
Cours
Travailler avec l'API OpenAI
3 h
143.1K
Dans ce tutoriel, nous allons apprendre à créer un pipeline d'ingénierie de données de bout en bout à l'aide de GPT-5.2 Codex via l'extension VSCode. Au lieu de demander au modèle de tout construire en une seule fois, nous construirons le MVP couche par couche, en guidant l'agent étape par étape à travers la conception, la mise en œuvre et les tests.
Cette approche reflète la manière dont GPT-5.2 Codex fonctionne le mieux dans la pratique et correspond aux flux de travail réels en matière d'ingénierie des données.
Si vous souhaitez en savoir plus sur l'utilisation de l'écosystème OpenAI, je vous recommande de consulter le cours cours « Travailler avec l'API OpenAI ».
GPT 5.2 Codex est le dernière génération des modèles de codage agentique d'OpenAI, conçus pour les flux de travail de génie logiciel dans le monde réel. Il s'appuie sur les récentes améliorations apportées à la compréhension du contexte à long terme, aux refactorisations et migrations à grande échelle, à l'utilisation fiable des outils et à la prise en charge native avancée de Windows.
Ces améliorations le rendent particulièrement efficace pour les travaux de développement de bout en bout de longue durée dans des IDE tels que VSCode. Au cours des derniers mois, l'extension OpenAI Codex VSCode d' s s'est considérablement améliorée et est désormais en concurrence directe avec Claude Code pour le développement complexe piloté par des agents.
Nous commencerons par créer un nouveau dépôt GitHub pour notre MVP d'ingénierie des données.
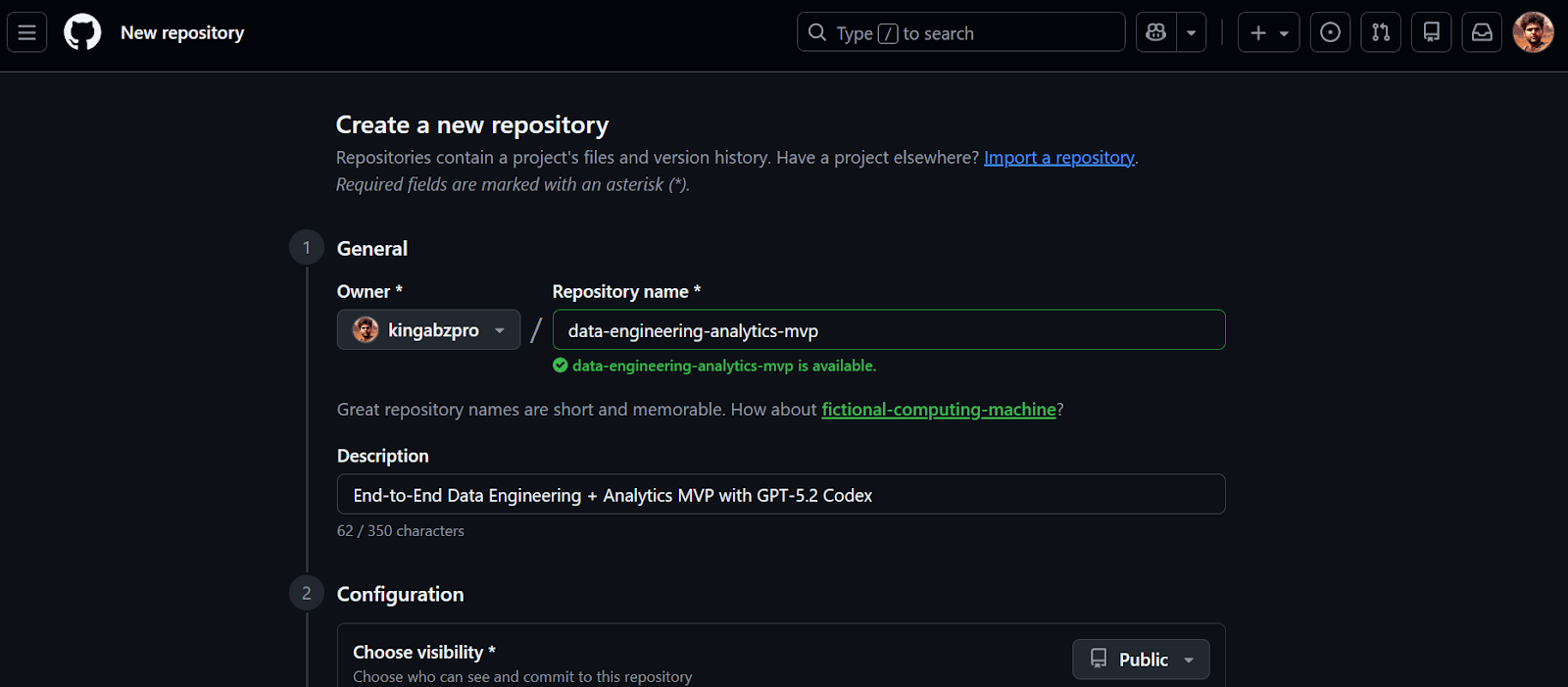
Une fois le référentiel créé, veuillez copier l'URL du référentiel. Nous utiliserons cette URL à l'étape suivante pour cloner le projet localement.
Avant de commencer, veuillez vous assurer que Visual Studio Code est installé et que vous disposez d'un compte chatGPT Plus actif. Les plans Free et Go ne permettent pas d'accéder aux modèles Codex dans l'extension VSCode.
1. Veuillez cloner le référentiel en utilisant l'URL que vous avez précédemment copiée.
2. Veuillez changer de répertoire pour accéder au référentiel et lancer VSCode.
git clone https://github.com/kingabzpro/data-engineering-analytics-mvp.git
cd data-engineering-analytics-mvp
code .3. Veuillez vous rendre dans Extensions (Ctrl + Maj + X), rechercher OpenAI Codex et l'installer. Cela ne devrait prendre que quelques secondes.
