
Cours
Développement d'applications LLM avec LangChain
3 h
46.5K
Imaginez que vous construisiez une application à commande vocale, comme un bot de service à la clientèle ou un transcripteur de podcasts. En règle générale, vous aurez besoin de plusieurs outils pour des tâches telles que la transcription et la génération de fichiers audio. OpenAI's gpt-4o-audio-preview simplifie cela en comprenant et en générant à la fois du texte et de l'audio.
Dans ce tutoriel, nous allons explorer ce modèle puissant et comment l'utiliser avec LangChain pour un traitement audio transparent. Je vous expliquerai comment mettre en place ce modèle, travailler avec des entrées audio, générer des réponses à la fois textuelles et audio, et même lier le tout pour construire des applications réelles.
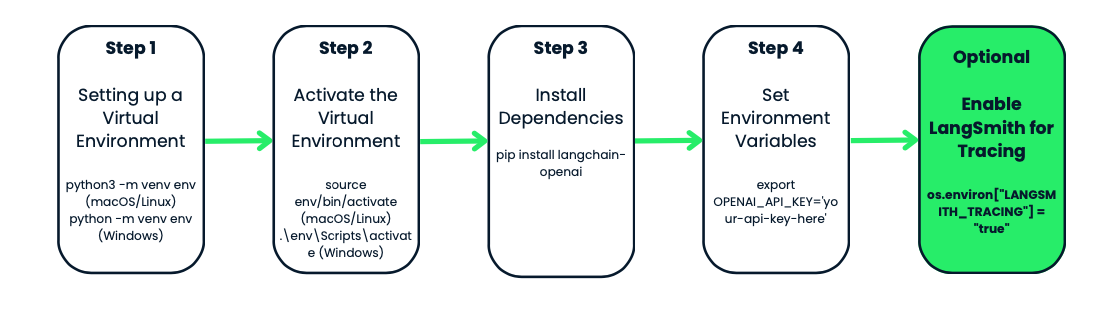
Avant d'utiliser le modèle gpt-4o-audio-preview d'OpenAI, configurons un environnement virtuel pour votre projet. Cela permet d'organiser les choses et d'éviter les conflits de dépendance, ce qui est particulièrement utile lorsque vous travaillez sur plusieurs projets.
Imaginez que vous ayez deux projets différents. L'un d'entre eux nécessite la version 1.0 d'un paquet, tandis que l'autre nécessite la version 2.0. Si vous installez tout globalement, vous rencontrerez des conflits.
Les environnements virtuels créent un espace de travail isolé, un peu comme une bulle, où vous pouvez installer tout ce dont vous avez besoin pour un projet spécifique. Lorsque vous créez un environnement pour votre projet, vous n'avez plus à vous soucier de casser la configuration Python de votre système ou de conflits de paquets.
Commençons par créer un environnement virtuel pour notre projet. Nous utiliserons le module intégré Python venv intégré à Python. Nous en aurons besoin :
python3 -m venv env. Sous Windows, il se présente comme suit : python -m venv env.venv est l'outil de Python pour la création d'environnements virtuels, et que env est le nom du dossier de l'environnement. Vous pouvez lui donner le nom que vous voulez : env, venv, my_project_env, etc. Il est conseillé d'être bref et simple.source env/bin/activate. Sous Windows, utilisez : .\env\Scripts\activateVous remarquerez que l'invite de votre terminal se transforme en quelque chose comme env- c'est le signe que vous travaillez dans votre environnement virtuel. À partir de maintenant, tous les paquets que vous installez ou les commandes que vous exécutez seront isolés dans ce projet.
Une fois votre environnement activé, il est temps d'installer les outils dont vous avez besoin. Puisque nous travaillons avec OpenAI et LangChain, commençons par installer le paquet langchain-openai. Ce paquet nous permettra d'interagir avec les modèles d'OpenAI.
Exécutez ceci dans votre terminal : pip install langchain-openai.
L'étape suivante consiste à s'assurer que vos informations sensibles, telles que les clés d'API, ne sont pas codées en dur dans vos scripts. Pour ce faire, nous allons définir des variables d'environnement.
Tout d'abord, vous devez avoir accès aux modèles d'OpenAI. Si vous ne l'avez pas encore fait, rendez-vous sur la plateforme OpenAI et créez un compte. Une fois que vous vous êtes inscrit, vous devez générer une clé API. Cette clé API vous permet d'accéder aux modèles d'OpenAI, y compris le gpt-4o-audio-preview.
