Curso
Understanding Machine Learning
2 h
293.2K
Si has experimentado la frustración de esperar a que ChatGPT responda, te encantará conocer el Motor de Inferencia de la Unidad de Procesamiento del Lenguaje (LPU) de Groq.
Con Groq, puedes obtener rápidamente la respuesta a tus consultas, reduciendo los tiempos de espera de 40 segundos a sólo 2 segundos.
En este tutorial:
Si no conoces los modelos lingüísticos de gran tamaño (LLM), te recomendamos que sigas el curso de Desarrollo de modelos lingüísticos de gran tamaño para aprender los fundamentos del ajuste fino de los LLM y construir tu propio modelo desde cero.
El motor de inferencia LPU (unidad de procesamiento lingüístico) de Groq es un nuevo sistema de procesamiento que se encarga de tareas computacionalmente extensas con componentes secuenciales, sobre todo en la generación de respuestas para grandes modelos lingüísticos. Esta tecnología innovadora transforma la forma de procesar y generar texto, ofreciendo un rendimiento y una precisión inigualables.
Comparada con la unidad central de procesamiento (CPU) y la unidad de procesamiento gráfico (GPU) tradicionales, la LPU tiene una mayor capacidad de cálculo. Esto significa que el tiempo que se tarda en predecir una palabra se reduce sustancialmente, por lo que las secuencias de texto que se generen serán mucho más rápidas. Además, la LPU también se ocupa de los cuellos de botella de la memoria, una limitación habitual de las GPU al tratar con LLMs.
Groq ha diseñado la LPU para afrontar retos como la densidad de cálculo, el ancho de banda de la memoria, la baja latencia y el alto rendimiento. Ofrece ganancias de rendimiento que superan a la GPU y a la TPU (unidad de procesamiento tensorial). Por ejemplo, la LPU puede generar más de 310 fichas por segundo y usuario en Llama-3 70B.
Puedes obtener más información sobre la arquitectura LPU leyendo el documento de investigación oficial Groq ISCA 2022 Paper.
Actualmente, sólo podemos acceder a los LLM de Groq a través de groq.com, Groq Cloud API, Groq Playground y plataformas de terceros como Poe.
En esta sección, conoceremos las características y modelos que ofrecen OpenAI y Groq Cloud. Además, probaremos la velocidad de las llamadas a la API utilizando CURL y compararemos los diseños de la API.
La API de OpenAI ofrece una amplia gama de funciones y modelos. Ofrece:
La API de OpenAI es rápida y cada vez más barata.
Podemos acceder al último modelo de OpenAI escribiendo el siguiente comando en el terminal. La API requiere la clave de la API de OpenAI, el nombre del modelo y los mensajes que contienen la petición del sistema y la consulta del usuario.
curl -X POST https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{ "role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How do I get better at programming?"
}
]
}'Tardó 13 segundos en completar la solicitud.
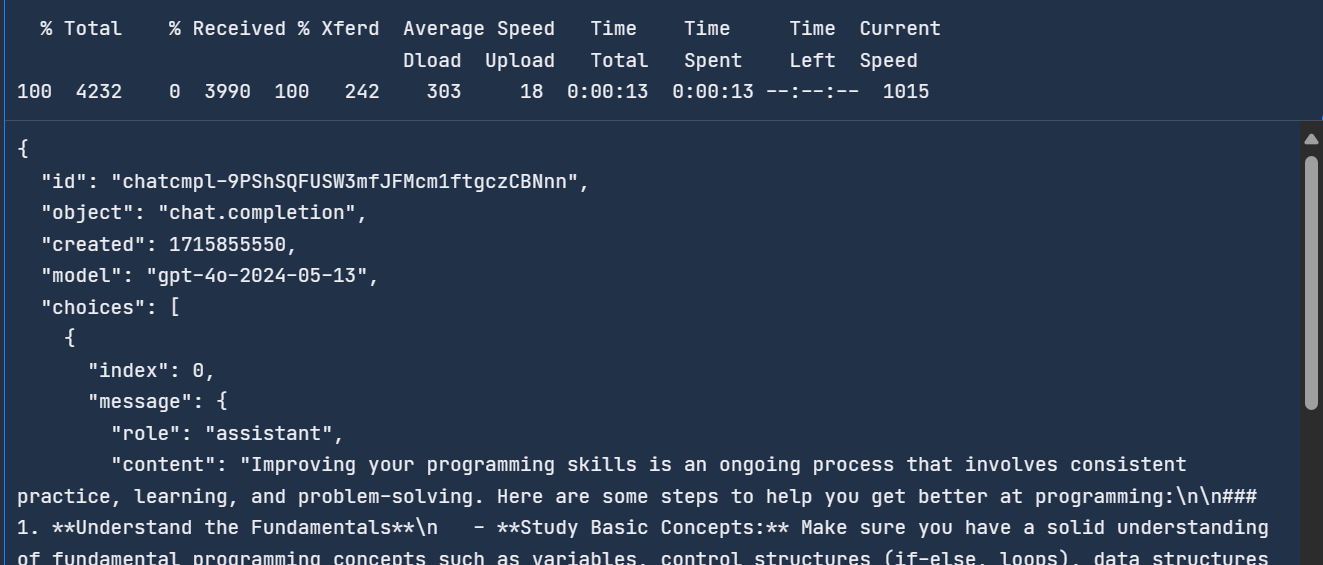
Para saber más sobre la API y las funciones de OpenAI, consulta esta Guía para principiantes sobre la API de OpenAI: Tutorial Práctico y Buenas Prácticas.
Groq es nuevo en la industria de la IA y actualmente ofrece funciones y modelos limitados. Ofrece:
La API de Groq Cloud proporciona un tiempo de respuesta más rápido en comparación con la API de OpenAI. Para comprobarlo, utilizaremos el comando CURL en el terminal y proporcionaremos el mismo mensaje a la API de Groq.
La API de Groq es similar a la API de OpenAI, con la única diferencia de la URL.
curl -X POST "https://api.groq.com/openai/v1/chat/completions" \
-H "Authorization: Bearer $GROQ_API_KEY" \
-H "Content-Type: application/json" \
-d '{"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{ "role": "user",
"content": "How do I get better at programming?"
}
],
"model": "llama3-70b-8192"}'Tardó dos segundos en responder, en comparación con la API OpenAI, que es 6,5 veces más rápida.
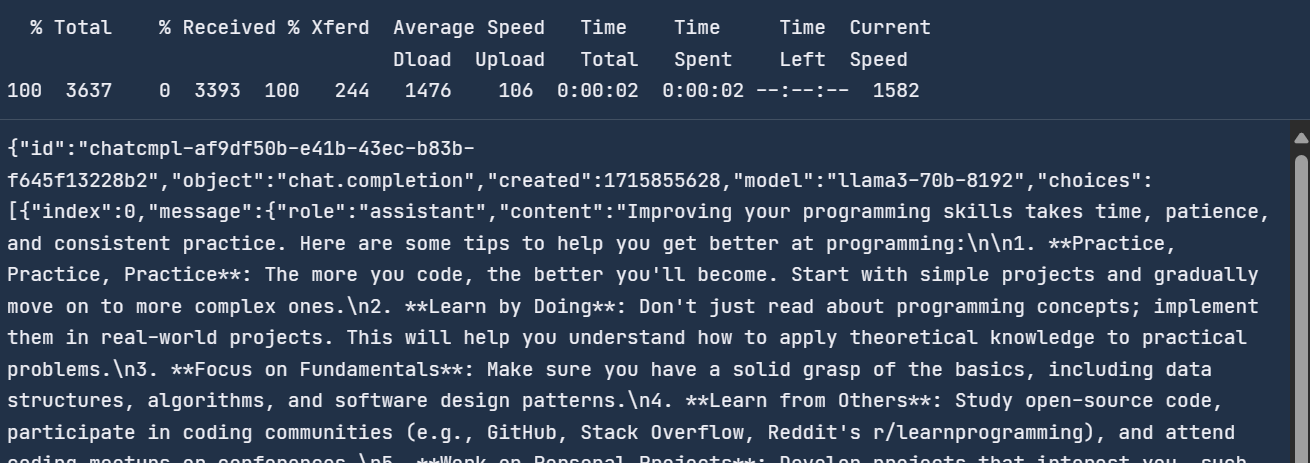
Con Groq, consigues generar respuestas en tiempo real, lo que es crucial para algunas aplicaciones.
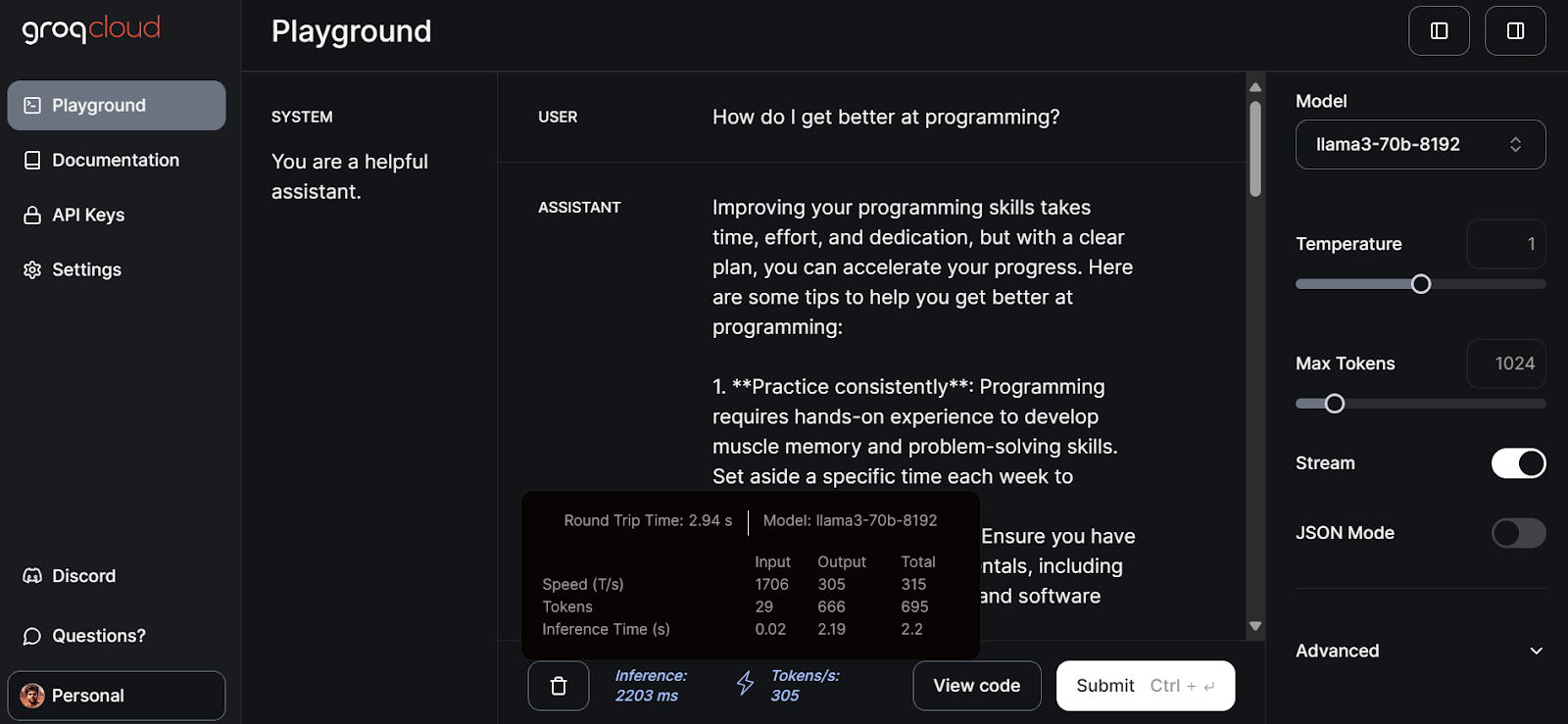
Groq Cloud viene con un patio de recreo de IA donde puedes probar todos los modelos y API que puedes utilizar para crear productos y aplicaciones de IA.
Para acceder a Groq Cloud, primero debes crear una cuenta accediendo a este enlace.
Después, haz clic en la pestaña "patio de recreo" del panel izquierdo, selecciona el modelo llama3-70b-8192 y empieza a escribir avisos para la entrada USUARIO.
Tardó 2,94 segundos en generar la respuesta completa, con una velocidad de 305 fichas por segundo. Se trata de un rendimiento máximo que no obtendremos con ChatGPT.
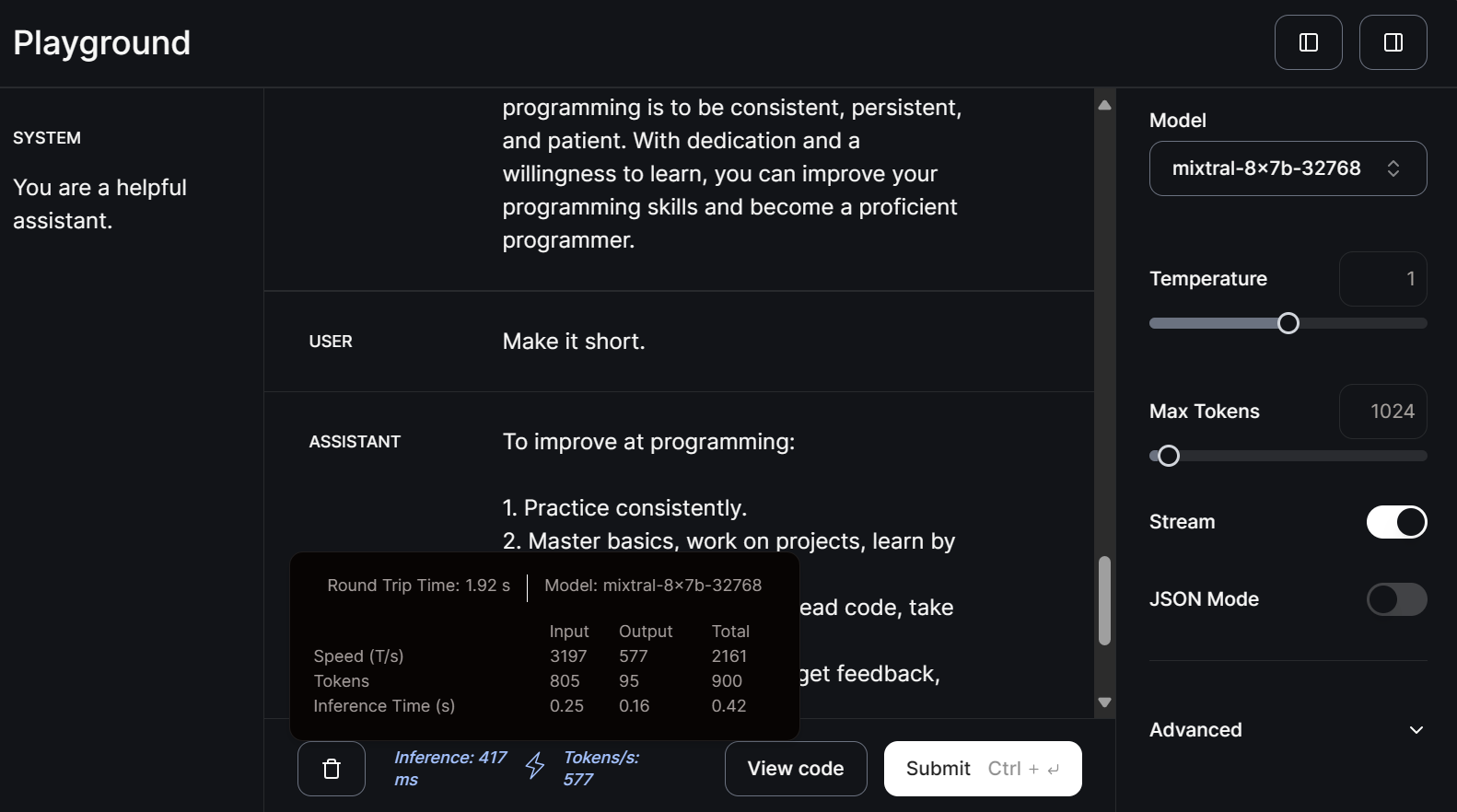
Seleccionemos ahora el modelo pequeño mitral-8x7b-32768 y escribamos la consulta de seguimiento.
Los modelos más pequeños son aún más rápidos a la hora de generar respuestas, con una velocidad de 577 fichas por segundo.
Puedes leer este tutorial en Clasificación LLM: Cómo seleccionar el mejor LLM para tu solicitud para conocer las opciones de LLM disponibles y los factores a tener en cuenta al elegir uno.
Para acceder localmente a los LLM de Groq, tenemos que generar una clave API yendo a la pestaña Claves API y pulsando el botón Crear clave API.
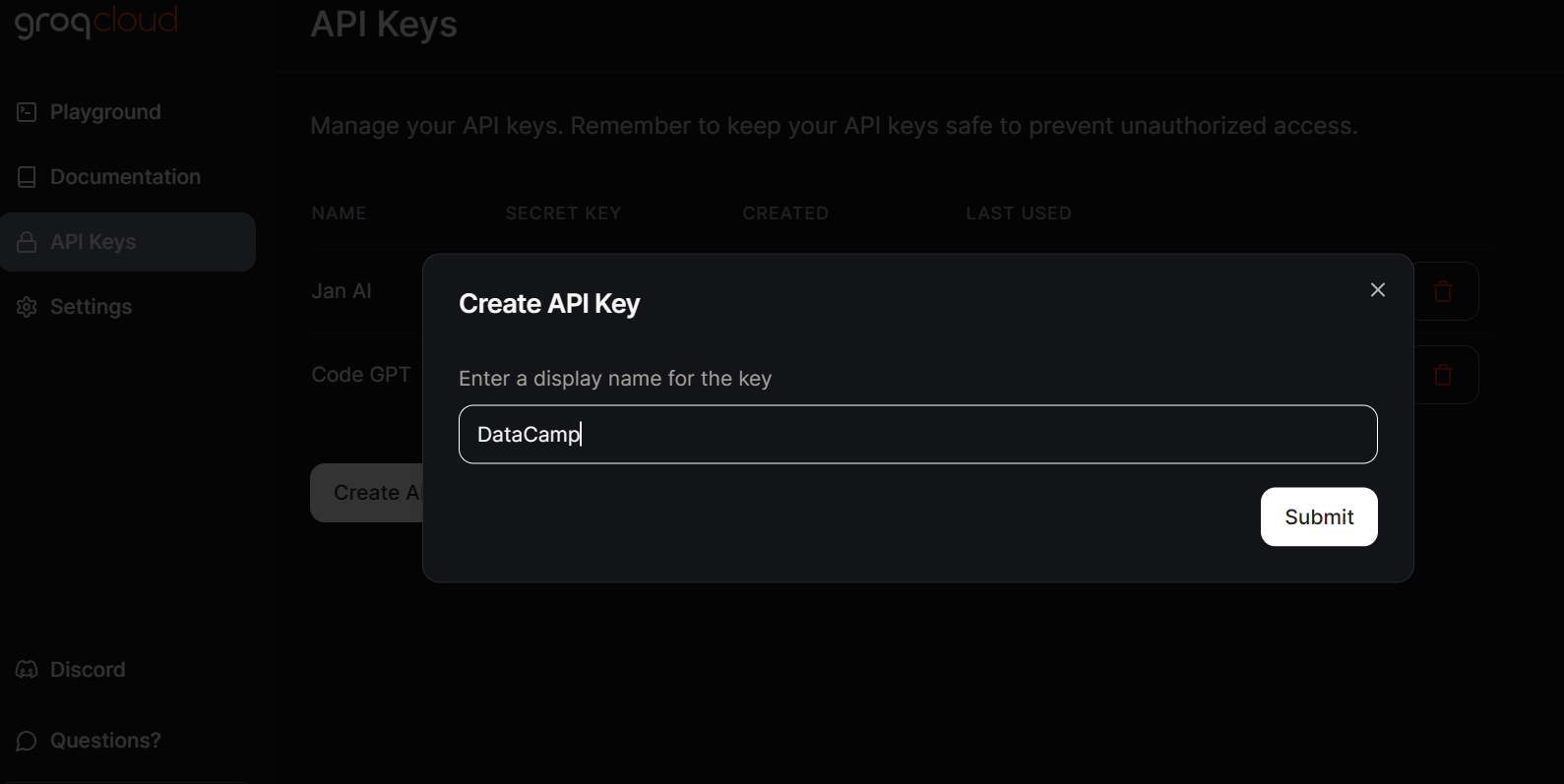
Jan AI nos permite utilizar localmente los LLM, tanto los de código abierto como los modelos patentados. Admite proveedores de modelos como OpenAI, Anthropic, Cohere, MistralAI y Groq.
Descargaremos e instalaremos Jan AI accediendo al sitio web oficial. A continuación, podemos lanzar la aplicación.
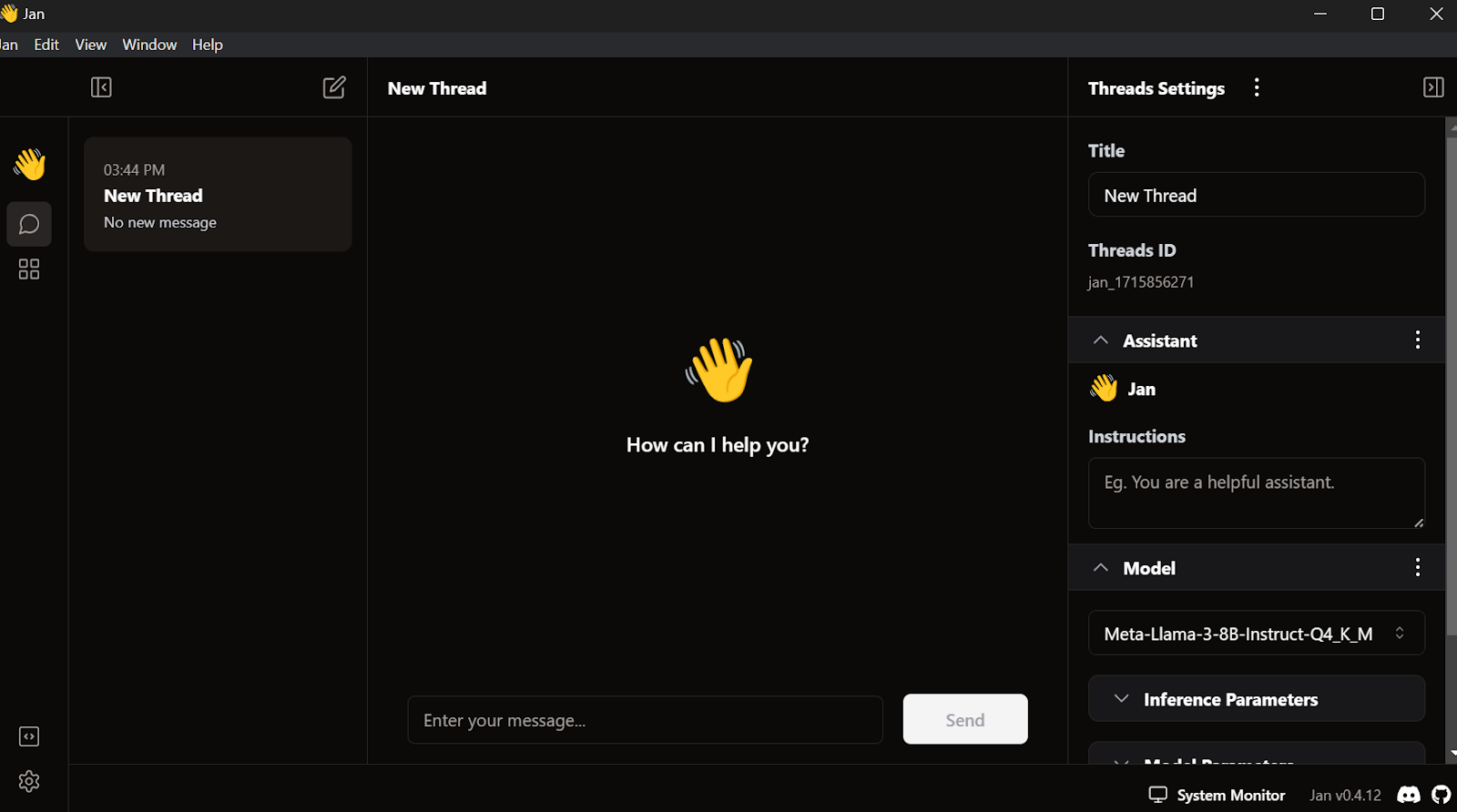
Ve a la configuración, selecciona la pestaña Motor de Inferencia Groq y pega la clave API que acabamos de crear.
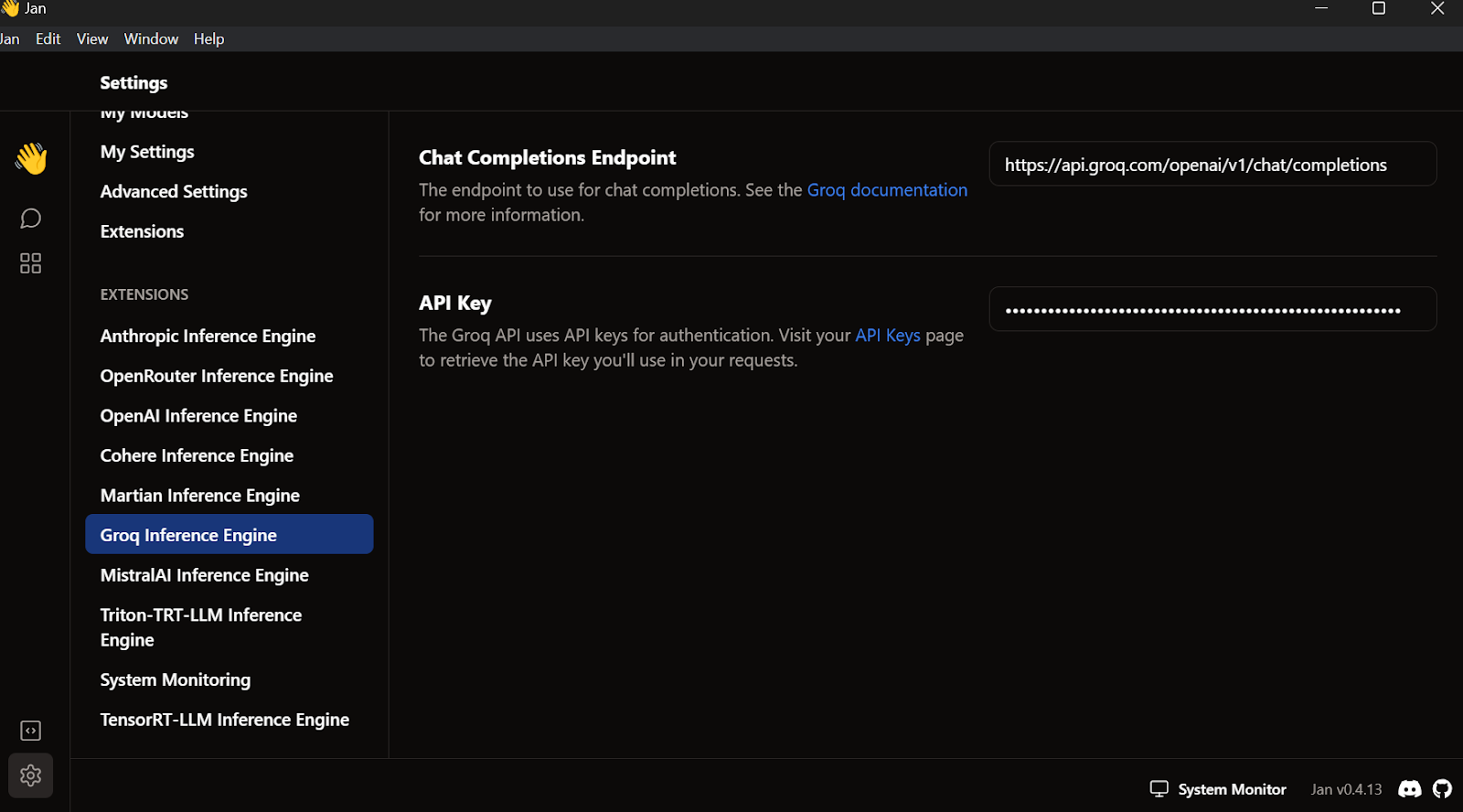
Sal del menú de ajustes, ve a Hilo y selecciona el modelo Groq Llama 3 70b.
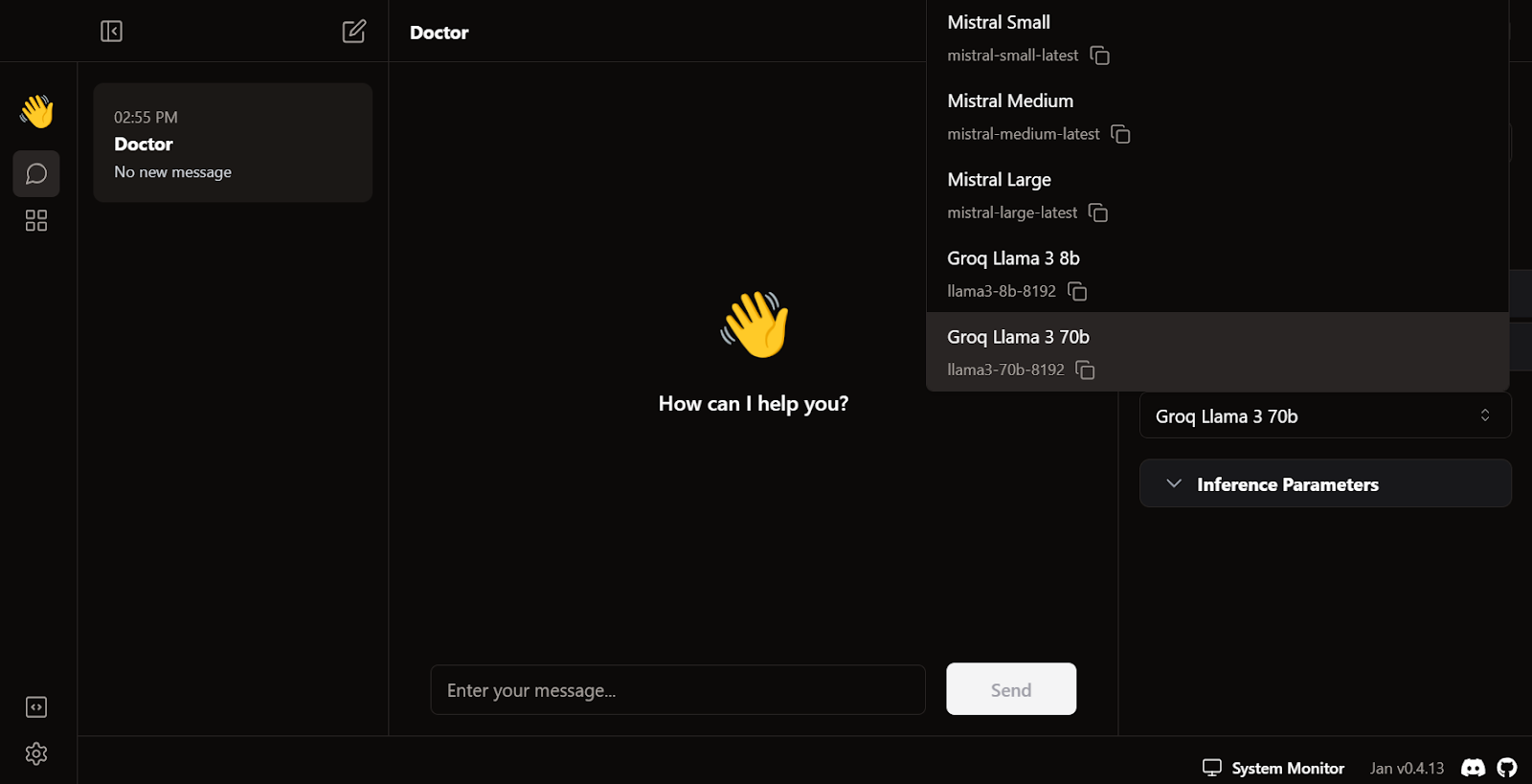
Escribe una pregunta o indicación para generar la respuesta en tiempo real:
La suscripción gratuita a Groq Cloud tiene ciertas limitaciones de tarifa. Por ejemplo, el plan llama3-70b-8192 permite 30 peticiones por minuto, 14.400 peticiones al día y 6.000 tokens por minuto. Aunque estas limitaciones son generosas, si pretendes crear una aplicación de IA adecuada utilizando la API de Groq, puede que tengas que plantearte pasar al paquete On Demand o Enterprise.
Puedes leer este tutorial sobre cómo ejecutar LLMs localmente para explorar siete formas sencillas de ejecutar aplicaciones de IA localmente.
Además de utilizar la API de Groq en una aplicación chatbot, también podemos integrarla en VSCode utilizando la extensión CodeGPT. Será nuestro asistente de codificación IA superrápido.
Para acceder al modelo Groq en VSCode, tenemos que instalar la extensión CodeGPT yendo al mercado de extensiones.

Una vez instalada, configuraremos la clave API Groq haciendo clic en el icono de chat CodeGPT del panel izquierdo y seleccionando el proveedor y el modelo. Hemos seleccionado a Groq como proveedor y a llama3-70b-8192 como modelo.
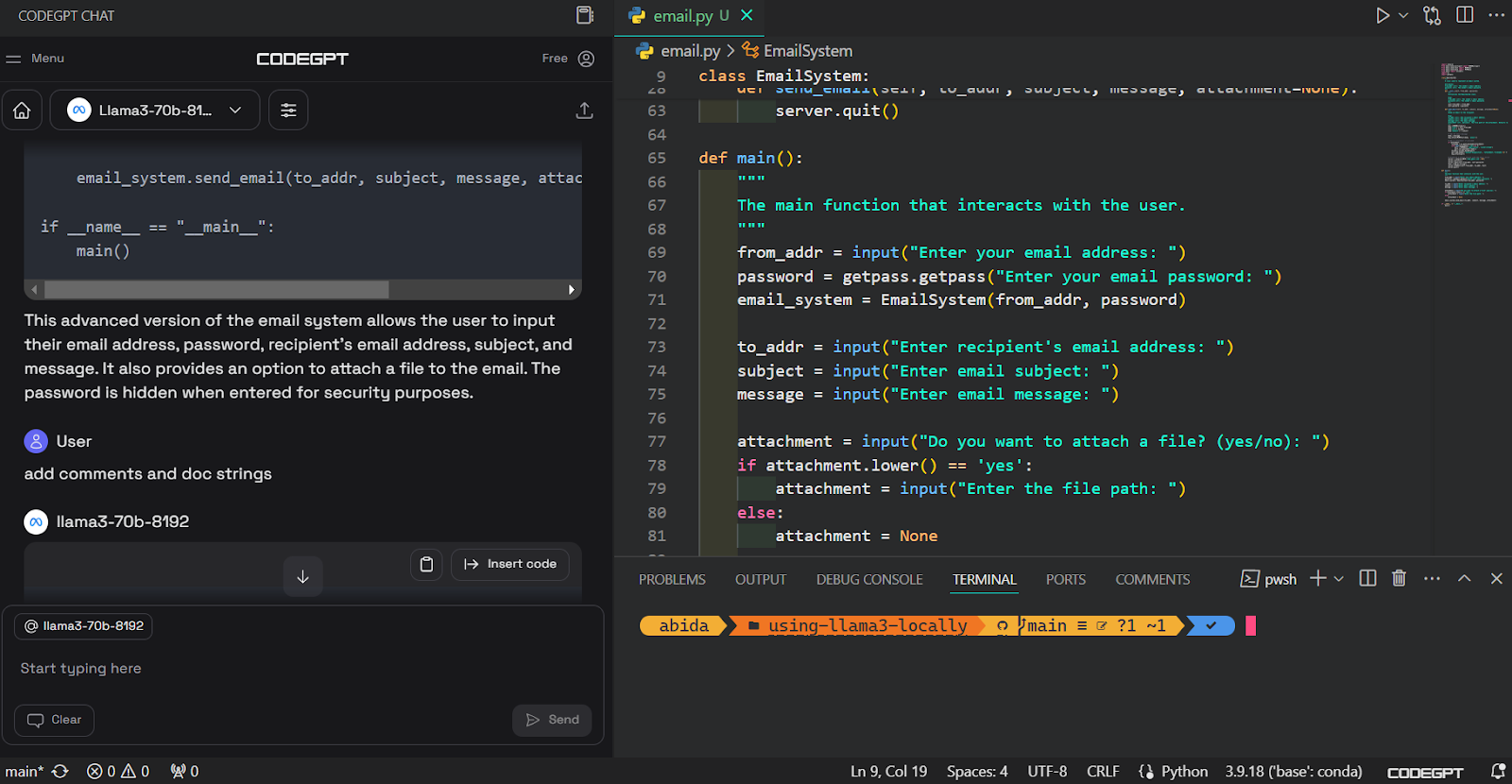
Después, podemos escribir un aviso en el cuadro de chat y generar el código. Nos llevó unos segundos generar el código adecuado y construir el sistema de correo electrónico.
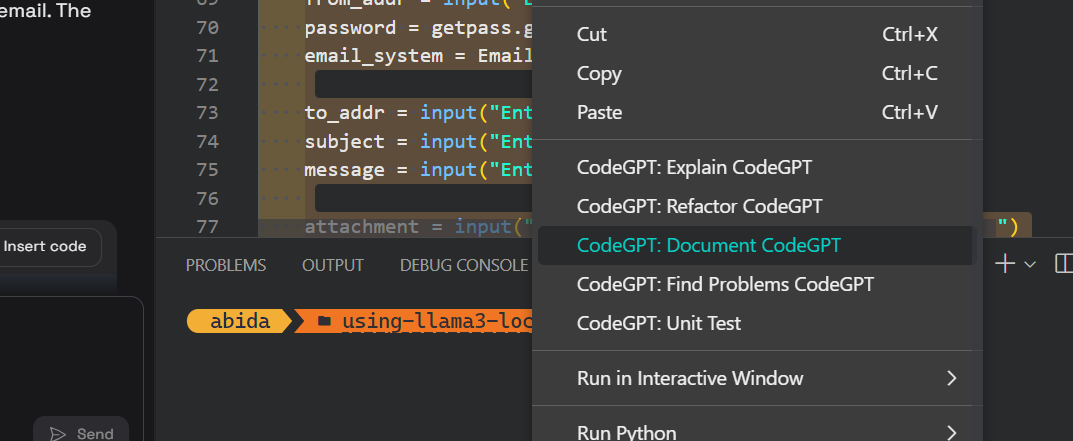
A continuación, podemos documentar el código, refactorizarlo y crear la prueba unitaria con comandos integrados.
Puedes aprender sobre VSCode leyendo este tutorial sobre la configuración de VSCode para Python.
En esta sección, aprenderemos los fundamentos de la API Python de Groq y sus características clave, como el streaming y la finalización asíncrona de conversaciones.
Para esta guía, vamos a utilizar el DataLab de DataCamp. El DataLab es un Cuaderno Jupyter en la Nube de la IA que viene con montones de funciones para escribir código, analizar datos y compartir ideas.
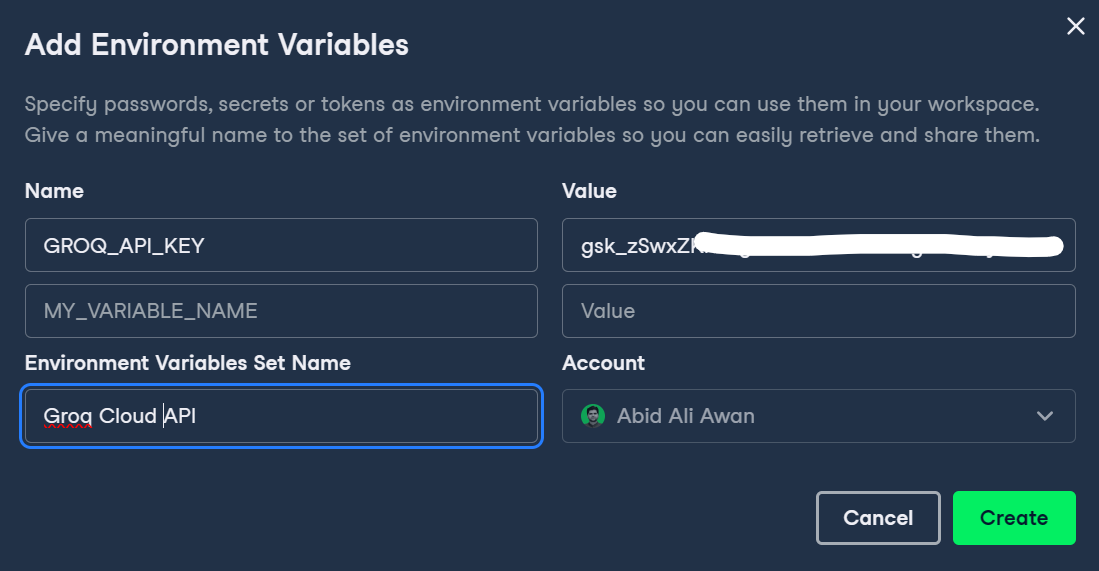
En primer lugar, tenemos que configurar la clave de la API Groq en DataLab haciendo clic en el botón Entorno del panel izquierdo y añadiendo la variable de entorno haciendo clic en el botón más +.
Podemos escribir el nombre de la variable y pegar la clave de la API Groq como se muestra a continuación.
A continuación, podemos activar la variable de entorno haciendo clic en los tres puntos que hay junto a la variable de entorno Groq y haciendo clic en Conectar.

Al final, instalaremos el paquete Groq Python utilizando el comando pip.
%pip install groq -qSi has utilizado la API Python de OpenAI, puede que la estructura del código te resulte similar. Para ejecutar la finalización del chat:
import os
from groq import Groq
from IPython.display import display, Markdown
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
chat_completion = client.chat.completions.create(
messages=[
{"role": "system", "content": "You are a professional Data Scientist."},
{"role": "user", "content": "Can you explain how the neural networks work?"},
],
model="llama3-70b-8192",)
Markdown(chat_completion.choices[0].message.content)Como resultado, tenemos una explicación perfectamente formateada de lo que son las redes neuronales.

El streaming en los LLM se refiere al procesamiento y generación de texto de un token cada vez, lo que permite un uso eficiente de la memoria y mejora la velocidad percibida de la aplicación de IA.
En estos ejemplos, activamos el streaming y personalizamos el modelo cambiando los hiperparámetros como temperatura, max_tokens y top_p.
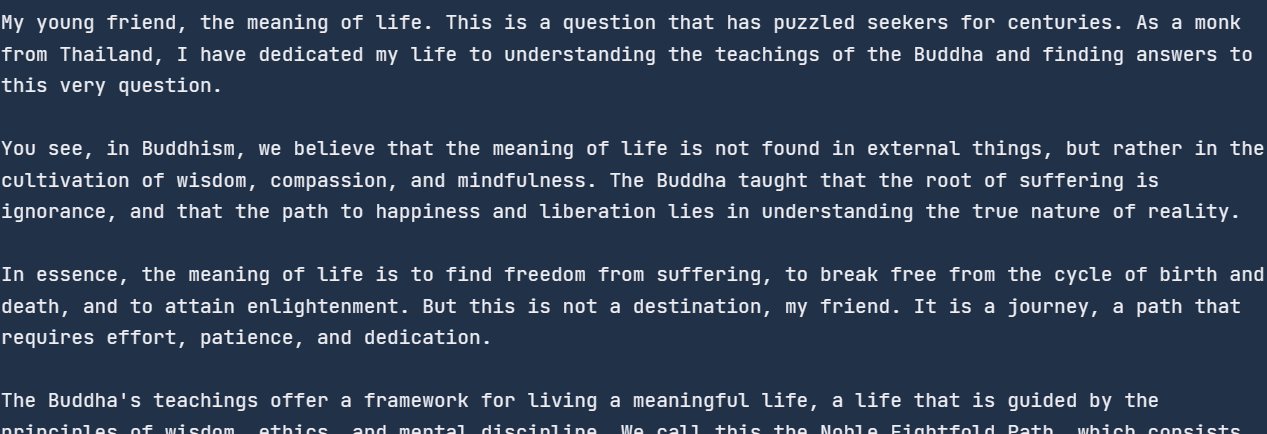
chat_streaming = client.chat.completions.create(
messages=[
{"role": "system", "content": "You are a monk from Thailand."},
{"role": "user", "content": "Can you explain the meaning of life?"},
],
model="llama3-70b-8192",
temperature=0.3,
max_tokens=360,
top_p=1,
stop=None,
stream=True,
)
for chunk in chat_streaming:
print(chunk.choices[0].delta.content, end="")Como resultado, empezamos a recibir la respuesta en cuanto ejecutamos este código.
Las API asíncronas permiten gestionar varias solicitudes simultáneas sin bloquearse, permitiendo que el sistema procese y responda a cada solicitud de forma independiente. Este enfoque es más eficaz y escalable, ya que puede gestionar un mayor volumen de solicitudes y proporcionar tiempos de respuesta más rápidos.
Para activar la llamada asíncrona a la API, tenemos que cambiar la estructura del código. Nosotros:
Como nota al margen, el código de abajo funciona en Jupyter Notebook, pero si estás ejecutando este código en el archivo Python, puede que tengas que cambiar la última línea por asyncio.run(main()).
import asyncio
from groq import AsyncGroq
client = AsyncGroq(
api_key=os.environ.get("GROQ_API_KEY"),
)
async def main():
chat_completion = await client.chat.completions.create(
messages=[ {"role": "system", "content": "You are a psychiatrist helping young minds"},
{ "role": "user", "content": "I panicked during the test, even though I knew everything on the test paper.", },
],
model="llama3-70b-8192",
temperature=0.3,
max_tokens=360,
top_p=1,
stop=None,
stream=False,
)
print(chat_completion.choices[0].message.content)
await main() # for Python file use asyncio.run(main())
También podemos hacer streaming de la API asíncrona activando el argumento stream en la función de finalización del chat y cambiando cómo imprimimos los resultados. Imprimiremos cada trozo utilizando el bucle for con el comando asíncrono.
import asyncio
from groq import AsyncGroq
client = AsyncGroq()
async def main():
chat_streaming = await client.chat.completions.create(
messages=[
{"role": "system", "content": "You are a psychiatrist helping young minds"},
{ "role": "user", "content": "I panicked during the test, even though I knew everything on the test paper.", },
],
model="llama3-70b-8192",
temperature=0.3,
max_tokens=360,
top_p=1,
stop=None,
stream=True,
)
async for chunk in chat_streaming:
print(chunk.choices[0].delta.content, end="")
await main() # for Python file use asyncio.run(main())
Si tienes problemas para ejecutar el código, consulta este cuaderno de DataLab: Groq Cloud API.
En esta guía, daremos un paso más y aprenderemos a crear una aplicación de IA utilizando la API Groq y LlamaIndex, que es un framework LLM. Construiremos una aplicación que cargará el texto de un archivo PDF, lo convertirá en incrustaciones y lo guardará en el almacén de vectores. Después, convertiremos el almacén vectorial en el recuperador que se utilizará para construir un motor de chat RAG con historial.
En resumen, estamos construyendo una aplicación ChatPDF consciente del contexto para ayudarte a entender el documento mucho más rápido.
Para aprender a ingerir, gestionar y recuperar datos privados y específicos de un dominio utilizando lenguaje natural, consulta este tutorial: LlamaIndex: Un marco de datos para grandes modelos lingüísticos (LLM).
En primer lugar, instalaremos todos los paquetes Python necesarios utilizando pip. Utilizamos la función mágica %%captura para suprimir los registros.
%%capture
%pip install llama-index
%pip install llama-index-llms-groq
%pip install llama-index-embeddings-huggingfaceCrearemos el cliente Groq LLM utilizando la función llama_index. El cliente LLM necesita un nombre de modelo y la clave API.
from llama_index.llms.groq import Groq
import os
llm =
Groq(model="llama3-70b-8192",api_key=os.environ.get("GROQ_API_KEY"))Ahora descargaremos y cargaremos el modelo de incrustación Cara Abrazada utilizando la API de incrustación LlamaIndex.
En nuestro caso, estamos cargando el modelo de incrustación más popular de Hugging Face, llamado mxbai-embed-large-v1.
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
embed_model =
HuggingFaceEmbedding(model_name="mixedbread-ai/mxbai-embed-large-v1")LlamaIndex nos permite establecer configuraciones globales, eliminando la necesidad de pasar el LLM o los objetos del modelo de incrustación por todas partes.
from llama_index.core import Settings
Settings.llm = llm
Settings.embed_model = embed_modelPara los datos, vamos a utilizar la publicación del blog 14 herramientas esenciales de ingeniería de datos que debes utilizar en 2024 y los convertiremos en un PDF utilizando el comando de impresión.
Utilizando la función SimpleDirectoryReader, puedes cargar todo tipo de documentos desde la carpeta. Sólo tienes que indicar el directorio de la carpeta y las extensiones de archivo necesarias.
from llama_index.core import SimpleDirectoryReader
de_tools_blog = SimpleDirectoryReader("./",required_exts=[".pdf", ".docx"]).load_data()VectorStoreIndex proporciona la forma más rápida de crear el almacén vectorial cargando los documentos y construyendo el índice. El índice puede utilizarse para motores de consulta, recuperadores y canalizadores de consulta.
En nuestro caso, estamos creando el índice proporcionando los documentos al almacén vectorial, que convertirá el texto en incrustaciones y luego lo almacenará en el almacén vectorial.
Después, convertiremos el índice en el motor de consulta para realizar la RAG básica (generación aumentada de recuperación), que combina los modelos de recuperación y de IA para generar una respuesta consciente del contexto.
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_documents(de_tools_blog)
query_engine = index.as_query_engine(similarity_top_k=3)
response = query_engine.query("How many tools are there?")
print(response)![]()
Ahora crearemos el motor de chat RAG con historial. Añadir el historial permitirá al motor de chat recordar tanto los mensajes del usuario como las respuestas generadas, y proporcionar respuestas adaptadas al contexto.
Para construir esta aplicación, necesitaremos crear el ChatMemoryBuffer de 3900 tokens y proporcionárselo al motor de chat junto con el recuperador y el objeto LLM.
Cuando hagas una pregunta, el motor de chat utilizará el documento PDF y los mensajes anteriores como contexto y responderá en consecuencia.
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.core.chat_engine import CondensePlusContextChatEngine
memory = ChatMemoryBuffer.from_defaults(token_limit=3900)
chat_engine = CondensePlusContextChatEngine.from_defaults(
index.as_retriever(),
memory=memory,
llm=llm
)
response = chat_engine.chat(
"What tools are suitable for data processing?"
)
print(str(response))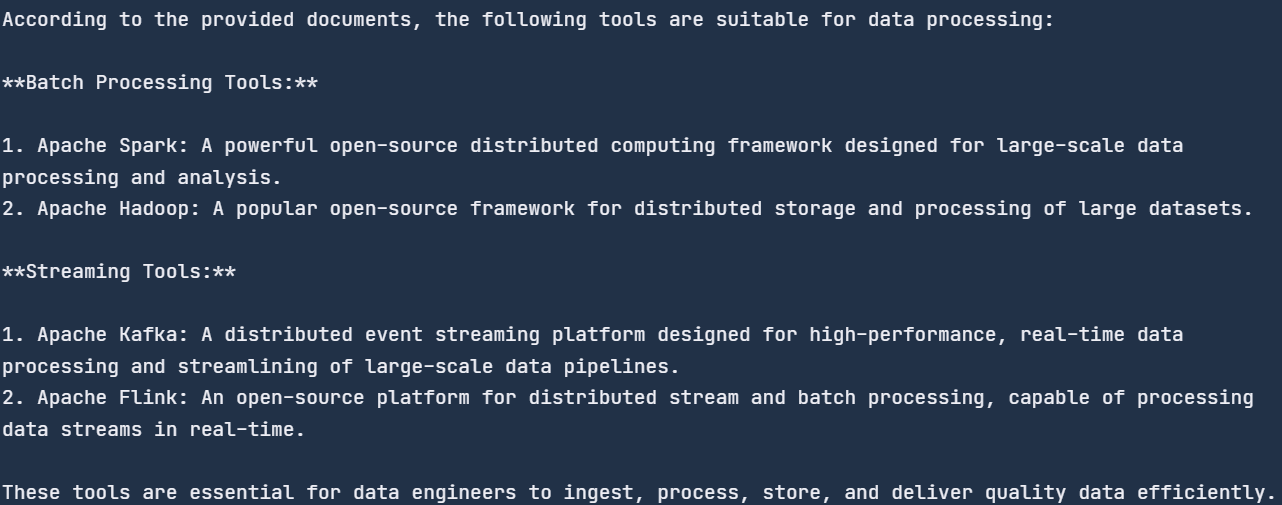
Hicimos preguntas genéricas, y buscó en el documento las herramientas de tratamiento de datos y nos proporcionó la lista. Todas las herramientas se mencionan en el blog.
Hagamos una pregunta de seguimiento para probar la parte de memoria del motor de chat.
response = chat_engine.chat(
"Can you create a diagram of a data pipeline using these tools?"
)
print(str(response))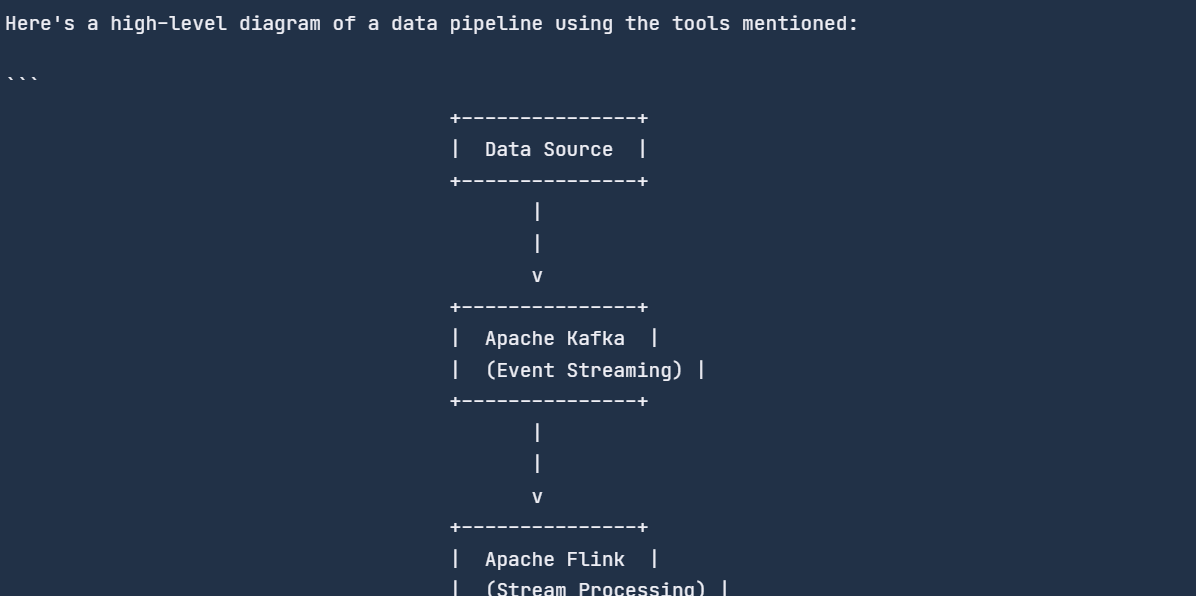
El motor del chat recordaba el chat anterior y respondía en consecuencia.
Todo el código que hemos utilizado está disponible en este cuaderno DataLab: Groq Cloud API — DataLab.
El motor de inferencia Groq LPU cambia las reglas del juego de la IA. Mientras que los principales actores, como OpenAI y Google, se centran en desarrollar LLM de alta calidad, Groq hace que estos modelos sean más rápidos. A pesar de ser nuevo en la escena de la IA, Groq está haciendo olas significativas en la comunidad de la IA.
En este blog, hemos aprendido sobre el motor de inferencia Groq LPU, hemos explorado Groq Cloud y hemos integrado la API de Groq en VSCode y en la aplicación Jan AI. Además, hemos profundizado en el paquete Groq Python con ejemplos de código y hemos aprendido a crear una aplicación de IA consciente del contexto que puede aprender del historial de chat y de documentos PDF.
Un posible paso siguiente en tu viaje de aprendizaje es afinar los LLM en un conjunto de datos personalizado. Puedes aprender a hacerlo siguiendo este tutorial: Ajuste fino Google Gemma: Mejorar los LLM con instrucciones personalizadas.
Aprende con DataCamp
Curso
Curso
Curso