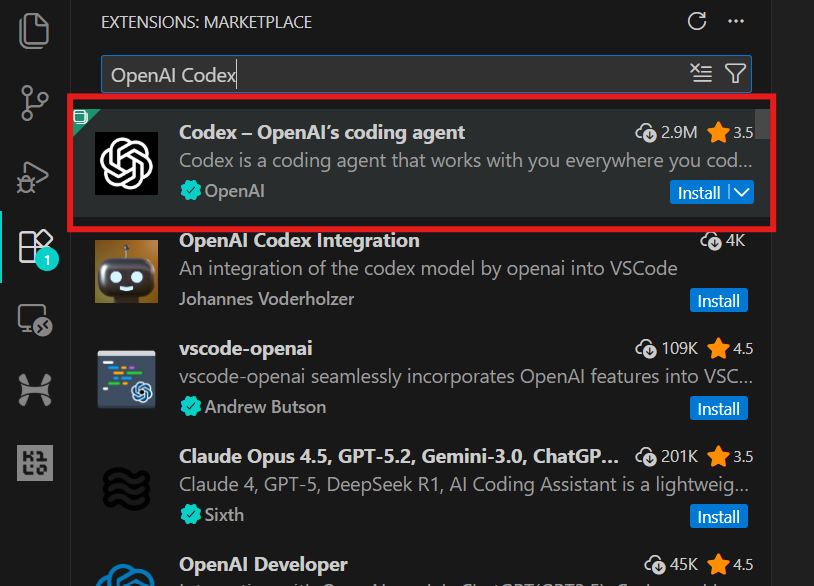
4. Veuillez cliquer sur l'icône OpenAI dans le panneau de gauche pour lancer l'extension Codex. Vous serez invité à vous connecter à l'aide de votre compte chatGPT ou d'un compte API. Veuillez sélectionner le compte chatGPT, ce qui vous redirigera vers le navigateur afin d'approuver l'accès. Une fois approuvé, veuillez revenir à VSCode, et Codex sera prêt à être utilisé.
Ce projet est délibérément conçu comme un produit minimum viable (MVP). L'objectif n'est pas de construire une plateforme de données de niveau production, mais de créer une tranche complète d'ingénierie des données de bout en bout qui démontre comment les systèmes d'analyse réels sont structurés.
Dans ce MVP, nous construisons un pipeline analytique simple mais fiable qui :
raw_events).fct_events).Le flux complet se présente comme suit :
CSV file
↓
raw_events (raw ingestion, 1:1 with source)
↓
fct_events (typed, deduplicated, transformed)
↓
metrics (daily count, 7-day rolling avg, top category)
↓
Streamlit UI (local dashboard)Dans cette étape, nous utilisons GPT-5.2 Codex pour générer la structure initiale du projet. L'objectif n'est pas encore de développer des fonctionnalités, mais de créer une base propre et fonctionnelle que nous développerons progressivement.
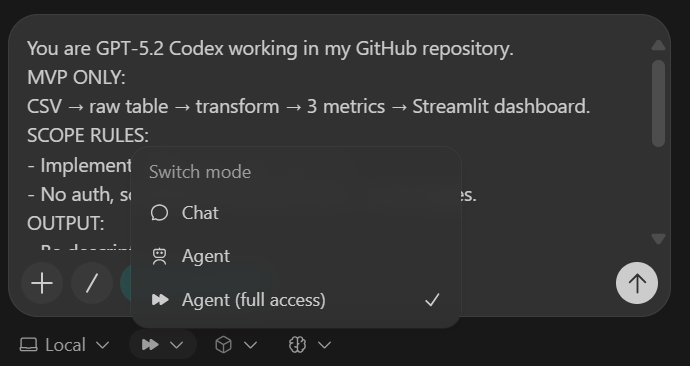
Afin de garantir la cohérence de Codex, nous utilisons un petit bloc de contrôle appelé Codex Harness. Ce harnais est placé en haut de chaque invite et garantit que Codex reste dans le champ d'application du MVP, produit des résultats cohérents et effectue des modifications claires et vérifiables.
Harnais Codex (à insérer dans chaque tâche) :
You are GPT-5.2 Codex working in my GitHub repository.
MVP ONLY:
CSV → raw table → transform → 3 metrics → Streamlit dashboard.
SCOPE RULES:
- Implement ONLY what this task asks.
- No auth, schedulers, cloud services, or extra pages.
OUTPUT:
- Be descriptive.
- After changes include:
1) What changed
2) Files touched
3) How to run locally
4) Quick verification step
- Commit after each major step with a clear message.Avant d'écrire tout code, Codex est explicitement chargé d'utiliser la recherche sur le Web pour vérifier les dernières versions compatibles avec Python 3.11 de toutes les dépendances. Cela permet d'éviter l'installation de paquets obsolètes ou incompatibles.
IMPORTANT: USE WEB SEARCH FIRST
TASK 1 (SCAFFOLD):
Use Python 3.11 + uv + DuckDB + Streamlit + Pydantic + pytest.
