
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Gemma 3n ist die neueste Familie multimodaler, offener Modelle von Google AI, die für den effizienten Einsatz auf Alltagsgeräten wie Telefonen, Tablets und Laptops entwickelt wurden. Aufgebaut auf einem Roman MatFormer Architektur mit Unterstützung für Per-Layer Embedding (PLE)-Parameter-Caching liefert Gemma 3n Leistung auf dem Gerät und minimiert gleichzeitig die Speicher- und Rechenkosten.
Ähnlich wie bei traditionellen vision-language models (VLMs)ähneln, unterstützt Gemma 3n Text-, Bild- und Audiomodalitäten. Die "3n"-Variante ist speziell für den Edge-Einsatz optimiert und wird über das Google AI Edge SDK auf CPUs, NPUs oder mobilen GPUs ausgeführt.
Das sind die wichtigsten Merkmale von Gemma 3n:
Wichtiger Hinweis: Gemma 3n unterstützt zwar Audioeingänge in seiner vollständigen Architektur, aber die Audiofunktionen sind in der öffentlichen Vorschau noch nicht verfügbar.
Du kannst Gemma 3n mit einer von drei Methoden ausprobieren:
.task von Gemma 3n wird im Google-Format ai-edge-litert veröffentlicht. Du kannst den Zugang zur Seite mit den Hugging Face-Modellen beantragen und das Modell lokal herunterladen, um es zu inferenzieren. Eine .task Datei ist ein kompaktes, laufzeitfreundliches Paket, das eine vorkompilierte Version des Modells, seine Metadaten und alle erforderlichen Konfigurationen enthält und speziell für die schnelle und sichere Ausführung auf dem Gerät mit Googles AI Edge SDK entwickelt wurde.Als Nächstes zeige ich dir, wie du eine funktionierende Android-App erstellst, die das Gemma 3n-Modell nutzt, um Bild- und Textaufforderungen zu verarbeiten. Wir verwenden Googles offizielles Galerie-Repository als Basis und passen es so an, dass es sich direkt und ohne Ablenkungen auf dem Bildschirm von Ask Image öffnet.
Beginnen wir damit, ein neues Projekt zu erstellen und das Original-Repository von Google zu klonen.
Auf deinem Laptop öffnest du das Projekt zunächst als neues Projekt in Android Studio und wählst eine leere Aktivität aus.
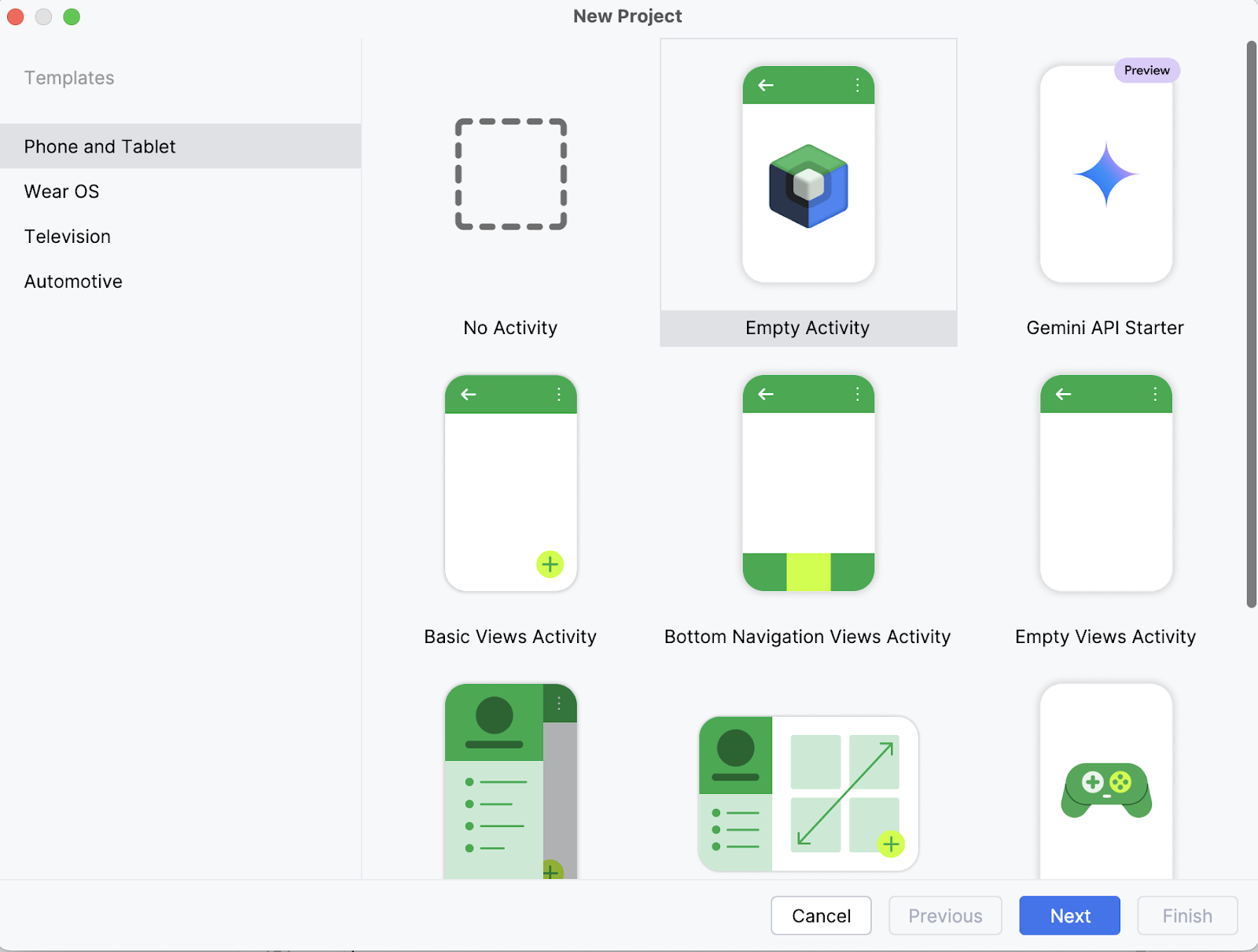
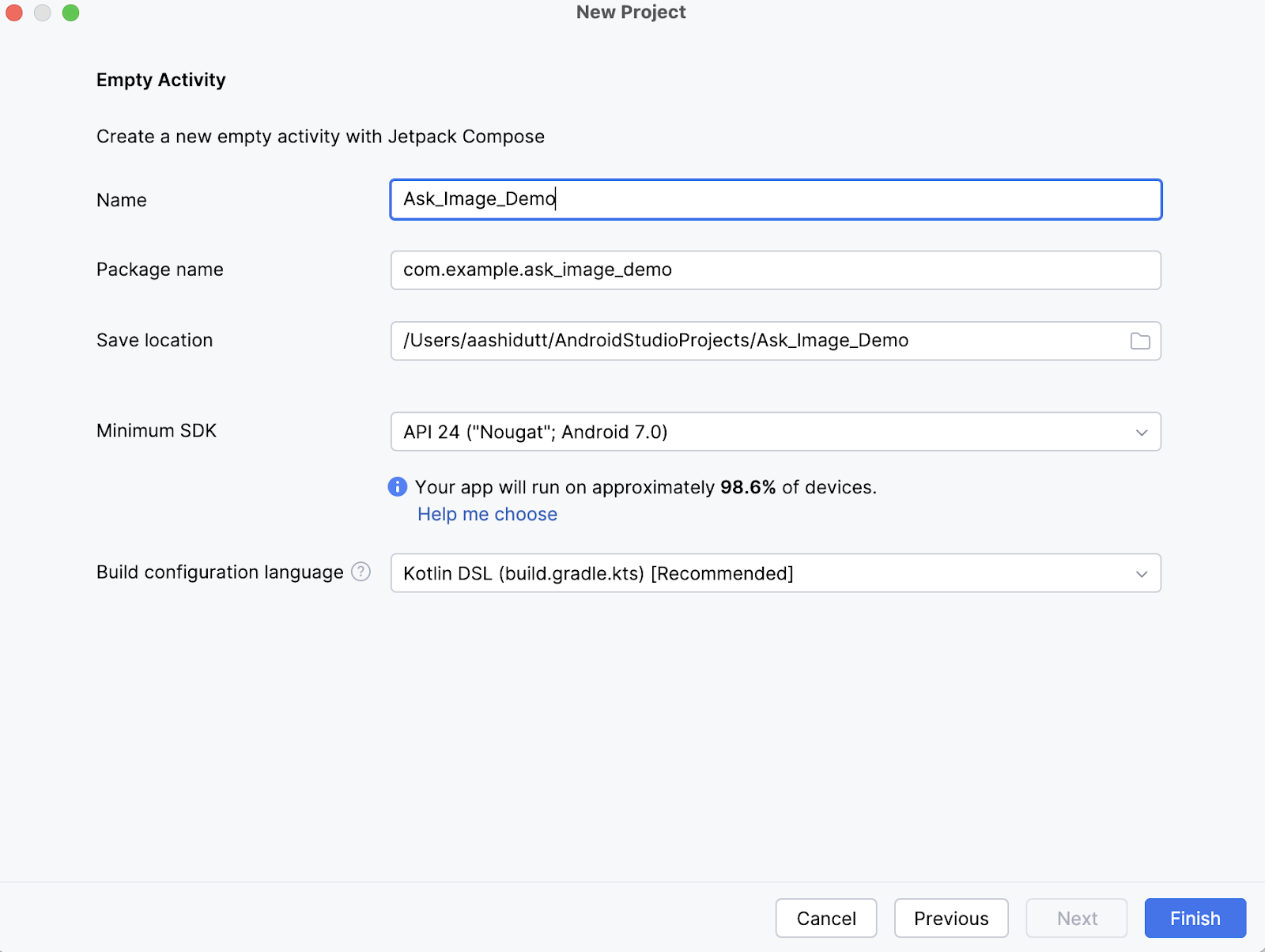
Als Nächstes gibst du den Namen deiner Aktivität ein (z.B. "Ask_Image_Demo") und lässt den Rest unverändert. Klicke dann auf Fertig stellen.
