
Cursus
Principes fondamentaux de l'IA
10 h
Les entreprises du monde entier sont de plus en plus soucieuses de protéger les informations sensibles tout en exploitant la puissance de l'IA. Ce guide présente une solution complète pour créer des applications d'IA locales et sécurisées à l'aide d'une puissante combinaison d'outils open-source.
Nous utiliserons le Kit de démarrage de l'IA auto-hébergée pour mettre rapidement en place un environnement d'IA local. Ce kit exécutera automatiquement Ollama, Qdrant, n8n et Postgres. En outre, nous apprendrons à construire un flux de travail d'IA pour un chatbot RAG (Retrieval-augmented generation) en utilisant l'ensemble de données Harry Potter à travers le tableau de bord n8n.
Que vous soyez un développeur, un data scientist ou un professionnel non technique cherchant à mettre en œuvre des solutions d'IA sécurisées, ce tutoriel vous fournira les bases pour créer des flux de travail d'IA puissants et auto-hébergés tout en conservant un contrôle total sur vos données sensibles.
L'IA locale vous permet d'exécuter des systèmes d'intelligence artificielle et des flux de travail sur votre propre infrastructure plutôt que sur des services cloud, ce qui offre une confidentialité et une rentabilité accrues.
Si vous êtes nouveau dans l'écosystème de l'IA, vous devriez d'abord consulter notre cursus de compétences sur les sujets suivants. Principes fondamentaux de l'IA pour vous mettre à niveau. En suivant cette série de cours, vous acquerrez des connaissances exploitables sur des sujets d'IA populaires tels que le ChatGPT, les grands modèles de langage, l'IA générative, et plus encore.
Image par l'auteur
Voici la liste des outils que nous utiliserons pour créer et exécuter nos applications locales d'IA :
Le n8n est notre cadre principal pour construire le flux de travail de l'IA pour le Chatbot RAG. Nous utiliserons Qdrant comme magasin de vecteurs et Ollama comme fournisseur de modèles d'IA. Ensemble, ces éléments nous aideront à créer le système RAG.
Nous allons télécharger et installer le logiciel Docker en allant sur le site officiel de Docker. Il est assez facile à installer et à mettre en route.
Pour en savoir plus sur Docker, suivez le lien suivant Docker pour la science des données ou suivez notre cours cours d'introduction à Docker.
Source : Docker : Développement accéléré d'applications en conteneur
Les utilisateurs de Windows ont besoin d'un outil supplémentaire pour exécuter avec succès les conteneurs Docker : le Windows Subsystem for Linux (WSL). Cela permet aux développeurs d'installer une distribution Linux et d'utiliser des applications Linux directement sous Windows.
Pour installer WSL sur Windows, tapez la commande suivante dans le terminal ou dans PowerShell. Veillez à lancer PowerShell en tant qu'administrateur.
$ wsl --installUne fois l'installation du WSL terminée, redémarrez votre système. Ensuite, tapez la commande suivante dans PowerShell pour vérifier si Docker fonctionne correctement.
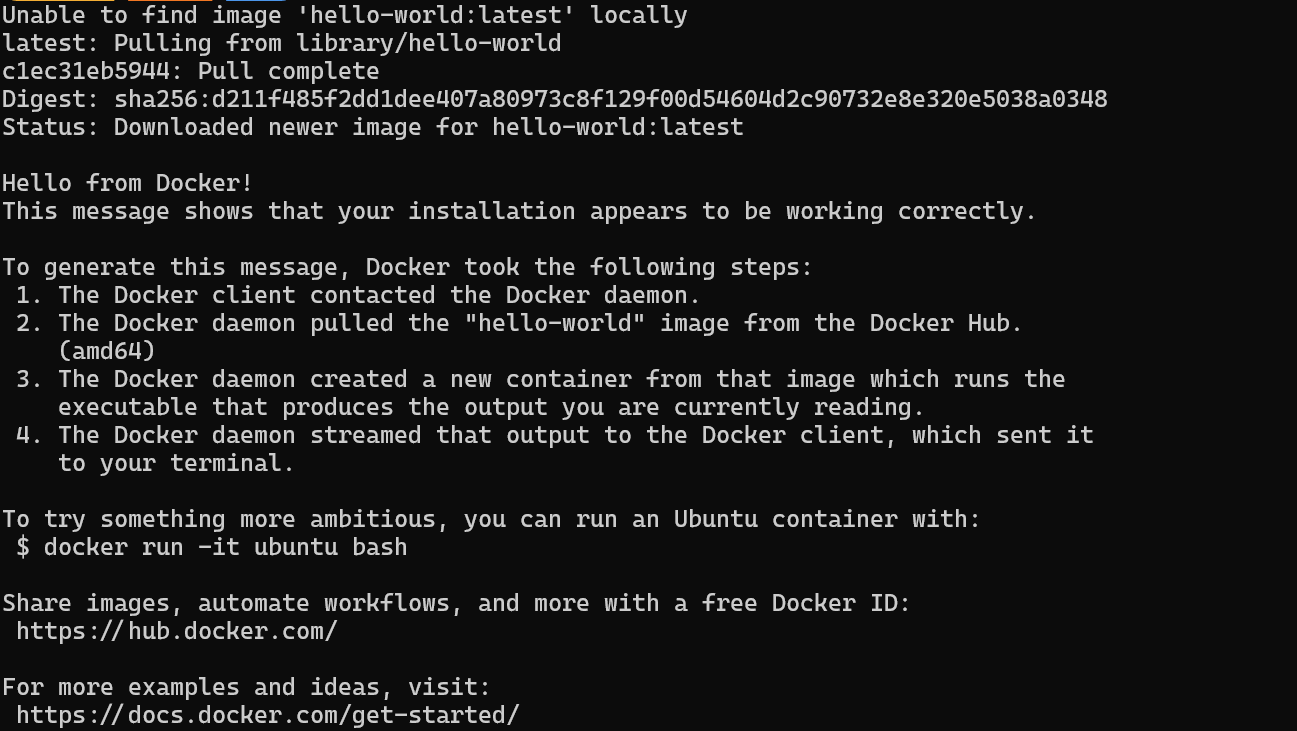
$ docker run hello-worldDocker a réussi à extraire l'image hello-world et a démarré le conteneur.