Create repo structure:
- backend/
- db.py
- ingest.py
- pipeline.py
- models.py
- sql/
- app/
- app.py
- data/
- sample.csv
- tests/
Add:
1) data/sample.csv (~50 rows) with columns:
event_time, user_id, event_name, category, amount
2) DuckDB schema for raw_events
3) a command to ingest sample.csv and print row count
4) pyproject.toml for uv
5) README with exact local run steps
Stop after scaffolding. Commit.La tâche d'échafaudage crée :
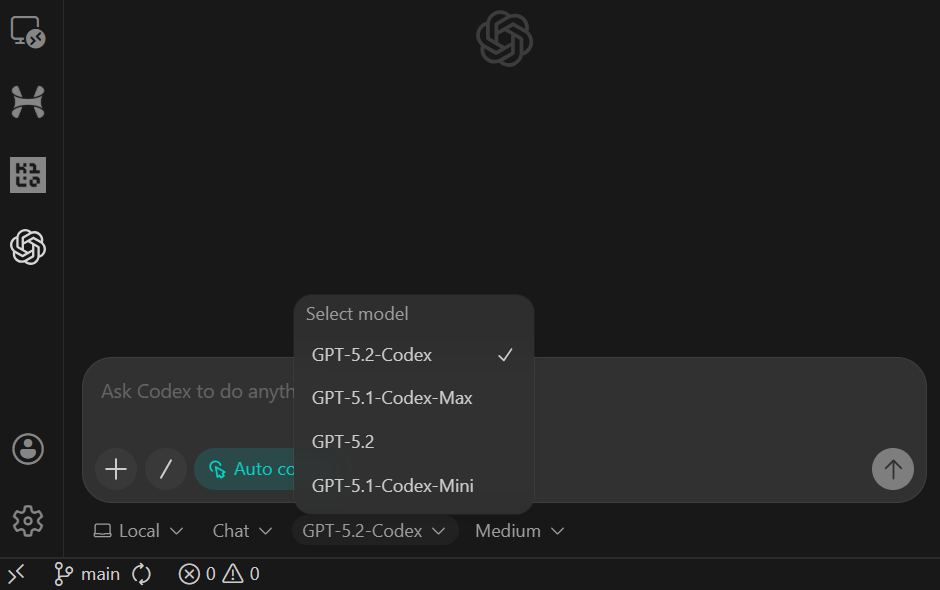
sample.csvraw_events DuckDBpyproject.toml, et README fonctionnelsAprès avoir collé l'invite, veuillez basculer le modèle vers Agent (Accès complet) et confirmer que GPT-5.2 Codex est sélectionné (il s'agit du paramètre par défaut).
Une fois la tâche terminée, vous constaterez que tous les dossiers et fichiers ont été créés automatiquement.
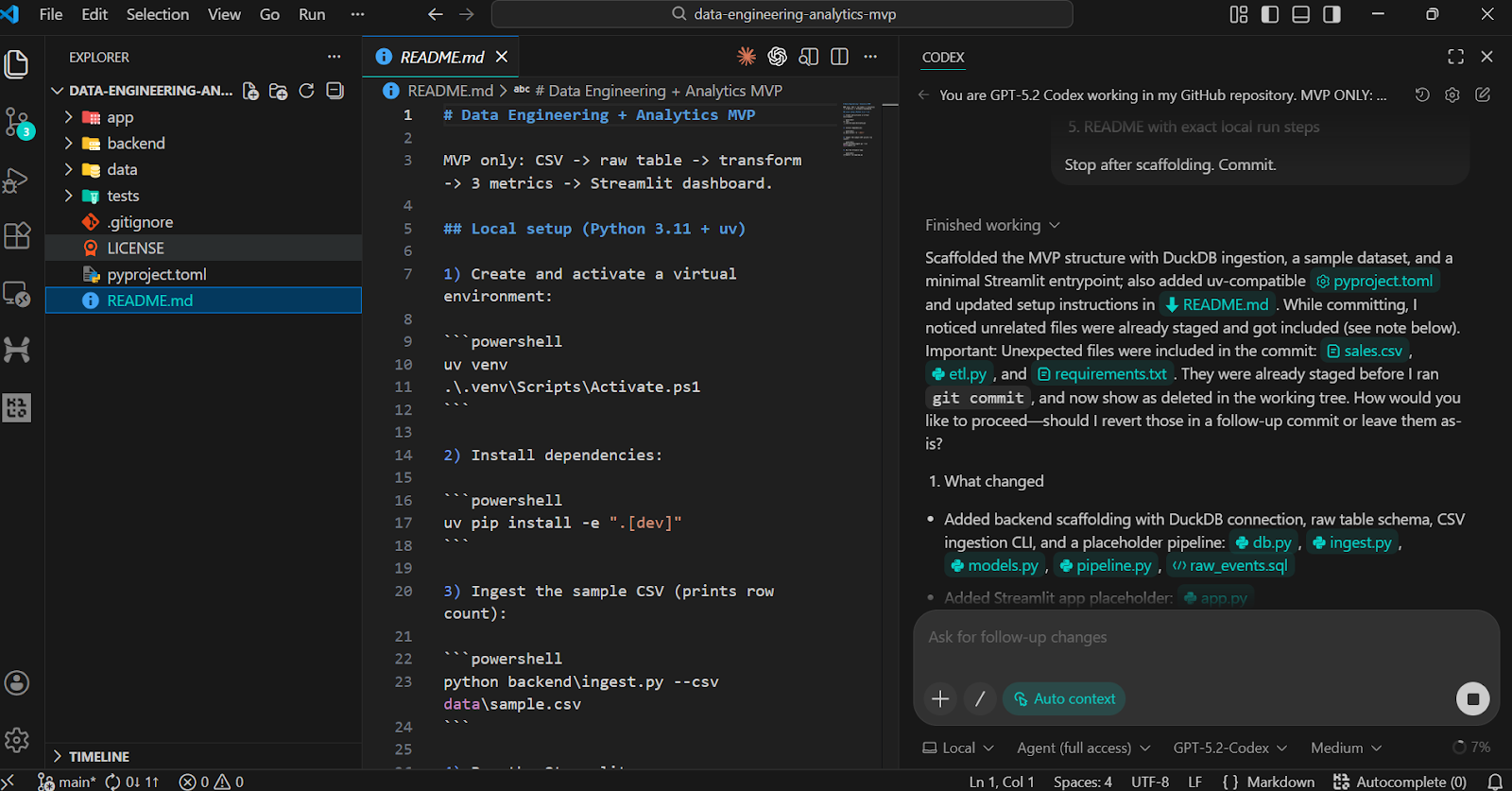
Pour valider le framework, veuillez demander à Codex d'exécuter les étapes d'installation et de vérification localement.