Öffne nun das Terminal in Android Studio (unten links) und führe die folgenden Bash-Befehle aus:
git clone https://github.com/google-ai-edge/gallery
cd gallery/android
Dadurch wird dein Projekt geöffnet. Du kannst alle Projektdateien auf der linken Seite der Registerkarte sehen.
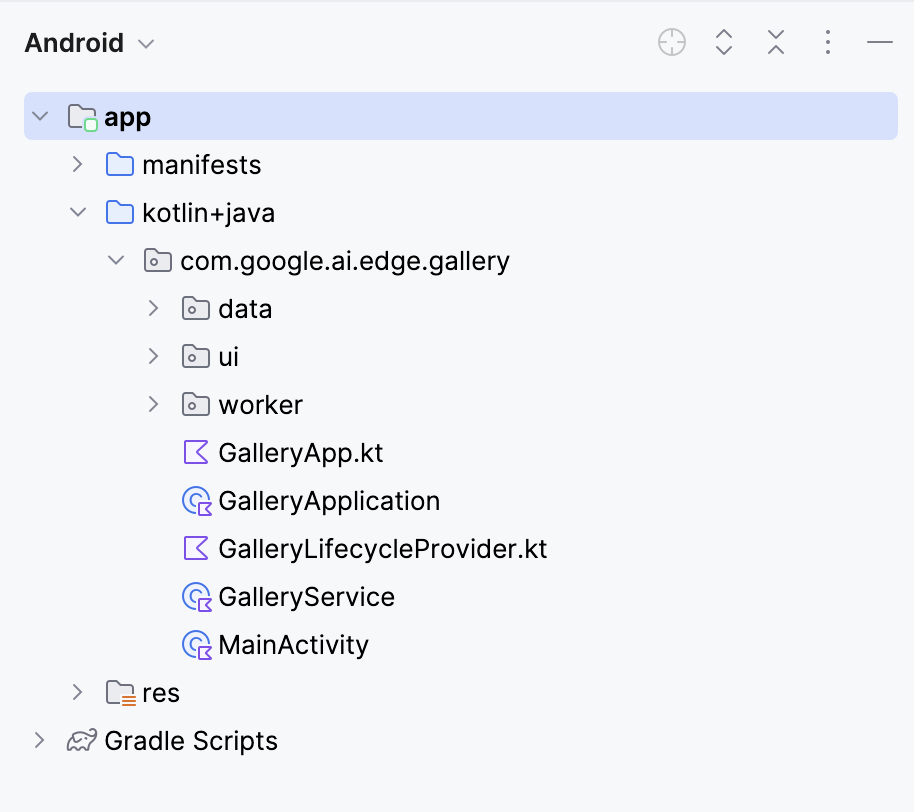
Als Nächstes bearbeiten wir ein paar Dateien, damit das Öffnen unserer App direkt zur Seite "Bild fragen" führt. Dann navigieren wir zu der Datei Tasks.kt an folgendem Ort: app/src/main/java/com/google/ai/edge/gallery/data/Tasks.kt. Um die Funktionalität der App auf die Funktion "Bild fragen" zu beschränken, werden wir die folgenden Änderungen vornehmen:
Vorher:
/** All tasks. */
val TASKS: List<Task> = listOf(
TASK_LLM_ASK_IMAGE,
TASK_LLM_PROMPT_LAB,
TASK_LLM_CHAT,
)Nach:
/** All tasks. */
val TASKS: List<Task> = listOf(
TASK_LLM_ASK_IMAGE
)Dadurch werden die anderen Demos wie Prompt Lab und Chat deaktiviert, sodass nur Ask Image angezeigt wird.
Aktualisiere in GalleryApp.kt (zu finden unter // app/src/main/java/com/google/ai/edge/gallery/GalleryApp.kt) die LaunchedEffect, um automatisch zur Bildseite zu navigieren. Diese Änderung stellt sicher, dass die App die Ask Image-Oberfläche direkt öffnet und den Standard-Bildschirm zur Aufgabenauswahl umgeht.
