Curso
Biomedical Image Analysis in Python
4 h
23.4K
El núcleo de los modelos de visión del lenguaje es la integración de la visión por ordenador y el procesamiento del lenguaje natural.
La visión por ordenador se centra en capacitar a las máquinas para interpretar y analizar datos visuales, como imágenes y vídeos, mediante el reconocimiento de objetos, patrones y otros elementos visuales.
Por otra parte, el procesamiento del lenguaje natural se ocupa de comprender y generar el lenguaje humano, permitiendo a las máquinas comprender, analizar y producir texto.
Los VLM tienden un puente entre estos dos campos creando modelos que pueden procesar y comprender simultáneamente entradas visuales y textuales. Esto se consigue mediante arquitecturas de aprendizaje profundoen particular los modelos transformadores, que han sido fundamentales para el éxito de grandes modelos lingüísticos como el GPT-4o, Llama, Géminisy Gemma.
Estas arquitecturas basadas en transformadores se han adaptado para manejar entradas multimodalespermitiendo a los VLM captar las complejas relaciones entre datos visuales y lingüísticos.
El modelo transformador, introducido inicialmente para tareas de PNL, se ha convertido en la columna vertebral de muchos sistemas avanzados de IA debido a su capacidad para manejar dependencias de largo alcance y captar relaciones contextuales en los datos.
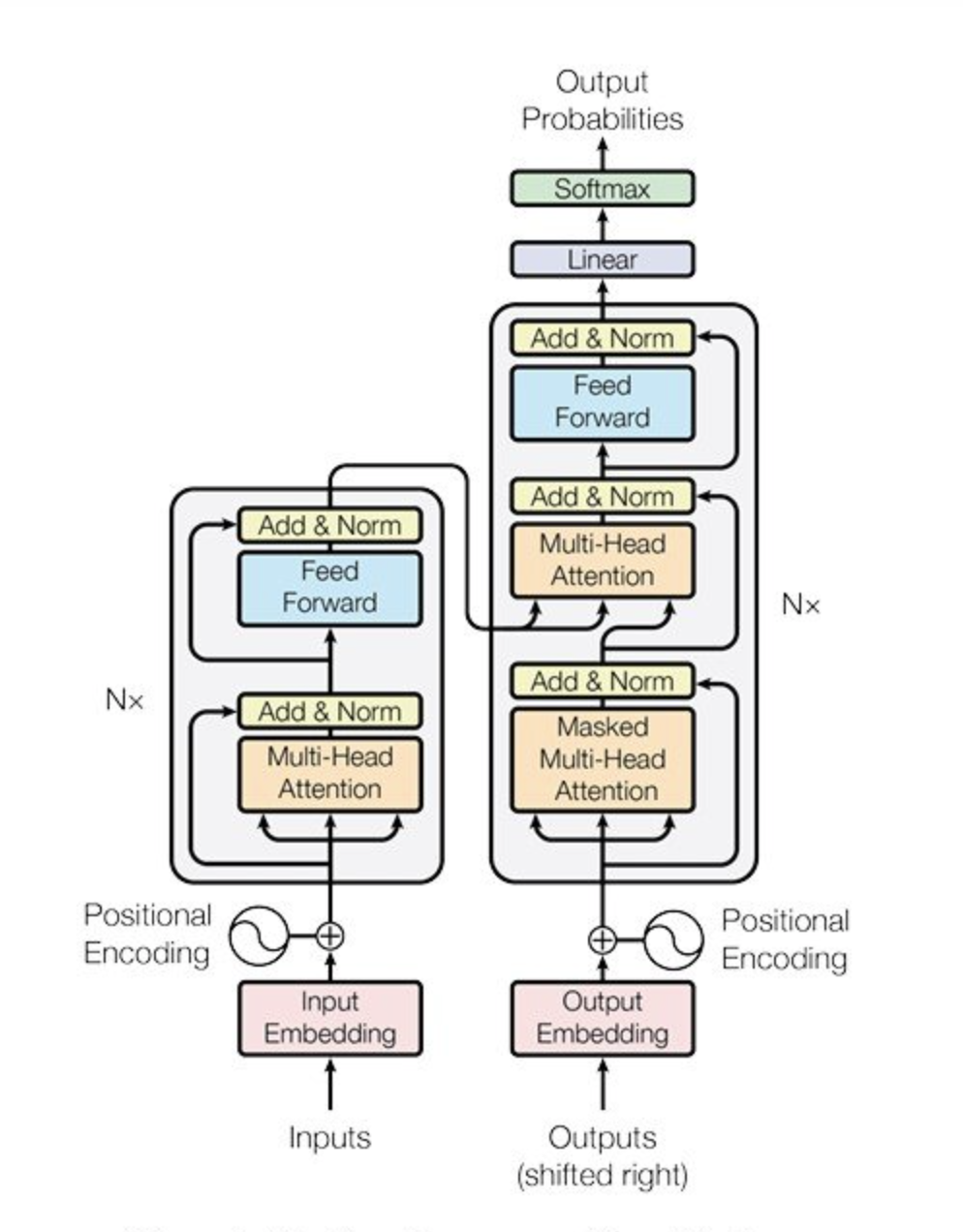
Fuente: Vaswani et al., 2017
En el contexto de los VLM, los transformadores se han adaptado para procesar tanto imágenes como texto, lo que permite una integración perfecta de estas dos modalidades.