Dans ce guide, nous allons apprendre à utiliser Docker Compose pour mettre en place des services d'IA localement. Cette approche vous permet de charger des images Docker et de déployer des conteneurs en quelques minutes, ce qui constitue un moyen simple d'exécuter et de gérer plusieurs services d'IA sur votre infrastructure.
Tout d'abord, nous allons cloner n8n-io/self-hosted-ai-starter-kit en tapant la commande suivante dans le terminal.
$ git clone https://github.com/n8n-io/self-hosted-ai-starter-kit.git
$ cd self-hosted-ai-starter-kitLe kit de démarrage est le moyen le plus simple de mettre en place les serveurs et les applications nécessaires à l'élaboration d'un flux de travail d'IA. Ensuite, nous chargerons les images Docker et exécuterons les conteneurs.
$ docker compose --profile cpu upSi vous disposez d'un GPU NVIDIA, essayez de taper la commande ci-dessous pour accéder à l'accélération dans la génération de réponses. Configurez également le GPU NVIDIA pour Docker en suivant la procédure suivante Ollama Docker d'Ollama.
$ docker compose --profile gpu-nvidia upCela prendra quelques minutes, le temps de télécharger toutes les images Docker et d'exécuter les conteneurs Docker un par un.
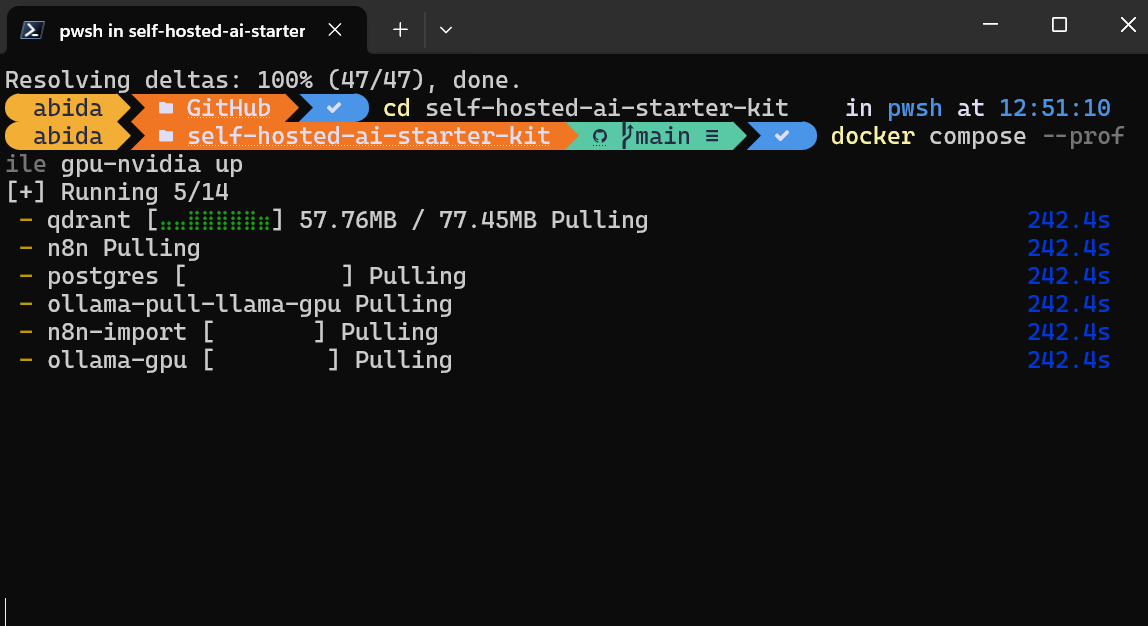
Tous les services Docker sont en cours d'exécution. Les conteneurs Docker quittés ont été utilisés pour télécharger le modèle Llama 3.2 et importer le flux de travail de sauvegarde n8n.