Vorher:
@Composable
fun GalleryApp(navController: NavHostController = rememberNavController()) {
GalleryNavHost(navController = navController)
}Nach:
package com.google.ai.edge.gallery
import androidx.compose.runtime.Composable
import androidx.compose.runtime.LaunchedEffect
import androidx.navigation.NavHostController
import androidx.navigation.compose.rememberNavController
import com.google.ai.edge.gallery.data.TASK_LLM_ASK_IMAGE
import com.google.ai.edge.gallery.ui.llmchat.LlmAskImageDestination
import com.google.ai.edge.gallery.ui.navigation.GalleryNavHost
@Composable
fun GalleryApp(
navController: NavHostController = rememberNavController()
) {
// as soon as GalleryApp comes up, navigate to Ask-Image
// and drop “home” off the back-stack:
LaunchedEffect(Unit) {
TASK_LLM_ASK_IMAGE.models
.firstOrNull() // safety: don’t crash if the models list is empty
?.name
?.let { modelName ->
navController.navigate("${LlmAskImageDestination.route}/$modelName") {
popUpTo("home") { inclusive = true }
}
}
}
GalleryNavHost(navController = navController)
}Hier ist eine Übersicht darüber, was die aktualisierte Funktion GalleryApp im neuen Code macht:
LaunchedEffect: Ein Nebeneffekt von Jetpack Compose, der einmal bei der Zusammenstellung ausgelöst wird. Hier wird sie verwendet, um die Navigationslogik sofort auszuführen, sobald GalleryApp gerendert wird.TASK_LLM_ASK_IMAGE.models.firstOrNull() holt sicher den Namen des ersten verfügbaren Bild-Text-Modells (z. B. Gemma 3n), das in der Navigation verwendet werden soll. Das verhindert, dass die App abstürzt, wenn die Modellliste leer ist.navController.navigate(): Sie leitet die App mit dem Namen des ausgewählten Modells dynamisch zum Bildschirm "Ask-Image" weiter. Dies ersetzt den üblichen Startbildschirm als Einstiegspunkt.popUpTo("home") räumt den Navigationsstapel auf, indem sie den Startbildschirm aus dem Verlauf entfernt. Dadurch wird sichergestellt, dass der/die Nutzer/in nicht über die Zurück-Schaltfläche des Systems dorthin zurück navigieren kann.Behalte den Rest des Codes so bei, wie er ist. Diese Änderungen sorgen dafür, dass die App direkt in die Ask-Image-Oberfläche startet, wenn ein gültiges Modell geladen ist, und verbessern so den Benutzerfluss für deine Demo.
Sobald du alle notwendigen Änderungen vorgenommen hast, führen wir die App aus. Um deine App auf deinem lokalen Android-Gerät auszuführen, koppelst du dein Android-Gerät mit Android Studio und verwendest das drahtlose Debugging mit den folgenden Schritten.
Gehe in die Einstellungen-App auf deinem Android-Gerät und aktiviere die Entwickleroptionen. Schalte dann Wireless debugging ein. Du solltest einen Bildschirm mit zwei Paarungsoptionen sehen.
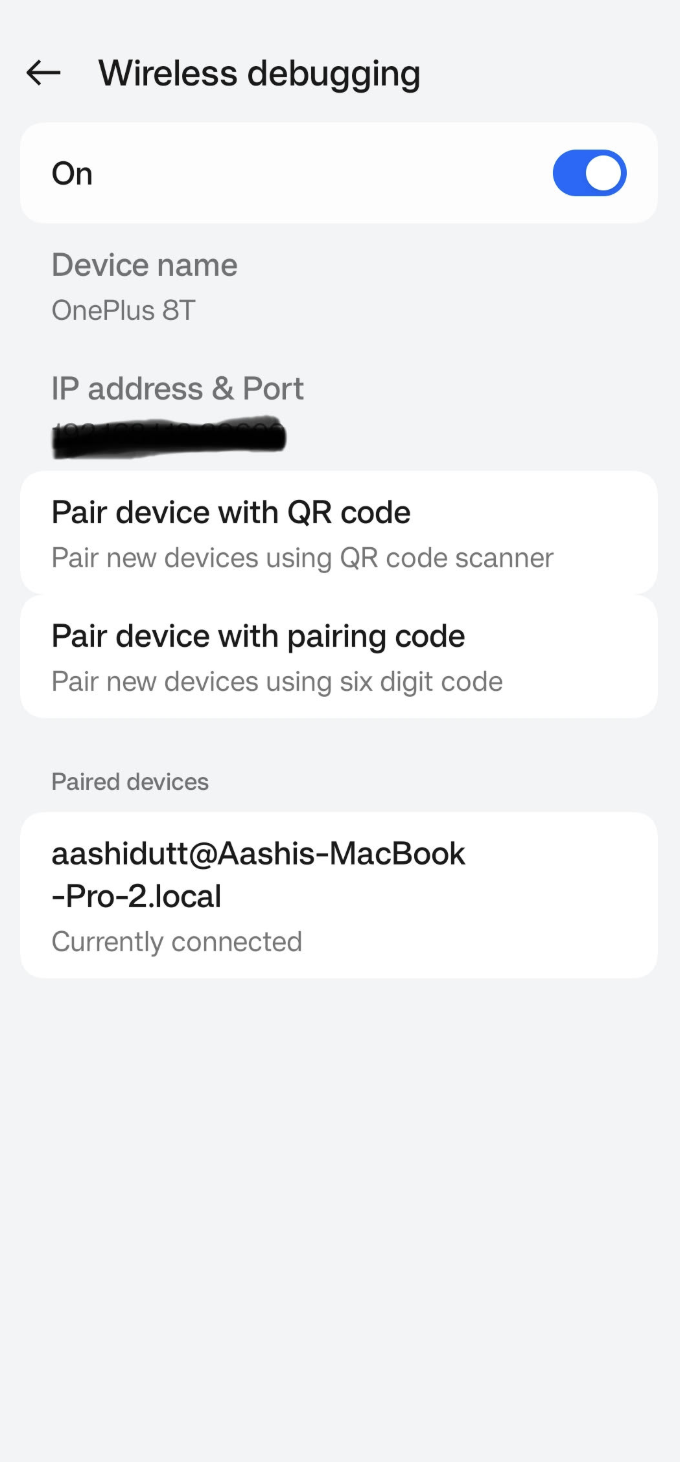
Öffnen Sie in Android Studio den Geräte-Manager (das Symbol ähnelt einem Telefon mit einem Android-Logo) und klicke auf Über QR-Code koppeln.
