izquierda) y ejecuta los siguientes comandos bash:
git clone https://github.com/google-ai-edge/gallery
cd gallery/android
Esto abrirá tu proyecto. Puedes ver todos los archivos del proyecto en la parte izquierda de la pestaña.
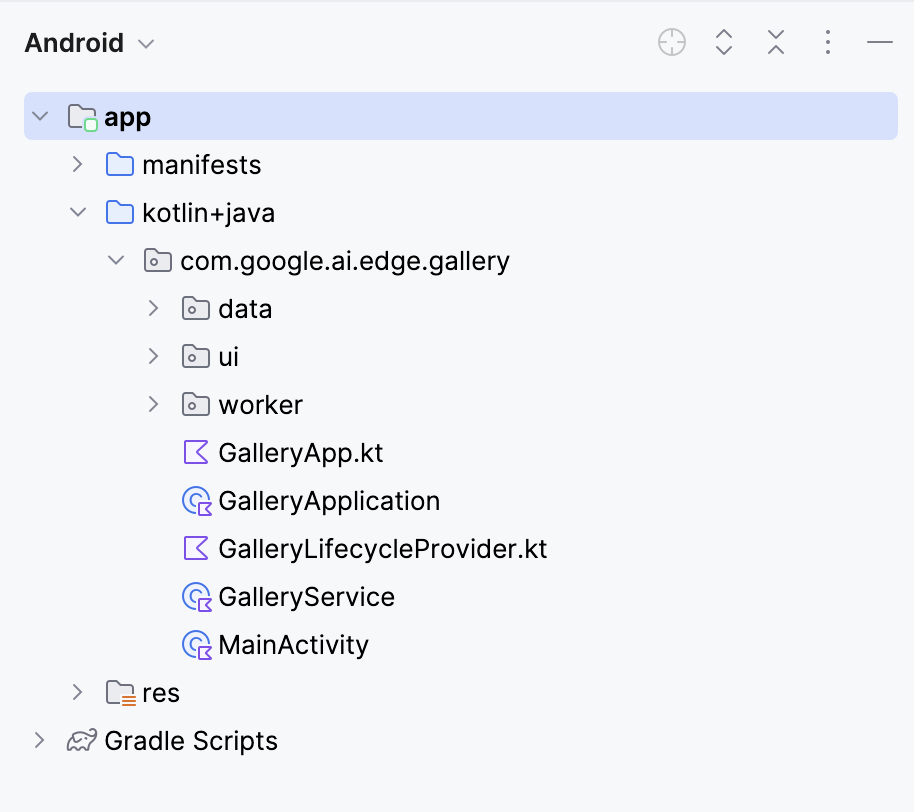
A continuación, editamos algunos archivos para que al abrir nuestra aplicación se acceda directamente a la página Pedir imagen. A continuación, navegamos hasta el archivo Tasks.kt en la siguiente ubicación: app/src/main/java/com/google/ai/edge/gallery/data/Tasks.kt. Para limitar la funcionalidad de la aplicación sólo a la función "Preguntar imagen", haremos las siguientes modificaciones:
Antes:
/** All tasks. */
val TASKS: List<Task> = listOf(
TASK_LLM_ASK_IMAGE,
TASK_LLM_PROMPT_LAB,
TASK_LLM_CHAT,
)Después:
/** All tasks. */
val TASKS: List<Task> = listOf(
TASK_LLM_ASK_IMAGE
)Esto desactiva las otras demos como Prompt Lab y Chat, asegurando que sólo aparezca Preguntar Imagen.
En GalleryApp.kt (situado en // app/src/main/java/com/google/ai/edge/gallery/GalleryApp.kt), actualiza el LaunchedEffect para navegar automáticamente a la página de la imagen. Este cambio garantiza que la aplicación abra directamente la interfaz de Preguntar Imagen, evitando la pantalla de selección de tareas por defecto.