Una arquitectura VLM típica consta de dos componentes principales: un codificador de imágenes y un descodificador de texto:
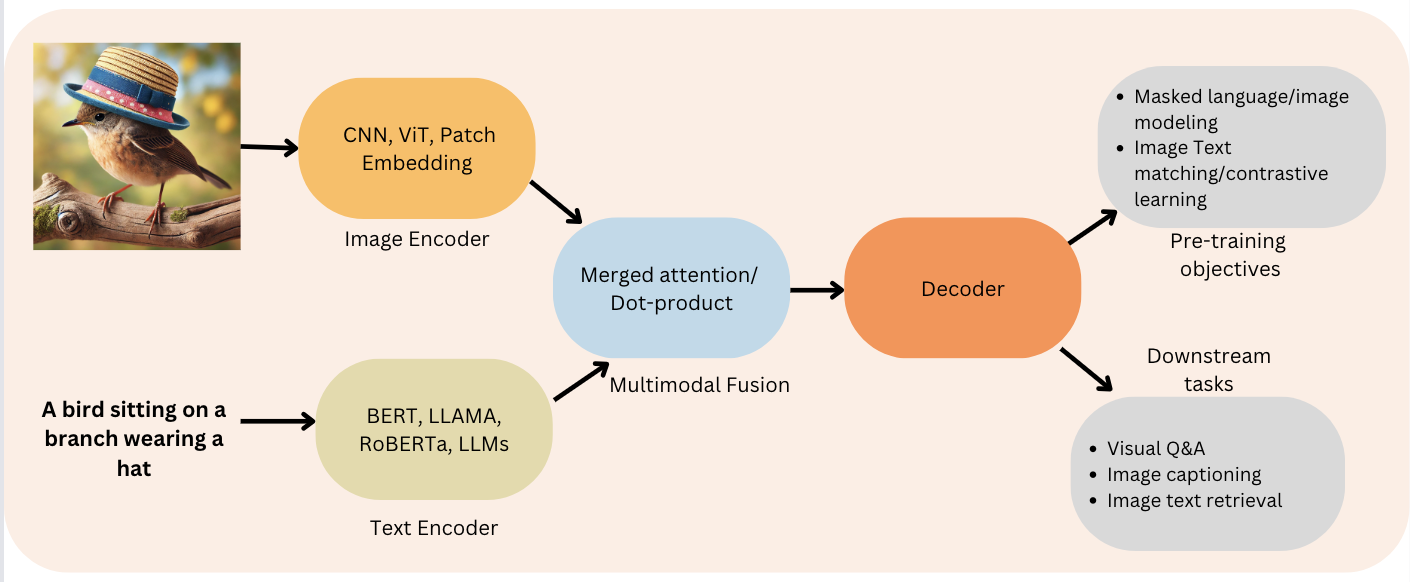
Figura 2: Función codificador-decodificador (Fuente: Viso.ai)
Combinando estas dos partes, los VLM pueden hacer cosas asombrosas como describir imágenes en detalle, responder a preguntas sobre lo que ven, ¡e incluso generar nuevas imágenes basadas en descripciones de texto! El proceso que siguen los VLM sigue los siguientes pasos:
La mayoría de los VLM utilizan un Transformador de Visión (ViT) como codificador de imágenes, que ha sido preentrenado en conjuntos de datos de imágenes a gran escala para garantizar que puede captar eficazmente las características visuales necesarias para las tareas multimodales.
El descodificador de texto se basa en el modelo lingüístico, que ha sido afinado para manejar las complejidades de la generación del lenguaje en el contexto de los datos visuales. Esta combinación de capacidades avanzadas de procesamiento visual y lingüístico hace que el VLM sea muy versátil y potente.
