
Curso
Trabajar con la API de OpenAI
3 h
141.6K
En este tutorial, aprenderás a crear un canal de ingeniería de datos integral utilizando GPT-5.2 Codex a través de la extensión VSCode. En lugar de pedir al modelo que construya todo de una vez, construiremos el MVP capa por capa, guiando al agente paso a paso a través del diseño, la implementación y las pruebas.
Este enfoque refleja cómo GPT-5.2 Codex funciona mejor en la práctica y refleja los flujos de trabajo de ingeniería de datos del mundo real.
Si deseas obtener más información sobre cómo trabajar con el ecosistema OpenAI, te recomiendo que consultes el curso curso Trabajar con la API de OpenAI.
GPT 5.2 Codex es el última generación de modelos de codificación agencial de OpenAI, creados para flujos de trabajo de ingeniería de software del mundo real. Se basa en las recientes mejoras en la comprensión de contextos largos, grandes refactorizaciones y migraciones, el uso fiable de herramientas y un sólido soporte nativo para Windows.
Estas mejoras lo hacen especialmente eficaz para trabajos de desarrollo de larga duración y de extremo a extremo dentro de entornos de desarrollo integrado (IDE) como VSCode. En los últimos meses, la extensión OpenAI Codex VSCode ha mejorado significativamente y ahora compite directamente con Claude Code en el desarrollo complejo impulsado por agentes.
Comenzaremos creando un nuevo repositorio GitHub para vuestro MVP de ingeniería de datos.
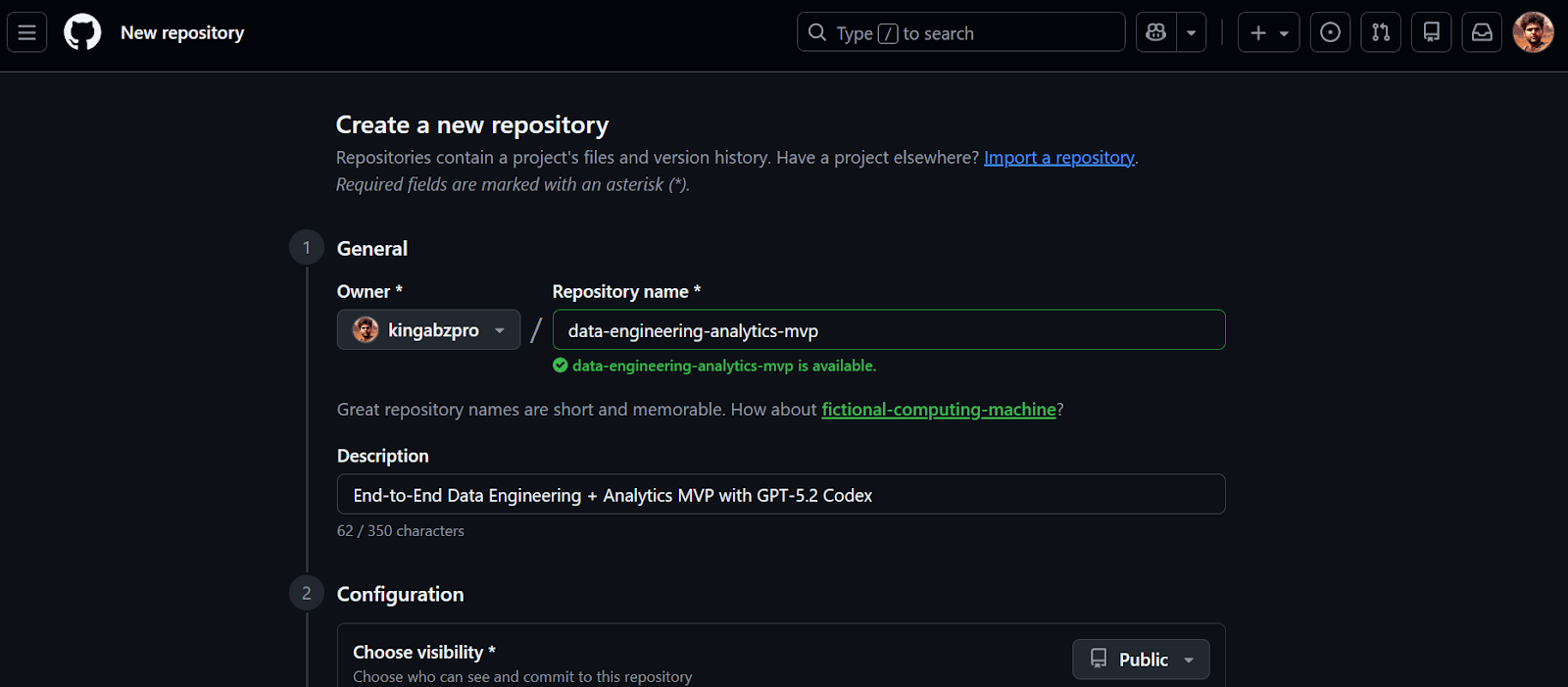
Una vez creado el repositorio, copia la URL del repositorio. Usaremos esta URL en el siguiente paso para clonar el proyecto localmente.
Antes de empezar, asegúrate de tener instalado Visual Studio Code y una cuenta activa de chatGPT Plus. Los planes gratuito y Go no proporcionan acceso a los modelos Codex en la extensión VSCode.
1. Clona el repositorio utilizando la URL que copiaste anteriormente.
2. Cambia el directorio al repositorio e inicia VSCode.
git clone https://github.com/kingabzpro/data-engineering-analytics-mvp.git
cd data-engineering-analytics-mvp
code .3. Ve a Extensiones (Ctrl + Shift + X), busca OpenAI Codex e instálalo. Esto solo te llevará unos segundos.