Dans notre cas, nous devons définir l'adresse OPENAI_API_KEY. Vous pouvez le définir manuellement à chaque fois que vous travaillez sur votre projet, ou utiliser un fichier .env pour le stocker et y accéder facilement. Examinons les deux méthodes.
Si vous ne travaillez que temporairement et souhaitez une configuration rapide, vous pouvez définir la variable d'environnement directement dans votre terminal.
export OPENAI_API_KEY='your-api-key-here'set OPENAI_API_KEY='your-api-key-here'Votre clé API est désormais disponible dans votre script, et vous pouvez y accéder à l'aide du module os de Python.
Si vous préférez une solution plus permanente, vous pouvez utiliser un fichier .env pour stocker vos variables d'environnement. Ce fichier sera placé dans votre dossier de projet et gardera vos clés en sécurité.
Tout d'abord, créez un fichier .env dans le répertoire de votre projet, et à l'intérieur, ajoutez votre clé API comme ceci :
OPENAI_API_KEY=your-api-key-hereEnsuite, installez le paquetage python-dotenv:
pip install python-dotenvMaintenant, dans votre script Python, chargez les variables d'environnement à partir du fichier .env comme suit :
from dotenv import load_dotenv
import os
load_dotenv() # Load variables from .env file
api_key = os.getenv('OPENAI_API_KEY')Cette méthode est particulièrement utile si vous avez plusieurs variables d'environnement à gérer, et elle permet de conserver un code propre et sécurisé.
Si vous souhaitez suivre et surveiller vos appels d'API à des fins de débogage ou de performance, OpenAI dispose d'une fonctionnalité intéressante appelée LangSmith. Il vous fournit des journaux détaillés de chaque appel d'API effectué par votre modèle, ce qui peut s'avérer très utile si vous essayez d'optimiser ou de dépanner votre flux de travail.
Vous pouvez activer le traçage LangSmith de la manière suivante :
os.environ["LANGSMITH_API_KEY"] = getpass.getpass("Enter your LangSmith API key: ")
os.environ["LANGSMITH_TRACING"] = "true"Encore une fois, cette option est totalement facultative, mais c'est un outil pratique si vous travaillez sur une application complexe et que vous souhaitez contrôler le comportement de vos modèles.
Maintenant que notre environnement est configuré et prêt à fonctionner, il est temps de passer à la partie la plus amusante, à savoir l'établissement du modèle gpt-4o-audio-preview d'OpenAI. C'est ici que nous commençons à interagir avec le modèle, à faire des demandes et à traiter les entrées et les sorties.
Dans cette section, nous verrons comment instancier le modèle à l'aide du cadre LangChain, personnaliser certains paramètres de base et mettre en place tout ce dont vous avez besoin pour commencer à générer des réponses.
Avant d'entrer dans le code, prenons le temps de comprendre ce que signifie "instancier" le modèle. Lorsque nous disons que nous instancions le modèle, nous créons essentiellement un objet dans Python qui nous permettra d'interagir avec le modèle gpt-4o-audio-preview. Cet objet est comme le panneau de contrôle - il contient tous les paramètres, configurations et méthodes dont nous aurons besoin pour envoyer des données au modèle et obtenir des résultats en retour.
Commençons par créer cet objet modèle. Puisque nous travaillons dans le cadre de LangChain, nous utiliserons la classe ChatOpenAI du paquet langchain_openai. Cette classe nous permet d'accéder facilement aux modèles OpenAI et à leurs fonctionnalités.
from langchain_openai import ChatOpenAI
# Create the model object
llm = ChatOpenAI(
model="gpt-4o-audio-preview", # Specifying the model
temperature=0, # Controls randomness in the output
max_tokens=None, # Unlimited tokens in output (or specify a max if needed)
timeout=None, # Optional: Set a timeout for requests
max_retries=2 # Number of retries for failed requests
)L'un des grands avantages de ce modèle est qu'il est personnalisable. Vous pouvez modifier les paramètres en fonction de vos besoins. Par exemple, si vous créez une application qui nécessite une transcription audio, vous pouvez ajuster les paramètres pour traiter des entrées plus importantes ou limiter la longueur de la sortie.
Par exemple, si vous traitez des demandes sensibles au temps et que vous voulez vous assurer que le modèle ne prend pas trop de temps, vous pouvez également définir un délai d'attente :
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
timeout=30 # Set timeout to 30 seconds
)Maintenant que le modèle gpt-4o-audio-preview est opérationnel, examinons sa capacité à gérer les entrées et sorties audio.