Uno de los retos más importantes a la hora de desarrollar VLM es la necesidad de disponer de conjuntos de datos grandes y diversos que contengan información tanto visual como textual. Estos conjuntos de datos son esenciales para entrenar los modelos de comprensión y generación de contenidos multimodales.
El proceso de entrenamiento de un VLM consiste en alimentar el modelo con pares de imágenes y sus correspondientes descripciones textuales, permitiendo que el modelo aprenda las intrincadas relaciones entre los elementos visuales y las expresiones lingüísticas.
Para manejar estos datos, los VLM suelen utilizar capas de incrustación que transforman las entradas visuales y textuales en un espacio de alta dimensión donde se pueden comparar y combinar.
Este proceso de incrustación permite al modelo comprender las conexiones entre las dos modalidades y generar resultados coherentes y contextualmente relevantes.
El panorama de los modelos de visión del lenguaje (VLM) es muy amplio, con numerosos modelos de código abierto disponibles en la red. Hugging Face Hub. Estos modelos varían en tamaño, capacidades y licencias, proporcionando a los usuarios una gama de opciones adaptadas a diferentes aplicaciones. A continuación se ofrece una visión general de algunos de los VLM de código abierto más destacados, resaltando sus características principales:
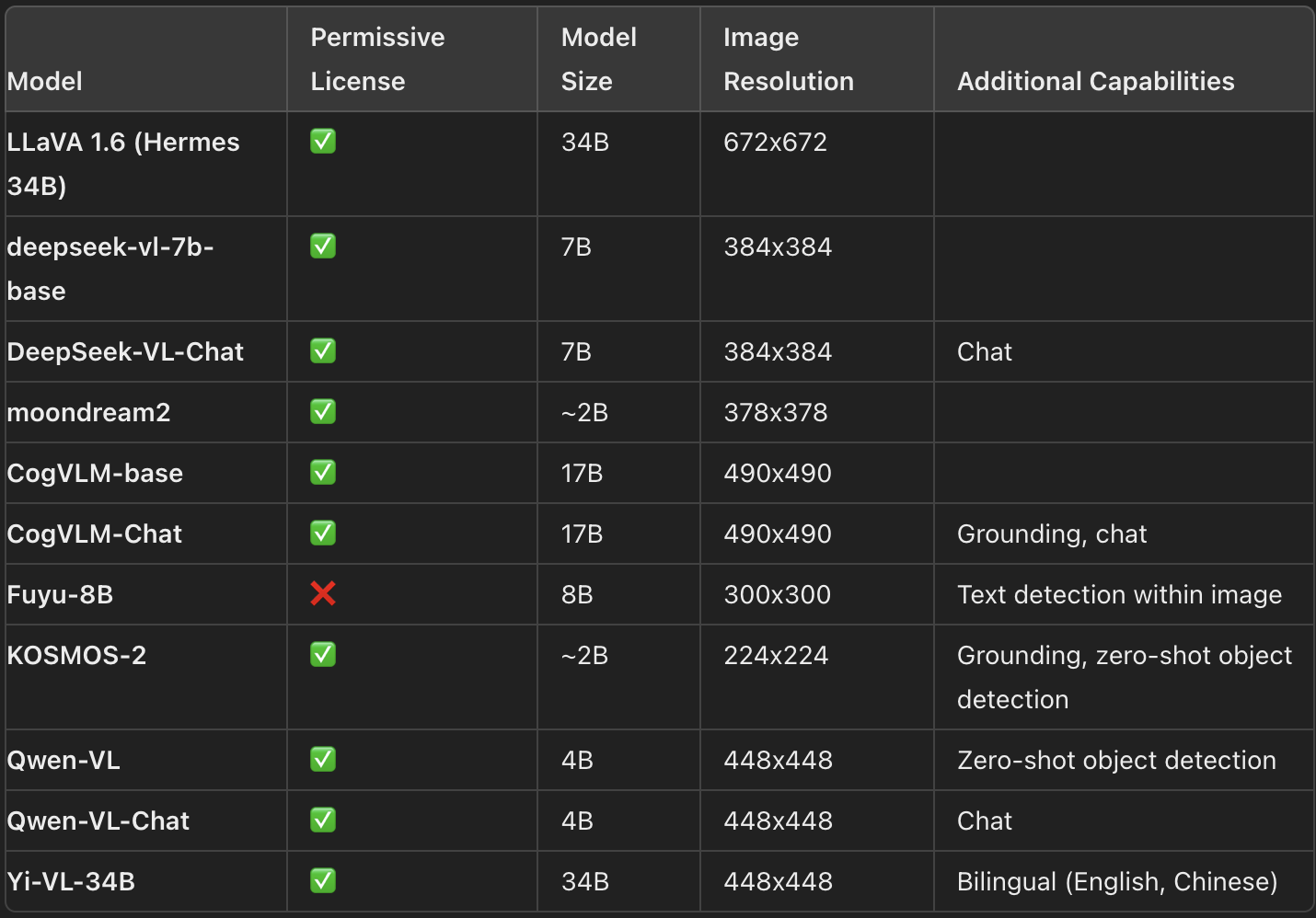
Últimos VLM y sus características clave (Fuente: HuggingFace)
Seleccionar el VLM más adecuado para tu caso de uso específico puede ser un reto, dada la variedad de opciones disponibles. Varias herramientas y recursos pueden ayudar en este proceso de selección:
Aunque tanto Vision Arena como Open VLM Leaderboard ofrecen información valiosa, se limitan a los modelos que se han presentado y requieren actualizaciones periódicas para incluir nuevos modelos.
