
Lernpfad
Grundlagen der KI
10 Std.
Unternehmen auf der ganzen Welt machen sich zunehmend Gedanken über den Schutz sensibler Daten, während sie die Möglichkeiten der KI nutzen. Dieser Leitfaden stellt eine umfassende Lösung für den Aufbau sicherer, lokaler KI-Anwendungen mit einer leistungsstarken Kombination von Open-Source-Tools vor.
Wir verwenden das Selbstgehostetes AI Starter Kit um schnell eine lokale KI-Umgebung einzurichten. Mit diesem Kit werden automatisch Ollama, Qdrant, n8n und Postgres ausgeführt. Außerdem werden wir lernen, wie man einen KI-Workflow für einen RAG-Chatbot (Retrieval-augmented Generation) mit Hilfe des Harry Potter-Datensatzes über das n8n-Dashboard erstellt.
Egal, ob du ein Entwickler, ein Datenwissenschaftler oder eine nichttechnische Fachkraft bist, die sichere KI-Lösungen implementieren möchte, dieses Tutorial vermittelt dir die Grundlagen, um leistungsstarke, selbst gehostete KI-Workflows zu erstellen und dabei die vollständige Kontrolle über deine sensiblen Daten zu behalten.
Lokale KI ermöglicht es dir, Systeme und Workflows der künstlichen Intelligenz auf deiner eigenen Infrastruktur statt auf Cloud-Diensten laufen zu lassen, was den Datenschutz und die Kosteneffizienz erhöht.
Wenn du neu im KI-Ökosystem bist, solltest du dir zuerst unseren Skill Track über KI-Grundlagen um auf den neuesten Stand zu kommen. Mit dem Abschluss dieser Kursreihe erwirbst du umsetzbares Wissen über beliebte KI-Themen wie ChatGPT, große Sprachmodelle, generative KI und mehr.
Bild vom Autor
Hier ist die Liste der Tools, die wir verwenden werden, um unsere lokalen KI-Anwendungen zu erstellen und auszuführen:
Das n8n ist unser wichtigstes Framework für den Aufbau des KI-Workflows für den RAG Chatbot. Wir werden Qdrant als Vektorspeicher und Ollama als KI-Modellanbieter verwenden. Zusammen helfen uns diese Komponenten, das RAG-System zu schaffen.
Wir laden und installieren die Docker Desktop-Anwendung herunter und installieren sie auf der offiziellen Docker-Website. Es ist ganz einfach zu installieren und loszulegen.
Erfahre mehr über Docker, indem du die Docker für Datenwissenschaft Tutorials oder in unserem Kurs Einführung in Docker.
Quelle: Docker: Beschleunigte Entwicklung von Containeranwendungen
Windows-Nutzer brauchen ein zusätzliches Tool, um Docker-Container erfolgreich auszuführen: das Windows Subsystem für Linux (WSL). Dies ermöglicht es Entwicklern, eine Linux-Distribution zu installieren und Linux-Anwendungen direkt unter Windows zu nutzen.
Um die WSL unter Windows zu installieren, gibst du den folgenden Befehl im Terminal oder in der PowerShell ein. Achte darauf, dass du die PowerShell als Administrator startest.
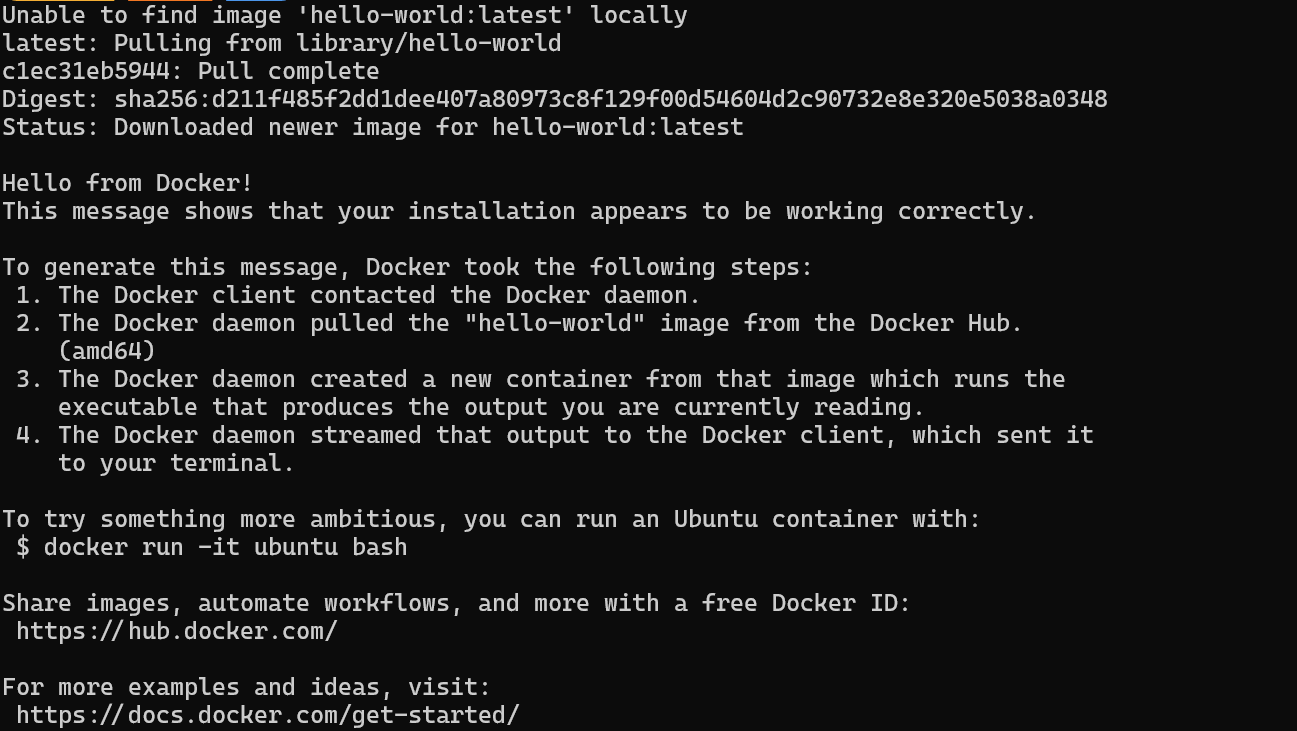
$ wsl --installNachdem du die WSL erfolgreich installiert hast, starte dein System neu. Gib dann den folgenden Befehl in die PowerShell ein, um zu überprüfen, ob Docker richtig funktioniert.