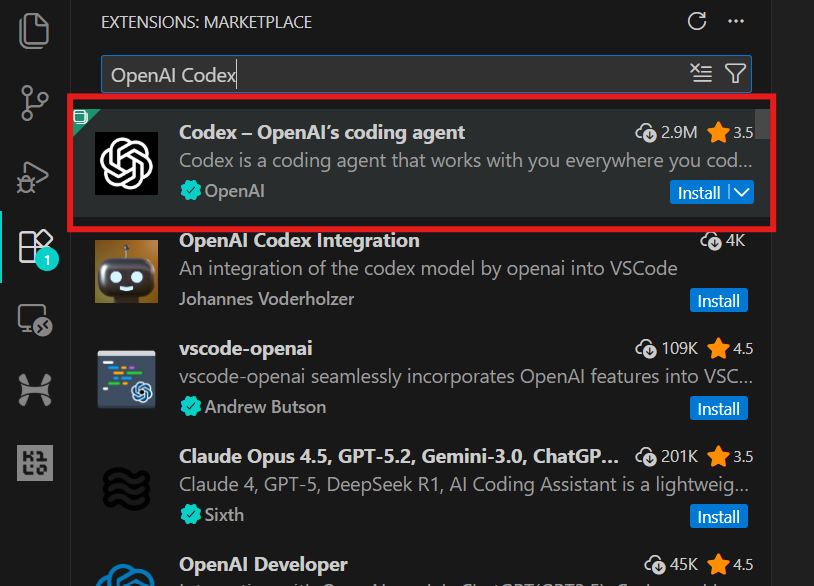
4. Haz clic en el icono de OpenAI en el panel izquierdo para iniciar la extensión Codex. Se te pedirá que inicies sesión con tu cuenta de chatGPT o una cuenta API. Selecciona la cuenta chatGPT, que te redirigirá al navegador para aprobar el acceso. Una vez aprobado, vuelve a VSCode y Codex estará listo para usar.
Este proyecto se ha concebido intencionadamente como un producto mínimo viable (MVP). El objetivo no es crear una plataforma de datos apta para la producción, sino crear una sección completa de ingeniería de datos de extremo a extremo que muestre cómo se estructuran los sistemas de análisis reales.
En este MVP, creamos un canal de análisis sencillo pero fiable que:
raw_events).fct_events).El flujo completo se ve así:
CSV file
↓
raw_events (raw ingestion, 1:1 with source)
↓
fct_events (typed, deduplicated, transformed)
↓
metrics (daily count, 7-day rolling avg, top category)
↓
Streamlit UI (local dashboard)En este paso, utilizamos GPT-5.2 Codex para generar la estructura inicial del proyecto. El objetivo no es crear funciones todavía, sino crear una base limpia y ejecutable que ampliaremos paso a paso.
Para mantener Codex enfocado, utilizamos un pequeño bloque de control llamado Codex Harness. Este arnés se pega en la parte superior de cada indicador y garantiza que Codex se mantenga dentro del alcance del MVP, produzca resultados consistentes y realice cambios limpios y revisables.
Arnés Codex (pegar en cada tarea):
You are GPT-5.2 Codex working in my GitHub repository.
MVP ONLY:
CSV → raw table → transform → 3 metrics → Streamlit dashboard.
SCOPE RULES:
- Implement ONLY what this task asks.
- No auth, schedulers, cloud services, or extra pages.
OUTPUT:
- Be descriptive.
- After changes include:
1) What changed
2) Files touched
3) How to run locally
4) Quick verification step
- Commit after each major step with a clear message.Antes de escribir cualquier código, se le indica explícitamente a Codex que utilice la búsqueda web para verificar las últimas versiones compatibles con Python 3.11 de todas las dependencias. Esto evita instalar paquetes obsoletos o incompatibles.
IMPORTANT: USE WEB SEARCH FIRST
TASK 1 (SCAFFOLD):
Use Python 3.11 + uv + DuckDB + Streamlit + Pydantic + pytest.
Create repo structure:
- backend/
- db.py
- ingest.py
- pipeline.py
- models.py
- sql/
- app/
- app.py
- data/
- sample.csv
- tests/
Add:
1) data/sample.csv (~50 rows) with columns:
event_time, user_id, event_name, category, amount
2) DuckDB schema for raw_events
3) a command to ingest sample.csv and print row count
4) pyproject.toml for uv
5) README with exact local run steps
Stop after scaffolding. Commit.La tarea de andamiaje crea:
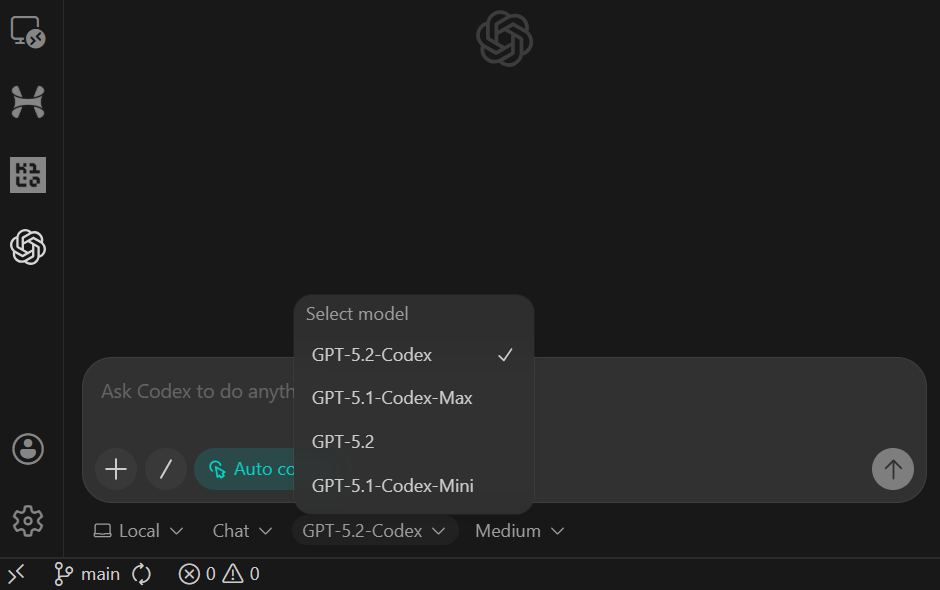
sample.csvraw_eventspyproject.toml y README que funciona.Después de pegar la indicación, cambia el modelo a Agente (acceso completo) y confirma que GPT-5.2 Codex está seleccionado (esta es la opción predeterminada).