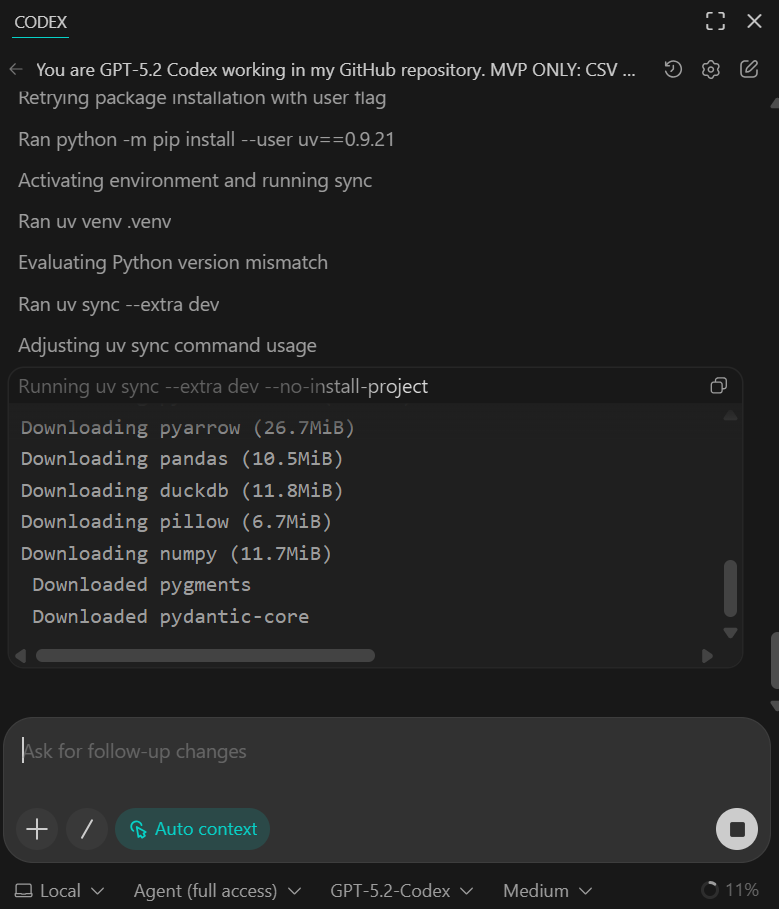
Vous devriez voir toutes les dépendances installées avec succès et le script de vérification rapide confirmant que 50 lignes ont été ingérées à partir de l'ensemble de données d'exemple.
À ce stade, l'échantillon de données est volontairement restreint. Dans les étapes suivantes, nous le remplacerons par un ensemble de données plus vaste et plus réaliste.
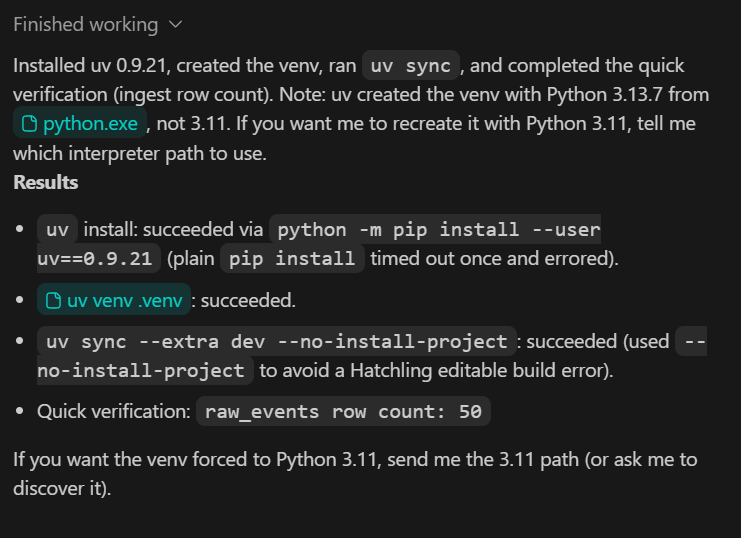
Enfin, si vous consultez https://chatGPT.com/codex/settings/usage, vous constaterez que la majeure partie de votre quota d'utilisation reste disponible, ce qui signifie que vous pouvez continuer à développer et à itérer ce projet en toute tranquillité, voire l'étendre vers un pipeline plus prêt pour la production si nécessaire.
Au cours de cette étape, nous nous assurons que le processus d'ingestion est idempotent, ce qui signifie qu'il peut être réexécuté en toute sécurité sans créer de données en double. Il s'agit d'une exigence fondamentale en ingénierie des données, car les tâches d'ingestion doivent souvent être réessayées ou réexécutées.
TASK 2 (IDEMPOTENT INGEST):
Make CSV ingestion idempotent.
- Rerunning ingest must not duplicate rows
- Validate required columns
- Validate event_time parseable and amount numeric
Add pytest:
- ingest twice → row count unchanged
Update README verification section.
Commit.Ce que cette étape permet d'atteindre :
Une fois la tâche terminée, vous pouvez consulter l'historique Git dans VSCode et constater que l'agent IA valide automatiquement les modifications après la mise à jour majeure. Cela permet d'obtenir un historique de développement clair et traçable.