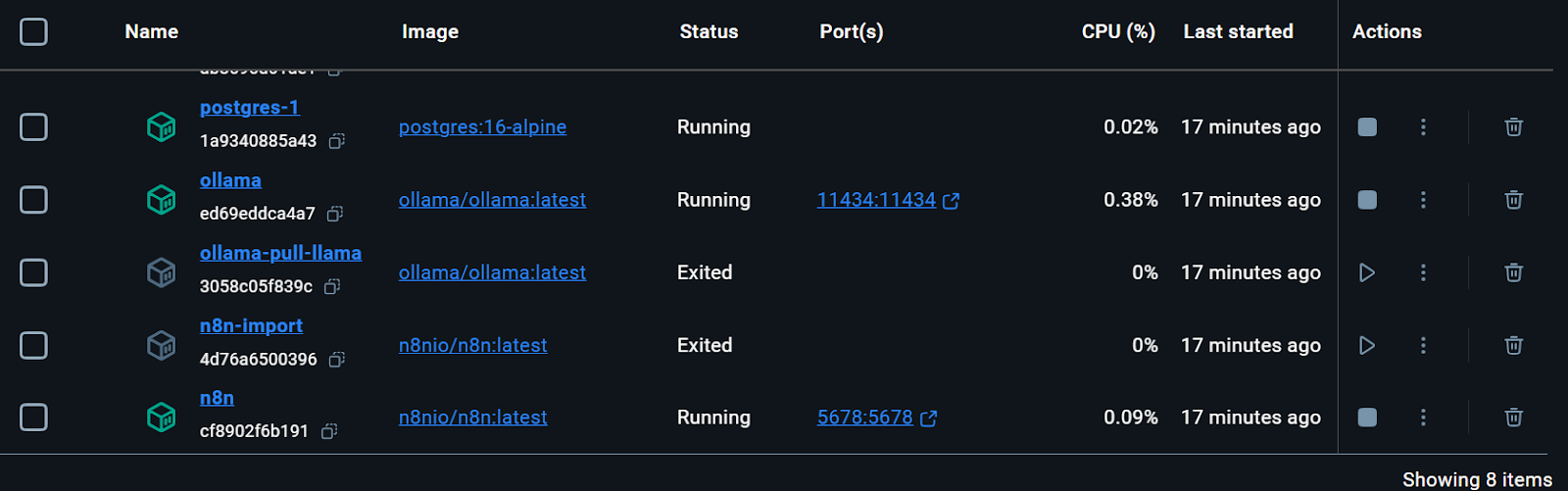
Nous pouvons même vérifier l'état d'exécution du conteneur Docker en tapant la commande suivante dans le terminal.
$ docker compose psLe kit de démarrage comprenait le script permettant de télécharger le modèle Llama 3.2. Cependant, pour une application RAG Chatbot appropriée, nous avons également besoin du modèle d'intégration. Nous allons nous rendre dans le conteneur Docker d'Ollama, cliquer sur l'onglet "Exec", et taper la commande suivante pour télécharger le modèle "nomic-embed-text".
$ ollama pull nomic-embed-textComme nous le voyons, nous pouvons interagir avec un conteneur Docker comme s'il s'agissait d'une machine virtuelle distincte.
Ouvrez l'URL du tableau de bord n8n http://localhost:5678/ dans votre navigateur pour créer un compte utilisateur n8n avec un e-mail et un mot de passe. Ensuite, cliquez sur le bouton d'accueil de la page principale du tableau de bord et accédez au flux de travail de démonstration.
