
Lernpfad
KI-Grundlagen für Unternehmen
12 Std.
Hast du dich schon mal gefragt, wie digitale Assistenten wie Alexa oder Google Assistant so präzise Antworten auf deine Fragen geben?
Die Magie dahinter heißt Retrieval-Augmented Generation (RAG), die Information Retrieval mit Techniken zur Sprachgenerierung kombiniert. Ein wichtiger Akteur in diesem Prozess ist ein Wissensgraph, der diesen Assistenten hilft, auf einen riesigen Pool strukturierter Informationen zuzugreifen, um ihre Antworten zu verbessern.
In diesem Tutorial lernen wir Wissensgraphen kennen und erfahren, wie sie genutzt werden können, um RAG-Anwendungen für genauere und relevante Antworten zu erstellen.
Wir beginnen damit, die Grundlagen von Wissensgraphen und ihre Rolle in der RAG zu erläutern. Wir werden diese mit Vektordatenbanken vergleichen und lernen, wann es am besten ist, die eine oder die andere zu verwenden. Dann werden wir einen Wissensgraphen aus Textdaten erstellen, ihn in einer Datenbank speichern und ihn nutzen, um relevante Informationen für Benutzeranfragen zu finden. Wir werden uns auch ansehen, wie wir diesen Ansatz erweitern können, um verschiedene Arten von Daten und Dateiformaten zu verarbeiten, die über reinen Text hinausgehen.
Wenn du mehr über RAG erfahren möchtest, schau dir diesen Artikel über Retrieval Augmented Generation an.
Wissensgraphen stellen Informationen in einem strukturierten, vernetzten Format dar. Sie bestehen aus Entitäten (Knoten) und Beziehungen (Kanten) zwischen diesen Entitäten. Entitäten können Objekte, Konzepte oder Ideen aus der realen Welt darstellen, während Beziehungen beschreiben, wie diese Entitäten miteinander verbunden sind.
Die Intuition hinter Wissensgraphen ist es, die Art und Weise nachzuahmen, wie Menschen die Welt verstehen und über sie denken. Wir speichern Informationen nicht in isolierten Silos, sondern stellen Verbindungen zwischen verschiedenen Informationen her und bilden so ein reichhaltiges, miteinander verbundenes Wissensnetz.
Wissensgraphen helfen uns zu erkennen, wie Entitäten miteinander verbunden sind, indem sie die Beziehungen zwischen verschiedenen Entitäten klar darstellen. Das Erforschen dieser Verbindungen ermöglicht es uns, neue Informationen zu finden und Schlussfolgerungen zu ziehen, die aus einzelnen Informationen nur schwer zu ziehen wären.
Schauen wir uns ein Beispiel an.
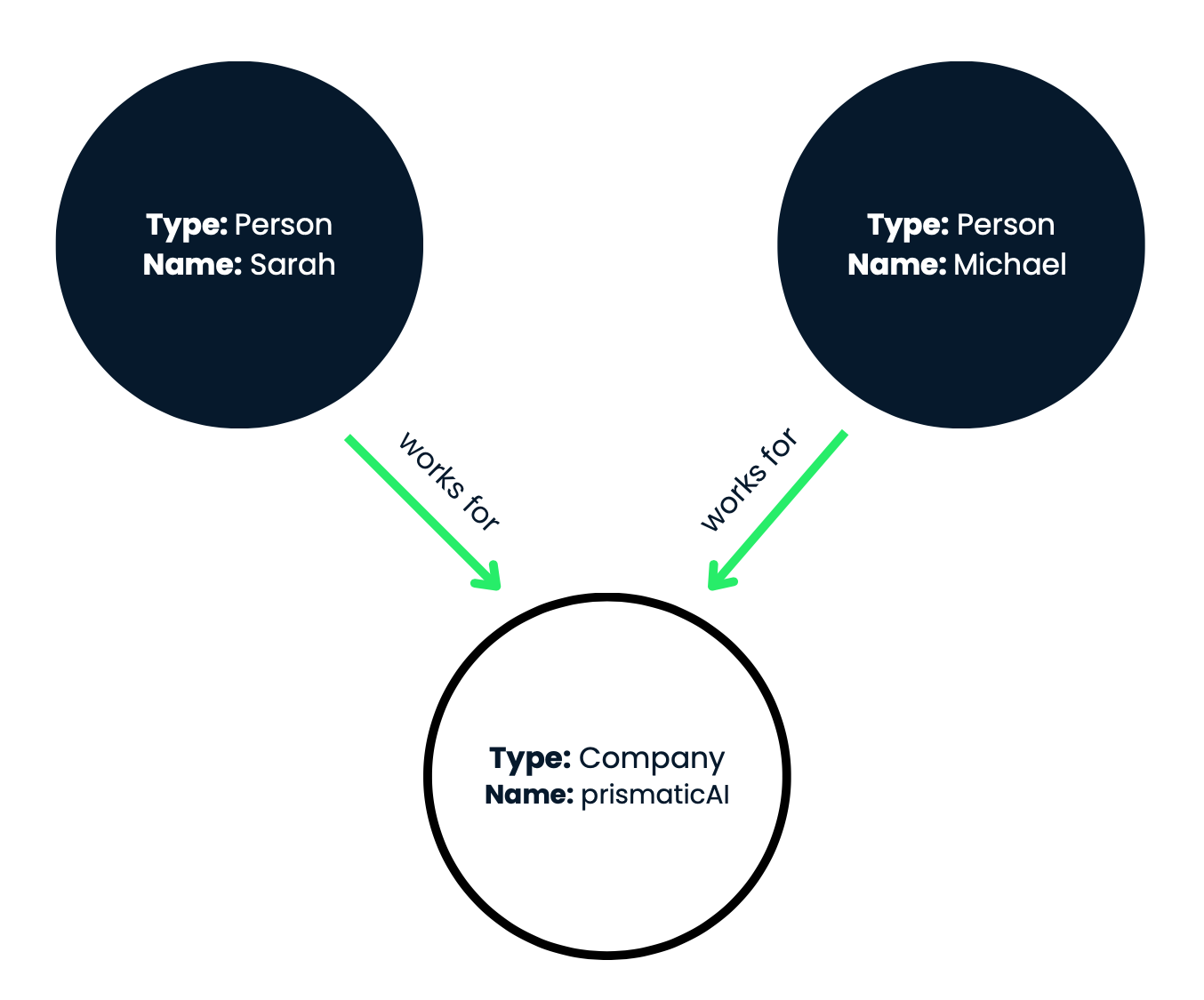
Abbildung 1: In dieser visuellen Darstellung werden die Knoten als Kreise und die Beziehungen als beschriftete Pfeile, die die Knoten verbinden, dargestellt.
Dieser Wissensgraph erfasst effektiv die Beschäftigungsverhältnisse zwischen den Personen Sarah und Michael und dem Unternehmen prismaticAI. In unserem Beispiel haben wir drei Knotenpunkte:
Wir haben also zwei Personenknoten (Sarah und Michael) und einen Unternehmensknoten (prismaticAI). Schauen wir uns nun die Beziehungen (Kanten) zwischen diesen Knotenpunkten an:
Einer der mächtigsten Aspekte von Wissensgraphen ist die Möglichkeit, die Beziehungen zwischen Entitäten abzufragen und zu durchlaufen, um relevante Informationen zu extrahieren oder neues Wissen abzuleiten. Sehen wir uns an, wie wir das mit unserem Beispiel-Wissensgraphen machen können.
Zuerst müssen wir festlegen, welche Informationen wir aus dem Wissensgraphen abrufen wollen. Zum Beispiel:
Abfrage 1: Wo arbeitet Sarah?
Um die Anfrage zu beantworten, müssen wir den passenden Startpunkt im Wissensgraphen finden. In diesem Fall wollen wir mit dem Knoten beginnen, der Sarah repräsentiert.
Vom Startpunkt (Sarahs Knotenpunkt) aus folgen wir der ausgehenden Beziehungskante "arbeitet für". Diese Kante verbindet Sarahs Knoten mit dem Knoten, der prismaticAI darstellt. Wenn wir die Beziehung "arbeitet für" durchgehen, können wir feststellen, dass Sarah für prismaticAI arbeitet.
Antwort 1: Sarah arbeitet für prismaticAI.
Versuchen wir eine andere Abfrage:
Abfrage 2: Wer arbeitet für prismaticAI?
Dieses Mal wollen wir mit dem Knoten beginnen, der prismaticAI repräsentiert.
Vom PrismaticAI-Knotenpunkt aus folgen wir den Beziehungskanten "arbeitet für" rückwärts. Das führt uns zu den Knotenpunkten, die die Menschen repräsentieren, die für prismaticAI arbeiten. Wenn wir die "arbeitet für"-Beziehungen in umgekehrter Reihenfolge durchgehen, können wir feststellen, dass sowohl Sarah als auch Michael für prismaticAI arbeiten.
Antwort 2: Sarah und Michael arbeiten für prismaticAI.
Ein weiteres Beispiel!
Abfrage 3: Arbeitet Michael für die gleiche Firma wie Sarah?
Wir können entweder von Sarahs Knotenpunkt oder von Michaels Knotenpunkt aus starten. Beginnen wir bei Sarahs Knotenpunkt.
Wir folgen der "works for"-Beziehung, um den prismatischenAI-Knoten zu erreichen.
Dann prüfen wir, ob Michael auch eine "arbeitet für"-Beziehung hat, die zu demselben prismatischenAI-Knoten führt. Da sowohl Sarah als auch Michael eine "arbeitet für"-Beziehung mit dem prismaticAI-Knoten haben, können wir daraus schließen, dass sie für dasselbe Unternehmen arbeiten.
Antwort 3: Ja, Michael arbeitet für das gleiche Unternehmen wie Sarah (prismaticAI).
Das Durchlaufen der Beziehungen im Wissensgraphen ermöglicht es uns, bestimmte Informationen zu extrahieren und die Verbindungen zwischen Entitäten zu verstehen. Wissensgraphen können viel komplexer werden, mit zahlreichen Knoten und Beziehungen, die es ermöglichen, komplexes Wissen aus der realen Welt strukturiert und vernetzt darzustellen.
RAG-Anwendungen kombinieren Information Retrieval und die Generierung natürlicher Sprache, um relevante und kohärente Antworten auf Benutzeranfragen oder Aufforderungen zu geben. Wissensgraphen bieten mehrere Vorteile, die sie für diese Anwendungen besonders gut geeignet machen. Lass uns die wichtigsten Vorteile kennenlernen:
Wie wir im vorherigen Abschnitt gelernt haben, stellen Wissensgraphen Informationen auf strukturierte Weise dar, mit Entitäten (Knoten) und ihren Beziehungen (Kanten). Diese strukturierte Darstellung macht es einfacher, relevante Informationen für eine bestimmte Anfrage oder Aufgabe zu finden, als unstrukturierte Textdaten.
In unserem Beispiel-Wissensgraphen können wir ganz einfach Informationen darüber abrufen, wer für prismaticAI arbeitet, indem wir den "arbeitet für"-Beziehungen folgen.
Wissensgraphen erfassen die Beziehungen zwischen Entitäten und ermöglichen ein tieferes Verständnis des Kontexts, in dem Informationen präsentiert werden. Dieses kontextbezogene Verständnis ist entscheidend für die Erstellung kohärenter und relevanter Antworten in RAG-Anträgen.
Um auf unser Beispiel zurückzukommen: Wenn du die Beziehung zwischen Sarah, Michael und prismaticAI verstehst, kann eine RAG-Anwendung kontextbezogenere Antworten über ihre Beschäftigung geben.
Das Durchlaufen der Beziehungen in einem Wissensgraphen ermöglicht es RAG-Anwendungen, Schlussfolgerungen zu ziehen und neues Wissen abzuleiten, das möglicherweise nicht explizit angegeben ist. Diese Fähigkeit zum schlussfolgernden Denken verbessert die Qualität und Vollständigkeit der generierten Antworten.
Durch das Durchgehen der Beziehungen kann eine RAG-Anwendung darauf schließen, dass Sarah und Michael für dasselbe Unternehmen arbeiten, auch wenn diese Information nicht direkt angegeben wird.
Wissensgraphen können Informationen aus verschiedenen Quellen integrieren, so dass RAG-Anwendungen verschiedene und sich ergänzende Wissensgrundlagen nutzen können. Diese Integration von Wissen kann zu umfassenderen und fundierteren Antworten führen.
Wir könnten unserem Wissensgraphen Informationen über Unternehmen, Mitarbeiter und ihre Rollen aus verschiedenen Quellen hinzufügen, um ein vollständigeres Bild für die Erstellung von Antworten zu erhalten.
Wissensgraphen bieten eine transparente Darstellung des Wissens, das bei der Erstellung von Antworten verwendet wird. Diese Transparenz ist wichtig, um die Gründe für die erzeugten Ergebnisse zu erklären, was bei vielen Anwendungen, wie z.B. Frage-Antwort-Systemen, wichtig ist.
Die Erklärung für Antwort 3 in unserem Beispiel könnte lauten: Ja, Michael arbeitet für die gleiche Firma wie Sarah. Ich kam zu dieser Schlussfolgerung, indem ich feststellte, dass Sarah für prismaticAI arbeitet, und dann überprüfte, dass Michael auch eine Beziehung zu prismaticAI hat. Da sie beide eine Beziehung zu demselben Unternehmen haben, kann ich daraus schließen, dass sie für dasselbe Unternehmen arbeiten.
Durch diese Transparenz im Argumentationsprozess können Nutzer und Entwickler nachvollziehen, wie die RAG-Anwendung zu ihrer Antwort gekommen ist, anstatt sie als Blackbox zu behandeln. Außerdem wird das Vertrauen in das System gestärkt, da der Entscheidungsprozess klar dargelegt ist und anhand des Wissensgraphen überprüft werden kann.
Wenn es Unstimmigkeiten oder fehlende Informationen im Wissensgraphen gibt, kann die Erklärung helfen, diese Probleme zu erkennen und zu beheben, was zu einer besseren Genauigkeit und Vollständigkeit der Antworten führt.
Mit Wissensgraphen können RAG-Anwendungen genauere, klarere und verständlichere Antworten geben. Das macht sie für verschiedene Aufgaben in der natürlichen Sprachverarbeitung nützlich.
Beim Aufbau von RAG-Anwendungen kannst du auf zwei verschiedene Ansätze stoßen: Wissensgraphen und Vektordatenbanken. Obwohl beide zur Darstellung und zum Abruf von Informationen verwendet werden, unterscheiden sie sich in ihren zugrundeliegenden Datenstrukturen und der Art und Weise, wie sie Informationen verarbeiten.
Sehen wir uns die wichtigsten Unterschiede zwischen diesen beiden Ansätzen an:
|
Feature |
Wissensgraphen |
Vektordatenbanken |
|
Darstellung der Daten |
Entitäten (Knoten) und Beziehungen (Kanten) zwischen Entitäten, die eine Graphenstruktur bilden. |
Hochdimensionale Vektoren, die jeweils eine Information (z. B. ein Dokument, einen Satz) darstellen. |
|
Abrufmechanismen |
Durchlaufen der Graphenstruktur und Verfolgen der Beziehungen zwischen den Entitäten. Ermöglicht Schlussfolgerungen und die Ableitung von neuem Wissen. |
Vektorielle Ähnlichkeit basierend auf einer Ähnlichkeitsmetrik (z.B. Cosinusähnlichkeit). Gibt die ähnlichsten Vektoren und die dazugehörigen Informationen zurück. |
|
Interpretierbarkeit |
Von Menschen interpretierbare Darstellung von Wissen. Die Struktur des Graphen und die beschrifteten Beziehungen verdeutlichen die Verbindungen zwischen den Entitäten. |
Aufgrund der hochdimensionalen numerischen Darstellungen sind sie für Menschen weniger interpretierbar. Es ist schwierig, Zusammenhänge oder Überlegungen hinter den abgerufenen Informationen direkt zu verstehen. |
|
Wissensintegration |
Erleichtert die Integration durch die Darstellung von Entitäten und Beziehungen in einer einheitlichen Graphenstruktur. Nahtlose Integration, wenn Entitäten und Beziehungen richtig abgebildet werden. |
Eine größere Herausforderung. Erfordert Techniken wie Vektorraum-Alignment oder Ensemble-Methoden, um Informationen zu kombinieren. Die Gewährleistung der Vektorkompatibilität kann nicht trivial sein. |
|
Schlussfolgernde Argumentation |
Ermöglicht schlussfolgernde Schlussfolgerungen, indem die Graphenstruktur durchlaufen und Beziehungen zwischen Entitäten genutzt werden. Deckt implizite Zusammenhänge auf und leitet neue Erkenntnisse ab. |
Mehr eingeschränkt. Verlässt sich auf Vektorähnlichkeit und kann implizite Beziehungen oder Schlussfolgerungen übersehen. Kann ähnliche Informationen, aber keine komplexen Beziehungen aus Wissensgraphen erkennen. |
Sowohl Wissensgraphen als auch Vektordatenbanken haben ihre Stärken und Anwendungsfälle, und die Wahl zwischen ihnen hängt von den spezifischen Anforderungen deiner Anwendung ab. Wissensgraphen eignen sich hervorragend, um strukturiertes Wissen darzustellen und Schlussfolgerungen zu ziehen, während Vektordatenbanken gut für Aufgaben geeignet sind, die sich stark auf semantische Ähnlichkeit und die Suche nach Informationen auf der Grundlage von Vektordarstellungen stützen.
Mehr über Vektordatenbanken erfährst du in dieser Einführung in Vektordatenbanken für maschinelles Lernen. Außerdem findest du hier die fünf beliebtesten Vektordatenbanken.
In diesem Abschnitt werden wir untersuchen, wie man einen Wissensgraphen implementiert, um den Sprachgenerierungsprozess für die RAG-Anwendung zu erweitern.
Wir gehen auf die folgenden wichtigen Schritte ein:
Am Ende dieses Abschnitts wirst du ein solides Verständnis für die Implementierung von Wissensgraphen in RAG-Anwendungen haben, das es dir ermöglicht, intelligentere und kontextbezogene Sprachgenerierungssysteme zu entwickeln.
Bevor wir beginnen, solltest du sicherstellen, dass du Folgendes installiert hast:
pip install langchain)pip install llama-index)Der erste Schritt besteht darin, die Textdaten, aus denen wir den Wissensgraphen extrahieren wollen, zu laden und vorzuverarbeiten. In diesem Beispiel verwenden wir einen Textausschnitt, der ein Technologieunternehmen namens prismaticAI, seine Mitarbeiter und ihre Aufgaben beschreibt.
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
# Load text data
text = """Sarah is an employee at prismaticAI, a leading technology company based in Westside Valley. She has been working there for the past three years as a software engineer.
Michael is also an employee at prismaticAI, where he works as a data scientist. He joined the company two years ago after completing his graduate studies.
prismaticAI is a well-known technology company that specializes in developing cutting-edge software solutions and artificial intelligence applications. The company has a diverse workforce of talented individuals from various backgrounds.
Both Sarah and Michael are highly skilled professionals who contribute significantly to prismaticAI's success. They work closely with their respective teams to develop innovative products and services that meet the evolving needs of the company's clients."""
loader = TextLoader(text)
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=200, chunk_overlap=20)
texts = text_splitter.split_documents(documents)Wir beginnen mit dem Import der notwendigen Klassen von LangChain: TextLoader und CharacterTextSplitter. TextLoader lädt die Textdaten, während CharacterTextSplitter den Text in kleinere Stücke aufteilt, um ihn effizienter zu verarbeiten.
Als Nächstes definieren wir die Textdaten als eine mehrzeilige String-Variable text.
Wir verwenden dann TextLoader, um die Textdaten direkt aus der Textvariable zu laden. Die Methode loader.load() gibt eine Liste von Document Objekten zurück, die jeweils ein Stück des Textes enthalten.
Um den Text in kleinere, überschaubare Teile aufzuteilen, erstellen wir eine Instanz von CharacterTextSplitter mit einer chunk_size von 200 Zeichen und einer chunk_overlap von 20 Zeichen. Der Parameter chunk_overlap stellt sicher, dass es eine gewisse Überlappung zwischen benachbarten Chunks gibt, was hilfreich sein kann, um den Kontext während der Wissensextraktion zu erhalten.
Schließlich verwenden wir die split_documents Methode von CharacterTextSplitter, um die Document Objekte in kleinere Stücke zu zerlegen, die in der Variable texts als Liste von Document Objekten gespeichert werden.
Durch diese Vorverarbeitung der Textdaten können wir sie für den nächsten Schritt vorbereiten, in dem wir ein Sprachmodell initialisieren und es verwenden, um einen Wissensgraphen aus den Textstücken zu extrahieren.
Nach dem Laden und der Vorverarbeitung der Textdaten wird im nächsten Schritt ein Sprachmodell initialisiert und damit ein Wissensgraph aus den Textstücken extrahiert. In diesem Beispiel verwenden wir das OpenAI-Sprachmodell, das von LangChain bereitgestellt wird.
from langchain.llms import OpenAI
from langchain.transformers import LLMGraphTransformer
import getpass
import os
# Load environment variable for OpenAI API key
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Initialize LLM
llm = OpenAI(temperature=0)
# Extract Knowledge Graph
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(texts)Zuerst importieren wir die notwendigen Klassen von LangChain: OpenAI und LLMGraphTransformer. OpenAI ist ein Wrapper für das OpenAI-Sprachmodell, das wir verwenden werden, um den Wissensgraphen zu extrahieren. LLMGraphTransformer ist eine Hilfsklasse, die dabei hilft, Textdaten in eine Wissensgraphen-Darstellung zu konvertieren.
Als nächstes laden wir den OpenAI API-Schlüssel aus einer Umgebungsvariablen. Dies ist eine bewährte Sicherheitspraxis, um zu vermeiden, dass sensible Anmeldeinformationen in deinem Code fest codiert werden.
Wir initialisieren dann eine Instanz des OpenAI Sprachmodells mit einer Temperatur von 0. Der Temperaturparameter steuert die Zufälligkeit der Ausgabe des Modells, wobei niedrigere Werte zu deterministischeren Antworten führen.
Nach der Initialisierung des Sprachmodells erstellen wir eine Instanz von LLMGraphTransformer und übergeben das initialisierte llm Objekt an sie. Die Klasse LLMGraphTransformer wandelt die Textbausteine (texts) in eine Wissensgraphen-Darstellung um.
Schließlich rufen wir die Methode convert_to_graph_documents von LLMGraphTransformer auf und übergeben die Textliste. Diese Methode nutzt das Sprachmodell, um die Textabschnitte zu analysieren und relevante Entitäten, Beziehungen und andere strukturierte Informationen zu extrahieren, die dann als Wissensgraph dargestellt werden. Der resultierende Wissensgraph wird in der Variable graph_documents gespeichert.
Wir haben erfolgreich ein Sprachmodell initialisiert und es verwendet, um einen Wissensgraphen aus den Textdaten zu extrahieren. Im nächsten Schritt werden wir den Wissensgraphen in einer Datenbank speichern, um ihn aufzubewahren und abzufragen.
Nachdem du den Wissensgraphen aus den Textdaten extrahiert hast, ist es wichtig, ihn in einem persistenten und abfragbaren Format zu speichern. In diesem Lernprogramm verwenden wir Neo4j, um den Wissensgraphen zu speichern.
from langchain.graph_stores import Neo4jGraphStore
# Store Knowledge Graph in Neo4j
graph_store = Neo4jGraphStore(url="neo4j://your_neo4j_url", username="your_username", password="your_password")
graph_store.write_graph(graph_documents)Zuerst importieren wir die Klasse Neo4jGraphStore von LangChain. Diese Klasse bietet eine praktische Schnittstelle für die Interaktion mit einer Neo4j-Datenbank und die Speicherung von Wissensgraphen.
Als Nächstes erstellen wir eine Instanz von Neo4jGraphStore, indem wir die notwendigen Verbindungsdetails angeben: die URL der Neo4j-Datenbank, den Benutzernamen und das Passwort. Achte darauf, dass du "your_neo4j_url", "your_username" und "your_password" durch die entsprechenden Werte für deine Neo4j-Instanz ersetzt.
Schließlich rufen wir die Methode write_graph der Instanz graph_store auf und übergeben die Liste graph_documents, die wir im vorherigen Schritt erhalten haben. Diese Methode serialisiert den Wissensgraphen und schreibt ihn in die Neo4j-Datenbank.
Indem wir den Wissensgraphen in einer Neo4j-Datenbank speichern, können wir sicherstellen, dass er beständig ist und bei Bedarf einfach abgefragt und abgerufen werden kann. Die Graphenstruktur von Neo4j ermöglicht eine effiziente Darstellung und Durchquerung der komplexen Beziehungen und Entitäten, die im Wissensgraphen vorhanden sind.
Im nächsten Schritt richten wir die Komponenten ein, mit denen wir Wissen aus dem Graphen abrufen und Antworten aus dem abgerufenen Kontext erzeugen.
Es ist wichtig zu wissen, dass dieses Tutorial zwar Neo4j als Graphdatenbank verwendet, LangChain aber auch andere Graphdatenbanken wie Amazon Neptune und TinkerPop-kompatible Datenbanken wie Gremlin Server unterstützt. Du kannst die Neo4jGraphStore mit der entsprechenden Graph-Store-Implementierung für deine gewählte Datenbank austauschen.
Jetzt, wo wir den Wissensgraphen in einer Datenbank gespeichert haben, können wir die Komponenten einrichten, um relevantes Wissen aus dem Graphen auf der Grundlage von Benutzeranfragen abzurufen und Antworten unter Verwendung des abgerufenen Kontexts zu erzeugen. Dies ist die Kernfunktion einer RAG-Anwendung.
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import KnowledgeGraphRAGRetriever
from llama_index.core.response_synthesis import ResponseSynthesizer
# Retrieve Knowledge for RAG
graph_rag_retriever = KnowledgeGraphRAGRetriever(storage_context=graph_store.storage_context, verbose=True)
query_engine = RetrieverQueryEngine.from_args(graph_rag_retriever)Zuerst importieren wir die notwendigen Klassen aus LlamaIndex: RetrieverQueryEngine, KnowledgeGraphRAGRetriever, und ResponseSynthesizer.
RetrieverQueryEngine ist eine Abfrage-Engine, die einen Retriever verwendet, um relevanten Kontext aus einer Datenquelle (in unserem Fall dem Wissensgraphen) zu holen und dann eine Antwort aus diesem Kontext zu erstellen.
KnowledgeGraphRAGRetriever ist ein spezieller Retriever, der relevante Informationen aus einem in einer Datenbank gespeicherten Wissensgraphen abrufen kann.
ResponseSynthesizer ist für die Erstellung einer endgültigen Antwort verantwortlich, indem sie den abgerufenen Kontext mit einem Sprachmodell kombiniert.
Als Nächstes erstellen wir eine Instanz von KnowledgeGraphRAGRetriever, indem wir storage_context aus unserer Instanz graph_store übergeben. Diese storage_context enthält die notwendigen Informationen, um sich mit der Neo4j-Datenbank zu verbinden und sie abzufragen, in der wir den Wissensgraphen gespeichert haben. Wir haben auch verbose=True eingestellt, um eine detaillierte Protokollierung während des Abrufs zu ermöglichen.
Dann initialisieren wir ein RetrieverQueryEngine mit der Methode from_args und übergeben unsere graph_rag_retriever Instanz. Diese Query Engine übernimmt den gesamten Prozess des Abrufens von relevantem Kontext aus dem Wissensgraphen und der Generierung einer Antwort auf der Grundlage dieses Kontexts.
Mit diesen Komponenten sind wir nun bereit, den Wissensgraphen abzufragen und aus dem gefundenen Kontext Antworten zu generieren. Im nächsten Schritt werden wir sehen, wie wir das in der Praxis umsetzen können.
Schließlich können wir den Wissensgraphen abfragen und aus dem gefundenen Kontext Antworten generieren.
def query_and_synthesize(query):
retrieved_context = query_engine.query(query)
response = response_synthesizer.synthesize(query, retrieved_context)
print(f"Query: {query}")
print(f"Answer: {response}\n")
# Initialize the ResponseSynthesizer instance
response_synthesizer = ResponseSynthesizer(llm)
# Query 1
query_and_synthesize("Where does Sarah work?")
# Query 2
query_and_synthesize("Who works for prismaticAI?")
# Query 3
query_and_synthesize("Does Michael work for the same company as Sarah?")In diesem Beispiel definieren wir drei verschiedene Abfragen zu den Mitarbeitern und dem Unternehmen, die in den Textdaten beschrieben sind. Für jede Abfrage verwenden wir query_engine, um den relevanten Kontext aus dem Wissensgraphen abzurufen, erstellen eine Instanz von ResponseSynthesizer und rufen dessen Methode synthesize mit der Abfrage und dem abgerufenen Kontext auf.
ResponseSynthesizer verwendet das Sprachmodell und den abgerufenen Kontext, um eine endgültige Antwort auf die Anfrage zu generieren, die dann auf der Konsole ausgegeben wird und mit den Antworten im ersten Abschnitt dieses Artikels übereinstimmt.
Während das Tutorial die Verwendung eines Wissensgraphen für RAG-Anwendungen mit relativ einfachem Text demonstriert, gibt es in der Praxis oft komplexere und vielfältigere Datensätze. Außerdem können die Eingabedaten in verschiedenen Dateiformaten vorliegen, die über reinen Text hinausgehen. In diesem Abschnitt werden wir untersuchen, wie die wissensgraphenbasierte RAG-Anwendung erweitert werden kann, um solche Szenarien zu bewältigen.
Je größer und komplexer die Eingabedaten sind, desto schwieriger kann die Extraktion des Wissensgraphen werden. Hier sind einige Strategien für den Umgang mit großen und vielfältigen Datensätzen:
In der Praxis können Daten in verschiedenen Dateiformaten vorliegen, z. B. als PDF, Word-Dokument, Tabellenkalkulation oder sogar in strukturierten Datenformaten wie JSON oder XML. Um mit diesen verschiedenen Dateitypen umzugehen, kannst du die folgenden Strategien anwenden:
Diese Strategien helfen dir, die wissensgraphenbasierte RAG-Anwendung so zu erweitern, dass sie komplexere und vielfältigere Datensätze sowie eine breitere Palette von Dateitypen verarbeiten kann.
Es ist wichtig zu wissen, dass mit zunehmender Komplexität der Eingabedaten der Prozess der Wissensgraphenextraktion mehr domänenspezifische Anpassungen und Abstimmungen erfordern kann, um genaue und zuverlässige Ergebnisse zu gewährleisten.
Die Erstellung von Wissensgraphen für RAG-Anwendungen in der realen Welt kann eine komplexe Aufgabe mit mehreren Herausforderungen sein. Lass uns einige von ihnen erkunden:
Der Aufbau eines hochwertigen Wissensgraphen ist ein komplexer und zeitaufwändiger Prozess, der viel Fachwissen und Aufwand erfordert. Entitäten, Beziehungen und Fakten aus verschiedenen Datenquellen zu extrahieren und in einen kohärenten Wissensgraphen zu integrieren, kann eine Herausforderung sein, insbesondere bei großen und vielfältigen Datenbeständen. Es geht darum, die Domäne zu verstehen, relevante Informationen zu identifizieren und sie so zu strukturieren, dass die Beziehungen und die Semantik genau erfasst werden.
RAG-Anwendungen müssen oft Daten aus verschiedenen heterogenen Quellen integrieren, die jeweils ihre eigene Struktur, ihr eigenes Format und ihre eigene Semantik haben. Es ist nicht trivial, die Datenkonsistenz zu gewährleisten, Konflikte zu lösen und Entitäten und Beziehungen zwischen verschiedenen Datenquellen abzubilden. Es erfordert eine sorgfältige Datenbereinigung, -umwandlung und -zuordnung, um sicherzustellen, dass der Wissensgraph die Informationen aus den verschiedenen Quellen korrekt wiedergibt.
Wissensgraphen sind nicht statisch. Sie müssen ständig aktualisiert und gepflegt werden, wenn neue Informationen verfügbar werden oder sich bestehende Informationen ändern. Es kann ein ressourcenintensiver Prozess sein, den Wissensgraphen auf dem neuesten Stand und mit den sich entwickelnden Datenquellen konsistent zu halten. Es geht darum, Änderungen in den Datenquellen zu überwachen, relevante Aktualisierungen zu identifizieren und diese Aktualisierungen an den Wissensgraphen weiterzugeben und dabei seine Integrität und Konsistenz zu wahren.
Da der Wissensgraph immer größer und komplexer wird, wird es immer schwieriger, die Graphen effizient zu speichern, abzurufen und abzufragen. Skalierbarkeits- und Leistungsprobleme können vor allem bei großen RAG-Anwendungen mit hohem Abfragevolumen auftreten. Die Optimierung der Speicher-, Indizierungs- und Abfragetechniken für den Wissensgraphen ist entscheidend, um ein akzeptables Leistungsniveau zu erreichen.
Wissensgraphen eignen sich zwar hervorragend zur Darstellung komplexer Beziehungen und ermöglichen Multi-Hop-Argumentation, aber die Formulierung und Ausführung komplexer Abfragen, die diese Fähigkeiten nutzen, kann schwierig sein. Die Entwicklung effizienter Algorithmen für die Verarbeitung von Anfragen und das Reasoning ist ein aktiver Forschungsbereich. Um das volle Potenzial des Wissensgraphen zu nutzen, ist es wichtig, die Abfragesprache und die Schlussfolgerungsmöglichkeiten des Systems zu verstehen.
Es gibt keine allgemein anerkannten Standards für die Darstellung und Abfrage von Wissensgraphen, was zu Interoperabilitätsproblemen und Herstellerabhängigkeit führen kann. Verschiedene Knowledge-Graph-Systeme können unterschiedliche Datenmodelle, Abfragesprachen und APIs verwenden, was es schwierig macht, zwischen ihnen zu wechseln oder sie mit anderen Systemen zu integrieren. Die Übernahme oder Entwicklung von Standards kann die Interoperabilität erleichtern und die Bindung an bestimmte Anbieter verringern.
Wissensgraphen können zwar erklärbare und transparente Schlussfolgerungen liefern, aber es kann eine Herausforderung sein, sicherzustellen, dass der Schlussfolgerungsprozess für die Endnutzer leicht interpretierbar und verständlich ist, insbesondere bei komplexen Abfragen oder Schlussfolgerungspfaden. Die Entwicklung von benutzerfreundlichen Schnittstellen und Erklärungen, die den Denkprozess und die zugrunde liegenden Annahmen klar vermitteln, ist wichtig für das Vertrauen der Nutzer und die Akzeptanz.
Je nach Bereich und Anwendung können zusätzliche Herausforderungen auftreten, wie z.B. der Umgang mit bereichsspezifischer Terminologie, Ontologien oder Datenformaten. Im medizinischen Bereich zum Beispiel kann der Umgang mit komplexen medizinischen Terminologien, Kodierungssystemen und Datenschutzbelangen den Aufbau und die Nutzung des Wissensgraphen zusätzlich verkomplizieren.
Trotz dieser Herausforderungen bieten Wissensgraphen erhebliche Vorteile für RAG-Anwendungen, insbesondere in Bezug auf die Darstellung von strukturiertem Wissen, die Ermöglichung komplexer Schlussfolgerungen und die Bereitstellung erklärbarer und transparenter Ergebnisse. Die Bewältigung dieser Herausforderungen durch ein sorgfältiges Wissensgraphen-Design, Datenintegrationsstrategien und effiziente Abfrageverarbeitungstechniken ist entscheidend für die erfolgreiche Implementierung von wissensgraphenbasierten RAG-Anwendungen.
In diesem Tutorium haben wir die Möglichkeiten von Wissensgraphen erkundet, um genauere, informativere und kontextbezogene Antworten zu erstellen. Wir begannen damit, die grundlegenden Konzepte hinter Wissensgraphen und ihre Rolle in RAG-Anwendungen zu verstehen. Dann gingen wir durch ein praktisches Beispiel, bei dem wir einen Wissensgraphen aus Textdaten extrahierten, ihn in einer Neo4j-Datenbank speicherten und ihn nutzten, um relevanten Kontext für Benutzeranfragen zu finden. Schließlich haben wir gezeigt, wie man den abgerufenen Kontext nutzen kann, um mit Hilfe des strukturierten Wissens im Graphen Antworten zu generieren.
Wenn du mehr über KI und LLMs erfahren möchtest, schau dir diesen Lernpfad mit sechs Kursen zu KI-Grundlagen an.
Ich hoffe, du findest dieses Tutorial hilfreich und es macht dir Spaß.
Viel Spaß beim Codieren!
Erfahre mehr über KI und LLMs!
Lernpfad
Kurs
Kurs