$ docker run hello-worldDocker hat das hello-world-Image erfolgreich gezogen und den Container gestartet.
In diesem Leitfaden lernen wir, wie man Docker Compose verwendet, um KI-Dienste lokal einzurichten. Mit diesem Ansatz kannst du innerhalb von Minuten Docker-Images laden und Container bereitstellen. So kannst du auf einfache Weise mehrere KI-Dienste in deiner Infrastruktur betreiben und verwalten.
Zuerst klonen wir n8n-io/self-hosted-ai-starter-kit indem wir den folgenden Befehl in das Terminal eintippen.
$ git clone https://github.com/n8n-io/self-hosted-ai-starter-kit.git
$ cd self-hosted-ai-starter-kitDas Starter Kit ist der einfachste Weg, um die Server und Anwendungen einzurichten, die für den Aufbau eines KI-Workflows benötigt werden. Dann laden wir die Docker-Images und starten die Container.
$ docker compose --profile cpu upWenn du einen NVIDIA-Grafikprozessor hast, versuche, den folgenden Befehl einzugeben, um die Beschleunigung bei der Antwortgenerierung zu nutzen. Richte auch die NVIDIA GPU für Docker ein, indem du die Ollama Docker Anleitung.
$ docker compose --profile gpu-nvidia upEs wird ein paar Minuten dauern, bis alle Docker-Images heruntergeladen und die Docker-Container nacheinander ausgeführt sind.
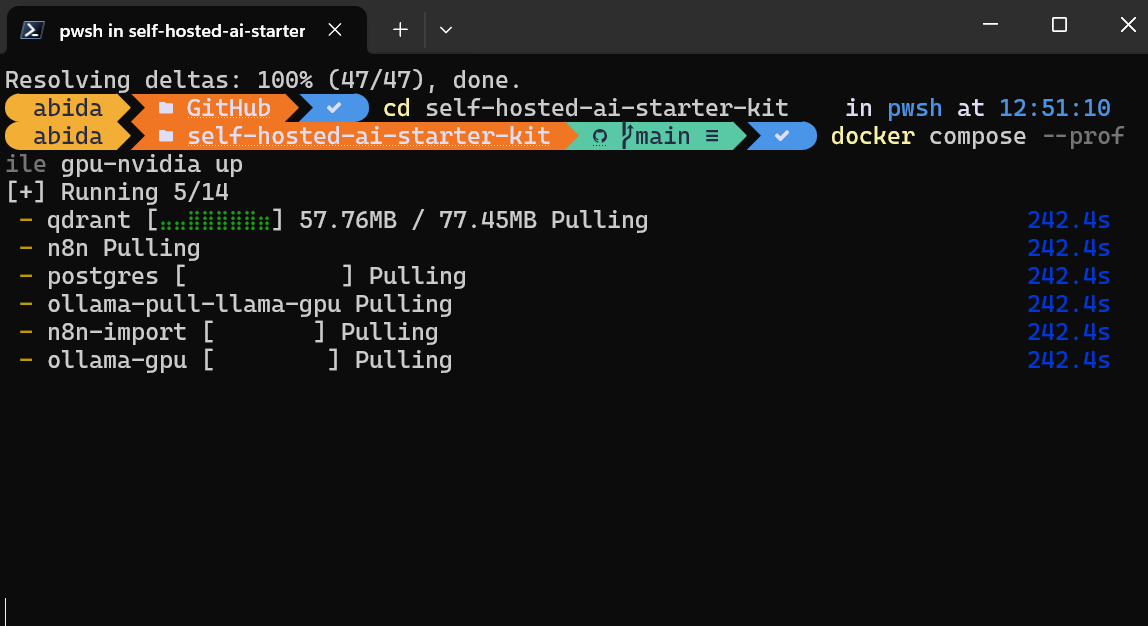
Alle Docker-Dienste werden ausgeführt. Die verlassenen Docker-Container wurden verwendet, um das Llama 3.2-Modell herunterzuladen und den n8n-Backup-Workflow zu importieren.
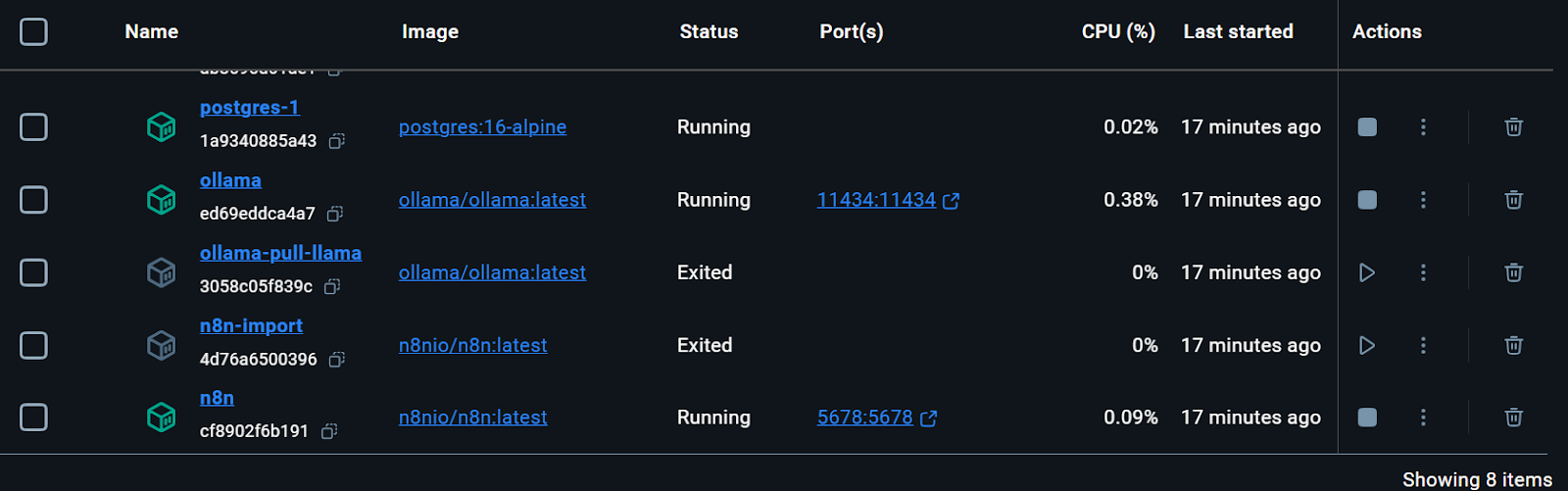
Wir können sogar den Status der Ausführung des Docker-Containers überprüfen, indem wir den folgenden Befehl in das Terminal eingeben.
$ docker compose psDas Starterkit enthält das Skript zum Herunterladen des Llama 3.2 Modells. Für eine richtige RAG-Chatbot-Anwendung brauchen wir aber auch das Einbettungsmodell. Wir gehen zum Ollama-Docker-Container, klicken auf den Reiter "Ausführen" und geben den folgenden Befehl ein, um das Modell "nomic-embed-text" herunterzuladen.
$ ollama pull nomic-embed-textWie wir sehen, können wir mit einem Docker-Container interagieren, als wäre er eine separate virtuelle Maschine.
Öffne die n8n Dashboard URL http://localhost:5678/ in deinem Browser, um ein n8n-Benutzerkonto mit E-Mail und Passwort einzurichten. Dann klickst du auf der Hauptseite des Dashboards auf den Home-Button und rufst den Demo-Workflow auf.
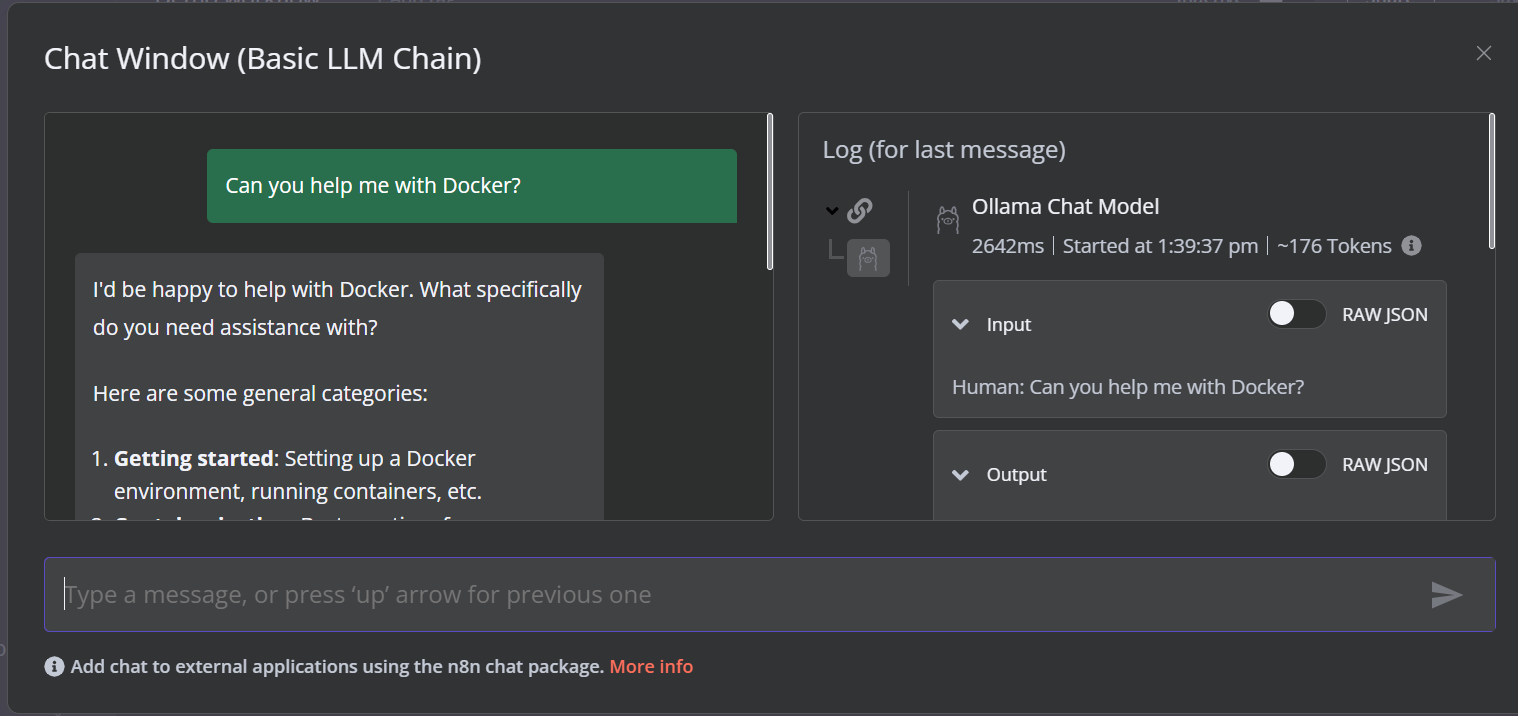
Die Demo ist ein einfacher LLM-Workflow, der die Benutzereingaben entgegennimmt und die Antwort erzeugt.
Um den Workflow zu starten, klicke auf die Schaltfläche Chat und beginne mit der Eingabe deiner Frage. Innerhalb weniger Sekunden erhältst du eine Antwort.
Bitte beachte, dass wir ein kleines Sprachmodell mit GPU-Beschleunigung verwenden, sodass die Antwort normalerweise nur etwa 2 Sekunden dauert.
In diesem Projekt werden wir eine RAG (Retrieval-Augmented Generation) Chatbot entwickeln, der Daten aus den Harry Potter-Filmen nutzt, um kontextabhängige und genaue Antworten zu geben. Dieses Projekt ist eine No-Code-Lösung, d.h. du musst nur die notwendigen Workflow-Komponenten suchen und sie miteinander verbinden, um einen KI-Workflow zu erstellen.
n8n ist eine no-code Plattform ähnlich wie Langchain. Folge der RAG mit Llama 3.1 8B, Ollama, und Langchain Tutorial, um einen Überblick darüber zu bekommen, wie du einen ähnlichen KI-Workflow mit Langchain erstellen kannst.
Klicke auf die Schaltfläche "Den ersten Schritt hinzufügen" in der Mitte des Dashboards, suche nach dem "Chat-Auslöser" und füge ihn hinzu.
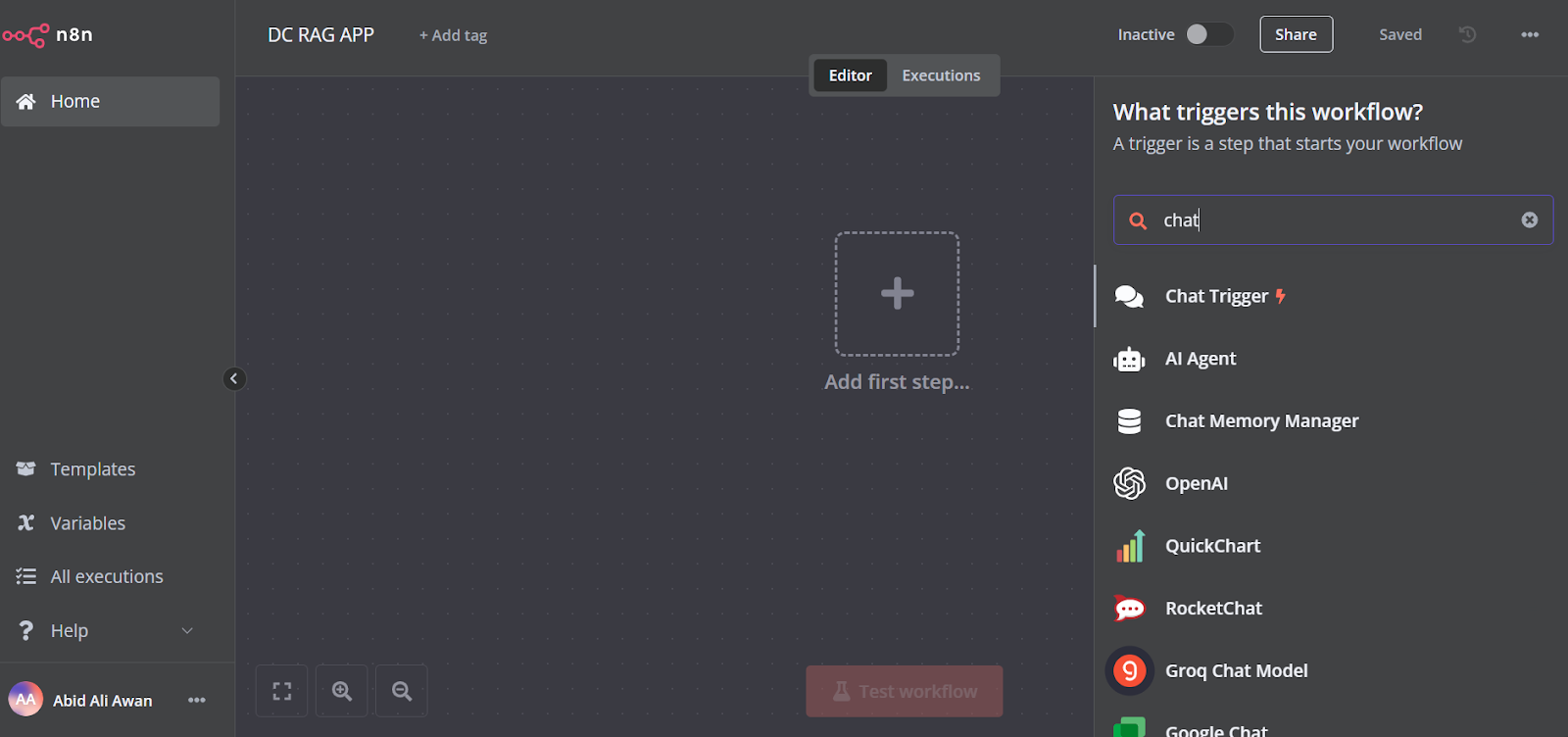
Stelle sicher, dass du "Datei-Uploads zulassen" aktiviert hast.
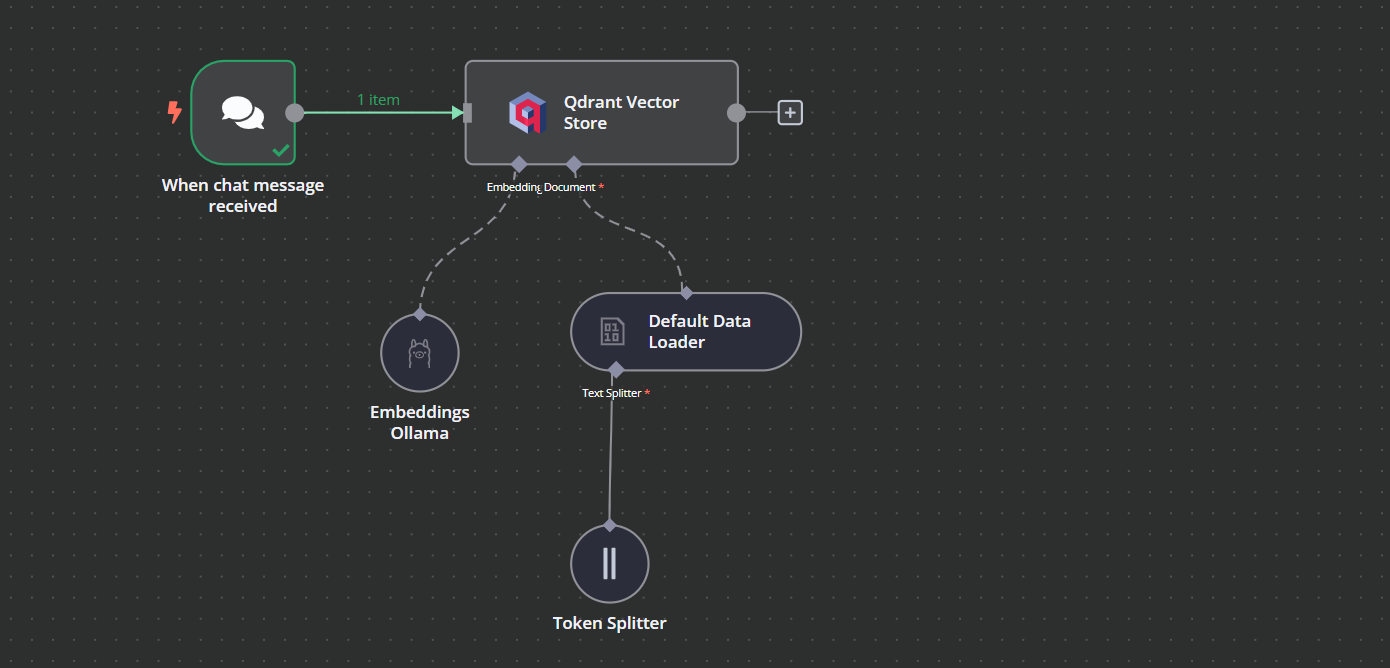
Du kannst eine weitere Komponente namens "Qdrant Vector Store" hinzufügen, indem du auf die Plus-Schaltfläche (+) der Komponente "Chat Trigger" klickst und sie suchst.
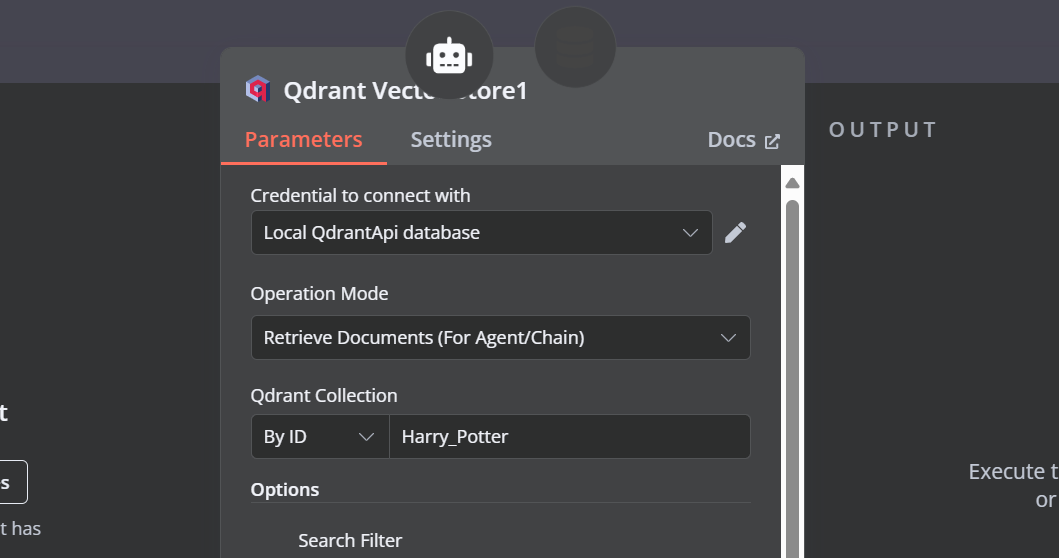
Ändere den Betriebsmodus auf "Dokumente einfügen", ändere die Qdrant-Sammlung auf "Nach ID" und gib die ID als "Harry_Potter" ein.
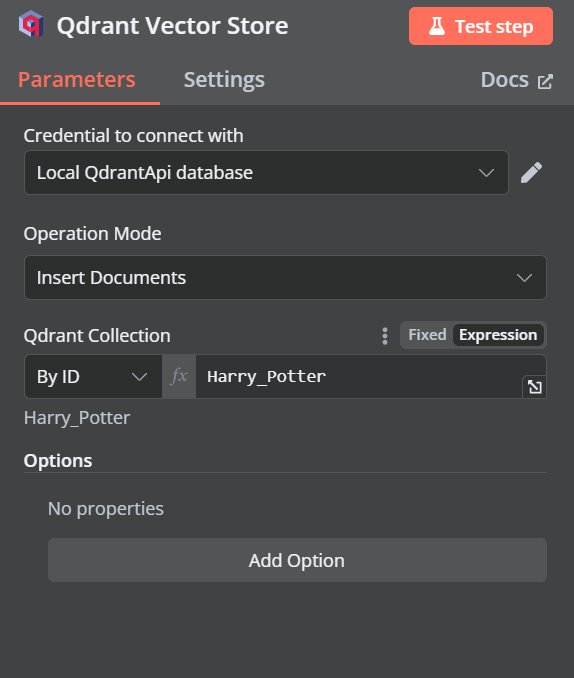
Wenn wir die Option verlassen, sehen wir, dass der Chat-Trigger mit unserem Vektorspeicher verbunden ist.
Klicke auf den Plus-Button unter dem Qdrant-Vektorspeicher mit der Aufschrift "Einbetten". Wir werden zum Modellverwaltungsmenü weitergeleitet, wo wir Einbettungen Ollama auswählen und das Modell in "nomic-embed-text:latest" ändern.
Klicke auf die Plus-Schaltfläche unter dem Qdrant-Vektorspeicher, auf der "Dokument" steht, und wähle "Standard-Datenlader" aus dem Menü. Ändere den Typ der Daten in "Binär".
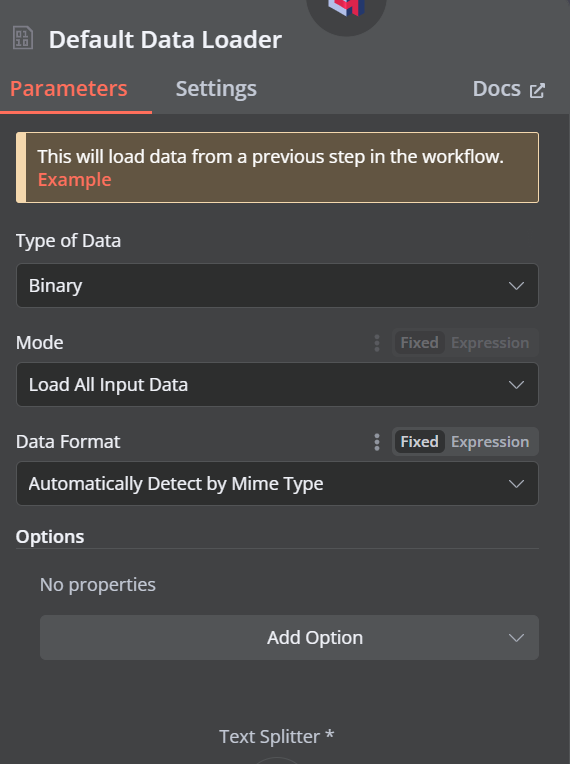
Dann fügst du einen Token-Splitter mit einer Chunk-Größe von 500 und einer Chunk-Überlappung von 50 in den Dokumentenlader ein.
So sollte unser Arbeitsablauf am Ende aussehen. Dieser Arbeitsablauf nimmt die CSV-Dateien des Nutzers entgegen, wandelt sie in Text um, wandelt den Text dann in Einbettungen um und speichert sie im Vektorspeicher.