Antes:
@Composable
fun GalleryApp(navController: NavHostController = rememberNavController()) {
GalleryNavHost(navController = navController)
}Después:
package com.google.ai.edge.gallery
import androidx.compose.runtime.Composable
import androidx.compose.runtime.LaunchedEffect
import androidx.navigation.NavHostController
import androidx.navigation.compose.rememberNavController
import com.google.ai.edge.gallery.data.TASK_LLM_ASK_IMAGE
import com.google.ai.edge.gallery.ui.llmchat.LlmAskImageDestination
import com.google.ai.edge.gallery.ui.navigation.GalleryNavHost
@Composable
fun GalleryApp(
navController: NavHostController = rememberNavController()
) {
// as soon as GalleryApp comes up, navigate to Ask-Image
// and drop “home” off the back-stack:
LaunchedEffect(Unit) {
TASK_LLM_ASK_IMAGE.models
.firstOrNull() // safety: don’t crash if the models list is empty
?.name
?.let { modelName ->
navController.navigate("${LlmAskImageDestination.route}/$modelName") {
popUpTo("home") { inclusive = true }
}
}
}
GalleryNavHost(navController = navController)
}Aquí tienes un desglose de lo que hace la función GalleryApp actualizada en el nuevo código:
LaunchedEffect: Un efecto secundario de Jetpack Compose que se activa una vez en la composición. Aquí se utiliza para ejecutar inmediatamente la lógica de navegación en cuanto se visualiza GalleryApp.TASK_LLM_ASK_IMAGE.models.firstOrNull() obtiene con seguridad el nombre del primer modelo imagen-texto disponible (por ejemplo, Gemma 3n) que se utilizará en la navegación. Esto evita que la aplicación se bloquee si la lista de modelos está vacía.navController.navigate(): Dirige dinámicamente la aplicación a la pantalla Preguntar-Imagen utilizando el nombre del modelo seleccionado. Esto sustituye a la habitual pantalla de Inicio como punto de entrada.popUpTo("home") limpia la pila de navegación eliminando la pantalla de inicio del historial. Esto garantiza que el usuario no pueda volver a ella utilizando el botón Atrás del sistema.Mantén el resto del código como está. Juntos, estos cambios hacen que la aplicación se inicie directamente en la interfaz Ask-Image con un modelo válido cargado, mejorando el flujo de usuario para tu demostración.
