Curso
Desenvolvimento de aplicativos de LLM com LangChain
3 h
46.2K
Imagine criar um aplicativo habilitado para voz, como um bot de atendimento ao cliente ou um transcritor de podcast. Normalmente, você precisaria de várias ferramentas para tarefas como transcrição e geração de áudio. OpenAI's gpt-4o-audio-preview da OpenAI simplifica isso ao compreender e gerar texto e áudio.
Neste tutorial, exploraremos esse modelo avançado e como usá-lo com o LangChain para um processamento de áudio perfeito. Explicarei como você pode configurar esse modelo, trabalhar com entradas de áudio, gerar respostas em texto e áudio e até mesmo unir tudo isso para criar aplicativos do mundo real.
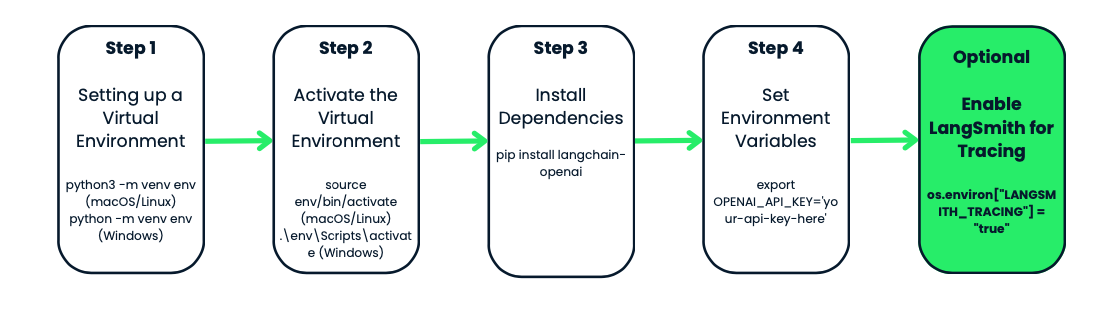
Antes de usar o modelo gpt-4o-audio-preview da OpenAI, vamos configurar um ambiente virtual para o seu projeto. Isso mantém as coisas organizadas e evita conflitos de dependência, o que é especialmente útil quando você trabalha com vários projetos.
Imagine que você tenha dois projetos diferentes. Um deles requer a versão 1.0 de um pacote, enquanto o outro requer a versão 2.0. Se você instalar tudo globalmente, terá conflitos.
Os ambientes virtuais criam um espaço de trabalho isolado, como uma bolha, onde você pode instalar tudo o que precisa para um projeto específico. Quando você cria um ambiente para o seu projeto, não precisa mais se preocupar com a quebra da configuração do Python no seu sistema ou com pacotes conflitantes.
Vamos começar criando um ambiente virtual para o nosso projeto. Usaremos o módulo venv integrado do Python. Vamos precisar:
python3 -m venv env. No Windows, você verá o seguinte python -m venv env.venv é a ferramenta do Python para criar ambientes virtuais, e env é o nome da pasta do ambiente. Você pode dar a ele o nome que quiser: env, venv, my_project_env, etc. É uma boa prática mantê-lo curto e simplessource env/bin/activate. No Windows, use: .\env\Scripts\activateVocê perceberá que o prompt do terminal muda para algo como env- isso é um sinal de que você está trabalhando dentro do ambiente virtual. De agora em diante, todos os pacotes que você instalar ou comandos que executar serão isolados para este projeto.
Com seu ambiente ativado, é hora de instalar as ferramentas de que você precisa. Como estamos trabalhando com o OpenAI e o LangChain, vamos começar instalando o pacote langchain-openai. Esse pacote permitirá que você interaja com os modelos da OpenAI.
Execute isso em seu terminal: pip install langchain-openai.
A próxima etapa é garantir que suas informações confidenciais, como chaves de API, não sejam codificadas em seus scripts. Faremos isso definindo variáveis de ambiente.
Antes de mais nada, você precisará acessar os modelos da OpenAI. Se você ainda não o fez, acesse a plataforma OpenAI e crie uma conta. Depois de se inscrever, você precisará gerar uma chave de API. Essa chave de API é o passe para você acessar os modelos da OpenAI, incluindo o gpt-4o-audio-preview.