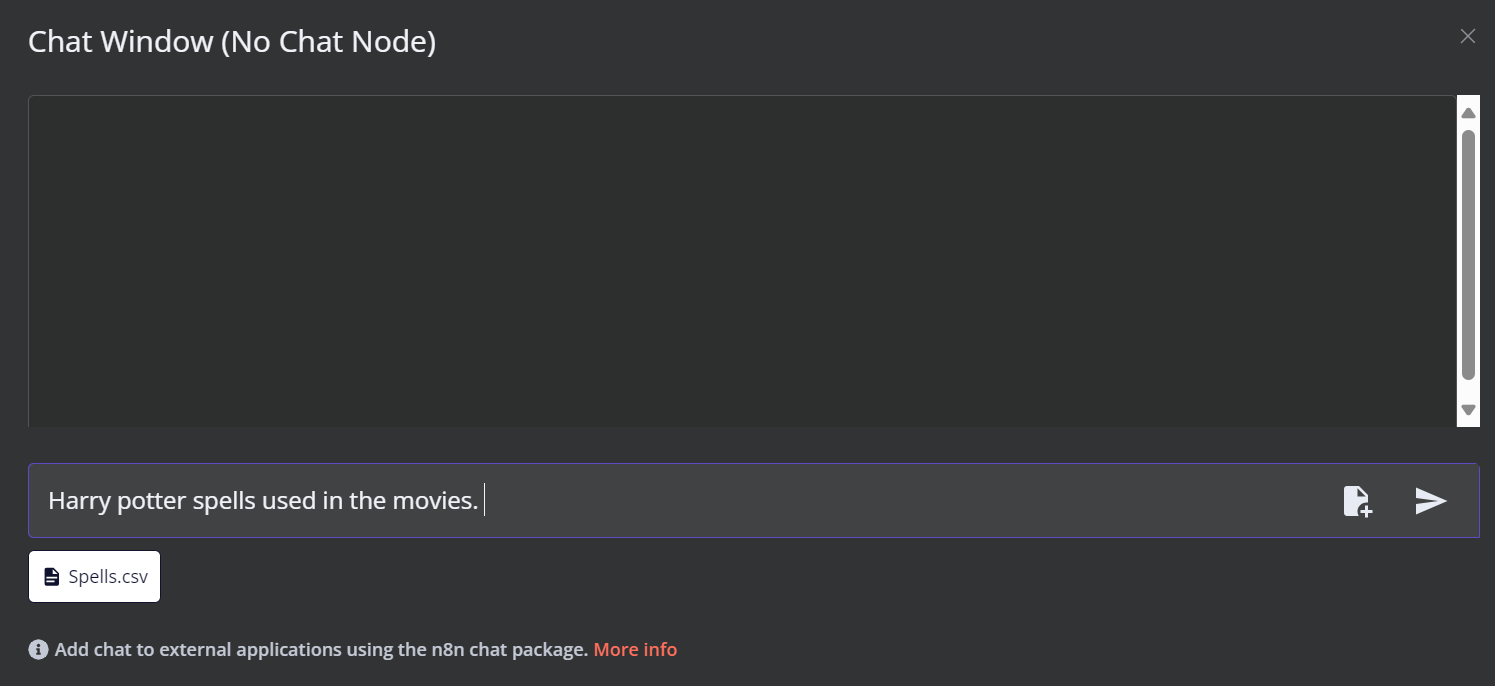
Klicke unten im Dashboard auf die Schaltfläche Chat. Sobald sich das Chat-Fenster öffnet, klicke auf die Schaltfläche "Datei" (siehe unten).
In diesem Arbeitsablauf laden wir alle CSV-Dateien aus der Datei Harry Potter Filme Datensatz. Um unseren Arbeitsablauf zu testen, laden wir jedoch nur eine einzige CSV-Datei namens "spell" auf der Grundlage einer Benutzerabfrage.
Du kannst den Qdrant-Server über die URL aufrufen http://localhost:6333/dashboard aufrufen und überprüfen, ob die Datei in den Vektorspeicher geladen wurde oder nicht.
Jetzt fügst du die restlichen Dateien zum Vektorspeicher hinzu.
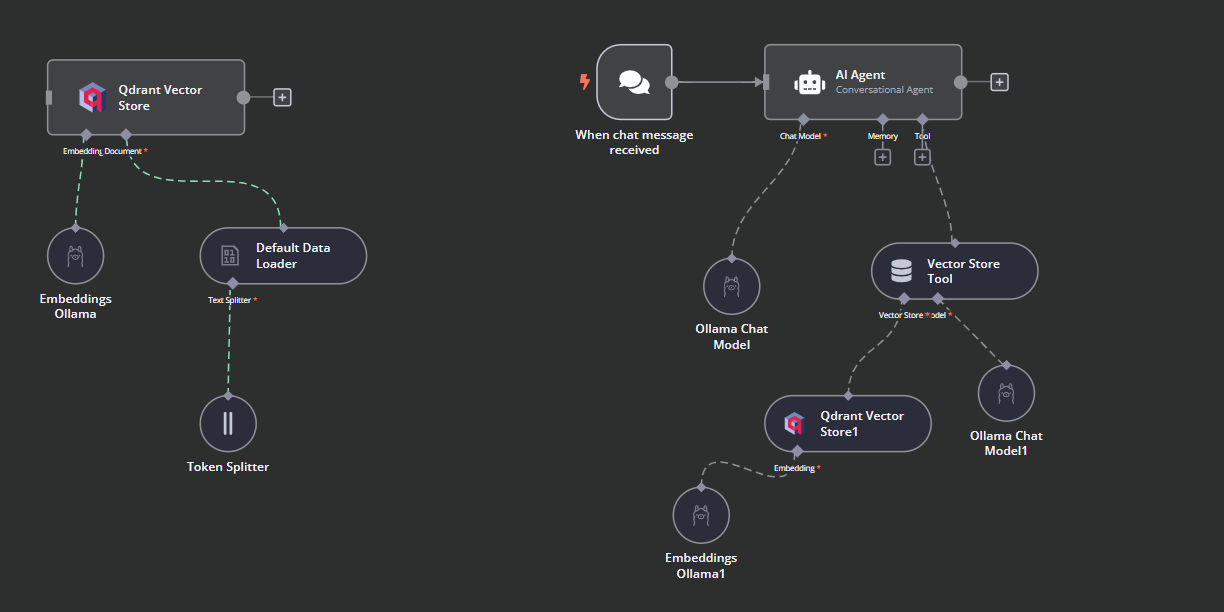
Wir verbinden den Chat-Trigger mit dem Vektorspeicher, verknüpfen ihn mit dem KI-Agenten und ändern den Agententyp in "Conversation Agent".
Klicke auf die Schaltfläche "Chat-Modell" unter KI-Agent und wähle das Ollama Chat-Modell aus dem Menü aus. Danach rufe den Modellnamen "Llama3.2:latest" auf.
Klicke auf die Schaltfläche "Werkzeug" unter dem KI-Agenten und wähle das Werkzeug "Vektorspeicher" aus dem Menü. Gib den Namen des Werkzeugs und die Beschreibung an.
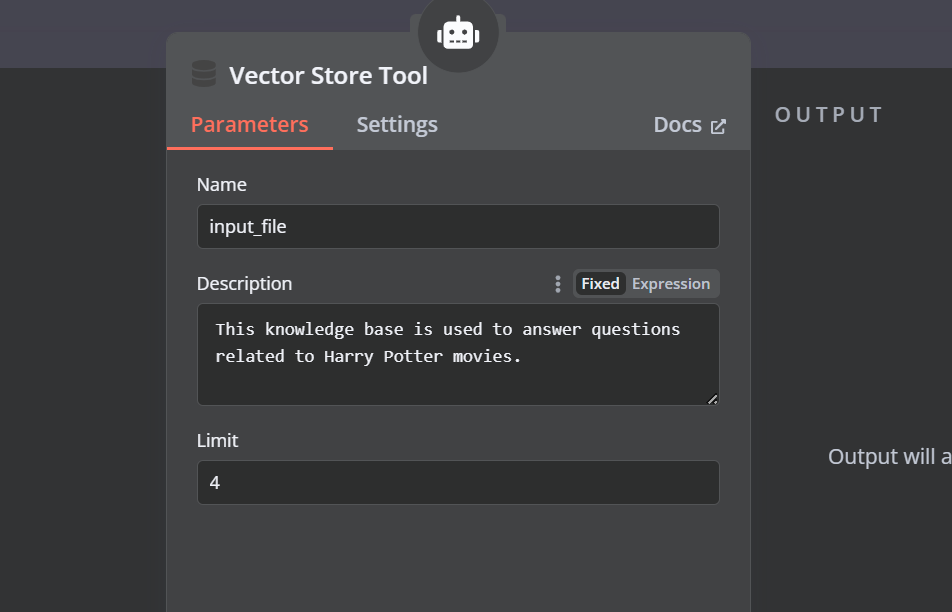
Wir müssen dem Vektorspeicherwerkzeug Komponenten hinzufügen. Zuerst werden wir Qdrant als Vektorspeicher einbinden und die Sammlungs-ID auf "Harry_Potter" setzen. Dieser Vektorspeicher wird bei der Ähnlichkeitssuche auf die Harry Potter-Sammlung zugreifen. Ändere außerdem den Betriebsmodus auf "Abgerufene Dokumente".
Das Vektorspeicher-Tool benötigt ebenfalls ein LLM-Modell. Wir verbinden das Ollama-Chatmodell und ändern das Modell in "llama3.2:latest".
Im letzten Schritt versorgen wir den Retrieval-Vektorspeicher mit dem Einbettungsmodell. Auf diese Weise kann er die Benutzeranfrage in eine Einbettung umwandeln und die Einbettung dann wieder in Text umwandeln, den der LLM dann verarbeiten kann.
Stelle sicher, dass du das richtige Einbettungsmodell für deinen Vektorspeicher angibst.
So sollte der KI-Workflow aussehen.
Klicke auf den Chat-Button, um Fragen über das Harry Potter-Universum zu stellen.
Prompt: "Was ist der geheimste Ort in Hogwarts?"
Prompt: "Was ist der mächtigste Zauberspruch?"
Unser KI-Workflow ist schnell und funktioniert reibungslos. Dieser No-Code-Ansatz ist ganz einfach auszuführen. n8n ermöglicht es den Nutzern auch, ihre Anwendungen zu teilen, so dass jeder über einen Link darauf zugreifen kann, genau wie bei einem ChatGPT.
n8n ist ein perfektes Werkzeug für LLM/AI-Projekte, vor allem für technisch nicht versierte Personen. Manchmal müssen wir den Workflow nicht einmal von Grund auf neu erstellen. Alles, was wir tun müssen, ist nach ähnlichen Projekten auf der n8n-Websitezu suchen, den JSON-Code zu kopieren und ihn in unser n8n-Dashboard einzufügen. So einfach ist das.

Quelle: Entdecke über 900 Automatisierungsworkflows aus der n8n-Community
In diesem Tutorium haben wir etwas über lokale KI gelernt und wie man das selbst gehostete KI-Starterkit verwendet, um verschiedene KI-Dienste zu erstellen und einzusetzen. Dann haben wir das n8n Dashboard gestartet und unseren eigenen KI-Workflow mit Qdrant, Einbettungsmodellen, Vektorspeicher-Tools, LLMs und Dokumentenladern erstellt. Das Erstellen und Ausführen von Arbeitsabläufen ist mit n8n ganz einfach. Wenn du dich noch nicht mit KI-Tools auskennst und mehr über No-Code-KI-Lösungen erfahren möchtest, schau dir unsere anderen Ressourcen an:
Top KI-Kurse
Lernpfad
Lernpfad
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