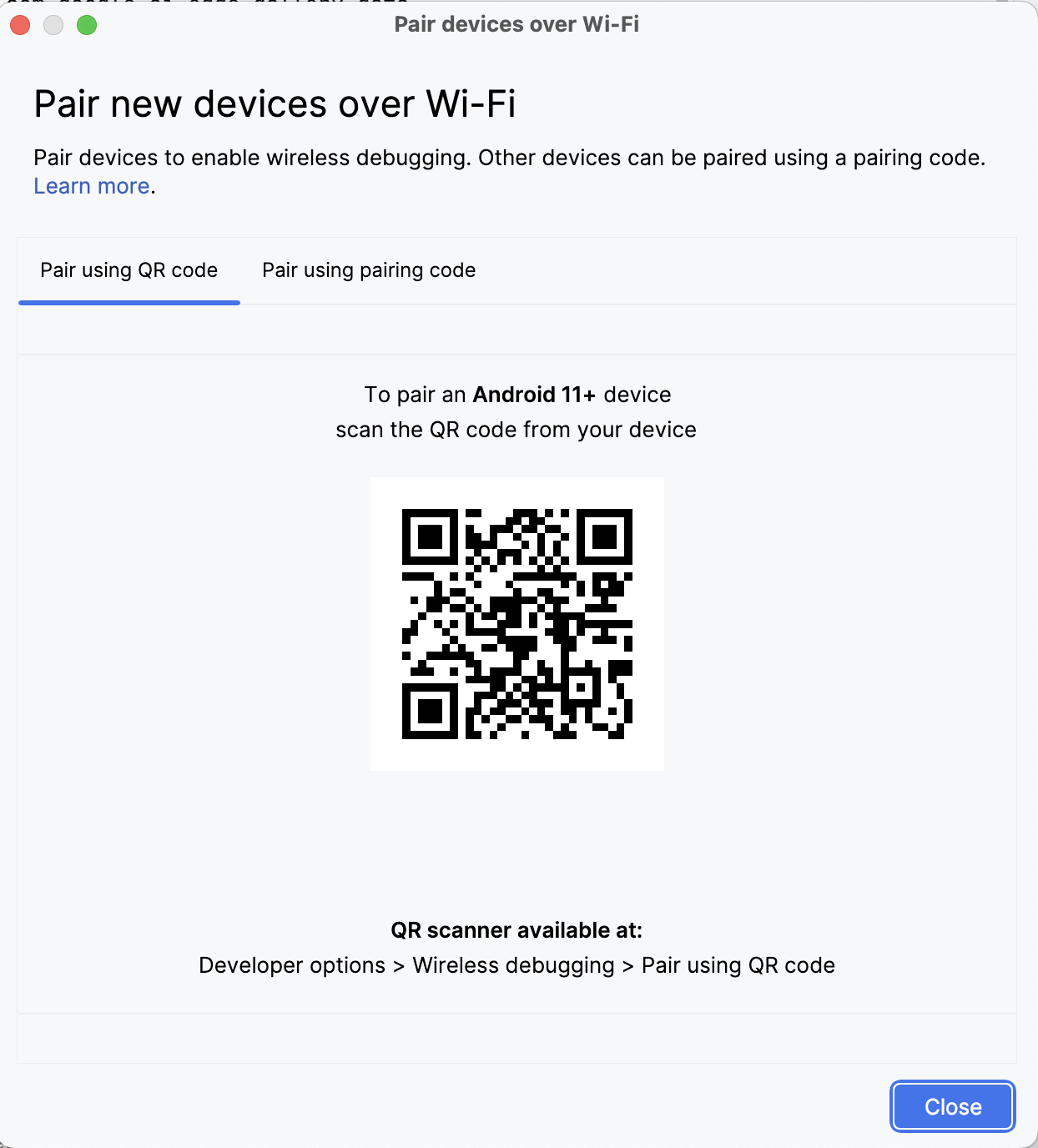
Scanne den QR-Code mit deinem Gerät und schließe die Kopplungseinrichtung ab. Sobald dein Gerät verbunden ist, siehst du deinen Gerätenamen im Gerätemanager. Vergewissere dich, dass dein System und dein Android-Gerät mit demselben WiFi-Netzwerk verbunden sind.
