
Programa
Fundamentos da IA
10 h
As empresas do mundo todo estão cada vez mais preocupadas em proteger informações confidenciais e, ao mesmo tempo, aproveitar o poder da IA. Este guia apresenta uma solução abrangente para a criação de aplicativos de IA locais e seguros usando uma combinação poderosa de ferramentas de código aberto.
Usaremos o Kit inicial de IA auto-hospedado para configurar rapidamente um ambiente local de IA. Esse kit executará automaticamente o Ollama, o Qdrant, o n8n e o Postgres. Além disso, aprenderemos a criar um fluxo de trabalho de IA para um chatbot RAG (Retrieval-augmented generation) usando o conjunto de dados do Harry Potter por meio do painel n8n.
Se você é um desenvolvedor, cientista de dados ou profissional não técnico que deseja implementar soluções seguras de IA, este tutorial fornecerá a base para criar fluxos de trabalho de IA avançados e auto-hospedados, mantendo o controle total sobre seus dados confidenciais.
A IA local permite que você execute sistemas de inteligência artificial e fluxos de trabalho em sua própria infraestrutura, em vez de serviços em nuvem, proporcionando maior privacidade e eficiência de custos.
Se você é novo no ecossistema de IA, primeiro deve conferir nossa trilha de habilidades sobre Fundamentos de IA para que você se familiarize com o assunto. Ao concluir esta série de cursos, você obterá conhecimento prático sobre tópicos populares de IA, como ChatGPT, modelos de linguagem grandes, IA generativa e muito mais.
Imagem do autor
Aqui está a lista de ferramentas que usaremos para criar e executar nossos aplicativos locais de IA:
O n8n é nossa principal estrutura para criar o fluxo de trabalho de IA para o RAG Chatbot. Usaremos o Qdrant como o armazenamento de vetores e o Ollama como o provedor de modelos de IA. Juntos, esses componentes nos ajudarão a criar o sistema RAG.
Faremos o download e instalaremos o Docker acessando o site oficial do Docker. É muito fácil de instalar e começar a usar.
Saiba mais sobre o Docker seguindo a seção Docker para ciência de dados ou faça nosso Curso de introdução ao Docker.
Fonte: Docker: Desenvolvimento acelerado de aplicativos em contêineres
Os usuários do Windows precisam de uma ferramenta adicional para executar com êxito os contêineres do Docker: o Windows Subsystem for Linux (WSL). Isso permite que os desenvolvedores instalem uma distribuição Linux e usem aplicativos Linux diretamente no Windows.
Para instalar a WSL no Windows, digite o seguinte comando no terminal ou no PowerShell. Certifique-se de iniciar o PowerShell como administrador.
$ wsl --installDepois de instalar o WSL com êxito, reinicie o sistema. Em seguida, digite o seguinte comando no PowerShell para verificar se o Docker está funcionando corretamente.
$ docker run hello-worldO Docker extraiu com sucesso a imagem hello-world e iniciou o contêiner.
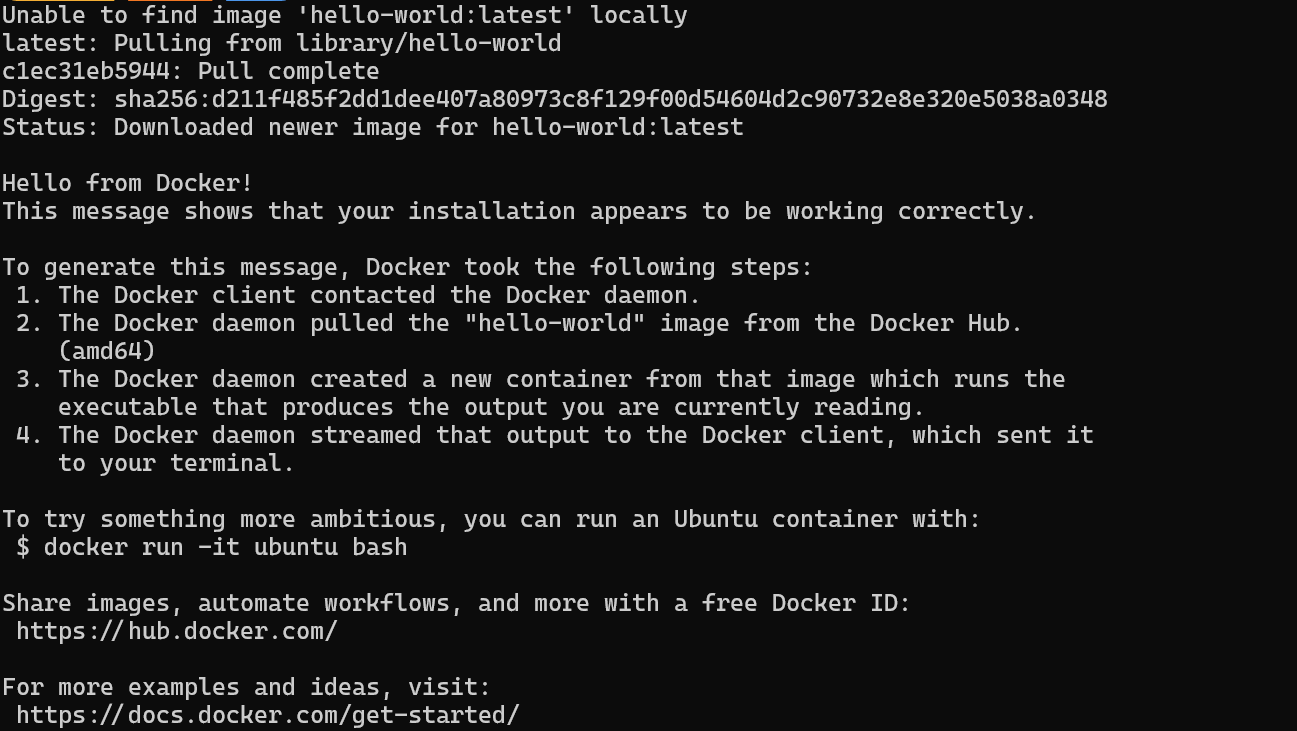
Neste guia, aprenderemos como usar o Docker Compose para configurar serviços de IA localmente. Essa abordagem permite que você carregue imagens do Docker e implemente contêineres em minutos, fornecendo uma maneira simples de executar e gerenciar vários serviços de IA na sua infraestrutura.
Primeiro, vamos clonar o n8n-io/self-hosted-ai-starter-kit digitando o seguinte comando no terminal.
$ git clone https://github.com/n8n-io/self-hosted-ai-starter-kit.git
$ cd self-hosted-ai-starter-kitO kit inicial é a maneira mais fácil de configurar os servidores e aplicativos necessários para criar um fluxo de trabalho de IA. Em seguida, carregaremos as imagens do Docker e executaremos os contêineres.
$ docker compose --profile cpu upSe você tiver uma GPU NVIDIA, tente digitar o comando abaixo para acessar a aceleração na geração de respostas. Além disso, configure a GPU NVIDIA para o Docker seguindo as instruções do Ollama Docker do Ollama.
$ docker compose --profile gpu-nvidia upIsso levará alguns minutos, pois você fará o download de todas as imagens do Docker e, em seguida, executará os contêineres do Docker um a um.
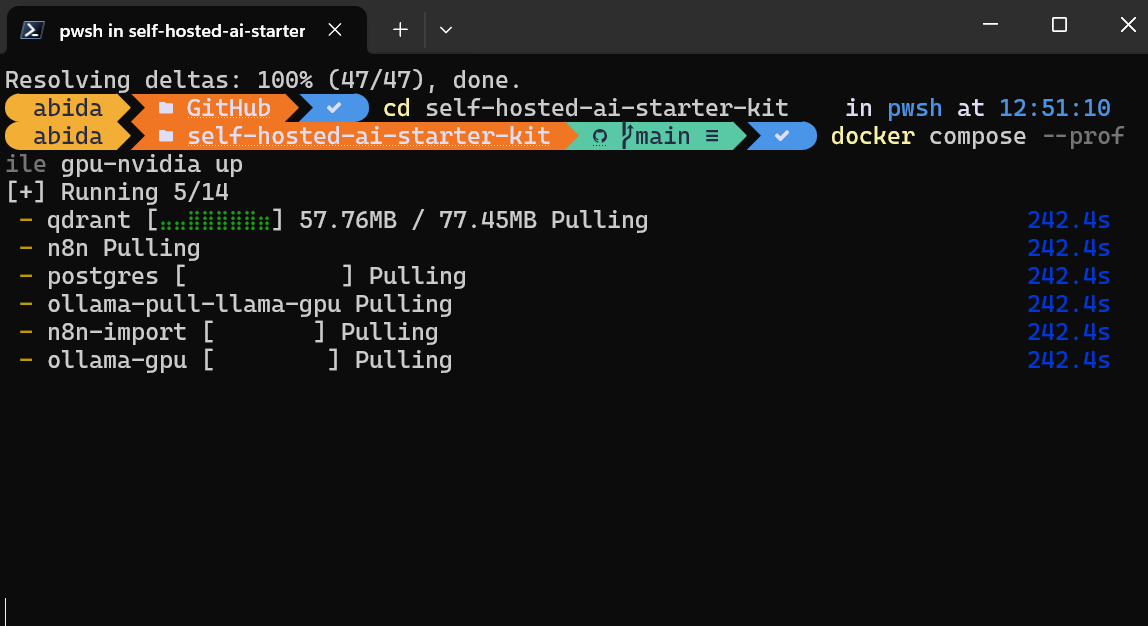
Todos os serviços do Docker estão em execução. Os contêineres do Docker que saíram foram usados para fazer o download do modelo Llama 3.2 e importar o fluxo de trabalho de backup do n8n.
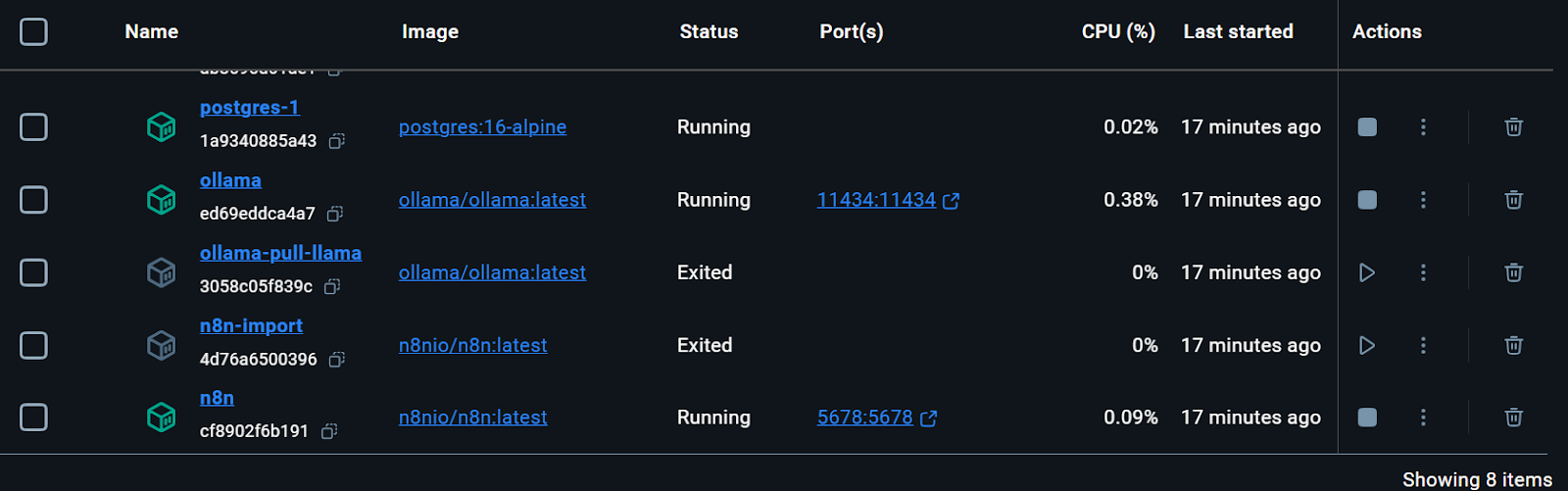
Você pode até mesmo verificar o status de execução do contêiner do docker digitando o seguinte comando no terminal.
$ docker compose psO kit inicial incluía o script para fazer download do modelo Llama 3.2. No entanto, para um aplicativo RAG Chatbot adequado, também precisamos do modelo de incorporação. Vamos acessar o contêiner do Ollama Docker, clicar na guia "Exec" e digitar o seguinte comando para fazer download do modelo "nomic-embed-text".
$ ollama pull nomic-embed-textComo podemos ver, podemos interagir com um contêiner do Docker como se ele fosse uma máquina virtual separada.
Abra o URL do painel da n8n http://localhost:5678/ em seu navegador para configurar uma conta de usuário da n8n com e-mail e senha. Em seguida, clique no botão home na página principal do painel e acesse o fluxo de trabalho de demonstração.
A demonstração é um fluxo de trabalho LLM simples que recebe a entrada do usuário e gera a resposta.
Para executar o fluxo de trabalho, clique no botão Chat e comece a digitar sua pergunta. Em alguns segundos, será gerada uma resposta.
Observe que estamos usando um modelo de linguagem pequeno com aceleração de GPU, portanto, a resposta normalmente leva apenas cerca de 2 segundos.
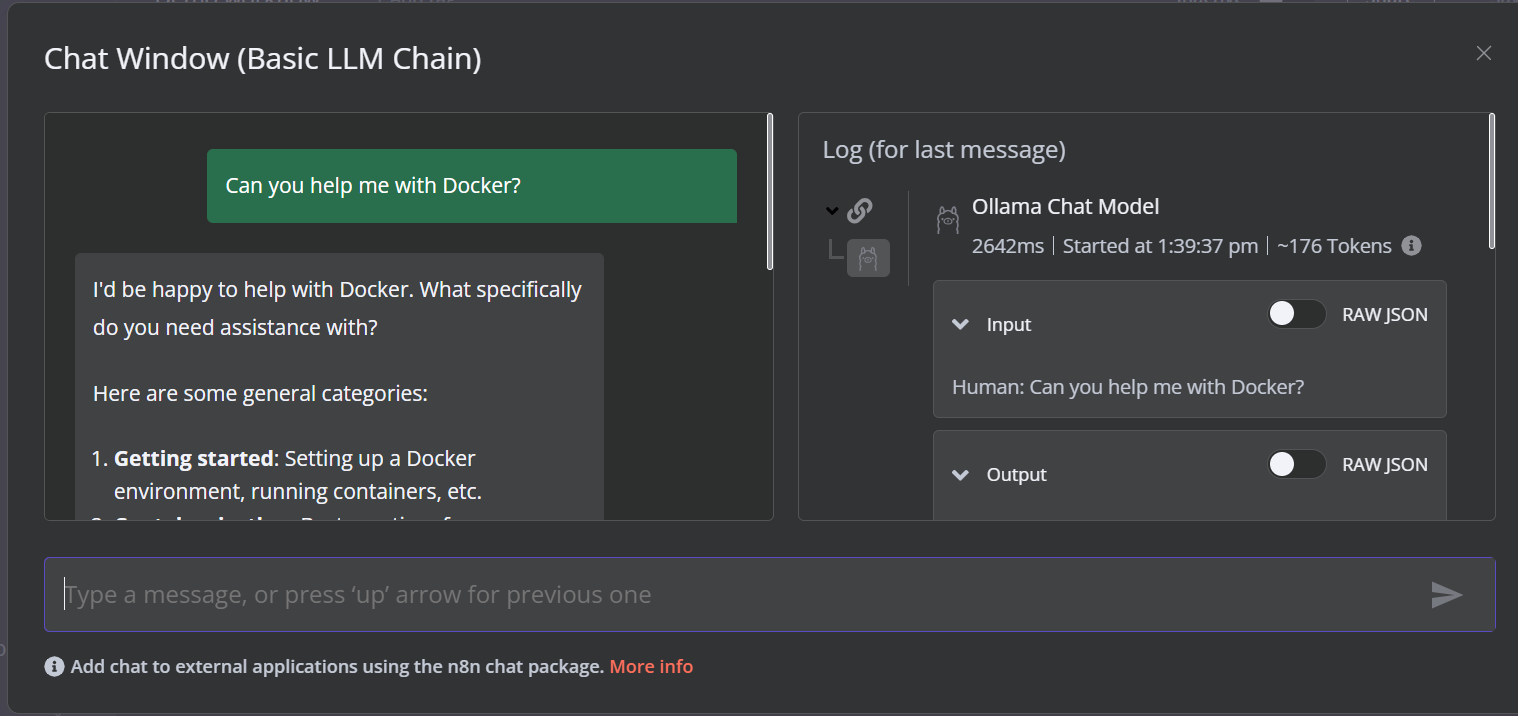
Neste projeto, criaremos um RAG (Retrieval-Augmented Generation) que usa dados dos filmes de Harry Potter para fornecer respostas precisas e contextualizadas. Esse projeto é uma solução sem código, o que significa que tudo o que você precisa fazer é procurar os componentes de fluxo de trabalho necessários e conectá-los para criar um fluxo de trabalho de IA.
A n8n é uma plataforma sem código semelhante à Langchain. Siga o RAG com Llama 3.1 8B, Ollama e Langchain para que você tenha uma visão geral de como criar um fluxo de trabalho de IA semelhante usando Langchain.
Clique no botão "Add the first step" (Adicionar a primeira etapa) no meio do painel, procure o "Chat Trigger" (Acionador de bate-papo) e adicione-o.
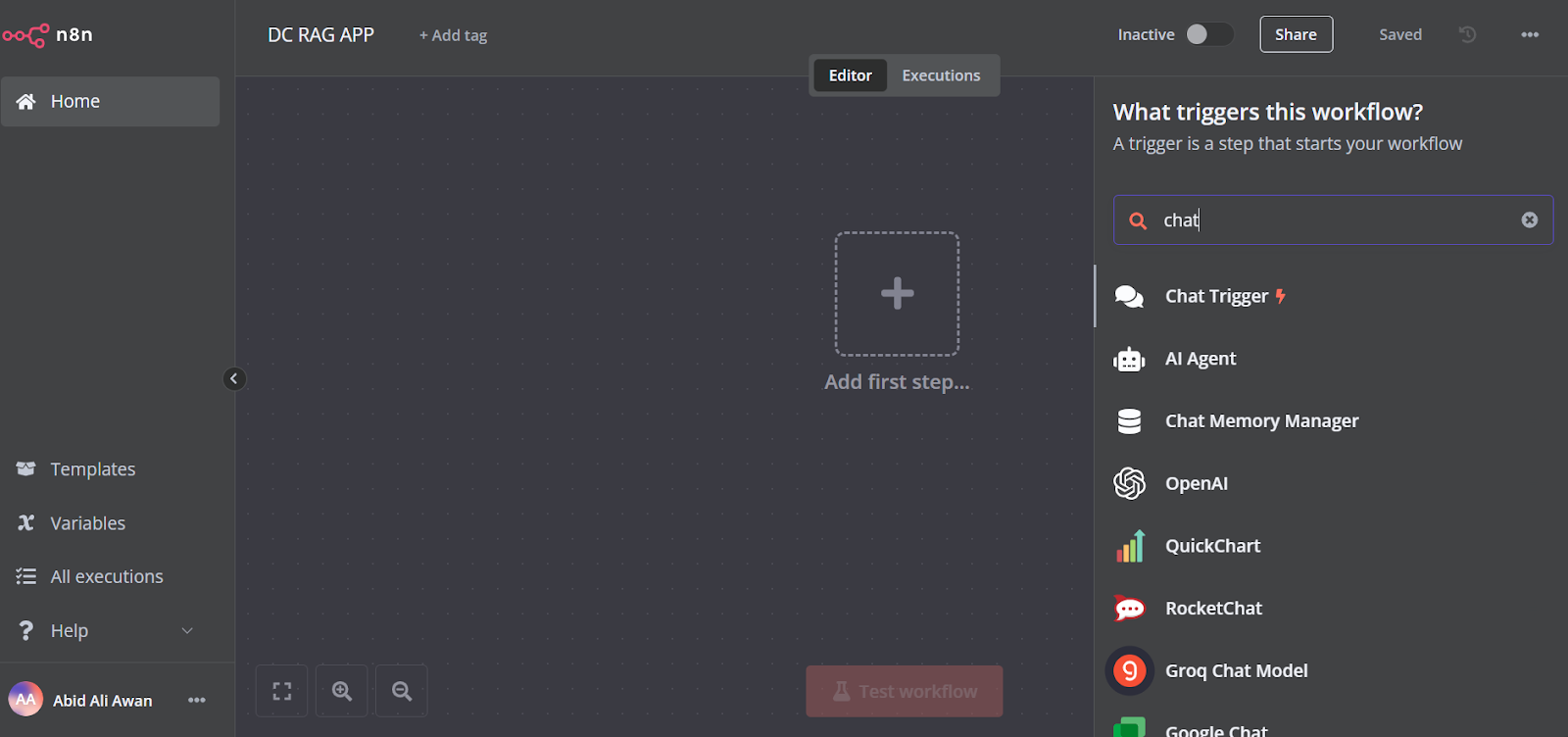
Certifique-se de que você ativou a opção "Allow File Uploads".
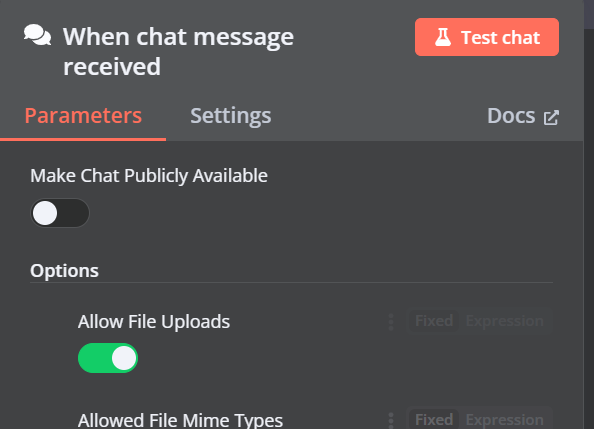
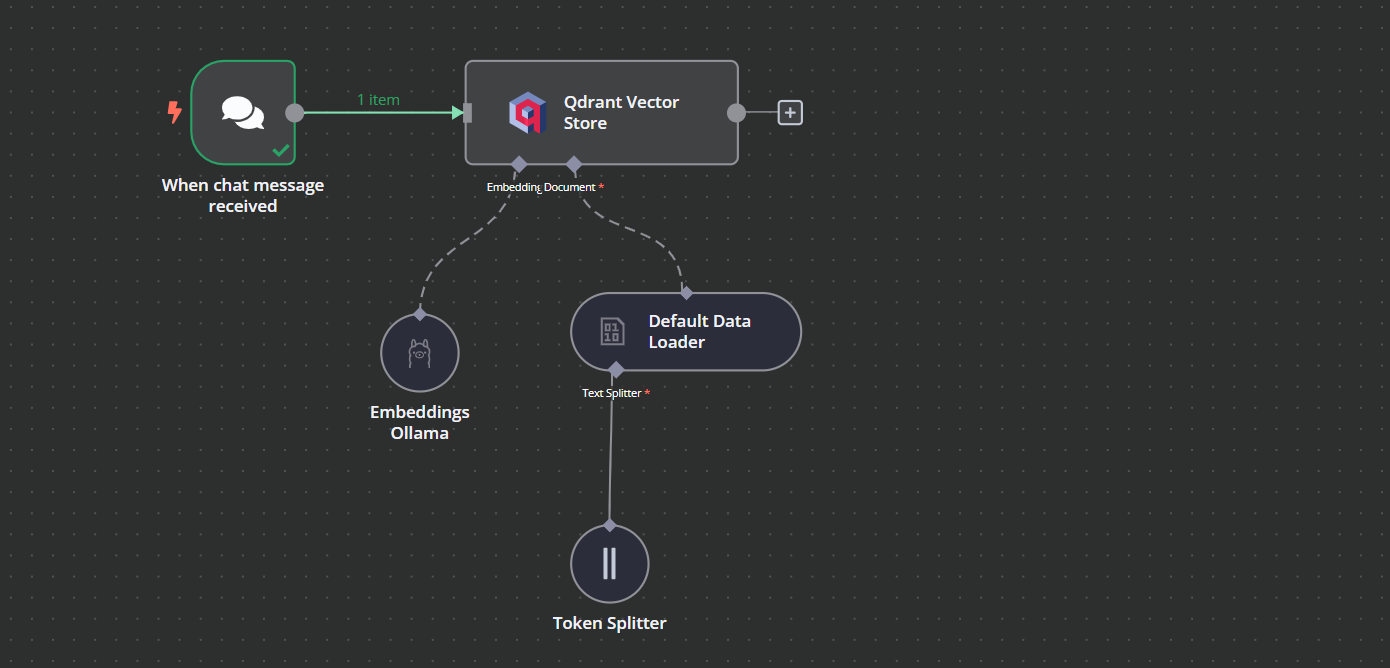
Você pode adicionar outro componente chamado "Qdrant Vector Store" clicando no botão de adição (+) no componente "Chat Trigger" e procurando por ele.
Altere o modo de operação para "Insert Documents" (Inserir documentos), altere a coleção Qdrant para "By ID" (Por ID) e digite o ID como "Harry_Potter".
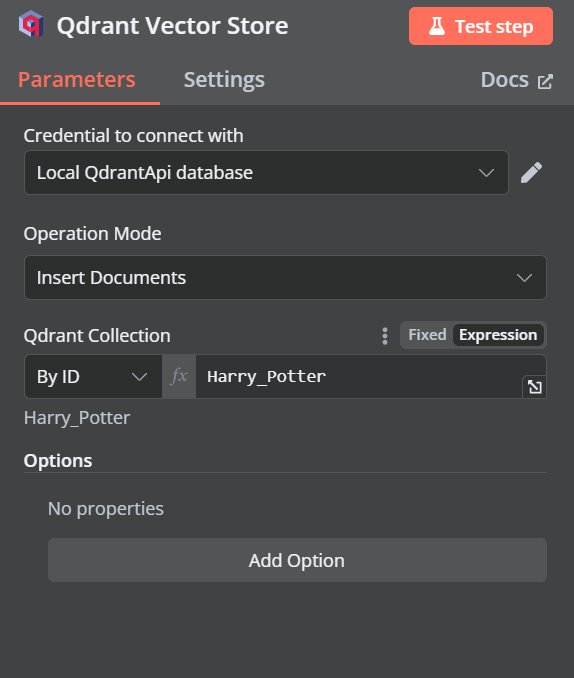
Quando sairmos da opção, veremos que o acionador do chat está conectado à nossa loja de vetores.
Clique no botão de adição abaixo do armazenamento de vetores Qdrant chamado "Embedding" (Incorporação). Seremos levados ao menu de gerenciamento de modelos, onde selecionaremos as incorporações Ollama e alteraremos o modelo para "nomic-embed-text:latest".
Clique no botão de adição abaixo do armazenamento de vetores do Qdrant que diz "Document" e selecione "Default Data Loader" (Carregador de dados padrão) no menu. Altere o tipo de dados para "Binário".
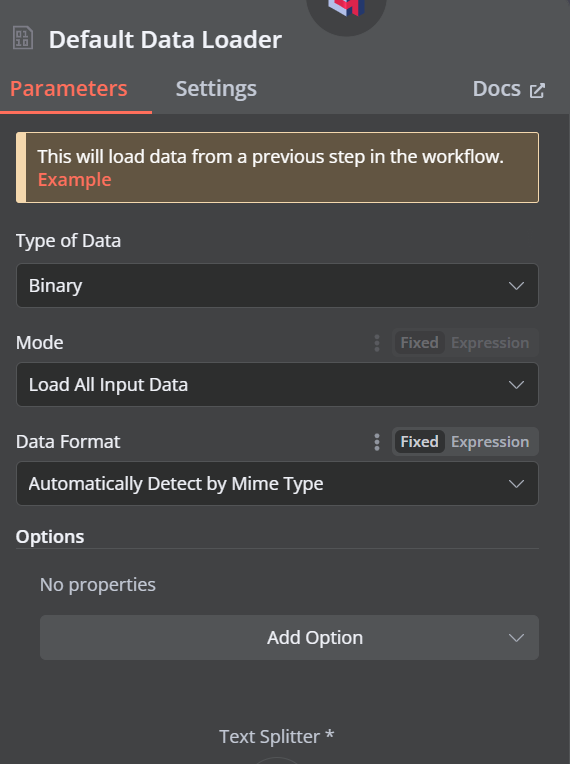
Em seguida, adicione um divisor de token com um tamanho de bloco de 500 e uma sobreposição de bloco de 50 será adicionada ao carregador de documentos.
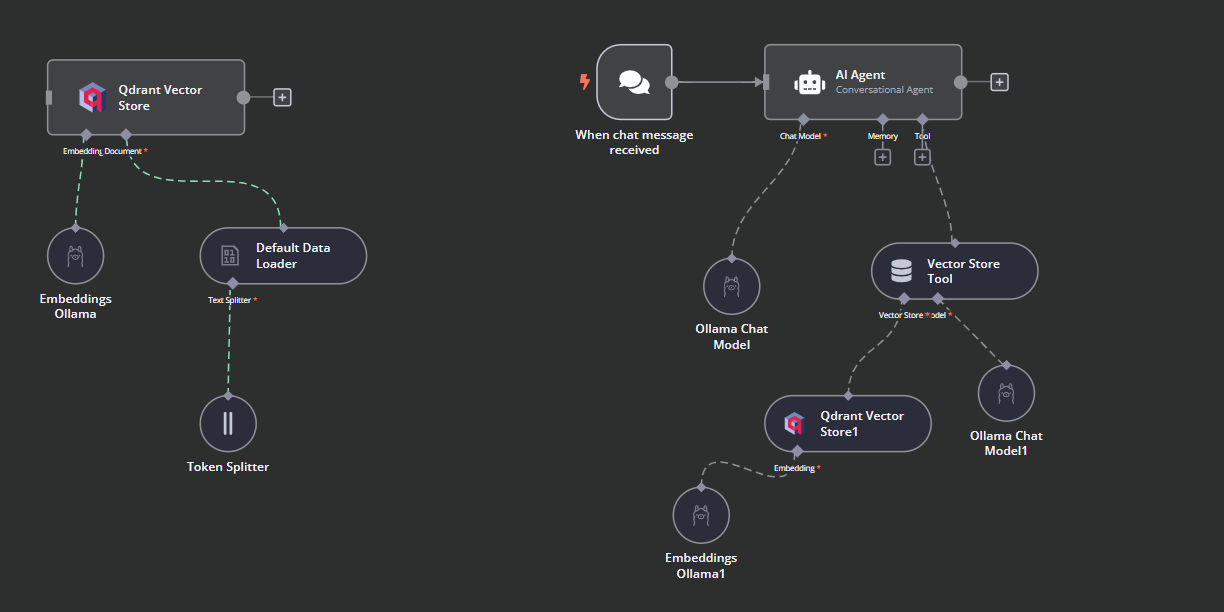
É assim que nosso fluxo de trabalho deve ficar no final. Esse fluxo de trabalho pegará os arquivos CSV do usuário, os converterá em texto e, em seguida, transformará o texto em embeddings e os armazenará no armazenamento de vetores.
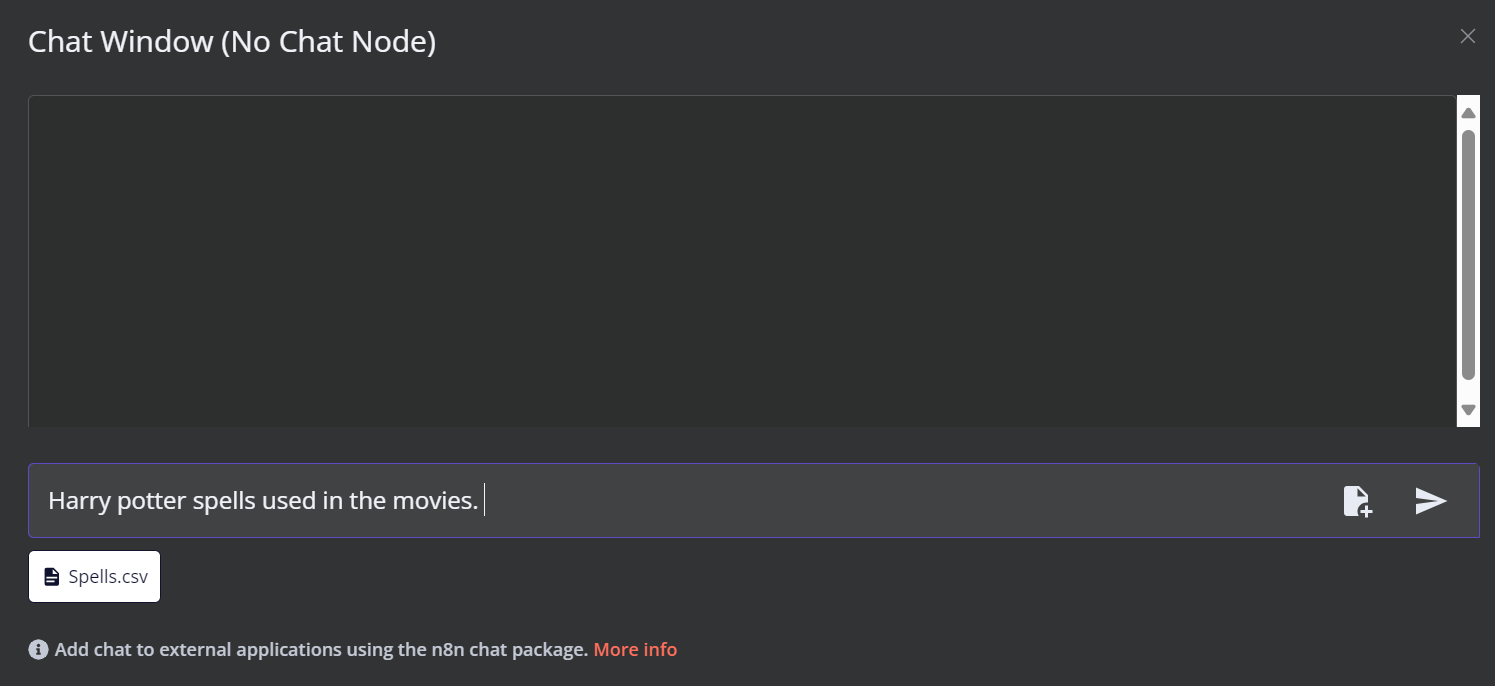
Clique no botão Chat na parte inferior do painel. Quando a janela de bate-papo for aberta, clique no botão de arquivo, conforme mostrado abaixo.
Neste fluxo de trabalho, carregaremos todos os arquivos CSV da pasta Filmes do Harry Potter do conjunto de dados Harry Potter Movies. No entanto, para testar nosso fluxo de trabalho, carregaremos apenas um único arquivo CSV chamado "spell" com base em uma consulta do usuário.
Você pode acessar o servidor Qdrant usando o URL http://localhost:6333/dashboard e verificar se o arquivo foi carregado no armazenamento de vetores ou anotado.
Agora, adicione o restante dos arquivos ao armazenamento de vetores.
Conectaremos o acionador de bate-papo ao armazenamento de vetores, o vincularemos ao agente de IA e alteraremos o tipo de agente para "Agente de conversação".
Clique no botão "Chat Model" (Modelo de bate-papo) em AI agent (Agente de IA) e selecione o modelo Ollama Chat no menu. Depois disso, entoe o nome do modelo como "Llama3.2:latest".
Clique no botão "Tool" (Ferramenta) abaixo do agente de IA e selecione a ferramenta de armazenamento de vetores no menu. Forneça o nome da ferramenta e a descrição.
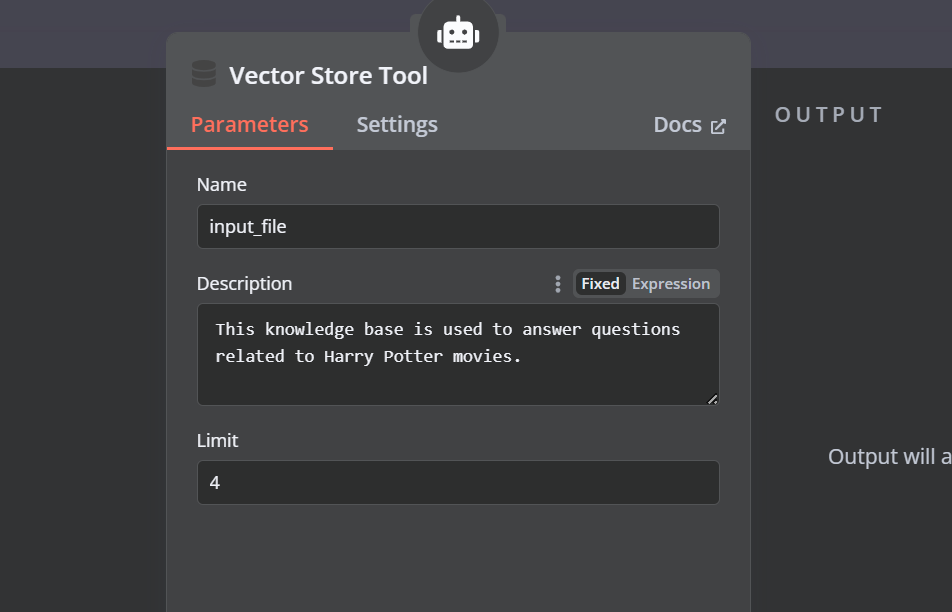
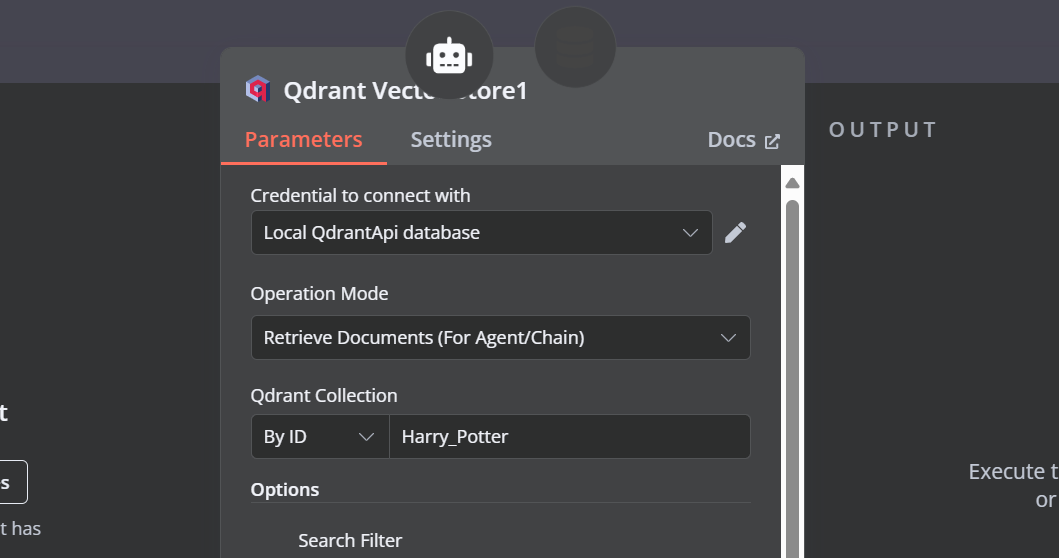
Precisamos adicionar componentes à ferramenta de armazenamento de vetores. Primeiro, incorporaremos o Qdrant como o armazenamento de vetores e definiremos o ID da coleção como "Harry_Potter". Esse armazenamento de vetores acessará a coleção Harry Potter durante a pesquisa de similaridade. Além disso, altere o modo de operação para "Retrieved Documents" (Documentos recuperados).
A ferramenta de armazenamento de vetores também requer um modelo LLM. Vamos conectar o modelo de bate-papo do Ollama e alterar o modelo para "llama3.2:latest".
Na etapa final, forneceremos o armazenamento do vetor de recuperação com o modelo de incorporação. Isso permite que ele converta a consulta do usuário em uma incorporação e, em seguida, converta a incorporação novamente em texto para o LLM processar.
Certifique-se de que você forneça o modelo de incorporação correto para seu armazenamento de vetores.
É assim que deve ser o fluxo de trabalho de IA.
Clique no botão de bate-papo para começar a fazer perguntas sobre o universo de Harry Potter.
Sugestão: "Qual é o lugar mais secreto de Hogwarts?"
Sugestão: "Qual é o feitiço mais poderoso?"
Nosso fluxo de trabalho de IA é rápido e funciona sem problemas. Essa abordagem sem código é muito fácil de executar. O n8n também permite que os usuários compartilhem seus aplicativos para que qualquer pessoa possa acessá-los usando um link, assim como um ChatGPT.
O n8n é uma ferramenta perfeita para projetos de LLM/AI, especialmente para pessoas não técnicas. Às vezes, nem precisamos criar o fluxo de trabalho do zero. Tudo o que precisamos fazer é pesquisar projetos semelhantes no site da site da n8ncopiar o código JSON e colá-lo em nosso painel da n8n. É simples assim.

Fonte: Descubra mais de 900 fluxos de trabalho de automação da comunidade n8n
Neste tutorial, aprendemos sobre IA local e como usar o kit inicial de IA auto-hospedado para criar e implantar vários serviços de IA. Em seguida, lançamos o painel n8n e criamos nosso próprio fluxo de trabalho de IA usando Qdrant, modelos de incorporação, ferramentas de armazenamento de vetores, LLMs e carregadores de documentos. Criar e executar fluxos de trabalho é muito fácil com a n8n. Se você não conhece as ferramentas de IA e deseja saber mais sobre soluções de IA sem código, confira nossos outros recursos:
Principais cursos de IA
Programa
Programa
Curso
blog
Natasha Al-Khatib
14 min
blog
Armstrong Asenavi
15 min
blog
DataCamp Team
4 min
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial