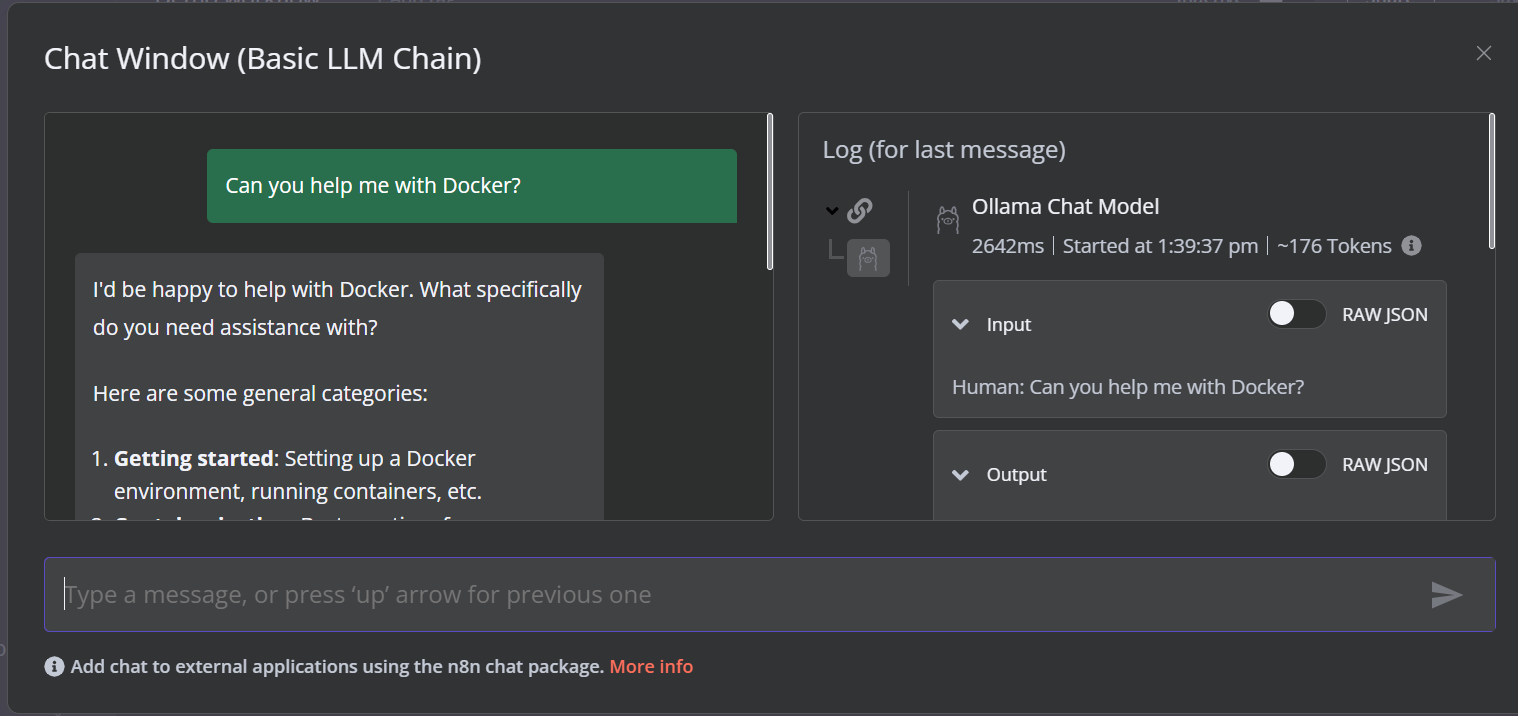
La démo est un simple flux de travail LLM qui prend l'entrée de l'utilisateur et génère la réponse.
Pour lancer le flux de travail, cliquez sur le bouton "Chat" et commencez à taper votre question. Dans les secondes qui suivent, une réponse est générée.
Veuillez noter que nous utilisons un petit modèle linguistique avec accélération GPU, de sorte que la réponse ne prend généralement que 2 secondes.
Dans ce projet, nous construirons un RAG (Retrieval-Augmented Generation) qui utilise les données des films Harry Potter pour fournir des réponses précises et adaptées au contexte. Ce projet est une solution sans code, ce qui signifie que tout ce que vous avez à faire est de rechercher les composants de flux de travail nécessaires et de les connecter pour créer un flux de travail d'IA.
n8n est une plateforme sans code similaire à Langchain. Suivez le RAG avec Llama 3.1 8B, Ollama et Langchain pour avoir une vue d'ensemble de la façon de créer un flux de travail d'IA similaire en utilisant Langchain.
Cliquez sur le bouton "Ajouter la première étape" au milieu du tableau de bord, recherchez le "déclencheur de chat" et ajoutez-le.
Assurez-vous d'avoir activé l'option "Autoriser les téléchargements de fichiers".
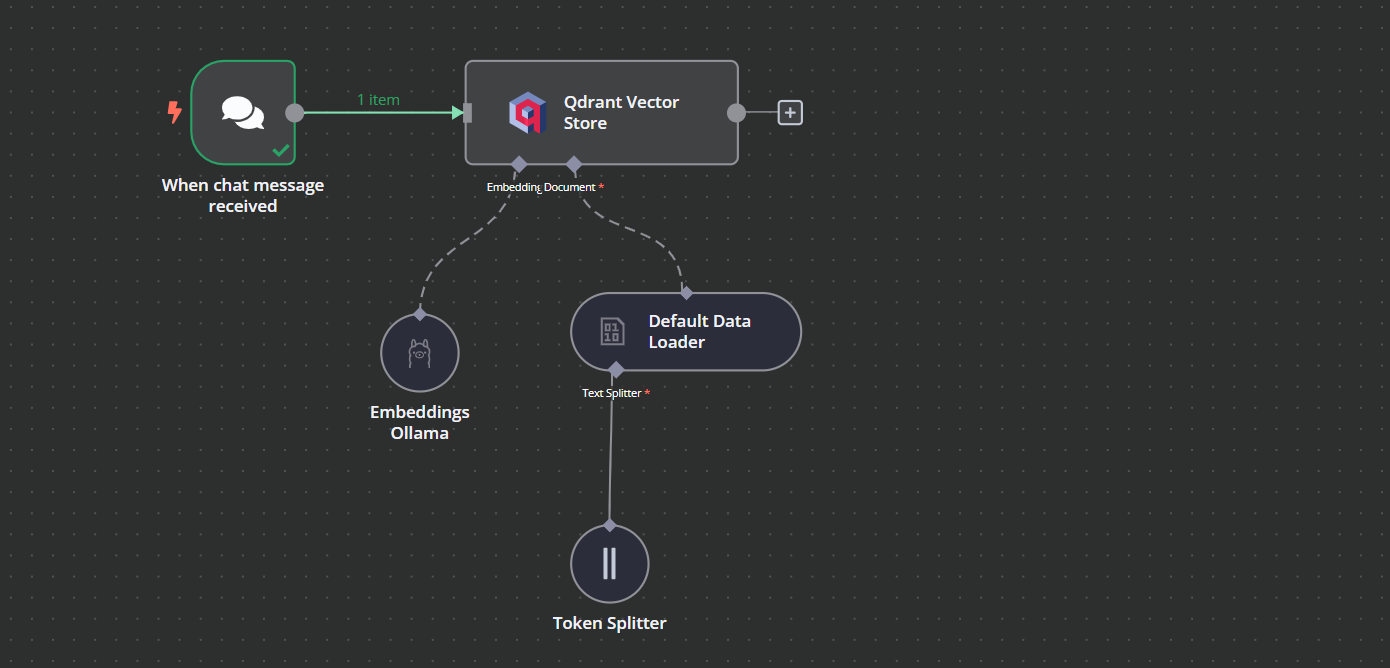
Vous pouvez ajouter un autre composant appelé "Qdrant Vector Store" en cliquant sur le bouton plus (+) du composant "Chat Trigger" et en le recherchant.
Changez le mode d'opération en "Insérer des documents", changez la collection Qdrant en "Par ID" et tapez l'ID comme "Harry_Potter".
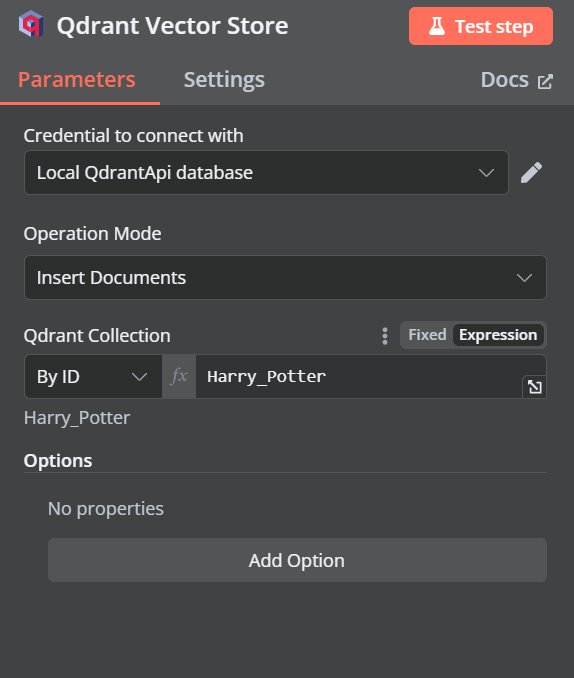
Lorsque nous quittons l'option, nous constatons que le déclencheur de chat est connecté à notre boutique vectorielle.
Cliquez sur le bouton plus situé sous le magasin de vecteurs Qdrant et intitulé "Embedding". Nous serons amenés au menu de gestion du modèle, où nous sélectionnerons les embeddings Ollama et changerons le modèle en "nomic-embed-text:latest".
Cliquez sur le bouton plus situé sous le magasin de vecteurs Qdrant, qui indique "Document", et sélectionnez "Default Data Loader" dans le menu. Changez le type de données en "Binaire".
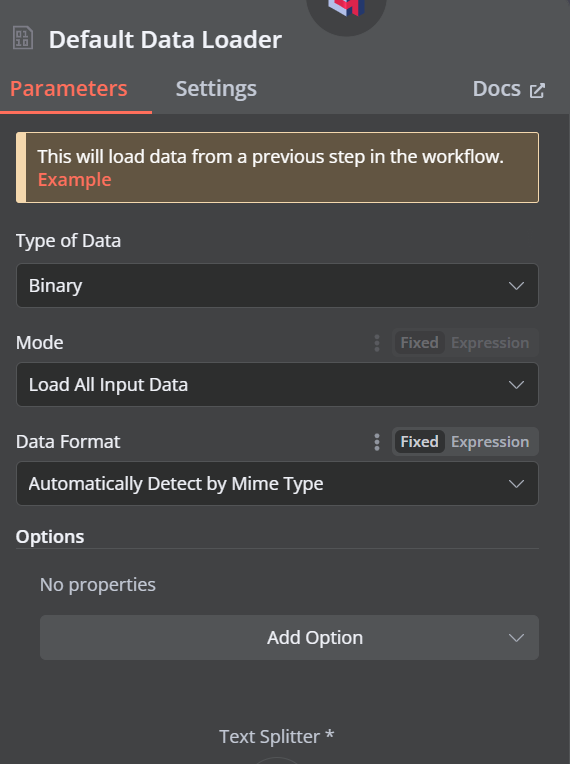
Ensuite, ajoutez un séparateur de jetons avec une taille de bloc de 500 et un chevauchement de bloc de 50 sera ajouté au chargeur de documents.
Voici à quoi devrait ressembler notre flux de travail à la fin. Ce flux de travail prend les fichiers CSV de l'utilisateur, les convertit en texte, puis transforme le texte en enchâssements et les stocke dans le magasin vectoriel.
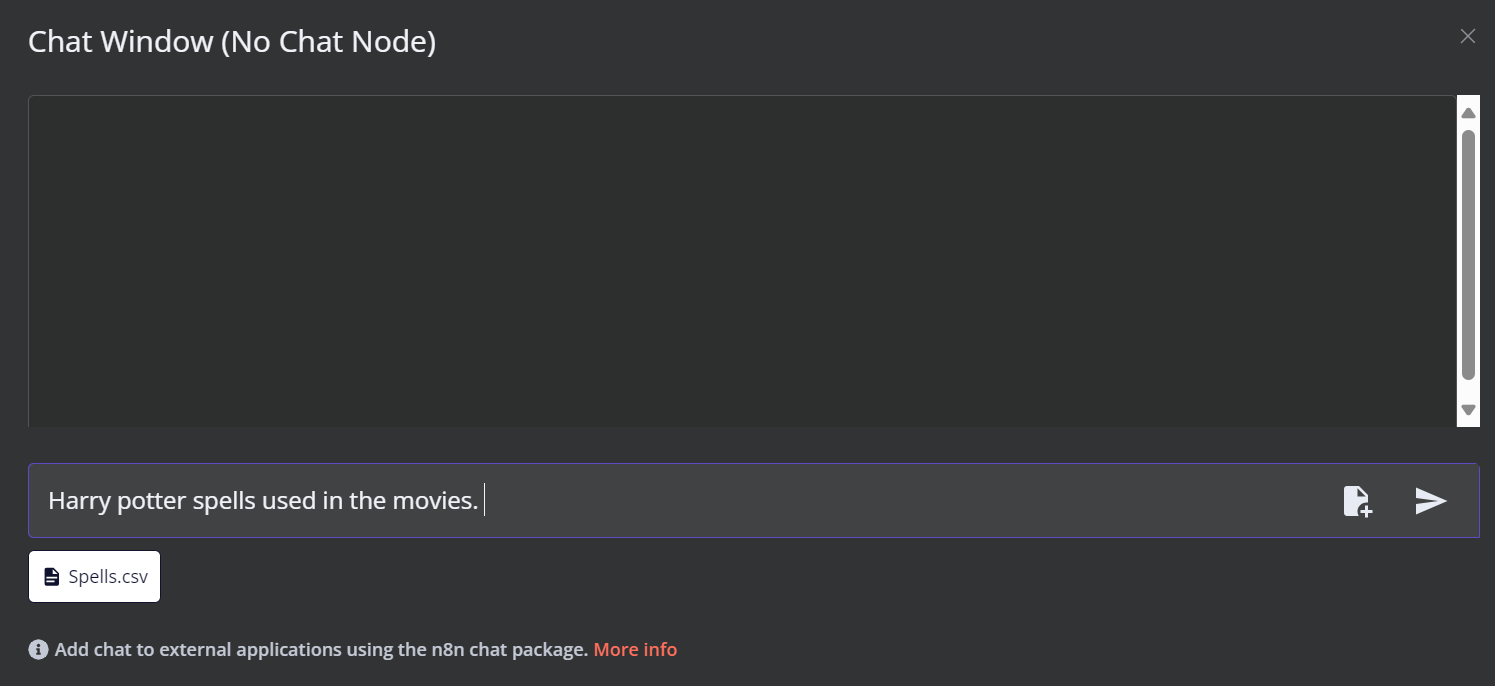
Cliquez sur le bouton Chat en bas du tableau de bord. Lorsque la fenêtre de chat s'ouvre, cliquez sur le bouton "fichier" comme indiqué ci-dessous.
Dans ce flux de travail, nous chargerons tous les fichiers CSV de la base de données Films Harry Potter de l'ensemble de données. Toutefois, pour tester notre flux de travail, nous ne chargerons qu'un seul fichier CSV appelé "orthographe" en fonction d'une requête de l'utilisateur.
Vous pouvez accéder au serveur Qdrant en utilisant l'URL suivante http://localhost:6333/dashboard et vérifier si le fichier a été chargé dans le magasin de vecteurs ou dans la note.
Ajoutez maintenant le reste des fichiers au magasin vectoriel.
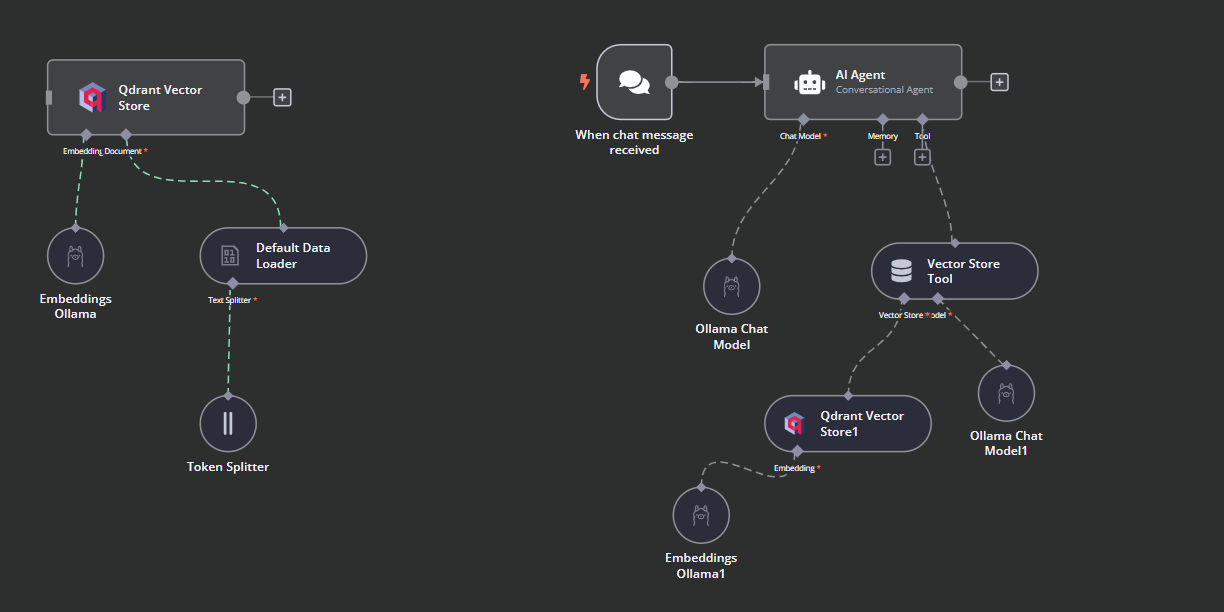
Nous allons connecter le déclencheur de chat au magasin de vecteurs, le relier à l'agent d'intelligence artificielle et changer le type d'agent en "agent de conversation".
Cliquez sur le bouton "Chat Model" sous AI agent et sélectionnez le modèle Ollama Chat dans le menu. Ensuite, scandez le nom du modèle à "Llama3.2:latest".
Cliquez sur le bouton "Outil" sous l'agent AI et sélectionnez l'outil magasin vectoriel dans le menu. Indiquez le nom de l'outil et sa description.
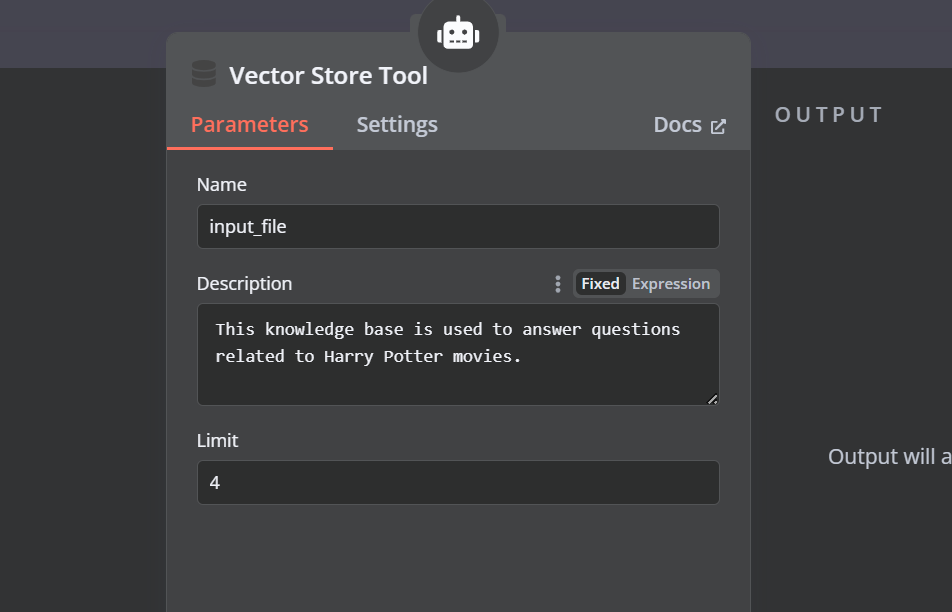
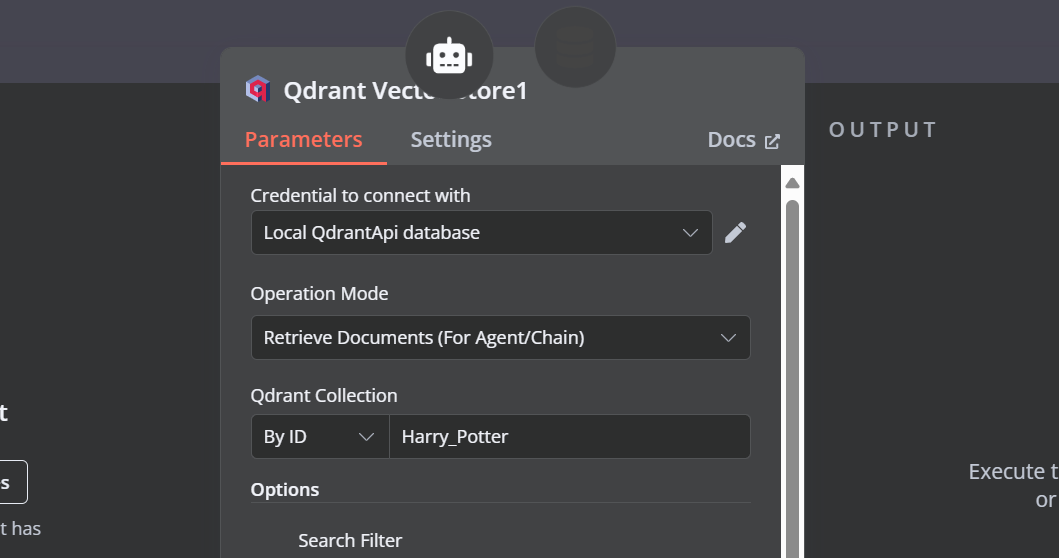
Nous devons ajouter des composants à l'outil de stockage vectoriel. Tout d'abord, nous allons incorporer Qdrant comme magasin de vecteurs et définir l'identifiant de la collection à "Harry_Potter". Ce magasin vectoriel accèdera à la collection Harry Potter lors de la recherche de similarités. De plus, changez le mode d'opération en "Documents récupérés".
L'outil de stockage de vecteurs nécessite également un modèle LLM. Nous allons connecter le modèle de chat Ollama et changer le modèle en "llama3.2:latest".
Dans la dernière étape, nous alimenterons le magasin de vecteurs de recherche avec le modèle d'intégration. Cela lui permet de convertir la requête de l'utilisateur en une image intégrée, puis de reconvertir l'image intégrée en texte pour que le LLM puisse la traiter.
Assurez-vous de fournir le modèle d'intégration correct pour votre magasin de vecteurs.
Voici à quoi devrait ressembler le flux de travail de l'IA.
Cliquez sur le bouton "chat" pour commencer à poser des questions sur l'univers de Harry Potter.
Prompt : "Quel est l'endroit le plus secret de Poudlard ?"
Prompt : "Quel est le sort le plus puissant ?"
Notre flux de travail en matière d'IA est rapide et fonctionne sans heurts. Cette approche sans code est assez facile à exécuter. n8n permet également aux utilisateurs de partager leurs applications afin que n'importe qui puisse y accéder à l'aide d'un lien, tout comme un ChatGPT.
n8n est un outil parfait pour les projets LLM/AI, en particulier pour les personnes non techniques. Parfois, il n'est même pas nécessaire de créer le flux de travail à partir de zéro. Il suffit de rechercher des projets similaires sur le site web de site web n8ncopier le code JSON et le coller dans notre tableau de bord n8n. C'est aussi simple que cela.

Source : Découvrez plus de 900 flux d'automatisation de la communauté n8n's
Dans ce tutoriel, nous avons appris ce qu'est l'IA locale et comment utiliser le kit de démarrage de l'IA auto-hébergée pour créer et déployer divers services d'IA. Nous avons ensuite lancé le tableau de bord n8n et créé notre propre flux de travail d'IA en utilisant Qdrant, des modèles d'intégration, des outils de stockage de vecteurs, des LLM et des chargeurs de documents. La création et l'exécution de flux de travail sont très faciles avec n8n. Si vous êtes novice en matière d'outils d'IA et que vous souhaitez en savoir plus sur les solutions d'IA sans code, consultez nos autres ressources :
Principaux cours sur l'IA
Cursus
Cursus
Cours