Curso
Desarrollo de aplicaciones LLM con LangChain
3 h
46.4K
Imagina crear una aplicación con voz, como un bot de atención al cliente o un transcriptor de podcasts. Normalmente, necesitarías varias herramientas para tareas como la transcripción y la generación de audio. OpenAI's gpt-4o-audio-preview simplifica este proceso al comprender y generar tanto texto como audio.
En este tutorial, exploraremos este potente modelo y cómo utilizarlo con LangChain para un procesamiento de audio sin fisuras. Explicaré cómo configurar este modelo, trabajar con entradas de audio, generar respuestas tanto en texto como en audio, e incluso unirlo todo para construir aplicaciones del mundo real.
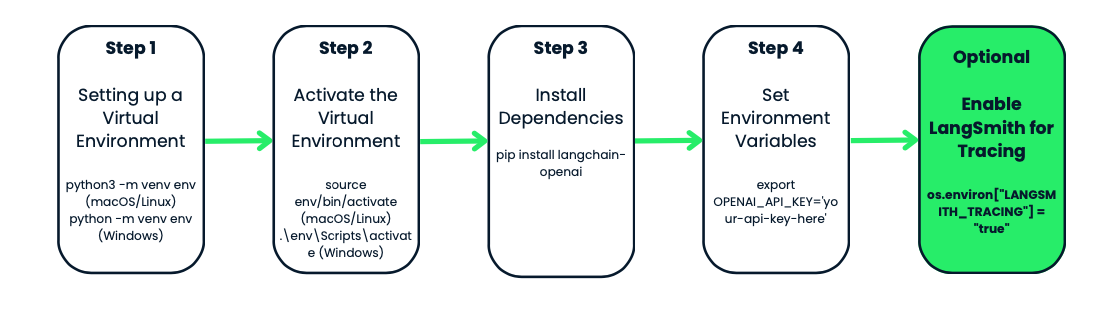
Antes de utilizar el modelo gpt-4o-audio-preview de OpenAI, vamos a configurar un entorno virtual para tu proyecto. Esto mantiene las cosas organizadas y evita conflictos de dependencias, lo que es especialmente útil cuando se trabaja con varios proyectos.
Imagina que tienes dos proyectos diferentes. Uno de ellos necesita la versión 1.0 de un paquete, mientras que el otro necesita la versión 2.0. Si instalas todo globalmente, te encontrarás con conflictos.
Los entornos virtuales crean un espacio de trabajo aislado, algo así como una burbuja, donde puedes instalar lo que necesites para un proyecto concreto. Cuando creas un entorno para tu proyecto, ya no tienes que preocuparte por romper la configuración de Python de tu sistema o por paquetes conflictivos.
Empecemos creando un entorno virtual para nuestro proyecto. Utilizaremos el módulo incorporado de Python módulo venv. Vamos a ne to:
python3 -m venv env. En Windows, tiene este aspecto python -m venv env.venv es la herramienta de Python para crear entornos virtuales, y env es el nombre de la carpeta del entorno. Puedes ponerle el nombre que quieras: env, venv, mi_proyecto_env, etc. Es una buena práctica hacerlo breve y sencillosource env/bin/activate. En Windows, utiliza: .\env\Scripts\activateObservarás que el indicador de tu terminal cambia a algo como env-esto es señal de que estás trabajando dentro de tu entorno virtual-. A partir de ahora, cualquier paquete que instales o comando que ejecutes estará aislado en este proyecto.
Con tu entorno activado, es hora de instalar las herramientas que necesitas. Como estamos trabajando con OpenAI y LangChain, vamos a empezar instalando el paquete langchain-openai. Este paquete nos permitirá interactuar con los modelos de OpenAI.
Ejecuta esto en tu terminal: pip install langchain-openai.
El siguiente paso es asegurarte de que tu información sensible, como las claves API, no acabe codificada en tus scripts. Lo haremos estableciendo variables de entorno.
Lo primero es lo primero: necesitarás acceso a los modelos de OpenAI. Si aún no lo has hecho, dirígete a la plataforma OpenAI y crea una cuenta. Una vez que te hayas registrado, tendrás que generar una clave API. Esta clave API es tu pase para acceder a los modelos de OpenAI, incluido el gpt-4o-audio-preview.
En nuestro caso, tendremos que fijar la dirección OPENAI_API_KEY. Puedes configurarlo manualmente cada vez que trabajes en tu proyecto, o utilizar un archivo .env para almacenarlo y acceder a él fácilmente. Veamos ambos métodos.
Si sólo estás trabajando temporalmente y quieres una configuración rápida, puedes establecer la variable de entorno directamente en tu terminal.
export OPENAI_API_KEY='your-api-key-here'set OPENAI_API_KEY='your-api-key-here'Ahora tu clave API está disponible en tu script, y puedes acceder a ella utilizando el módulo os de Python.
Si prefieres una solución más permanente, puedes utilizar un archivo .env para almacenar tus variables de entorno. Este archivo se guardará en la carpeta de tu proyecto y mantendrá a salvo tus claves.
Primero, crea un archivo .env en el directorio de tu proyecto, y dentro, añade tu clave API de la siguiente manera:
OPENAI_API_KEY=your-api-key-hereA continuación, instala el paquete python-dotenv:
pip install python-dotenvAhora, en tu script de Python, carga las variables de entorno desde el archivo .env de la siguiente manera:
from dotenv import load_dotenv
import os
load_dotenv() # Load variables from .env file
api_key = os.getenv('OPENAI_API_KEY')Este método es especialmente útil si tienes que gestionar múltiples variables de entorno, y mantiene tu código limpio y seguro.
Si quieres rastrear y monitorizar tus llamadas a la API con fines de depuración o rendimiento, OpenAI tiene una función genial llamada LangSmith. Te proporciona registros detallados de cada llamada a la API realizada por tu modelo, lo que puede ser muy útil si intentas optimizar o solucionar problemas de tu flujo de trabajo.
Puedes activar el rastreo de LangSmith así:
os.environ["LANGSMITH_API_KEY"] = getpass.getpass("Enter your LangSmith API key: ")
os.environ["LANGSMITH_TRACING"] = "true"De nuevo, esto es totalmente opcional, pero es una herramienta útil si estás trabajando en una aplicación compleja y quieres controlar cómo se comportan tus modelos.
Ahora que ya tenemos nuestro entorno configurado y listo para funcionar, es hora de pasar a la parte divertida: demostrar el modelo gpt-4o-audio-preview de OpenAI. Aquí es donde empezamos a interactuar con el modelo, a hacer peticiones y a procesar entradas y salidas.
En esta sección, veremos cómo instanciar el modelo utilizando el marco LangChain, personalizar algunos parámetros básicos y configurar todo lo necesario para empezar a generar respuestas.
Antes de entrar en el código, tomémonos un momento para entender qué significa "instanciar" el modelo. Cuando decimos que estamos instanciando el modelo, esencialmente estamos creando un objeto en Python que nos permitirá interactuar con el modelo gpt-4o-audio-preview. Este objeto es como el panel de control: contiene todos los ajustes, configuraciones y métodos que necesitaremos para enviar datos al modelo y obtener resultados.
Empecemos por crear este objeto modelo. Como estamos trabajando en el marco LangChain, utilizaremos la clase ChatOpenAI del paquete langchain_openai. Esta clase nos permite acceder fácilmente a los modelos OpenAI y a sus funcionalidades.
from langchain_openai import ChatOpenAI
# Create the model object
llm = ChatOpenAI(
model="gpt-4o-audio-preview", # Specifying the model
temperature=0, # Controls randomness in the output
max_tokens=None, # Unlimited tokens in output (or specify a max if needed)
timeout=None, # Optional: Set a timeout for requests
max_retries=2 # Number of retries for failed requests
)Una de las grandes ventajas de este modelo es lo personalizable que es. Puedes ajustar los parámetros en función de lo que necesites. Por ejemplo, si estás creando una aplicación que requiere la transcripción de audio, puedes ajustar los parámetros para manejar entradas más grandes o limitar la longitud de la salida.
Por ejemplo, si se trata de solicitudes sensibles al tiempo y quieres asegurarte de que el modelo no tarda demasiado, también puedes establecer un tiempo de espera:
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
timeout=30 # Set timeout to 30 seconds
)Ahora que ya tenemos el modelo gpt-4o-audio-preview en funcionamiento, vamos a entrar en la capacidad de manejar entradas y salidas de audio.
Antes de que puedas empezar a trabajar con audio, el primer paso es cargar y codificar tu archivo de audio en un formato que el modelo pueda entender. OpenAI espera que los datos de audio se envíen en un formato codificado en base64, así que empezaremos subiendo un archivo y codificándolo.
Digamos que tienes un archivo .wav que quieres que procese el modelo - yo lo he llamado gpt.wav. Puedes sustituirlo por tu archivo utilizando el siguiente código. A continuación te explicamos cómo puedes cargar y preparar ese archivo:
import base64
# Open the audio file and convert to base64
with open("gpt.wav", "rb") as f:
audio_data = f.read()
# Convert binary audio data to base64
audio_b64 = base64.b64encode(audio_data).decode()¿Qué ocurre aquí? Estamos leyendo el archivo de audio como datos binarios (modo "rb"), y luego utilizamos la biblioteca base64 para codificarlo en una cadena base64. Este es el formato que OpenAI necesita para procesar las entradas de audio.
Una vez codificado tu audio, es hora de pasarlo al modelo. El modelo gpt-4o-audio-preview puede transcribir voz de archivos de audio, así que si alguna vez has necesitado convertir en texto un podcast, una nota de voz o una grabación de una reunión, ¡esto es exactamente lo que estabas esperando! Veamos cómo funciona.
# Define the input message with audio
messages = [
(
"human",
[
{"type": "text", "text": "Transcribe the following:"},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Send the request to the model and get the transcription
output_message = llm.invoke(messages)
print(output_message.content)En este ejemplo, estamos enviando dos datos al modelo:
El modelo procesa esta entrada y devuelve una transcripción del audio. Así, si tu archivo de audio contuviera algo como una frase hablada: "Estoy aprendiendo a utilizar la IA", el modelo devolvería una salida de texto como: "Estoy aprendiendo a utilizar la IA".
Pero el modelo gpt-4o-audio-preview no se limita a comprender el audio, también puede generarlo. A continuación te explicamos cómo puedes configurar el modelo para generar salidas de audio:
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
temperature=0,
model_kwargs={
"modalities": ["text", "audio"], # We’re telling the model to handle both text and audio
"audio": {"voice": "alloy", "format": "wav"}, # Configure voice and output format
}
)
# Send a request and ask the model to respond with audio
messages = [("human", "Are you human? Reply either yes or no.")]
output_message = llm.invoke(messages)
# Access the generated audio data
audio_response = output_message.additional_kwargs['audio']['data']Vamos a desentrañar esto:
La respuesta de audio codificada en base64 se almacena en output_message.additional_kwargs['audio']['data'], y puedes descodificar y guardar fácilmente este archivo para reproducirlo.
Ahora que estás generando audio, probablemente quieras guardar el archivo y reproducirlo, ¿verdad? He aquí cómo puedes tomar esos datos de audio codificados en base64, descodificarlos y guardarlos como un archivo .wav:
# Decode the base64 audio data
audio_bytes = base64.b64decode(output_message.additional_kwargs['audio']['data'])
# Save the audio file
with open("output.wav", "wb") as f:
f.write(audio_bytes)
print("Audio saved as output.wav")Ahora puedes reproducir este archivo.wav en tu máquina local utilizando cualquier reproductor multimedia. Así que ahora, cuando invoques al modelo, no sólo generará una respuesta de texto, sino también un archivo de audio que diga la respuesta.
En esta sección, explicaré cómo vincular herramientas al modelo gpt-4o-audio-preview, manejar flujos de trabajo más complejos e incluso encadenar varios pasos para crear soluciones totalmente automatizadas. Si alguna vez has querido crear un asistente de voz que no sólo transcriba audio, sino que también obtenga información de fuentes externas, esta sección te será útil.
Empecemos por la llamada a la herramienta. Se trata de enseñar a tu modelo de IA a utilizar herramientas o funciones externas para mejorar sus capacidades. En lugar de limitarse a procesar texto o audio, el modelo puede realizar tareas adicionales como obtener datos de API, hacer cálculos o incluso buscar información meteorológica.
El modelo gpt-4o-audio-preview de OpenAI puede combinarse con otras herramientas y funciones utilizando el método bind_tools de LangChain. Con este método, puedes crear un flujo de trabajo fluido en el que el modelo decida cuándo y cómo utilizar las herramientas que le has proporcionado.
Voy a guiarte a través de un ejemplo práctico de vinculación de una herramienta al modelo. En este caso, vamos a enlazar una herramienta que busque el tiempo.
En primer lugar, definimos un modelo pydántico que represente la herramienta que queremos utilizar. A continuación, vinculamos esa herramienta al modelo gpt-4o-audio-preview para que pueda ser invocada cuando sea necesario. Para ello, necesitarás una clave API de OpenWeatherMap.
import requests
from pydantic import BaseModel, Field
# Define a tool schema using Pydantic
class GetWeather(BaseModel):
"""Get the current weather in a given location."""
location: str = Field(..., description="The city and state, e.g. Edinburgh, UK")
def fetch_weather(self):
# Using OpenWeatherMap API to fetch real-time weather
API_KEY = "YOUR_API_KEY_HERE" # Replace with your actual API key
base_url = f"http://api.openweathermap.org/data/2.5/weather?q={self.location}&APPID={API_KEY}&units=metric"
response = requests.get(base_url)
if response.status_code == 200:
data = response.json()
weather_description = data['weather'][0]['description']
temperature = data['main']['temp']
return f"The weather in {self.location} is {weather_description} with a temperature of {temperature}°C."
else:
# Print the status code and response for debugging
print(f"Error: {response.status_code}, {response.text}")
return f"Could not fetch the weather for {self.location}."
# Example usage
weather_tool = GetWeather(location="Edinburgh, GB") # Using city name and country code
ai_msg = weather_tool.fetch_weather()
print(ai_msg)Veamos en qué consiste:
En este ejemplo concreto, quiero saber el tiempo que hace en Edimburgo. Cuando lo ejecuté, obtuve este resultado: El tiempo en Edimburgo, GB, es de nubes rotas, con una temperatura de 13,48°C.
Encadenando tareas, puedes crear flujos de trabajo de varios pasos que combinen varias herramientas y llamadas a modelos para gestionar solicitudes complejas. Imagina un escenario en el que quieres que tu asistente transcriba un audio y luego realice una acción para el lugar mencionado en el audio. En este ejemplo, encadenaremos una tarea de transcripción de audio con una búsqueda meteorológica basada en la ubicación transcrita.
import base64
import requests
from pydantic import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# Define the tool schema for fetching weather
class GetWeather(BaseModel):
"""Get the current weather in a given location."""
location: str = Field(..., description="The city and state, e.g. Edinburgh, UK")
def fetch_weather(self):
# Using OpenWeatherMap API to fetch real-time weather
API_KEY = "YOUR_API_KEY_HERE" # Replace with your actual API key
base_url = f"http://api.openweathermap.org/data/2.5/weather?q={self.location}&appid={API_KEY}&units=metric"
response = requests.get(base_url)
if response.status_code == 200:
data = response.json()
weather_description = data['weather'][0]['description']
temperature = data['main']['temp']
return f"The weather in {self.location} is {weather_description} with a temperature of {temperature}°C."
else:
return f"Could not fetch the weather for {self.location}."
# Instantiate the LLM model
llm = ChatOpenAI(
model="gpt-4o-audio-preview"
)
# Function to handle audio transcription using the LLM
def audio_to_text(audio_b64: str) -> str:
# Define the message to send for transcription
messages = [
(
"human",
[
{"type": "text", "text": "Transcribe the following:"},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Invoke the model and get the transcription
output_message = llm.invoke(messages)
# Return the transcription from the model's output
return output_message.content
# Create a prompt template for transcription and weather lookup
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are an assistant that transcribes audio and fetches weather information."),
("human", "Transcribe the following and tell me the weather in the location mentioned in the audio."),
]
)
# Bind the tool to the model
llm_with_tools = llm.bind_tools([GetWeather])
# Chain the transcription and weather tool
chain = prompt | llm_with_tools
# Read and encode the audio file in base64
audio_file = "weather_input.wav" #Replace with your audio file
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Transcribe the audio to get the location
transcribed_location = audio_to_text(audio_b64)
# Print the transcription result for debugging
print(f"Transcribed location: {transcribed_location}")
# Check if transcription returned a valid result
if transcribed_location:
# Fetch weather for the transcribed location
weather_tool = GetWeather(location=transcribed_location)
weather_result = weather_tool.fetch_weather()
print(f"Weather result: {weather_result}")
else:
print("No valid location was transcribed from the audio.")Desglosemos el código:
Para este ejemplo, le di al modelo un archivo de audio en el que decía: "Edimburgo". Este es el resultado que obtuve:Ubicación transcrita: Edimburgo
Resultado meteorológico: El tiempo en Edimburgo es de nubes rotas, con una temperatura de 13,47°C.

En algunos casos, puede que quieras afinar el modelo para manejar tareas específicas con mayor eficacia. Por ejemplo, si estás creando una aplicación que transcribe audio médico, puede que quieras que el modelo tenga un profundo conocimiento de los términos y la jerga médica. OpenAI te permite afinar el modelo entrenándolo con conjuntos de datos personalizados.
Veamos cómo hacerlo:
import base64
from langchain_openai import ChatOpenAI
# Step 1: Instantiate the fine-tuned audio-capable model
fine_tuned_model = ChatOpenAI(
temperature=0,
model="ft:gpt-4o-audio-preview:your-organization::model-id"
)
# Step 2: Capture and encode the input audio file (medical report)
audio_file = "medical_report.wav"
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Step 3: Create the message structure for transcription request
messages = [
(
"human",
[
{"type": "text", "text": "Please transcribe this medical report audio."},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Step 4: Invoke the fine-tuned model to transcribe the audio
result = fine_tuned_model.invoke(messages)
# Step 5: Extract and print the transcribed text from the response
transcription = result.content # This contains the transcription
print(f"Transcription: {transcription}")
# Debugging: Print the full structure of the additional_kwargs for inspection
print(result.additional_kwargs)Utiliza un modelo ajustado y entrenado específicamente para tratar audio médico, pero también puedes ajustar modelos para otros casos de uso, como transcripciones jurídicas, grabaciones de atención al cliente o edición de podcasts.
Por último, veamos un ejemplo práctico en el que construimos un asistente de voz que escucha las consultas del usuario mediante audio, genera una respuesta y responde mediante audio.
Este es el flujo de trabajo que vamos a seguir:
Veamos cómo codificar esto:
import base64
from langchain_openai import ChatOpenAI
# Step 1: Instantiate the audio-capable model with configuration for generating audio
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
temperature=0,
model_kwargs={
"modalities": ["text", "audio"], # Enable both text and audio modalities
"audio": {"voice": "alloy", "format": "wav"}, # Set the desired voice and output format
}
)
# Step 2: Capture and encode the audio
audio_file = "math_joke_audio.wav" #You can replace your audio file here
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Step 3: Create the message structure for transcription and audio response
messages = [
(
"human",
[
{"type": "text", "text": "Answer the question."},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Step 4: Invoke the model to transcribe the audio and generate a response
result = llm.invoke(messages)
# Step 5: Extract the audio response
audio_response = result.additional_kwargs.get('audio', {}).get('data') # Safely check if audio exists
# Step 6: Save the audio response to a file if it exists
if audio_response:
# Decode the base64 audio data and save it as a .wav file
audio_bytes = base64.b64decode(audio_response)
with open("response.wav", "wb") as f:
f.write(audio_bytes)
print("Audio response saved as 'response.wav'")
else:
print("No audio response available")Veamos cómo funciona:
Este asistente está hecho para hablar con audio. Escucha la voz del usuario, entiende la pregunta y responde con su propia voz. Esta configuración es genial para crear asistentes de voz sencillos, ¡y puedes hacerla más avanzada más adelante si es necesario!

En este tutorial, exploramos el modelo gpt-4o-audio-preview de OpenAI, cubriendo la configuración, la entrada/salida de audio, los casos de uso avanzados e incluso la construcción de un asistente de voz básico. Este potente modelo proporciona una base sólida para crear aplicaciones de audio del mundo real.
Si quieres mejorar tus conocimientos prácticos sobre LangChain, te recomiendo estos blogs:
Aprende IA con estos cursos
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
9 min
blog
Matt Crabtree
13 min
blog
Abid Ali Awan
10 min
Tutorial
Kurtis Pykes
Tutorial
Adel Nehme