
Programa
Desenvolvimento de aplicativos de IA
21 h
A Gemma 3n é a mais recente família de modelos multimodais e de peso aberto do Google AI, projetada para ser executada com eficiência em dispositivos de uso diário, como telefones, tablets e laptops. Criado com base em um romance MatFormer com suporte para cache de parâmetros Per-Layer Embedding (PLE), o Gemma 3n oferece desempenho no dispositivo e minimiza os custos de memória e computação.
Embora semelhantes aos modelos tradicionais de modelos de visão-linguagem (VLMs)o Gemma 3n é compatível com as modalidades de texto, imagem e áudio. Sua variante "3n" é especificamente otimizada para implantação de borda, com execução leve em CPUs, NPUs ou GPUs móveis por meio do AI Edge SDK do Google.
Esses são os principais recursos do Gemma 3n:
Observação importante: embora o Gemma 3n seja compatível com entradas de áudio em sua arquitetura completa, os recursos de áudio ainda não estão disponíveis na visualização pública.
Você pode experimentar o Gemma 3n usando um destes três métodos:
.task de Gemma 3n é publicado no formato ai-edge-litert do Google. Você pode solicitar acesso à página de modelos do Hugging Face e fazer o download do modelo localmente para inferência. Um arquivo .task é um pacote compacto e de fácil execução que contém uma versão pré-compilada do modelo, seus metadados e todas as configurações necessárias, projetado especificamente para execução rápida e segura no dispositivo usando o AI Edge SDK do Google.Em seguida, mostrarei a você como criar um aplicativo Android funcional que usa o modelo Gemma 3n para processar prompts de imagem e texto. Usaremos o repositório oficial da Galeria do Google como base e o personalizaremos para abrir diretamente na tela Pergunte à imagem, sem distrações.
Vamos começar configurando um novo projeto e clonando o repositório original do Google.
Em seu laptop, comece abrindo o projeto como um novo projeto no Android Studio e selecione uma Empty Activity.
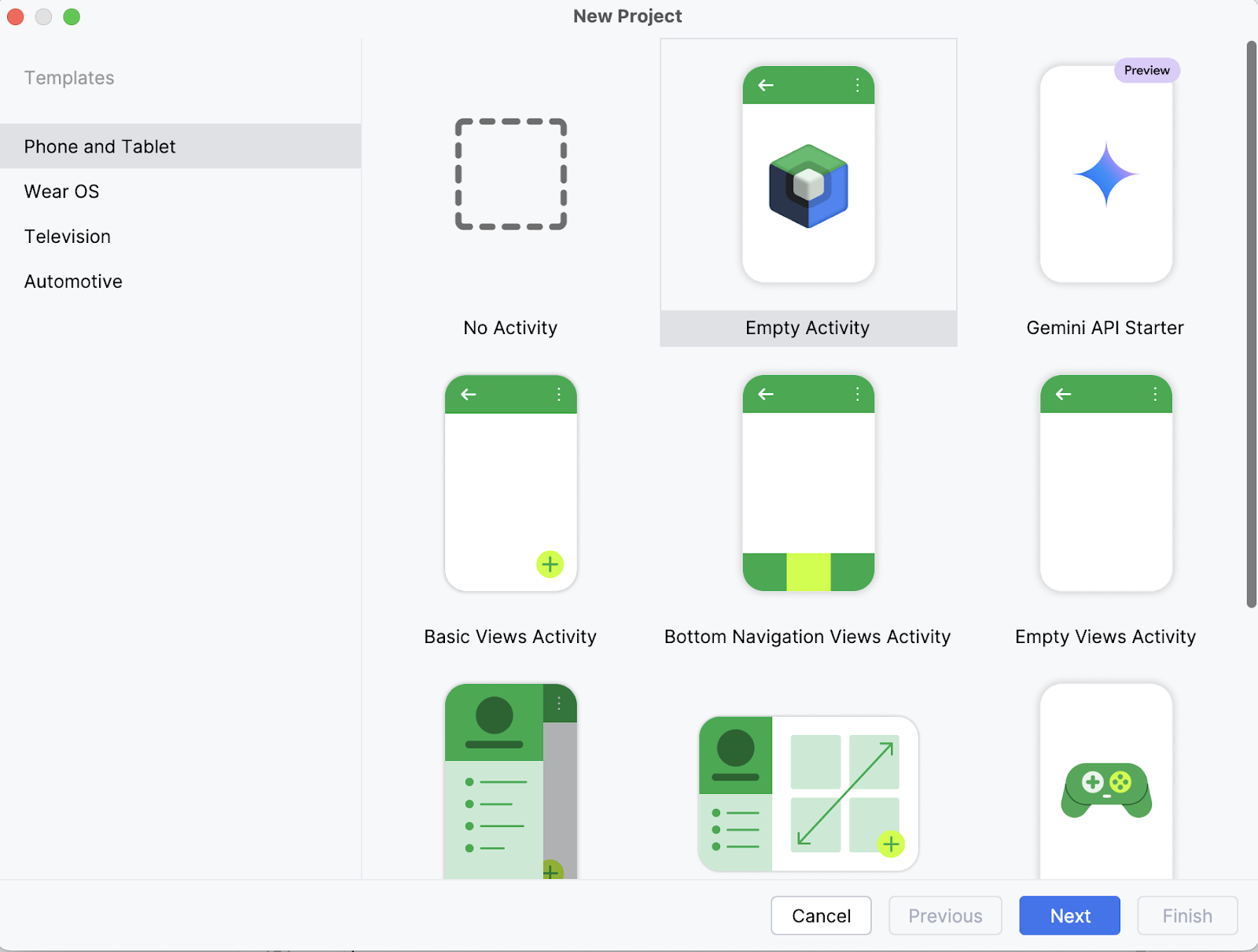
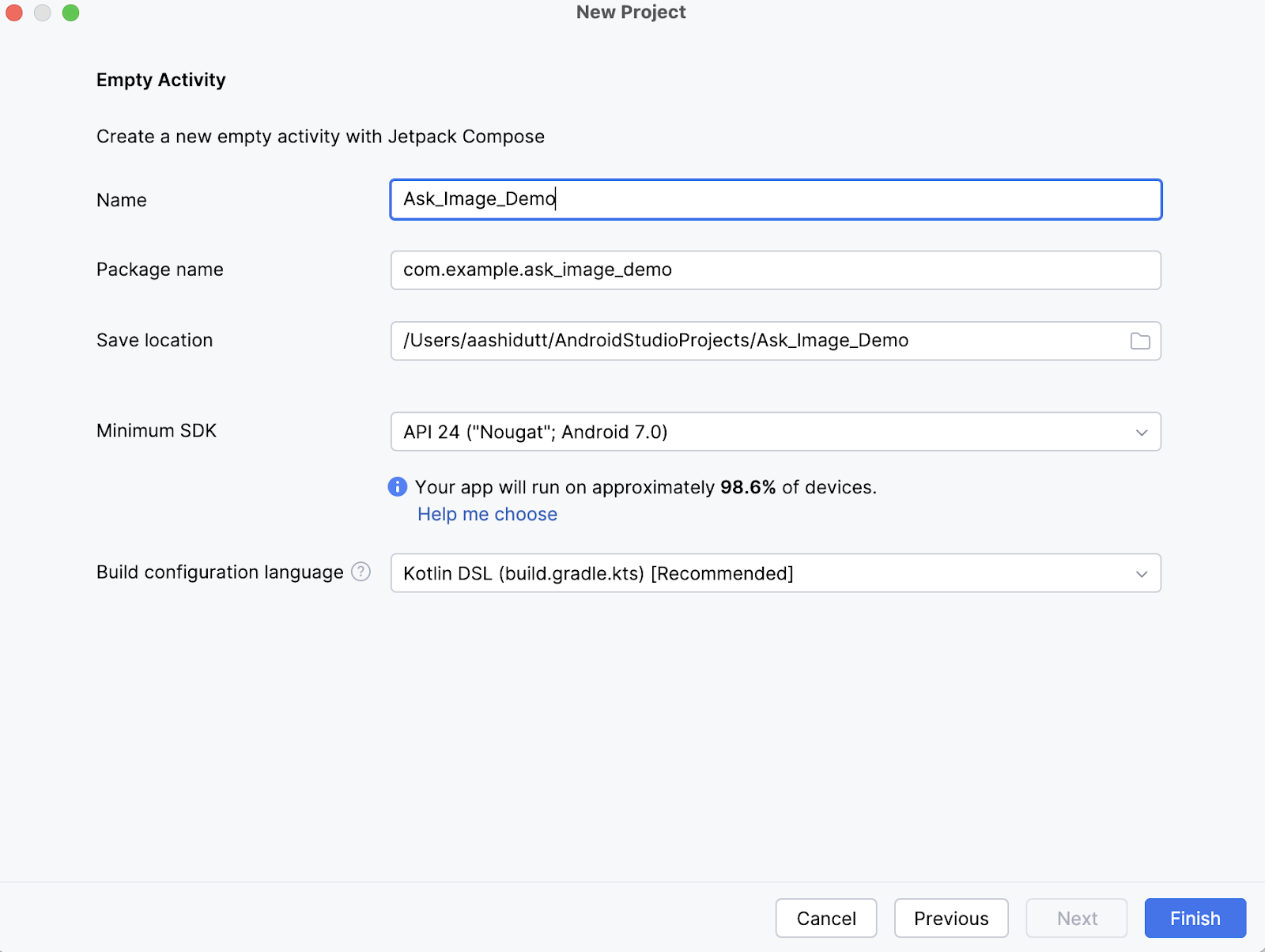
Em seguida, preencha o nome da sua atividade (por exemplo, "Ask_Image_Demo") e mantenha o restante como está. Em seguida, clique em Finish (Concluir).
