
Course
Efficient AI Model Training with PyTorch
4 hr
1.5K
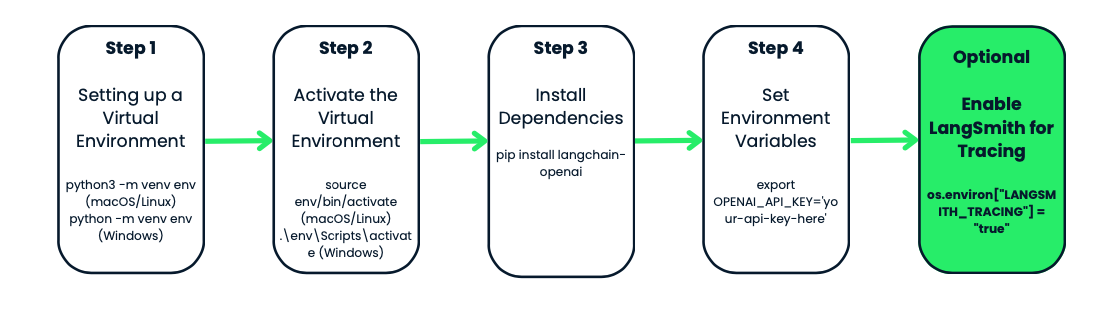
Before using OpenAI's gpt-4o-audio-preview model, let's set up a virtual environment for your project. This keeps things organized and prevents dependency conflicts, which is especially useful when working with multiple projects.
Imagine you have two different projects. One of them requires version 1.0 of a package, while the other needs version 2.0. If you install everything globally, you’re going to run into conflicts.
Virtual environments create an isolated workspace, kind of like a bubble, where you can install whatever you need for a specific project. When you create an environment for your project, there is no more worrying about breaking your system’s Python setup or conflicting packages.
Let’s get started by creating a virtual environment for our project. We’ll be using Python’s built-in venv module. We’ll ne to:
python3 -m venv env. On Windows, it looks like this python -m venv env.venv is Python’s tool for creating virtual environments, and env is the name of the environment folder. You can name it anything you like: env, venv, my_project_env, etc. It’s good practice to keep it short and simplesource env/bin/activate. On Windows, use: .\env\Scripts\activateYou’ll notice that your terminal prompt changes to something like env—this is a sign that you’re working inside your virtual environment. From now on, any packages you install or commands you run will be isolated to this project.
With your environment activated, it’s time to install the tools you need. Since we’re working with OpenAI and LangChain, let’s start by installing the langchain-openai package. This package will allow us to interact with OpenAI’s models.
Run this in your terminal: pip install langchain-openai.
The next step is making sure your sensitive information, like API keys, don’t end up hard-coded in your scripts. We’ll do this by setting environment variables.
First things first, you’ll need access to OpenAI’s models. If you haven’t already, head over to the OpenAI platform and create an account. Once you’ve signed up, you’ll need to generate an API key. This API key is your pass to access OpenAI’s models, including the gpt-4o-audio-preview.
In our case, we’ll need to set the OPENAI_API_KEY. You can set this manually every time you work on your project, or use an .env file to store it for easy access. Let’s look at both methods.
If you’re just working temporarily and want a quick setup, you can set the environment variable directly in your terminal.
export OPENAI_API_KEY='your-api-key-here'set OPENAI_API_KEY='your-api-key-here'Now your API key is available in your script, and you can access it using the os module in Python.
If you prefer a more permanent solution, you can use a .env file to store your environment variables. This file will sit in your project folder and keep your keys safe.
First, create a .env file in your project directory, and inside, add your API key like this:
OPENAI_API_KEY=your-api-key-hereNext, install the python-dotenv package:
pip install python-dotenvNow, in your Python script, load the environment variables from the .env file like this:
from dotenv import load_dotenv
import os
load_dotenv() # Load variables from .env file
api_key = os.getenv('OPENAI_API_KEY')This method is particularly useful if you have multiple environment variables to manage, and it keeps your code clean and secure.
If you want to track and monitor your API calls for debugging or performance purposes, OpenAI has a cool feature called LangSmith. It gives you detailed logs of every API call made by your model, which can be super helpful if you're trying to optimize or troubleshoot your workflow.
You can enable LangSmith tracing like this:
os.environ["LANGSMITH_API_KEY"] = getpass.getpass("Enter your LangSmith API key: ")
os.environ["LANGSMITH_TRACING"] = "true"Again, this is totally optional, but it’s a handy tool if you’re working on a complex application and want to monitor how your models behave.
Now that we’ve got our environment set up and ready to go, it’s time to get to the fun part—instantiating OpenAI’s gpt-4o-audio-preview model. This is where we start interacting with the model, making requests, and processing inputs and outputs.
In this section, we’ll walk through how to instantiate the model using the LangChain framework, customize some basic parameters, and set up everything you need to start generating responses.
Before we get into the code, let’s take a moment to understand what it means to "instantiate" the model. When we say we’re instantiating the model, we’re essentially creating an object in Python that will allow us to interact with the gpt-4o-audio-preview model. This object is like the control panel - it holds all the settings, configurations, and methods we’ll need to send data to the model and get results back.
Let’s get started by creating this model object. Since we’re working within the LangChain framework, we’ll use the ChatOpenAI class from the langchain_openai package. This class gives us easy access to the OpenAI models and their functionalities.
from langchain_openai import ChatOpenAI
# Create the model object
llm = ChatOpenAI(
model="gpt-4o-audio-preview", # Specifying the model
temperature=0, # Controls randomness in the output
max_tokens=None, # Unlimited tokens in output (or specify a max if needed)
timeout=None, # Optional: Set a timeout for requests
max_retries=2 # Number of retries for failed requests
)One of the great things about this model is how customizable it is. You can tweak the parameters depending on what you need. For example, if you’re building an application that requires audio transcription, you can adjust the parameters to handle larger inputs or limit the output length.
For instance, if you’re dealing with time-sensitive requests and want to make sure the model doesn’t take too long, you can also set a timeout:
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
timeout=30 # Set timeout to 30 seconds
)Now that we’ve got the gpt-4o-audio-preview model up and running, let’s get into the ability to handle audio inputs and outputs.
Before you can start working with audio, the first step is to load and encode your audio file into a format that the model can understand. OpenAI expects audio data to be sent in a base64-encoded format, so we’ll start by uploading a file and encoding it.
Let’s say you have a .wav file that you want the model to process - I have named it gpt.wav. You can replace this with your file using the following code. Here’s how you can load and prepare that file:
import base64
# Open the audio file and convert to base64
with open("gpt.wav", "rb") as f:
audio_data = f.read()
# Convert binary audio data to base64
audio_b64 = base64.b64encode(audio_data).decode()What’s happening here? We’re reading the audio file as binary data ("rb" mode), then using the base64 library to encode it into a base64 string. This is the format that OpenAI requires for processing audio inputs.
Once your audio is encoded, it’s time to pass it to the model. The gpt-4o-audio-preview model can transcribe speech from audio files—so if you’ve ever needed to turn a podcast, voice memo, or meeting recording into text, this is exactly what you’ve been waiting for! Let’s see how this works.
# Define the input message with audio
messages = [
(
"human",
[
{"type": "text", "text": "Transcribe the following:"},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Send the request to the model and get the transcription
output_message = llm.invoke(messages)
print(output_message.content)In this example, we’re sending two pieces of data to the model:
The model processes this input and returns a transcription of the audio. So, if your audio file contained something like a spoken sentence, "I’m learning how to use AI," the model would return a text output like: "I'm learning how to use AI."
But the gpt-4o-audio-preview model isn’t just about understanding audio—it can also generate it. Here’s how you can configure the model to generate audio outputs:
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
temperature=0,
model_kwargs={
"modalities": ["text", "audio"], # We’re telling the model to handle both text and audio
"audio": {"voice": "alloy", "format": "wav"}, # Configure voice and output format
}
)
# Send a request and ask the model to respond with audio
messages = [("human", "Are you human? Reply either yes or no.")]
output_message = llm.invoke(messages)
# Access the generated audio data
audio_response = output_message.additional_kwargs['audio']['data']Let’s unpack this:
The base64-encoded audio response is stored in output_message.additional_kwargs['audio']['data'], and you can easily decode and save this file for playback.
