
programa
Fundamentos de la IA
10 h
Las empresas de todo el mundo están cada vez más preocupadas por proteger la información sensible a la vez que aprovechan el poder de la IA. Esta guía presenta una solución completa para crear aplicaciones de IA locales y seguras utilizando una potente combinación de herramientas de código abierto.
Utilizaremos el Kit de iniciación a la IA autoalojada para crear rápidamente un entorno local de IA. Este kit ejecutará automáticamente Ollama, Qdrant, n8n y Postgres. Además, aprenderemos a construir un flujo de trabajo de IA para un chatbot RAG (generación aumentada por recuperación) utilizando el conjunto de datos de Harry Potter a través del panel n8n.
Tanto si eres un desarrollador, un científico de datos o un profesional no técnico que busca implantar soluciones de IA seguras, este tutorial te proporcionará las bases para crear flujos de trabajo de IA potentes y autoalojados, al tiempo que mantienes un control total sobre tus datos sensibles.
La IA local te permite ejecutar sistemas de inteligencia artificial y flujos de trabajo en tu propia infraestructura en lugar de servicios en la nube, lo que proporciona una mayor privacidad y rentabilidad.
Si eres nuevo en el ecosistema de la IA, primero deberías consultar nuestra pista de habilidades sobre Fundamentos de la IA para ponerte al día. Al completar esta serie de cursos, adquirirás conocimientos prácticos sobre temas populares de IA, como ChatGPT, grandes modelos de lenguaje, IA generativa y mucho más.
Imagen del autor
Ésta es la lista de herramientas que utilizaremos para construir y ejecutar nuestras aplicaciones locales de IA:
El n8n es nuestro marco principal para construir el flujo de trabajo de IA para el Chatbot RAG. Utilizaremos Qdrant como almacén de vectores y Ollama como proveedor de modelos de IA. Juntos, estos componentes nos ayudarán a crear el sistema GAR.
Descargaremos e instalaremos el Docker accediendo al sitio web oficial de Docker. Es bastante fácil de instalar y poner en marcha.
Aprende más sobre Docker siguiendo el Docker para la Ciencia de Datos o sigue nuestro curso Curso de Introducción a Docker.
Fuente: Docker: Desarrollo acelerado de aplicaciones en contenedores
Los usuarios de Windows necesitan una herramienta adicional para ejecutar con éxito los contenedores Docker: el Subsistema Windows para Linux (WSL). Esto permite a los desarrolladores instalar una distribución Linux y utilizar aplicaciones Linux directamente en Windows.
Para instalar WSL en Windows, escribe el siguiente comando en el terminal o en PowerShell. Asegúrate de iniciar PowerShell como administrador.
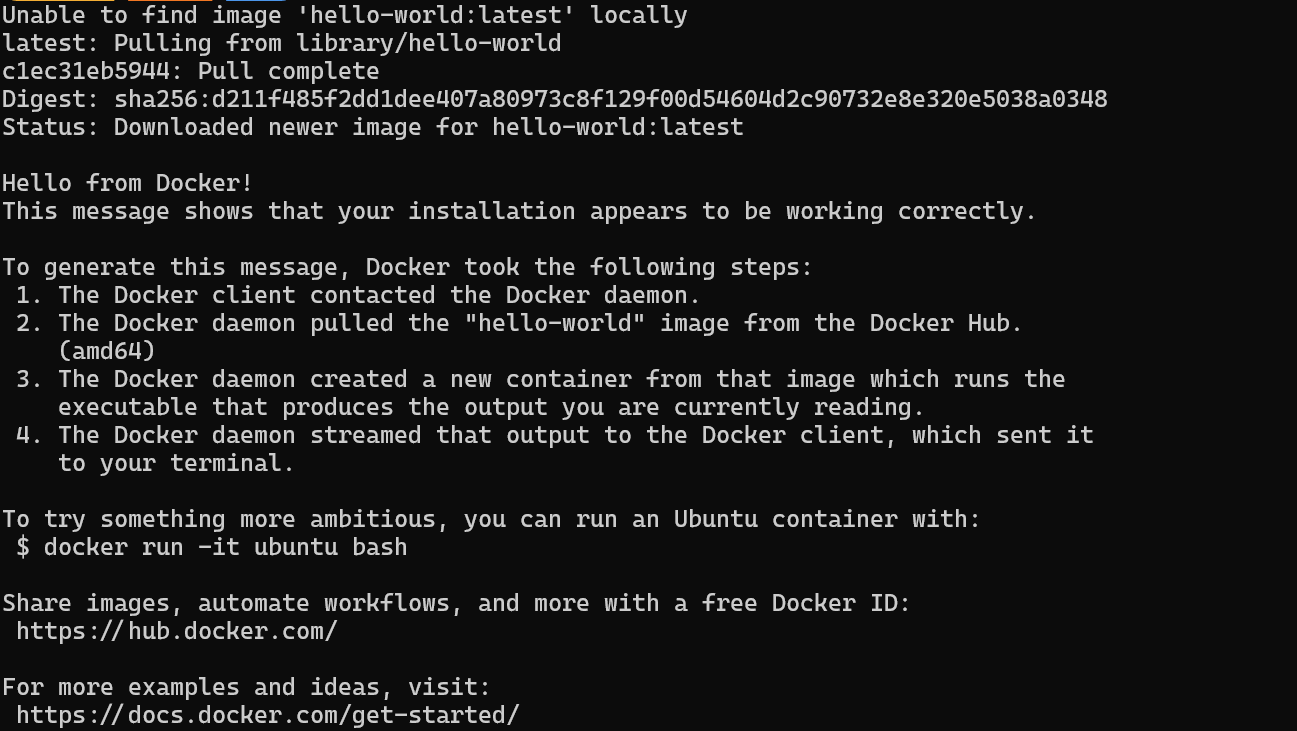
$ wsl --installTras instalar correctamente WSL, reinicia el sistema. A continuación, escribe el siguiente comando en PowerShell para comprobar si Docker funciona correctamente.
$ docker run hello-worldDocker ha extraído correctamente la imagen hello-world y ha iniciado el contenedor.
En esta guía, aprenderemos a utilizar Docker Compose para configurar servicios de IA localmente. Este enfoque te permite cargar imágenes Docker y desplegar contenedores en cuestión de minutos, proporcionando una forma sencilla de ejecutar y gestionar múltiples servicios de IA en tu infraestructura.
En primer lugar, clonaremos n8n-io/self-hosted-ai-starter-kit escribiendo el siguiente comando en el terminal.
$ git clone https://github.com/n8n-io/self-hosted-ai-starter-kit.git
$ cd self-hosted-ai-starter-kitEl kit de inicio es la forma más sencilla de configurar los servidores y aplicaciones necesarios para crear un flujo de trabajo de IA. A continuación, cargaremos las imágenes Docker y ejecutaremos los contenedores.
$ docker compose --profile cpu upSi tienes una GPU NVIDIA, prueba a escribir el siguiente comando para acceder a la aceleración en la generación de respuestas. Además, configura la GPU NVIDIA para Docker siguiendo las instrucciones de Ollama Docker de Ollama.
$ docker compose --profile gpu-nvidia upTardará unos minutos mientras descarga todas las imágenes Docker y luego ejecuta los contenedores Docker uno a uno.
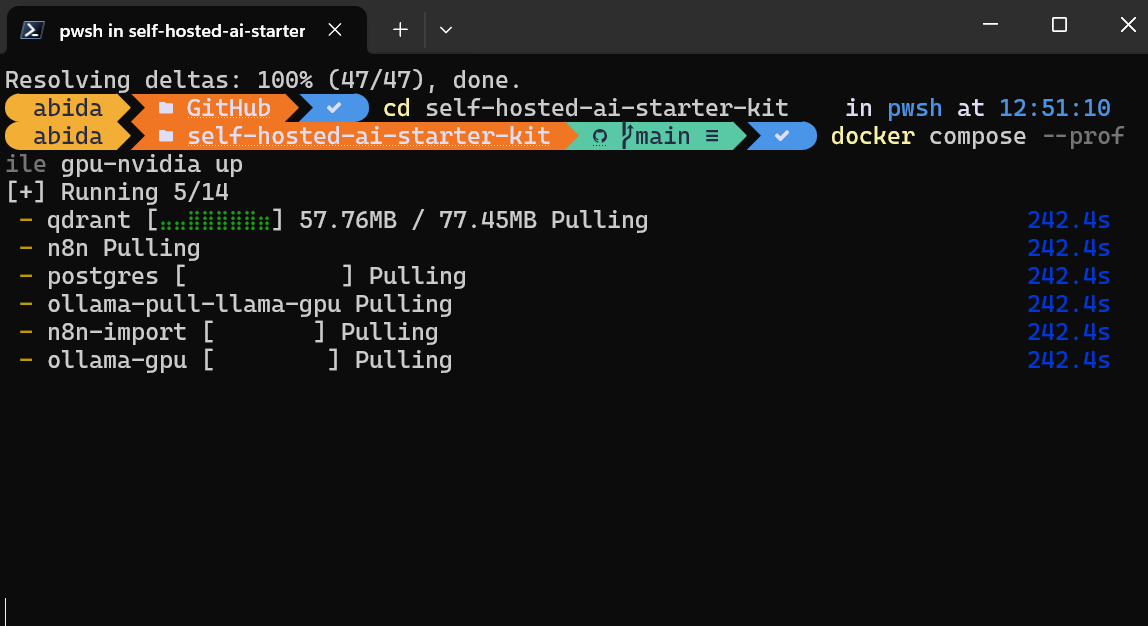
Todos los servicios Docker están en marcha. Los contenedores Docker salidos se utilizaron para descargar el modelo Llama 3.2 e importar el flujo de trabajo de copia de seguridad n8n.