Agora, abra o terminal no Android Studio (canto inferior esquerdo) e execute os seguintes comandos bash:
git clone https://github.com/google-ai-edge/gallery
cd gallery/android
Isso abrirá seu projeto. Você pode visualizar todos os arquivos de projeto no lado esquerdo da guia.
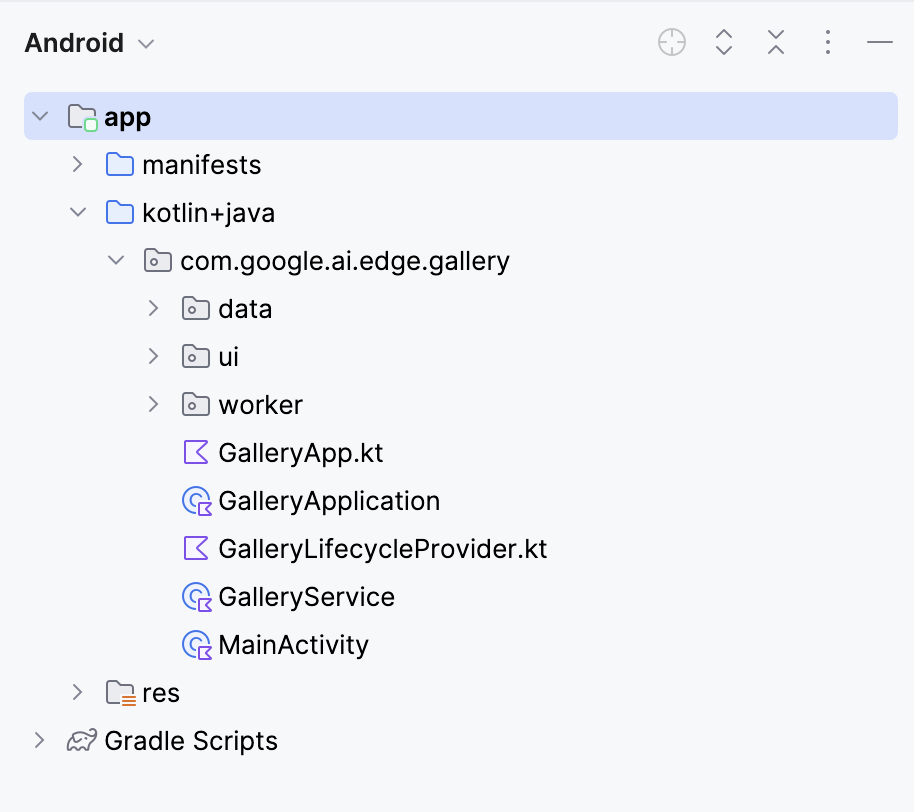
Em seguida, editamos alguns arquivos para que a abertura do nosso aplicativo leve diretamente à página Ask Image. Em seguida, navegamos até o arquivo Tasks.kt no seguinte local: app/src/main/java/com/google/ai/edge/gallery/data/Tasks.kt. Para limitar a funcionalidade do aplicativo apenas ao recurso "Ask Image", faremos as seguintes edições:
Antes:
/** All tasks. */
val TASKS: List<Task> = listOf(
TASK_LLM_ASK_IMAGE,
TASK_LLM_PROMPT_LAB,
TASK_LLM_CHAT,
)Depois:
/** All tasks. */
val TASKS: List<Task> = listOf(
TASK_LLM_ASK_IMAGE
)Isso desativa as outras demonstrações, como Prompt Lab e Chat, garantindo que apenas o Ask Image seja exibido.
Em GalleryApp.kt (localizado em // app/src/main/java/com/google/ai/edge/gallery/GalleryApp.kt), atualize o LaunchedEffect para navegar automaticamente até a página da imagem. Essa alteração garante que o aplicativo abra a interface do Ask Image diretamente, ignorando a tela de seleção de tarefas padrão.
Antes:
@Composable
fun GalleryApp(navController: NavHostController = rememberNavController()) {
GalleryNavHost(navController = navController)
}Depois:
package com.google.ai.edge.gallery
import androidx.compose.runtime.Composable
import androidx.compose.runtime.LaunchedEffect
import androidx.navigation.NavHostController
import androidx.navigation.compose.rememberNavController
import com.google.ai.edge.gallery.data.TASK_LLM_ASK_IMAGE
import com.google.ai.edge.gallery.ui.llmchat.LlmAskImageDestination
import com.google.ai.edge.gallery.ui.navigation.GalleryNavHost
@Composable
fun GalleryApp(
navController: NavHostController = rememberNavController()
) {
// as soon as GalleryApp comes up, navigate to Ask-Image
// and drop “home” off the back-stack:
LaunchedEffect(Unit) {
TASK_LLM_ASK_IMAGE.models
.firstOrNull() // safety: don’t crash if the models list is empty
?.name
?.let { modelName ->
navController.navigate("${LlmAskImageDestination.route}/$modelName") {
popUpTo("home") { inclusive = true }
}
}
}
GalleryNavHost(navController = navController)
}Aqui está um detalhamento do que a função GalleryApp atualizada faz no novo código:
LaunchedEffect: Um efeito colateral do Jetpack Compose que é acionado uma vez na composição. Aqui, ele é usado para executar imediatamente a lógica de navegação assim que o site GalleryApp é renderizado.TASK_LLM_ASK_IMAGE.models.firstOrNull() busca com segurança o nome do primeiro modelo de imagem-texto disponível (por exemplo, Gemma 3n) a ser usado na navegação. Isso evita que o aplicativo trave se a lista de modelos estiver vazia.navController.navigate(): Ele direciona dinamicamente o aplicativo para a tela Ask-Image usando o nome do modelo selecionado. Isso substitui a tela inicial usual como ponto de entrada.popUpTo("home") limpa a pilha de navegação, removendo a tela inicial do histórico. Isso garante que o usuário não possa navegar de volta para ele usando o botão Voltar do sistema.Mantenha o restante do código como está. Juntas, essas alterações fazem com que o aplicativo seja iniciado diretamente na interface do Ask-Image com um modelo válido carregado, melhorando o fluxo do usuário para sua demonstração.
Depois que você tiver feito todas as alterações necessárias, executaremos o aplicativo. Para executar o aplicativo em seu dispositivo Android local, emparelhe seu dispositivo Android com o Android Studio usando a depuração sem fio com as seguintes etapas.
Acesse o aplicativo Configurações em seu dispositivo Android e ative as Opções do desenvolvedor. Em seguida, ative Depuração sem fio. Você deverá ver uma tela com duas opções de emparelhamento.
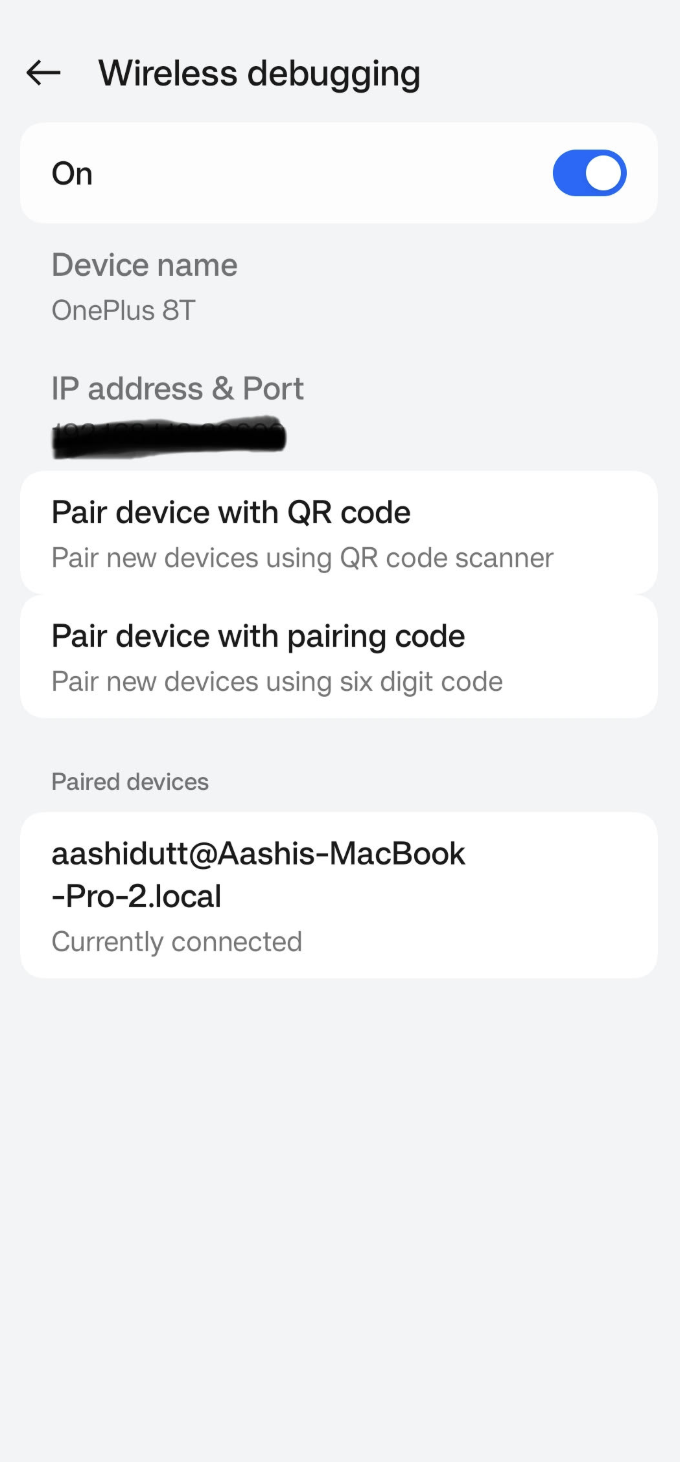
No Android Studio, abra o Gerenciador de dispositivos (o ícone se assemelha a um telefone com um logotipo do Android) e clique em Emparelhar usando o código QR.
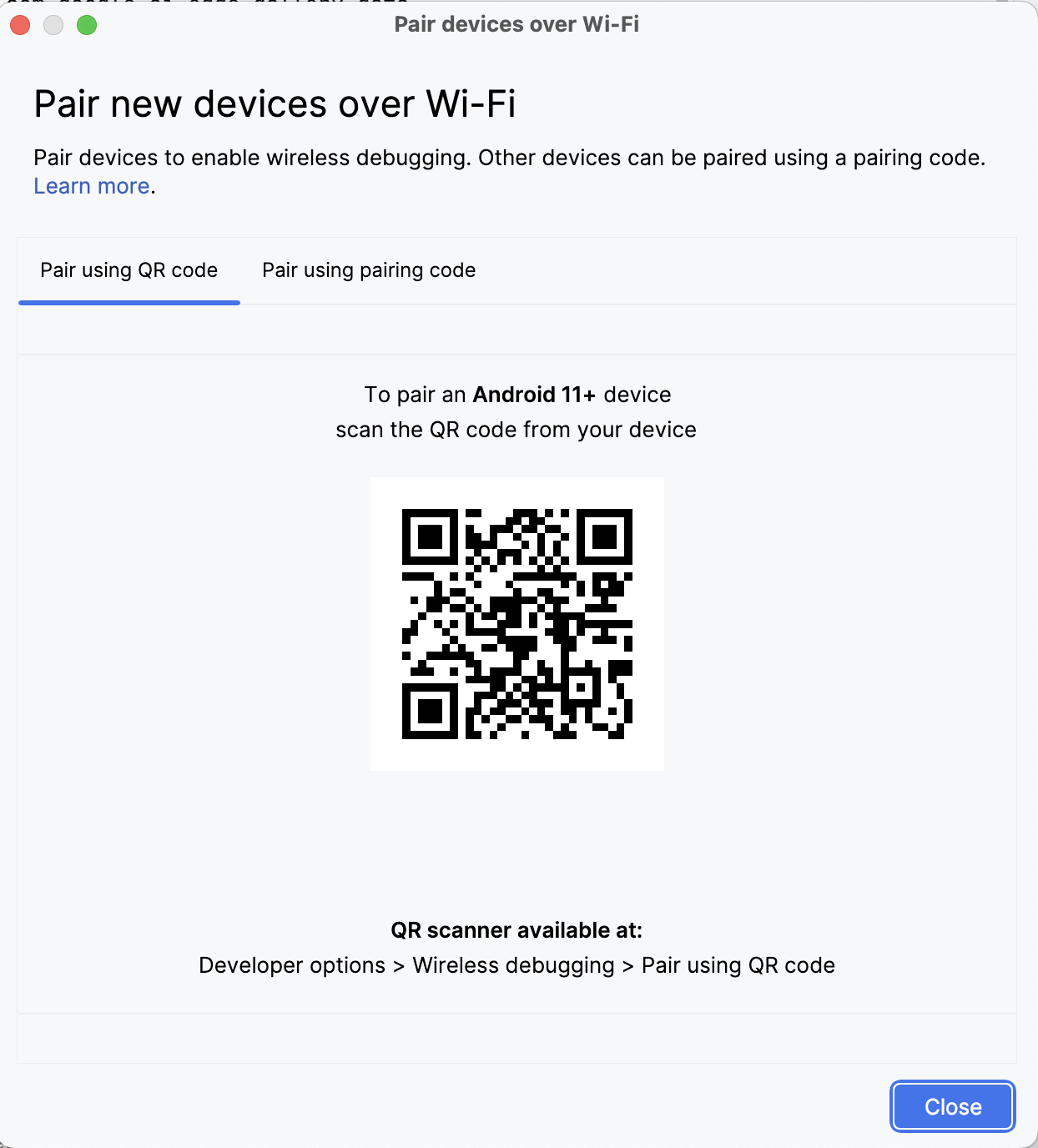
Digitalize o código QR usando seu dispositivo e conclua a configuração do emparelhamento. Quando o dispositivo estiver conectado, você verá o nome do dispositivo em Device Manager. Verifique se o sistema e o dispositivo Android estão conectados à mesma rede WiFi.