Avant de commencer à travailler avec l'audio, la première étape consiste à charger et à encoder votre fichier audio dans un format que le modèle peut comprendre. OpenAI s'attend à ce que les données audio soient envoyées dans un format encodé en base64, nous allons donc commencer par télécharger un fichier et l'encoder.
Disons que vous avez un fichier .wav que vous voulez que le modèle traite - je l'ai nommé gpt.wav. Vous pouvez le remplacer par votre fichier en utilisant le code suivant. Voici comment vous pouvez charger et préparer ce fichier :
import base64
# Open the audio file and convert to base64
with open("gpt.wav", "rb") as f:
audio_data = f.read()
# Convert binary audio data to base64
audio_b64 = base64.b64encode(audio_data).decode()Que se passe-t-il ici ? Nous lisons le fichier audio sous forme de données binaires (mode "rb"), puis nous utilisons la bibliothèque base64 pour l'encoder en une chaîne base64. Il s'agit du format requis par OpenAI pour le traitement des entrées audio.
Une fois l'audio encodé, il est temps de le transmettre au modèle. Le modèle gpt-4o-audio-preview peut transcrire la parole à partir de fichiers audio. Si vous avez déjà eu besoin de transformer un podcast, un mémo vocal ou un enregistrement de réunion en texte, c'est exactement ce que vous attendiez ! Voyons comment cela fonctionne.
# Define the input message with audio
messages = [
(
"human",
[
{"type": "text", "text": "Transcribe the following:"},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Send the request to the model and get the transcription
output_message = llm.invoke(messages)
print(output_message.content)Dans cet exemple, nous envoyons deux données au modèle :
Le modèle traite cette entrée et renvoie une transcription de l'audio. Ainsi, si votre fichier audio contient une phrase telle que "J'apprends à utiliser l'intelligence artificielle", le modèle renverra un texte comme celui-ci : "J'apprends à utiliser l'IA.
Mais le modèle gpt-4o-audio-preview ne se contente pas de comprendre l'audio, il peut aussi le générer. Voici comment vous pouvez configurer le modèle pour générer des sorties audio :
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
temperature=0,
model_kwargs={
"modalities": ["text", "audio"], # We’re telling the model to handle both text and audio
"audio": {"voice": "alloy", "format": "wav"}, # Configure voice and output format
}
)
# Send a request and ask the model to respond with audio
messages = [("human", "Are you human? Reply either yes or no.")]
output_message = llm.invoke(messages)
# Access the generated audio data
audio_response = output_message.additional_kwargs['audio']['data']Voyons cela de plus près :
La réponse audio codée en base64 est stockée dans output_message.additional_kwargs['audio']['data'], et vous pouvez facilement décoder et enregistrer ce fichier pour le lire.
Maintenant que vous produisez de l'audio, vous souhaitez probablement enregistrer le fichier et le lire, n'est-ce pas ? Voici comment vous pouvez prendre ces données audio codées en base64, les décoder et les enregistrer sous forme de fichier .wav :
# Decode the base64 audio data
audio_bytes = base64.b64decode(output_message.additional_kwargs['audio']['data'])
# Save the audio file
with open("output.wav", "wb") as f:
f.write(audio_bytes)
print("Audio saved as output.wav")Vous pouvez maintenant lire ce fichier.wav sur votre machine locale à l'aide de n'importe quel lecteur multimédia. Ainsi, lorsque vous invoquez le modèle, il génère non seulement une réponse textuelle, mais aussi un fichier audio qui énonce la réponse.
Dans cette section, je vous expliquerai comment lier des outils au modèle gpt-4o-audio-preview, gérer des flux de travail plus complexes et même enchaîner plusieurs étapes pour créer des solutions entièrement automatisées. Si vous avez toujours voulu créer un assistant vocal qui ne se contente pas de transcrire de l'audio, mais qui va aussi chercher des informations dans des sources externes, cette section vous sera utile.
Commençons par l'appel d'outils. Il s'agit d'enseigner à votre modèle d'IA comment utiliser des outils ou des fonctions externes pour améliorer ses capacités. Au lieu de se contenter de traiter du texte ou de l'audio, le modèle peut effectuer des tâches supplémentaires telles que l'extraction de données à partir d'API, des calculs ou même la recherche d'informations météorologiques.
