Curso
Entendendo Machine Learning
2 h
293.5K
Se você já passou pela frustração de esperar a resposta do ChatGPT, ficará feliz em conhecer o mecanismo de inferência da Unidade de Processamento de Linguagem (LPU) do Groq.
Com o Groq, você pode obter rapidamente a resposta às suas consultas, reduzindo o tempo de espera de 40 segundos para apenas 2 segundos.
Neste tutorial, você verá:
Se você não tem experiência com modelos de linguagem grandes (LLMs), recomendamos que faça o curso de habilidade Developing Large Language Models para aprender os conceitos básicos de ajuste fino de LLMs e criar seu próprio modelo do zero.
O mecanismo de inferência LPU (unidade de processamento de linguagem) da Groq é um novo sistema de processamento que lida com tarefas computacionalmente extensas com componentes sequenciais, especialmente na geração de respostas para grandes modelos de linguagem. Essa tecnologia inovadora transforma a maneira como processamos e geramos texto, oferecendo desempenho e precisão inigualáveis.
Em comparação com a unidade de processamento central (CPU) e a unidade de processamento gráfico (GPU) tradicionais, a LPU tem uma capacidade de computação maior. Isso significa que o tempo necessário para prever uma palavra é substancialmente reduzido, fazendo com que as sequências de texto sejam geradas muito mais rapidamente. Além disso, a LPU também lida com gargalos de memória, uma limitação comum das GPUs ao lidar com LLMs.
A Groq projetou a LPU para enfrentar desafios como densidade de computação, largura de banda da memória, baixa latência e alta taxa de transferência. Ele oferece ganhos de desempenho que superam a GPU e a TPU (unidade de processamento de tensor). Por exemplo, a LPU pode gerar mais de 310 tokens por segundo por usuário no Llama-3 70B.
Você pode saber mais sobre a arquitetura LPU lendo o documento oficial de pesquisa Groq ISCA 2022 Paper.
Atualmente, só podemos acessar os LLMs do Groq por meio do groq.com, da API do Groq Cloud, do Groq Playground e de plataformas de terceiros, como a Poe.
Nesta seção, aprenderemos sobre os recursos e modelos oferecidos pela OpenAI e pelo Groq Cloud. Além disso, testaremos a velocidade das chamadas de API usando CURL e compararemos os designs de API.
A API da OpenAI oferece uma ampla variedade de recursos e modelos. Ele oferece:
A API da OpenAI é rápida e está ficando mais barata com o tempo.
Você pode acessar o modelo mais recente da OpenAI digitando o seguinte comando no terminal. A API requer a chave da API da OpenAI, o nome do modelo e as mensagens que contêm o prompt do sistema e a consulta do usuário.
curl -X POST https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{ "role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How do I get better at programming?"
}
]
}'Você levou 13 segundos para concluir a solicitação.
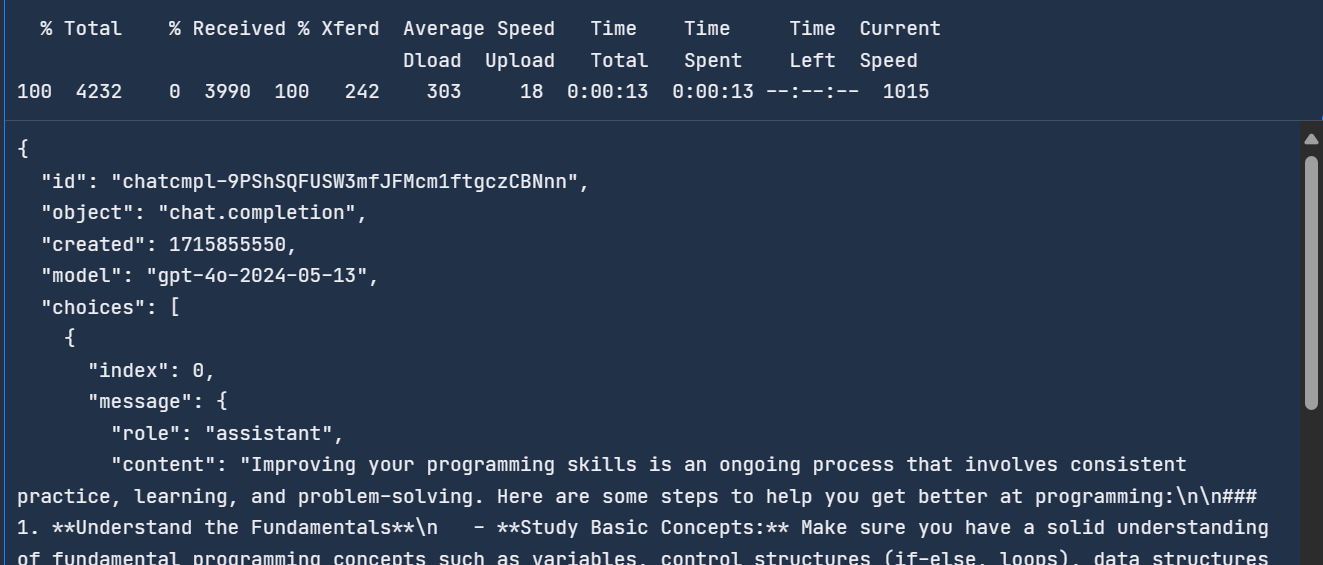
Para saber mais sobre a API e os recursos da OpenAI, confira este Guia da API da OpenAI para iniciantes: Tutorial prático e práticas recomendadas.
A Groq é nova no setor de IA e atualmente oferece recursos e modelos limitados. Ele oferece:
A API do Groq Cloud oferece um tempo de resposta mais rápido em comparação com a API do OpenAI. Para testar isso, usaremos o comando CURL no terminal e forneceremos a mesma mensagem para a API do Groq.
A API do Groq é semelhante à API do OpenAI, com a única diferença sendo o URL.
curl -X POST "https://api.groq.com/openai/v1/chat/completions" \
-H "Authorization: Bearer $GROQ_API_KEY" \
-H "Content-Type: application/json" \
-d '{"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{ "role": "user",
"content": "How do I get better at programming?"
}
],
"model": "llama3-70b-8192"}'Você levou dois segundos para responder, em comparação com a API OpenAI, que é 6,5 vezes mais rápida.
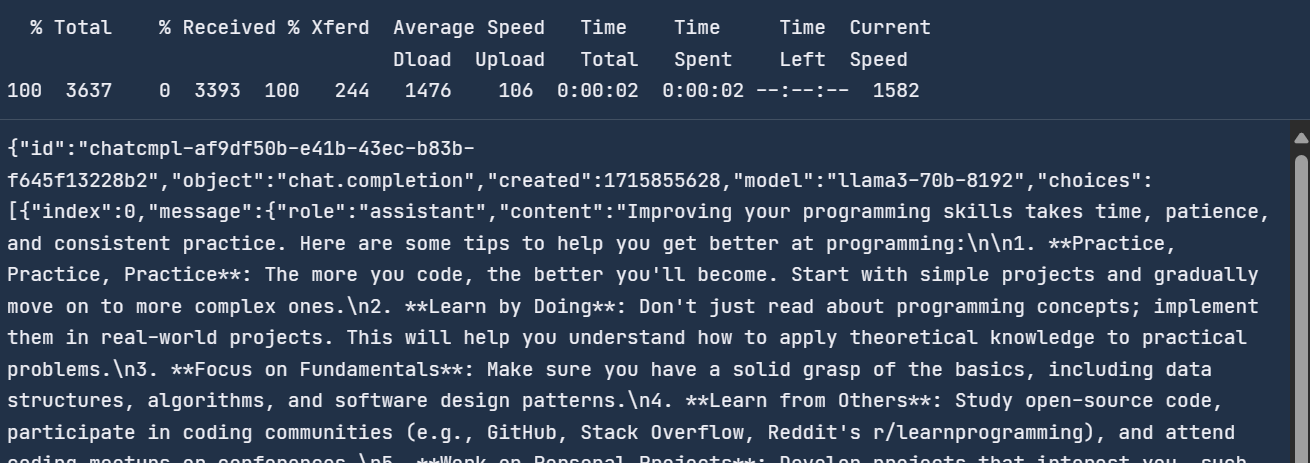
Com o Groq, você obtém geração de respostas em tempo real, o que é crucial para alguns aplicativos.
O Groq Cloud vem com um playground de IA onde você pode testar todos os modelos e APIs que pode usar para criar produtos e aplicativos de IA.
Para acessar o Groq Cloud, você deve primeiro criar uma conta acessando este link.
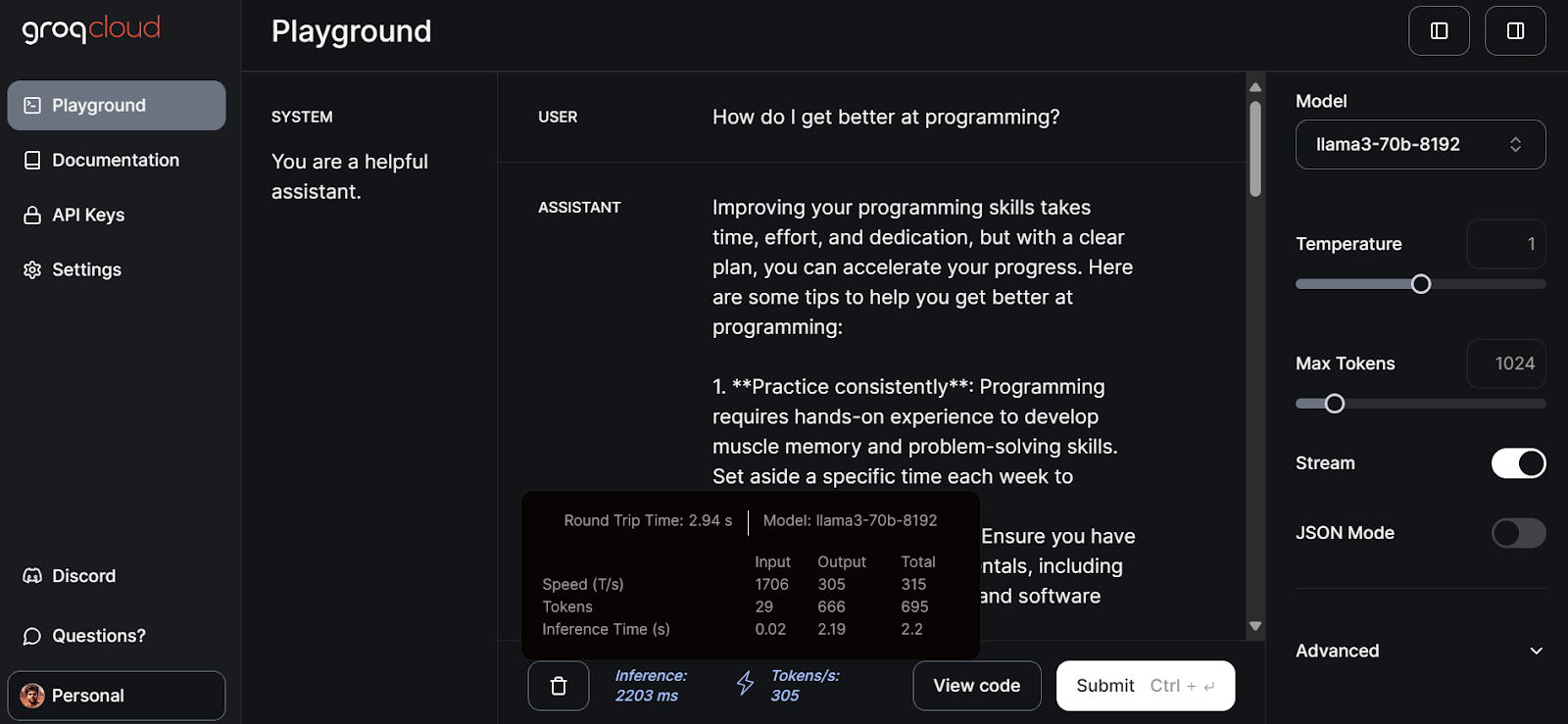
Depois disso, clique na guia playground no painel esquerdo, selecione o modelo llama3-70b-8192 e comece a escrever prompts para a entrada do USUÁRIO.
Foram necessários 2,94 segundos para gerar a resposta completa com uma velocidade de 305 tokens por segundo. Isso é apenas o desempenho máximo que você não obterá com o ChatGPT.
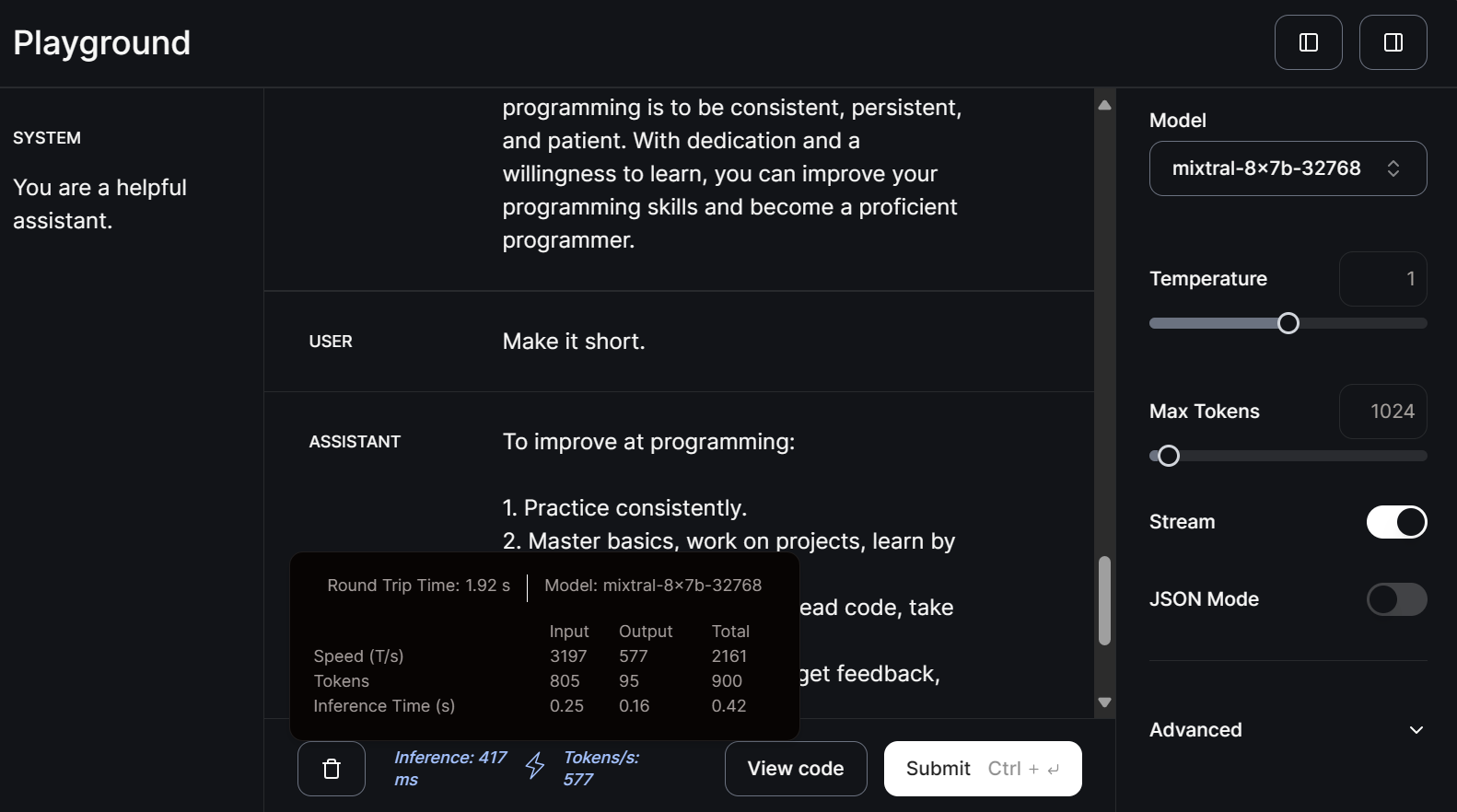
Vamos agora selecionar o modelo pequeno mitral-8x7b-32768 e escrever o prompt de acompanhamento.
Os modelos menores são ainda mais rápidos na geração de respostas, com velocidade de 577 tokens por segundo.
Você pode ler este tutorial em LLM Classification: How to Select the Best LLM for Your Application para saber mais sobre as opções de LLM disponíveis e os fatores que você deve considerar ao escolher uma.
Para acessar os LLMs do Groq localmente, temos que gerar uma chave de API acessando a guia Chaves de API e clicando no botão Criar chave de API.
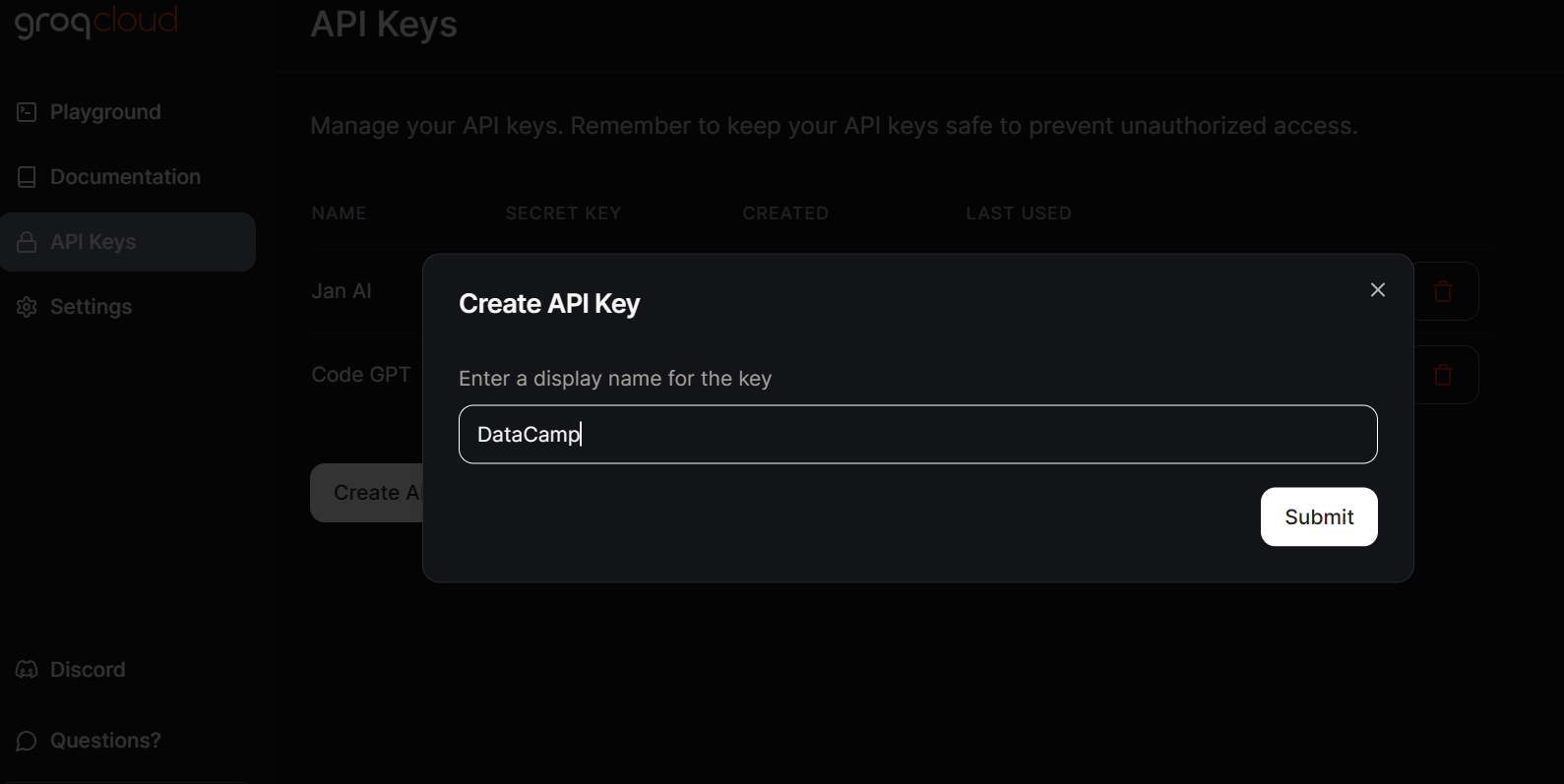
A Jan AI nos permite usar LLMs localmente, tanto modelos de código aberto quanto modelos proprietários. Ele é compatível com provedores de modelos como OpenAI, Anthropic, Cohere, MistralAI e Groq.
Faremos o download e instalaremos o Jan AI acessando o site oficial. Em seguida, podemos iniciar o aplicativo.
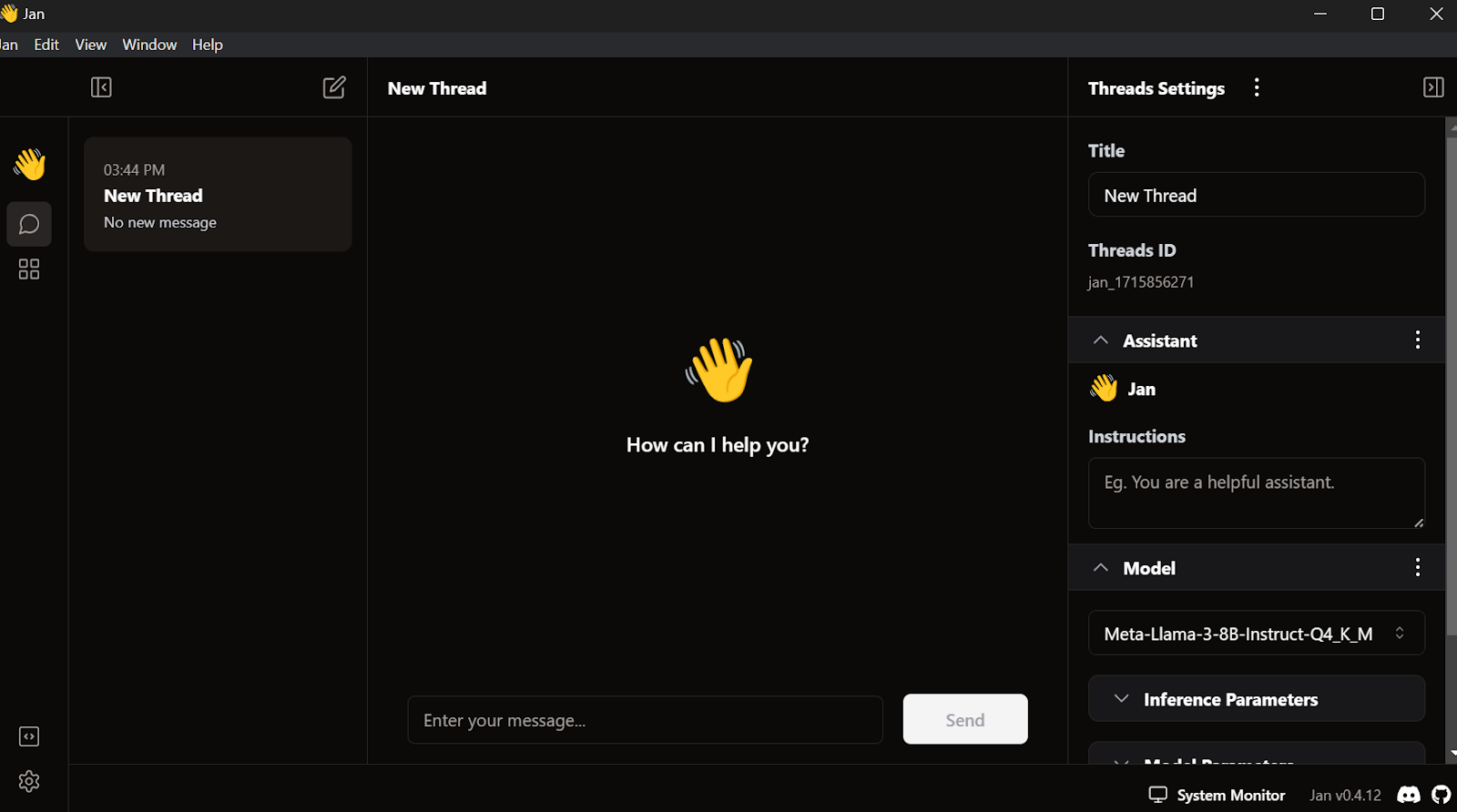
Vá para as configurações, selecione a guia Groq Inference Engine e cole a chave de API que acabamos de criar.
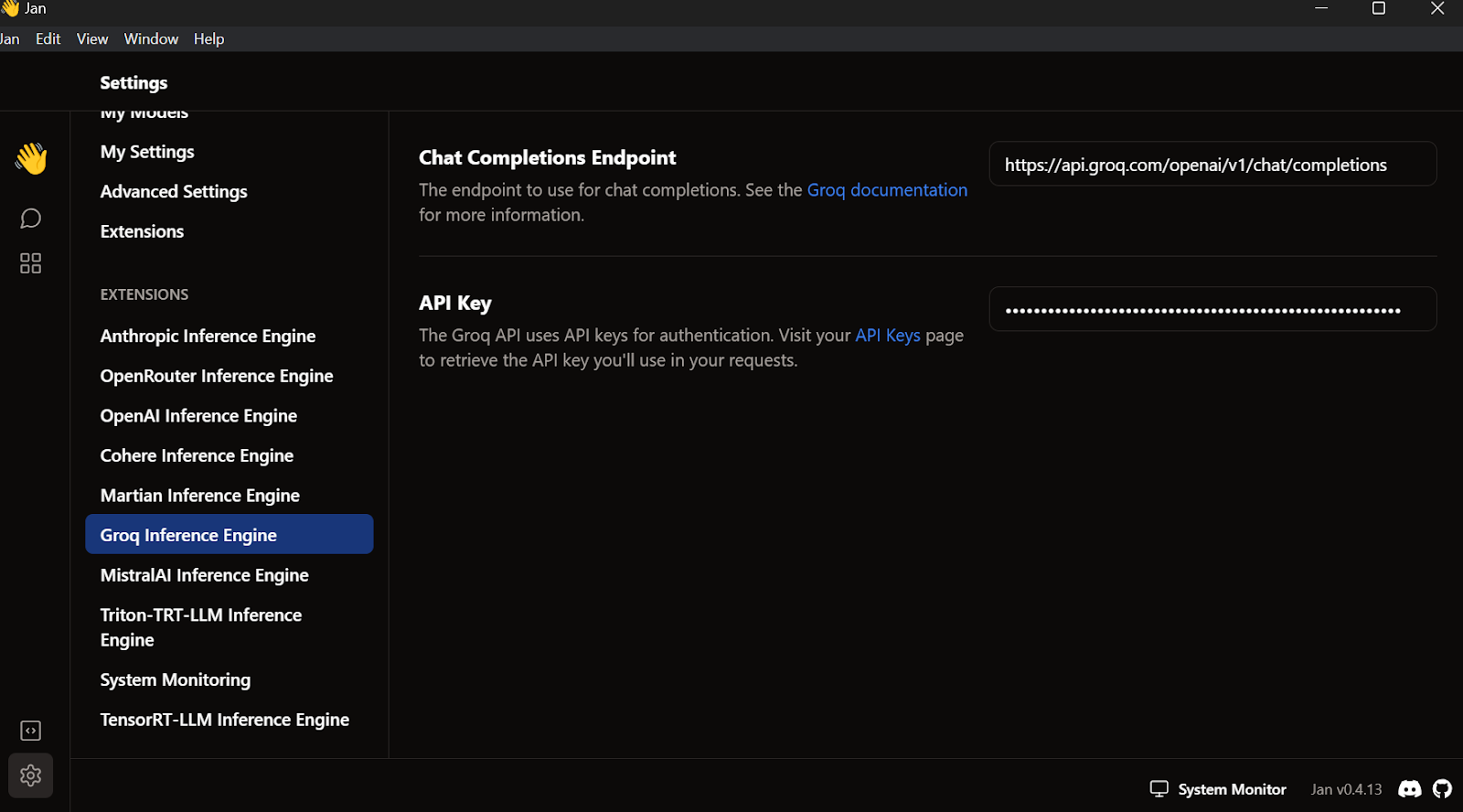
Saia do menu de configurações, vá para Thread e selecione o modelo Groq Llama 3 70b.
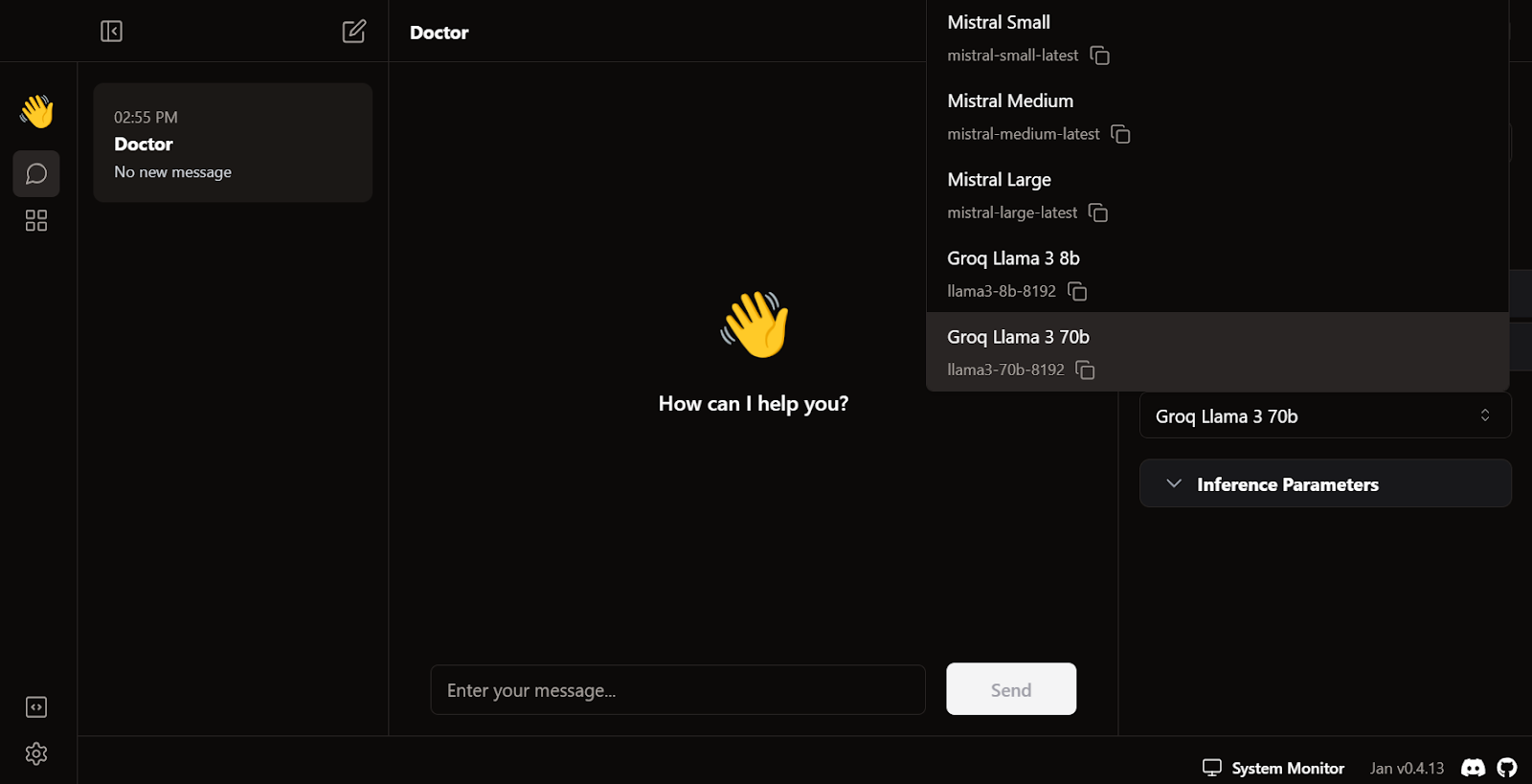
Escreva uma pergunta ou um prompt para gerar a resposta em tempo real:
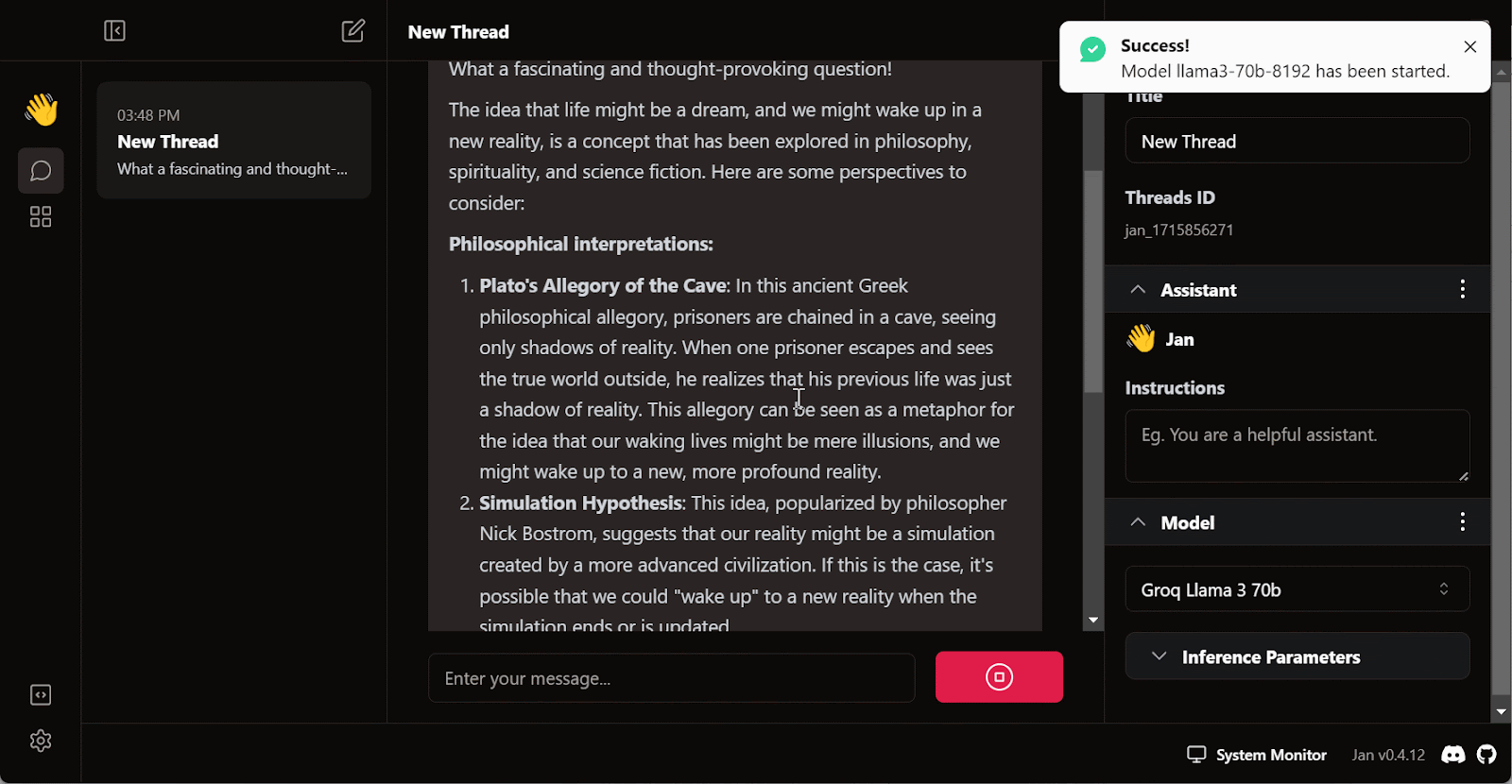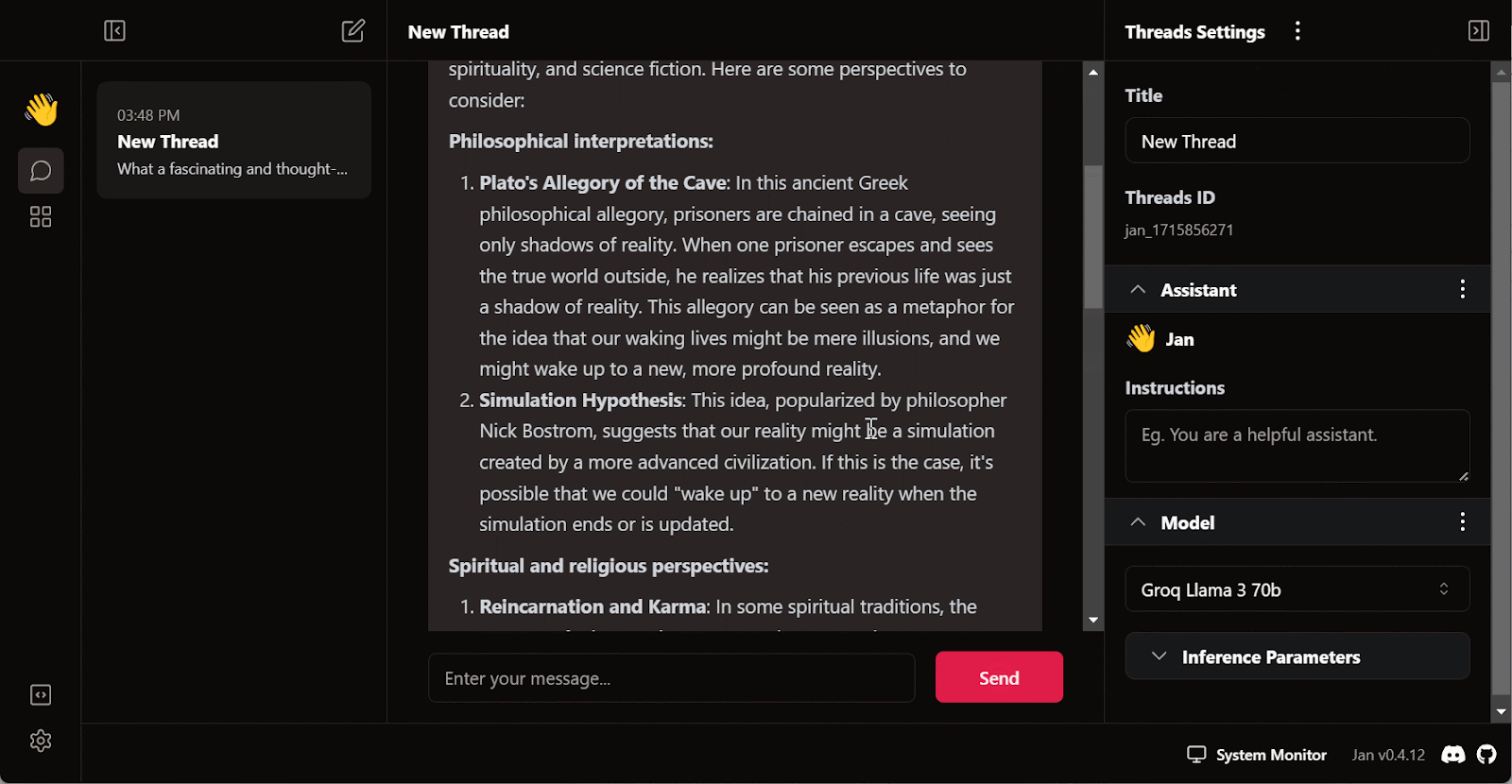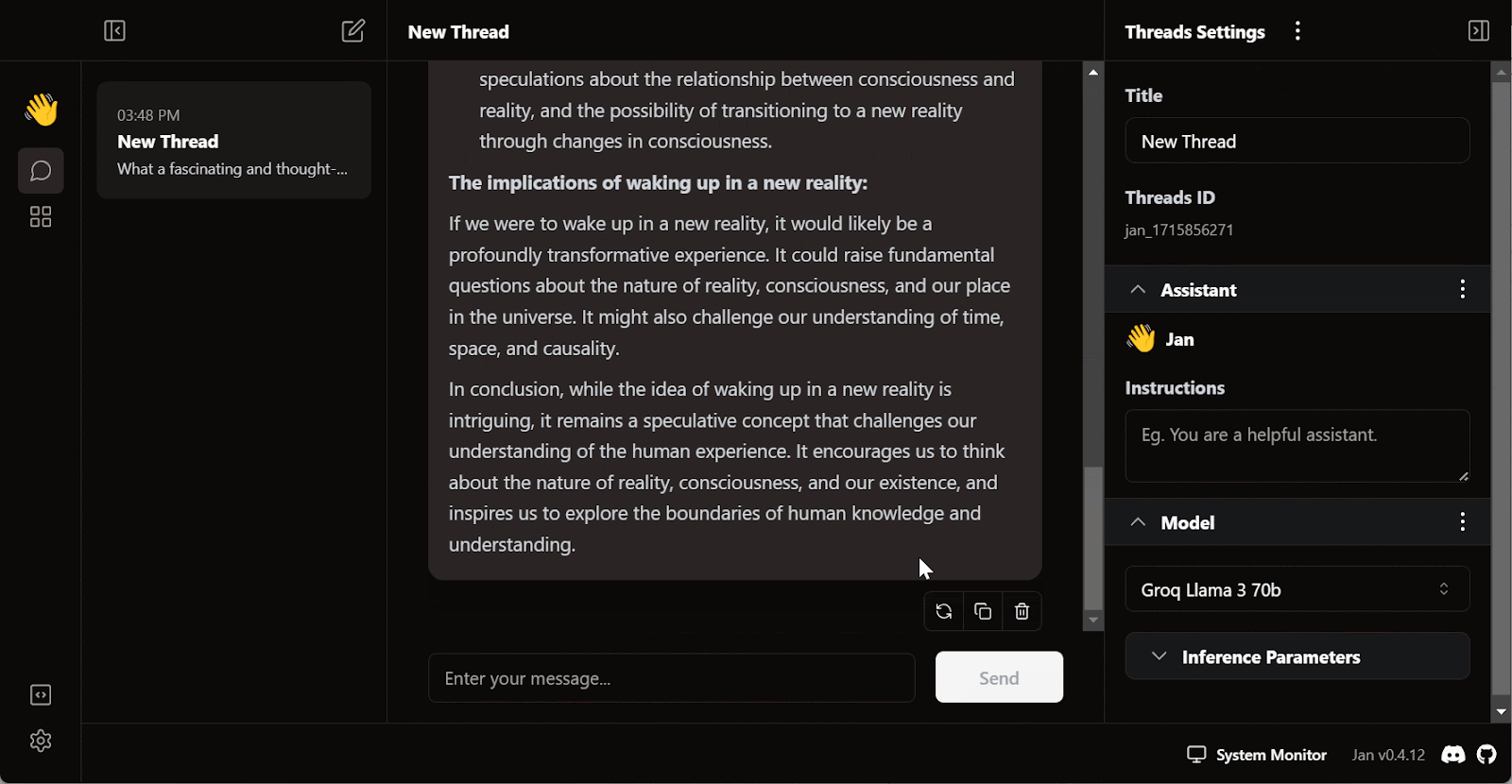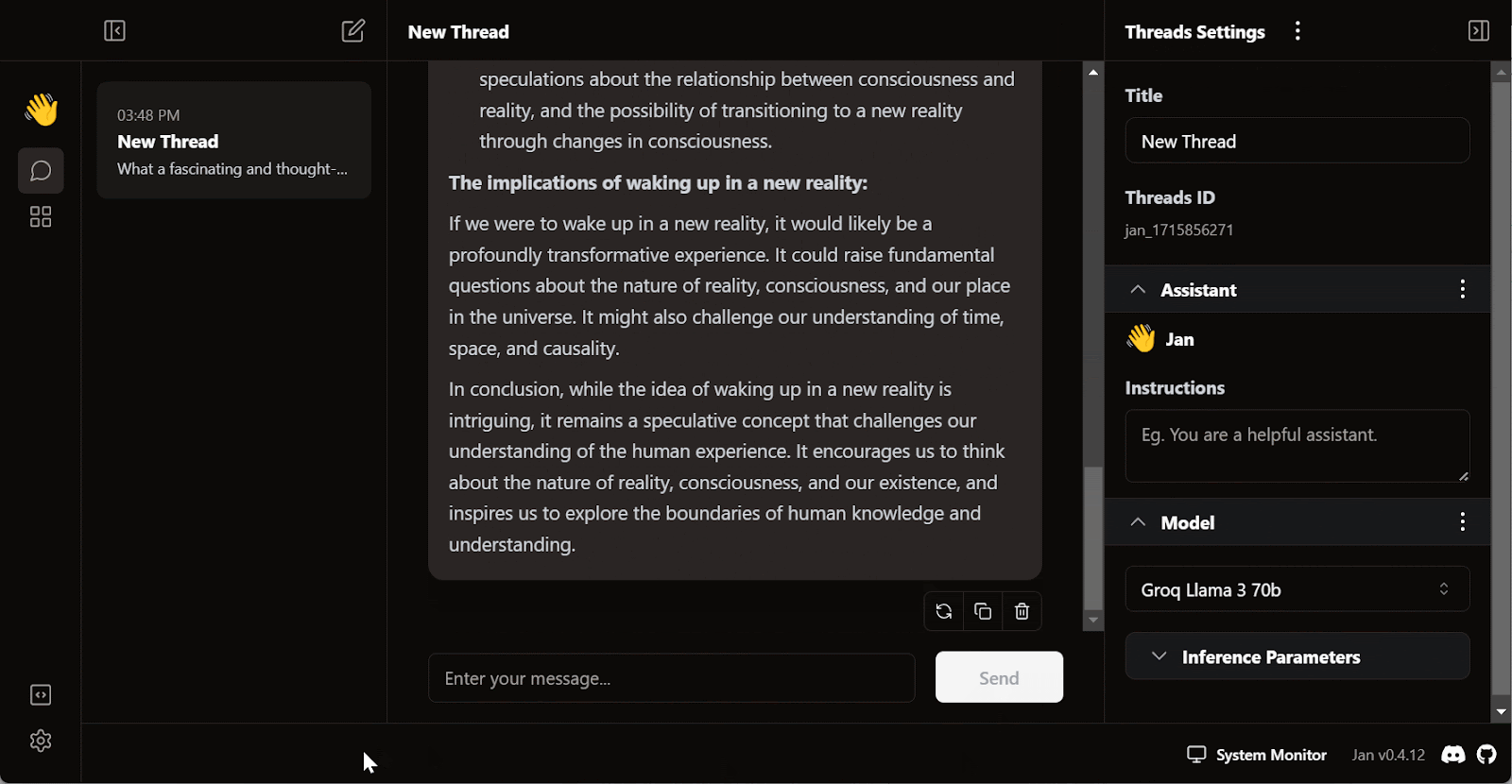
A assinatura gratuita do Groq Cloud vem com certas limitações de taxa. Por exemplo, o plano llama3-70b-8192 permite 30 solicitações por minuto, 14.400 solicitações por dia e 6.000 tokens por minuto. Embora essas limitações sejam generosas, se você pretende criar um aplicativo de IA adequado usando a API do Groq, talvez seja necessário considerar a atualização para o pacote On Demand ou Enterprise.
Você pode ler este tutorial sobre como executar LLMs localmente para explorar sete maneiras simples de executar aplicativos de IA localmente.
Além de usar a API do Groq em um aplicativo de chatbot, também podemos integrá-la ao VSCode usando a extensão CodeGPT. Ele será nosso assistente de codificação de IA super rápido.
Para acessar o modelo Groq no VSCode, precisamos instalar a extensão CodeGPT acessando o mercado de extensões.

Depois de instalada, configuraremos a chave da API do Groq clicando no ícone de bate-papo do CodeGPT no painel esquerdo e selecionando o provedor e o modelo. Selecionamos o Groq como provedor e o llama3-70b-8192 como modelo.
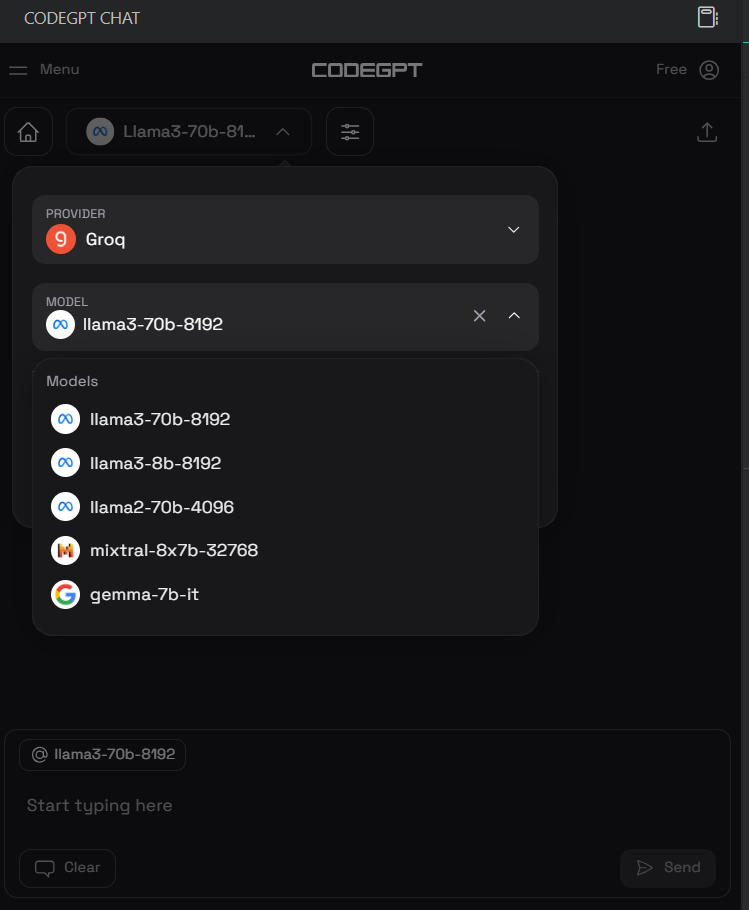
Depois disso, podemos escrever um prompt na caixa de bate-papo e gerar o código. Levamos alguns segundos para gerar o código adequado e criar o sistema de e-mail.
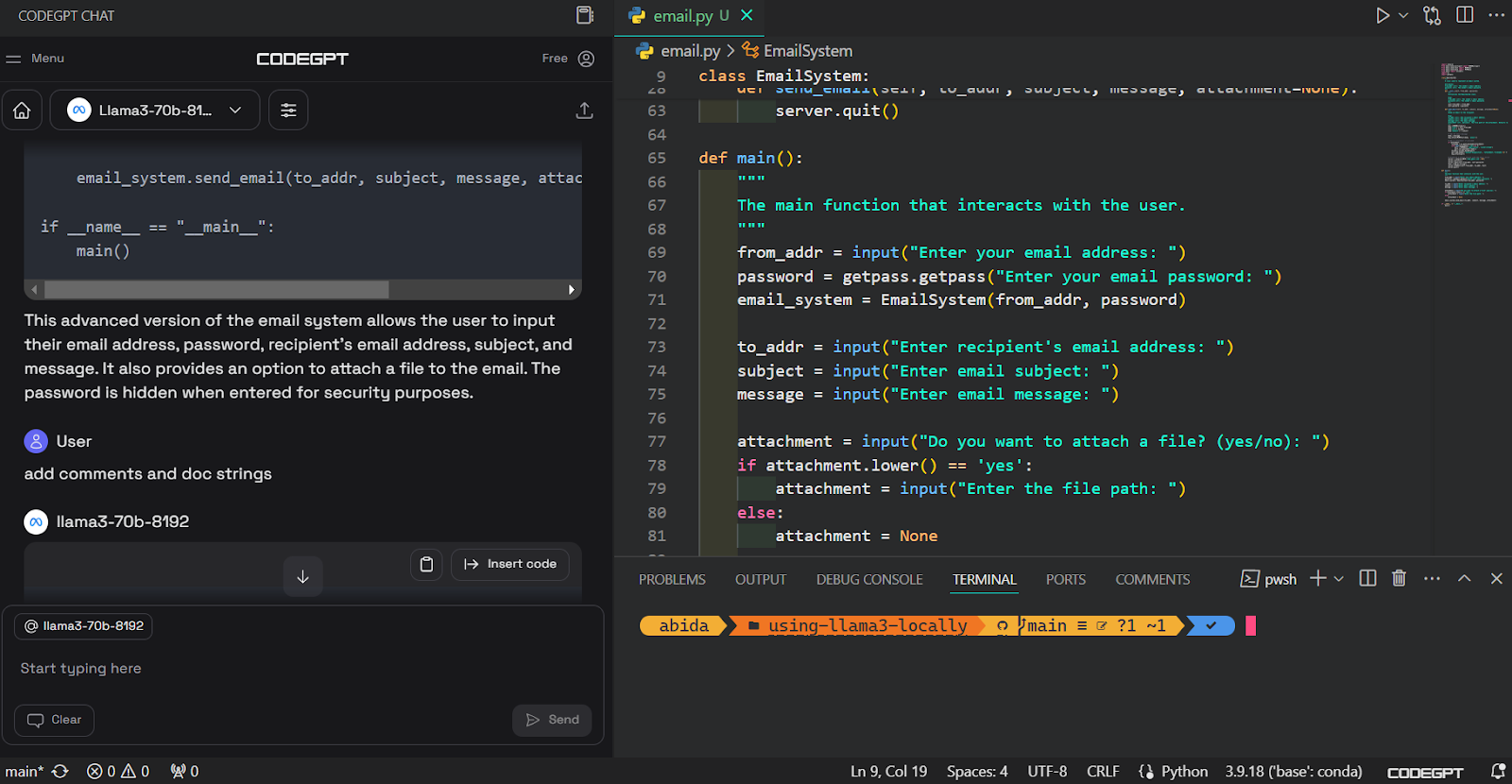
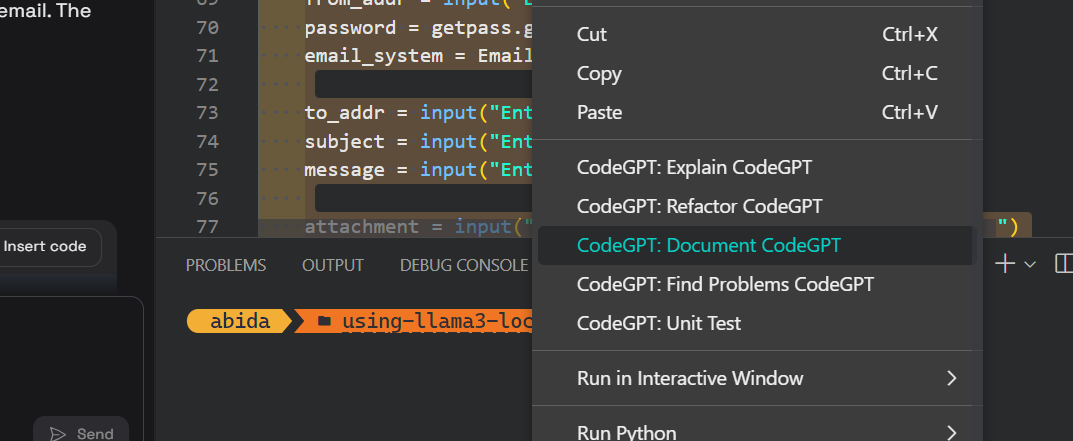
Em seguida, podemos documentar o código, refatorá-lo e criar o teste de unidade com comandos incorporados.
Você pode aprender sobre o VSCode lendo este tutorial sobre como configurar o VSCode para Python.
Nesta seção, aprenderemos os conceitos básicos da API Python do Groq e seus principais recursos, como streaming e conclusão de bate-papo assíncrono.
Para este guia, estamos usando o DataCamp's DataLab. O DataLab é um AI Cloud Jupyter Notebook que vem com vários recursos para escrever códigos, analisar dados e compartilhar percepções.
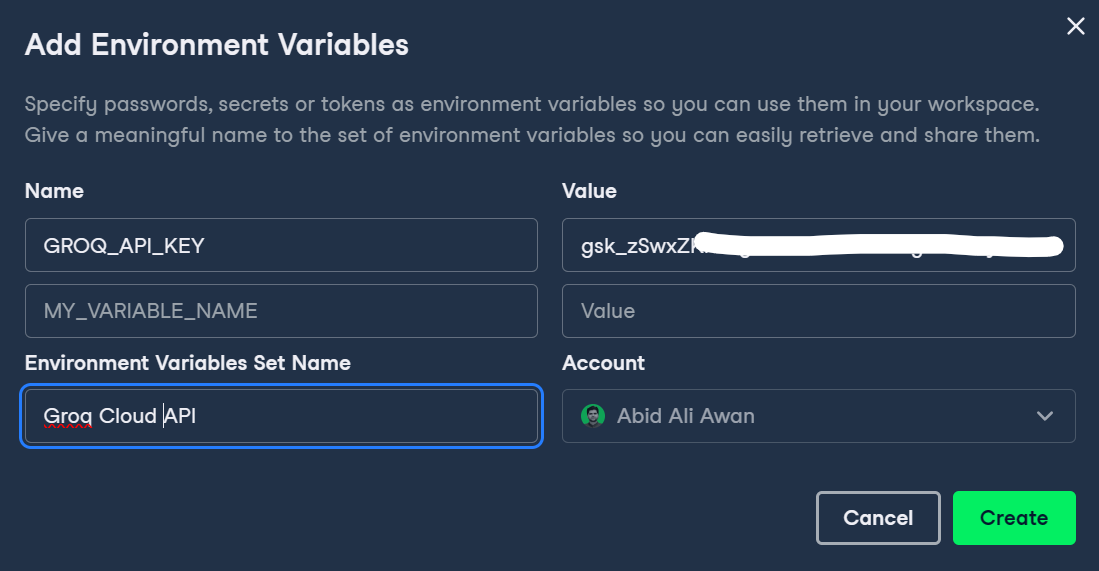
Primeiro, precisamos configurar a chave da API do Groq no DataLab clicando no botão Environment (Ambiente) no painel esquerdo e adicionando a variável de ambiente clicando no botão mais +.
Você pode escrever o nome da variável e colar a chave da API do Groq, conforme mostrado abaixo.
Em seguida, podemos ativar a variável de ambiente clicando nos três pontos ao lado da variável de ambiente do Groq e clicando em Conectar.

No final, instalaremos o pacote Groq Python usando o comando pip.
%pip install groq -qSe você já usou a API Python da OpenAI, talvez ache a estrutura do código semelhante. Para executar a conclusão do bate-papo:
import os
from groq import Groq
from IPython.display import display, Markdown
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
chat_completion = client.chat.completions.create(
messages=[
{"role": "system", "content": "You are a professional Data Scientist."},
{"role": "user", "content": "Can you explain how the neural networks work?"},
],
model="llama3-70b-8192",)
Markdown(chat_completion.choices[0].message.content)Como resultado, temos uma explicação perfeitamente formatada do que são as redes neurais.

O streaming em LLMs refere-se ao processamento e à geração de texto um token por vez, permitindo o uso eficiente da memória e melhorando a velocidade percebida do aplicativo de IA.
Nesses exemplos, ativamos o streaming e personalizamos o modelo alterando os hiperparâmetros, como temperatura, max_tokens e top_p.
chat_streaming = client.chat.completions.create(
messages=[
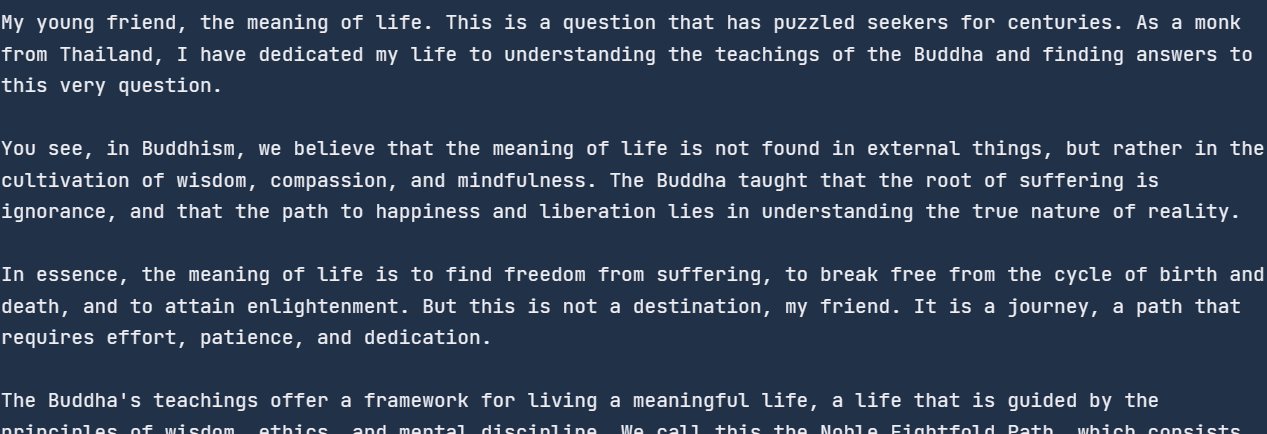
{"role": "system", "content": "You are a monk from Thailand."},
{"role": "user", "content": "Can you explain the meaning of life?"},
],
model="llama3-70b-8192",
temperature=0.3,
max_tokens=360,
top_p=1,
stop=None,
stream=True,
)
for chunk in chat_streaming:
print(chunk.choices[0].delta.content, end="")Como resultado, começamos a receber a resposta assim que executamos esse código.
As APIs assíncronas permitem lidar com várias solicitações simultâneas sem bloqueio, permitindo que o sistema processe e responda a cada solicitação de forma independente. Essa abordagem é mais eficiente e dimensionável, pois pode lidar com um volume maior de solicitações e fornecer tempos de resposta mais rápidos.
Para ativar a chamada de API assíncrona, precisamos alterar a estrutura do código. Nós:
Como observação lateral, o código abaixo funciona no Jupyter Notebook, mas se você estiver executando esse código no arquivo Python, talvez seja necessário alterar a última linha com asyncio.run(main()).
import asyncio
from groq import AsyncGroq
client = AsyncGroq(
api_key=os.environ.get("GROQ_API_KEY"),
)
async def main():
chat_completion = await client.chat.completions.create(
messages=[ {"role": "system", "content": "You are a psychiatrist helping young minds"},
{ "role": "user", "content": "I panicked during the test, even though I knew everything on the test paper.", },
],
model="llama3-70b-8192",
temperature=0.3,
max_tokens=360,
top_p=1,
stop=None,
stream=False,
)
print(chat_completion.choices[0].message.content)
await main() # for Python file use asyncio.run(main())
Também podemos transmitir a API assíncrona ativando o argumento stream na função de conclusão do chat e alterando a forma como imprimimos os resultados. Imprimiremos cada bloco usando o loop for com o comando async.
import asyncio
from groq import AsyncGroq
client = AsyncGroq()
async def main():
chat_streaming = await client.chat.completions.create(
messages=[
{"role": "system", "content": "You are a psychiatrist helping young minds"},
{ "role": "user", "content": "I panicked during the test, even though I knew everything on the test paper.", },
],
model="llama3-70b-8192",
temperature=0.3,
max_tokens=360,
top_p=1,
stop=None,
stream=True,
)
async for chunk in chat_streaming:
print(chunk.choices[0].delta.content, end="")
await main() # for Python file use asyncio.run(main())
Se você estiver com problemas para executar o código, consulte este notebook do DataLab: API do Groq Cloud.
Neste guia, daremos um passo adiante e aprenderemos a criar um aplicativo de IA usando a API Groq e o LlamaIndex, que é uma estrutura LLM. Criaremos um aplicativo que carregará o texto de um arquivo PDF, o converterá em incorporação e o salvará no armazenamento de vetores. Depois disso, converteremos o armazenamento de vetores no retriever que será usado para criar um mecanismo de bate-papo RAG com histórico.
Em resumo, estamos criando um aplicativo ChatPDF sensível ao contexto para ajudar você a entender o documento com muito mais rapidez.
Para saber como ingerir, gerenciar e recuperar dados privados e específicos de domínio usando linguagem natural, confira este tutorial: LlamaIndex: Uma estrutura de dados para modelos de linguagem grandes (LLMs).
Primeiro, instalaremos todos os pacotes Python necessários usando o pip. Usamos a função mágica %%capture para suprimir os registros.
%%capture
%pip install llama-index
%pip install llama-index-llms-groq
%pip install llama-index-embeddings-huggingfaceCriaremos o cliente Groq LLM usando a função llama_index. O cliente LLM requer um nome de modelo e a chave da API.
from llama_index.llms.groq import Groq
import os
llm =
Groq(model="llama3-70b-8192",api_key=os.environ.get("GROQ_API_KEY"))Agora, faremos o download e carregaremos o modelo de incorporação Hugging Face usando a API de incorporação LlamaIndex.
No nosso caso, estamos carregando o modelo de incorporação mais popular no Hugging Face, chamado mxbai-embed-large-v1.
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
embed_model =
HuggingFaceEmbedding(model_name="mixedbread-ai/mxbai-embed-large-v1")O LlamaIndex nos permite definir configurações globais, eliminando a necessidade de passar o LLM ou incorporar objetos de modelo em todos os lugares.
from llama_index.core import Settings
Settings.llm = llm
Settings.embed_model = embed_modelPara os dados, estamos usando a publicação do blog 14 Essential Data Engineering Tools to Use in 2024 e convertendo-os em um PDF usando o comando print.
Usando a função SimpleDirectoryReader, você pode carregar todos os tipos de documentos da pasta. Basta fornecer o diretório da pasta e as extensões de arquivo necessárias.
from llama_index.core import SimpleDirectoryReader
de_tools_blog = SimpleDirectoryReader("./",required_exts=[".pdf", ".docx"]).load_data()O VectorStoreIndex oferece a maneira mais rápida de criar o armazenamento de vetores, carregando os documentos e criando o índice. O índice pode ser usado para mecanismos de consulta, recuperadores e pipelines de consulta.
No nosso caso, estamos criando o índice fornecendo os documentos ao armazenamento de vetores, que converterá o texto em embeddings e o armazenará no armazenamento de vetores.
Depois disso, converteremos o índice no mecanismo de consulta para executar o RAG (retrieval augmented generation) básico, que combina os modelos de recuperação e IA para gerar uma resposta com reconhecimento de contexto.
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_documents(de_tools_blog)
query_engine = index.as_query_engine(similarity_top_k=3)
response = query_engine.query("How many tools are there?")
print(response)![]()
Agora, criaremos o mecanismo de chat do RAG com histórico. A adição do histórico permitirá que o mecanismo de bate-papo se lembre das mensagens do usuário e das respostas geradas e forneça respostas contextualizadas.
Para criar esse aplicativo, precisaremos criar o ChatMemoryBuffer de 3900 tokens e fornecê-lo ao mecanismo de bate-papo junto com o objeto retriever e LLM.
Quando você fizer uma pergunta, o mecanismo de bate-papo usará o documento PDF e as mensagens anteriores como contexto e responderá de acordo.
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.core.chat_engine import CondensePlusContextChatEngine
memory = ChatMemoryBuffer.from_defaults(token_limit=3900)
chat_engine = CondensePlusContextChatEngine.from_defaults(
index.as_retriever(),
memory=memory,
llm=llm
)
response = chat_engine.chat(
"What tools are suitable for data processing?"
)
print(str(response))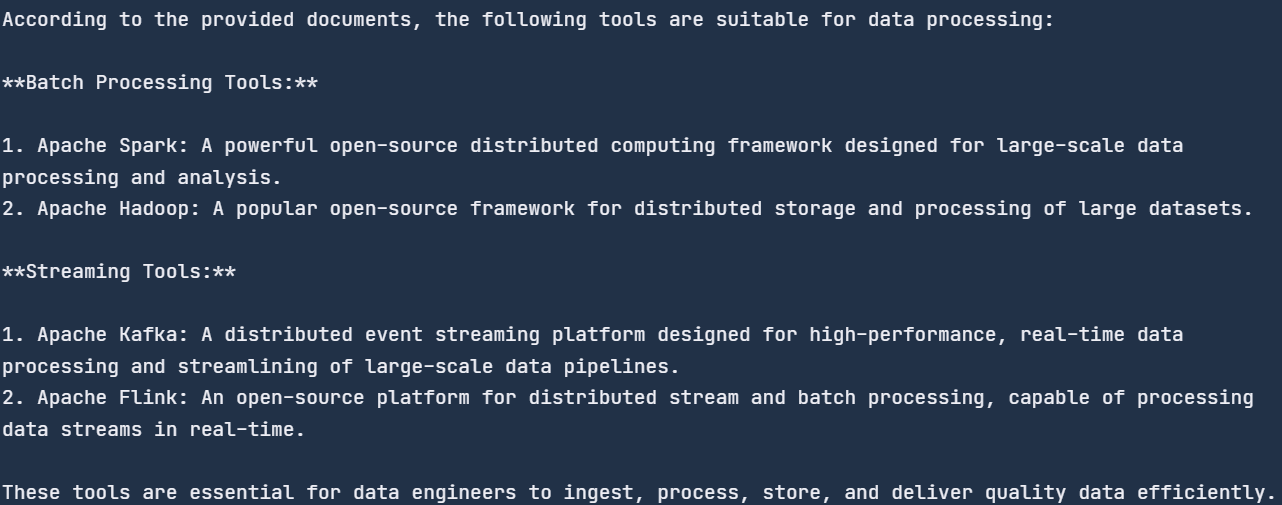
Fizemos perguntas genéricas, e ele pesquisou no documento as ferramentas de processamento de dados e nos forneceu a lista. Todas as ferramentas são mencionadas no blog.
Vamos fazer uma pergunta de acompanhamento para testar a parte de memória do mecanismo de bate-papo.
response = chat_engine.chat(
"Can you create a diagram of a data pipeline using these tools?"
)
print(str(response))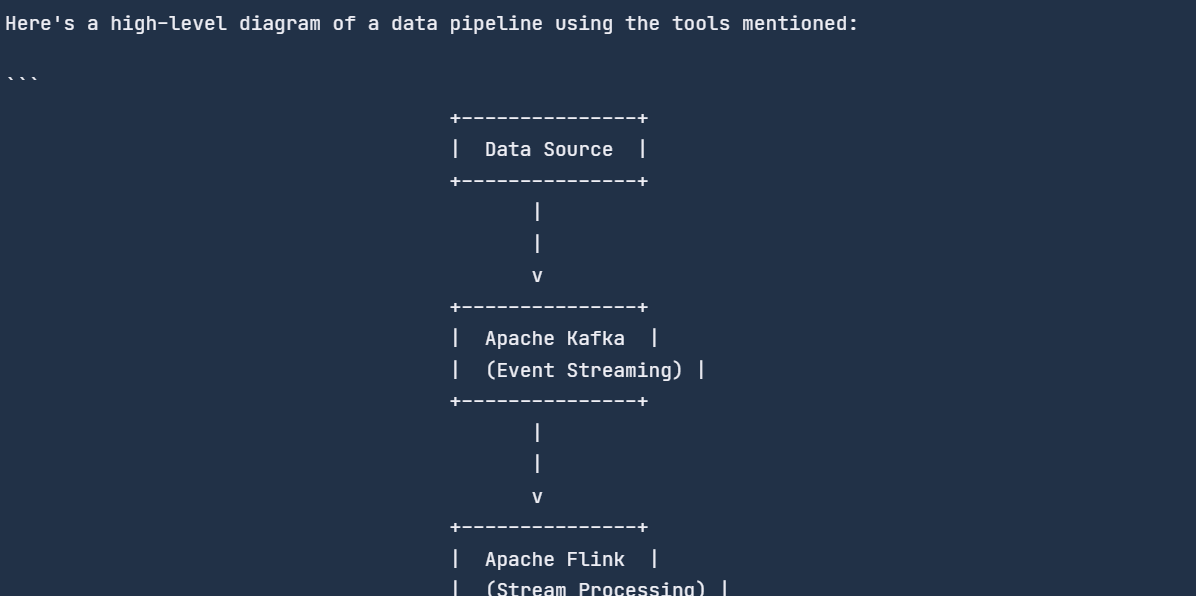
O mecanismo de bate-papo lembrava o bate-papo anterior e respondia de acordo.
Todo o código que usamos está disponível neste notebook do DataLab: API do Groq na nuvem - DataLab.
O mecanismo de inferência Groq LPU é um divisor de águas na IA. Enquanto os principais participantes, como a OpenAI e o Google, se concentram no desenvolvimento de LLMs de alta qualidade, a Groq torna esses modelos mais rápidos. Apesar de ser novo no cenário da IA, o Groq está causando um impacto significativo na comunidade de IA.
Neste blog, aprendemos sobre o mecanismo de inferência LPU do Groq, exploramos o Groq Cloud e integramos a API do Groq ao VSCode e ao aplicativo de IA Jan. Além disso, nos aprofundamos no pacote Groq Python com exemplos de código e aprendemos a criar um aplicativo de IA com reconhecimento de contexto que pode aprender com o histórico de bate-papo e documentos PDF.
Uma próxima etapa possível em sua jornada de aprendizado é o ajuste fino dos LLMs em um conjunto de dados personalizado. Você pode aprender como fazer isso seguindo este tutorial: Ajuste fino do Google Gemma: Aprimorando os LLMs com instruções personalizadas.
Aprenda com a DataCamp
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Thushan Ganegedara