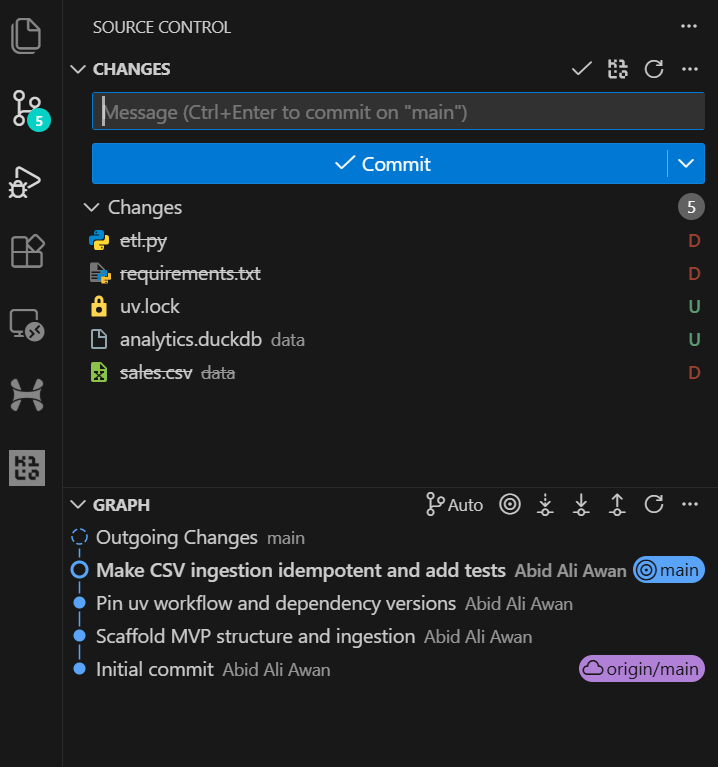
Nous avons demandé à GPT-5.2 Codex d'exécuter la suite de tests dans le cadre de cette tâche. En conséquence, les tests ont été exécutés avec succès et tous les contrôles ont été validés.
Dans cette étape, nous présentons la couche de transformation du pipeline. Les transformations sont mises en œuvre à l'aide de DuckDB SQL, ce qui nous permet de convertir les données brutes ingérées en un tableau de faits propre et prêt à être analysé.
TASK 3 (TRANSFORM SQL):
Create backend/sql/010_fct_events.sql:
- typed columns
- deterministic dedupe
Execute transform from backend/pipeline.py.
Add sanity checks to README:
- raw_events count
- fct_events count
Commit.Ce que cette étape permet d'atteindre :
raw_events en fct_events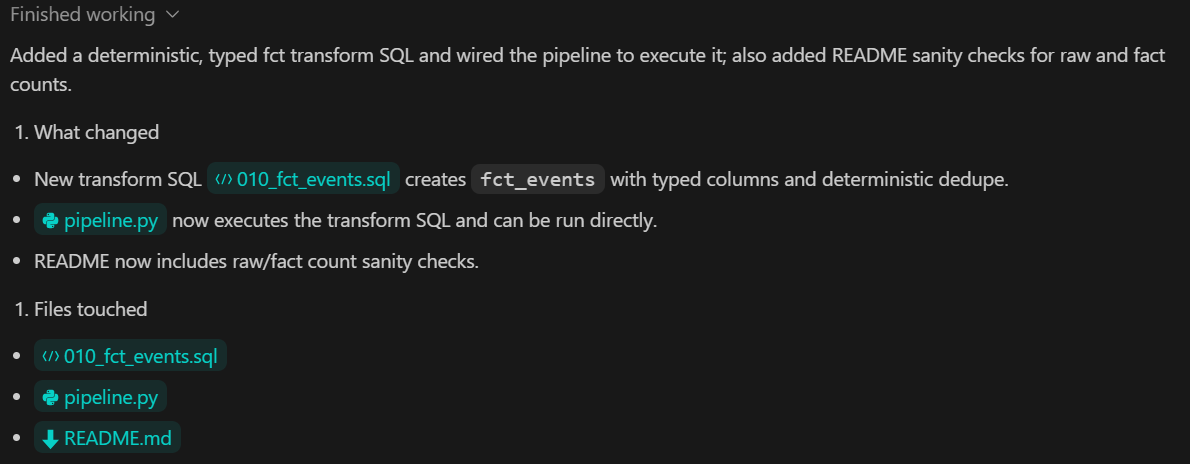
Au cours de cette étape, nous intégrons la couche métrique, qui est chargée de calculer les résultats analytiques à partir des données transformées. Les métriques sont dérivées à l'aide de DuckDB SQL et exposées au reste du système via une interface Python typée.
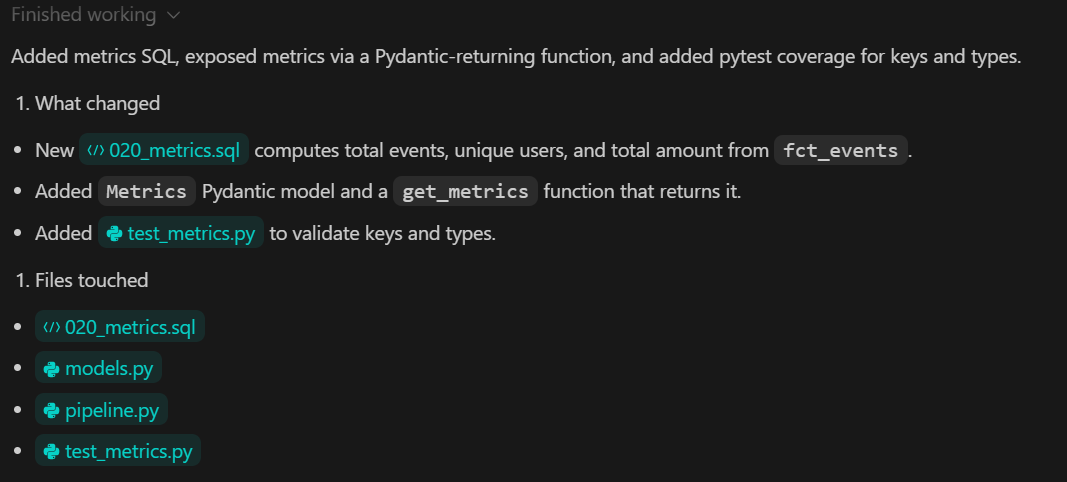
TASK 4 (METRICS):
Create backend/sql/020_metrics.sql.