No nosso caso, precisaremos definir o endereço OPENAI_API_KEY. Você pode definir isso manualmente sempre que trabalhar no projeto ou usar um arquivo .env para armazená-lo e facilitar o acesso. Vamos dar uma olhada nos dois métodos.
Se você estiver trabalhando apenas temporariamente e quiser uma configuração rápida, poderá definir a variável de ambiente diretamente no terminal.
export OPENAI_API_KEY='your-api-key-here'set OPENAI_API_KEY='your-api-key-here'Agora sua chave de API está disponível no script e você pode acessá-la usando o módulo os no Python.
Se preferir uma solução mais permanente, você pode usar um arquivo .env para armazenar suas variáveis de ambiente. Esse arquivo ficará na pasta do seu projeto e manterá suas chaves seguras.
Primeiro, crie um arquivo .env no diretório do seu projeto e, dentro dele, adicione sua chave de API da seguinte forma:
OPENAI_API_KEY=your-api-key-hereEm seguida, instale o pacote python-dotenv:
pip install python-dotenvAgora, em seu script Python, carregue as variáveis de ambiente do arquivo .env da seguinte forma:
from dotenv import load_dotenv
import os
load_dotenv() # Load variables from .env file
api_key = os.getenv('OPENAI_API_KEY')Esse método é particularmente útil se você tiver várias variáveis de ambiente para gerenciar e mantém seu código limpo e seguro.
Se você quiser rastrear e monitorar suas chamadas de API para fins de depuração ou desempenho, a OpenAI tem um recurso interessante chamado LangSmith. Ele fornece logs detalhados de cada chamada de API feita pelo seu modelo, o que pode ser muito útil se você estiver tentando otimizar ou solucionar problemas do seu fluxo de trabalho.
Você pode ativar o rastreamento do LangSmith desta forma:
os.environ["LANGSMITH_API_KEY"] = getpass.getpass("Enter your LangSmith API key: ")
os.environ["LANGSMITH_TRACING"] = "true"Novamente, isso é totalmente opcional, mas é uma ferramenta útil se você estiver trabalhando em um aplicativo complexo e quiser monitorar como os modelos se comportam.
Agora que temos nosso ambiente configurado e pronto para funcionar, é hora de passar para a parte divertida: demonstrar o modelo gpt-4o-audio-preview da OpenAI. É aqui que começamos a interagir com o modelo, fazendo solicitações e processando entradas e saídas.
Nesta seção, veremos como instanciar o modelo usando a estrutura LangChain, personalizar alguns parâmetros básicos e configurar tudo o que você precisa para começar a gerar respostas.
Antes de entrarmos no código, vamos parar um pouco para entender o que significa "instanciar" o modelo. Quando dizemos que estamos instanciando o modelo, estamos essencialmente criando um objeto em Python que nos permitirá interagir com o modelo gpt-4o-audio-preview. Esse objeto é como o painel de controle - ele contém todas as definições, configurações e métodos necessários para enviar dados ao modelo e obter resultados.
Vamos começar criando esse objeto de modelo. Como estamos trabalhando com a estrutura LangChain, usaremos a classe ChatOpenAI do pacote langchain_openai. Essa classe nos dá acesso fácil aos modelos da OpenAI e suas funcionalidades.
from langchain_openai import ChatOpenAI
# Create the model object
llm = ChatOpenAI(
model="gpt-4o-audio-preview", # Specifying the model
temperature=0, # Controls randomness in the output
max_tokens=None, # Unlimited tokens in output (or specify a max if needed)
timeout=None, # Optional: Set a timeout for requests
max_retries=2 # Number of retries for failed requests
)Uma das melhores coisas sobre esse modelo é o fato de ele ser personalizável. Você pode ajustar os parâmetros de acordo com o que precisa. Por exemplo, se você estiver criando um aplicativo que exija transcrição de áudio, poderá ajustar os parâmetros para lidar com entradas maiores ou limitar o comprimento da saída.
Por exemplo, se estiver lidando com solicitações sensíveis ao tempo e quiser garantir que o modelo não demore muito, você também poderá definir um tempo limite:
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
timeout=30 # Set timeout to 30 seconds
)Agora que já temos o modelo gpt-4o-audio-preview em funcionamento, vamos analisar a capacidade de lidar com entradas e saídas de áudio.
Antes que você possa começar a trabalhar com áudio, a primeira etapa é carregar e codificar o arquivo de áudio em um formato que o modelo possa entender. O OpenAI espera que os dados de áudio sejam enviados em um formato codificado em base64, portanto, começaremos fazendo o upload de um arquivo e codificando-o. Você pode usar o OpenAI para enviar dados de áudio em um formato codificado em base64.
Digamos que você tenha um arquivo .wav que deseja que o modelo processe - eu o chamei de gpt.wav. Você pode substituí-lo pelo seu arquivo usando o código a seguir. Veja como você pode carregar e preparar esse arquivo:
import base64
# Open the audio file and convert to base64
with open("gpt.wav", "rb") as f:
audio_data = f.read()
# Convert binary audio data to base64
audio_b64 = base64.b64encode(audio_data).decode()O que está acontecendo aqui? Estamos lendo o arquivo de áudio como dados binários (modo "rb") e, em seguida, usando a biblioteca base64 para codificá-lo em uma string base64. Esse é o formato que o OpenAI exige para processar entradas de áudio.
Depois que o áudio estiver codificado, é hora de passá-lo para o modelo. O modelo gpt-4o-audio-preview pode transcrever a fala de arquivos de áudio. Portanto, se você já precisou transformar um podcast, um memorando de voz ou uma gravação de reunião em texto, isso é exatamente o que você estava esperando! Vamos ver como isso funciona.
# Define the input message with audio
messages = [
(
"human",
[
{"type": "text", "text": "Transcribe the following:"},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Send the request to the model and get the transcription
output_message = llm.invoke(messages)
print(output_message.content)Neste exemplo, estamos enviando dois dados para o modelo:
O modelo processa essa entrada e retorna uma transcrição do áudio. Portanto, se o seu arquivo de áudio contivesse algo como uma frase falada, "Estou aprendendo a usar IA", o modelo retornaria uma saída de texto como: "Estou aprendendo a usar a IA."
Mas o modelo gpt-4o-audio-preview não se limita a entender o áudio, ele também pode gerá-lo. Veja como você pode configurar o modelo para gerar saídas de áudio:
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
temperature=0,
model_kwargs={
"modalities": ["text", "audio"], # We’re telling the model to handle both text and audio
"audio": {"voice": "alloy", "format": "wav"}, # Configure voice and output format
}
)
# Send a request and ask the model to respond with audio
messages = [("human", "Are you human? Reply either yes or no.")]
output_message = llm.invoke(messages)
# Access the generated audio data
audio_response = output_message.additional_kwargs['audio']['data']Vamos analisar isso:
A resposta de áudio codificada em base64 é armazenada em output_message.additional_kwargs['audio']['data'], e você pode facilmente decodificar e salvar esse arquivo para reprodução.
Agora que você está gerando áudio, provavelmente quer salvar o arquivo e reproduzi-lo, certo? Veja como você pode pegar esses dados de áudio codificados em base64, decodificá-los e salvá-los como um arquivo .wav:
# Decode the base64 audio data
audio_bytes = base64.b64decode(output_message.additional_kwargs['audio']['data'])
# Save the audio file
with open("output.wav", "wb") as f:
f.write(audio_bytes)
print("Audio saved as output.wav")Agora você pode reproduzir esse arquivo.wav em seu computador local usando qualquer reprodutor de mídia. Portanto, agora, quando você invoca o modelo, ele gera não apenas uma resposta de texto, mas também um arquivo de áudio que diz a resposta.
Nesta seção, abordarei como vincular ferramentas ao modelo gpt-4o-audio-preview, lidar com fluxos de trabalho mais complexos e até mesmo encadear várias etapas para criar soluções totalmente automatizadas. Se você já quis criar um assistente de voz que não apenas transcreva áudio, mas também busque informações de fontes externas, esta seção será útil.
Vamos começar com a chamada de ferramentas. Isso significa ensinar ao seu modelo de IA como usar ferramentas ou funções externas para aprimorar seus recursos. Em vez de apenas processar texto ou áudio, o modelo pode executar tarefas adicionais, como buscar dados de APIs, fazer cálculos ou até mesmo procurar informações meteorológicas.
O modelo gpt-4o-audio-preview da OpenAI pode ser combinado com outras ferramentas e funções usando o método bind_tools da LangChain. Com esse método, você pode criar um fluxo de trabalho tranquilo em que o modelo decide quando e como usar as ferramentas que você forneceu.
Vou orientar você em um exemplo prático de vinculação de uma ferramenta ao modelo. Nesse caso, vamos vincular uma ferramenta que busca o clima.
Primeiro, definimos um modelo Pydantic que representa a ferramenta que queremos usar. Em seguida, associamos essa ferramenta ao modelo gpt-4o-audio-preview para que ela possa ser chamada quando necessário. Para isso, você precisará de uma chave de API do OpenWeatherMap.
import requests
from pydantic import BaseModel, Field
# Define a tool schema using Pydantic
class GetWeather(BaseModel):
"""Get the current weather in a given location."""
location: str = Field(..., description="The city and state, e.g. Edinburgh, UK")
def fetch_weather(self):
# Using OpenWeatherMap API to fetch real-time weather
API_KEY = "YOUR_API_KEY_HERE" # Replace with your actual API key
base_url = f"http://api.openweathermap.org/data/2.5/weather?q={self.location}&APPID={API_KEY}&units=metric"
response = requests.get(base_url)
if response.status_code == 200:
data = response.json()
weather_description = data['weather'][0]['description']
temperature = data['main']['temp']
return f"The weather in {self.location} is {weather_description} with a temperature of {temperature}°C."
else:
# Print the status code and response for debugging
print(f"Error: {response.status_code}, {response.text}")
return f"Could not fetch the weather for {self.location}."
# Example usage
weather_tool = GetWeather(location="Edinburgh, GB") # Using city name and country code
ai_msg = weather_tool.fetch_weather()
print(ai_msg)Vamos ver o que está acontecendo:
Neste exemplo específico, quero saber como está o tempo em Edimburgo. Quando o executei, obtive este resultado: O tempo em Edimburgo, GB, está nublado, com uma temperatura de 13,48°C.
Ao encadear tarefas, você pode criar fluxos de trabalho de várias etapas que combinam várias ferramentas e chamadas de modelo para lidar com solicitações complexas. Imagine um cenário em que você queira que seu assistente transcreva o áudio e, em seguida, execute uma ação para o local mencionado no áudio. Neste exemplo, encadearemos uma tarefa de transcrição de áudio com uma pesquisa de clima com base no local transcrito.
import base64
import requests
from pydantic import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# Define the tool schema for fetching weather
class GetWeather(BaseModel):
"""Get the current weather in a given location."""
location: str = Field(..., description="The city and state, e.g. Edinburgh, UK")
def fetch_weather(self):
# Using OpenWeatherMap API to fetch real-time weather
API_KEY = "YOUR_API_KEY_HERE" # Replace with your actual API key
base_url = f"http://api.openweathermap.org/data/2.5/weather?q={self.location}&appid={API_KEY}&units=metric"
response = requests.get(base_url)
if response.status_code == 200:
data = response.json()
weather_description = data['weather'][0]['description']
temperature = data['main']['temp']
return f"The weather in {self.location} is {weather_description} with a temperature of {temperature}°C."
else:
return f"Could not fetch the weather for {self.location}."
# Instantiate the LLM model
llm = ChatOpenAI(
model="gpt-4o-audio-preview"
)
# Function to handle audio transcription using the LLM
def audio_to_text(audio_b64: str) -> str:
# Define the message to send for transcription
messages = [
(
"human",
[
{"type": "text", "text": "Transcribe the following:"},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Invoke the model and get the transcription
output_message = llm.invoke(messages)
# Return the transcription from the model's output
return output_message.content
# Create a prompt template for transcription and weather lookup
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are an assistant that transcribes audio and fetches weather information."),
("human", "Transcribe the following and tell me the weather in the location mentioned in the audio."),
]
)
# Bind the tool to the model
llm_with_tools = llm.bind_tools([GetWeather])
# Chain the transcription and weather tool
chain = prompt | llm_with_tools
# Read and encode the audio file in base64
audio_file = "weather_input.wav" #Replace with your audio file
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Transcribe the audio to get the location
transcribed_location = audio_to_text(audio_b64)
# Print the transcription result for debugging
print(f"Transcribed location: {transcribed_location}")
# Check if transcription returned a valid result
if transcribed_location:
# Fetch weather for the transcribed location
weather_tool = GetWeather(location=transcribed_location)
weather_result = weather_tool.fetch_weather()
print(f"Weather result: {weather_result}")
else:
print("No valid location was transcribed from the audio.")Vamos detalhar o código:
Para este exemplo, forneci ao modelo um arquivo de áudio no qual eu dizia: "Edimburgo". Este é o resultado que obtive:Local transcrito: Edimburgo
Resultado do clima: O tempo em Edimburgo está nublado, com uma temperatura de 13,47°C.

Em alguns casos, você pode querer ajustar o modelo para lidar com tarefas específicas de forma mais eficaz. Por exemplo, se você estiver criando um aplicativo que transcreve áudio médico, talvez queira que o modelo tenha um conhecimento profundo de termos e jargões médicos. O OpenAI permite que você faça o ajuste fino do modelo treinando-o em conjuntos de dados personalizados.
Vamos ver como você pode fazer isso:
import base64
from langchain_openai import ChatOpenAI
# Step 1: Instantiate the fine-tuned audio-capable model
fine_tuned_model = ChatOpenAI(
temperature=0,
model="ft:gpt-4o-audio-preview:your-organization::model-id"
)
# Step 2: Capture and encode the input audio file (medical report)
audio_file = "medical_report.wav"
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Step 3: Create the message structure for transcription request
messages = [
(
"human",
[
{"type": "text", "text": "Please transcribe this medical report audio."},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Step 4: Invoke the fine-tuned model to transcribe the audio
result = fine_tuned_model.invoke(messages)
# Step 5: Extract and print the transcribed text from the response
transcription = result.content # This contains the transcription
print(f"Transcription: {transcription}")
# Debugging: Print the full structure of the additional_kwargs for inspection
print(result.additional_kwargs)Isso usa um modelo ajustado especificamente treinado para lidar com áudio médico, mas você também pode ajustar modelos para outros casos de uso, como transcrições jurídicas, gravações de atendimento ao cliente ou edição de podcast.
Por fim, vamos analisar um exemplo prático em que criamos um assistente habilitado para voz que ouve as consultas do usuário por meio de áudio, gera uma resposta e responde de volta usando áudio.
Este é o fluxo de trabalho que você seguirá:
Vamos ver como você pode codificar isso:
import base64
from langchain_openai import ChatOpenAI
# Step 1: Instantiate the audio-capable model with configuration for generating audio
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
temperature=0,
model_kwargs={
"modalities": ["text", "audio"], # Enable both text and audio modalities
"audio": {"voice": "alloy", "format": "wav"}, # Set the desired voice and output format
}
)
# Step 2: Capture and encode the audio
audio_file = "math_joke_audio.wav" #You can replace your audio file here
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Step 3: Create the message structure for transcription and audio response
messages = [
(
"human",
[
{"type": "text", "text": "Answer the question."},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Step 4: Invoke the model to transcribe the audio and generate a response
result = llm.invoke(messages)
# Step 5: Extract the audio response
audio_response = result.additional_kwargs.get('audio', {}).get('data') # Safely check if audio exists
# Step 6: Save the audio response to a file if it exists
if audio_response:
# Decode the base64 audio data and save it as a .wav file
audio_bytes = base64.b64decode(audio_response)
with open("response.wav", "wb") as f:
f.write(audio_bytes)
print("Audio response saved as 'response.wav'")
else:
print("No audio response available")Vamos detalhar como isso funciona:
Esse assistente foi criado para falar com áudio. Ele ouve a voz do usuário, entende a pergunta e, em seguida, responde usando sua própria voz. Essa configuração é ótima para criar assistentes de voz simples, e você pode torná-la mais avançada posteriormente, se necessário!

Neste tutorial, exploramos o modelo gpt-4o-audio-preview da OpenAI, abordando a configuração, a entrada/saída de áudio, os casos de uso avançados e até mesmo a criação de um assistente de voz básico. Esse modelo avançado oferece uma base sólida para a criação de aplicativos habilitados para áudio no mundo real.
Se você quiser aprimorar seu conhecimento prático sobre LangChain, recomendo estes blogs:
Aprenda IA com estes cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali
Tutorial
Moez Ali





