Cursus
Principes fondamentaux de l'intelligence artificielle dans le monde des affaires
12 h
Vous êtes-vous déjà demandé comment les assistants numériques comme Alexa ou Google Assistant donnent des réponses aussi précises à vos questions ?
Il s'agit d'une technique magique appelée Retrieval-Augmented Generation (RAG), qui associe la recherche d'informations à des techniques de génération de langage. Un acteur clé de ce processus est le graphe de connaissances, qui permet à ces assistants d'accéder à un vaste ensemble d'informations structurées afin d'améliorer leurs réponses.
Dans ce tutoriel, nous allons explorer les graphes de connaissances et la façon dont ils peuvent être utilisés pour construire des applications RAG afin d'obtenir des réponses plus précises et plus pertinentes.
Nous commencerons par expliquer les principes de base des graphes de connaissances et leur rôle dans le RAG. Nous les comparerons aux bases de données vectorielles et apprendrons quand il est préférable d'utiliser l'une ou l'autre. Ensuite, nous mettrons la main à la pâte pour créer un graphe de connaissances à partir de données textuelles, le stocker dans une base de données et l'utiliser pour trouver des informations pertinentes pour les requêtes des utilisateurs. Nous étudierons également la possibilité d'étendre cette approche pour traiter différents types de données et de formats de fichiers, au-delà du simple texte.
Si vous souhaitez en savoir plus sur la RAG, consultez cet article sur la génération augmentée de recherche.
Les graphes de connaissances représentent l'information dans un format structuré et interconnecté. Ils se composent d'entités (nœuds) et de relations (arêtes) entre ces entités. Les entités peuvent représenter des objets, des concepts ou des idées du monde réel, tandis que les relations décrivent la manière dont ces entités sont connectées.
L'intuition derrière les graphes de connaissances est d'imiter la façon dont les humains comprennent et raisonnent sur le monde. Nous ne stockons pas les informations dans des silos isolés, mais nous établissons des liens entre les différents éléments d'information, formant ainsi un réseau de connaissances riche et interconnecté.
Les graphes de connaissances nous aident à voir comment les entités sont connectées en montrant clairement les relations entre les différentes entités. L'exploration de ces liens nous permet de trouver de nouvelles informations et de tirer des conclusions qu'il serait difficile de tirer à partir d'éléments d'information distincts.
Prenons un exemple.
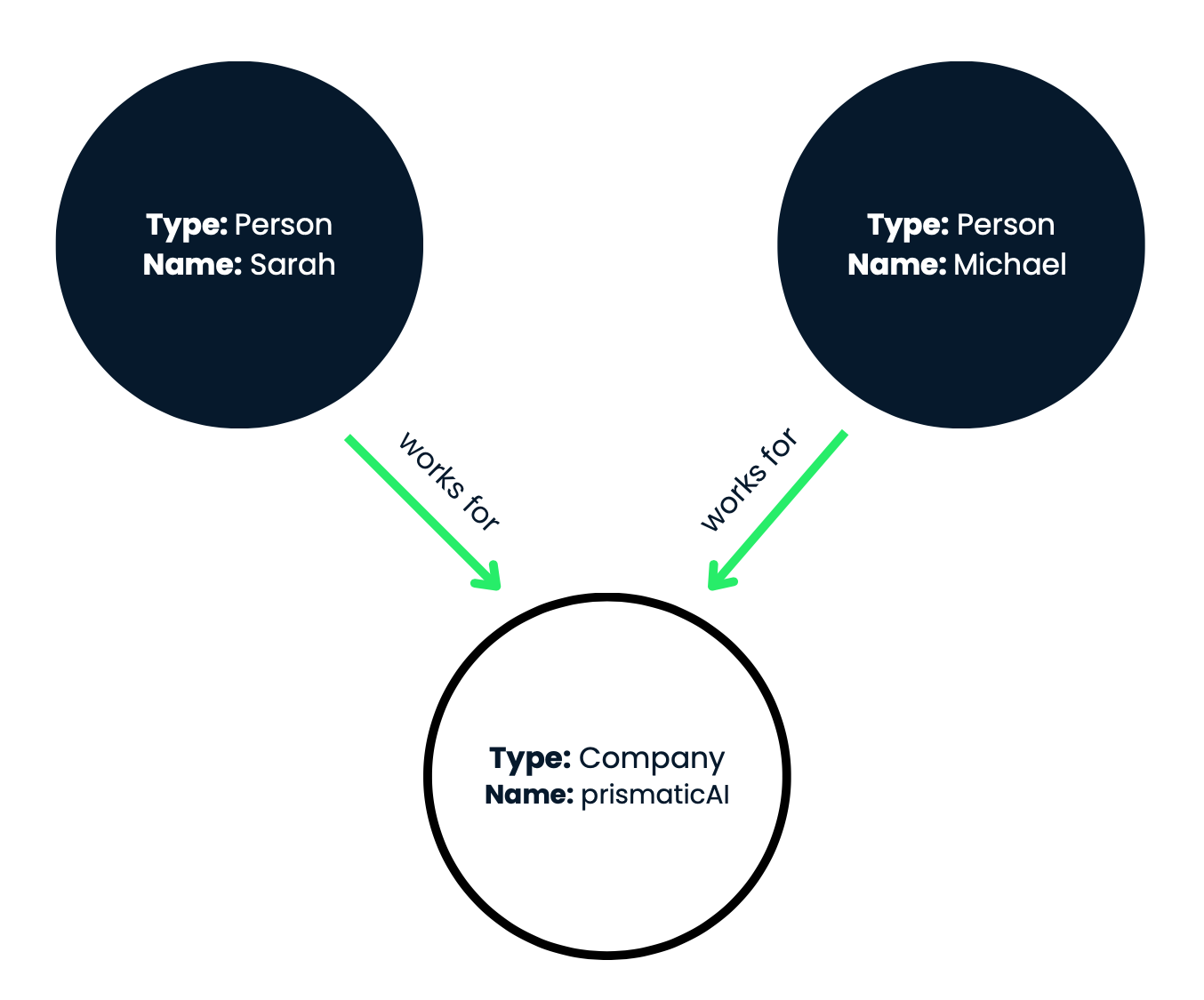
Figure 1 : Dans cette représentation visuelle, les nœuds sont représentés par des cercles et les relations par des flèches étiquetées reliant les nœuds.
Ce graphe de connaissances illustre efficacement les relations de travail entre les individus Sarah et Michael et l'entreprise prismaticAI. Dans notre exemple, nous avons trois nœuds :
En résumé, nous avons deux nœuds de personnes (Sarah et Michael) et un nœud d'entreprise (prismaticAI). Examinons maintenant les relations (arêtes) entre ces nœuds :
L'un des aspects puissants des graphes de connaissances est la possibilité d'interroger et de parcourir les relations entre les entités afin d'extraire des informations pertinentes ou de déduire de nouvelles connaissances. Voyons comment nous pouvons le faire avec notre exemple de graphe de connaissances.
Tout d'abord, nous devons déterminer les informations que nous voulons extraire du graphe de connaissances. Par exemple :
Question 1: Où travaille Sarah ?
Pour répondre à la requête, nous devons trouver le point de départ approprié dans le graphe de connaissances. Dans ce cas, nous voulons commencer par le nœud représentant Sarah.
À partir du point de départ (nœud de Sarah), nous suivons l'arête de relation sortante "travaille pour". Cette arête relie le nœud de Sarah au nœud représentant l'IA prismatique. En parcourant la relation "travaille pour", nous pouvons conclure que Sarah travaille pour prismaticAI.
Réponse 1 : Sarah travaille pour prismaticAI.
Essayons une autre requête :
Question 2: Qui travaille pour prismaticAI ?
Cette fois, nous voulons partir du nœud représentant prismaticAI.
À partir du nœud prismaticAI, nous suivons les arêtes de relation " travaille pour " vers l'arrière. Cela nous mènera aux nœuds représentant les personnes qui travaillent pour prismaticAI. En parcourant les relations "travaille pour" en sens inverse, nous pouvons identifier que Sarah et Michael travaillent tous deux pour prismaticAI.
Réponse 2: Sarah et Michael travaillent pour prismaticAI.
Encore un exemple !
Question 3: Michael travaille-t-il pour la même entreprise que Sarah ?
Nous pouvons partir du nœud de Sarah ou du nœud de Michael. Commençons par le nœud de Sarah.
Nous suivons la relation "travaille pour" pour atteindre le nœud prismaticAI.
Ensuite, nous vérifions si Michael a également une relation "travaille pour" menant au même nœud prismaticAI. Puisque Sarah et Michael ont tous deux une relation " travaille pour " avec le nœud prismaticAI, nous pouvons en conclure qu'ils travaillent pour la même entreprise.
Réponse 3: Oui, Michael travaille pour la même entreprise que Sarah (prismaticAI).
En parcourant les relations dans le graphe de connaissances, nous pouvons extraire des éléments d'information spécifiques et comprendre les liens entre les entités. Les graphes de connaissances peuvent devenir beaucoup plus complexes, avec de nombreux nœuds et relations, ce qui permet de représenter des connaissances complexes du monde réel de manière structurée et interconnectée.
Les applications RAG combinent la recherche d'informations et la génération de langage naturel pour fournir des réponses pertinentes et cohérentes aux requêtes ou aux invites des utilisateurs. Les graphes de connaissances présentent plusieurs avantages qui les rendent particulièrement adaptés à ces applications. Voyons quels sont les principaux avantages :
Comme nous l'avons appris dans la section précédente, les graphes de connaissances représentent l'information de manière structurée, avec des entités (nœuds) et leurs relations (arêtes). Cette représentation structurée facilite la recherche d'informations pertinentes pour une requête ou une tâche donnée, par rapport aux données textuelles non structurées.
Dans notre exemple de graphe de connaissances, nous pouvons facilement retrouver des informations sur les personnes qui travaillent pour prismaticAI en suivant les relations "travaille pour".
Les graphes de connaissances saisissent les relations entre les entités, ce qui permet de mieux comprendre le contexte dans lequel l'information est présentée. Cette compréhension du contexte est cruciale pour générer des réponses cohérentes et pertinentes dans les applications RAG.
Pour en revenir à notre exemple, la compréhension de la relation "travaille pour" entre Sarah, Michael et prismaticAI permettrait à une application RAG de fournir des réponses plus pertinentes sur le plan contextuel en ce qui concerne leur emploi.
Le fait de parcourir les relations d'un graphe de connaissances permet aux applications RAG de faire des déductions et de dériver de nouvelles connaissances qui peuvent ne pas être explicitement énoncées. Cette capacité de raisonnement déductif améliore la qualité et l'exhaustivité des réponses générées.
En parcourant les relations, une application RAG peut déduire que Sarah et Michael travaillent pour la même entreprise, même si cette information n'est pas directement mentionnée.
Les graphes de connaissances peuvent intégrer des informations provenant de sources multiples, ce qui permet aux applications RAG d'utiliser des bases de connaissances diverses et complémentaires. Cette intégration des connaissances peut conduire à des réponses plus complètes et mieux adaptées.
Nous pourrions ajouter des informations sur les entreprises, les employés et leurs rôles provenant de diverses sources à notre exemple de graphe de connaissances, fournissant ainsi une image plus complète pour générer des réponses.
Les graphiques de connaissances fournissent une représentation transparente des connaissances utilisées pour générer des réponses. Cette transparence est essentielle pour expliquer le raisonnement qui sous-tend le résultat généré, ce qui est important dans de nombreuses applications, telles que les systèmes de réponse aux questions.
L'explication de la réponse 3 dans notre exemple pourrait être la suivante : Oui, Michael travaille pour la même entreprise que Sarah. Je suis arrivé à cette conclusion en identifiant que Sarah travaille pour prismaticAI et en vérifiant que Michael a également une relation de "travailleur" avec prismaticAI. Étant donné qu'ils entretiennent tous deux cette relation avec la même entité, je peux en déduire qu'ils travaillent pour la même entreprise.
Cette transparence dans le processus de raisonnement permet aux utilisateurs et aux développeurs de comprendre comment l'application RAG est parvenue à sa réponse plutôt que de la traiter comme une boîte noire. Il renforce également la confiance dans le système, car le processus de prise de décision est clairement exposé et peut être vérifié à l'aide du graphe de connaissances.
En outre, en cas d'incohérences ou d'informations manquantes dans le graphique de connaissances, l'explication peut aider à identifier et à résoudre ces problèmes, ce qui permet d'améliorer la précision et l'exhaustivité des réponses.
En utilisant les graphes de connaissances, les applications RAG peuvent créer des réponses plus précises, plus claires et plus compréhensibles. Ils sont donc utiles pour différentes tâches de traitement du langage naturel.
Lorsque vous créez des applications RAG, vous pouvez rencontrer deux approches différentes : les graphes de connaissances et les bases de données vectorielles. Bien qu'ils soient tous deux utilisés pour représenter et rechercher des informations, ils diffèrent par leurs structures de données sous-jacentes et par la manière dont ils traitent les informations.
Examinons les principales différences entre ces deux approches :
|
Fonctionnalité |
Graphes de connaissances |
Bases de données vectorielles |
|
Représentation des données |
Entités (nœuds) et relations (arêtes) entre les entités, formant une structure graphique. |
Vecteurs à haute dimension, représentant chacun un élément d'information (par exemple, un document, une phrase). |
|
Mécanismes de récupération |
Traverser la structure du graphe et suivre les relations entre les entités. Permet l'inférence et la dérivation de nouvelles connaissances. |
Similitude vectorielle basée sur une métrique de similarité (par exemple, la similarité cosinus). Renvoie les vecteurs les plus similaires et les informations associées. |
|
Interprétabilité |
Représentation de la connaissance interprétable par l'homme. La structure du graphe et les relations étiquetées clarifient les connexions entre les entités. |
Moins interprétables par l'homme en raison des représentations numériques à haute dimension. Difficulté à comprendre directement les relations ou le raisonnement qui sous-tendent les informations extraites. |
|
Intégration des connaissances |
Facilite l'intégration en représentant les entités et les relations dans une structure graphique unifiée. Intégration transparente si les entités et les relations sont correctement cartographiées. |
Plus de défis. Nécessite des techniques telles que l'alignement de l'espace vectoriel ou des méthodes d'ensemble pour combiner les informations. Assurer la compatibilité des vecteurs peut s'avérer difficile. |
|
Raisonnement déductif |
Permet un raisonnement déductif en parcourant la structure du graphe et en exploitant les relations entre les entités. Découvrir des liens implicites et en tirer de nouvelles idées. |
Plus limité. S'appuie sur la similarité des vecteurs et peut ne pas tenir compte des relations implicites ou des déductions. Peut identifier des informations similaires mais pas de relations complexes à partir de graphiques de connaissances. |
Les graphes de connaissances et les bases de données vectorielles ont tous deux leurs points forts et leurs cas d'utilisation, et le choix entre les deux dépend des exigences spécifiques de votre application. Les graphes de connaissances excellent dans la représentation et le raisonnement sur des connaissances structurées, tandis que les bases de données vectorielles sont bien adaptées aux tâches qui reposent fortement sur la similarité sémantique et la recherche d'informations sur la base de représentations vectorielles.
Pour en savoir plus sur les bases de données vectorielles, consultez cette introduction aux bases de données vectorielles pour l'apprentissage automatique. En outre, consultez les cinq bases de données vectorielles les plus populaires.
Dans cette section, nous verrons comment mettre en œuvre un graphe de connaissances afin d'améliorer le processus de génération de langage pour l'application RAG.
Nous aborderons les étapes clés suivantes :
À la fin de cette section, vous aurez acquis une solide compréhension de la mise en œuvre des graphes de connaissances dans les applications RAG, ce qui vous permettra de construire des systèmes de génération de langues plus intelligents et tenant compte du contexte.
Avant de commencer, assurez-vous que les éléments suivants sont installés :
pip install langchain)pip install llama-index)La première étape consiste à charger et à prétraiter les données textuelles à partir desquelles nous extrairons le graphe de connaissances. Dans cet exemple, nous utiliserons un extrait de texte décrivant une entreprise technologique appelée prismaticAI, ses employés et leurs rôles.
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
# Load text data
text = """Sarah is an employee at prismaticAI, a leading technology company based in Westside Valley. She has been working there for the past three years as a software engineer.
Michael is also an employee at prismaticAI, where he works as a data scientist. He joined the company two years ago after completing his graduate studies.
prismaticAI is a well-known technology company that specializes in developing cutting-edge software solutions and artificial intelligence applications. The company has a diverse workforce of talented individuals from various backgrounds.
Both Sarah and Michael are highly skilled professionals who contribute significantly to prismaticAI's success. They work closely with their respective teams to develop innovative products and services that meet the evolving needs of the company's clients."""
loader = TextLoader(text)
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=200, chunk_overlap=20)
texts = text_splitter.split_documents(documents)Nous commençons par importer les classes nécessaires de LangChain : TextLoader et CharacterTextSplitter. TextLoader charge les données textuelles, tandis que CharacterTextSplitter divise le texte en petits morceaux pour un traitement plus efficace.
Ensuite, nous définissons les données textuelles sous la forme d'une variable de type chaîne de caractères multilignes text.
Nous utilisons ensuite TextLoader pour charger les données textuelles directement à partir de la variable text. La méthode loader.load() renvoie une liste d'objets Document, chacun contenant un morceau du texte.
Pour diviser le texte en morceaux plus petits et plus faciles à gérer, nous créons une instance de CharacterTextSplitter avec un chunk_size de 200 caractères et un chunk_overlap de 20 caractères. Le paramètre chunk_overlap garantit un certain chevauchement entre les morceaux adjacents, ce qui peut être utile pour maintenir le contexte pendant le processus d'extraction des connaissances.
Enfin, nous utilisons la méthode split_documents de CharacterTextSplitter pour diviser les objets Document en morceaux plus petits, qui sont stockés dans la variable texts sous la forme d'une liste d'objets Document.
Le prétraitement des données textuelles de cette manière nous permet de les préparer pour l'étape suivante, au cours de laquelle nous initialiserons un modèle de langage et l'utiliserons pour extraire un graphe de connaissances à partir des morceaux de texte.
Après le chargement et le prétraitement des données textuelles, l'étape suivante consiste à initialiser un modèle linguistique et à l'utiliser pour extraire un graphe de connaissances à partir des morceaux de texte. Dans cet exemple, nous utiliserons le modèle linguistique OpenAI fourni par LangChain.
from langchain.llms import OpenAI
from langchain.transformers import LLMGraphTransformer
import getpass
import os
# Load environment variable for OpenAI API key
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Initialize LLM
llm = OpenAI(temperature=0)
# Extract Knowledge Graph
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(texts)Tout d'abord, nous importons les classes nécessaires de LangChain : OpenAI et LLMGraphTransformer. OpenAI est une enveloppe pour le modèle de langage OpenAI, que nous utiliserons pour extraire le graphe de connaissances. LLMGraphTransformer est une classe utilitaire qui aide à convertir les données textuelles en une représentation de graphe de connaissances.
Ensuite, nous chargeons la clé API OpenAI à partir d'une variable d'environnement. Il s'agit d'une bonne pratique de sécurité qui permet d'éviter de coder en dur des informations d'identification sensibles dans votre code.
Nous initialisons ensuite une instance du modèle linguistique OpenAI avec une température de 0. Le paramètre de température contrôle le caractère aléatoire de la sortie du modèle, des valeurs plus faibles produisant des réponses plus déterministes.
Après avoir initialisé le modèle linguistique, nous créons une instance de LLMGraphTransformer et lui transmettons l'objet llm initialisé. La classe LLMGraphTransformer convertit les morceaux de texte (texts) en une représentation sous forme de graphe de connaissances.
Enfin, nous appelons la méthode convert_to_graph_documents de LLMGraphTransformer, en lui transmettant la liste des textes. Cette méthode utilise le modèle linguistique pour analyser les morceaux de texte et extraire les entités, relations et autres informations structurées pertinentes, qui sont ensuite représentées sous la forme d'un graphe de connaissances. Le graphe de connaissances résultant est stocké dans la variable graph_documents.
Nous avons initialisé avec succès un modèle linguistique et l'avons utilisé pour extraire un graphe de connaissances à partir des données textuelles. Dans l'étape suivante, nous stockerons le graphe de connaissances dans une base de données pour la persistance et l'interrogation.
Après avoir extrait le graphe de connaissances des données textuelles, il est important de le stocker dans un format persistant et interrogeable. Dans ce tutoriel, nous utiliserons Neo4j pour stocker le graphe de connaissances.
from langchain.graph_stores import Neo4jGraphStore
# Store Knowledge Graph in Neo4j
graph_store = Neo4jGraphStore(url="neo4j://your_neo4j_url", username="your_username", password="your_password")
graph_store.write_graph(graph_documents)Tout d'abord, nous importons la classe Neo4jGraphStore de LangChain. Cette classe fournit une interface pratique pour interagir avec une base de données Neo4j et stocker des graphes de connaissances.
Ensuite, nous créons une instance de Neo4jGraphStore en fournissant les détails de connexion nécessaires : l'URL de la base de données Neo4j, le nom d'utilisateur et le mot de passe. Veillez à remplacer "your_neo4j_url", "your_username", et "your_password" par les valeurs appropriées pour votre instance Neo4j.
Enfin, nous appelons la méthode write_graph de l'instance graph_store, en lui transmettant la liste graph_documents obtenue à l'étape précédente. Cette méthode sérialise le graphe de connaissances et l'écrit dans la base de données Neo4j.
Le stockage du graphe de connaissances dans une base de données Neo4j nous permet de nous assurer qu'il est persistant et qu'il peut être facilement interrogé et récupéré en cas de besoin. La structure graphique de Neo4j permet de représenter et de parcourir efficacement les relations complexes et les entités présentes dans le graphe de connaissances.
Dans l'étape suivante, nous mettrons en place les composants permettant d'extraire les connaissances du graphe et de générer des réponses en utilisant le contexte extrait.
Il est important de noter que si ce tutoriel utilise Neo4j comme base de données de graphes, LangChain supporte également d'autres bases de données de graphes, comme Amazon Neptune et des bases de données compatibles avec TinkerPop comme Gremlin Server. Vous pouvez remplacer le site Neo4jGraphStore par l'implémentation du magasin de graphes appropriée à la base de données que vous avez choisie.
Maintenant que nous avons stocké le graphe de connaissances dans une base de données, nous pouvons mettre en place les composants permettant d'extraire les connaissances pertinentes du graphe en fonction des requêtes de l'utilisateur et de générer des réponses à l'aide du contexte extrait. Il s'agit de la fonctionnalité de base d'une application RAG.
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import KnowledgeGraphRAGRetriever
from llama_index.core.response_synthesis import ResponseSynthesizer
# Retrieve Knowledge for RAG
graph_rag_retriever = KnowledgeGraphRAGRetriever(storage_context=graph_store.storage_context, verbose=True)
query_engine = RetrieverQueryEngine.from_args(graph_rag_retriever)Tout d'abord, nous importons les classes nécessaires de LlamaIndex : RetrieverQueryEngine, KnowledgeGraphRAGRetriever, et ResponseSynthesizer.
RetrieverQueryEngine est un moteur de requête qui utilise un extracteur pour récupérer le contexte pertinent d'une source de données (dans notre cas, le graphe de connaissances) et synthétise ensuite une réponse à l'aide de ce contexte.
KnowledgeGraphRAGRetriever est un récupérateur spécialisé qui peut extraire des informations pertinentes d'un graphe de connaissances stocké dans une base de données.
ResponseSynthesizer est chargé de générer une réponse finale en combinant le contexte récupéré avec un modèle linguistique.
Ensuite, nous créons une instance de KnowledgeGraphRAGRetriever en passant le storage_context de notre instance graph_store. Ce site storage_context contient les informations nécessaires pour se connecter à la base de données Neo4j, où nous avons stocké le graphe de connaissances, et pour l'interroger. Nous avons également configuré verbose=True pour permettre un enregistrement détaillé pendant le processus d'extraction.
Ensuite, nous initialisons un site RetrieverQueryEngine à l'aide de la méthode from_args et nous lui transmettons notre instance graph_rag_retriever. Ce moteur de requête se chargera de l'ensemble du processus de récupération du contexte pertinent à partir du graphe de connaissances et de la génération d'une réponse basée sur ce contexte.
Avec ces composants mis en place, nous sommes maintenant prêts à interroger le graphe de connaissances et à générer des réponses en utilisant le contexte récupéré. Dans l'étape suivante, nous verrons comment procéder en pratique.
Enfin, nous pouvons interroger le graphe de connaissances et générer des réponses en utilisant le contexte récupéré.
def query_and_synthesize(query):
retrieved_context = query_engine.query(query)
response = response_synthesizer.synthesize(query, retrieved_context)
print(f"Query: {query}")
print(f"Answer: {response}\n")
# Initialize the ResponseSynthesizer instance
response_synthesizer = ResponseSynthesizer(llm)
# Query 1
query_and_synthesize("Where does Sarah work?")
# Query 2
query_and_synthesize("Who works for prismaticAI?")
# Query 3
query_and_synthesize("Does Michael work for the same company as Sarah?")Dans cet exemple, nous définissons trois requêtes différentes relatives aux employés et à l'entreprise décrits dans les données textuelles. Pour chaque requête, nous utilisons query_engine pour extraire le contexte pertinent du graphe de connaissances, créons une instance de ResponseSynthesizer et appelons sa méthode synthesize avec la requête et le contexte extrait.
Le site ResponseSynthesizer utilise le modèle linguistique et le contexte récupéré pour générer une réponse finale à la requête, qui est ensuite imprimée sur la console, correspondant aux réponses de la première section de cet article.
Bien que le tutoriel démontre l'utilisation d'un graphe de connaissances pour les applications RAG avec un texte relativement simple, les scénarios du monde réel impliquent souvent des ensembles de données plus complexes et plus diversifiés. En outre, les données d'entrée peuvent se présenter sous différents formats de fichiers autres que le texte brut. Dans cette section, nous verrons comment l'application RAG basée sur les graphes de connaissances peut être étendue pour gérer de tels scénarios.
Au fur et à mesure que la taille et la complexité des données d'entrée augmentent, le processus d'extraction des graphes de connaissances peut devenir plus difficile. Voici quelques stratégies pour traiter des ensembles de données volumineux et diversifiés :
Dans le monde réel, les données peuvent se présenter sous différents formats de fichiers, tels que des PDF, des documents Word, des feuilles de calcul ou même des formats de données structurées tels que JSON ou XML. Pour gérer ces différents types de fichiers, vous pouvez utiliser les stratégies suivantes :
Ces stratégies vous aideront à étendre l'application RAG basée sur le graphe de connaissances pour traiter des ensembles de données plus complexes et plus diversifiés, ainsi qu'un plus large éventail de types de fichiers.
Il est important de noter qu'au fur et à mesure que la complexité des données d'entrée augmente, le processus d'extraction des graphes de connaissances peut nécessiter une personnalisation et un réglage plus spécifiques au domaine afin de garantir des résultats précis et fiables.
La mise en place de graphes de connaissances pour les applications RAG dans le monde réel peut s'avérer une tâche complexe comportant plusieurs défis. Examinons-en quelques-unes :
La construction d'un graphe de connaissances de haute qualité est un processus complexe et fastidieux qui nécessite une expertise et des efforts considérables dans le domaine. L'extraction d'entités, de relations et de faits à partir de diverses sources de données et leur intégration dans un graphe de connaissances cohérent peut s'avérer difficile, en particulier pour les ensembles de données volumineux et diversifiés. Il s'agit de comprendre le domaine, d'identifier les informations pertinentes et de les structurer de manière à rendre compte avec précision des relations et de la sémantique.
Les applications RAG doivent souvent intégrer des données provenant de sources multiples et hétérogènes, chacune ayant sa propre structure, son propre format et sa propre sémantique. Assurer la cohérence des données, résoudre les conflits et mettre en correspondance les entités et les relations entre différentes sources de données n'est pas une mince affaire. Elle nécessite un nettoyage, une transformation et un mappage minutieux des données afin de garantir que le graphe de connaissances représente avec précision les informations provenant de diverses sources.
Les graphes de connaissances ne sont pas statiques. Ils doivent être continuellement mis à jour et entretenus au fur et à mesure que de nouvelles informations sont disponibles ou que les informations existantes changent. Maintenir le graphe de connaissances à jour et cohérent avec l'évolution des sources de données peut être un processus gourmand en ressources. Il s'agit de surveiller les changements dans les sources de données, d'identifier les mises à jour pertinentes et de propager ces mises à jour dans le graphe de connaissances tout en maintenant son intégrité et sa cohérence.
Au fur et à mesure que la taille et la complexité des graphes de connaissances augmentent, il devient de plus en plus difficile d'assurer un stockage, une récupération et une interrogation efficaces des données des graphes. Des problèmes d'évolutivité et de performance peuvent se poser, en particulier pour les applications RAG à grande échelle avec des volumes d'interrogation élevés. L'optimisation des techniques de stockage, d'indexation et de traitement des requêtes des graphes de connaissances devient cruciale pour maintenir des niveaux de performance acceptables.
Bien que les graphes de connaissances excellent dans la représentation de relations complexes et dans le raisonnement multi-sauts, la formulation et l'exécution de requêtes complexes qui exploitent ces capacités peuvent s'avérer difficiles. Le développement d'algorithmes efficaces de traitement des requêtes et de raisonnement est un domaine de recherche actif. Il est important de comprendre le langage d'interrogation et les capacités de raisonnement du système de graphe de connaissances afin d'utiliser efficacement tout son potentiel.
Il n'existe pas de normes largement adoptées pour la représentation et l'interrogation des graphes de connaissances, ce qui peut entraîner des problèmes d'interopérabilité et de verrouillage des fournisseurs. Les différents systèmes de graphes de connaissances peuvent utiliser des modèles de données, des langages d'interrogation et des API différents, ce qui complique le passage d'un système à l'autre ou l'intégration avec d'autres systèmes. L'adoption ou l'élaboration de normes peut faciliter l'interopérabilité et réduire la dépendance à l'égard des fournisseurs.
Si les graphes de connaissances peuvent fournir un raisonnement explicable et transparent, s'assurer que le processus de raisonnement est facilement interprétable et compréhensible pour les utilisateurs finaux peut être un défi, en particulier pour les requêtes ou les parcours de raisonnement complexes. Le développement d'interfaces conviviales et d'explications qui communiquent clairement le processus de raisonnement et ses hypothèses sous-jacentes est important pour la confiance et l'adoption des utilisateurs.
En fonction du domaine et de l'application, il peut y avoir des défis supplémentaires spécifiques à ce domaine, tels que la gestion de la terminologie, des ontologies ou des formats de données spécifiques au domaine. Par exemple, dans le domaine médical, la gestion de terminologies médicales complexes, de systèmes de codage et de problèmes de confidentialité peut ajouter des couches de complexité supplémentaires à la configuration et à l'utilisation du graphe de connaissances.
Malgré ces défis, les graphes de connaissances offrent des avantages significatifs pour les applications RAG, notamment en termes de représentation de connaissances structurées, de raisonnement complexe et de fourniture de résultats explicables et transparents. Il est essentiel de relever ces défis par une conception minutieuse des graphes de connaissances, des stratégies d'intégration des données et des techniques efficaces de traitement des requêtes pour mettre en œuvre avec succès les applications RAG basées sur les graphes de connaissances.
Dans ce tutoriel, nous avons exploré la puissance des graphes de connaissances pour créer des réponses plus précises, plus informatives et plus pertinentes sur le plan contextuel. Nous avons commencé par comprendre les concepts fondamentaux des graphes de connaissances et leur rôle dans les applications RAG. Ensuite, nous avons présenté un exemple pratique, en extrayant un graphe de connaissances à partir de données textuelles, en le stockant dans une base de données Neo4j, et en l'utilisant pour extraire un contexte pertinent pour les requêtes des utilisateurs. Enfin, nous avons démontré comment utiliser le contexte récupéré pour générer des réponses à l'aide des connaissances structurées dans le graphe.
Si vous souhaitez en savoir plus sur l'IA et les LLM, consultez ce cursus de six cours sur les fondamentaux de l'IA.
J'espère que vous avez trouvé ce tutoriel utile et amusant, et je vous donne rendez-vous au prochain tutoriel.
Bon codage !
En savoir plus sur l'IA et les LLM !
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach