
Curso
Trabalhar com a API da OpenAI
3 h
141.9K
Neste tutorial, vamos aprender a criar um pipeline completo de engenharia de dados usando o GPT-5.2 Codex através da extensão VSCode. Em vez de pedir ao modelo para construir tudo de uma vez, vamos construir o MVP camada por camada, guiando o agente passo a passo pelo design, implementação e testes.
Essa abordagem mostra como o GPT-5.2 Codex funciona melhor na prática e reflete os fluxos de trabalho reais de engenharia de dados.
Se você quiser saber mais sobre como trabalhar com o ecossistema OpenAI, recomendo dar uma olhada no curso curso Trabalhando com a API OpenAI.
O GPT 5.2 Codex é o última geração dos modelos de codificação de agentes da OpenAI, criada para fluxos de trabalho de engenharia de software do mundo real. Ele se baseia em melhorias recentes na compreensão de contextos longos, grandes refatorações e migrações, uso confiável de ferramentas e forte suporte nativo ao Windows.
Essas melhorias tornam-no especialmente eficaz para trabalhos de desenvolvimento de longo prazo e de ponta a ponta dentro de IDEs, como o VSCode. Nos últimos meses, a extensão OpenAI Codex VSCode melhorou bastante e agora tá competindo direto com o Claude Code no desenvolvimento complexo e orientado por agentes.
Vamos começar criando um novo repositório GitHub para o nosso MVP de engenharia de dados.
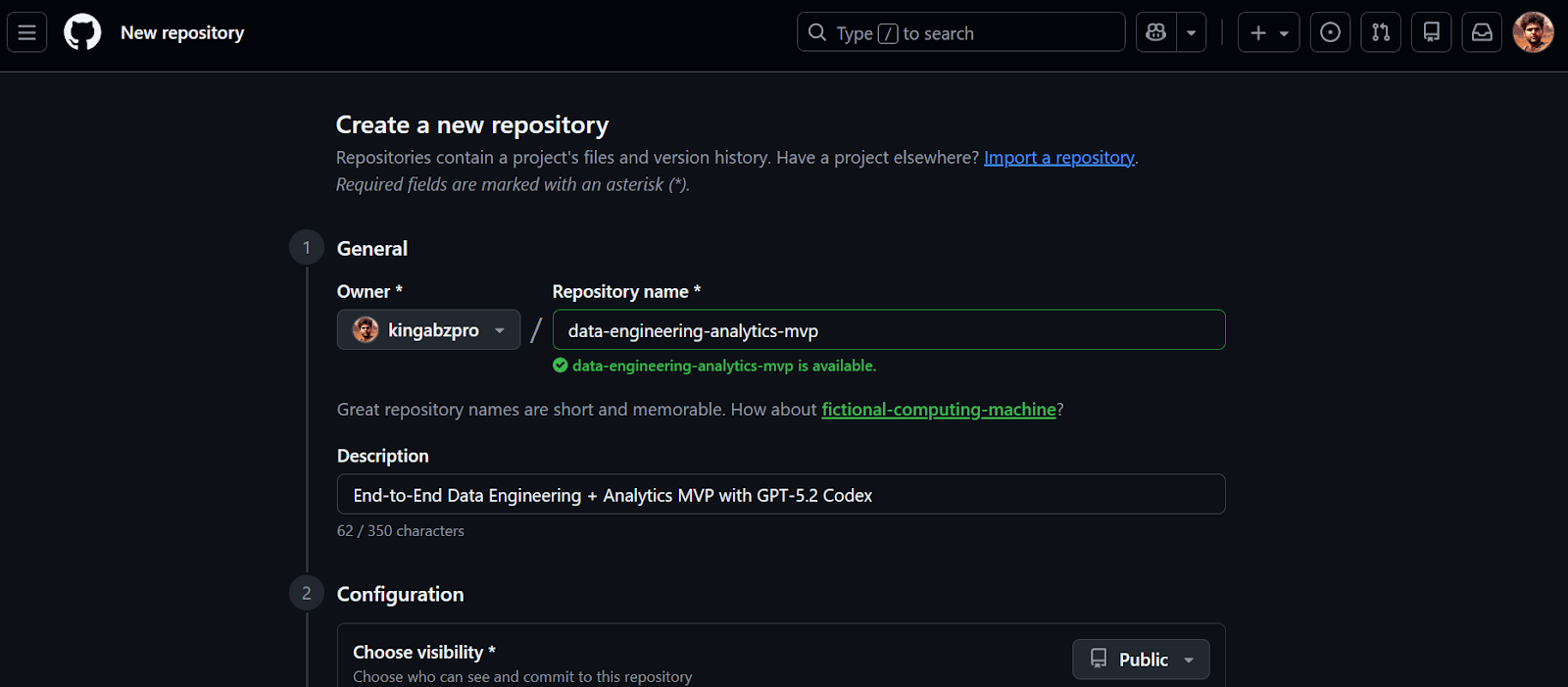
Depois de criar o repositório, copie o URL do repositório. Vamos usar essa URL na próxima etapa para clonar o projeto localmente.
Antes de começar, certifique-se de que você tem o Visual Studio Code instalado e uma conta ativa do chatGPT Plus. Os planos gratuito e Go não oferecem acesso aos modelos Codex na extensão VSCode.
1. Clone o repositório usando a URL que você copiou antes.
2. Mude o diretório para o repositório e abra o VSCode.
git clone https://github.com/kingabzpro/data-engineering-analytics-mvp.git
cd data-engineering-analytics-mvp
code .3. Vá para Extensões (Ctrl + Shift + X), procure por OpenAI Codex e instale-o. Isso deve levar só alguns segundos.
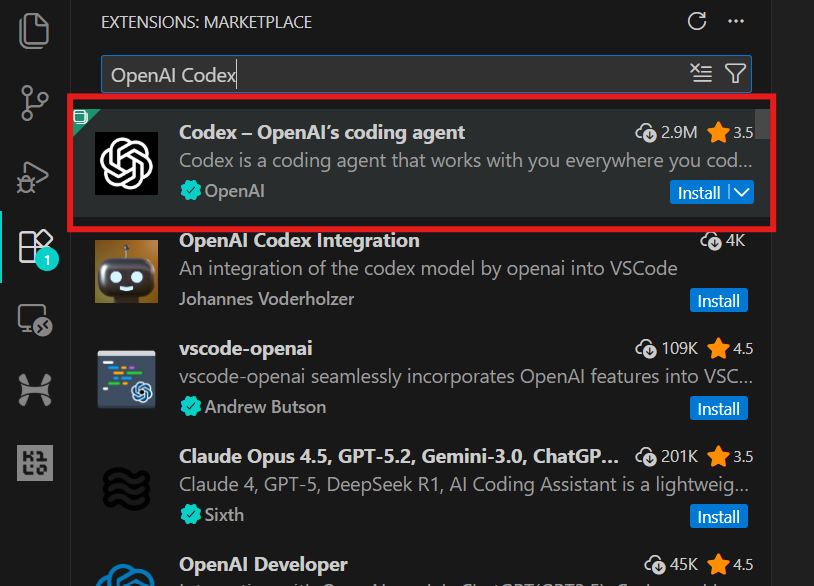
4. Clique no ícone OpenAI no painel esquerdo para abrir a extensão Codex. Você vai precisar fazer login usando sua conta chatGPT ou uma conta API. Escolha a conta chatGPT, que vai te redirecionar para o navegador para aprovar o acesso. Depois de aprovado, volte ao VSCode e o Codex estará pronto para ser usado.
Esse projeto foi feito de propósito como um Produto Mínimo Viável (MVP). O objetivo não é construir uma plataforma de dados de nível de produção, mas criar uma fatia completa e completa de engenharia de dados que mostre como os sistemas analíticos reais são estruturados.
Neste MVP, criamos um pipeline de análise simples, mas confiável, que:
raw_events)fct_events)O fluxo completo é assim:
CSV file
↓
raw_events (raw ingestion, 1:1 with source)
↓
fct_events (typed, deduplicated, transformed)
↓
metrics (daily count, 7-day rolling avg, top category)
↓
Streamlit UI (local dashboard)Nesta etapa, usamos o GPT-5.2 Codex para criar a estrutura inicial do projeto. O objetivo ainda não é criar recursos, mas sim uma base limpa e funcional que vamos expandir aos poucos.
Para manter o Codex focado, usamos um pequeno bloco de controle chamado Codex Harness. Esse arnês é colado no topo de cada prompt e garante que o Codex fique dentro do escopo do MVP, produza resultados consistentes e faça alterações limpas e revisáveis.
Código Harness (coloque em todas as tarefas):
You are GPT-5.2 Codex working in my GitHub repository.
MVP ONLY:
CSV → raw table → transform → 3 metrics → Streamlit dashboard.
SCOPE RULES:
- Implement ONLY what this task asks.
- No auth, schedulers, cloud services, or extra pages.
OUTPUT:
- Be descriptive.
- After changes include:
1) What changed
2) Files touched
3) How to run locally
4) Quick verification step
- Commit after each major step with a clear message.Antes de escrever qualquer código, o Codex recebe instruções explícitas para usar a pesquisa na web para verificar as versões mais recentes compatíveis com Python 3.11 de todas as dependências. Isso evita a instalação de pacotes desatualizados ou incompatíveis.
IMPORTANT: USE WEB SEARCH FIRST
TASK 1 (SCAFFOLD):
Use Python 3.11 + uv + DuckDB + Streamlit + Pydantic + pytest.
Create repo structure:
- backend/
- db.py
- ingest.py
- pipeline.py
- models.py
- sql/
- app/
- app.py
- data/
- sample.csv
- tests/
Add:
1) data/sample.csv (~50 rows) with columns:
event_time, user_id, event_name, category, amount
2) DuckDB schema for raw_events
3) a command to ingest sample.csv and print row count
4) pyproject.toml for uv
5) README with exact local run steps
Stop after scaffolding. Commit.A tarefa de andaime cria:
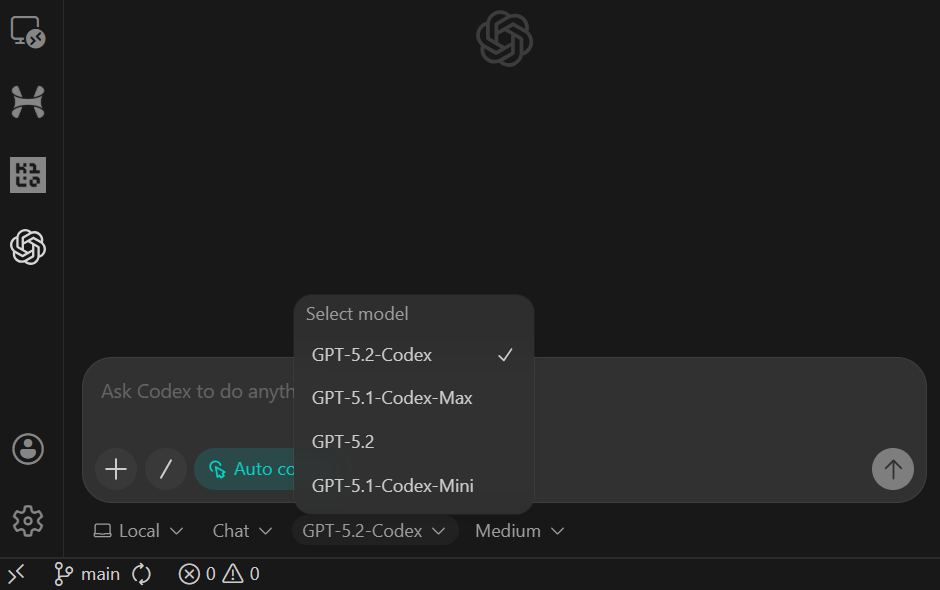
sample.csvraw_eventspyproject.toml e README funcionandoDepois de colar o prompt, mude o modelo para Agente (Acesso Total) e veja se o GPT-5.2 Codex está selecionado (essa é a configuração padrão).
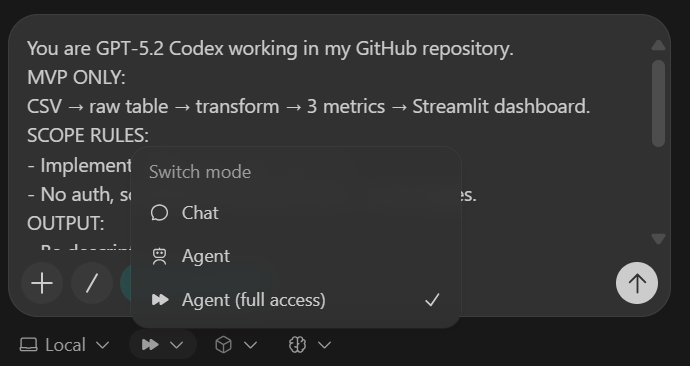
Quando a tarefa estiver pronta, você vai ver que todas as pastas e arquivos foram criados automaticamente.
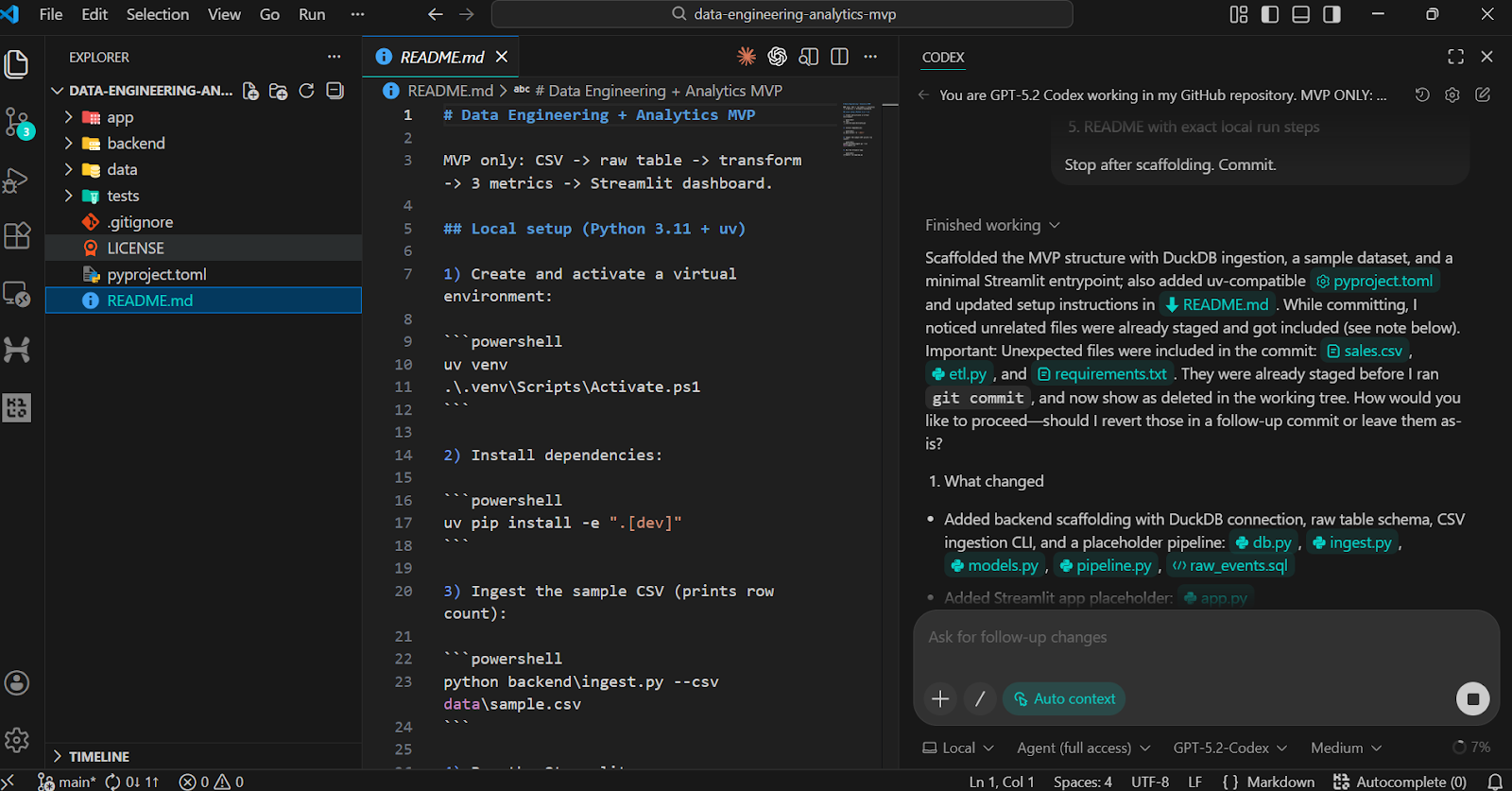
Para validar o scaffold, peça ao Codex para executar as etapas de instalação e verificação localmente.
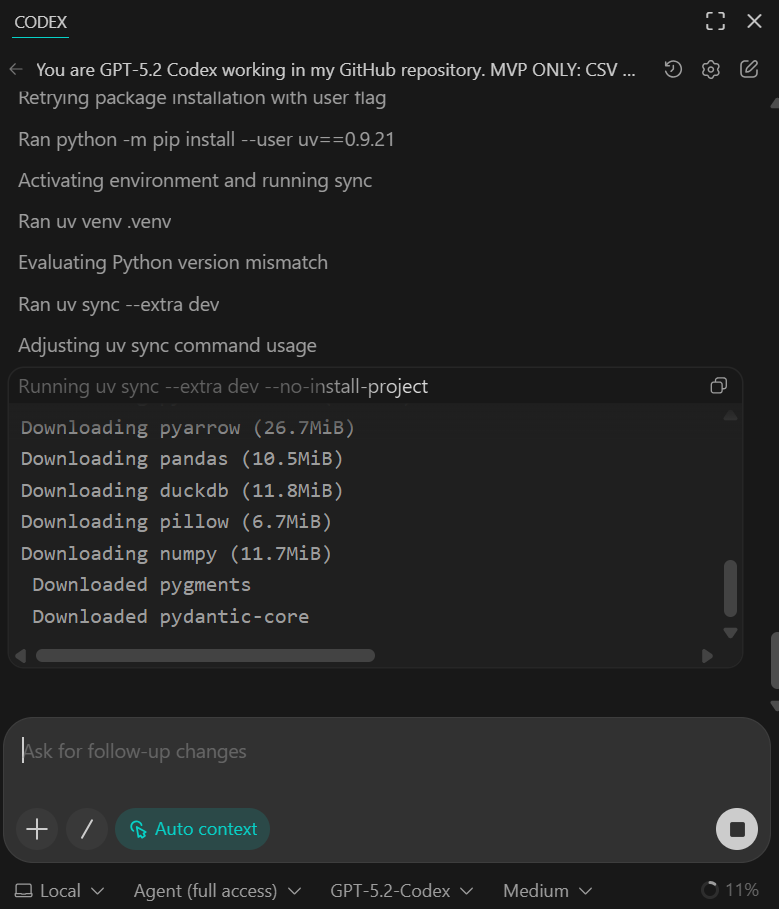
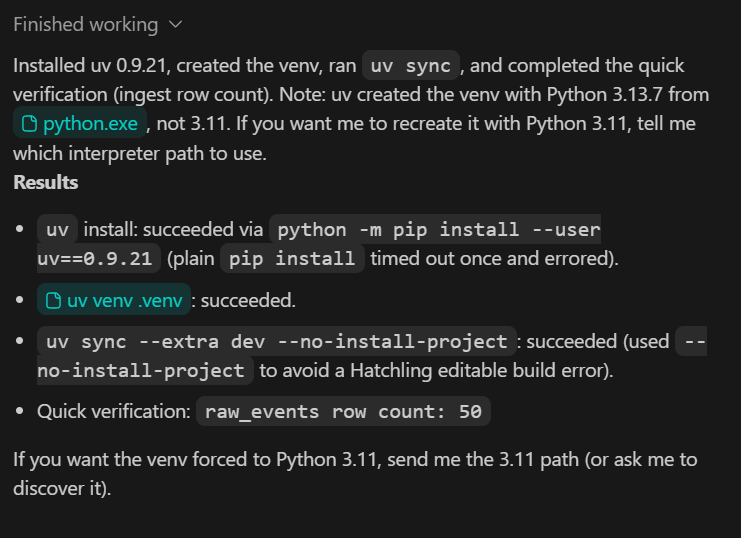
Você deve ver todas as dependências instaladas com sucesso e o script de verificação rápida confirmando que 50 linhas foram inseridas a partir do conjunto de dados de amostra.
Nesta fase, os dados da amostra são intencionalmente pequenos. Nas etapas seguintes, vamos trocar isso por um conjunto de dados maior e mais realista.
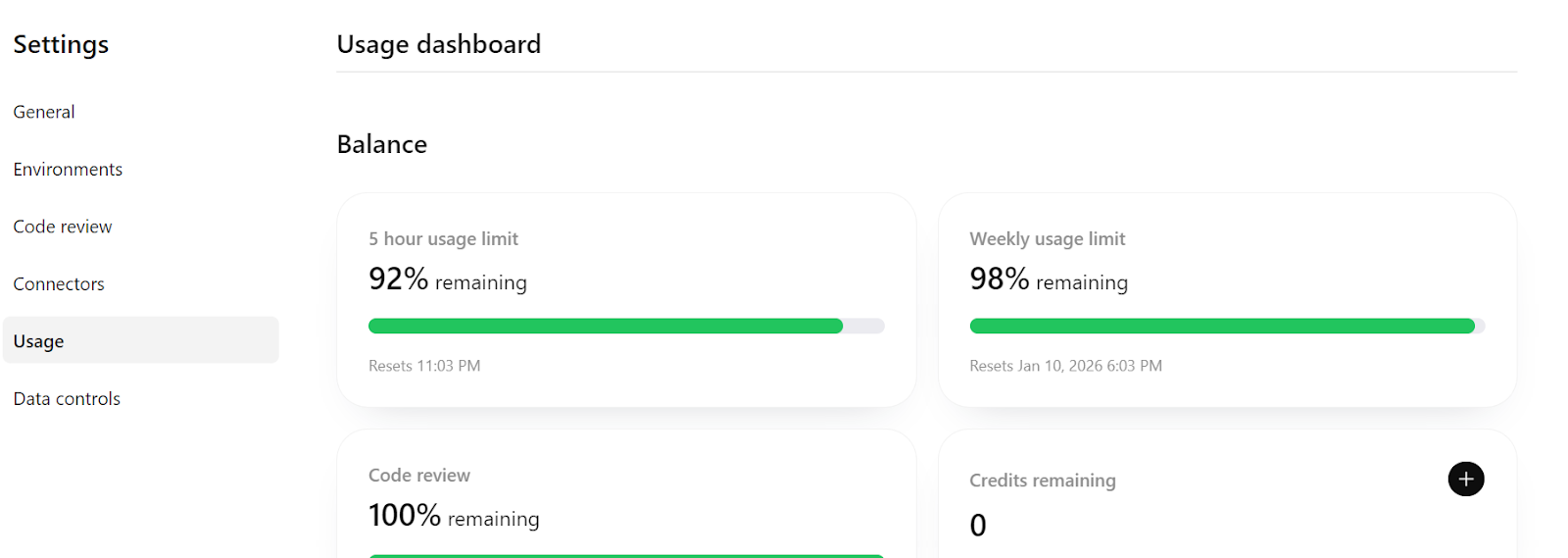
Por fim, se você der uma olhada em https://chatGPT.com/codex/settings/usage, vai ver que a maior parte da sua cota de uso ainda tá disponível, o que significa que você pode continuar tranquilo construindo e iterando nesse projeto, até mesmo expandindo-o para um pipeline mais pronto para produção, se precisar.
Nesta etapa, garantimos que o processo de ingestão seja idempotente, ou seja, que ele possa ser executado novamente com segurança, sem criar dados duplicados. Isso é super importante na engenharia de dados, porque muitas vezes os trabalhos de ingestão precisam ser repetidos ou executados de novo.
TASK 2 (IDEMPOTENT INGEST):
Make CSV ingestion idempotent.
- Rerunning ingest must not duplicate rows
- Validate required columns
- Validate event_time parseable and amount numeric
Add pytest:
- ingest twice → row count unchanged
Update README verification section.
Commit.O que essa etapa faz:
Depois que a tarefa terminar, você pode dar uma olhada no histórico do Git no VSCode e ver que o agente de IA faz os commits das alterações automaticamente depois da grande atualização. Isso dá um histórico de desenvolvimento bem claro e fácil de acompanhar.
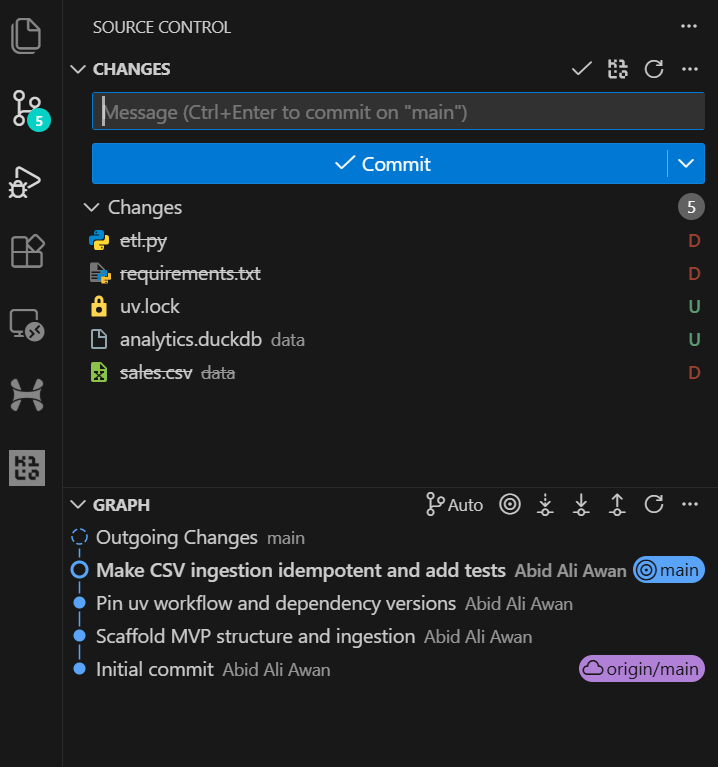
Pedimos ao GPT-5.2 Codex para rodar o conjunto de testes como parte dessa tarefa. No fim das contas, os testes rolaram bem e todas as verificações deram certo.
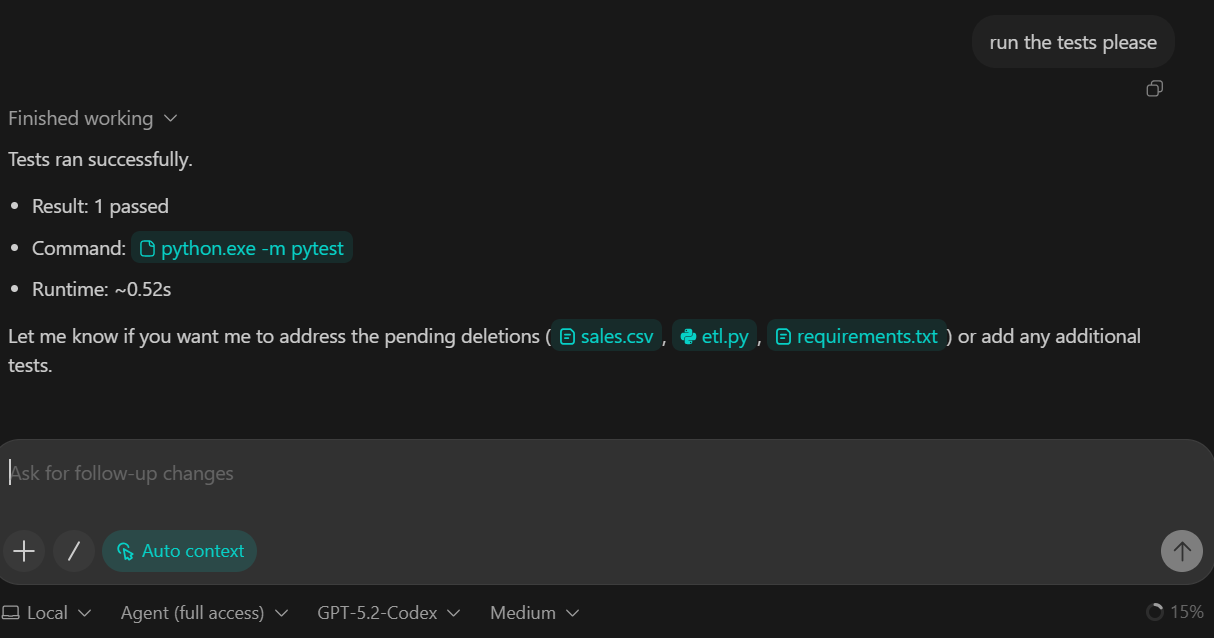
Nesta etapa, vamos apresentar a camada de transformação do pipeline. As transformações são implementadas usando DuckDB SQL, que nos permite converter dados brutos ingeridos em uma tabela de fatos limpa e pronta para análise.
TASK 3 (TRANSFORM SQL):
Create backend/sql/010_fct_events.sql:
- typed columns
- deterministic dedupe
Execute transform from backend/pipeline.py.
Add sanity checks to README:
- raw_events count
- fct_events count
Commit.O que essa etapa faz:
raw_events em fct_events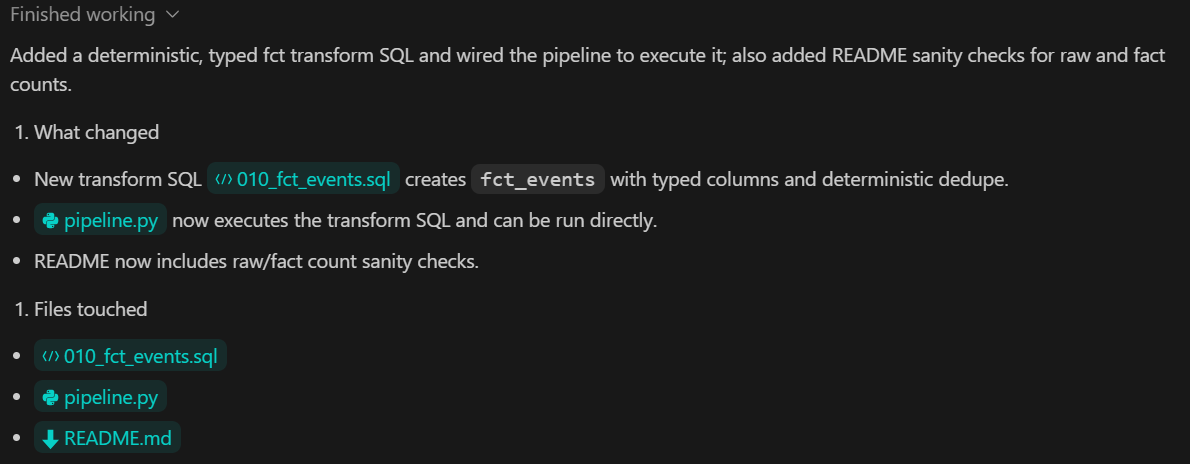
Nesta etapa, adicionamos a camada de métricas, que é responsável por calcular os resultados analíticos a partir dos dados transformados. As métricas são derivadas usando DuckDB SQL e expostas ao resto do sistema por meio de uma interface Python tipada.
TASK 4 (METRICS):
Create backend/sql/020_metrics.sql.
Expose metrics via a Python function returning a Pydantic model.
Add pytest validating:
- keys exist
- types correct
Commit.O que essa etapa faz:
Nesta etapa, criamos o painel de análise local usando o Streamlit. O painel é só pra visualização. Não calcula métricas nem transforma dados. Todos os valores são lidos da camada de métricas criada na etapa anterior.
TASK 5 (STREAMLIT UI):
Build app/app.py:
- 3 KPI cards
- line chart for daily_count
- UI calls backend metrics function
Add a minimal smoke test.
Commit.Depois que a tarefa estiver pronta, o Codex dá umas dicas pra reconstruir o banco de dados DuckDB e rodar todo o pipeline de dados. Nesta etapa, usamos um novo banco de dados preenchido com um conjunto de dados maior.
python backend\ingest.py --csv data\sample.csv
python backend\pipeline.pyDepois de fazer a ingestão, a saída mostra o número de eventos brutos carregados no DuckDB:
raw_events row count: 3738Quando o pipeline estiver pronto, dá o start no aplicativo Streamlit:
streamlit run app\app.pyVocê pode acessar o painel abrindo o http://localhost:8501 no seu navegador.
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.18.10:8501Se aparecer um erro quando o painel for carregado pela primeira vez, isso é normal nas primeiras versões. Copia a mensagem de erro e manda pro GPT-5.2 Codex.
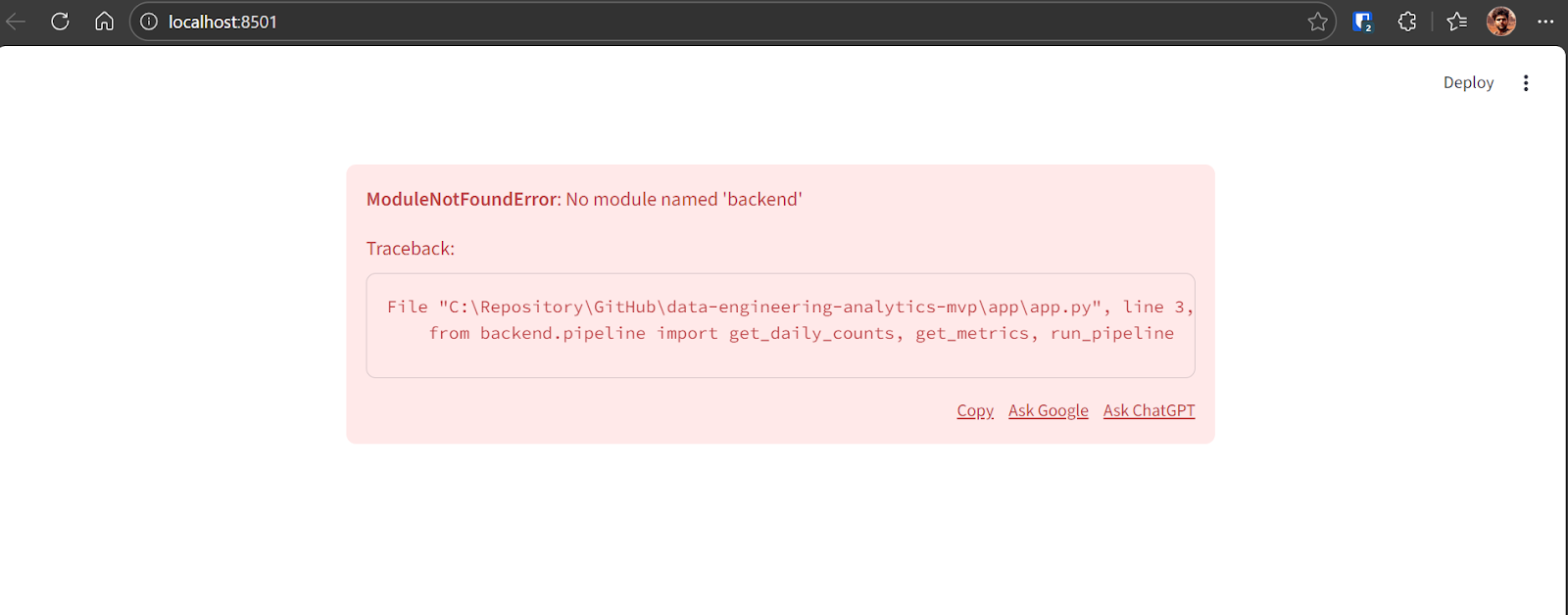
A Codex vai identificar o problema e aplicar a correção necessária. Depois da correção, o aplicativo funciona direitinho e mostra:
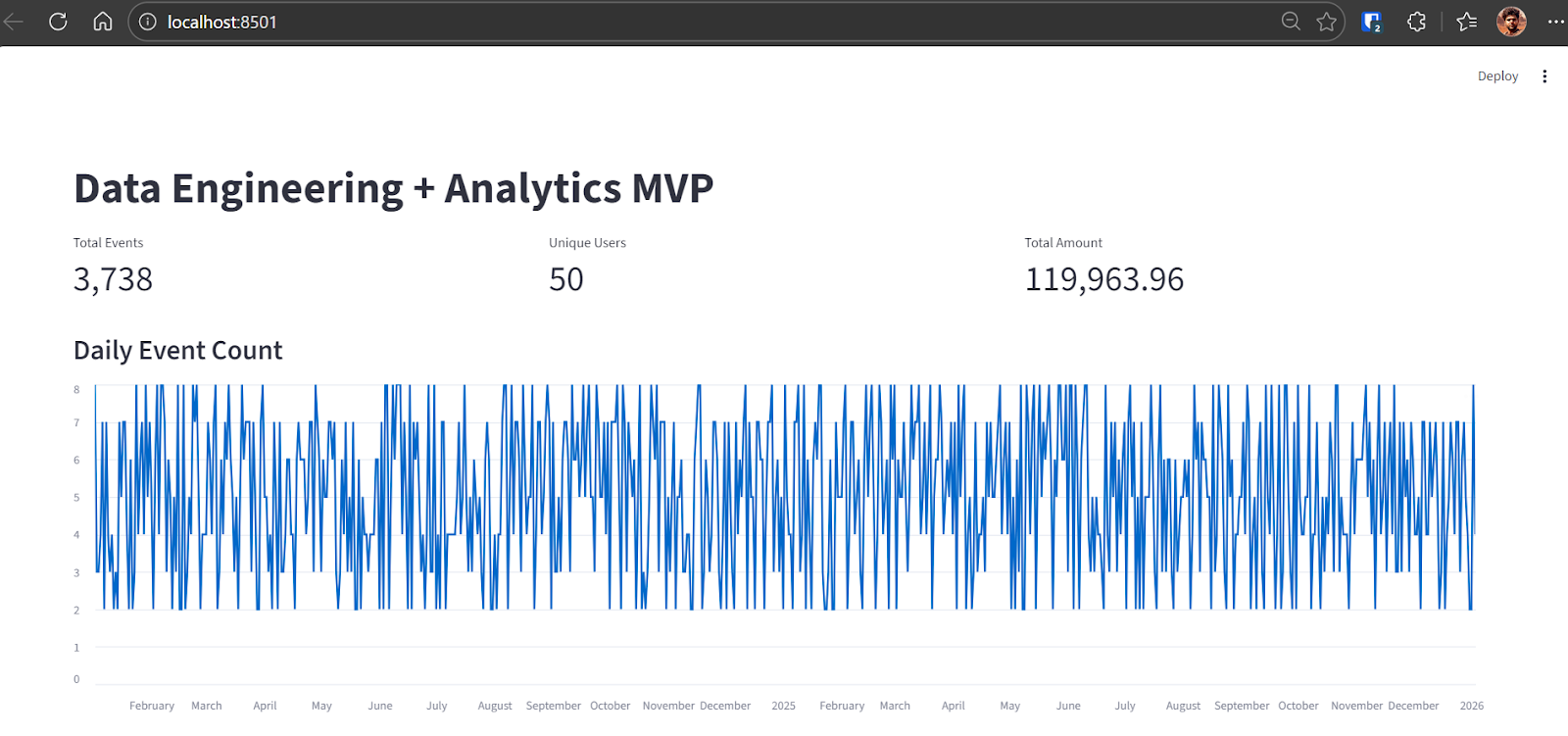
Neste ponto, o pipeline MVP de ponta a ponta está completo e totalmente funcional.
Nesta etapa final, a gente foca na verificação e na confiabilidade. O objetivo é ter um comando único que mostre que todo o pipeline funciona direitinho, desde a ingestão até as métricas e os testes.
TASK 6 (VERIFY):
Add a verify command that:
- rebuilds DB from scratch
- ingests sample.csv
- runs transforms
- runs pytest
Document as "Local Demo" and "Verify" in README.
Commit.O que essa etapa faz:
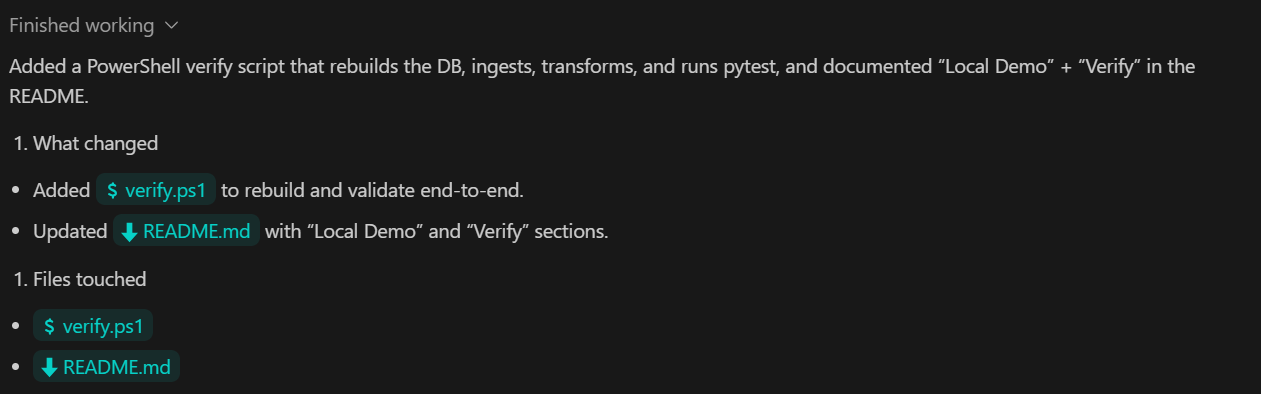
Pedimos ao Codex para atualizar o README, fazer o commit de todas as alterações e enviá-las para o repositório remoto do GitHub.
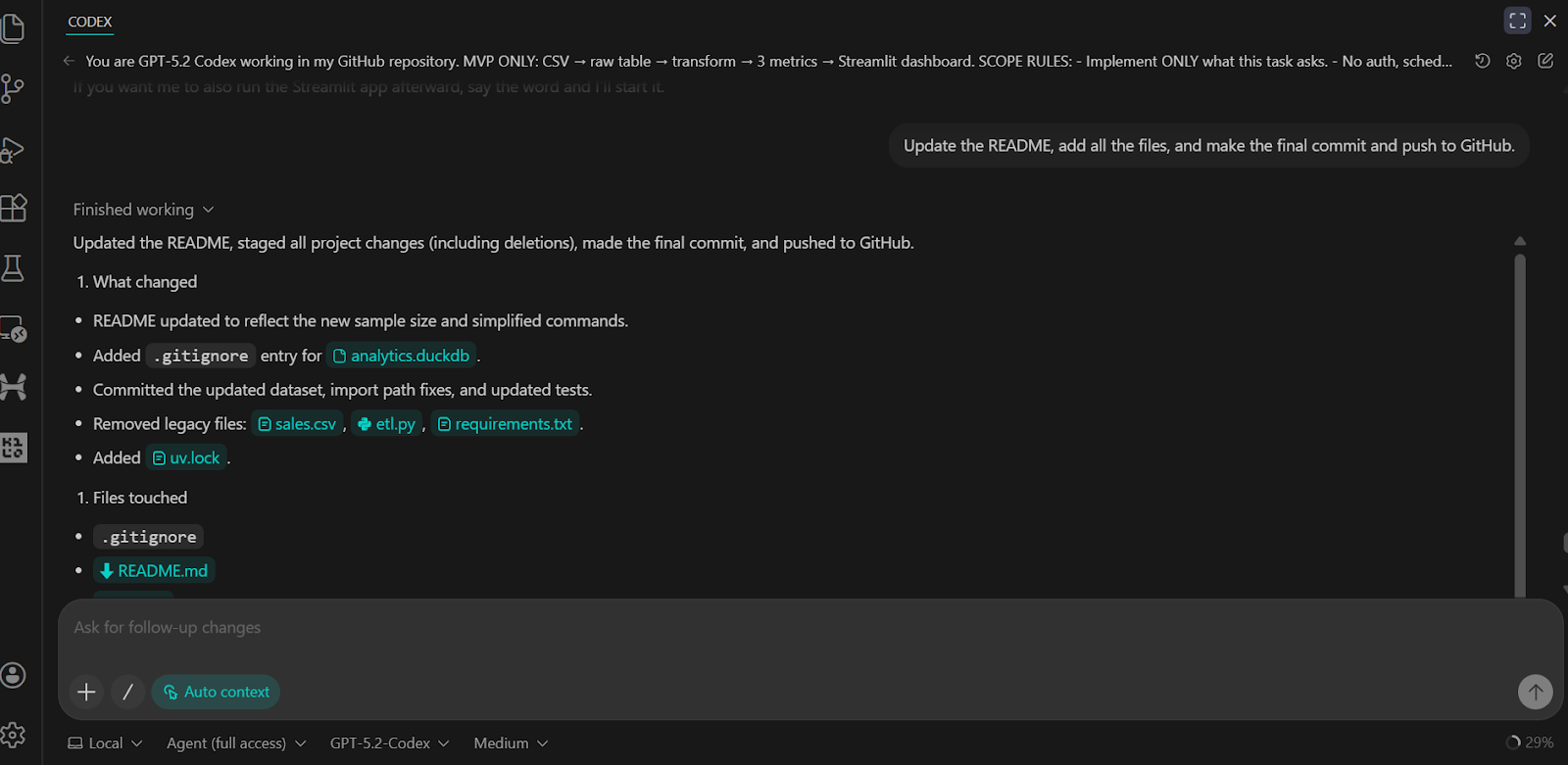
O resultado é um repositório GitHub completo e bem estruturado que inclui todos os scripts, testes, lógica de back-end e instruções claras para executar e verificar o projeto.
Fonte: kingabzpro/engenharia-de-dados-análise-mvp
Já usei o Codex pela CLI e no VSCode de vez em quando no passado, mas as atualizações recentes com o GPT-5.2 Codex fizeram uma diferença notável. O modelo é bem melhor na hora de montar sistemas completos, resolver problemas de depuração e trabalhar com ferramentas como MCP e ferramentas internas. Isso também mostra uma compreensão muito mais profunda da base de código existente, o que torna o desenvolvimento iterativo muito mais eficiente.
Do começo ao fim, levei menos de trinta minutos pra montar, depurar e rodar esse MVP do começo ao fim. O Codex cuidou da configuração do repositório, gerenciamento de dependências, ingestão de dados, transformações SQL, testes e do painel Streamlit com pouquíssima intervenção manual. O ciclo de desenvolvimento parecia rígido e previsível, que é exatamente o que você quer quando precisa construir algo rapidinho.
Esse projeto é propositalmente um MVP. Seria preciso mais algumas tentativas e ajustes para ficar pronto para a produção. Dito isso, a estrutura principal reflete bem como os sistemas reais de engenharia de dados são projetados, o que faz dela uma base sólida para se construir.
Se você estiver interessado em expandir este projeto para uma plataforma de dados mais voltada para a produção, os seguintes componentes são os próximos passos naturais, mas foram intencionalmente excluídos aqui para manter o foco do escopo:
Essas ferramentas são comuns em sistemas de produção, mas excluí-las aqui mantém o projeto simples, local e fácil de entender, ao mesmo tempo em que reflete os padrões reais de engenharia de dados.
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
Tutorial
Dimitri Didmanidze
Tutorial
Arunn Thevapalan
Tutorial
Nadia mhadhbi
Tutorial
Abid Ali Awan
Tutorial
Matt Crabtree