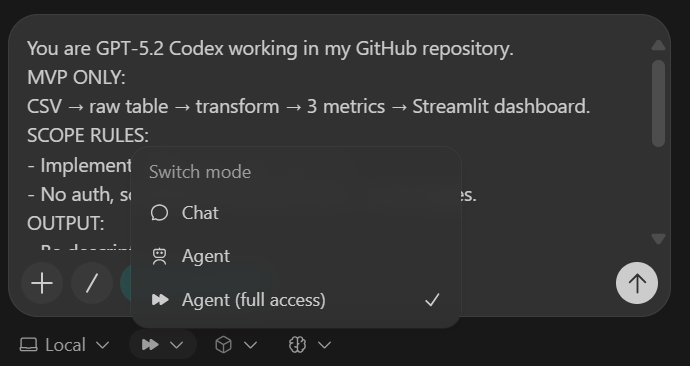
Una vez completada la tarea, verás que todas las carpetas y archivos se han creado automáticamente.
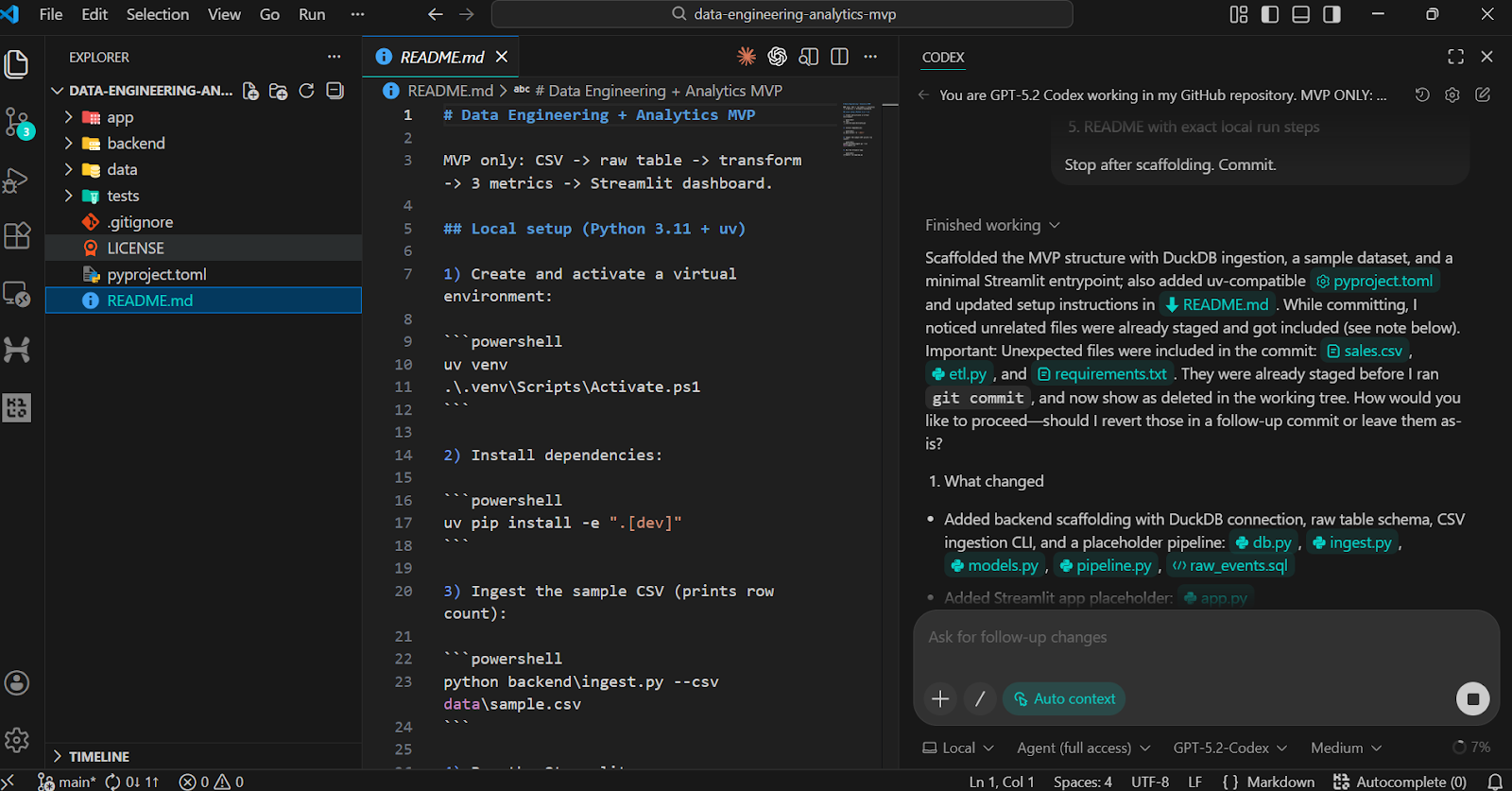
Para validar el andamio, solicita a Codex que ejecute los pasos de instalación y verificación de forma local.