Le modèle gpt-4o-audio-preview d'OpenAI peut être combiné avec d'autres outils et fonctions à l'aide de la méthode LangChain bind_tools. Grâce à cette méthode, vous pouvez créer un flux de travail fluide dans lequel le modèle décide quand et comment utiliser les outils que vous lui avez fournis.
Je vais vous présenter un exemple pratique de liaison d'un outil au modèle. Dans ce cas, nous allons lier un outil qui récupère la météo.
Tout d'abord, nous définissons un modèle pydantique qui représente l'outil que nous voulons utiliser. Ensuite, nous lions cet outil au modèle gpt-4o-audio-preview afin qu'il puisse être invoqué si nécessaire. Pour cela, vous aurez besoin d'une clé API de OpenWeatherMap.
import requests
from pydantic import BaseModel, Field
# Define a tool schema using Pydantic
class GetWeather(BaseModel):
"""Get the current weather in a given location."""
location: str = Field(..., description="The city and state, e.g. Edinburgh, UK")
def fetch_weather(self):
# Using OpenWeatherMap API to fetch real-time weather
API_KEY = "YOUR_API_KEY_HERE" # Replace with your actual API key
base_url = f"http://api.openweathermap.org/data/2.5/weather?q={self.location}&APPID={API_KEY}&units=metric"
response = requests.get(base_url)
if response.status_code == 200:
data = response.json()
weather_description = data['weather'][0]['description']
temperature = data['main']['temp']
return f"The weather in {self.location} is {weather_description} with a temperature of {temperature}°C."
else:
# Print the status code and response for debugging
print(f"Error: {response.status_code}, {response.text}")
return f"Could not fetch the weather for {self.location}."
# Example usage
weather_tool = GetWeather(location="Edinburgh, GB") # Using city name and country code
ai_msg = weather_tool.fetch_weather()
print(ai_msg)Voyons ce qu'il en est :
Dans cet exemple particulier, je souhaite connaître le temps qu'il fait à Édimbourg. Lorsque je l'ai exécuté, j'ai obtenu le résultat suivant : Le temps à Edinburgh, GB est à nuages fragmentés avec une température de 13,48°C.
En enchaînant les tâches, vous pouvez créer des flux de travail en plusieurs étapes qui combinent plusieurs outils et appels de modèles pour traiter des demandes complexes. Imaginez un scénario dans lequel vous souhaitez que votre assistant transcrive un document audio et effectue ensuite une action pour le lieu mentionné dans le document audio. Dans cet exemple, nous allons enchaîner une tâche de transcription audio avec une recherche météorologique basée sur le lieu transcrit.
import base64
import requests
from pydantic import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# Define the tool schema for fetching weather
class GetWeather(BaseModel):
"""Get the current weather in a given location."""
location: str = Field(..., description="The city and state, e.g. Edinburgh, UK")
def fetch_weather(self):
# Using OpenWeatherMap API to fetch real-time weather
API_KEY = "YOUR_API_KEY_HERE" # Replace with your actual API key
base_url = f"http://api.openweathermap.org/data/2.5/weather?q={self.location}&appid={API_KEY}&units=metric"
response = requests.get(base_url)
if response.status_code == 200:
data = response.json()
weather_description = data['weather'][0]['description']
temperature = data['main']['temp']
return f"The weather in {self.location} is {weather_description} with a temperature of {temperature}°C."
else:
return f"Could not fetch the weather for {self.location}."
# Instantiate the LLM model
llm = ChatOpenAI(
model="gpt-4o-audio-preview"
)
# Function to handle audio transcription using the LLM
def audio_to_text(audio_b64: str) -> str:
# Define the message to send for transcription
messages = [
(
"human",
[
{"type": "text", "text": "Transcribe the following:"},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Invoke the model and get the transcription
output_message = llm.invoke(messages)
# Return the transcription from the model's output
return output_message.content
# Create a prompt template for transcription and weather lookup
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are an assistant that transcribes audio and fetches weather information."),
("human", "Transcribe the following and tell me the weather in the location mentioned in the audio."),
]
)
# Bind the tool to the model
llm_with_tools = llm.bind_tools([GetWeather])
# Chain the transcription and weather tool
chain = prompt | llm_with_tools
# Read and encode the audio file in base64
audio_file = "weather_input.wav" #Replace with your audio file
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Transcribe the audio to get the location
transcribed_location = audio_to_text(audio_b64)
# Print the transcription result for debugging
print(f"Transcribed location: {transcribed_location}")
# Check if transcription returned a valid result
if transcribed_location:
# Fetch weather for the transcribed location
weather_tool = GetWeather(location=transcribed_location)
weather_result = weather_tool.fetch_weather()
print(f"Weather result: {weather_result}")
else:
print("No valid location was transcribed from the audio.")Décomposons le code :
Pour cet exemple, j'ai donné au modèle un fichier audio dans lequel je disais : "Edimbourg". Voici le résultat que j'ai obtenu :Transcribed location : Edinburgh
Résultats météorologiques : Le temps à Édimbourg est à nuages fragmentés avec une température de 13,47°C.

Dans certains cas, vous souhaiterez peut-être affiner le modèle pour traiter plus efficacement des tâches spécifiques. Par exemple, si vous créez une application qui transcrit des données audio médicales, vous voudrez peut-être que le modèle ait une connaissance approfondie des termes médicaux et du jargon. OpenAI vous permet d'affiner le modèle en l'entraînant sur des ensembles de données personnalisés.
Voyons comment procéder :
import base64
from langchain_openai import ChatOpenAI
# Step 1: Instantiate the fine-tuned audio-capable model
fine_tuned_model = ChatOpenAI(
temperature=0,
model="ft:gpt-4o-audio-preview:your-organization::model-id"
)
# Step 2: Capture and encode the input audio file (medical report)
audio_file = "medical_report.wav"
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Step 3: Create the message structure for transcription request
messages = [
(
"human",
[
{"type": "text", "text": "Please transcribe this medical report audio."},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Step 4: Invoke the fine-tuned model to transcribe the audio
result = fine_tuned_model.invoke(messages)
# Step 5: Extract and print the transcribed text from the response
transcription = result.content # This contains the transcription
print(f"Transcription: {transcription}")
# Debugging: Print the full structure of the additional_kwargs for inspection
print(result.additional_kwargs)Il s'agit d'un modèle affiné, spécialement formé pour traiter les données audio médicales, mais vous pouvez également affiner les modèles pour d'autres cas d'utilisation, tels que les transcriptions juridiques, les enregistrements du service clientèle ou l'édition de podcasts.
Enfin, examinons un exemple pratique dans lequel nous construisons un assistant à commande vocale qui écoute les requêtes de l'utilisateur par le biais de l'audio, génère une réponse et répond par le biais de l'audio.
Voici la procédure que nous allons suivre :
Voyons comment coder cela :
import base64
from langchain_openai import ChatOpenAI
# Step 1: Instantiate the audio-capable model with configuration for generating audio
llm = ChatOpenAI(
model="gpt-4o-audio-preview",
temperature=0,
model_kwargs={
"modalities": ["text", "audio"], # Enable both text and audio modalities
"audio": {"voice": "alloy", "format": "wav"}, # Set the desired voice and output format
}
)
# Step 2: Capture and encode the audio
audio_file = "math_joke_audio.wav" #You can replace your audio file here
with open(audio_file, "rb") as audio_file:
audio_b64 = base64.b64encode(audio_file.read()).decode('utf-8')
# Step 3: Create the message structure for transcription and audio response
messages = [
(
"human",
[
{"type": "text", "text": "Answer the question."},
{"type": "input_audio", "input_audio": {"data": audio_b64, "format": "wav"}},
],
)
]
# Step 4: Invoke the model to transcribe the audio and generate a response
result = llm.invoke(messages)
# Step 5: Extract the audio response
audio_response = result.additional_kwargs.get('audio', {}).get('data') # Safely check if audio exists
# Step 6: Save the audio response to a file if it exists
if audio_response:
# Decode the base64 audio data and save it as a .wav file
audio_bytes = base64.b64decode(audio_response)
with open("response.wav", "wb") as f:
f.write(audio_bytes)
print("Audio response saved as 'response.wav'")
else:
print("No audio response available")Voyons comment cela fonctionne :
Cet assistant est conçu pour parler avec l'audio. Il écoute la voix de l'utilisateur, comprend la question et y répond en utilisant sa propre voix. Cette configuration est idéale pour créer des assistants vocaux simples, et vous pouvez la rendre plus avancée par la suite si nécessaire !

Dans ce tutoriel, nous avons exploré le modèle gpt-4o-audio-preview d'OpenAI, couvrant la configuration, l'entrée/sortie audio, les cas d'utilisation avancés, et même la construction d'un assistant vocal de base. Ce modèle puissant constitue une base solide pour la création d'applications audio réelles.
Si vous souhaitez améliorer vos connaissances pratiques sur LangChain, je vous recommande ces blogs :
Apprenez l'IA avec ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach