Programa
Fundamentos do Negócio de IA
12 h
Você já se perguntou como os assistentes digitais, como a Alexa ou o Google Assistant, dão respostas tão precisas às suas perguntas?
A mágica por trás disso é chamada de geração aumentada por recuperação (RAG, na sigla em inglês), que combina a recuperação de informações com técnicas de geração de linguagem. Um participante importante nesse processo é um grafo de conhecimento, que ajuda esses assistentes a acessar um enorme conjunto de informações estruturadas para melhorar suas respostas.
Neste tutorial, exploraremos os grafos de conhecimento e como eles podem ser usados para criar aplicativos RAG para obter respostas mais precisas e relevantes.
Começaremos detalhando os conceitos básicos dos grafos de conhecimento e sua função na RAG. Vamos comparar esses bancos de dados com os bancos de dados de vetores e aprender quando é melhor usar um ou outro. Em seguida, vamos criar um grafo de conhecimento a partir de dados de texto, armazená-lo em um banco de dados e usá-lo para encontrar informações relevantes para consultas de usuários. Também analisaremos a expansão dessa abordagem para lidar com diferentes tipos de dados e formatos de arquivos além de texto simples.
Se você quiser saber mais sobre RAG, confira este artigo sobre geração aumentada de recuperação.
Os grafos de conhecimento representam informações em um formato estruturado e interconectado. Eles consistem em entidades (nós) e relacionamentos (bordas) entre essas entidades. As entidades podem representar objetos, conceitos ou ideias do mundo real, enquanto os relacionamentos descrevem como essas entidades estão conectadas.
A intuição por trás dos grafos de conhecimento é imitar a maneira como os seres humanos entendem e raciocinam sobre o mundo. Não armazenamos informações em silos isolados; em vez disso, fazemos conexões entre diferentes partes da informação, formando uma rede de conhecimento rica e interconectada.
Os grafos de conhecimento nos ajudam a ver como as entidades estão conectadas, mostrando claramente os relacionamentos entre diferentes entidades. A exploração dessas conexões nos permite encontrar novas informações e tirar conclusões que seriam difíceis obter a partir de informações separadas.
Vamos dar uma olhada em um exemplo.
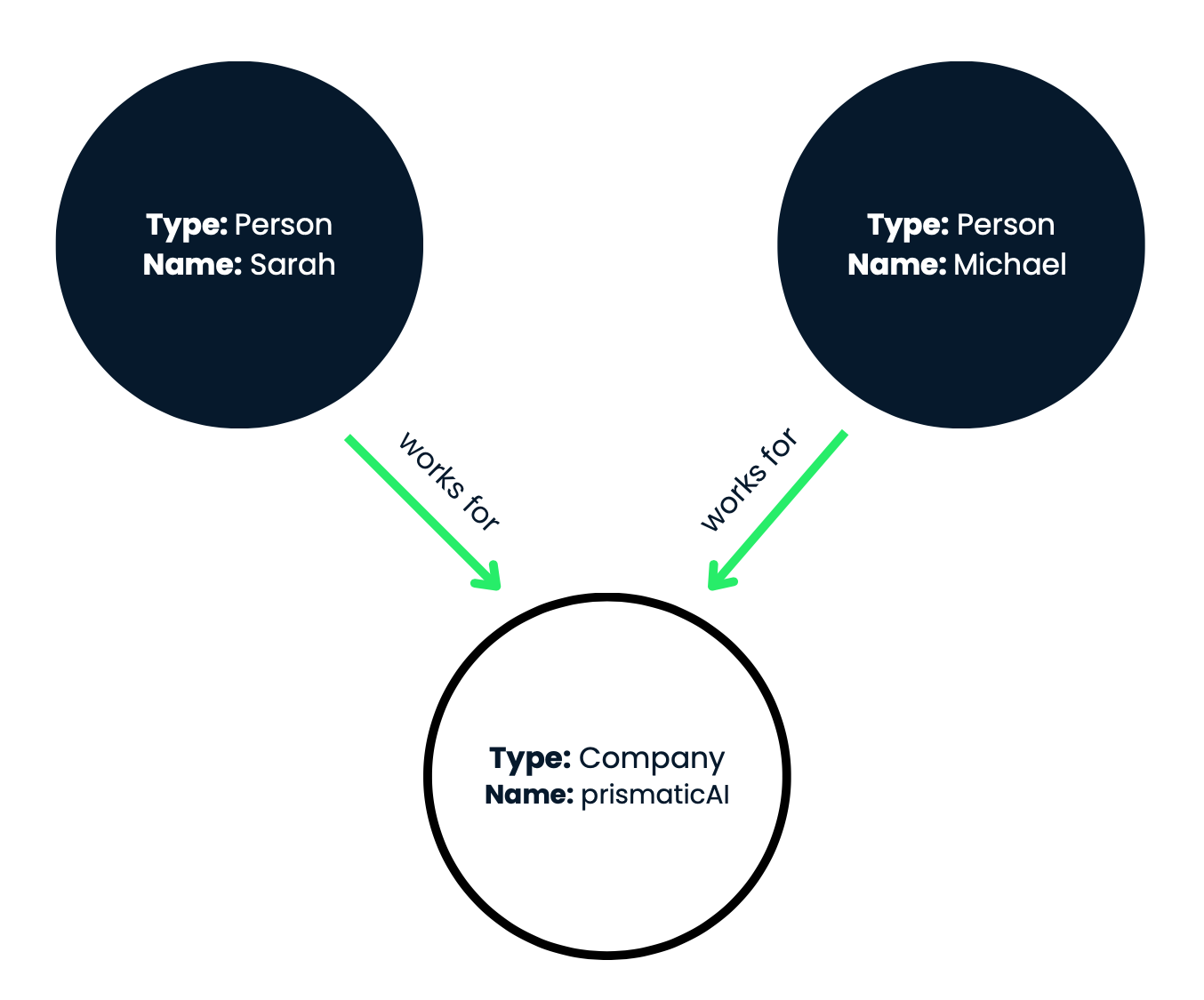
Figura 1: Nessa representação visual, os nós são mostrados como círculos e as relações são representadas como setas rotuladas que conectam os nós.
Esse grafo de conhecimento captura efetivamente as relações de trabalho entre os indivíduos Sarah e Michael e a empresa prismaticAI. Em nosso exemplo, temos três nós:
Em suma, temos dois nós de pessoa (Sarah e Michael) e um nó de empresa (prismaticAI). Agora, vamos examinar as relações (bordas) entre esses nós:
Um dos aspectos poderosos dos grafos de conhecimento é a capacidade de consultar e percorrer as relações entre as entidades para extrair informações relevantes ou inferir novos conhecimentos. Vamos explorar como podemos fazer isso com nosso grafo de conhecimento de exemplo.
Primeiro, precisamos determinar quais informações queremos obter do grafo de conhecimento. Por exemplo:
Consulta 1: Onde Sarah trabalha?
Para responder à consulta, precisamos encontrar o ponto de partida apropriado no grafo de conhecimento. Nesse caso, queremos começar pelo nó que representa Sarah.
Do ponto de partida (nó de Sarah), seguimos a borda de relacionamento de saída "trabalha na". Essa borda conecta o nó de Sarah ao nó que representa a prismaticAI. Ao analisar a relação "trabalha na", podemos concluir que Sarah trabalha na prismaticAI.
Resposta 1: Sarah trabalha na prismaticAI.
Vamos tentar outra consulta:
Consulta 2: Quem trabalha na prismaticAI?
Desta vez, queremos começar pelo nó que representa a prismaticAI.
A partir do nó prismaticAI, seguimos as bordas do relacionamento "trabalha na" para trás. Isso nos levará aos nós que representam as pessoas que trabalham na prismaticAI. Ao percorrer as relações "trabalha na" no sentido inverso, podemos identificar que tanto Sarah quanto Michael trabalham na prismaticAI.
Resposta 2: Sarah e Michael trabalham na prismaticAI.
Mais um exemplo!
Consulta 3: Michael trabalha na mesma empresa que Sarah?
Podemos começar pelo nó da Sarah ou pelo nó do Michael. Vamos começar pelo nó da Sarah.
Seguimos a relação "trabalha na" para chegar ao nó prismaticAI.
Em seguida, verificamos se Michael também tem um relacionamento "trabalha na" que leva ao mesmo nó prismaticAI. Como Sarah e Michael têm um relacionamento "trabalha na" com o nó prismaticAI, podemos concluir que eles trabalham para a mesma empresa.
Resposta 3: Sim, Michael trabalha na mesma empresa que a Sarah (prismaticAI).
Percorrer as relações no grafo de conhecimento nos permite extrair informações específicas e entender as conexões entre as entidades. Os grafos de conhecimento podem se tornar muito mais complexos, com vários nós e relacionamentos, permitindo a representação do intrincado conhecimento do mundo real de forma estruturada e interconectada.
Os aplicativos RAG combinam a recuperação de informações e a geração de linguagem natural para fornecer respostas relevantes e coerentes às consultas ou solicitações dos usuários. Os grafos de conhecimento oferecem várias vantagens que os tornam particularmente adequados para esses aplicativos. Vamos nos aprofundar nos principais benefícios:
Como aprendemos na seção anterior, os grafos de conhecimento representam informações de forma estruturada, com entidades (nós) e seus relacionamentos (bordas). Essa representação estruturada facilita a recuperação de informações relevantes para uma determinada consulta ou tarefa, em comparação com dados de texto não estruturados.
Em nosso grafo de conhecimento de exemplo, podemos facilmente recuperar informações sobre quem trabalha na prismaticAI seguindo os relacionamentos "trabalha na".
Os grafos de conhecimento capturam as relações entre as entidades, permitindo uma compreensão mais profunda do contexto em que as informações são apresentadas. A compreensão contextual é fundamental para gerar respostas coerentes e relevantes nos aplicativos RAG.
Voltando ao nosso exemplo, entender a relação "trabalha na" entre Sarah, Michael e a prismaticAI permitiria que um aplicativo RAG fornecesse respostas mais contextualmente relevantes sobre o emprego deles.
Percorrer as relações em um grafo de conhecimento permite que os aplicativos RAG façam inferências e obtenham novos conhecimentos que podem não estar explicitamente declarados. Esse recurso de raciocínio inferencial melhora a qualidade e a integridade das respostas geradas.
Ao percorrer os relacionamentos, um aplicativo RAG pode inferir que Sarah e Michael trabalham para a mesma empresa, mesmo que essa informação não seja declarada diretamente.
Os grafos de conhecimento podem integrar informações de várias fontes, permitindo que aplicativos RAG usem bases de conhecimento diversas e complementares. Essa integração do conhecimento pode levar a respostas mais abrangentes e completas.
Poderíamos adicionar informações de várias fontes sobre empresas, funcionários e suas funções ao nosso exemplo de grafo de conhecimento, fornecendo um quadro mais completo para a geração de respostas.
Os grafos de conhecimento fornecem uma representação transparente do conhecimento usado na geração de respostas. Essa transparência é fundamental para explicar o raciocínio por trás do resultado gerado, o que é importante em muitos aplicativos, como sistemas de resposta a perguntas.
A explicação para a resposta 3 do nosso exemplo poderia ser: Sim, Michael trabalha na mesma empresa que Sarah. Cheguei a essa conclusão identificando que Sarah trabalha na prismaticAI e depois verificando se Michael também tem um relacionamento de "trabalha na" com a prismaticAI. Como ambos têm esse relacionamento com a mesma entidade da empresa, posso inferir que eles trabalham na mesma empresa.
Essa transparência no processo de raciocínio permite que os usuários e desenvolvedores entendam como o aplicativo RAG chegou à sua resposta, em vez de tratá-lo como uma caixa preta. Isso também aumenta a confiança no sistema, pois o processo de tomada de decisão é claramente definido e pode ser verificado no grafo de conhecimento.
Além disso, se houver inconsistências ou informações faltantes no grafo de conhecimento, a explicação pode ajudar a identificar e solucionar esses problemas, o que leva a uma maior precisão e integridade das respostas.
Usando grafos de conhecimento, os aplicativos RAG podem criar respostas mais claras, precisas e compreensíveis. Isso os torna úteis para diferentes tarefas no processamento de linguagem natural.
Ao criar aplicativos RAG, você pode encontrar duas abordagens diferentes: grafos de conhecimento e bancos de dados vetoriais. Embora ambos sejam usados para representar e recuperar informações, eles diferem em suas estruturas de dados subjacentes e na maneira como lidam com as informações.
Vamos explorar as principais diferenças entre essas duas abordagens:
|
Recurso |
Grafos de conhecimento |
Bancos de dados de vetores |
|
Representação de dados |
Entidades (nós) e relacionamentos (bordas) entre entidades, formando uma estrutura de grafos. |
Vetores de alta dimensão, cada um representando uma parte da informação (por exemplo, documento, frase). |
|
Mecanismos de recuperação |
Percorre a estrutura do grafo e segue os relacionamentos entre as entidades. Permite a inferência e a derivação de novos conhecimentos. |
Similaridade de vetor com base em uma métrica de similaridade (por exemplo, similaridade de cosseno). Retorna os vetores mais semelhantes e as informações associadas. |
|
Interpretabilidade |
Representação de conhecimento interpretável por humanos. A estrutura do grafo e os relacionamentos rotulados esclarecem as conexões das entidades. |
Menos interpretável para humanos devido às representações numéricas de alta dimensão. Difícil para entender diretamente as relações ou o raciocínio por trás das informações recuperadas. |
|
Integração do conhecimento |
Facilita a integração ao representar entidades e relacionamentos em uma estrutura de grafo unificada. Integração perfeita se as entidades e os relacionamentos forem mapeados corretamente. |
Mais difícil. Requer técnicas como alinhamento de espaço vetorial ou métodos de conjunto para combinar informações. Garantir a compatibilidade de vetores pode não ser trivial. |
|
Raciocínio inferencial |
Permite o raciocínio inferencial percorrendo a estrutura do grafo e usando as relações entre as entidades. Descobre conexões implícitas e obtém novas percepções. |
Mais limitado. Depende da similaridade de vetores e pode perder relações ou inferências implícitas. É capaz de identificar informações semelhantes mas não relações complexas a partir de grafos de conhecimento. |
Tanto os grafos de conhecimento quanto os bancos de dados de vetores têm seus pontos fortes e casos de uso, e a escolha entre eles depende dos requisitos específicos do seu aplicativo. Os grafos de conhecimento são excelentes para representar e raciocinar sobre o conhecimento estruturado, enquanto os bancos de dados vetoriais são adequados para tarefas que dependem muito da similaridade semântica e da recuperação de informações com base em representações vetoriais.
Você pode saber mais sobre bancos de dados de vetores nesta introdução aos bancos de dados de vetores para aprendizado de máquina. Além disso, veja os cinco bancos de dados de vetores mais populares.
Nesta seção, exploraremos como implementar um grafo de conhecimento para aumentar o processo de geração de linguagem para um aplicativo RAG.
Abordaremos as seguintes etapas principais:
Ao final desta seção, você terá um sólido entendimento da implementação de grafos de conhecimento em aplicativos RAG, o que lhe permitirá criar sistemas de geração de linguagem mais inteligentes e sensíveis ao contexto.
Antes de começarmos, verifique se você tem os seguintes itens instalados:
pip install langchain)pip install llama-index)A primeira etapa é carregar e pré-processar os dados de texto dos quais extrairemos o grafo de conhecimento. Neste exemplo, usaremos um trecho de texto que descreve uma empresa de tecnologia chamada prismaticAI, seus funcionários e suas funções.
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
# Load text data
text = """Sarah is an employee at prismaticAI, a leading technology company based in Westside Valley. She has been working there for the past three years as a software engineer.
Michael is also an employee at prismaticAI, where he works as a data scientist. He joined the company two years ago after completing his graduate studies.
prismaticAI is a well-known technology company that specializes in developing cutting-edge software solutions and artificial intelligence applications. The company has a diverse workforce of talented individuals from various backgrounds.
Both Sarah and Michael are highly skilled professionals who contribute significantly to prismaticAI's success. They work closely with their respective teams to develop innovative products and services that meet the evolving needs of the company's clients."""
loader = TextLoader(text)
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=200, chunk_overlap=20)
texts = text_splitter.split_documents(documents)Começamos importando as classes necessárias do LangChain: TextLoader e CharacterTextSplitter. TextLoader carrega os dados do texto, enquanto CharacterTextSplitter divide o texto em partes menores para um processamento mais eficiente.
Em seguida, definimos os dados de texto como uma variável string de várias linhastext.
Em seguida, usamos TextLoader para carregar os dados de texto diretamente da variável de texto. O método loader.load() retorna uma lista de objetos Document, cada um contendo um trecho do texto.
Para dividir o texto em partes menores e mais gerenciáveis, criamos uma instância de CharacterTextSplitter com um chunk_size de 200 caracteres e um chunk_overlap de 20 caracteres. O parâmetro chunk_overlap garante que haja alguma sobreposição entre os blocos adjacentes, o que pode ser útil para manter o contexto durante o processo de extração de conhecimento.
Por fim, usamos o método split_documents de CharacterTextSplitter para dividir os objetos Document em partes menores, que são armazenadas na variável de textos como uma lista de objetos Document.
O pré-processamento dos dados de texto dessa forma nos permite prepará-los para a próxima etapa, na qual inicializaremos um modelo de linguagem e o usaremos para extrair um grafo de conhecimento dos blocos de texto.
Depois de carregar e pré-processar os dados de texto, a próxima etapa é inicializar um modelo de linguagem e usá-lo para extrair um grafo de conhecimento dos blocos de texto. Neste exemplo, usaremos o modelo de linguagem OpenAI fornecido pela LangChain.
from langchain.llms import OpenAI
from langchain.transformers import LLMGraphTransformer
import getpass
import os
# Load environment variable for OpenAI API key
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Initialize LLM
llm = OpenAI(temperature=0)
# Extract Knowledge Graph
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(texts)Primeiro, importamos as classes necessárias do LangChain: OpenAI e LLMGraphTransformer. OpenAI é um wrapper para o modelo de linguagem da OpenAI, que usaremos para extrair o grafo de conhecimento. LLMGraphTransformer é uma classe utilitária que ajuda a converter dados de texto em uma representação de grafo de conhecimento.
Em seguida, carregamos a chave da API da OpenAI em uma variável de ambiente. Essa é uma prática recomendada de segurança para evitar inserir credenciais confidenciais em seu código.
Em seguida, inicializamos uma instância do modelo de linguagem OpenAI com uma temperatura de 0. O parâmetro de temperatura controla a aleatoriedade do resultado do modelo, com valores mais baixos produzindo respostas mais determinísticas.
Depois de inicializar o modelo de linguagem, criamos uma instância de LLMGraphTransformer e passamos o objeto llm inicializado para ele. A classe LLMGraphTransformer converte os blocos de texto (texts) em uma representação de grafo de conhecimento.
Por fim, chamamos o método convert_to_graph_documents de LLMGraphTransformer, passando a lista de textos. Esse método usa o modelo de linguagem para analisar os blocos de texto e extrair entidades, relacionamentos e outras informações estruturadas relevantes, que são então representadas como um grafo de conhecimento. O grafo de conhecimento resultante é armazenado na variável graph_documents.
Inicializamos com sucesso um modelo de linguagem e o usamos para extrair um grafo de conhecimento dos dados de texto. Na próxima etapa, armazenaremos o grafo de conhecimento em um banco de dados para persistência e consulta.
Depois de extrair o grafo de conhecimento dos dados de texto, é importante armazená-lo em um formato persistente que possa ser consultado. Neste tutorial, usaremos o Neo4j para armazenar o grafo de conhecimento.
from langchain.graph_stores import Neo4jGraphStore
# Store Knowledge Graph in Neo4j
graph_store = Neo4jGraphStore(url="neo4j://your_neo4j_url", username="your_username", password="your_password")
graph_store.write_graph(graph_documents)Primeiro, importamos a classe Neo4jGraphStore da LangChain. Essa classe fornece uma interface conveniente para interagir com um banco de dados Neo4j e armazenar grafos de conhecimento.
Em seguida, criamos uma instância de Neo4jGraphStore fornecendo os detalhes de conexão necessários: o URL do banco de dados Neo4j, o nome de usuário e a senha. Certifique-se de substituir "your_neo4j_url", "your_username" e "your_password" pelos valores apropriados para sua instância do Neo4j.
Por fim, chamamos o método write_graph da instância graph_store, passando a lista graph_documents obtida na etapa anterior. Esse método serializa o grafo de conhecimento e o grava no banco de dados Neo4j.
O armazenamento do grafo de conhecimento em um banco de dados Neo4j nos permite garantir que ele seja persistente e possa ser facilmente consultado e recuperado quando necessário. A estrutura orientada a grafos do Neo4j permite representar e percorrer com eficiência os relacionamentos complexos e entidades presentes no grafo de conhecimento.
Na próxima etapa, configuraremos os componentes para recuperar o conhecimento do grafo e gerar respostas usando o contexto recuperado.
É importante observar que, embora este tutorial use o Neo4j como banco de dados de grafo, o LangChain também é compatível com outros bancos de dados de grafo, como o Amazon Neptune e bancos de dados compatíveis com o TinkerPop, como o Gremlin Server. Você pode trocar o Neo4jGraphStore pela implementação de armazenamento de grafos apropriada para o banco de dados escolhido.
Agora que armazenamos o grafo de conhecimento em um banco de dados, podemos configurar os componentes para recuperar o conhecimento relevante do grafo com base nas consultas do usuário e gerar respostas usando o contexto recuperado. Essa é a funcionalidade principal de um aplicativo RAG.
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import KnowledgeGraphRAGRetriever
from llama_index.core.response_synthesis import ResponseSynthesizer
# Retrieve Knowledge for RAG
graph_rag_retriever = KnowledgeGraphRAGRetriever(storage_context=graph_store.storage_context, verbose=True)
query_engine = RetrieverQueryEngine.from_args(graph_rag_retriever)Primeiro, importamos as classes necessárias do LlamaIndex: RetrieverQueryEngine, KnowledgeGraphRAGRetriever e ResponseSynthesizer.
RetrieverQueryEngine é um mecanismo de consulta que usa um recuperador para buscar o contexto relevante de uma fonte de dados (no nosso caso, o grafo de conhecimento) e, em seguida, sintetiza uma resposta usando esse contexto.
KnowledgeGraphRAGRetriever é um recuperador especializado que pode recuperar informações relevantes de um grafo de conhecimento armazenado em um banco de dados.
ResponseSynthesizer é responsável por gerar uma resposta final, combinando o contexto recuperado com um modelo de linguagem.
Em seguida, criamos uma instância de KnowledgeGraphRAGRetriever passando o storage_context da nossa instância graph_store. Esse storage_context contém as informações necessárias para se conectar e consultar o banco de dados Neo4j, onde armazenamos o grafo de conhecimento. Também definimos verbose=True para permitir o registro detalhado durante o processo de recuperação.
Em seguida, inicializamos RetrieverQueryEngine usando o método from_args e passando nossa instância graph_rag_retriever. Esse mecanismo de consulta cuidará de todo o processo de recuperação do contexto relevante do grafo de conhecimento e da geração de uma resposta com base nesse contexto.
Com esses componentes configurados, agora estamos prontos para consultar o grafo de conhecimento e gerar respostas usando o contexto recuperado. Na próxima etapa, veremos como fazer isso na prática.
Por fim, podemos consultar o grafo de conhecimento e gerar respostas usando o contexto recuperado.
def query_and_synthesize(query):
retrieved_context = query_engine.query(query)
response = response_synthesizer.synthesize(query, retrieved_context)
print(f"Query: {query}")
print(f"Answer: {response}\n")
# Initialize the ResponseSynthesizer instance
response_synthesizer = ResponseSynthesizer(llm)
# Query 1
query_and_synthesize("Where does Sarah work?")
# Query 2
query_and_synthesize("Who works for prismaticAI?")
# Query 3
query_and_synthesize("Does Michael work for the same company as Sarah?")Neste exemplo, definimos três consultas diferentes relacionadas aos funcionários e à empresa descritos nos dados de texto. Para cada consulta, usamos query_engine para recuperar o contexto relevante do grafo de conhecimento, criar uma instância de ResponseSynthesizer e chamar seu método synthesize com a consulta e o contexto recuperado.
O ResponseSynthesizer usa o modelo de linguagem e o contexto recuperado para gerar uma resposta final à consulta, que é impressa no console, correspondendo às respostas da primeira seção deste artigo.
Embora o tutorial demonstre o uso de um grafo de conhecimento para aplicativos RAG com texto relativamente simples, os cenários do mundo real geralmente envolvem conjuntos de dados mais complexos e diversificados. Além disso, os dados de entrada podem vir em vários formatos de arquivo além de texto simples. Nesta seção, exploraremos como o aplicativo RAG baseado em grafos de conhecimento pode ser estendido para lidar com esses cenários.
À medida que o tamanho e a complexidade dos dados de entrada aumentam, o processo de extração do grafo de conhecimento pode se tornar mais difícil. Aqui estão algumas estratégias para lidar com conjuntos de dados grandes e diversificados:
Em cenários do mundo real, os dados podem vir em vários formatos de arquivo, como PDFs, documentos do Word, planilhas ou até mesmo formatos de dados estruturados, como JSON ou XML. Para lidar com esses diferentes tipos de arquivos, você pode usar as seguintes estratégias:
Essas estratégias ajudarão a ampliar o aplicativo RAG baseado em grafos de conhecimento para lidar com conjuntos de dados mais complexos e diversificados, bem como com uma variedade maior de tipos de arquivos.
É importante observar que, à medida que a complexidade dos dados de entrada aumenta, o processo de extração do grafo de conhecimento pode exigir mais personalização e ajuste específicos do domínio para garantir resultados precisos e confiáveis.
A configuração de grafos de conhecimento para aplicativos RAG no mundo real pode ser uma tarefa complexa com vários desafios. Vamos explorar alguns deles:
A criação de um grafo de conhecimento de alta qualidade é um processo complexo e demorado, que exige um esforço e um conhecimento especializado significativo do domínio. Extrair entidades, relacionamentos e fatos de várias fontes de dados e integrá-los em um grafo de conhecimento coerente pode ser um desafio, especialmente com conjuntos de dados grandes e diversificados. Envolve a compreensão do domínio, a identificação de informações relevantes e sua estruturação de forma a capturar com precisão as relações e a semântica.
Os aplicativos RAG geralmente precisam integrar dados de várias fontes heterogêneas, cada uma com sua própria estrutura, formato e semântica. Garantir a consistência dos dados, resolver conflitos e mapear entidades e relacionamentos em diferentes fontes de dados não é algo trivial. Isso requer a execução cuidadosa de limpeza, transformação e mapeamento dos dados para garantir que o grafo de conhecimento represente com precisão as informações de várias fontes.
Os grafos de conhecimento não são estáticos. Eles precisam ser continuamente atualizados e mantidos à medida que novas informações se tornam disponíveis ou que as informações existentes mudam. Manter o grafo de conhecimento atualizado e consistente com as fontes de dados em evolução pode ser um processo que consome muitos recursos. Ele envolve o monitoramento de alterações nas fontes de dados, a identificação de atualizações relevantes e a propagação dessas atualizações para o grafo de conhecimento, mantendo sua integridade e consistência.
À medida que o grafo de conhecimento cresce em tamanho e complexidade, garantir o armazenamento, a recuperação e a consulta eficientes dos dados do grafos torna-se cada vez mais difícil. Podem surgir problemas de escalabilidade e desempenho, especialmente em aplicativos RAG de grande escala com grandes volumes de consulta. A otimização do armazenamento do grafo de conhecimento, da indexação e das técnicas de processamento de consultas é fundamental para manter níveis de desempenho aceitáveis.
Embora os grafos de conhecimento sejam excelentes para representar relações complexas e permitir o raciocínio multi-hop, pode ser difícil formular e executar consultas complexas que aproveitem esses recursos. O desenvolvimento de algoritmos eficientes de raciocínio e processamento de consultas é uma área ativa de pesquisa. Compreender a linguagem de consulta e os recursos de raciocínio do sistema de grafos de conhecimento é importante para utilizar todo o seu potencial de forma eficaz.
Há uma falta de padrões amplamente adotados para representar e consultar grafos de conhecimento, o que pode levar a problemas de interoperabilidade e dependência de fornecedores. Diferentes sistemas de grafos de conhecimento podem usar diferentes modelos de dados, linguagens de consulta e APIs, o que dificulta a troca entre eles ou a integração com outros sistemas. A adoção ou o desenvolvimento de padrões pode facilitar a interoperabilidade e reduzir a dependência de fornecedores.
Embora os grafos de conhecimento possam fornecer raciocínio explicável e transparente, garantir que o processo de raciocínio seja facilmente interpretável e compreensível para os usuários finais pode ser difícil, especialmente para consultas ou caminhos de raciocínio complexos. O desenvolvimento de interfaces amigáveis e explicações que comuniquem claramente o processo de raciocínio e suas suposições subjacentes é importante para conquistar a confiança do usuário e sua adoção.
Dependendo do domínio e do aplicativo, pode haver desafios adicionais específicos para esse domínio, como lidar com terminologia, ontologias ou formatos de dados específicos do domínio. Por exemplo, no domínio médico, lidar com terminologias médicas complexas, sistemas de codificação e questões de privacidade pode acrescentar outras camadas de complexidade à configuração e ao uso do grafo de conhecimento.
Apesar desses desafios, os grafos de conhecimento oferecem vantagens significativas para os aplicativos RAG, especialmente em termos de representação de conhecimento estruturado, permitindo raciocínio complexo e fornecendo resultados explicáveis e transparentes. A abordagem desses desafios por meio de um projeto cuidadoso de grafos de conhecimento, estratégias de integração de dados e técnicas eficientes de processamento de consultas é fundamental para a implementação bem-sucedida de aplicativos RAG baseados em grafos de conhecimento.
Neste tutorial, exploramos o poder dos grafos de conhecimento para criar respostas mais precisas, informativas e contextualmente relevantes. Começamos entendendo os conceitos fundamentais por trás dos grafos de conhecimento e sua função nos aplicativos RAG. Em seguida, apresentamos um exemplo prático, extraindo um grafo de conhecimento de dados de texto, armazenando-o em um banco de dados Neo4j e usando-o para recuperar o contexto relevante para consultas do usuário. Por fim, demonstramos como usar o contexto recuperado para gerar respostas usando o conhecimento estruturado no grafo.
Se você quiser saber mais sobre IA e LLMs, confira este programa de seis cursos sobre Fundamentos de IA.
Espero que este tutorial seja útil e divertido. Até o próximo.
Divirta-se com a programação!
Saiba mais sobre IA e LLMs!
Programa
Curso
Curso
blog
Armstrong Asenavi
15 min
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Moez Ali