Para evaluar el rendimiento de los evaluar el rendimiento de los VLM:
El preentrenamiento de los VLM consiste en unificar las representaciones de imagen y texto para introducirlas en un descodificador de texto para su generación. La estructura suele incluir un codificador de imagen, un proyector de incrustación para alinear las representaciones de imagen y texto, y un decodificador de texto. Sin embargo, los distintos modelos emplean diferentes estrategias de preentrenamiento.
En muchos casos, el preentrenamiento de un VLM es incluso innecesario si puedes afinar los modelos existentes para tu caso de uso específico. Herramientas como Transformers y SFTTrainer simplifican el proceso de ajuste de modelos para tareas concretas, haciéndolo accesible incluso a quienes tienen recursos limitados.
Aquí tienes una implementación de HuggingFace para utilizar gratuitamente el modelo de código abierto VLM LlavaNext en tu máquina Colab o local con la biblioteca Transformers de HuggingFace.
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
processor = LlavaNextProcessor.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf"
)
model = LlavaNextForConditionalGeneration.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf",
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
model.to(device)Las capacidades de los modelos de lenguaje visual van mucho más allá del subtitulado de imágenes. Los VLM han abierto las puertas a muchas aplicaciones que utilizan su capacidad para tender puentes entre la información visual y la textual. Exploremos algunas de las aplicaciones más impactantes de los VLM en diversos sectores.
La respuesta a preguntas visuales (VQA) es una tarea que consiste en responder a preguntas sobre el contenido de una imagen.
Esta aplicación requiere que el modelo comprenda tanto los elementos visuales de la imagen como el contexto lingüístico de la pregunta. Por ejemplo, dada una imagen de un bullicioso paisaje urbano, un VLM puede responder a preguntas como "¿Cuál es el color del edificio más alto?" o "¿Cuántas personas se ven en la imagen?".
El VQA tiene numerosas aplicaciones prácticas, sobre todo en industrias en las que los datos visuales desempeñan un papel fundamental. En sanidadpor ejemplo, el VQA puede utilizarse para analizar imágenes médicas y dar respuesta a preguntas que ayuden al diagnóstico y a la planificación del tratamiento. En venta al por menorel VQA puede mejorar la experiencia de compra permitiendo a los clientes interactuar con las imágenes de los productos de una forma más natural e intuitiva.
Una de las capacidades más interesantes de los VLM es la generación de texto a imagen. Esta tarea consiste en generar una representación visual de una escena u objeto a partir de una descripción textual. Por ejemplo, un VLM puede tomar una indicación como "Una serena puesta de sol sobre una cadena montañosa con un río fluyendo por el valle" y generar la imagen correspondiente.
La generación de texto a imagen tiene un inmenso potencial en campos creativos como el diseño y la publicidad. Los diseñadores y publicistas pueden utilizar esta tecnología para generar rápidamente ideas visuales basadas en indicaciones textuales. La generación de texto a imagen puede agilizar el proceso de creación de contenidos visuales que se alineen con mensajes de marketing específicos.
La recuperación de imágenes es el proceso de encontrar imágenes relevantes a partir de una consulta textual. Los VLM destacan en esta tarea gracias a su capacidad para comprender tanto el contenido visual de las imágenes como el contexto lingüístico de la consulta.
Esta capacidad hace que motores de búsqueda más potentes y precisos, permitiendo a los usuarios encontrar las imágenes exactas que buscan con mayor facilidad.
La recuperación de imágenes tiene aplicaciones en diversos ámbitos, desde el comercio electrónico al análisis de imágenes médicas. En el comercio electrónico, la recuperación de imágenes puede ayudar a los clientes a encontrar productos que coincidan con sus preferencias basándose en descripciones visuales y textuales. En sanidad, la recuperación de imágenes puede ayudar a los profesionales médicos a encontrar imágenes médicas relevantes para la investigación o el diagnóstico.
Aunque los ejemplos anteriores se centran en imágenes, los VLM también pueden ampliarse para comprender y generar subtítulos para vídeos. La comprensión de vídeo consiste en analizar el contenido visual de un vídeo y generar un texto descriptivo que capte la esencia de las escenas representadas.
La comprensión de vídeos tiene aplicaciones en la búsqueda de vídeos, el resumen y la moderación de contenidos. En la búsqueda de vídeos, los VLM pueden ayudar a los usuarios a encontrar videoclips específicos basándose en consultas textuales. En tareas de resumen, los VLM pueden generar resúmenes concisos de vídeos largos, facilitando a los usuarios la comprensión rápida del contenido. En la moderación de contenidos, los VLM pueden ayudar a identificar contenidos inapropiados o perjudiciales en los vídeos, garantizando que las plataformas mantengan un entorno seguro y fácil de usar.
Consideremos ahora los retos asociados a los VLM, así como los aspectos éticos.
El entrenamiento y despliegue de los VLM requiere recursos informáticos significativossobre todo para modelos grandes como PaliGemma. Esto puede suponer un obstáculo para las organizaciones con acceso limitado a infraestructuras informáticas de alto rendimiento.
Para hacer frente a este reto, los investigadores están explorando formas de hacer que los VLM sean más eficientes, por ejemplo utilizando técnicas de compresión de modelos, optimizando la arquitectura del modelo y aprovechando aceleradores de hardware como GPUs y TPUs.
El desarrollo de los VLM plantea varias cuestiones éticas, sobre todo en torno a la posibilidad de sesgo en los resultados del modelo. Los VLM entrenados con datos de imagen-texto del mundo real a gran escala pueden reflejar sesgos socioculturales incorporados en el material de entrenamiento. Estos sesgos pueden manifestarse en los resultados del modelo, dando lugar a contenidos perjudiciales u ofensivos.
Para abordar estos problemas, los investigadores están aplicando diversas técnicas de mitigación de sesgos, como utilizar conjuntos de datos de entrenamiento equilibrados, incorporar algoritmos de aprendizaje que tengan en cuenta la imparcialidad y realizar evaluaciones rigurosas de los resultados del modelo para identificar y abordar los posibles sesgos.
Además, organizaciones como Google están implantando filtros de seguridad de contenidos para garantizar que los datos de entrenamiento utilizados para modelos como PaliGemma estén limpios y libres de contenidos nocivos.
Otra consideración importante en el desarrollo de los VLM es la la privacidad y seguridad de los datos. Los VLM a menudo necesitan acceder a grandes cantidades de datos, incluida información potencialmente sensible. Garantizar que estos datos se manejan de forma segura y cumpliendo la normativa sobre privacidad es fundamental para mantener la confianza de los usuarios y las partes interesadas.
Para abordar los problemas de privacidad, los investigadores están explorando técnicas como el aprendizaje federado, que permite entrenar modelos con datos descentralizados sin necesidad de transferir información sensible a un servidor central.
Además, organizaciones como Google están aplicando medidas de responsabilidad sobre los datos, como filtrar la información personal y los datos sensibles de los conjuntos de datos de entrenamiento, para proteger la privacidad de las personas.
Los modelos de lenguaje visual representan un importante paso adelante en la inteligencia artificial, ya que ofrecen la posibilidad de mejorar diversas aplicaciones gracias a su capacidad para procesar datos tanto visuales como textuales.
A medida que avanza la investigación en este campo, podemos anticipar el desarrollo de VLM más sofisticados, capaces de realizar tareas complejas y proporcionar valiosos conocimientos.
La integración de la comprensión visual y textual abre nuevas posibilidades de innovación, lo que convierte a los VLM en un prometedor campo de investigación y desarrollo.
Aprende IA con estos cursos
Curso
Curso
Curso
blog
Dimitri Didmanidze
7 min
blog
DataCamp Team
4 min
blog
Stanislav Karzhev
9 min
blog
Abid Ali Awan
10 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