Expose metrics via a Python function returning a Pydantic model.
Add pytest validating:
- keys exist
- types correct
Commit.Ce que cette étape permet d'atteindre :
Dans cette étape, nous créons le tableau de bord analytique local à l'aide de Streamlit. Le tableau de bord est uniquement destiné à la visualisation. Il ne calcule pas de mesures et ne transforme pas les données. Toutes les valeurs sont lues à partir de la couche de métriques créée à l'étape précédente.
TASK 5 (STREAMLIT UI):
Build app/app.py:
- 3 KPI cards
- line chart for daily_count
- UI calls backend metrics function
Add a minimal smoke test.
Commit.Une fois la tâche terminée, Codex fournit des instructions pour reconstruire la base de données DuckDB et exécuter l'ensemble du pipeline de données. Pour cette étape, nous utilisons une nouvelle base de données alimentée par un ensemble de données plus volumineux.
python backend\ingest.py --csv data\sample.csv
python backend\pipeline.pyAprès avoir exécuté l'ingestion, la sortie confirme le nombre d'événements bruts chargés dans DuckDB :
raw_events row count: 3738Une fois le pipeline terminé, veuillez démarrer l'application Streamlit :
streamlit run app\app.pyVous pouvez accéder au tableau de bord en ouvrant le http://localhost:8501 dans votre navigateur.
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.18.10:8501Si une erreur apparaît lors du premier chargement du tableau de bord, cela est normal lors des premières itérations. Veuillez copier le message d'erreur et le transmettre à GPT-5.2 Codex.
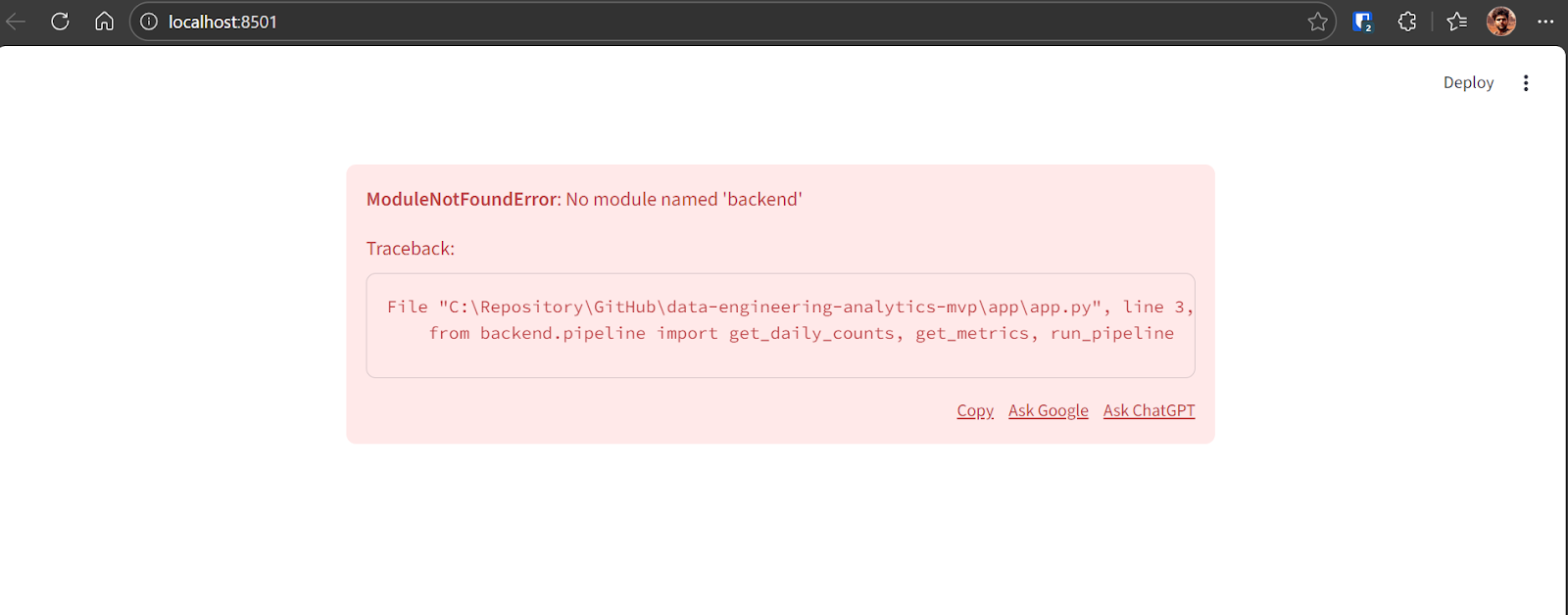
Codex identifiera le problème et appliquera la correction nécessaire. Après la correction, l'application s'exécute correctement et affiche :
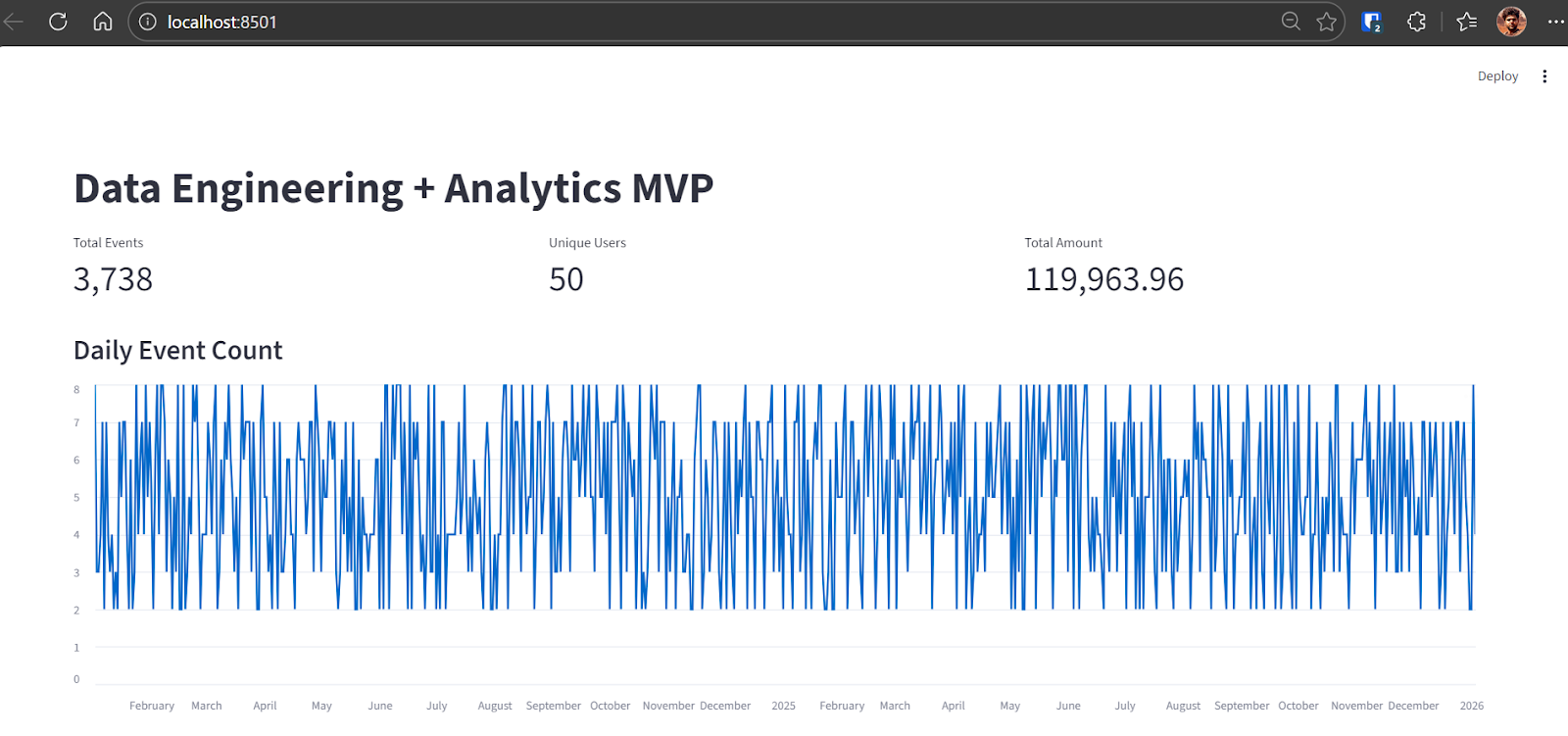
À ce stade, le pipeline MVP de bout en bout est achevé et pleinement opérationnel.
Dans cette dernière étape, nous nous concentrons sur la vérification et la fiabilité. L'objectif est de fournir une commande unique qui garantit le bon fonctionnement de l'ensemble du pipeline, depuis l'ingestion jusqu'aux métriques et aux tests.
TASK 6 (VERIFY):
Add a verify command that:
- rebuilds DB from scratch
- ingests sample.csv
- runs transforms
- runs pytest
Document as "Local Demo" and "Verify" in README.
Commit.Ce que cette étape permet d'atteindre :
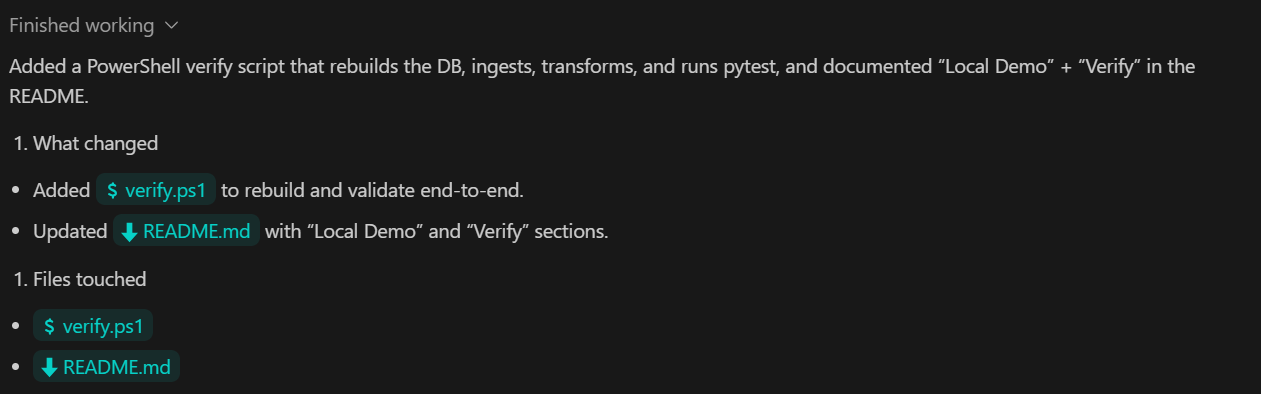
Nous avons demandé au Codex de mettre à jour le fichier README, de valider toutes les modifications et de les transférer vers le référentiel distant GitHub.