Una vez que hayas realizado todos los cambios necesarios, ejecutaremos la aplicación. Para ejecutar tu aplicación en tu dispositivo Android local, empareja tu dispositivo Android con Android Studio utilizando la depuración inalámbrica con los siguientes pasos.
Ve a la aplicación Ajustes de tu dispositivo Android y activa las opciones de los programadores. A continuación, activa ladepuración inalámbrica . Deberías ver una pantalla con dos opciones de emparejamiento.
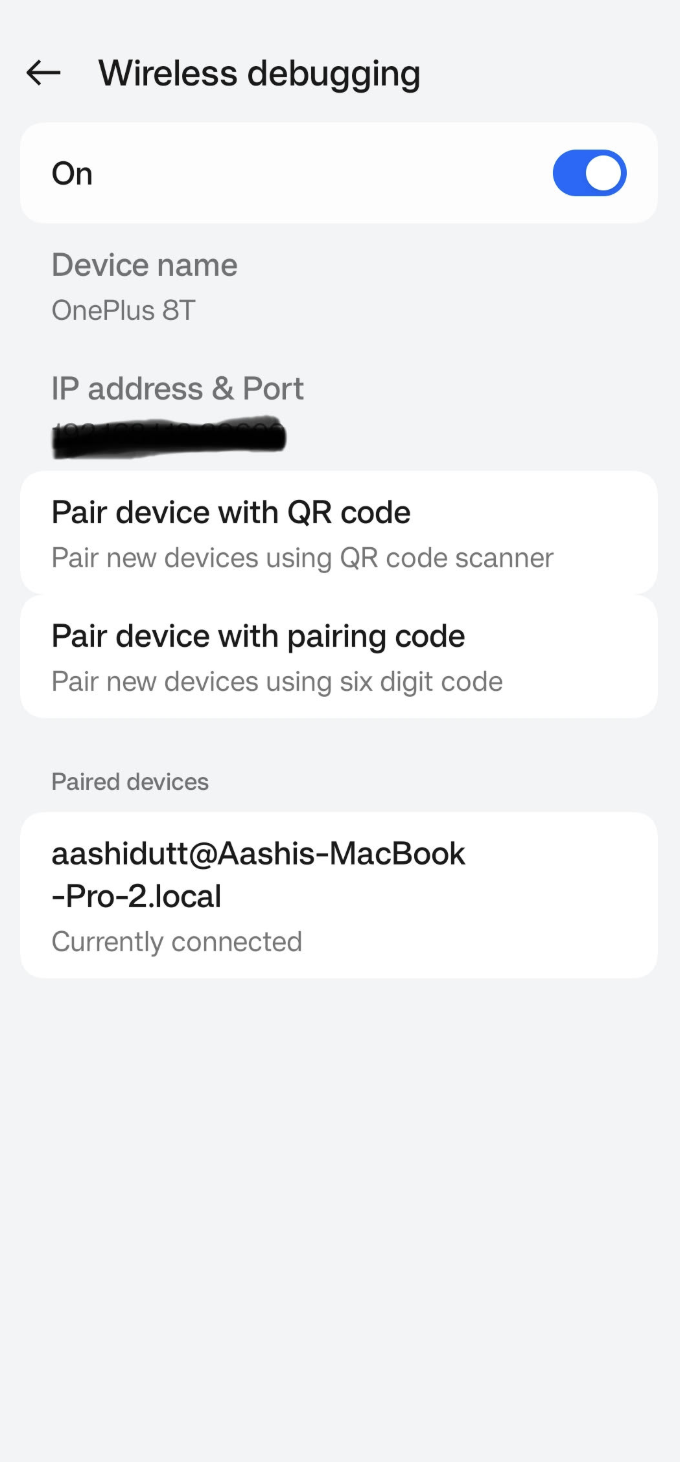
En Android Studio, abre Gestor de dispositivos (el icono se parece a un teléfono con el logotipo de Android) y haz clic en Emparejar mediante código QR.
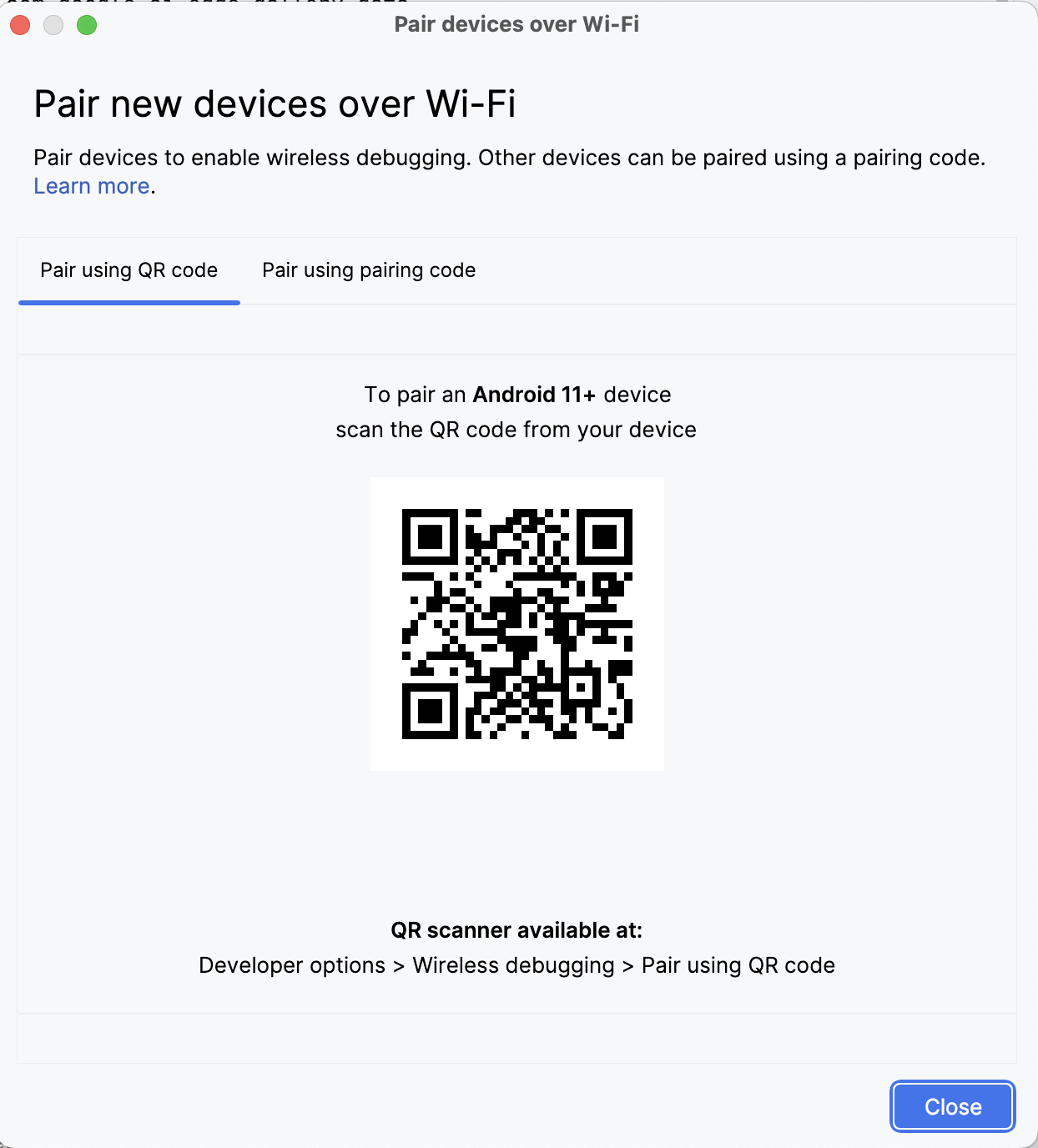
Escanea el código QR con tu dispositivo y completa la configuración del emparejamiento. Una vez que tu dispositivo esté conectado, verás el nombre de tu dispositivo en el Administrador de dispositivos. Asegúrate de que tanto tu sistema como tu dispositivo android están conectados a la misma red WiFi.
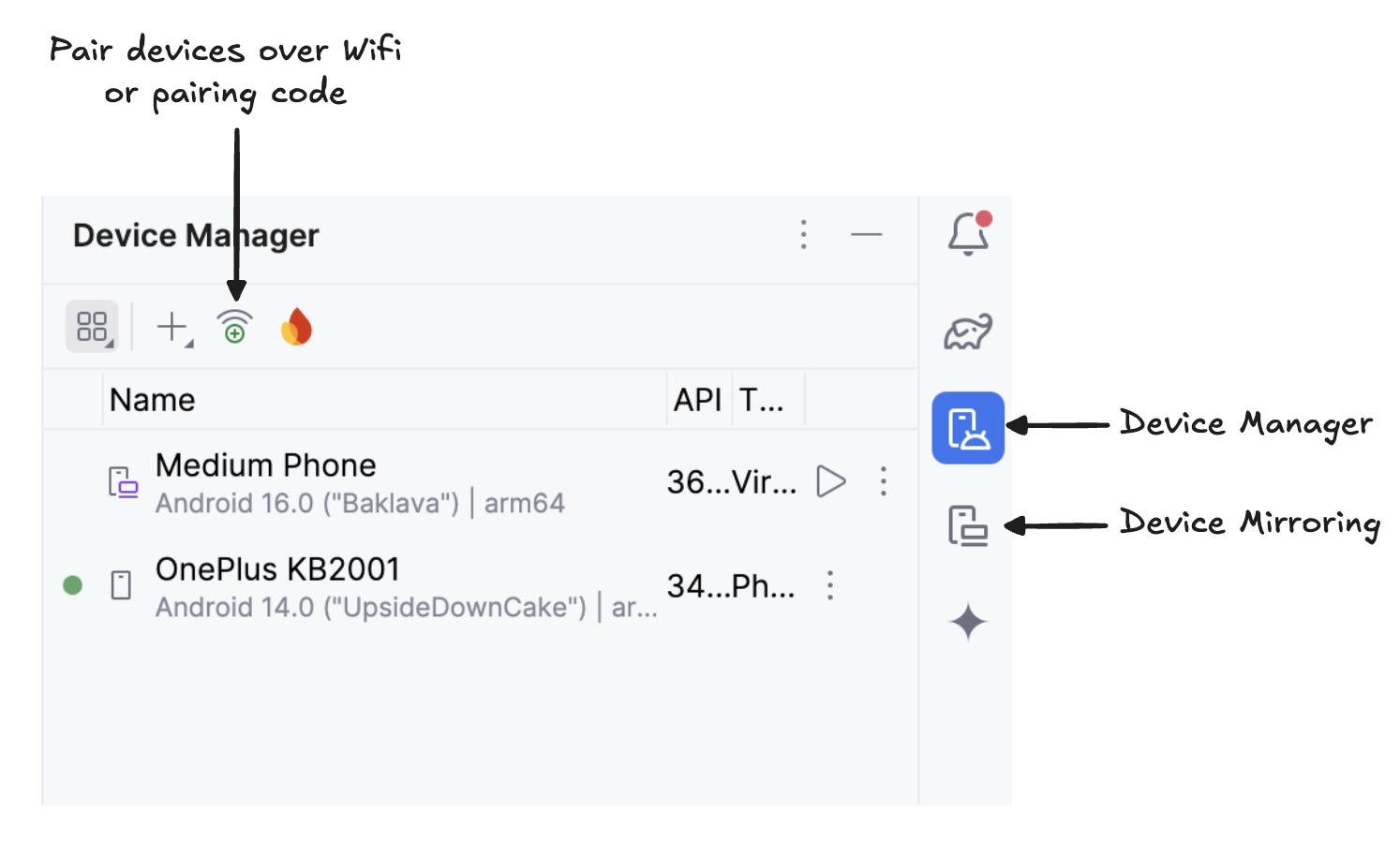
Inicia la duplicación de tu dispositivo Android haciendo clic en el icono deduplicación de dispositivos (que representa una pantalla de escritorio y una pantalla de teléfono). Cuando veas reflejada la pantalla de tu dispositivo, haz clic en el icono verde Ejecutar para desplegar la aplicación en tu dispositivo.
La aplicación se iniciará y se abrirá una ventana del navegador que te pedirá que inicies sesión en Hugging Face para descargar de forma segura el archivo del modelo.

Una vez que te conectes a HuggingFace, haz clic en iniciar descarga en el modelo elegido, y tu modelo empezará a descargarse. Para este ejemplo, utilizo por defecto el modelo Gemma-3n-E2B-it-int4.
Una vez finalizada la descarga, te llevará directamente a la página "Pedir imagen". A continuación, elige una imagen existente de tu galería o haz una foto nueva con la cámara de tu dispositivo. A continuación, pasa una indicación junto con la imagen y envíala al modelo.
Aquí tienes un ejemplo que he probado.


El modelo se ejecuta inicialmente en la CPU. Puedes cambiar a GPU para obtener un rendimiento potencialmente mejor utilizando el icono "Afinar" (representado por tres controles deslizantes horizontales).
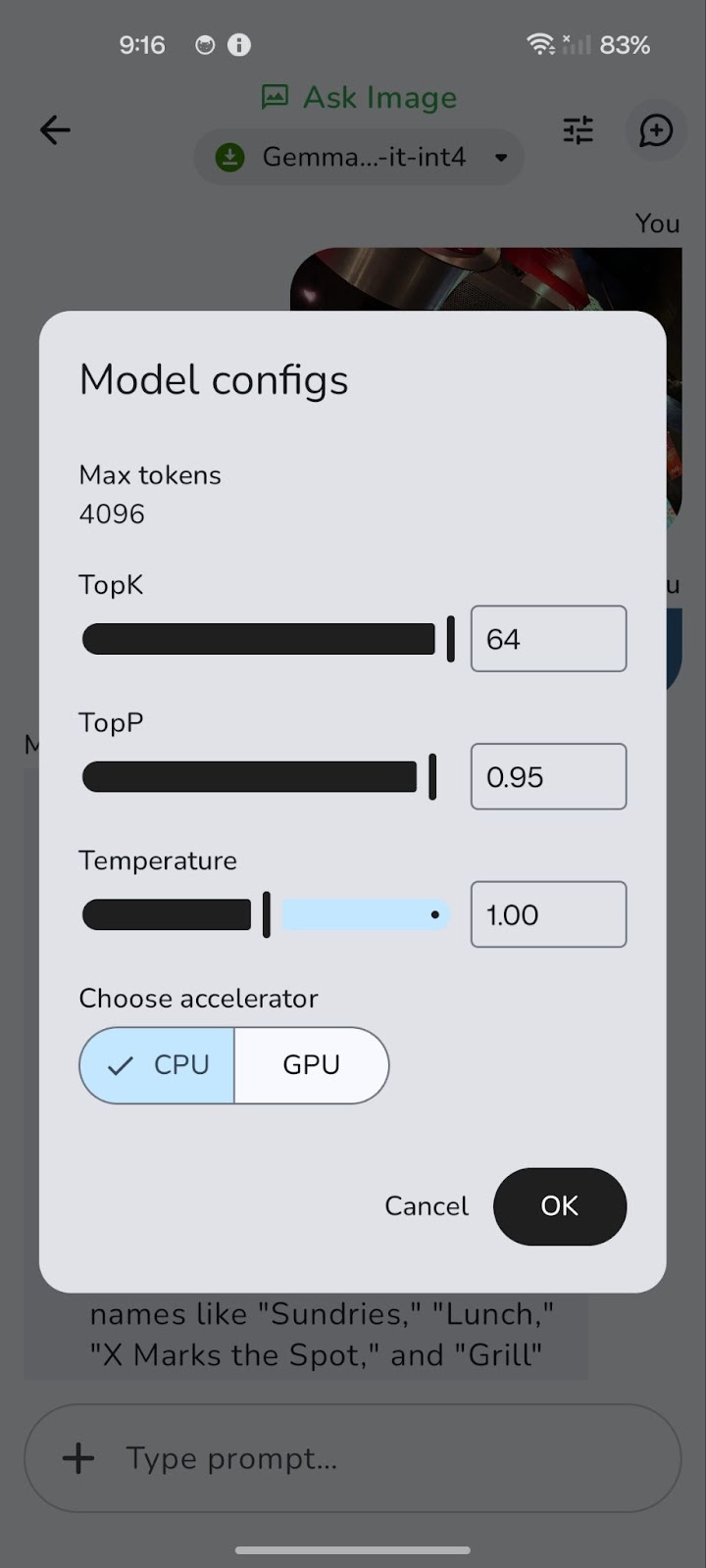
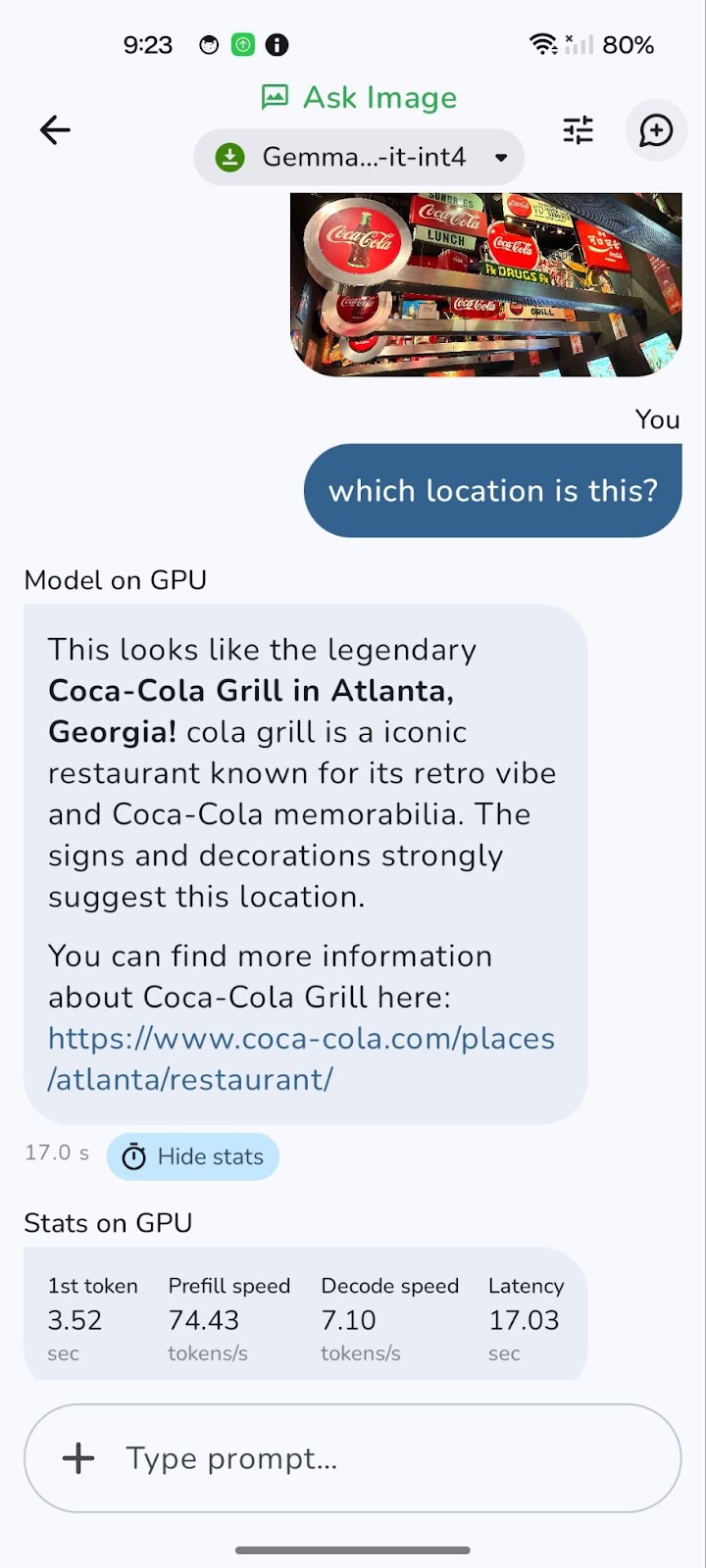
Cambiar a una GPU puede reducir significativamente la latencia general, especialmente para procesar imágenes más grandes y consultas más complejas. Aunque el procesamiento en la GPU suele ofrecer velocidades de descodificación más rápidas, lo que se traduce en respuestas más ágiles, hay que tener en cuenta que la velocidad de precarga a veces puede ser ligeramente superior en la CPU.
Esto se debe a que la carga inicial y la preparación de los datos (rellenado previo) pueden estar limitadas por la CPU. Sin embargo, la ventaja de una descodificación más rápida y una latencia general reducida en la GPU suele compensar esto, proporcionando una experiencia más fluida y con mayor capacidad de respuesta.
He creado este repositorio de GitHub si quieres explorar el código completo del proyecto.
Exploramos cómo Gemma 3n puede permitir responder a preguntas sobre imágenes en dispositivos periféricossin necesidad de inferencia en la nube. Has aprendido a integrar un archivo .task en una aplicación ligera para Android, a preguntar al modelo con lenguaje natural y a obtener respuestas precisas sobre cualquier imagen, directamente desde tu teléfono.
Este tutorial práctico muestra cómo Gemma 3n democratiza la IA multimodal, facilitando a programadores e investigadores el despliegue de modelos sólidos en el dispositivo. Tanto si estás creando asistentes offline, herramientas educativas, aplicaciones sanitarias, etc., Gemma 3n es compatible con muchos casos de uso.
A medida que Google siga perfeccionando la arquitectura Matformer, espero ver modelos aún más compactos y multimodales, con mayor precisión y menor latencia. Para obtener más información sobre Gemma 3n, consulta el publicación oficial de AI Edge o sumérgete en el repositorio de código abierto en GitHub.
Si quieres explorar más herramientas nuevas de IA, te recomiendo estos blogs:
Aprende IA con estos cursos
programa
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Ryan Ong
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan



