
Kurs
Arbeiten mit der OpenAI-API
3 Std.
143.1K
In diesem Tutorial zeigen wir dir, wie du mit GPT-5.2 Codex über die VSCode-Erweiterung eine komplette Datenverarbeitungs-Pipeline aufbaust. Anstatt vom Modell zu verlangen, alles auf einmal zu erstellen, bauen wir das MVP Schicht für Schicht auf und führen den Agenten Schritt für Schritt durch Design, Implementierung und Tests.
Dieser Ansatz zeigt, wie GPT-5.2 Codex in der Praxis am besten funktioniert, und spiegelt echte Datenverarbeitungsabläufe wider.
Wenn du mehr über die Arbeit mit dem OpenAI-Ökosystem erfahren möchtest, empfehle ich dir den Kurs „Arbeiten mit der OpenAI-API“. Kurs „Arbeiten mit der OpenAI-API“.
GPT 5.2 Codex ist die neueste Version der agentenbasierten Codierungsmodelle von OpenAI, die für echte Softwareentwicklungs-Workflows gemacht sind. Es baut auf den neuesten Verbesserungen beim Verständnis langer Kontexte, großen Refactorings und Migrationen, zuverlässiger Tool-Nutzung und starker nativer Windows-Unterstützung auf.
Diese Verbesserungen machen es besonders gut für lang andauernde, durchgängige Entwicklungsarbeiten in IDEs wie VSCode. In den letzten Monaten hat sich die VSCode-Erweiterung „ “ von OpenAI Codex echt verbessert und macht jetzt der Erweiterung „Claude Code“ von Claude Code direkt Konkurrenz . Claude Code bei der komplexen, agentenbasierten Entwicklung.
Zuerst machen wir ein neues GitHub-Repository für unser Data-Engineering-MVP.
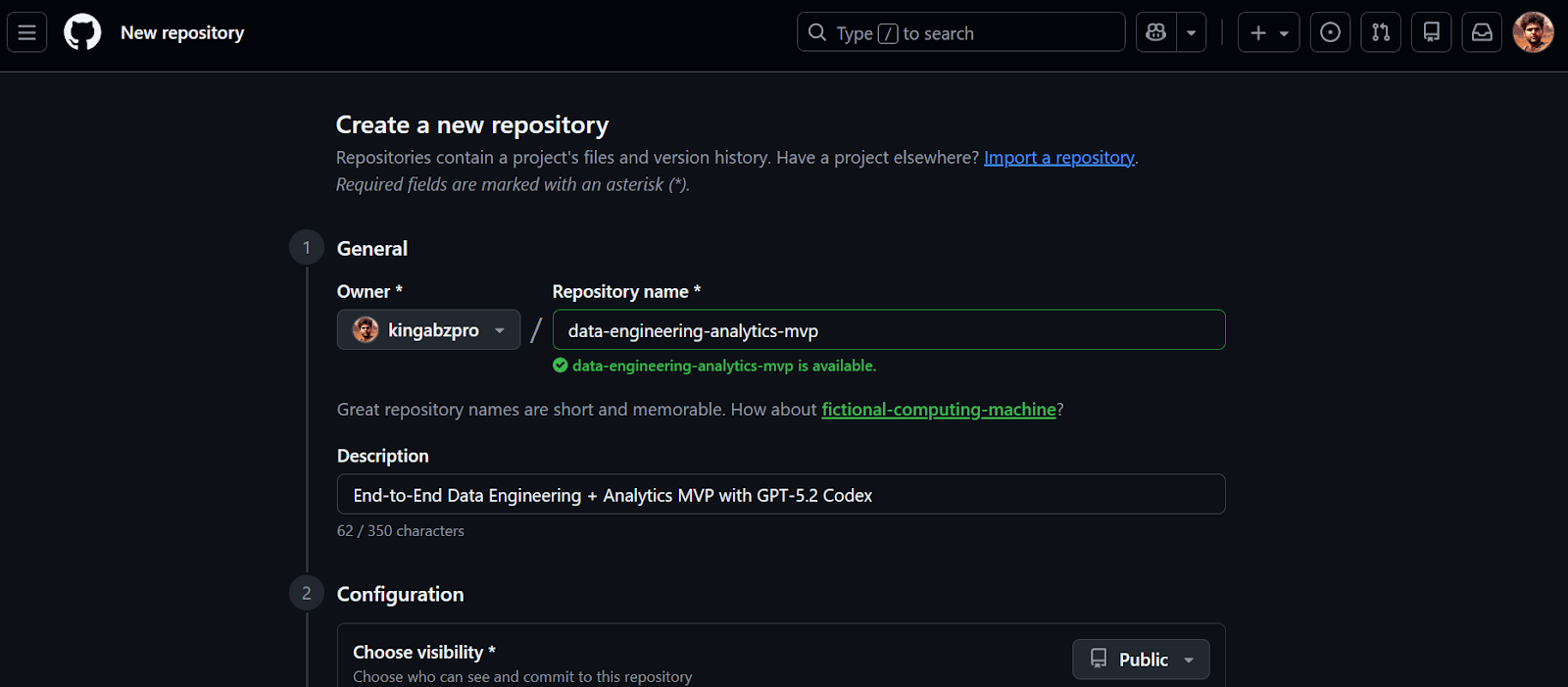
Sobald das Repository erstellt ist, kopierst du die Repository-URL. Wir werden diese URL im nächsten Schritt nutzen, um das Projekt lokal zu klonen.
Bevor du loslegst, stell sicher, dass du Visual Studio Code installiert hast und ein aktives chatGPT Plus-Konto hast. Die kostenlosen Tarife und der Go-Tarif bieten keinen Zugriff auf Codex-Modelle in der VSCode-Erweiterung.
1. Klon das Repository mit der URL, die du vorhin kopiert hast.
2. Wechsle ins Verzeichnis des Repositorys und starte VSCode.
git clone https://github.com/kingabzpro/data-engineering-analytics-mvp.git
cd data-engineering-analytics-mvp
code .3. Geh zu „Erweiterungen“ (Strg + Umschalt + X), such nach „OpenAI Codex“ und installier es. Das dauert nur ein paar Sekunden.