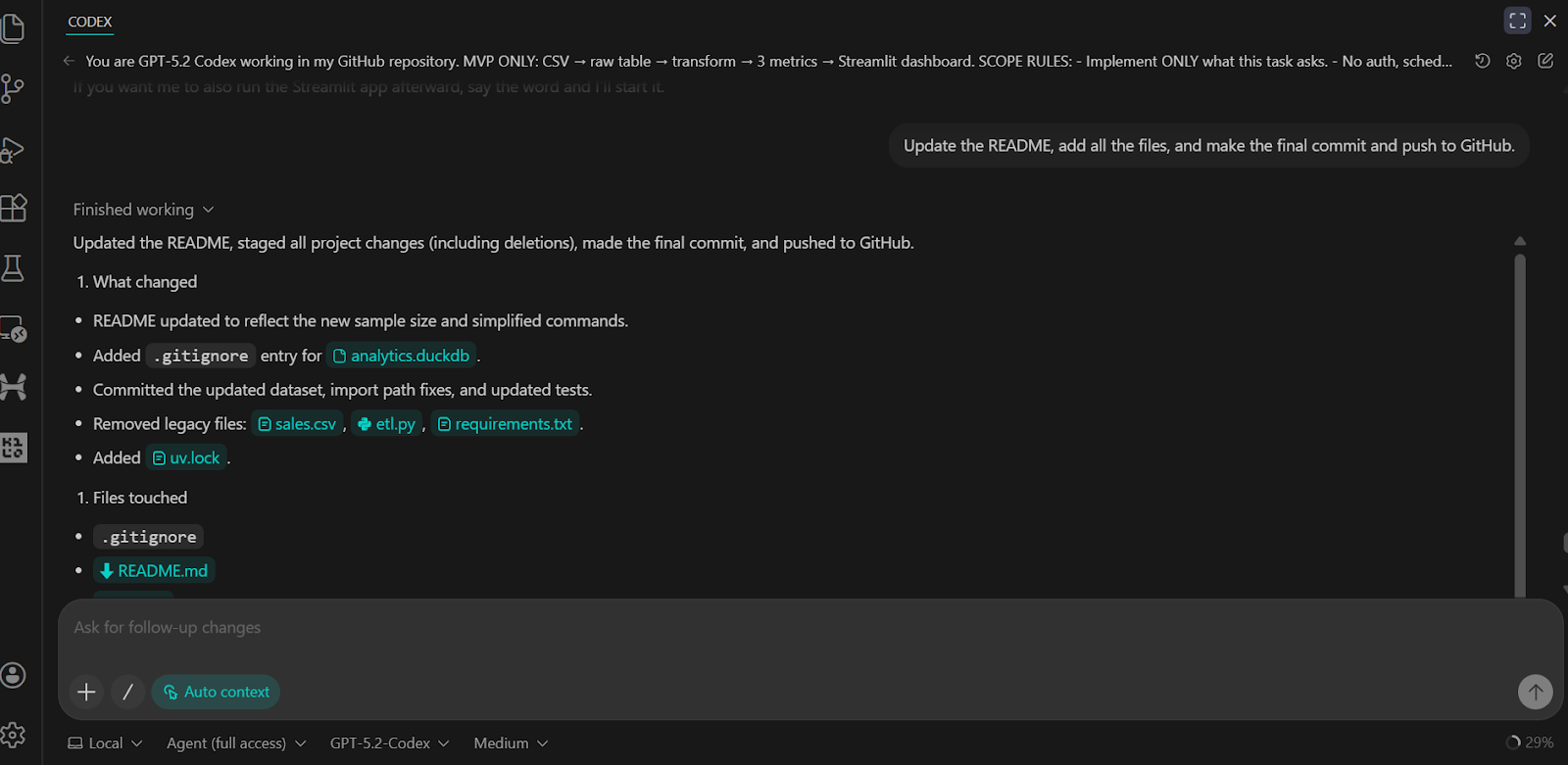
Le résultat est un référentiel GitHub complet et bien structuré qui comprend tous les scripts, les tests, la logique backend et des instructions claires pour exécuter et vérifier le projet.
Source : kingabzpro/data-engineering-analytics-mvp
J'ai utilisé Codex via l'interface CLI et dans VSCode de temps à autre par le passé, mais les récentes mises à jour avec GPT-5.2 Codex ont apporté une différence notable. Le modèle est nettement plus performant pour créer des systèmes complets, résoudre les problèmes de débogage et utiliser des outils tels que MCP et des outils internes. Cela démontre également une compréhension beaucoup plus approfondie du code existant, ce qui rend le développement itératif beaucoup plus efficace.
Du début à la fin, il m'a fallu moins de trente minutes pour mettre en place, déboguer et exécuter l'intégralité de ce MVP. Codex a géré la configuration du référentiel, la gestion des dépendances, l'ingestion des données, les transformations SQL, les tests et le tableau de bord Streamlit avec une intervention manuelle minimale. Le cycle de développement semblait rigoureux et prévisible, ce qui correspond exactement à ce que l'on recherche lorsqu'on souhaite construire rapidement.
Ce projet est délibérément un MVP. Il nécessiterait des itérations supplémentaires et un renforcement pour être prêt à être mis en production. Cela dit, la structure de base reflète étroitement la manière dont les systèmes d'ingénierie des données réels sont conçus, ce qui en fait une base solide sur laquelle s'appuyer.
Si vous envisagez d'étendre ce projet vers une plateforme de données davantage axée sur la production, les composants suivants constituent des étapes naturelles, mais ont été intentionnellement exclus ici afin de maintenir le champ d'application ciblé :
Ces outils sont courants dans les systèmes de production, mais leur exclusion ici permet de conserver un projet simple, local et facile à appréhender, tout en reflétant les modèles réels d'ingénierie des données.
Meilleurs cours DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Matt Crabtree
Tutoriel
DataCamp Team
Tutoriel
Aditya Sharma