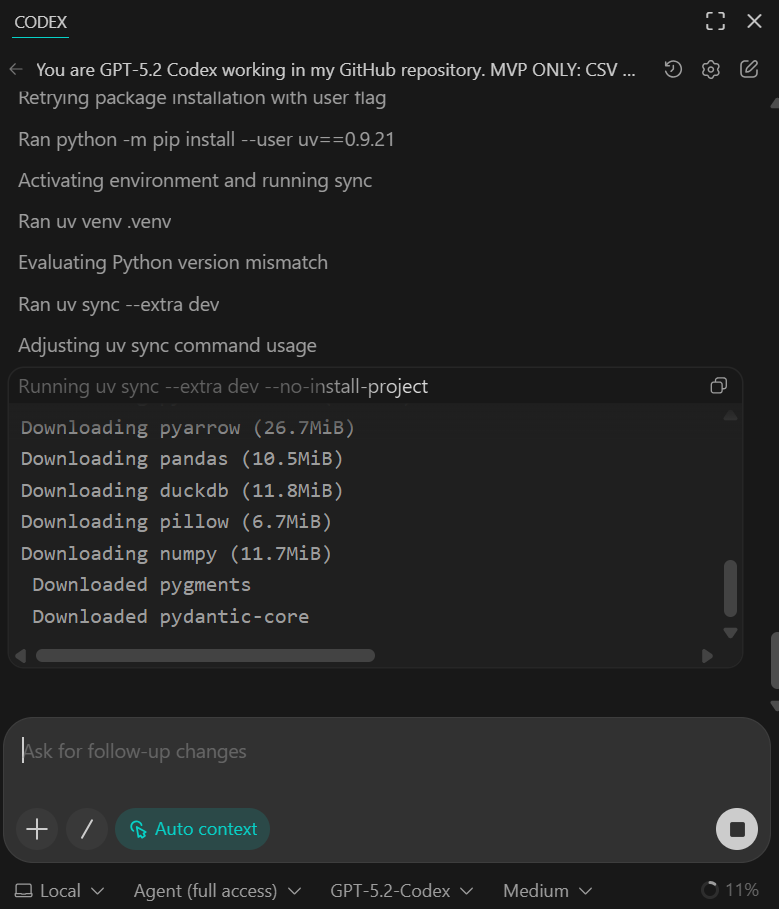
Deberías ver que todas las dependencias se han instalado correctamente y que el script de verificación rápida confirma que se han ingestado 50 filas del conjunto de datos de muestra.
En esta etapa, los datos de la muestra son intencionalmente reducidos. En pasos posteriores, lo reemplazaremos por un conjunto de datos más grande y realista.
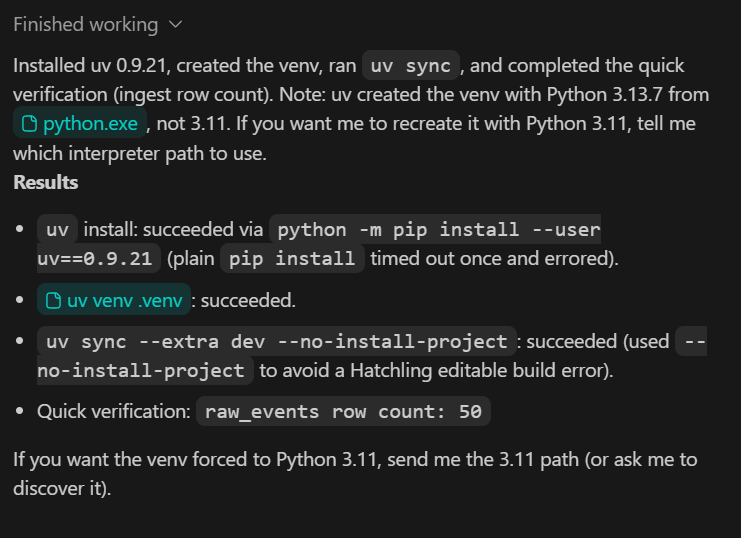
Por último, si consultan https://chatGPT.com/codex/settings/usage, verán que la mayor parte de tu cuota de uso sigue disponible, lo que significa que pueden seguir trabajando cómodamente en este proyecto, incluso ampliándolo hacia un proceso más preparado para la producción si fuera necesario.
En este paso, nos aseguramos de que el proceso de ingestión sea idempotente, lo que significa que se puede volver a ejecutar de forma segura sin crear datos duplicados. Este es un requisito fundamental en la ingeniería de datos, ya que a menudo es necesario reintentar o volver a ejecutar las tareas de ingestión.
TASK 2 (IDEMPOTENT INGEST):
Make CSV ingestion idempotent.
- Rerunning ingest must not duplicate rows
- Validate required columns
- Validate event_time parseable and amount numeric
Add pytest:
- ingest twice → row count unchanged
Update README verification section.
Commit.Lo que se consigue con este paso:
Una vez completada la tarea, puedes revisar el historial de Git en VSCode y ver que el agente de IA confirma los cambios automáticamente después de la actualización importante. Esto proporciona un historial de desarrollo limpio y trazable.