Now that you’re generating audio, you probably want to save the file and play it back, right? Here’s how you can take that base64-encoded audio data, decode it, and save it as a .wav file:
# Decode the base64 audio data
audio_bytes = base64.b64decode(output_message.additional_kwargs['audio']['data'])
# Save the audio file
with open("output.wav", "wb") as f:
f.write(audio_bytes)
print("Audio saved as output.wav")You can now play this .wav file on your local machine using any media player. So now, when you invoke the model, it generates not only a text response but also an audio file that says the response.
In this section, I’ll cover how to bind tools to the gpt-4o-audio-preview model, handle more complex workflows, and even chain multiple steps together to create fully automated solutions. If you’ve ever wanted to build a voice assistant that not only transcribes audio but also fetches information from external sources, this section will be helpful.
Let’s start with tool calling. This is teaching your AI model how to use external tools or functions to improve its capabilities. Instead of just processing text or audio, the model can perform additional tasks like fetching data from APIs, doing calculations, or even looking up weather information.
OpenAI’s gpt-4o-audio-preview model can be combined with other tools and functions using LangChain’s bind_tools method. With this method, you can create a smooth workflow where the model decides when and how to use the tools you’ve provided.
I am going to walk you through a practical example of binding a tool to the model. In this case, we’re going to bind a tool that fetches the weather.
First, we define a Pydantic model that represents the tool we want to use. Then, we bind that tool to the gpt-4o-audio-preview model so it can be invoked when necessary. For this, you will need an API key from OpenWeatherMap.
import requests
from pydantic import BaseModel, Field
# Define a tool schema using Pydantic
class GetWeather(BaseModel):
"""Get the current weather in a given location."""
location: str = Field(..., description="The city and state, e.g. Edinburgh, UK")
def fetch_weather(self):
# Using OpenWeatherMap API to fetch real-time weather
API_KEY = "YOUR_API_KEY_HERE" # Replace with your actual API key
base_url = f"http://api.openweathermap.org/data/2.5/weather?q={self.location}&APPID={API_KEY}&units=metric"
response = requests.get(base_url)
if response.status_code == 200:
data = response.json()
weather_description = data['weather'][0]['description']
temperature = data['main']['temp']
return f"The weather in {self.location} is {weather_description} with a temperature of {temperature}°C."
else:
# Print the status code and response for debugging
print(f"Error: {response.status_code}, {response.text}")
return f"Could not fetch the weather for {self.location}."
# Example usage
weather_tool = GetWeather(location="Edinburgh, GB") # Using city name and country code
ai_msg = weather_tool.fetch_weather()
print(ai_msg)Let’s see what it’s going on:
In this particular example, I want to know the weather in Edinburgh. When I ran it, I got this output: The weather in Edinburgh, GB is broken clouds with a temperature of 13.48°C.
By chaining tasks, you can create multi-step workflows that combine multiple tools and model calls to handle complex requests. Imagine a scenario where you want your assistant to transcribe audio and then perform an action for the location mentioned in the audio. In this example, we’ll chain an audio transcription task with a weather lookup based on the transcribed location.
import base64
import requests
from pydantic import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# Define the tool schema for fetching weather
class GetWeather(BaseModel):
"""Get the current weather in a given location."""
location: str = Field(..., description="The city and state, e.g. Edinburgh, UK")
def fetch_weather(self):
# Using OpenWeatherMap API to fetch real-time weather
API_KEY = "YOUR_API_KEY_HERE" # Replace with your actual API key
base_url = f"http://api.openweathermap.org/data/2.5/weather?q={self.location}&appid={API_KEY}&units=metric"
response = requests.get(base_url)
if response.status_code == 200:
data = response.json()
weather_description = data['weather'][0]['description']
temperature = data['main']['temp']
return f"The weather in {self.location} is {weather_description} with a temperature of {temperature}°C."
else:
return f"Could not fetch the weather for {self.location}."