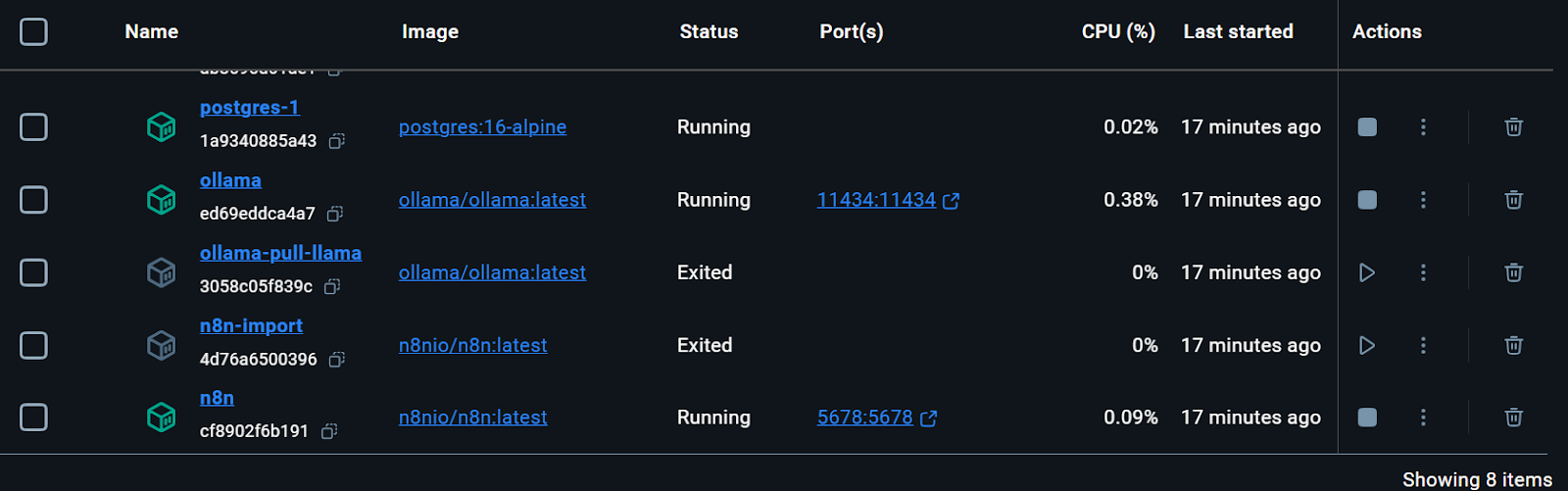
Incluso podemos comprobar el estado de ejecución del contenedor docker escribiendo el siguiente comando en el terminal.
$ docker compose psEl kit de inicio incluía el script para descargar el modelo Llama 3.2. Sin embargo, para una aplicación Chatbot RAG adecuada, también necesitamos el modelo de incrustación. Iremos al contenedor Docker de Ollama, haremos clic en la pestaña "Ejecutar" y escribiremos el siguiente comando para descargar el modelo "nomic-embed-text".
$ ollama pull nomic-embed-textComo vemos, podemos interactuar con un contenedor Docker como si fuera una máquina virtual independiente.
Abre la URL del salpicadero n8n http://localhost:5678/ en tu navegador para configurar una cuenta de usuario n8n con correo electrónico y contraseña. A continuación, haz clic en el botón de inicio de la página principal del panel de control y accede al flujo de trabajo Demo.
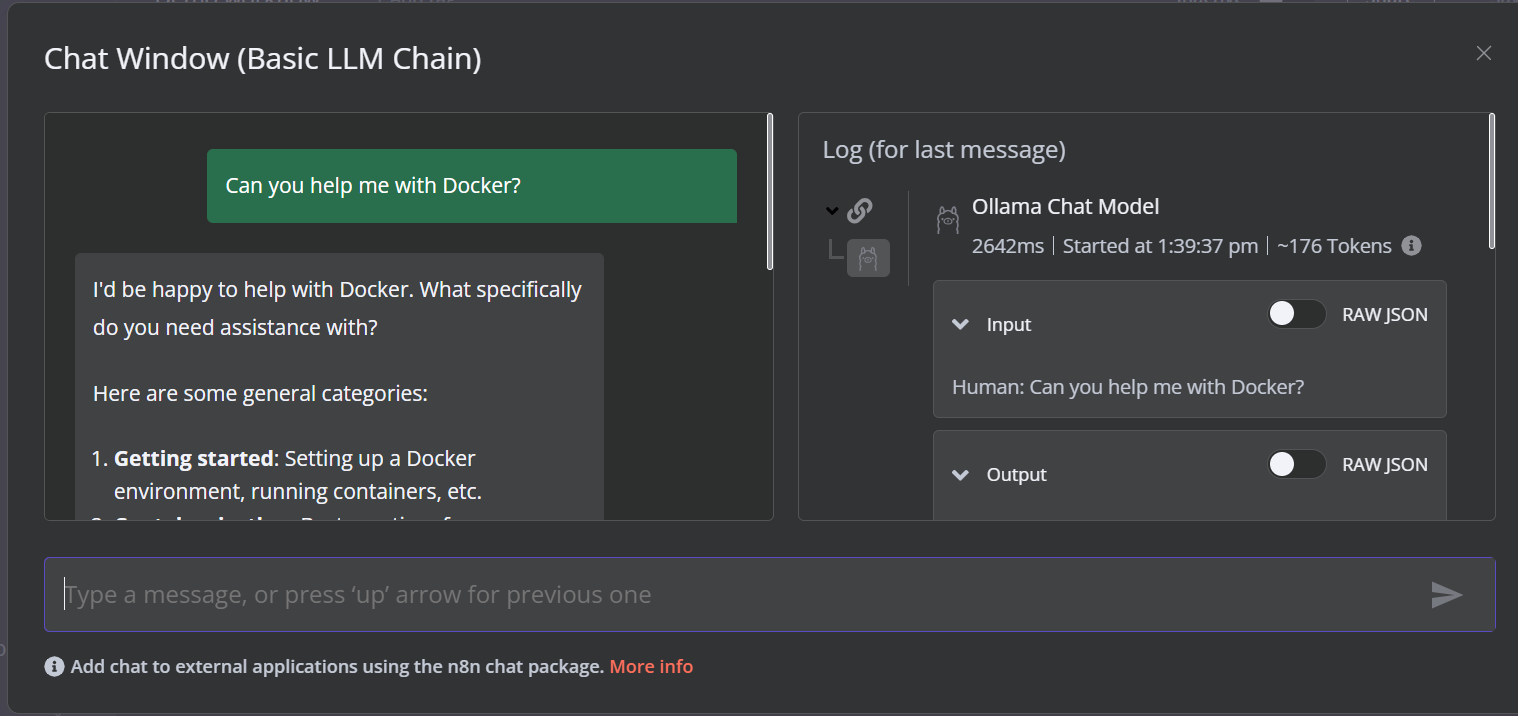
La demostración es un simple flujo de trabajo LLM que toma la entrada del usuario y genera la respuesta.
Para ejecutar el flujo de trabajo, haz clic en el botón Chat y empieza a escribir tu pregunta. En unos segundos se generará una respuesta.
Ten en cuenta que estamos utilizando un modelo de lenguaje pequeño con aceleración por GPU, por lo que la respuesta suele tardar sólo unos 2 segundos.
En este proyecto, construiremos un RAG (Generación Recuperada-Aumentada) que utiliza datos de las películas de Harry Potter para proporcionar respuestas precisas y contextualizadas. Este proyecto es una solución sin código, lo que significa que todo lo que tienes que hacer es buscar los componentes necesarios del flujo de trabajo y conectarlos para crear un flujo de trabajo de IA.
n8n es una plataforma sin código similar a Langchain. Sigue el RAG con Llama 3.1 8B, Ollama y Langchain para obtener una visión general de cómo crear un flujo de trabajo de IA similar utilizando Langchain.
Haz clic en el botón "Añadir el primer paso" en el centro del panel de control, busca el "Activador de chat" y añádelo.
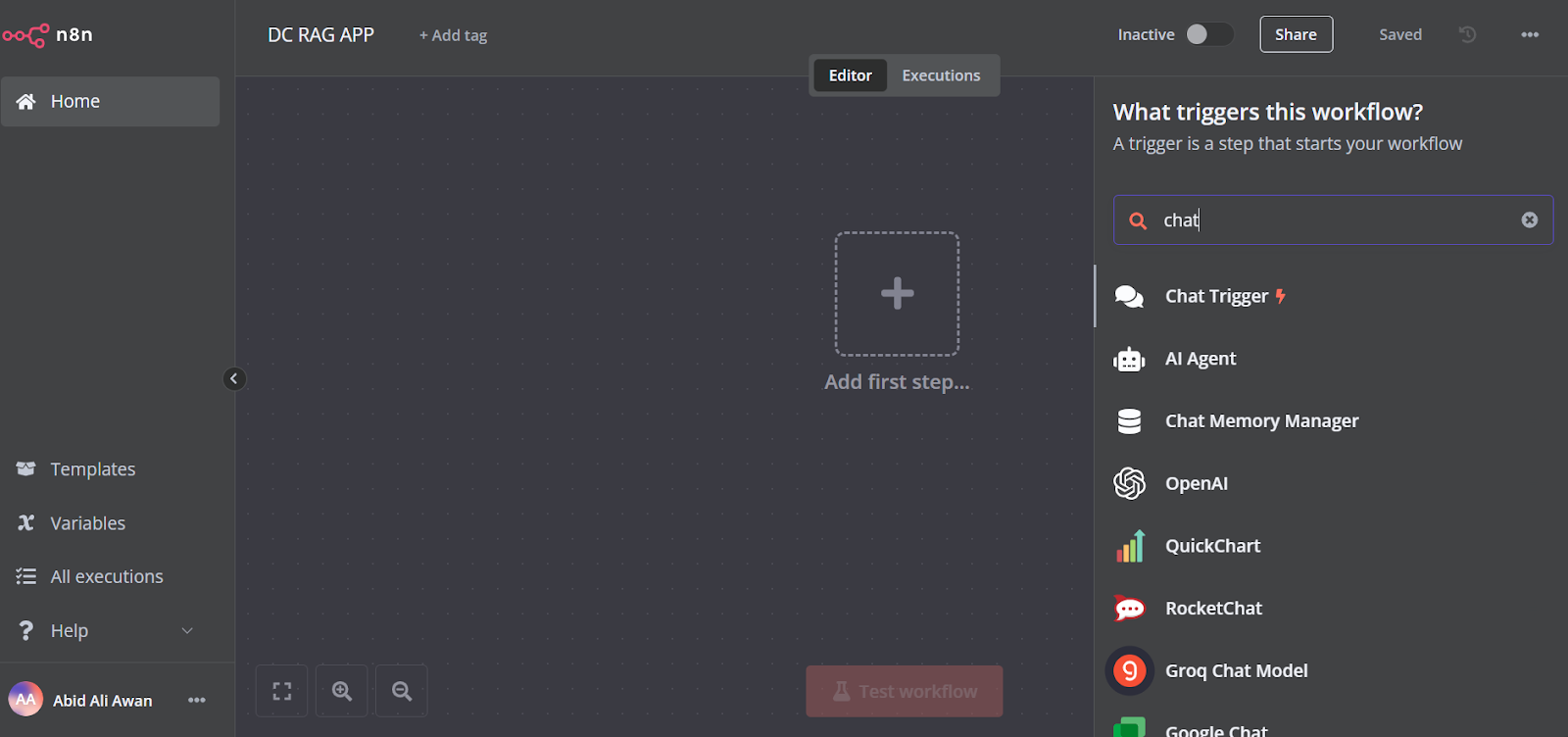
Asegúrate de que has activado "Permitir subir archivos".
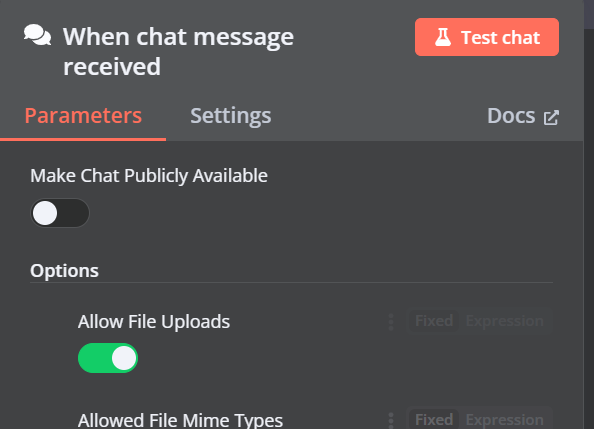
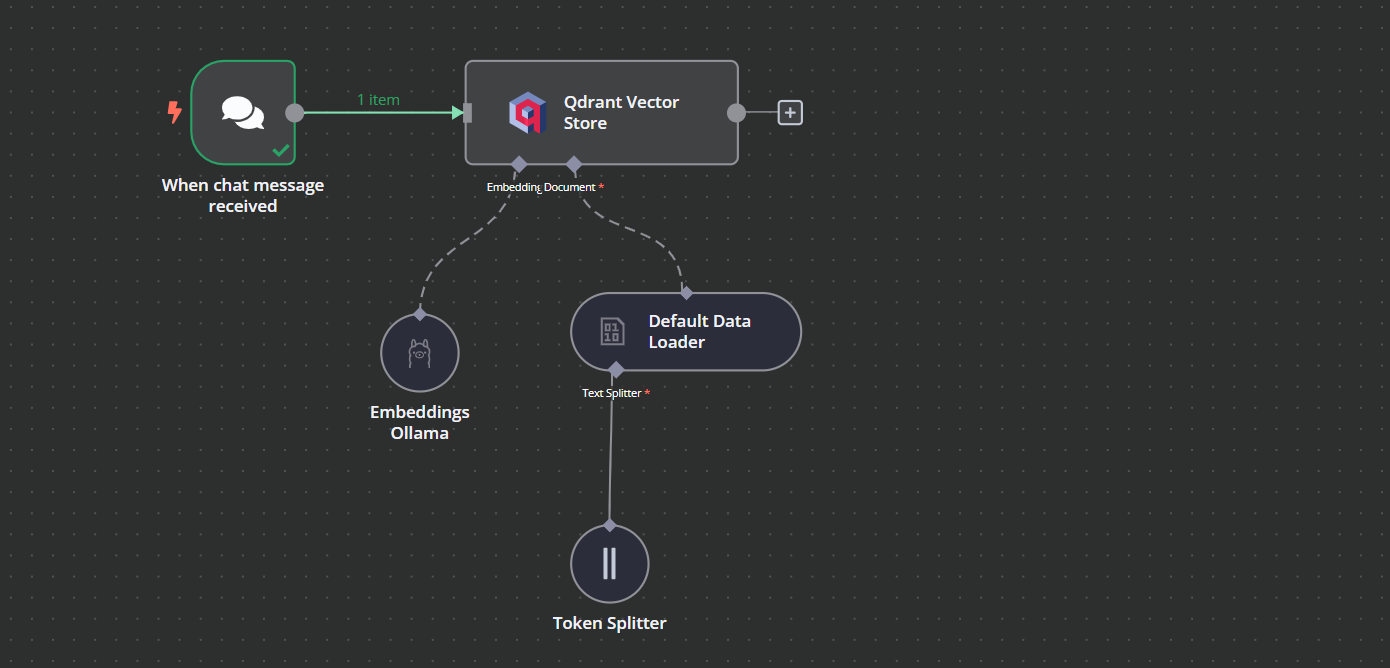
Puedes añadir otro componente llamado "Almacén vectorial Qdrant" haciendo clic en el botón más (+) del componente "Activador de chat" y buscándolo.
Cambia el modo de operación a "Insertar documentos", cambia la colección Qdrant a "Por ID" y escribe el ID como "Harry_Potter".
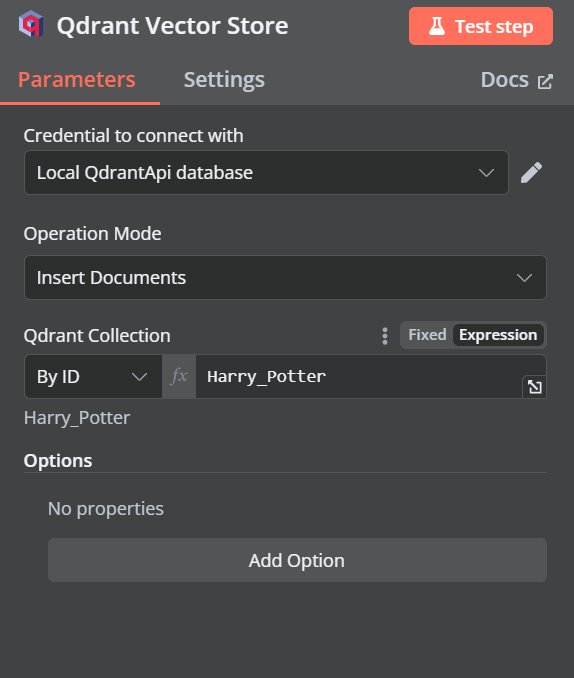
Cuando salgamos de la opción, veremos que el activador del chat está conectado con nuestro almacén vectorial.
Haz clic en el botón más situado bajo el almacén de vectores Qdrant, etiquetado como "Incrustación". Pasaremos al menú de gestión de modelos, donde seleccionaremos incrustaciones Ollama y cambiaremos el modelo a "nomic-embed-text:latest".
Haz clic en el botón más situado bajo el almacén vectorial Qdrant, que dice "Documento", y selecciona "Cargador de datos por defecto" en el menú. Cambia el tipo de los datos a "Binario".
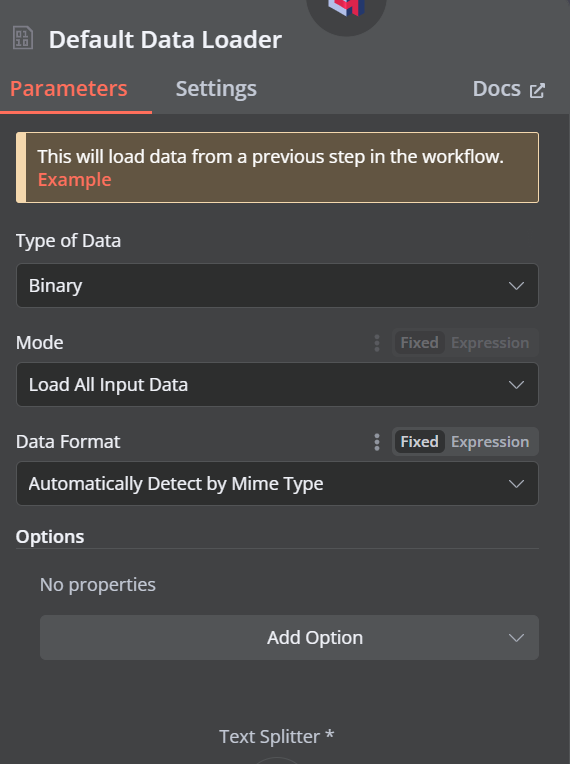
A continuación, añade un divisor de tokens con un tamaño de trozo de 500 y un solapamiento de trozo de 50 se añadirá al cargador de documentos.
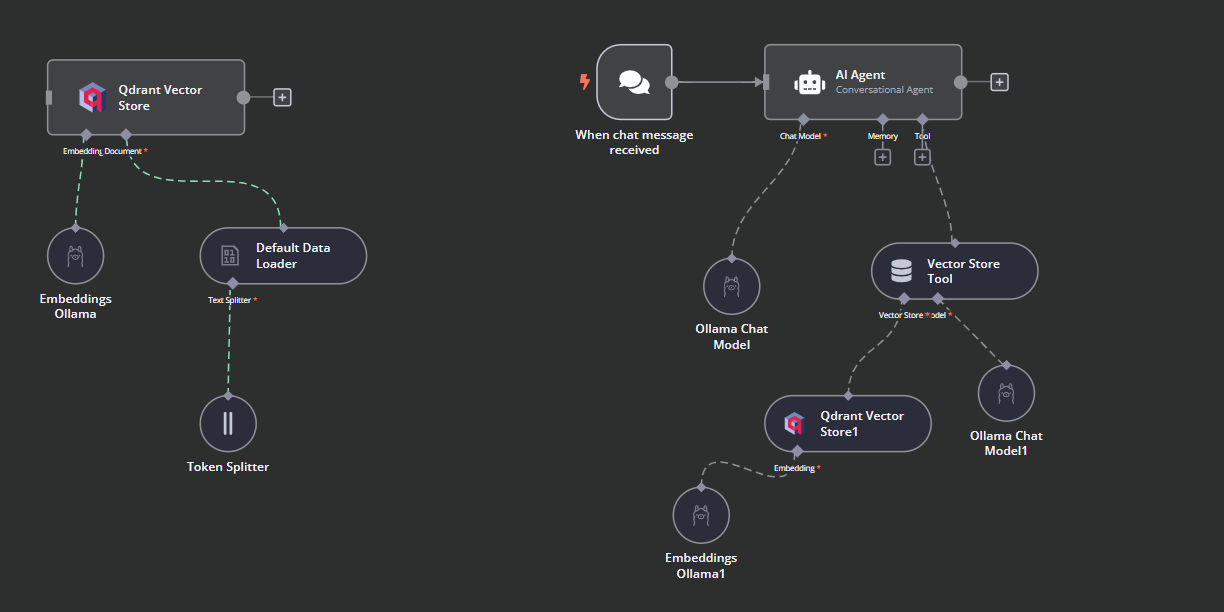
Así es como debe quedar nuestro flujo de trabajo al final. Este flujo de trabajo tomará los archivos CSV del usuario, los convertirá en texto, luego transformará el texto en incrustaciones y las almacenará en el almacén vectorial.
Haz clic en el botón Chat situado en la parte inferior del panel de control. Una vez que se abra la ventana del chat, haz clic en el botón de archivo, como se muestra a continuación.
En este flujo de trabajo, cargaremos todos los archivos CSV del archivo Películas de Harry Potter de Harry Potter. Sin embargo, para probar nuestro flujo de trabajo, sólo cargaremos un único archivo CSV llamado "hechizo" basado en una consulta del usuario.
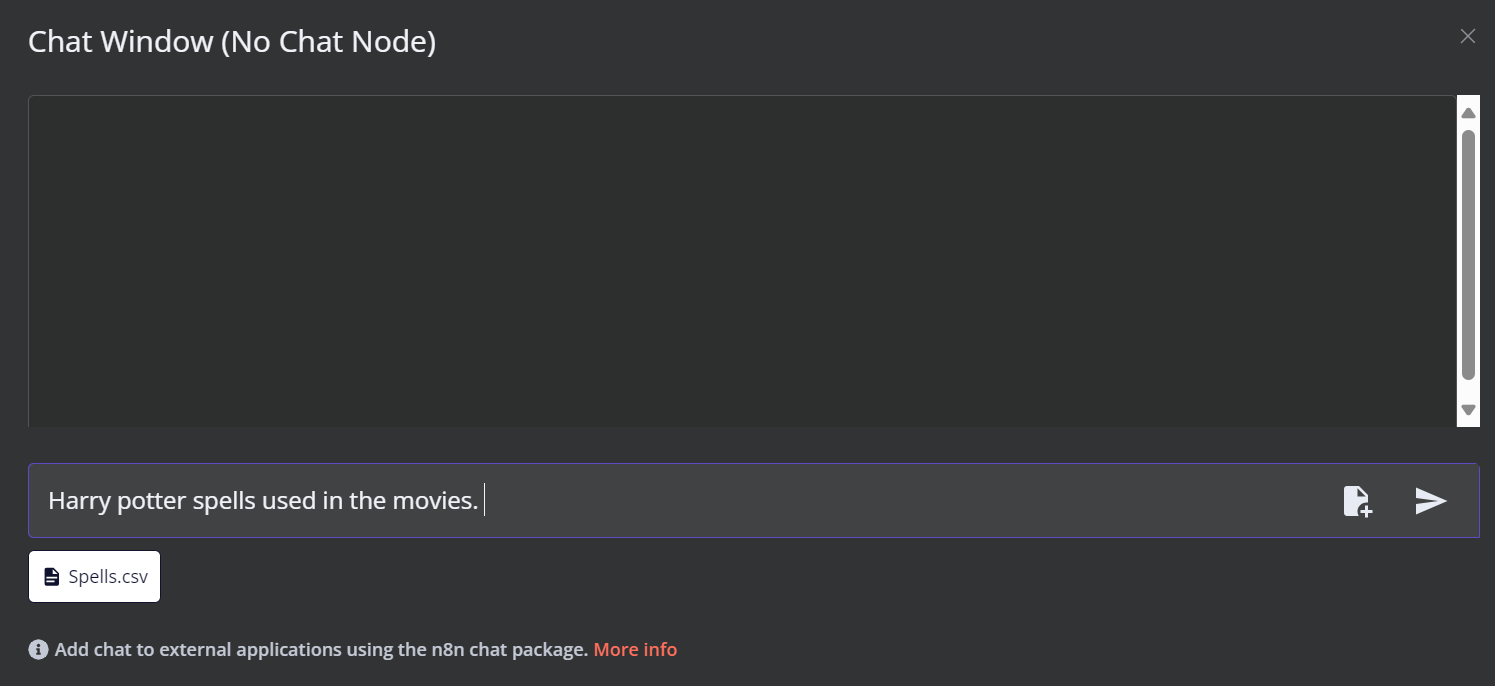
Puedes ir al servidor Qdrant utilizando la URL http://localhost:6333/dashboard y comprobar si el archivo se ha cargado en el almacén vectorial o nota.
Ahora, añade el resto de archivos al almacén vectorial.
Conectaremos el activador de chat al almacén de vectores, lo vincularemos al agente de IA y cambiaremos el tipo de agente a "Agente de Conversación".
Haz clic en el botón "Modelo de Chat" bajo Agente AI y selecciona el modelo de Chat Ollama en el menú. Después, canta el nombre del modelo a "Llama3.2:latest".
Haz clic en el botón "Herramienta" situado bajo el agente AI y selecciona la herramienta de almacén vectorial en el menú. Indica el nombre de la herramienta y la descripción.
