Track
AI Business Fundamentals
12 hr
Ever wonder how digital assistants like Alexa or Google Assistant give such accurate answers to your questions?
The magic behind this is called Retrieval-Augmented Generation (RAG), which combines information retrieval with language generation techniques. A key player in this process is a knowledge graph, which helps these assistants access a huge pool of structured information to improve their responses.
In this tutorial, we'll explore knowledge graphs and how they can be used to build RAG applications for more accurate and relevant responses.
We’ll start by breaking down the basics of knowledge graphs and their role in RAG. We’ll compare these to vector databases and learn when it's best to use one or the other. Then, we’ll get hands-on to create a knowledge graph from text data, store it in a database, and use it to find relevant info for user queries. We’ll also look at expanding this approach to handle different types of data and file formats beyond just plain text.
If you want to learn more about RAG, check out this article on retrieval augmented generation.
Knowledge graphs represent information in a structured, interconnected format. They consist of entities (nodes) and relationships (edges) between those entities. Entities can represent real-world objects, concepts, or ideas, while relationships describe how those entities are connected.
The intuition behind knowledge graphs is to mimic the way humans understand and reason about the world. We don't store information in isolated silos; instead, we make connections between different pieces of information, forming a rich, interconnected web of knowledge.
Knowledge graphs help us see how entities are connected by clearly showing the relationships between different entities. Exploring these connections allows us to find new information and make conclusions that would be hard to draw from separate pieces of information.
Let’s look at an example.
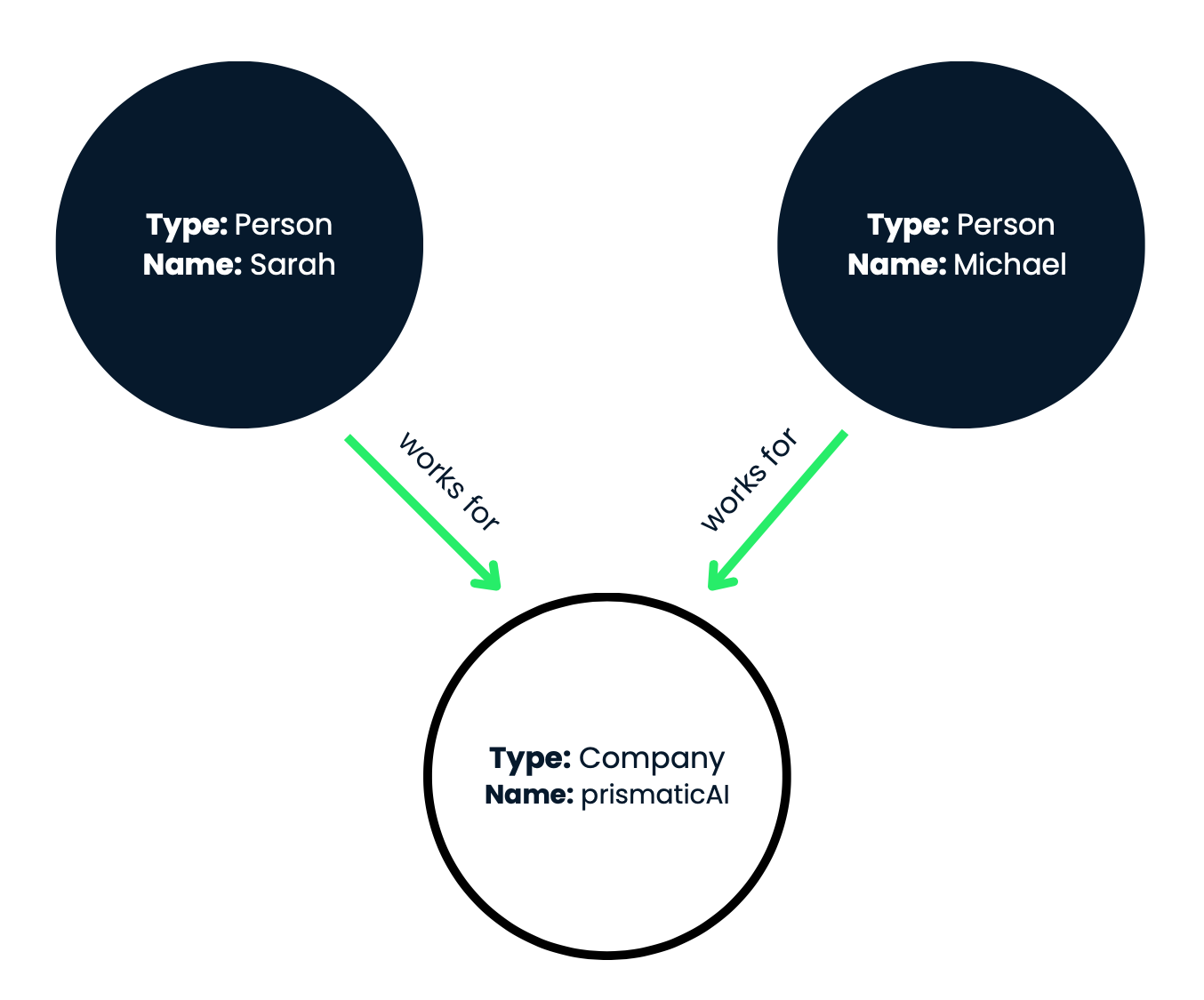
Figure 1: In this visual representation, the nodes are shown as circles, and the relationships are represented as labeled arrows connecting the nodes.
This knowledge graph effectively captures the employment relationships between the individuals Sarah and Michael and the company prismaticAI. In our example, we have three nodes:
In sum, we have two person nodes (Sarah and Michael) and one company node (prismaticAI). Now, let's look at the relationships (edges) between these nodes:
One of the powerful aspects of knowledge graphs is the ability to query and traverse the relationships between entities to extract relevant information or infer new knowledge. Let's explore how we can do this with our example knowledge graph.
First, we need to determine what information we want to retrieve from the knowledge graph. For example:
Query 1: Where does Sarah work?
To answer the query, we need to find the appropriate starting point in the knowledge graph. In this case, we want to start from the node representing Sarah.
From the starting point (Sarah's node), we follow the outgoing "works for" relationship edge. This edge connects Sarah's node to the node representing prismaticAI. By traversing the "works for" relationship, we can conclude that Sarah works for prismaticAI.
Answer 1: Sarah works for prismaticAI.
Let's try another query:
Query 2: Who works for prismaticAI?
This time, we want to start from the node representing prismaticAI.
From the prismaticAI node, we follow the "works for" relationship edges backward. This will lead us to the nodes representing the people who work for prismaticAI. By traversing the "works for" relationships in reverse, we can identify that both Sarah and Michael work for prismaticAI.
Answer 2: Sarah and Michael work for prismaticAI.
One more example!
Query 3: Does Michael work for the same company as Sarah?
We can start from either Sarah's node or Michael's node. Let's start from Sarah's node.
We follow the "works for" relationship to reach the prismaticAI node.
Then, we check if Michael also has a "works for" relationship leading to the same prismaticAI node. Since both Sarah and Michael have a "works for" relationship with the prismaticAI node, we can conclude that they work for the same company.
Answer 3: Yes, Michael works for the same company as Sarah (prismaticAI).
Traversing the relationships in the knowledge graph allows us to extract specific pieces of information and understand the connections between entities. Knowledge graphs can become much more complex, with numerous nodes and relationships, allowing for the representation of intricate real-world knowledge in a structured and interconnected way.
RAG applications combine information retrieval and natural language generation to provide relevant and coherent responses to user queries or prompts. Knowledge graphs offer several advantages that make them particularly well-suited for these applications. Let's dive into the key benefits:
As we learned in the previous section, knowledge graphs represent information in a structured manner, with entities (nodes) and their relationships (edges). This structured representation makes it easier to retrieve relevant information for a given query or task, compared to unstructured text data.
In our example knowledge graph, we can easily retrieve information about who works for prismaticAI by following the "works for" relationships.
Knowledge graphs capture the relationships between entities, enabling a deeper understanding of the context in which information is presented. This contextual understanding is crucial for generating coherent and relevant responses in RAG applications.
Back to our example, understanding the "works for" relationship between Sarah, Michael, and prismaticAI, would allow a RAG application to provide more contextually relevant responses about their employment.
Traversing the relationships in a knowledge graph allows RAG applications to make inferences and derive new knowledge that may not be explicitly stated. This inferential reasoning capability improves the quality and completeness of the generated responses.
By traversing the relationships, a RAG application can infer that Sarah and Michael work for the same company, even if this information is not directly stated.
Knowledge graphs can integrate information from multiple sources, allowing RAG applications to use diverse and complementary knowledge bases. This integration of knowledge can lead to more comprehensive and well-rounded responses.
We could add information about companies, employees, and their roles from various sources to our knowledge graph example, providing a more complete picture for generating responses.
Knowledge graphs provide a transparent representation of the knowledge used in generating responses. This transparency is key for explaining the reasoning behind the generated output, which is important in many applications, such as question-answering systems.
The explanation for answer 3 in our example could be: Yes, Michael works for the same company as Sarah. I arrived at this conclusion by identifying that Sarah works for prismaticAI and then verifying that Michael also has a 'works for' relationship with prismaticAI. Since they both have this relationship with the same company entity, I can infer that they work for the same company.
This transparency in the reasoning process allows users and developers to understand how the RAG application arrived at its response rather than treating it as a black box. It also increases trust in the system, as the decision-making process is clearly laid out and can be verified against the knowledge graph.
Also, if there are any inconsistencies or missing information in the knowledge graph, the explanation can help identify and address those issues, leading to improved accuracy and completeness of the responses.
Using knowledge graphs, RAG applications can create more accurate, clear, and understandable responses. This makes them useful for different tasks in natural language processing.
When building RAG applications, you may encounter two different approaches: knowledge graphs and vector databases. While both are used for representing and retrieving information, they differ in their underlying data structures and the way they handle information.
Let's explore the key differences between these two approaches:
|
Feature |
Knowledge Graphs |
Vector Databases |
|
Data Representation |
Entities (nodes) and relationships (edges) between entities, forming a graph structure. |
High-dimensional vectors, each representing a piece of information (e.g., document, sentence). |
|
Retrieval Mechanisms |
Traversing the graph structure and following relationships between entities. Enables inference and derivation of new knowledge. |
Vector similarity based on a similarity metric (e.g., cosine similarity). Returns most similar vectors and associated information. |
|
Interpretability |
Human-interpretable representation of knowledge. Graph structure and labeled relationships clarify entity connections. |
Less interpretable to humans due to high-dimensional numerical representations. Challenging to directly understand relationships or reasoning behind retrieved information. |
|
Knowledge Integration |
Facilitates integration by representing entities and relationships in a unified graph structure. Seamless integration if entities and relationships are mapped properly. |
More challenging. Requires techniques like vector space alignment or ensemble methods to combine information. Ensuring vector compatibility can be non-trivial. |
|
Inferential Reasoning |
Enables inferential reasoning by traversing the graph structure and leveraging relationships between entities. Uncovers implicit connections and derives new insights. |
More limited. Relies on vector similarity and may miss implicit relationships or inferences. Can identify similar information but not complex relationships from knowledge graphs. |
Both knowledge graphs and vector databases have their strengths and use cases, and the choice between them depends on the specific requirements of your application. Knowledge graphs excel at representing and reasoning over structured knowledge, while vector databases are well-suited for tasks that rely heavily on semantic similarity and information retrieval based on vector representations.
You can learn more about vector databases in this introduction to vector databases for machine learning. Additionally, see the five most popular vector databases.
In this section, we'll explore how to implement a knowledge graph to augment the language generation process for RAG application.
We'll cover the following key steps:
By the end of this section, you'll have a solid understanding of implementing knowledge graphs in RAG applications, enabling you to build more intelligent and context-aware language generation systems.
Before we begin, make sure you have the following installed:
pip install langchain)pip install llama-index)The first step is to load and preprocess the text data from which we'll extract the knowledge graph. In this example, we'll use a text snippet describing a technology company called prismaticAI, its employees, and their roles.
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
# Load text data
text = """Sarah is an employee at prismaticAI, a leading technology company based in Westside Valley. She has been working there for the past three years as a software engineer.
Michael is also an employee at prismaticAI, where he works as a data scientist. He joined the company two years ago after completing his graduate studies.
prismaticAI is a well-known technology company that specializes in developing cutting-edge software solutions and artificial intelligence applications. The company has a diverse workforce of talented individuals from various backgrounds.
Both Sarah and Michael are highly skilled professionals who contribute significantly to prismaticAI's success. They work closely with their respective teams to develop innovative products and services that meet the evolving needs of the company's clients."""
loader = TextLoader(text)
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=200, chunk_overlap=20)
texts = text_splitter.split_documents(documents)We start by importing the necessary classes from LangChain: TextLoader and CharacterTextSplitter. TextLoader loads the text data, while CharacterTextSplitter splits the text into smaller chunks for more efficient processing.
Next, we define the text data as a multi-line string variable text.
We then use TextLoader to load the text data directly from the text variable. The loader.load() method returns a list of Document objects, each containing a chunk of the text.
To split the text into smaller, more manageable chunks, we create an instance of CharacterTextSplitter with a chunk_size of 200 characters and a chunk_overlap of 20 characters. The chunk_overlap parameter ensures that there is some overlap between adjacent chunks, which can be helpful for maintaining context during the knowledge extraction process.
Finally, we use the split_documents method of CharacterTextSplitter to split the Document objects into smaller chunks, which are stored in the texts variable as a list of Document objects.
Preprocessing the text data in this way allows us to prepare it for the next step, where we'll initialize a language model and use it to extract a knowledge graph from the text chunks.
After loading and preprocessing the text data, the next step is to initialize a language model and use it to extract a knowledge graph from the text chunks. In this example, we'll be using the OpenAI language model provided by LangChain.
from langchain.llms import OpenAI
from langchain.transformers import LLMGraphTransformer
import getpass
import os
# Load environment variable for OpenAI API key
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Initialize LLM
llm = OpenAI(temperature=0)
# Extract Knowledge Graph
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(texts)First, we import the necessary classes from LangChain: OpenAI and LLMGraphTransformer. OpenAI is a wrapper for the OpenAI language model, which we'll use to extract the knowledge graph. LLMGraphTransformer is a utility class that helps convert text data into a knowledge graph representation.
Next, we load the OpenAI API key from an environment variable. This is a security best practice to avoid hardcoding sensitive credentials in your code.
We then initialize an instance of the OpenAI language model with a temperature of 0. The temperature parameter controls the randomness of the model's output, with lower values producing more deterministic responses.
After initializing the language model, we create an instance of LLMGraphTransformer and pass the initialized llm object to it. The LLMGraphTransformer class converts the text chunks (texts) into a knowledge graph representation.
Finally, we call the convert_to_graph_documents method of LLMGraphTransformer, passing in the texts list. This method uses the language model to analyze the text chunks and extract relevant entities, relationships, and other structured information, which are then represented as a knowledge graph. The resulting knowledge graph is stored in the graph_documents variable.
We have successfully initialized a language model and used it to extract a knowledge graph from the text data. In the next step, we’ll store the knowledge graph in a database for persistence and querying.
After extracting the knowledge graph from the text data, it's important to store it in a persistent and queryable format. In this tutorial, we'll use Neo4j to store the knowledge graph.
from langchain.graph_stores import Neo4jGraphStore
# Store Knowledge Graph in Neo4j
graph_store = Neo4jGraphStore(url="neo4j://your_neo4j_url", username="your_username", password="your_password")
graph_store.write_graph(graph_documents)First, we import the Neo4jGraphStore class from LangChain. This class provides a convenient interface for interacting with a Neo4j database and storing knowledge graphs.
Next, we create an instance of Neo4jGraphStore by providing the necessary connection details: the Neo4j database URL, username, and password. Make sure to replace "your_neo4j_url", "your_username", and "your_password" with the appropriate values for your Neo4j instance.
Finally, we call the write_graph method of the graph_store instance, passing in the graph_documents list obtained from the previous step. This method serializes the knowledge graph and writes it to the Neo4j database.
Storing the knowledge graph in a Neo4j database allows us to ensure that it’s persistent and can be easily queried and retrieved when needed. The graph structure of Neo4j allows for efficient representation and traversal of the complex relationships and entities present in the knowledge graph.
In the next step, we'll set up the components for retrieving knowledge from the graph and generating responses using the retrieved context.
It's important to note that while this tutorial uses Neo4j as the graph database, LangChain supports other graph databases as well, such as Amazon Neptune and TinkerPop-compatible databases like Gremlin Server. You can swap out the Neo4jGraphStore with the appropriate graph store implementation for your chosen database.
Now that we have stored the knowledge graph in a database, we can set up the components for retrieving relevant knowledge from the graph based on user queries and generating responses using the retrieved context. This is the core functionality of a RAG application.
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import KnowledgeGraphRAGRetriever
from llama_index.core.response_synthesis import ResponseSynthesizer
# Retrieve Knowledge for RAG
graph_rag_retriever = KnowledgeGraphRAGRetriever(storage_context=graph_store.storage_context, verbose=True)
query_engine = RetrieverQueryEngine.from_args(graph_rag_retriever)First, we import the necessary classes from LlamaIndex: RetrieverQueryEngine, KnowledgeGraphRAGRetriever, and ResponseSynthesizer.
RetrieverQueryEngine is a query engine that uses a retriever to fetch relevant context from a data source (in our case, the knowledge graph) and then synthesizes a response using that context.
KnowledgeGraphRAGRetriever is a specialized retriever that can retrieve relevant information from a knowledge graph stored in a database.
ResponseSynthesizer is responsible for generating a final response by combining the retrieved context with a language model.
Next, we create an instance of KnowledgeGraphRAGRetriever by passing in the storage_context from our graph_store instance. This storage_context contains the necessary information to connect to and query the Neo4j database, where we stored the knowledge graph. We also set verbose=True to enable detailed logging during the retrieval process.
Then, we initialize a RetrieverQueryEngine using the from_args method and passing in our graph_rag_retriever instance. This query engine will handle the entire process of retrieving relevant context from the knowledge graph and generating a response based on that context.
With these components set up, we are now ready to query the knowledge graph and generate responses using the retrieved context. In the next step, we'll see how to do this in practice.
Finally, we can query the knowledge graph and generate responses using the retrieved context.
def query_and_synthesize(query):
retrieved_context = query_engine.query(query)
response = response_synthesizer.synthesize(query, retrieved_context)
print(f"Query: {query}")
print(f"Answer: {response}\n")
# Initialize the ResponseSynthesizer instance
response_synthesizer = ResponseSynthesizer(llm)
# Query 1
query_and_synthesize("Where does Sarah work?")
# Query 2
query_and_synthesize("Who works for prismaticAI?")
# Query 3
query_and_synthesize("Does Michael work for the same company as Sarah?")In this example, we define three different queries related to the employees and the company described in the text data. For each query, we use the query_engine to retrieve the relevant context from the knowledge graph, create an instance of ResponseSynthesizer, and call its synthesize method with the query and retrieved context.
The ResponseSynthesizer uses the language model and the retrieved context to generate a final response to the query, which is then printed to the console, matching the answers in the first section of this article.
While the tutorial demonstrates using a knowledge graph for RAG applications with relatively simple text, real-world scenarios often involve more complex and diverse data sets. Additionally, the input data may come in various file formats beyond plain text. In this section, we'll explore how the knowledge graph-based RAG application can be extended to handle such scenarios.
As the size and complexity of the input data increase, the knowledge graph extraction process may become more challenging. Here are some strategies to handle large and diverse data sets:
In real-world scenarios, data can come in various file formats, such as PDFs, Word documents, spreadsheets, or even structured data formats like JSON or XML. To handle these different file types, you can use the following strategies:
These strategies will help you extend the knowledge graph-based RAG application to handle more complex and diverse data sets, as well as a wider range of file types.
It's important to note that as the complexity of the input data increases, the knowledge graph extraction process may require more domain-specific customization and tuning to ensure accurate and reliable results.
Setting up knowledge graphs for RAG applications in the real world can be a complex task with several challenges. Let’s explore some of them:
Building a high-quality knowledge graph is a complex and time-consuming process that requires significant domain expertise and effort. Extracting entities, relationships, and facts from various data sources and integrating them into a coherent knowledge graph can be challenging, especially for large and diverse datasets. It involves understanding the domain, identifying relevant information, and structuring it in a way that accurately captures the relationships and semantics.
RAG applications often need to integrate data from multiple heterogeneous sources, each with its own structure, format, and semantics. Ensuring data consistency, resolving conflicts, and mapping entities and relationships across different data sources is non-trivial. It requires careful data cleaning, transformation, and mapping to ensure that the knowledge graph accurately represents the information from various sources.
Knowledge graphs are not static. They need to be continuously updated and maintained as new information becomes available or existing information changes. Keeping the knowledge graph up-to-date and consistent with the evolving data sources can be a resource-intensive process. It involves monitoring changes in the data sources, identifying relevant updates, and propagating those updates to the knowledge graph while maintaining its integrity and consistency.
As the knowledge graph grows in size and complexity, ensuring efficient storage, retrieval, and querying of the graph data becomes increasingly challenging. Scalability and performance issues can arise, particularly for large-scale RAG applications with high query volumes. Optimizing the knowledge graph storage, indexing, and query processing techniques becomes crucial to maintaining acceptable performance levels.
While knowledge graphs excel at representing complex relationships and enabling multi-hop reasoning, formulating and executing complex queries that leverage these capabilities can be difficult. Developing efficient query processing and reasoning algorithms is an active area of research. Understanding the knowledge graph system's query language and reasoning capabilities is important to effectively utilize its full potential.
There is a lack of widely adopted standards for representing and querying knowledge graphs, which can lead to interoperability issues and vendor lock-in. Different knowledge graph systems may use different data models, query languages, and APIs, making it challenging to switch between them or integrate with other systems. Adopting or developing standards can facilitate interoperability and reduce vendor lock-in.
While knowledge graphs can provide explainable and transparent reasoning, ensuring that the reasoning process is easily interpretable and understandable to end-users can be a challenge, especially for complex queries or reasoning paths. Developing user-friendly interfaces and explanations that clearly communicate the reasoning process and its underlying assumptions is important for user trust and adoption.
Depending on the domain and application, there may be additional challenges specific to that domain, such as handling domain-specific terminology, ontologies, or data formats. For example, in the medical domain, dealing with complex medical terminologies, coding systems, and privacy concerns can add additional layers of complexity to the knowledge graph setup and usage.
Despite these challenges, knowledge graphs offer significant advantages for RAG applications, particularly in terms of representing structured knowledge, enabling complex reasoning, and providing explainable and transparent results. Addressing these challenges through careful knowledge graph design, data integration strategies, and efficient query processing techniques is crucial for successfully implementing knowledge graph-based RAG applications.
In this tutorial, we explored the power of knowledge graphs to create more accurate, informative, and contextually relevant responses. We started by understanding the fundamental concepts behind knowledge graphs and their role in RAG applications. Then, we walked through a hands-on example, extracting a knowledge graph from text data, storing it in a Neo4j database, and using it to retrieve relevant context for user queries. Finally, we demonstrated how to use the retrieved context to generate responses using the structured knowledge in the graph.
If you want to learn more about AI and LLMs, check out this six-course skill track on AI Fundamentals.
Hope you find this tutorial helpful and fun, I’ll see you in the next one.
Happy coding!
Learn more about AI and LLMs!
Track
Course
Course
blog
Stanislav Karzhev
12 min
Tutorial
Eugenia Anello
Tutorial
Ryan Ong
Tutorial
Bex Tuychiev
Tutorial
Ryan Ong
Tutorial
Bhavishya Pandit