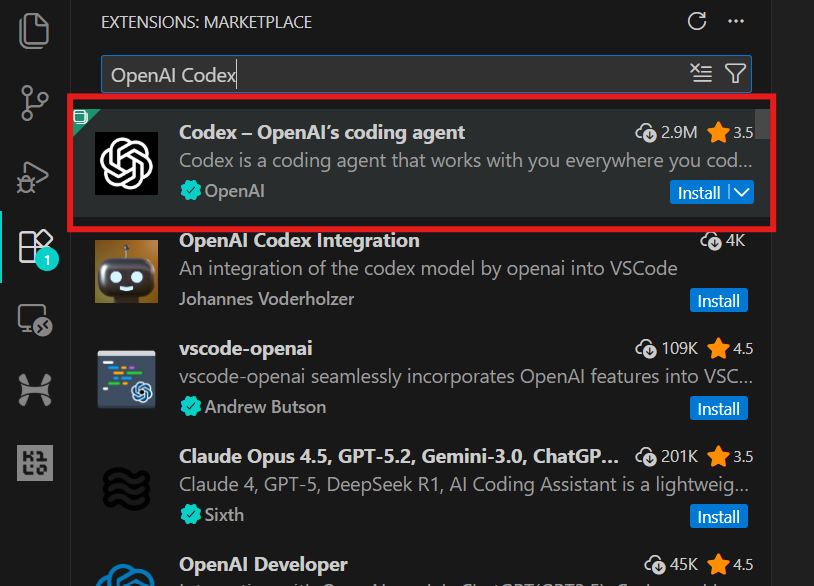
4. Klick einfach auf das OpenAI-Symbol im linken Bereich, um die Codex-Erweiterung zu starten. Du wirst aufgefordert, dich mit deinem chatGPT-Konto oder einem API-Konto anzumelden. Wähle das chatGPT-Konto aus, dann wirst du zum Browser weitergeleitet, um den Zugriff zu genehmigen. Sobald du das genehmigt hast, geh einfach zurück zu VSCode, und Codex ist einsatzbereit.
Dieses Projekt ist bewusst als Minimum Viable Product (MVP) angelegt. Das Ziel ist nicht, eine Datenplattform für die Produktion zu bauen, sondern einen kompletten End-to-End-Datenengineering-Ausschnitt zu erstellen, der zeigt, wie echte Analysesysteme aufgebaut sind.
In diesem MVP bauen wir eine einfache, aber zuverlässige Analyse-Pipeline, die:
raw_events)fct_events)Der ganze Ablauf geht so:
CSV file
↓
raw_events (raw ingestion, 1:1 with source)
↓
fct_events (typed, deduplicated, transformed)
↓
metrics (daily count, 7-day rolling avg, top category)
↓
Streamlit UI (local dashboard)In diesem Schritt nutzen wir GPT-5.2 Codex, um die erste Struktur des Projekts zu erstellen. Das Ziel ist noch nicht, Funktionen zu entwickeln, sondern eine saubere, lauffähige Basis zu schaffen, die wir Schritt für Schritt ausbauen werden.
Damit Codex immer auf Kurs bleibt, nutzen wir einen kleinen Kontrollblock namens Codex Harness. Dieser Harness wird oben in jede Eingabeaufforderung eingefügt und sorgt dafür, dass Codex im MVP-Bereich bleibt, konsistente Ergebnisse liefert und saubere, überprüfbare Änderungen durchführt.
Codex-Gurtzeug (in jede Aufgabe einfügen):
You are GPT-5.2 Codex working in my GitHub repository.
MVP ONLY:
CSV → raw table → transform → 3 metrics → Streamlit dashboard.
SCOPE RULES:
- Implement ONLY what this task asks.
- No auth, schedulers, cloud services, or extra pages.
OUTPUT:
- Be descriptive.
- After changes include:
1) What changed
2) Files touched
3) How to run locally
4) Quick verification step
- Commit after each major step with a clear message.Bevor Codex irgendwelchen Code schreibt, wird es extra angewiesen, die Websuche zu nutzen, um die neuesten Python 3.11-kompatiblen Versionen aller Abhängigkeiten zu checken. So vermeidest du, dass du veraltete oder nicht kompatible Pakete installierst.
IMPORTANT: USE WEB SEARCH FIRST
TASK 1 (SCAFFOLD):
Use Python 3.11 + uv + DuckDB + Streamlit + Pydantic + pytest.
Create repo structure:
- backend/
- db.py
- ingest.py
- pipeline.py
- models.py
- sql/
- app/
- app.py
- data/
- sample.csv
- tests/
Add:
1) data/sample.csv (~50 rows) with columns:
event_time, user_id, event_name, category, amount
2) DuckDB schema for raw_events
3) a command to ingest sample.csv and print row count
4) pyproject.toml for uv
5) README with exact local run steps
Stop after scaffolding. Commit.Die Gerüstaufgabe erstellt:
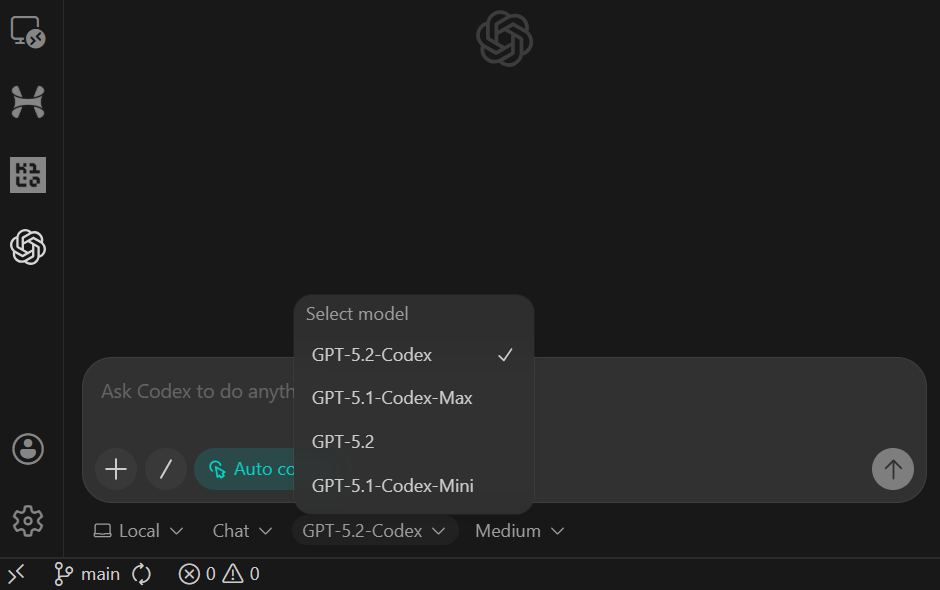
sample.csv “raw_events -Tabellepyproject.toml “ und „README“Nachdem du die Eingabeaufforderung eingefügt hast, stell das Modell auf „Agent (Vollzugriff)“ um und check, ob GPT-5.2 Codex ausgewählt ist (das ist die Standardeinstellung).
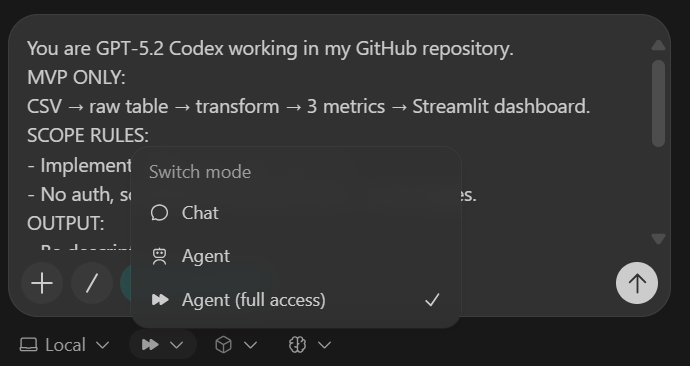
Sobald die Aufgabe erledigt ist, wirst du sehen, dass alle Ordner und Dateien automatisch erstellt wurden.
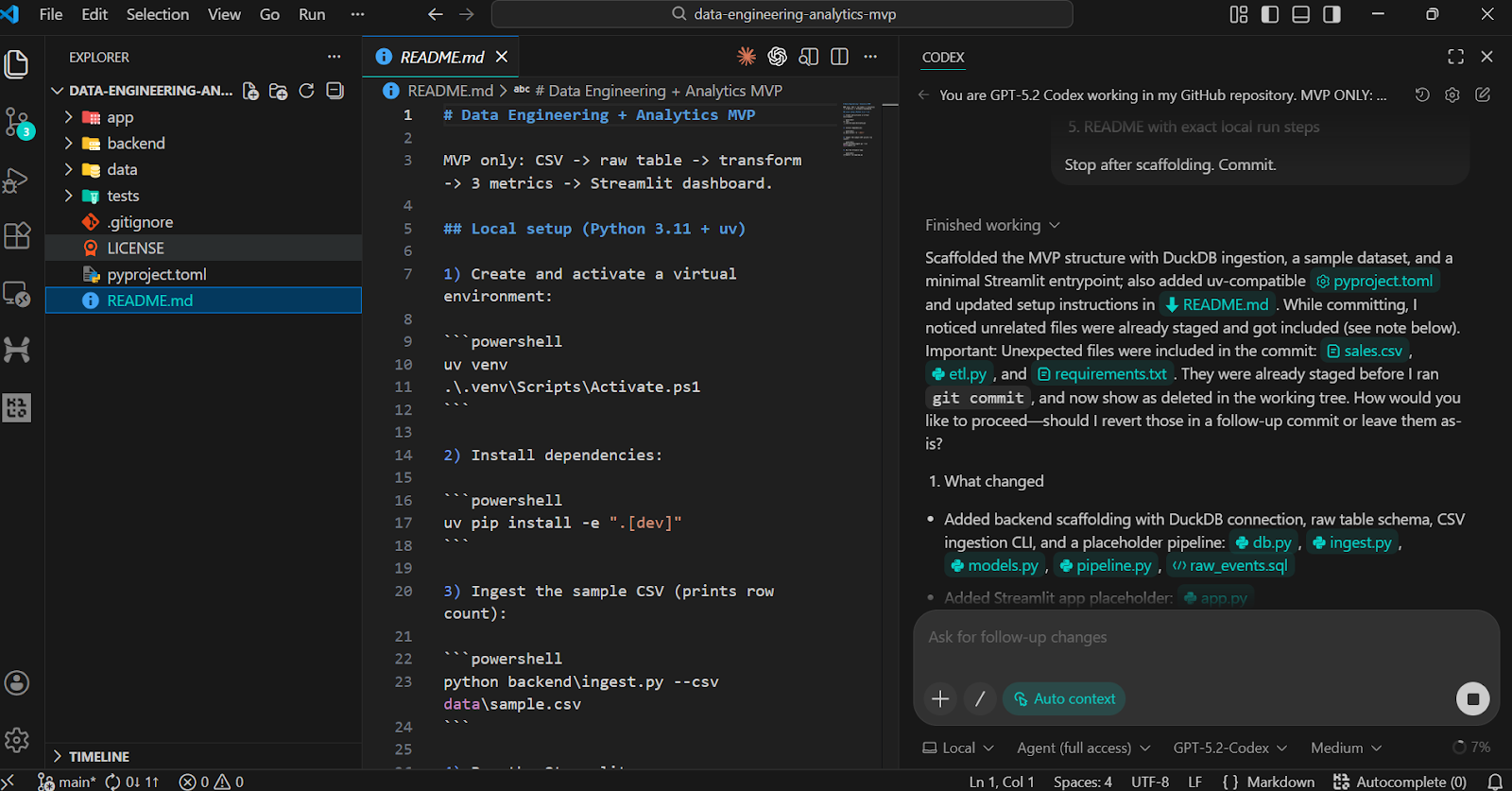
Um das Gerüst zu überprüfen, frag Codex, ob er die Installations- und Überprüfungsschritte lokal machen kann.