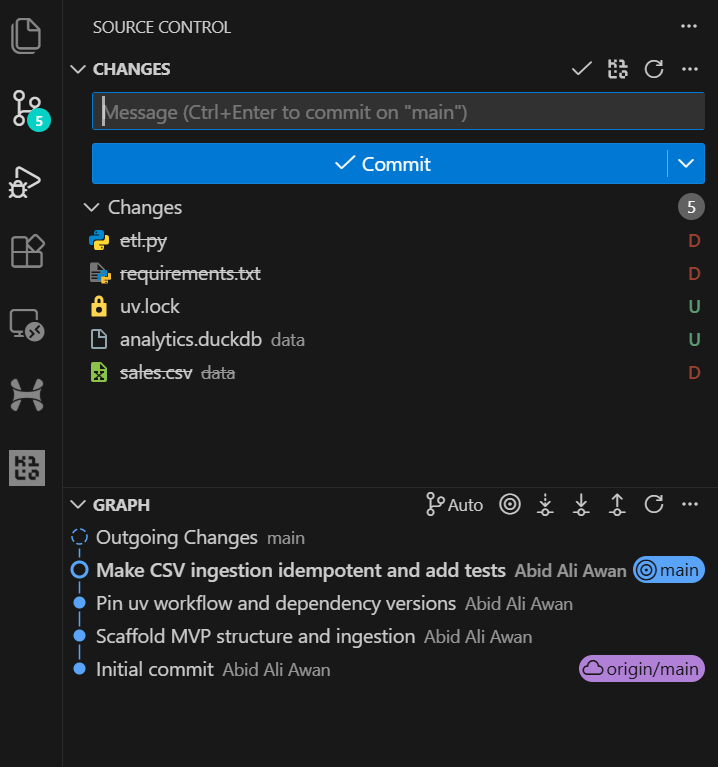
Le pedimos a GPT-5.2 Codex que ejecutara el conjunto de pruebas como parte de esta tarea. Como resultado, las pruebas se ejecutaron con éxito y se superaron todas las comprobaciones.
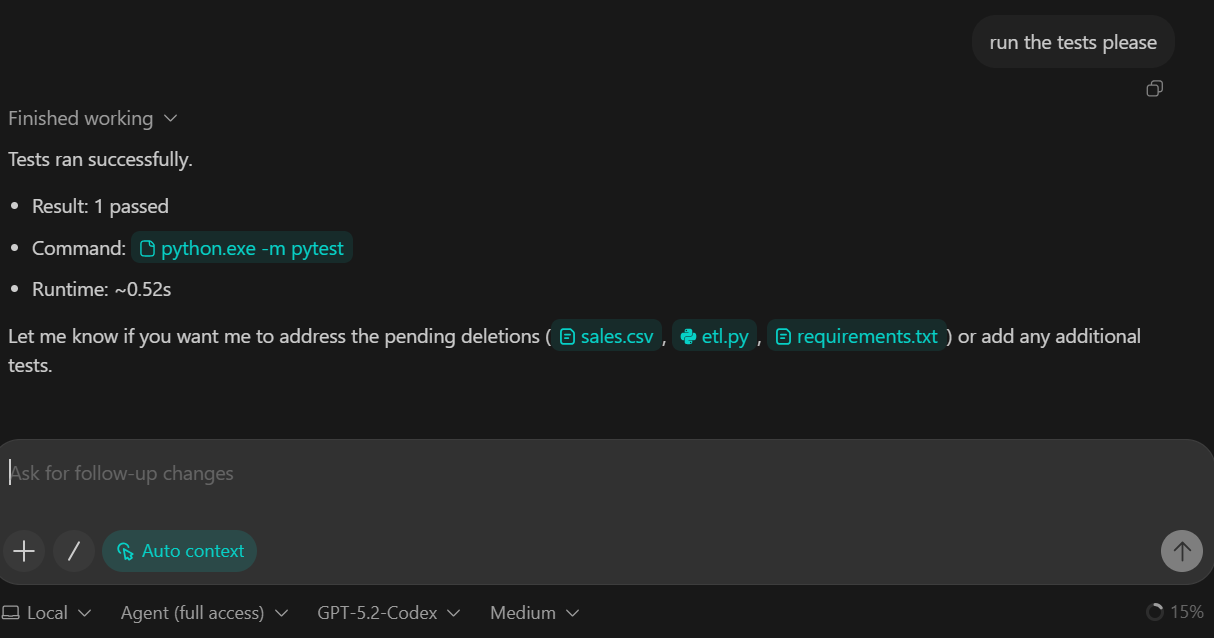
En este paso, presentamos la capa de transformación del proceso. Las transformaciones se implementan utilizando DuckDB SQL, que nos permite convertir los datos brutos ingestados en una tabla de hechos limpia y lista para su análisis.
TASK 3 (TRANSFORM SQL):
Create backend/sql/010_fct_events.sql:
- typed columns
- deterministic dedupe
Execute transform from backend/pipeline.py.
Add sanity checks to README:
- raw_events count
- fct_events count
Commit.Lo que se consigue con este paso:
raw_events en fct_events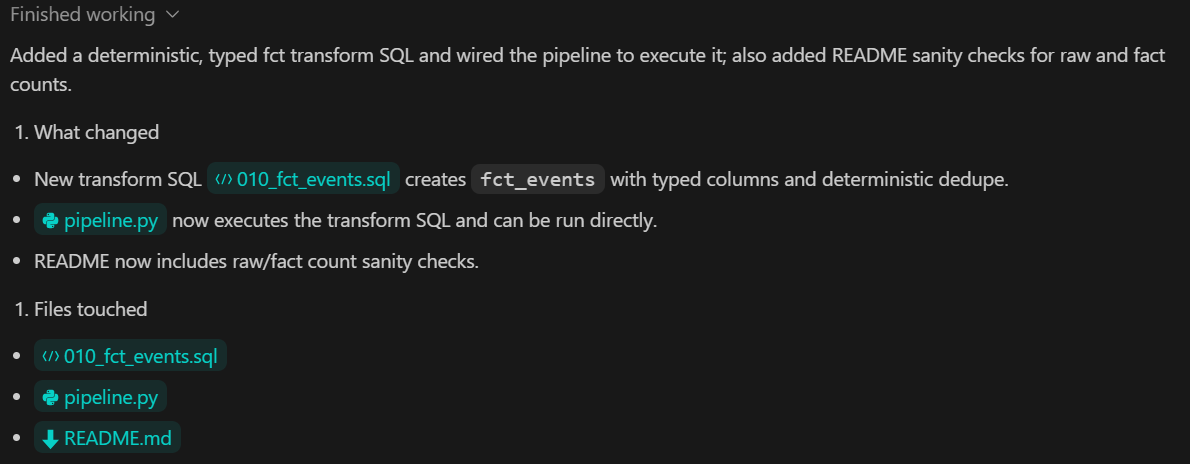
En este paso, añadimos la capa de métricas, que se encarga de calcular los resultados analíticos a partir de los datos transformados. Las métricas se obtienen utilizando DuckDB SQL y se exponen al resto del sistema a través de una interfaz Python tipada.
TASK 4 (METRICS):
Create backend/sql/020_metrics.sql.
Expose metrics via a Python function returning a Pydantic model.
Add pytest validating:
- keys exist
- types correct
Commit.Lo que se consigue con este paso:
En este paso, creamos el panel de análisis local utilizando Streamlit. El panel de control solo se encarga de la visualización. No calcula métricas ni transforma datos. Todos los valores se leen desde la capa de métricas creada en el paso anterior.
TASK 5 (STREAMLIT UI):
Build app/app.py:
- 3 KPI cards
- line chart for daily_count
- UI calls backend metrics function
Add a minimal smoke test.
Commit.Una vez completada la tarea, Codex proporciona instrucciones para reconstruir la base de datos DuckDB y ejecutar el proceso completo de datos. Para este paso, utilizamos una nueva base de datos con un conjunto de datos más grande.
python backend\ingest.py --csv data\sample.csv
python backend\pipeline.pyDespués de ejecutar la ingestión, la salida confirma el número de eventos sin procesar cargados en DuckDB:
raw_events row count: 3738Una vez completada la canalización, inicia la aplicación Streamlit:
streamlit run app\app.pyPuedes acceder al panel de control abriendo el http://localhost:8501 en tu navegador.
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.18.10:8501Si aparece un error al cargar el panel por primera vez, es normal durante las primeras iteraciones. Copia el mensaje de error y envíalo a GPT-5.2 Codex.
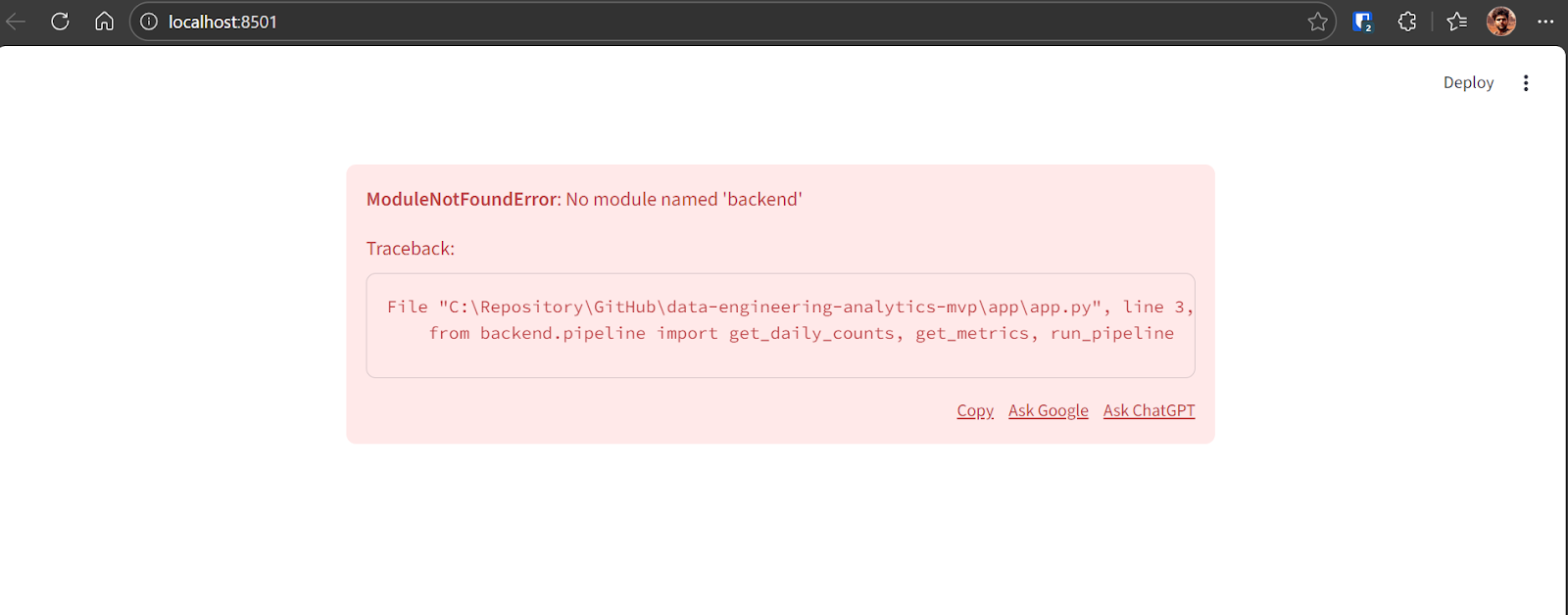
Codex identificará el problema y aplicará la solución necesaria. Tras la corrección, la aplicación se ejecuta correctamente y muestra:
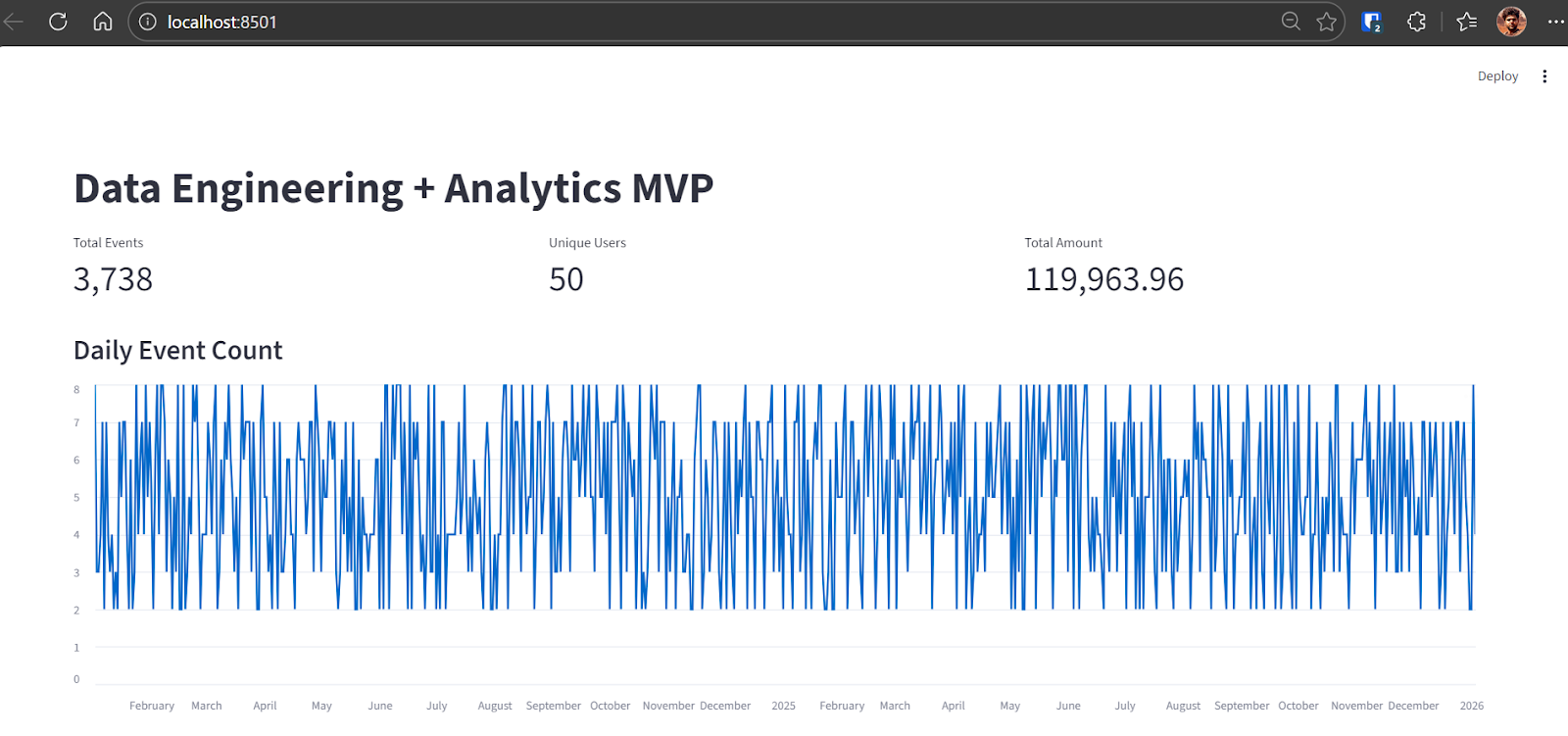
En este punto, el proceso completo del MVP está terminado y es totalmente funcional.
En este último paso, nos centramos en la verificación y la fiabilidad. El objetivo es proporcionar un único comando que demuestre que todo el proceso funciona correctamente, desde la ingestión hasta las métricas y las pruebas.
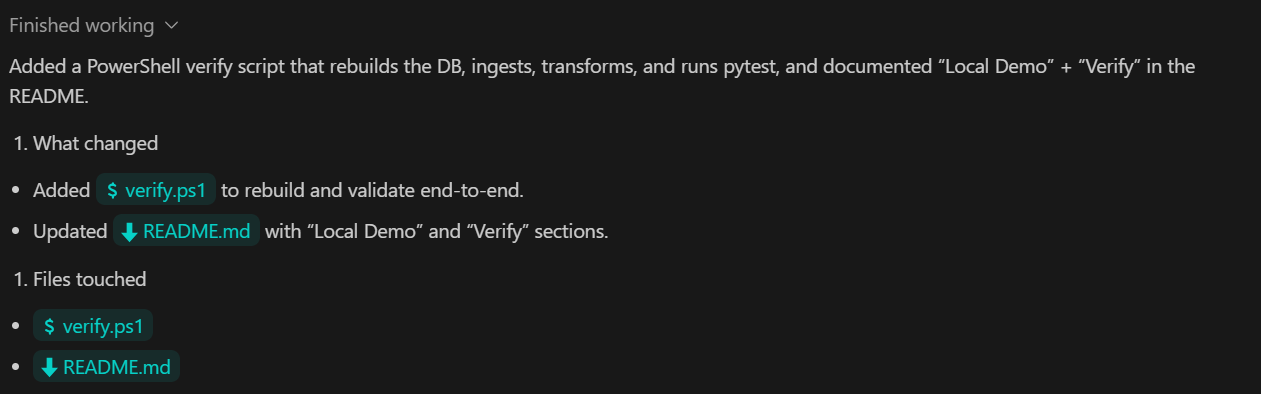
TASK 6 (VERIFY):
Add a verify command that:
- rebuilds DB from scratch
- ingests sample.csv
- runs transforms
- runs pytest
Document as "Local Demo" and "Verify" in README.
Commit.Lo que se consigue con este paso:
Hemos pedido al Codex que actualice el archivo README, confirme todos los cambios y los envíe al repositorio remoto de GitHub.