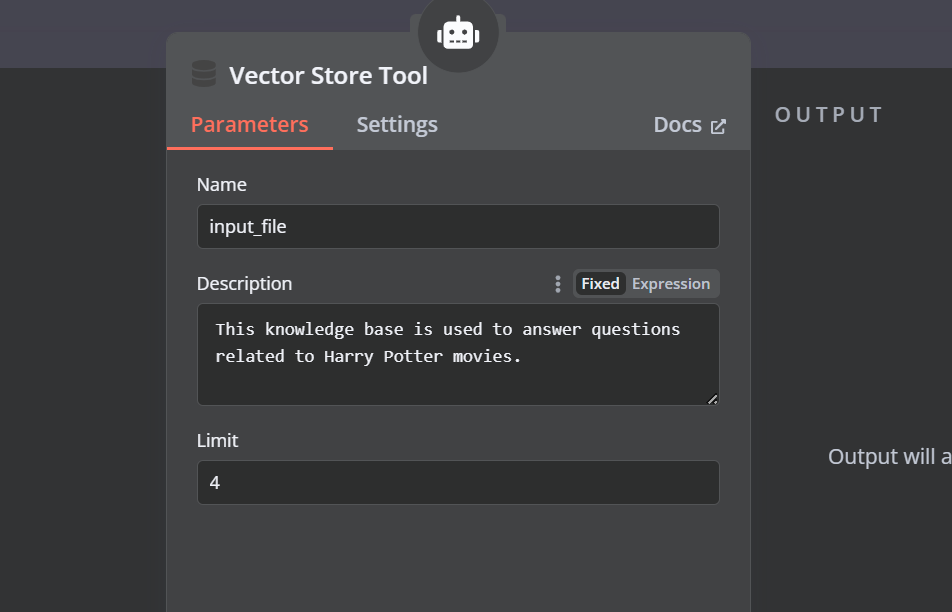
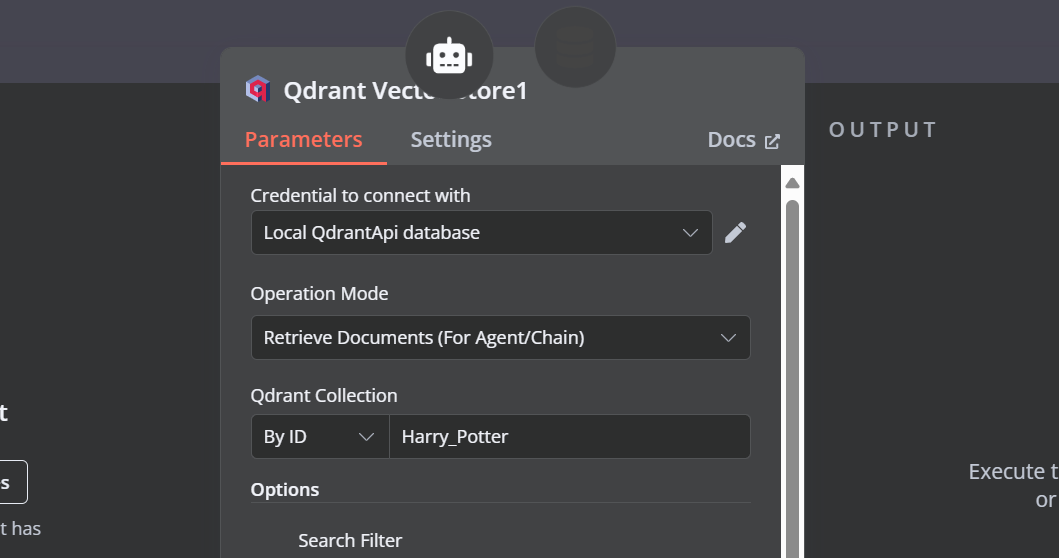
Tenemos que añadir componentes a la herramienta de almacén vectorial. En primer lugar, incorporaremos Qdrant como almacén de vectores y estableceremos el ID de la colección en "Harry_Potter". Este almacén vectorial accederá a la colección de Harry Potter durante la búsqueda de similitudes. Además, cambia el modo de funcionamiento a "Documentos recuperados".
La herramienta de almacén vectorial también requiere un modelo LLM. Conectaremos el modelo de chat de Ollama y cambiaremos el modelo a "llama3.2:latest".
En el último paso, suministraremos al almacén de vectores de recuperación el modelo de incrustación. Esto le permite convertir la consulta del usuario en una incrustación y luego volver a convertir la incrustación en texto para que lo procese el LLM.
Asegúrate de que proporcionas el modelo de incrustación correcto para tu almacén vectorial.
Así es como debería ser el flujo de trabajo de la IA.
Haz clic en el botón de chat para empezar a hacer preguntas sobre el universo de Harry Potter.
Prompt: "¿Cuál es el lugar más secreto de Hogwarts?"
Prompt: "¿Cuál es el hechizo más poderoso?"
Nuestro flujo de trabajo de IA es rápido y funciona sin problemas. Este enfoque sin código es bastante fácil de ejecutar. n8n también permite a los usuarios compartir sus aplicaciones para que cualquiera pueda acceder a ellas mediante un enlace, como si fuera un ChatGPT.
n8n es una herramienta perfecta para proyectos LLM/AI, especialmente para personas sin conocimientos técnicos. A veces, ni siquiera tenemos que crear el flujo de trabajo desde cero. Todo lo que tenemos que hacer es buscar proyectos similares en el sitio web de n8ncopiar el código JSON y pegarlo en nuestro panel n8n. Es así de sencillo.

Fuente: Descubre más de 900 flujos de trabajo de automatización de la Comunidad n8n
En este tutorial, hemos aprendido sobre la IA local y cómo utilizar el kit de inicio de IA autoalojado para construir y desplegar varios servicios de IA. A continuación, pusimos en marcha el salpicadero n8n y creamos nuestro propio flujo de trabajo de IA utilizando Qdrant, modelos de incrustación, herramientas de almacenamiento vectorial, LLM y cargadores de documentos. Crear y ejecutar flujos de trabajo es bastante fácil con n8n. Si eres nuevo en las herramientas de IA y quieres aprender sobre soluciones de IA sin código, consulta nuestros otros recursos:
Los mejores cursos de IA
programa
programa
Curso
blog
Abid Ali Awan
10 min
Tutorial
Moez Ali
Tutorial
Ryan Ong
Tutorial
Zoumana Keita
Tutorial

