Kurs
Entwickeln von LLM-Anwendungen mit LangChain
3 Std.
46.2K
Stell dir vor, du baust eine sprachgesteuerte App, z.B. einen Kundenservice-Bot oder einen Podcast-Transcriber. Normalerweise brauchst du mehrere Tools für Aufgaben wie Transkription und Audiogenerierung. OpenAI's gpt-4o-audio-preview Modell vereinfacht dies, indem es sowohl Text als auch Audio versteht und erzeugt.
In diesem Tutorial werden wir dieses leistungsstarke Modell erkunden und lernen, wie man es mit LangChain für eine nahtlose Audioverarbeitung nutzen können. Ich erkläre dir, wie du dieses Modell einrichtest, mit Audio-Eingaben arbeitest, Antworten in Text- und Audioform generierst und sogar alles miteinander verbindest, um reale Anwendungen zu erstellen.
Bevor du das gpt-4o-audio-preview-Modell von OpenAI verwendest, solltest du eine virtuelle Umgebung für dein Projekt einrichten. Das sorgt für Ordnung und verhindert Abhängigkeitskonflikte, was besonders nützlich ist, wenn du mit mehreren Projekten arbeitest.
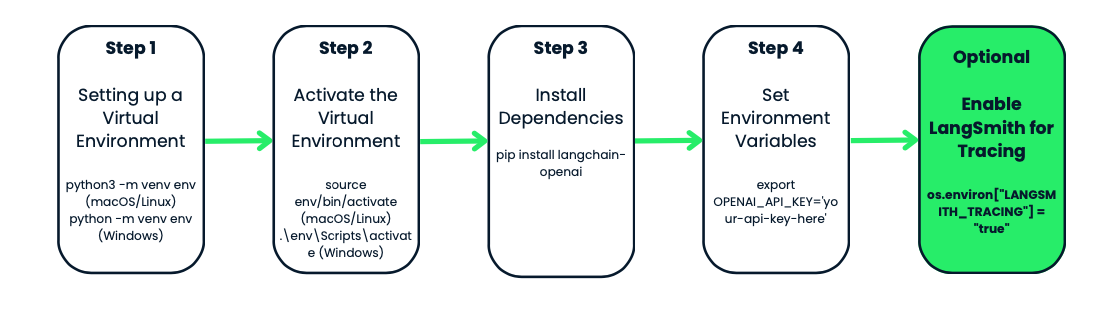
Stell dir vor, du hast zwei verschiedene Projekte. Einer von ihnen benötigt die Version 1.0 eines Pakets, der andere die Version 2.0. Wenn du alles global installierst, wirst du auf Konflikte stoßen.
Virtuelle Umgebungen schaffen einen isolierten Arbeitsbereich, eine Art Blase, in der du alles installieren kannst, was du für ein bestimmtes Projekt brauchst. Wenn du eine Umgebung für dein Projekt erstellst, musst du dir keine Sorgen mehr machen, dass die Python-Einrichtung deines Systems beschädigt wird oder Pakete in Konflikt geraten.
Beginnen wir damit, eine virtuelle Umgebung für unser Projekt zu erstellen. Wir werden das in Python integrierte venv-Modul. Wir werden es tun:
python3 -m venv env aus. Unter Windows sieht es so aus: python -m venv env.venv das Python-Tool zum Erstellen von virtuellen Umgebungen ist und env der Name des Umgebungsordners. Du kannst sie benennen, wie du willst: env, venv, my_project_env, etc. Es ist eine gute Praxis, es kurz und einfach zu haltensource env/bin/activate. Unter Windows verwendest du: .\env\Scripts\activateDu wirst feststellen, dass sich die Eingabeaufforderung deines Terminals in envändert - ein Zeichen dafür, dass du innerhalb deiner virtuellen Umgebung arbeitest. Von nun an werden alle Pakete, die du installierst oder Befehle, die du ausführst, auf dieses Projekt beschränkt.
Wenn deine Umgebung aktiviert ist, ist es an der Zeit, die Werkzeuge zu installieren, die du brauchst. Da wir mit OpenAI und LangChain arbeiten, installieren wir zunächst das Paket langchain-openai. Dieses Paket ermöglicht es uns, mit den Modellen von OpenAI zu interagieren.
Führe dies in deinem Terminal aus: pip install langchain-openai.
Im nächsten Schritt musst du sicherstellen, dass deine sensiblen Daten, wie z.B. API-Schlüssel, nicht in deinen Skripten fest codiert werden. Wir tun dies, indem wir Umgebungsvariablen setzen.
Das Wichtigste zuerst: Du brauchst Zugang zu den Modellen von OpenAI. Wenn du es noch nicht getan hast, gehe zur OpenAI-Plattform und erstelle ein Konto. Sobald du dich angemeldet hast, musst du einen API-Schlüssel generieren. Dieser API-Schlüssel ist dein Passierschein für den Zugriff auf die OpenAI-Modelle, einschließlich der gpt-4o-audio-preview.
In unserem Fall müssen wir die OPENAI_API_KEY einstellen. Du kannst diese Einstellung jedes Mal, wenn du an deinem Projekt arbeitest, manuell vornehmen oder eine .env-Datei verwenden, um sie für einen einfachen Zugriff zu speichern. Schauen wir uns beide Methoden an.
Wenn du nur vorübergehend arbeitest und eine schnelle Einrichtung brauchst, kannst du die Umgebungsvariable direkt in deinem Terminal setzen.
export OPENAI_API_KEY='your-api-key-here'set OPENAI_API_KEY='your-api-key-here'Jetzt ist dein API-Schlüssel in deinem Skript verfügbar und du kannst ihn mit dem os-Modul in Python abrufen.
Wenn du eine dauerhafte Lösung bevorzugst, kannst du eine .env-Datei verwenden, um deine Umgebungsvariablen zu speichern. Diese Datei wird in deinem Projektordner liegen und deine Schlüssel sicher aufbewahren.
Als erstes erstellst du eine .env-Datei in deinem Projektverzeichnis und fügst darin deinen API-Schlüssel wie folgt ein:
OPENAI_API_KEY=your-api-key-hereAls nächstes installierst du das Paket python-dotenv:
pip install python-dotenvNun lädst du in deinem Python-Skript die Umgebungsvariablen aus der .env-Datei wie folgt:
from dotenv import load_dotenv
import os
load_dotenv() # Load variables from .env file
api_key = os.getenv('OPENAI_API_KEY')Diese Methode ist besonders nützlich, wenn du mehrere Umgebungsvariablen zu verwalten hast, und sie hält deinen Code sauber und sicher.
Wenn du deine API-Aufrufe zu Debugging- oder Leistungszwecken verfolgen und überwachen möchtest, bietet OpenAI eine coole Funktion namens LangSmith. Du erhältst detaillierte Protokolle zu jedem API-Aufruf deines Modells, was sehr hilfreich sein kann, wenn du versuchst, deinen Workflow zu optimieren oder Fehler zu beheben.
Du kannst das LangSmith-Tracing wie folgt aktivieren:
os.environ["LANGSMITH_API_KEY"] = getpass.getpass("Enter your LangSmith API key: ")
os.environ["LANGSMITH_TRACING"] = "true"Auch dies ist völlig optional, aber es ist ein praktisches Werkzeug, wenn du an einer komplexen Anwendung arbeitest und überwachen willst, wie sich deine Modelle verhalten.
Jetzt, wo wir unsere Umgebung eingerichtet haben, ist es an der Zeit, dass wir das gpt-4o-audio-preview-Modell von OpenAI ausprobieren. Hier beginnen wir, mit dem Modell zu interagieren, Anfragen zu stellen und Eingaben und Ausgaben zu verarbeiten.
In diesem Abschnitt gehen wir durch, wie du das Modell mit dem LangChain-Framework instanziierst, einige grundlegende Parameter anpasst und alles einrichtest, was du brauchst, um mit der Generierung von Antworten zu beginnen.
Bevor wir uns mit dem Code befassen, sollten wir uns einen Moment Zeit nehmen, um zu verstehen, was es bedeutet, das Modell zu "instanziieren". Wenn wir sagen, dass wir das Modell instanziieren, erstellen wir im Wesentlichen ein Objekt in Python, das es uns ermöglicht, mit dem gpt-4o-audio-preview-Modell zu interagieren. Dieses Objekt ist so etwas wie das Bedienfeld - es enthält alle Einstellungen, Konfigurationen und Methoden, die wir brauchen, um Daten an das Modell zu senden und Ergebnisse zurückzubekommen.
Beginnen wir damit, dieses Modellobjekt zu erstellen. Da wir mit dem LangChain-Framework arbeiten, verwenden wir die Klasse ChatOpenAI aus dem Paket langchain_openai. Diese Klasse ermöglicht uns einen einfachen Zugang zu den OpenAI-Modellen und ihren Funktionen.
from langchain_openai import ChatOpenAI
# Create the model object
llm = ChatOpenAI(
model="gpt-4o-audio-preview", # Specifying the model
temperature=0, # Controls randomness in the output
max_tokens=None, # Unlimited tokens in output (or specify a max if needed)
timeout=None, # Optional: Set a timeout for requests
max_retries=2 # Number of retries for failed requests
)Das Tolle an diesem Modell ist, dass es individuell anpassbar ist. Du kannst die Parameter je nach deinen Bedürfnissen anpassen. Wenn du zum Beispiel eine Anwendung entwickelst, die eine Audiotranskription erfordert, kannst du die Parameter so anpassen, dass sie größere Eingaben verarbeiten oder die Länge der Ausgabe begrenzen.
Wenn du zum Beispiel mit zeitkritischen Anfragen zu tun hast und sicherstellen willst, dass das Modell nicht zu lange braucht, kannst du auch einen Timeout festlegen:
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
timeout=30 # Set timeout to 30 seconds
)Jetzt, wo wir das gpt-4o-audio-preview-Modell zum Laufen gebracht haben, wollen wir uns mit der Fähigkeit beschäftigen, Audioeingänge und -ausgänge zu verarbeiten.
Bevor du mit Audio arbeiten kannst, musst du zunächst deine Audiodatei in ein Format laden und kodieren, das das Modell versteht. OpenAI erwartet, dass Audiodaten in einem base64-kodierten Format gesendet werden, also laden wir zunächst eine Datei hoch und kodieren sie.
Angenommen, du hast eine . wav-Datei, die das Modell verarbeiten soll - ich habe sie gpt.wav genannt . Du kannst sie mit dem folgenden Code durch deine Datei ersetzen. Hier erfährst du, wie du diese Datei laden und vorbereiten kannst:
import base64
# Open the audio file and convert to base64
with open("gpt.wav", "rb") as f:
audio_data = f.read()
# Convert binary audio data to base64
audio_b64 = base64.b64encode(audio_data).decode()Was ist hier los? Wir lesen die Audiodatei als Binärdaten ("rb"-Modus) und verwenden dann die base64-Bibliothek, um sie in einen base64-String zu kodieren. Dies ist das Format, das OpenAI für die Verarbeitung von Audioeingaben benötigt.
Sobald deine Audiodaten kodiert sind, ist es an der Zeit, sie an das Modell zu übergeben. Das Modell gpt-4o-audio-preview kann Sprache aus Audiodateien transkribieren. Wenn du also schon immer einen Podcast, ein Sprachmemo oder eine Meeting-Aufnahme in Text umwandeln wolltest, ist dies genau das, worauf du gewartet hast! Schauen wir mal, wie das funktioniert.
# Define the input message with audio
messages = [
(
"human",
[
{"type": "text", "text": "Transcribe the following:"},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Send the request to the model and get the transcription
output_message = llm.invoke(messages)
print(output_message.content)In diesem Beispiel senden wir zwei Daten an das Modell:
Das Modell verarbeitet diese Eingabe und liefert eine Transkription des Tons. Wenn deine Audiodatei z. B. den gesprochenen Satz "Ich lerne, wie man KI benutzt" enthält, würde das Modell eine Textausgabe wie diese zurückgeben: "Ich lerne, wie man KI benutzt."
Aber das gpt-4o-Audio-Preview-Modell kann nicht nur Audio verstehen, sondern auch erzeugen. Hier erfährst du, wie du das Modell so konfigurieren kannst, dass es Audioausgaben erzeugt:
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
temperature=0,
model_kwargs={
"modalities": ["text", "audio"], # We’re telling the model to handle both text and audio
"audio": {"voice": "alloy", "format": "wav"}, # Configure voice and output format
}
)
# Send a request and ask the model to respond with audio
messages = [("human", "Are you human? Reply either yes or no.")]
output_message = llm.invoke(messages)
# Access the generated audio data
audio_response = output_message.additional_kwargs['audio']['data']Lass uns das mal auspacken:
Die base64-kodierte Audioantwort wird in output_message.additional_kwargs['audio']['data'] gespeichert, und du kannst diese Datei ganz einfach dekodieren und für die Wiedergabe speichern.
Jetzt, wo du Audio generierst, willst du die Datei wahrscheinlich speichern und abspielen, oder? Hier erfährst du, wie du die base64-kodierten Audiodaten dekodieren und als .wav-Datei speichern kannst:
# Decode the base64 audio data
audio_bytes = base64.b64decode(output_message.additional_kwargs['audio']['data'])
# Save the audio file
with open("output.wav", "wb") as f:
f.write(audio_bytes)
print("Audio saved as output.wav")Du kannst diese .wav Datei jetzt auf deinem lokalen Rechner mit einem beliebigen Media Player abspielen . Wenn du das Modell jetzt aufrufst, erzeugt es nicht nur eine Textantwort, sondern auch eine Audiodatei, die die Antwort wiedergibt.
In diesem Abschnitt erfährst du, wie du Werkzeuge an das gpt-4o-audio-preview-Modell anbindest, komplexere Workflows abwickelst und sogar mehrere Schritte miteinander verketten kannst, um vollautomatische Lösungen zu erstellen. Wenn du schon immer einen Sprachassistenten bauen wolltest, der nicht nur Audiosignale transkribiert, sondern auch Informationen aus externen Quellen abruft, wird dieser Abschnitt hilfreich sein.
Beginnen wir mit dem Aufruf der Werkzeuge. Das bedeutet, dass du deinem KI-Modell beibringst, wie es externe Tools oder Funktionen nutzen kann, um seine Fähigkeiten zu verbessern. Anstatt nur Text oder Audio zu verarbeiten, kann das Modell zusätzliche Aufgaben übernehmen, wie z. B. Daten von APIs abrufen, Berechnungen durchführen oder sogar Wetterinformationen abrufen.
Das gpt-4o-audio-preview-Modell von OpenAI kann mit Hilfe der bind_tools -Methode von LangChain mit anderen Tools und Funktionen kombiniert werden. Mit dieser Methode kannst du einen reibungslosen Arbeitsablauf schaffen, bei dem das Modell selbst entscheidet, wann und wie es die von dir zur Verfügung gestellten Werkzeuge nutzt.
Ich führe dich durch ein praktisches Beispiel, wie du ein Werkzeug an das Modell bindest. In diesem Fall werden wir ein Tool binden, das das Wetter abruft.
Zuerst definieren wir ein pydantisches Modell, das das Werkzeug darstellt, das wir verwenden wollen. Dann binden wir dieses Werkzeug an das gpt-4o-audio-preview-Modell, damit es bei Bedarf aufgerufen werden kann. Hierfür benötigst du einen API-Schlüssel von OpenWeatherMap.
import requests
from pydantic import BaseModel, Field
# Define a tool schema using Pydantic
class GetWeather(BaseModel):
"""Get the current weather in a given location."""
location: str = Field(..., description="The city and state, e.g. Edinburgh, UK")
def fetch_weather(self):
# Using OpenWeatherMap API to fetch real-time weather
API_KEY = "YOUR_API_KEY_HERE" # Replace with your actual API key
base_url = f"http://api.openweathermap.org/data/2.5/weather?q={self.location}&APPID={API_KEY}&units=metric"
response = requests.get(base_url)
if response.status_code == 200:
data = response.json()
weather_description = data['weather'][0]['description']
temperature = data['main']['temp']
return f"The weather in {self.location} is {weather_description} with a temperature of {temperature}°C."
else:
# Print the status code and response for debugging
print(f"Error: {response.status_code}, {response.text}")
return f"Could not fetch the weather for {self.location}."
# Example usage
weather_tool = GetWeather(location="Edinburgh, GB") # Using city name and country code
ai_msg = weather_tool.fetch_weather()
print(ai_msg)Schauen wir mal, was es damit auf sich hat:
In diesem Beispiel möchte ich wissen, wie das Wetter in Edinburgh ist. Als ich es ausführte, erhielt ich diese Ausgabe: Das Wetter in Edinburgh, GB ist wolkenverhangen mit einer Temperatur von 13,48°C.
Durch die Verkettung von Aufgaben kannst du mehrstufige Workflows erstellen, die mehrere Tools und Modellaufrufe kombinieren, um komplexe Anfragen zu bearbeiten. Stell dir ein Szenario vor, in dem du möchtest, dass dein Assistent Audiodaten transkribiert und dann eine Aktion für den in den Audiodaten genannten Ort ausführt. In diesem Beispiel verknüpfen wir eine Audiotranskription mit einer Wetterabfrage, die auf dem transkribierten Ort basiert.
import base64
import requests
from pydantic import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# Define the tool schema for fetching weather
class GetWeather(BaseModel):
"""Get the current weather in a given location."""
location: str = Field(..., description="The city and state, e.g. Edinburgh, UK")
def fetch_weather(self):
# Using OpenWeatherMap API to fetch real-time weather
API_KEY = "YOUR_API_KEY_HERE" # Replace with your actual API key
base_url = f"http://api.openweathermap.org/data/2.5/weather?q={self.location}&appid={API_KEY}&units=metric"
response = requests.get(base_url)
if response.status_code == 200:
data = response.json()
weather_description = data['weather'][0]['description']
temperature = data['main']['temp']
return f"The weather in {self.location} is {weather_description} with a temperature of {temperature}°C."
else:
return f"Could not fetch the weather for {self.location}."
# Instantiate the LLM model
llm = ChatOpenAI(
model="gpt-4o-audio-preview"
)
# Function to handle audio transcription using the LLM
def audio_to_text(audio_b64: str) -> str:
# Define the message to send for transcription
messages = [
(
"human",
[
{"type": "text", "text": "Transcribe the following:"},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Invoke the model and get the transcription
output_message = llm.invoke(messages)
# Return the transcription from the model's output
return output_message.content
# Create a prompt template for transcription and weather lookup
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are an assistant that transcribes audio and fetches weather information."),
("human", "Transcribe the following and tell me the weather in the location mentioned in the audio."),
]
)
# Bind the tool to the model
llm_with_tools = llm.bind_tools([GetWeather])
# Chain the transcription and weather tool
chain = prompt | llm_with_tools
# Read and encode the audio file in base64
audio_file = "weather_input.wav" #Replace with your audio file
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Transcribe the audio to get the location
transcribed_location = audio_to_text(audio_b64)
# Print the transcription result for debugging
print(f"Transcribed location: {transcribed_location}")
# Check if transcription returned a valid result
if transcribed_location:
# Fetch weather for the transcribed location
weather_tool = GetWeather(location=transcribed_location)
weather_result = weather_tool.fetch_weather()
print(f"Weather result: {weather_result}")
else:
print("No valid location was transcribed from the audio.")Lass uns den Code aufschlüsseln:
Für dieses Beispiel habe ich dem Modell eine Audiodatei gegeben, in der ich gesagt habe: "Edinburgh". Das ist die Ausgabe, die ich erhalten habe:Transcribed location: Edinburgh
Wetterergebnis: Das Wetter in Edinburgh ist wolkenverhangen mit einer Temperatur von 13,47°C.

In manchen Fällen möchtest du das Modell feiner abstimmen, um bestimmte Aufgaben effektiver zu erledigen. Wenn du z.B. eine Anwendung entwickelst, die medizinische Audiodateien transkribiert, möchtest du vielleicht, dass das Modell die medizinischen Begriffe und den Fachjargon versteht. Mit OpenAI kannst du das Modell feinabstimmen, indem du es mit eigenen Datensätzen trainierst.
Schauen wir uns an, wie das geht:
import base64
from langchain_openai import ChatOpenAI
# Step 1: Instantiate the fine-tuned audio-capable model
fine_tuned_model = ChatOpenAI(
temperature=0,
model="ft:gpt-4o-audio-preview:your-organization::model-id"
)
# Step 2: Capture and encode the input audio file (medical report)
audio_file = "medical_report.wav"
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Step 3: Create the message structure for transcription request
messages = [
(
"human",
[
{"type": "text", "text": "Please transcribe this medical report audio."},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Step 4: Invoke the fine-tuned model to transcribe the audio
result = fine_tuned_model.invoke(messages)
# Step 5: Extract and print the transcribed text from the response
transcription = result.content # This contains the transcription
print(f"Transcription: {transcription}")
# Debugging: Print the full structure of the additional_kwargs for inspection
print(result.additional_kwargs)Du kannst die Modelle aber auch für andere Anwendungsfälle anpassen, z. B. für juristische Transkriptionen, Kundendienstaufnahmen oder die Bearbeitung von Podcasts.
Zum Schluss wollen wir uns ein praktisches Beispiel ansehen, in dem wir einen sprachgesteuerten Assistenten bauen, der auf Benutzeranfragen per Audio hört, eine Antwort erzeugt und per Audio antwortet.
Dies ist der Arbeitsablauf, dem wir folgen werden:
Schauen wir uns an, wie man das codiert:
import base64
from langchain_openai import ChatOpenAI
# Step 1: Instantiate the audio-capable model with configuration for generating audio
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
temperature=0,
model_kwargs={
"modalities": ["text", "audio"], # Enable both text and audio modalities
"audio": {"voice": "alloy", "format": "wav"}, # Set the desired voice and output format
}
)
# Step 2: Capture and encode the audio
audio_file = "math_joke_audio.wav" #You can replace your audio file here
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Step 3: Create the message structure for transcription and audio response
messages = [
(
"human",
[
{"type": "text", "text": "Answer the question."},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Step 4: Invoke the model to transcribe the audio and generate a response
result = llm.invoke(messages)
# Step 5: Extract the audio response
audio_response = result.additional_kwargs.get('audio', {}).get('data') # Safely check if audio exists
# Step 6: Save the audio response to a file if it exists
if audio_response:
# Decode the base64 audio data and save it as a .wav file
audio_bytes = base64.b64decode(audio_response)
with open("response.wav", "wb") as f:
f.write(audio_bytes)
print("Audio response saved as 'response.wav'")
else:
print("No audio response available")Schauen wir uns an, wie das funktioniert:
Dieser Assistent ist für Gespräche mit Audio gemacht. Es hört auf die Stimme des Nutzers, versteht die Frage und antwortet dann mit seiner eigenen Stimme. Dieses Setup eignet sich hervorragend, um einfache Sprachassistenten zu erstellen, und du kannst es später bei Bedarf noch weiter ausbauen!

In diesem Tutorial haben wir das gpt-4o-audio-preview-Modell von OpenAI erkundet und dabei die Einrichtung, die Audioeingabe und -ausgabe, fortgeschrittene Anwendungsfälle und sogar den Bau eines einfachen Sprachassistenten behandelt. Dieses leistungsstarke Modell bietet eine solide Grundlage für die Entwicklung realer audiofähiger Anwendungen.
Wenn du dein praktisches Wissen über LangChain verbessern willst, empfehle ich dir diese Blogs:
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