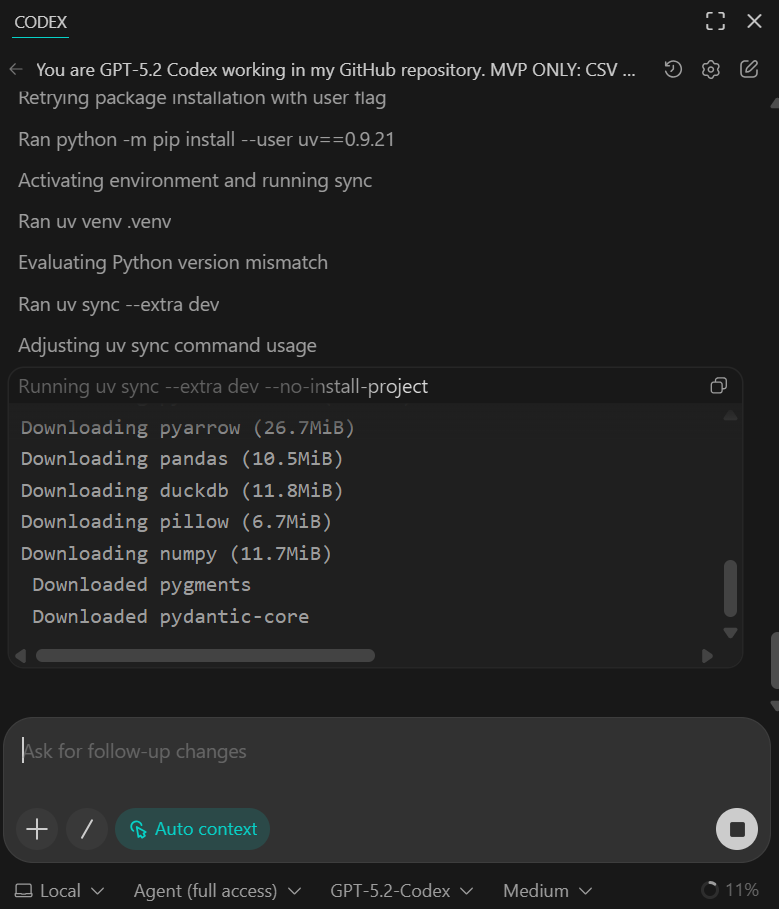
Du solltest sehen, dass alle Abhängigkeiten erfolgreich installiert wurden und das Schnellüberprüfungsskript bestätigt, dass 50 Zeilen aus dem Beispieldatensatz übernommen wurden.
Im Moment sind die Beispieldaten absichtlich klein gehalten. In den nächsten Schritten werden wir ihn durch einen größeren, realistischeren Datensatz ersetzen.
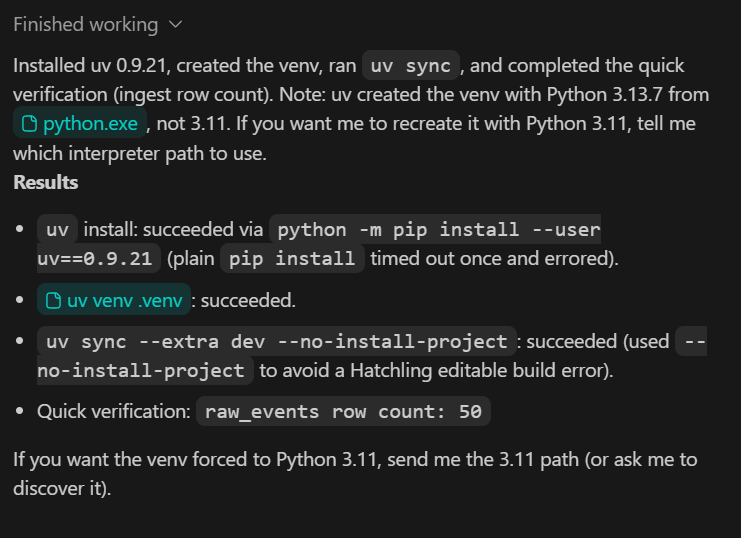
Wenn du unter „https://chatGPT.com/codex/settings/usage“ nachschaust, wirst du sehen, dass du noch die meiste deiner Nutzungsquote übrig hast. Das heißt, du kannst ganz entspannt weiter an diesem Projekt arbeiten und es sogar zu einer produktionsreifen Pipeline ausbauen, wenn du das brauchst.
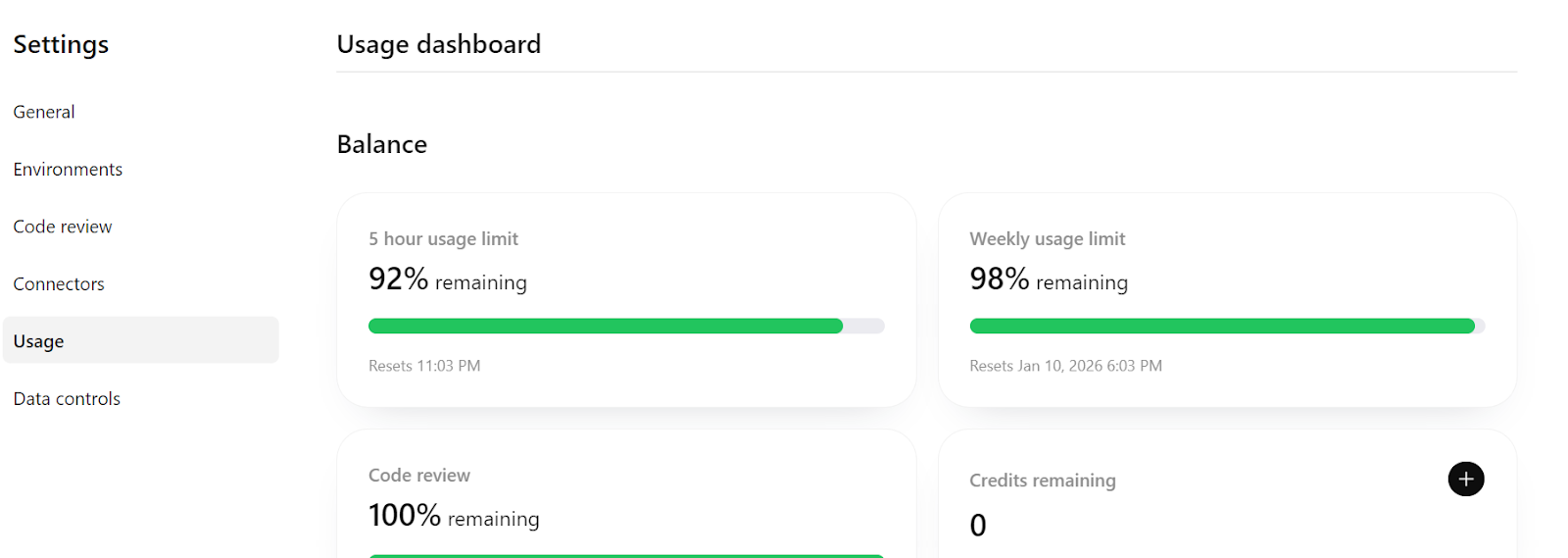
In diesem Schritt stellen wir sicher, dass der Erfassungsprozess idempotent ist, d. h. er kann sicher wiederholt werden, ohne dass doppelte Daten entstehen. Das ist echt wichtig im Bereich Data Engineering, weil man oft Daten-Import-Jobs nochmal versuchen oder ausführen muss.
TASK 2 (IDEMPOTENT INGEST):
Make CSV ingestion idempotent.
- Rerunning ingest must not duplicate rows
- Validate required columns
- Validate event_time parseable and amount numeric
Add pytest:
- ingest twice → row count unchanged
Update README verification section.
Commit.Was dieser Schritt bringt:
Sobald die Aufgabe erledigt ist, kannst du dir den Git-Verlauf in VSCode anschauen und sehen, dass der KI-Agent die Änderungen nach dem großen Update automatisch festschreibt. Das sorgt für eine übersichtliche und nachvollziehbare Entwicklungsgeschichte.
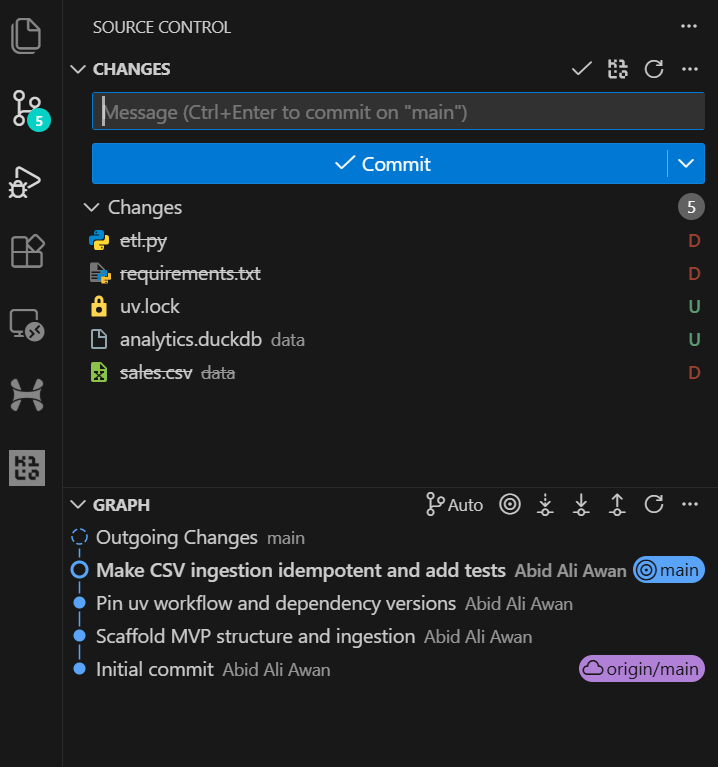
Wir haben GPT-5.2 Codex gebeten, die Testsuite als Teil dieser Aufgabe durchzuführen. Die Tests sind also erfolgreich gelaufen und alle Prüfungen haben geklappt.
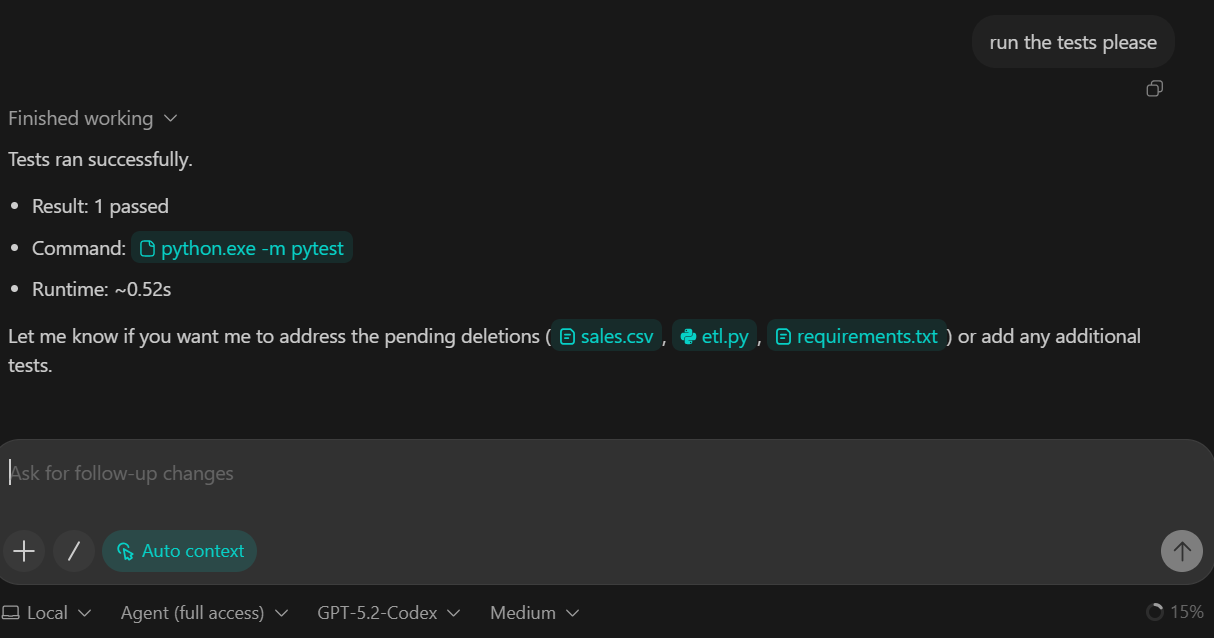
In diesem Schritt stellen wir die Transformationsebene der Pipeline vor. Transformationen werden mit DuckDB SQL, womit wir die rohen Daten in eine saubere, für Analysen geeignete Faktentabelle umwandeln können.
TASK 3 (TRANSFORM SQL):
Create backend/sql/010_fct_events.sql:
- typed columns
- deterministic dedupe
Execute transform from backend/pipeline.py.
Add sanity checks to README:
- raw_events count
- fct_events count
Commit.Was dieser Schritt bringt:
raw_events “ in fct_events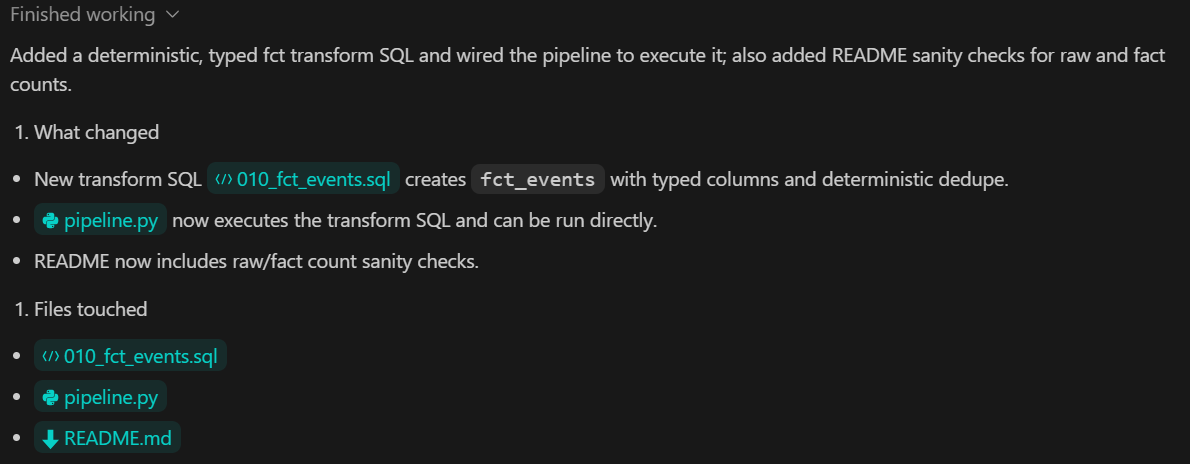
In diesem Schritt fügen wir die Metrik-Ebene hinzu, die dafür zuständig ist, analytische Ergebnisse aus den transformierten Daten zu berechnen. Die Metriken werden mit DuckDB SQL abgeleitet und über eine typisierte Python-Schnittstelle dem Rest des Systems zur Verfügung gestellt.
TASK 4 (METRICS):
Create backend/sql/020_metrics.sql.
Expose metrics via a Python function returning a Pydantic model.
Add pytest validating:
- keys exist
- types correct
Commit.Was dieser Schritt bringt:
In diesem Schritt erstellen wir das lokale Analyse-Dashboard mit Streamlit. Das Dashboard ist nur für die Visualisierung zuständig. Es berechnet keine Metriken und wandelt keine Daten um. Alle Werte werden aus der im vorherigen Schritt erstellten Metrikschicht gelesen.
TASK 5 (STREAMLIT UI):
Build app/app.py:
- 3 KPI cards
- line chart for daily_count
- UI calls backend metrics function
Add a minimal smoke test.
Commit.Sobald die Aufgabe erledigt ist, gibt Codex dir Anweisungen, wie du die DuckDB-Datenbank neu aufsetzen und die komplette Datenpipeline ausführen kannst. Für diesen Schritt nehmen wir eine neue Datenbank, die mit einem größeren Datensatz gefüllt ist.
python backend\ingest.py --csv data\sample.csv
python backend\pipeline.pyNach dem Ausführen der Erfassung zeigt die Ausgabe, wie viele Rohdatenereignisse in DuckDB geladen wurden:
raw_events row count: 3738Sobald die Pipeline fertig ist, starte die Streamlit-App:
streamlit run app\app.pyDu kannst das Dashboard aufrufen, indem du die http://localhost:8501 in deinem Browser.
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.18.10:8501Wenn beim ersten Laden des Dashboards ein Fehler auftritt, ist das in frühen Versionen normal. Kopiere die Fehlermeldung und gib sie an GPT-5.2 Codex weiter.
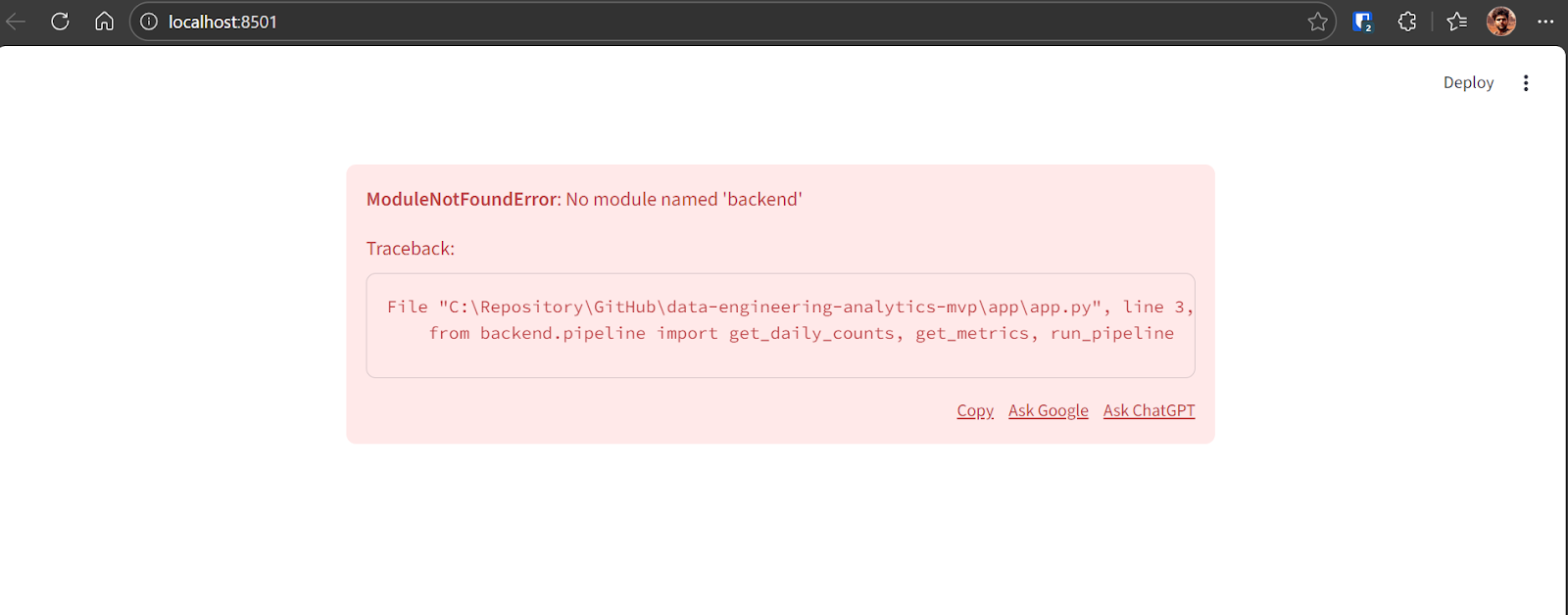
Codex wird das Problem finden und die nötige Lösung machen. Nach der Korrektur läuft die Anwendung einwandfrei und zeigt Folgendes an:
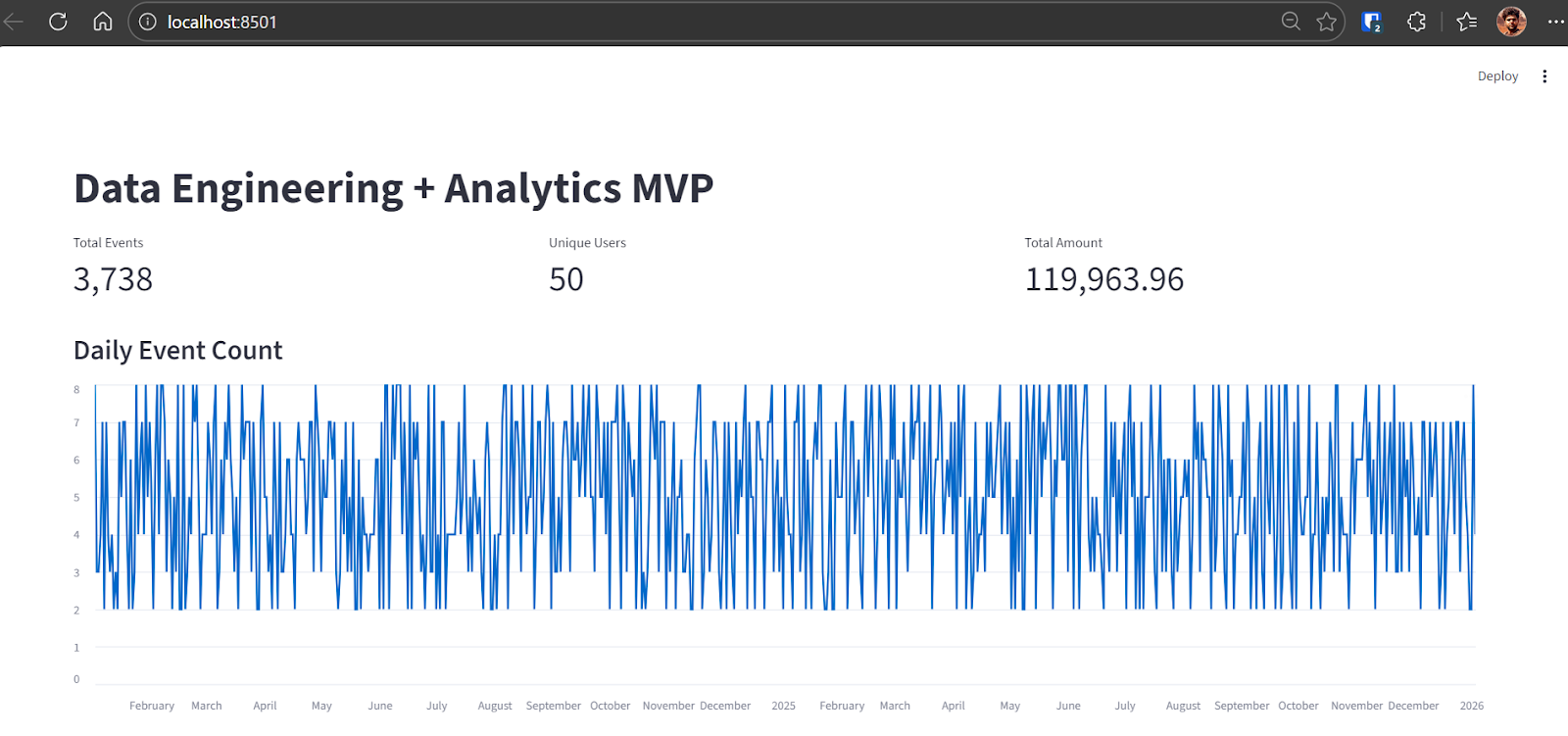
Jetzt ist die End-to-End-MVP-Pipeline fertig und läuft voll.
In diesem letzten Schritt geht's um die Überprüfung und Zuverlässigkeit. Das Ziel ist, einen einzigen Befehl zu haben, der zeigt, dass die ganze Pipeline von der Datenaufnahme bis hin zu Metriken und Tests richtig läuft.
TASK 6 (VERIFY):
Add a verify command that:
- rebuilds DB from scratch
- ingests sample.csv
- runs transforms
- runs pytest
Document as "Local Demo" and "Verify" in README.
Commit.Was dieser Schritt bringt:
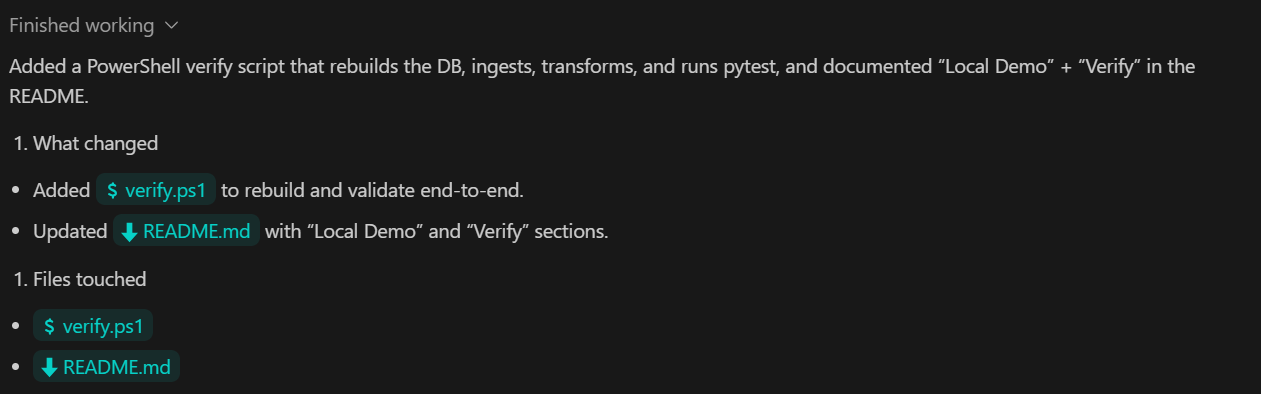
Wir haben den Codex gebeten, die README-Datei zu aktualisieren, alle Änderungen zu übernehmen und sie ins GitHub-Remote-Repository hochzuladen.
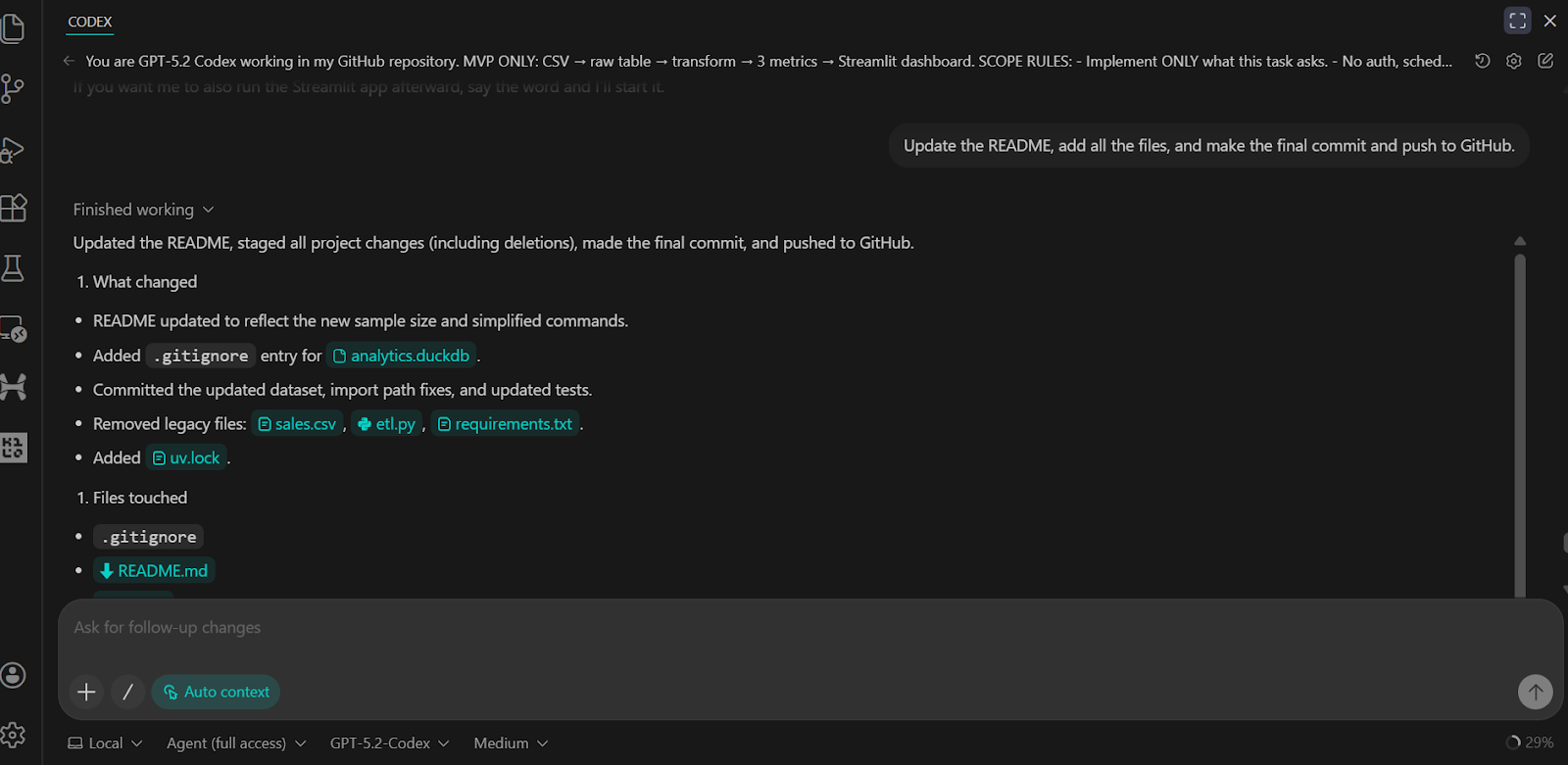
Das Ergebnis ist ein komplettes und gut strukturiertes GitHub-Repository, das alle Skripte, Tests, Backend-Logik und klare Anweisungen zum Ausführen und Überprüfen des Projekts enthält.
Quelle: kingabzpro/data-engineering-analytics-mvp
Ich hab Codex schon öfter über die CLI und in VSCode benutzt, aber die neuesten Updates mit GPT-5.2 Codex haben echt einen Unterschied gemacht. Das Modell ist echt besser darin, komplette Systeme aufzubauen, Probleme zu beheben und mit Tools wie MCP und internen Tools zu arbeiten. Es zeigt auch, dass man den bestehenden Code viel besser versteht, was die iterative Entwicklung echt effizienter macht.
Von Anfang bis Ende habe ich weniger als 30 Minuten gebraucht, um dieses ganze MVP aufzubauen, zu debuggen und komplett durchzuführen. Codex hat die Einrichtung des Repositorys, das Abhängigkeitsmanagement, die Datenerfassung, SQL-Transformationen, Tests und das Streamlit-Dashboard mit echt wenig manuellem Aufwand erledigt. Der Entwicklungszyklus war straff und vorhersehbar, was genau das ist, was man braucht, wenn man schnell etwas aufbauen will.
Dieses Projekt ist bewusst ein MVP. Es braucht noch ein paar weitere Durchläufe und Verbesserungen, bis es für die Produktion bereit ist. Trotzdem spiegelt die Kernstruktur ziemlich genau wider, wie echte Datenverarbeitungssysteme aufgebaut sind, was sie zu einer soliden Basis macht, auf der man aufbauen kann.
Wenn du daran interessiert bist, dieses Projekt zu einer produktionsorientierteren Datenplattform auszubauen, sind die folgenden Komponenten die logischen nächsten Schritte, wurden hier aber bewusst weggelassen, um den Umfang überschaubar zu halten:
Diese Tools sind in Produktionssystemen weit verbreitet, aber wenn man sie hier weglässt, bleibt das Projekt einfach, lokal und leicht verständlich, während es trotzdem die echten Datenverarbeitungsmuster widerspiegelt.
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Aditya Sharma
Tutorial
DataCamp Team