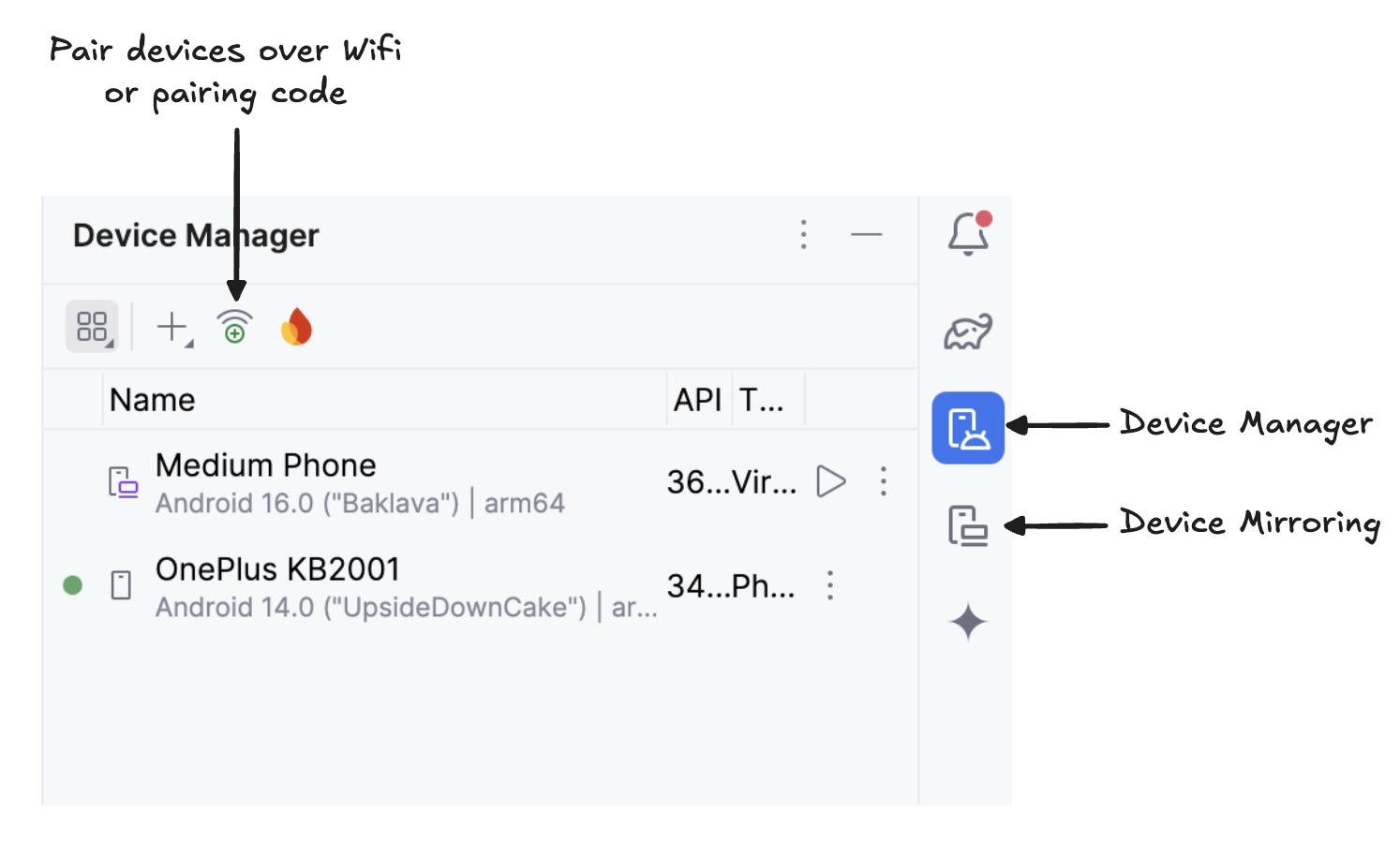
Beginne die Spiegelung deines Android-Geräts, indem du auf das SymbolDevice Mirroring klickst (das einen Desktop- und einen Telefonbildschirm darstellt). Sobald der Bildschirm deines Geräts gespiegelt wird, klickst du auf das grüne Symbol Run, um die App auf deinem Gerät zu installieren.
Die App wird gestartet und ein Browserfenster öffnet sich, in dem du aufgefordert wirst, dich bei Hugging Face anzumelden, um die Modelldatei sicher herunterzuladen.

Sobald du dich bei HuggingFace eingeloggt hast, klickst du bei dem Modell deiner Wahl auf Download starten und dein Modell wird heruntergeladen. Für dieses Beispiel verwende ich standardmäßig das Modell Gemma-3n-E2B-it-int4.
Sobald der Download abgeschlossen ist, wirst du direkt auf die Seite "Bild fragen" weitergeleitet. Als Nächstes wählst du ein bestehendes Bild aus deiner Galerie aus oder nimmst ein neues Foto mit der Kamera deines Geräts auf. Dann übergibst du eine Aufforderung zusammen mit dem Bild und schickst es an das Modell.
Hier ist ein Beispiel, das ich getestet habe.


Das Modell läuft zunächst auf der CPU. Mit dem Symbol "Tune" (dargestellt durch drei horizontale Schieberegler) kannst du auf GPU umschalten, um eine bessere Leistung zu erzielen.
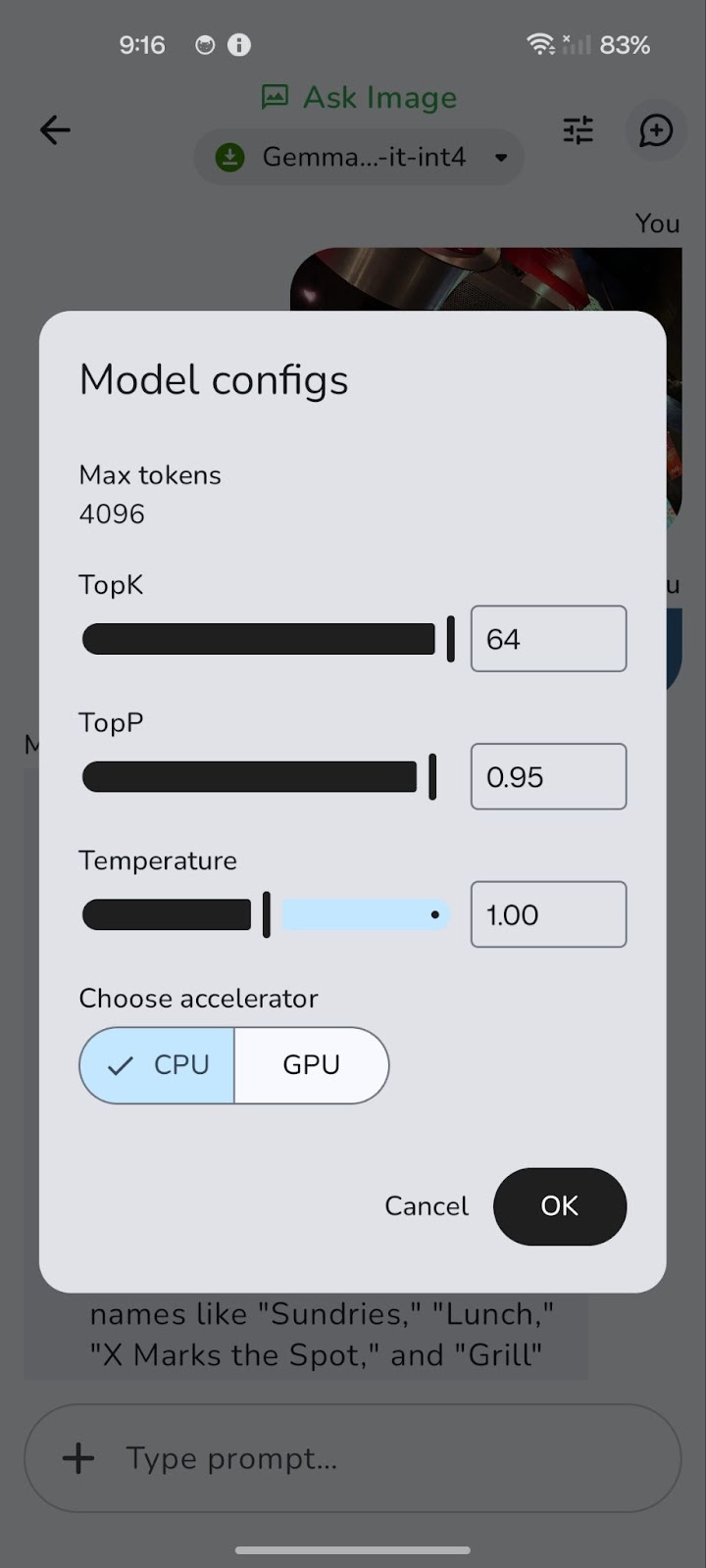
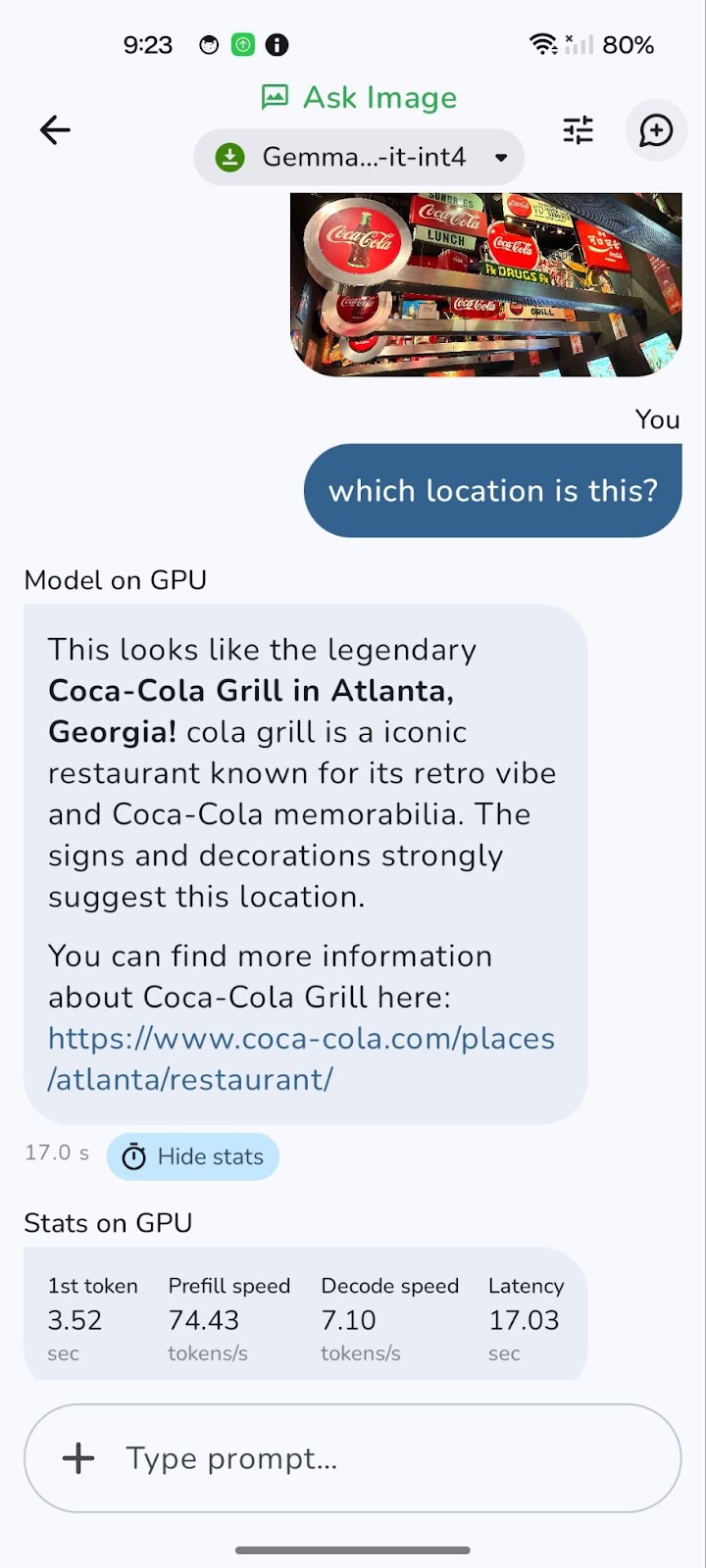
Die Umstellung auf einen Grafikprozessor kann die Gesamtlatenz erheblich reduzieren, insbesondere bei der Verarbeitung größerer Bilder und komplexerer Abfragen. Während die GPU-Verarbeitung in der Regel schnellere Dekodiergeschwindigkeiten bietet, was zu schnelleren Antworten führt, ist es erwähnenswert, dass die Ausfüllgeschwindigkeit bei der CPU manchmal geringfügig höher sein kann.
Der Grund dafür ist, dass das anfängliche Laden und Aufbereiten der Daten (Prefill) die CPU belasten kann. Der Vorteil der schnelleren Dekodierung und der insgesamt geringeren Latenz auf der GPU überwiegt jedoch in der Regel und sorgt für ein flüssigeres und reaktionsschnelleres Erlebnis.
Ich habe ein dieses GitHub-Repository eingerichtet, wenn du den gesamten Projektcode erkunden möchtest.
Wir haben untersucht, wie Gemma 3n die Beantwortung von Bild-Fragen auf Endgerätenohne die Notwendigkeit einer Cloud-Inferenz. Du hast gelernt, wie du eine .task Datei in eine leichtgewichtige Android-App integrierst, das Modell mit natürlicher Sprache abfragst und genaue Antworten zu jedem Bild bekommst, direkt von deinem Handy aus.
Diese praktische Übung zeigt, wie Gemma 3n die multimodale KI demokratisiert und es Entwicklern und Forschern erleichtert, starke Modelle auf dem Gerät einzusetzen. Egal, ob du Offline-Assistenten, Bildungstools, Apps für das Gesundheitswesen oder andere Anwendungen entwickelst, Gemma 3n kann viele Anwendungsfälle unterstützen.
Wenn Google die Matformer-Architektur weiter verfeinert, erwarte ich noch kompaktere, multimodale Modelle mit höherer Genauigkeit und geringerer Latenz. Um mehr über Gemma 3n zu erfahren, schau dir die offizielle AI Edge Veröffentlichung Blog oder stöbere im Open-Source-Repository auf GitHub.
Wenn du mehr über neue KI-Tools erfahren möchtest, empfehle ich dir diese Blogs:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