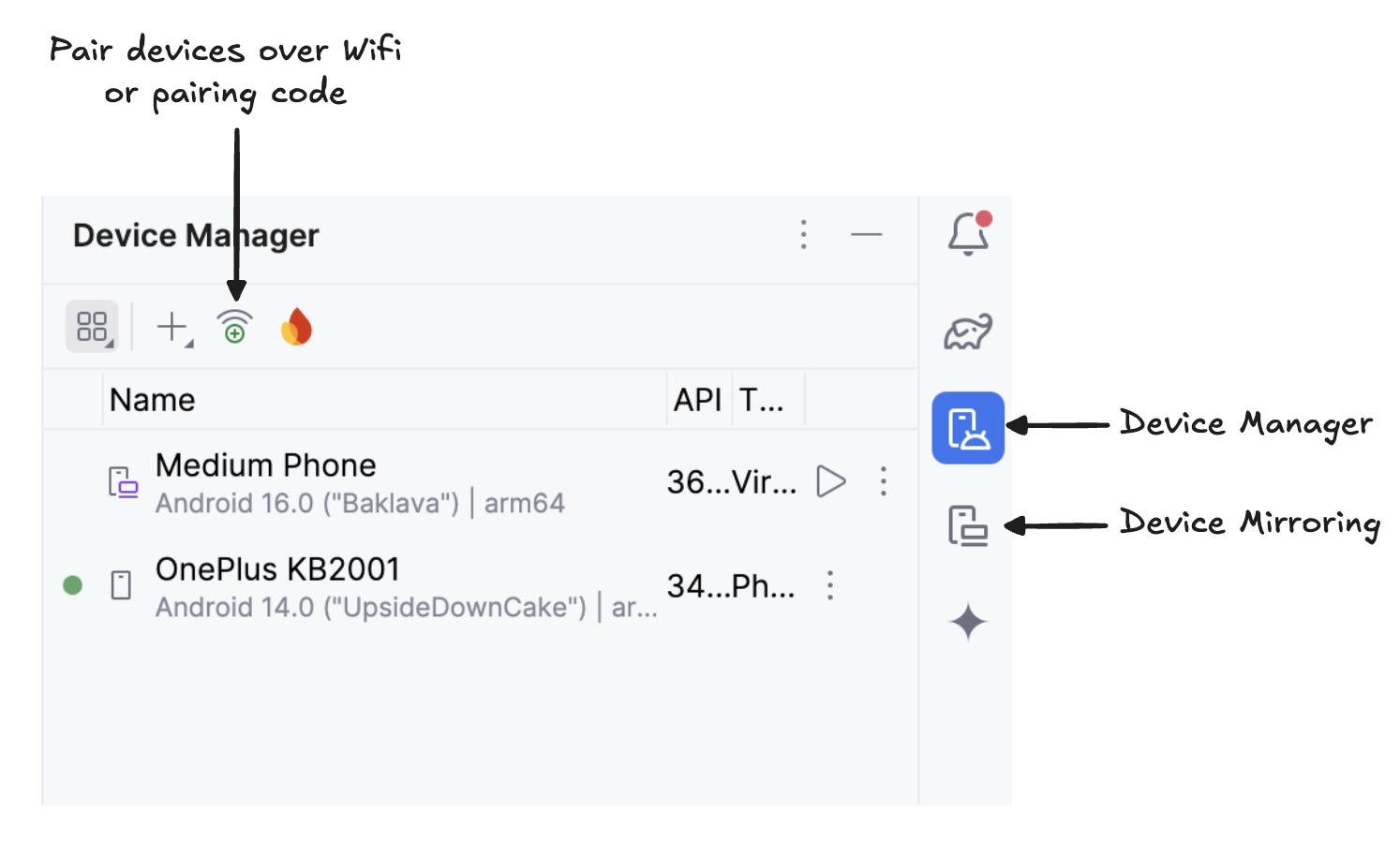
Comece a espelhar seu dispositivo Android clicando no íconeDevice Mirroring (que mostra uma tela de desktop e uma tela de telefone). Quando você vir a tela do seu dispositivo espelhada, clique no ícone verde Run para implantar o aplicativo no seu dispositivo.
O aplicativo será iniciado e uma janela do navegador será aberta, solicitando que você faça login no Hugging Face para baixar com segurança o arquivo do modelo.

Depois que você fizer login no HuggingFace, clique em iniciar o download no modelo escolhido, e o download do modelo começará. Para este exemplo, estou usando o modelo Gemma-3n-E2B-it-int4 por padrão.
Quando o download for concluído, você será levado diretamente para a página "Ask Image". Em seguida, escolha uma imagem existente na sua galeria ou tire uma nova foto com a câmera do dispositivo. Em seguida, passe um prompt junto com a imagem e envie-a para o modelo.
Aqui está um exemplo que testei.


O modelo é executado inicialmente na CPU. Você pode alternar para GPU para obter um desempenho potencialmente melhor usando o ícone "Tune" (representado por três controles deslizantes horizontais).
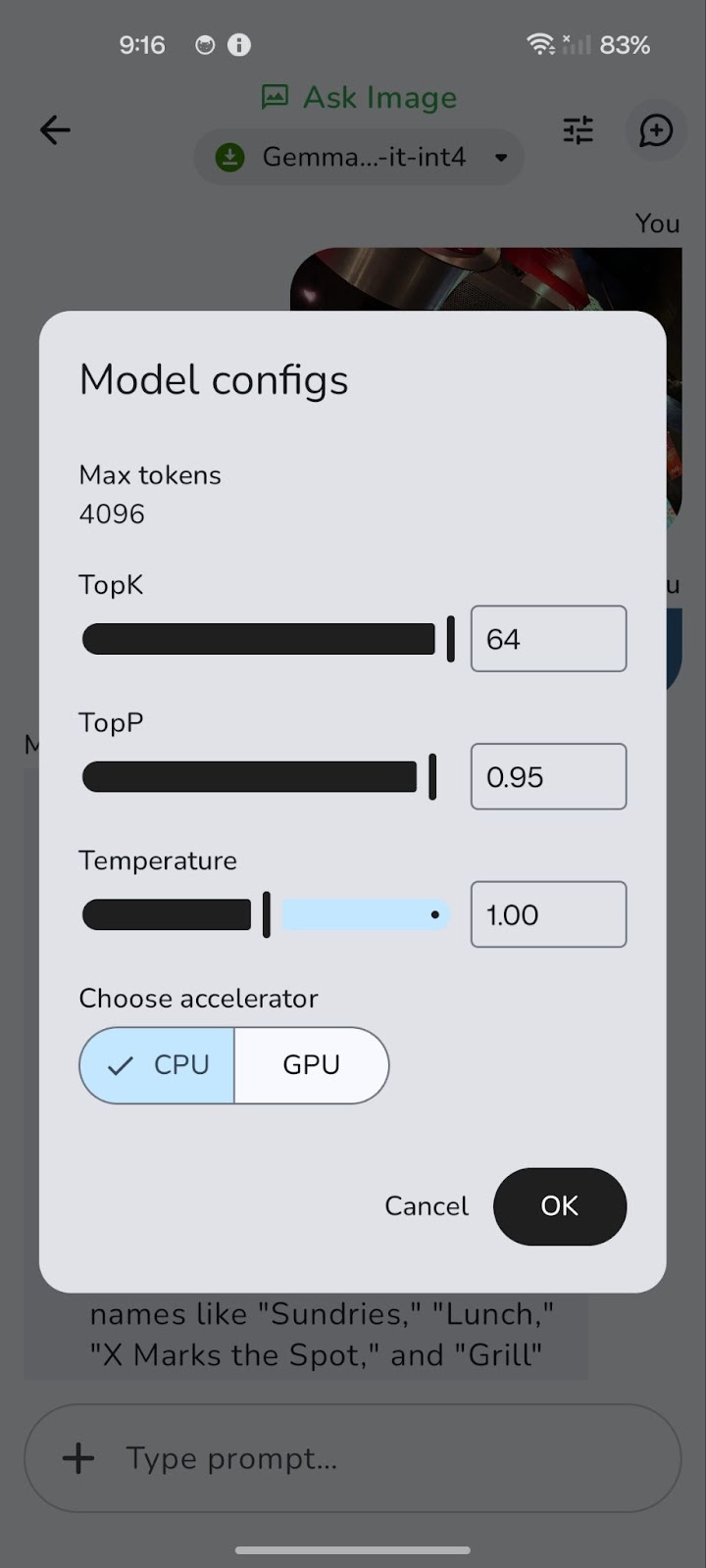
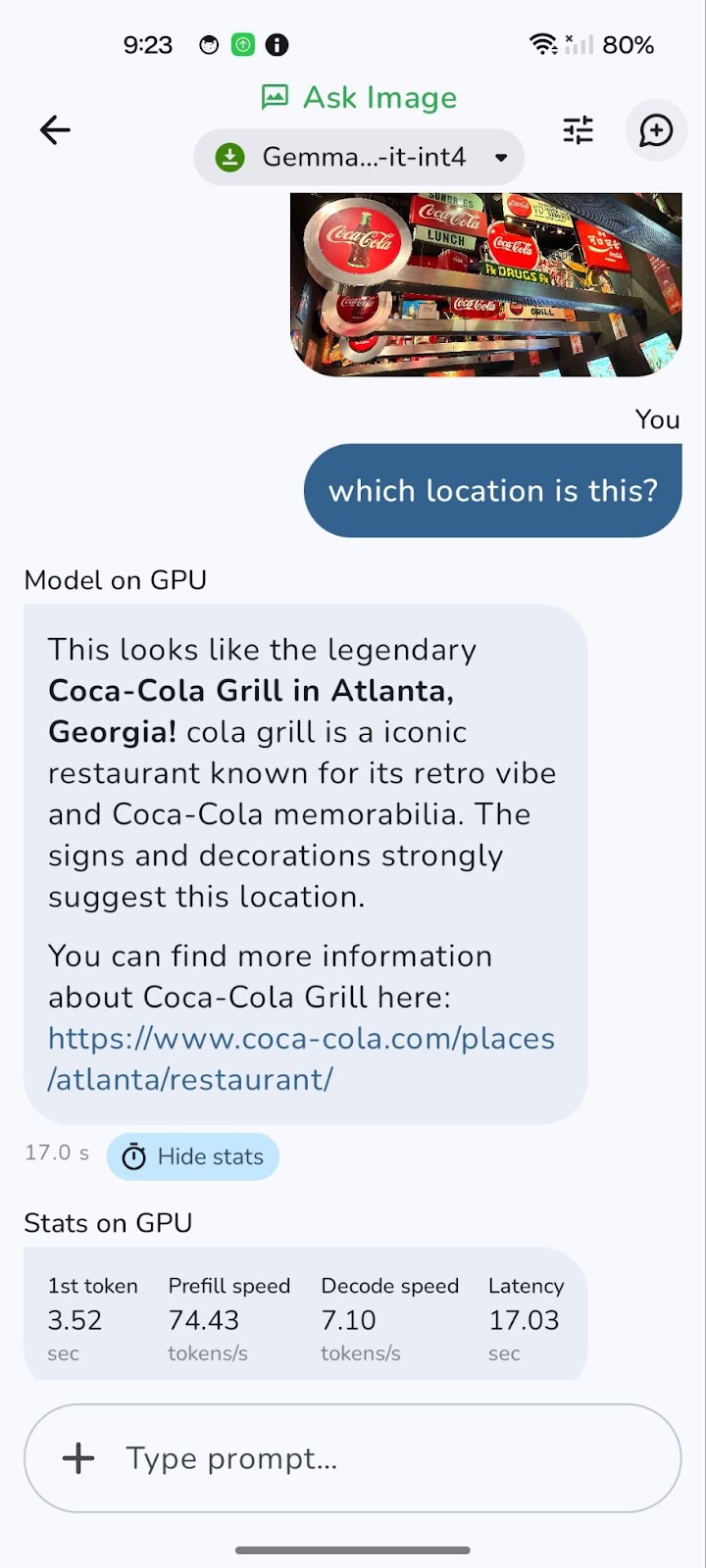
A mudança para uma GPU pode reduzir significativamente a latência geral, especialmente no processamento de imagens maiores e consultas mais complexas. Embora o processamento da GPU geralmente ofereça velocidades de decodificação mais rápidas, resultando em respostas mais rápidas, vale a pena observar que a velocidade de pré-preenchimento pode, às vezes, ser ligeiramente maior na CPU.
Isso ocorre porque o carregamento inicial e a preparação dos dados (pré-preenchimento) podem ser limitados pela CPU. No entanto, o benefício da decodificação mais rápida e da latência geral reduzida na GPU geralmente supera isso, proporcionando uma experiência mais suave e ágil.
Eu configurei este repositório do GitHub se você quiser explorar o código completo do projeto.
Exploramos como o Gemma 3n pode permitir a resposta a perguntas sobre imagens em dispositivos de bordasem a necessidade de inferência na nuvem. Você aprendeu a integrar um arquivo .task em um aplicativo leve para Android, a solicitar o modelo com linguagem natural e a obter respostas precisas sobre qualquer imagem, diretamente do seu telefone.
Este passo a passo prático mostra como o Gemma 3n democratiza a IA multimodal, facilitando aos desenvolvedores e pesquisadores a implantação de modelos robustos no dispositivo. Não importa se você está criando assistentes off-line, ferramentas educacionais, aplicativos de saúde ou outros, o Gemma 3n pode suportar muitos casos de uso.
À medida que o Google continua refinando a arquitetura do Matformer, espero ver modelos multimodais ainda mais compactos, com maior precisão e menor latência. Para saber mais sobre o Gemma 3n, confira a lançamento oficial do AI Edge ou mergulhe no repositório de código aberto no GitHub.
Se você quiser explorar mais ferramentas novas de IA, recomendo estes blogs:
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Bhavishya Pandit
8 min
Tutorial
Moez Ali
Tutorial
Ryan Ong
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
Tutorial
Matt Crabtree