# Instantiate the LLM model
llm = ChatOpenAI(
model="gpt-4o-audio-preview"
)
# Function to handle audio transcription using the LLM
def audio_to_text(audio_b64: str) -> str:
# Define the message to send for transcription
messages = [
(
"human",
[
{"type": "text", "text": "Transcribe the following:"},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Invoke the model and get the transcription
output_message = llm.invoke(messages)
# Return the transcription from the model's output
return output_message.content
# Create a prompt template for transcription and weather lookup
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are an assistant that transcribes audio and fetches weather information."),
("human", "Transcribe the following and tell me the weather in the location mentioned in the audio."),
]
)
# Bind the tool to the model
llm_with_tools = llm.bind_tools([GetWeather])
# Chain the transcription and weather tool
chain = prompt | llm_with_tools
# Read and encode the audio file in base64
audio_file = "weather_input.wav" #Replace with your audio file
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Transcribe the audio to get the location
transcribed_location = audio_to_text(audio_b64)
# Print the transcription result for debugging
print(f"Transcribed location: {transcribed_location}")
# Check if transcription returned a valid result
if transcribed_location:
# Fetch weather for the transcribed location
weather_tool = GetWeather(location=transcribed_location)
weather_result = weather_tool.fetch_weather()
print(f"Weather result: {weather_result}")
else:
print("No valid location was transcribed from the audio.")Let’s break down the code:
For this example, I gave the model an audio file in which I said: “Edinburgh”. This is the output I got:Transcribed location: Edinburgh
Weather result: The weather in Edinburgh is broken clouds with a temperature of 13.47°C.

In some cases, you might want to fine-tune the model to handle specific tasks more effectively. For example, if you’re building an application that transcribes medical audio, you might want the model to have a deep understanding of medical terms and jargon. OpenAI allows you to fine-tune the model by training it on custom datasets.
Let’s see how to do this:
import base64
from langchain_openai import ChatOpenAI
# Step 1: Instantiate the fine-tuned audio-capable model
fine_tuned_model = ChatOpenAI(
temperature=0,
model="ft:gpt-4o-audio-preview:your-organization::model-id"
)
# Step 2: Capture and encode the input audio file (medical report)
audio_file = "medical_report.wav"
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Step 3: Create the message structure for transcription request
messages = [
(
"human",
[
{"type": "text", "text": "Please transcribe this medical report audio."},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Step 4: Invoke the fine-tuned model to transcribe the audio
result = fine_tuned_model.invoke(messages)
# Step 5: Extract and print the transcribed text from the response
transcription = result.content # This contains the transcription
print(f"Transcription: {transcription}")
# Debugging: Print the full structure of the additional_kwargs for inspection
print(result.additional_kwargs)This uses a fine-tuned model specifically trained to handle medical audio, but you can fine-tune models for other use cases as well, such as legal transcriptions, customer service recordings, or podcast editing.
Finally, let’s look into a practical example where we build a voice-enabled assistant that listens to user queries through audio, generates a response, and replies back using audio.
This is the workflow we’re going to follow:
Let’s see how to code this:
import base64
from langchain_openai import ChatOpenAI
# Step 1: Instantiate the audio-capable model with configuration for generating audio
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
temperature=0,
model_kwargs={
"modalities": ["text", "audio"], # Enable both text and audio modalities
"audio": {"voice": "alloy", "format": "wav"}, # Set the desired voice and output format
}
)
# Step 2: Capture and encode the audio
audio_file = "math_joke_audio.wav" #You can replace your audio file here
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Step 3: Create the message structure for transcription and audio response
messages = [
(
"human",
[
{"type": "text", "text": "Answer the question."},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Step 4: Invoke the model to transcribe the audio and generate a response
result = llm.invoke(messages)
# Step 5: Extract the audio response
audio_response = result.additional_kwargs.get('audio', {}).get('data') # Safely check if audio exists
# Step 6: Save the audio response to a file if it exists
if audio_response:
# Decode the base64 audio data and save it as a .wav file
audio_bytes = base64.b64decode(audio_response)
with open("response.wav", "wb") as f:
f.write(audio_bytes)
print("Audio response saved as 'response.wav'")
else:
print("No audio response available")Let’s break down how this works:
This assistant is made for talking with audio. It listens to the user's voice, understands the question, and then answers using its own voice. This setup is great for building simple voice assistants, and you can make it more advanced later if needed!

In this tutorial, we explored OpenAI's gpt-4o-audio-preview model, covering setup, audio input/output, advanced use cases, and even building a basic voice assistant. This powerful model provides a robust foundation for creating real-world audio-enabled applications.
If you want to improve your LangChain practical knowledge, I recommend these blogs:
Learn AI with these courses!
Course
Course
Course
blog
Richie Cotton
8 min
Tutorial
Andrea Valenzuela
code-along
Emmanuel Pire
code-along
Richie Cotton
code-along
Andrea Valenzuela
code-along
Adel Nehme