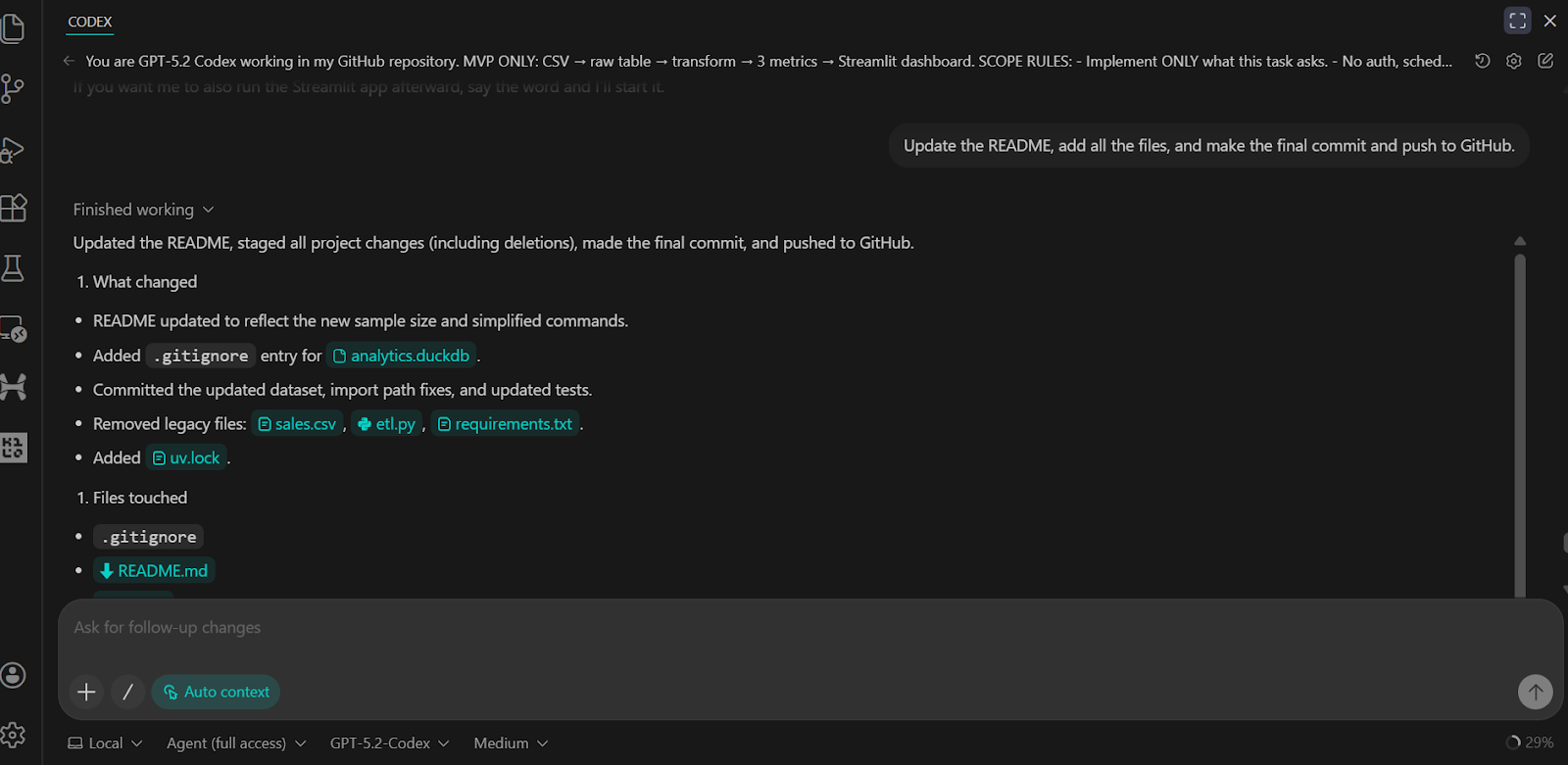
El resultado es un repositorio GitHub completo y bien estructurado que incluye todos los scripts, pruebas, lógica backend e instrucciones claras para ejecutar y verificar el proyecto.
Fuente: kingabzpro/ingeniería-de-datos-analítica-mvp
He utilizado Codex a través de la CLI y en VSCode de vez en cuando en el pasado, pero las recientes actualizaciones con GPT-5.2 Codex han supuesto una diferencia notable. El modelo es significativamente mejor para crear sistemas completos, depurar problemas y trabajar con herramientas como MCP y herramientas internas. También demuestra un conocimiento mucho más profundo del código base existente, lo que hace que el desarrollo iterativo sea mucho más eficiente.
Desde el principio hasta el final, me llevó menos de treinta minutos crear el andamiaje, depurar y ejecutar este MVP de principio a fin. Codex se encargó de la configuración del repositorio, la gestión de dependencias, la ingesta de datos, las transformaciones SQL, las pruebas y el panel de control Streamlit con muy poca intervención manual. El ciclo de desarrollo parecía ajustado y predecible, que es justo lo que se busca cuando se quiere construir rápidamente.
Este proyecto es intencionadamente un MVP. Se necesitarían más iteraciones y refuerzos para que estuviera listo para la producción. Dicho esto, la estructura central refleja fielmente el diseño de los sistemas de ingeniería de datos reales, lo que la convierte en una base sólida sobre la que construir.
Si estás interesado en ampliar este proyecto hacia una plataforma de datos más orientada a la producción, los siguientes componentes son los siguientes pasos lógicos, pero se han excluido intencionadamente aquí para mantener el enfoque del alcance:
Estas herramientas son habituales en los sistemas de producción, pero excluirlas aquí permite que el proyecto siga siendo sencillo, local y fácil de entender, al tiempo que refleja los patrones reales de la ingeniería de datos.
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
10 min
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali



