Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
99.8K
Cuando OpenAI lanzó ChatGPT en 2022, muchos se preguntaron si otras empresas podrían competir con un producto tan bueno respaldado por un gigante como Microsoft. Cuando todo el mundo tenía su atención puesta en otras grandes tecnológicas como Google y Meta para que cumplieran, apareció Mistral AI con su modelo 7B en 2023, que superó a todos los LLM de código abierto con casi el doble de tamaño.
Desde entonces, Mistral AI se ha convertido en un actor importante en la carrera de los LLM. En abril de 2024, lanzaron Mixtral 8X22B, un modelo que superaba fácilmente al entonces mejor LLM de código abierto, Llama 2, en muchos benchmarks.
En este tutorial, hablaremos en detalle del modelo Mixtral 8X22B, desde su arquitectura hasta la configuración de una canalización RAG con él.
Mixtral 8X22B es el último modelo lanzado por Mistral AI. Presume de una arquitectura de mezcla dispersa de expertos (SMoE) con 141.000 millones de parámetros. Es esta arquitectura SMoE la que aporta muchas de sus ventajas. SMoE es un tipo de red neuronal que utiliza diferentes modelos más pequeños (expertos) para diferentes tareas, activando sólo los necesarios para ahorrar tiempo y potencia de cálculo.
En primer lugar, el modelo ofrece una rentabilidad inigualable para su tamaño, proporcionando la mejor relación rendimiento-coste de la comunidad de código abierto:
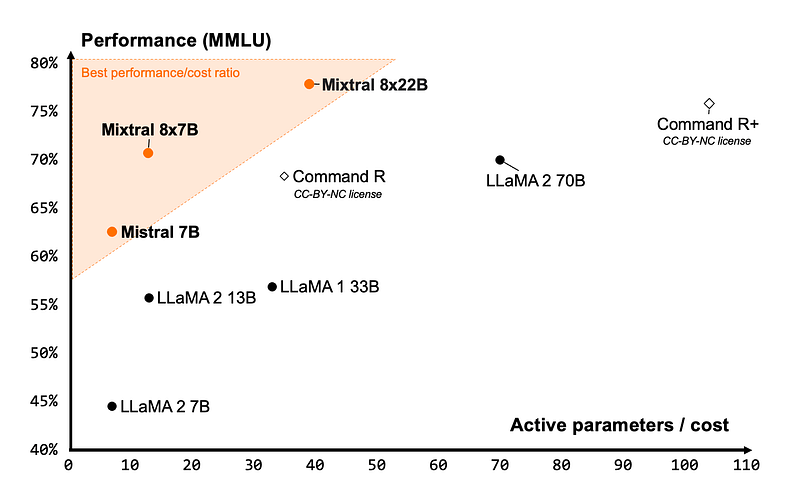
La imagen anterior muestra algunos de los principales LLM de código abierto y el número de parámetros activos que necesitan para alcanzar un determinado umbral de rendimiento. Mixtral está justo en la esquina superior izquierda, lo que significa que utiliza bastantes menos parámetros para alcanzar un rendimiento del +75% que un modelo del mismo rango: Comando R+.
Aunque Mixtral 8X22B tiene 141.000 millones de parámetros, su patrón de activación disperso sólo utiliza 39.000 millones de parámetros durante la inferencia. Esto hace que tenga un alto rendimiento y sea más rápido que cualquier modelo de 70 mil millones de parámetros densos como Llama 2 70B. También cuenta con una ventana contextual de 64k fichas, algo muy poco habitual en los LLM de código abierto actuales.
El modelo también viene con la licencia de código abierto más permisiva: Apache 2.0. Combinado con el bajo coste que requiere su funcionamiento, el Mixtral 8X22B es una opción excelente para escenarios de puesta a punto.
Mixtral 8x22B supera con nota las pruebas estándar del sector. En la mayoría de las evaluaciones comparativas, se hizo hincapié en lo bien que había funcionado el modelo en comparación con sus principales alternativas similares:
Por ejemplo, el Mixtral 8X22B domina cinco idiomas: Inglés, alemán, francés, español e italiano. La prueba puede verse en la tabla siguiente:
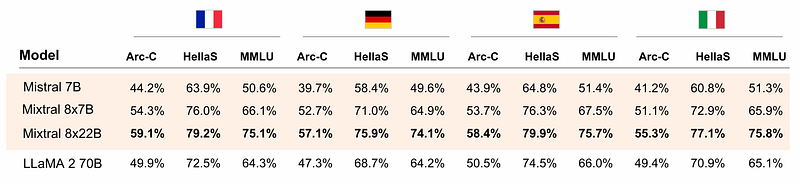
Supera al Llama 2 70B en tareas lingüísticas en tres pruebas de referencia:
En cuanto a las preguntas de razonamiento y conocimientos puros de sentido común en inglés, Mixtral vuelve a rendir admirablemente:
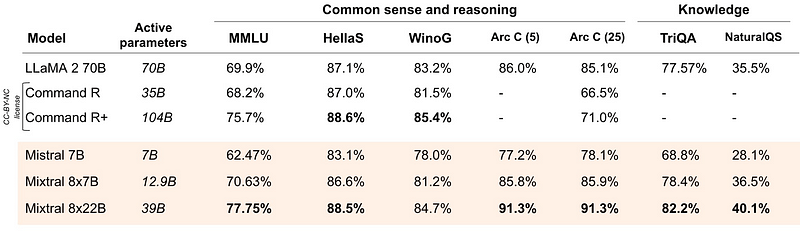
Es ligeramente peor que el Comando R+ en dos pruebas comparativas, pero en otras es significativamente mejor.
Y su punto más definitorio: Mixtral 8X22B aplasta a todas sus alternativas en tareas matemáticas y de codificación:
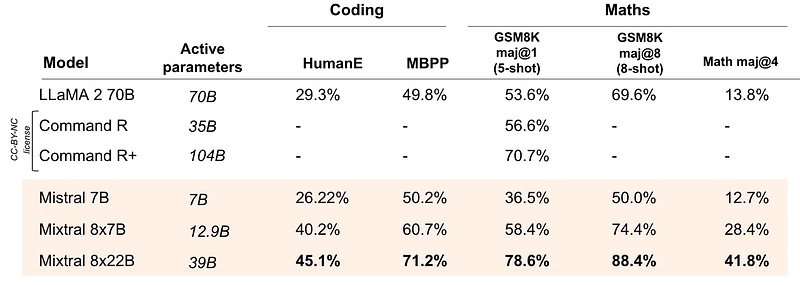
Veamos ahora cómo consigue el modelo sus prestaciones de vanguardia.
Para comprender mejor la arquitectura de la mezcla dispersa de expertos (SMoE), utilizaremos una sencilla analogía. Supongamos que 100 personas trabajan en un proyecto.
Los modelos SMoE tienen los siguientes componentes clave:
Este tipo de estructura modelo tiene muchas ventajas:
Sin embargo, al ser nuevos, los modelos SMoE presentan retos únicos que aún no se han abordado eficazmente:
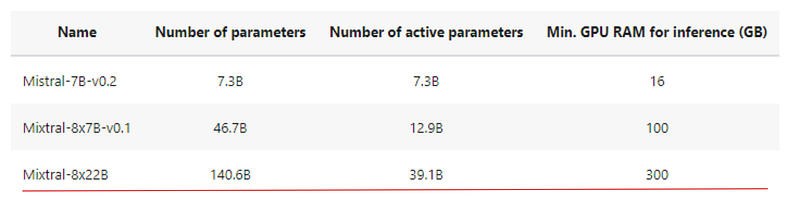
En resumen, dado que la escala del modelo es uno de los factores más importantes para mejorar la calidad del modelo, reducir el número de parámetros activos hace que los modelos sean mucho más baratos y rápidos de entrenar. Entrenar un modelo más grande para menos pasos es mejor que entrenar un modelo pequeño para más pasos cuando el presupuesto de cálculo es limitado.
La mezcla de arquitecturas expertas permite que los modelos se entrenen con mucho menos cálculo, lo que te permite ampliar el tamaño del modelo drásticamente con el mismo presupuesto que un modelo denso. Cualquier modelo SMoE debería alcanzar la misma calidad que su homólogo denso mucho más rápido durante el preentrenamiento.
En esta sección aprenderemos a empezar a utilizar el modelo Mixtral 8X22B mediante la API Mistral. Como el modelo tiene un tamaño de unos 80 gigabytes y requiere una GPU de 300 gigabytes, será un poco difícil y caro ejecutarlo en cualquier proveedor de la nube, por no hablar del hardware de consumo.
Mistral AI requiere que crees una cuenta e introduzcas información de facturación para obtener tu clave API. Por tanto, dirígete a mistral.ai para crear tu cuenta. Una vez que te conectes con tus credenciales, serás dirigido a tu consola Mistral en console.mistral.ai.
A continuación, dirígete a "Facturación" y añade tu información de pago:

Después, añade algunos créditos:
Esto te permitirá generar una clave API desde la sección "CLAVES API":
Cuando crees una clave, sólo se mostrará una vez, así que guárdala en un lugar seguro. Lo utilizaremos en la siguiente sección.
Ahora, vamos a configurar un entorno virtual para ejecutar la API Mistral. Utilizaremos Conda:
$ conda init # Run if your Conda executable is new
$ conda env create -n mistral python==3.8 -y
$ conda activate mistral
A continuación, podemos instalar el paquete mistralai Python junto con un par de elementos esenciales más:
$ pip install mistralai
$ pip install python-dotenv ipykernel
$ ipython kernel install --user --name=mistral
El último comando añade el entorno Conda recién instalado como núcleo Jupyter.
Utilizaremos el paquete python-dotenv para leer de forma segura nuestra clave API Mistral desde un bloc de notas. Para ello, crea un archivo .env en tu directorio de trabajo:
$ touch .envA continuación, edita el archivo para que enumere tu clave con la siguiente sintaxis:
MISTRAL_API_KEY=YOUR_KEY_HEREAdemás, asegúrate de añadir el archivo .env a .gitignore para que no se filtre accidentalmente a GitHub:
$ echo ".env" >> .gitignore
Ahora, para leer la clave que acabamos de guardar, podemos utilizar la función load_dotenv junto con la biblioteca os:
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.getenv("MISTRAL_API_KEY")
Por último, para interactuar con cualquier modelo de Mistral, utilizaremos el objeto MistralClient:
from mistralai.client import MistralClient
client = MistralClient(api_key=api_key)
El cliente necesita nuestra clave API para conectarse a los servidores de Mistral. A continuación, importaremos la clase ChatMessage para mantener diálogos con modelos Mistral:
from mistralai.models.chat_completion import ChatMessage
model = "open-mixtral-8x22b"
message = "Who is the best French football player of all time?"
chat_response = client.chat(
model=model,
messages=[ChatMessage(role="user", content=message)],
)
print(chat_response.choices[0].message.content[:300])
Determining the "best" French football player of all time can be subjective and depends on personal opinion. However, one player who is often mentioned in this context is Zinedine Zidane. He had an impressive career both for the French national team and at club level. He was a key player in France'sRecibimos una respuesta, así que todo está configurado correctamente.
Un objeto ChatResponse suele contener más de una respuesta, por lo que estamos seleccionando la primera e imprimiendo un subtexto.
Más allá de la generación de texto plano, puedes hacer mucho más con Mixtral:
etc. Examinaremos cada uno de estos supuestos uno por uno.
En la sección anterior, pudimos generar una gran cantidad de texto del cliente de chat. En algunos casos, cuando suponemos que la respuesta puede ser más larga, tiene sentido transmitir la salida como en ChatGPT. También podemos hacerlo con Mixtral
messages = [ChatMessage(role="user", content="What led to Zidane's ban from football?")]
# With streaming
stream_response = client.chat_stream(model=model, messages=messages)
for chunk in stream_response:
print(chunk.choices[0].delta.content, end="")
En lugar del método chat, podemos utilizar chat_stream, que da la respuesta a demanda, en trozos:
Las incrustaciones son componentes clave de las aplicaciones LLM. Una incrustación es una representación vectorial del texto que capta su significado semántico a través de su posición en un espacio vectorial de alta dimensión. Si la distancia entre dos incrustaciones es cercana, significa que son similares en significado. Por ejemplo, la palabra manzana estará más cerca de naranja que de teclado en el espacio de incrustación.
La API Mistral ofrece modelos de incrustación de texto de última generación. Veamos brevemente cómo funcionan:
to_embed = ["Is Messi better than Zidane?", "How about Ronaldo?"]
embeddings_batch_response = client.embeddings(
model="mistral-embed",
input=to_embed,
)
type(embeddings_batch_response)
mistralai.models.embeddings.EmbeddingResponse
En primer lugar, creamos una lista de frases para incrustar en to_embed. A continuación, los pasaremos al método embeddings junto con un nombre de modelo de incrustación - mistral-embed. El resultado es un objeto EmbeddingResponse. Cuando imprimamos la longitud de su atributo data, veremos que tiene dos vectores para las dos frases incrustadas:
len(embeddings_batch_response.data)2También podemos obtener las dimensiones de los vectores:
first_sentence = embeddings_batch_response.data[0]
len(first_sentence.embedding) # Embedding dimension
1024Hemos obtenido un resultado de 1024, lo que significa que Mistral incrusta cualquier texto, independientemente de su longitud, en un vector de 1024 dimensiones.
Ten en cuenta que las incrustaciones de mayor dimensión pueden captar mejor la información del texto y mejorar el rendimiento, pero requieren más cálculo para el alojamiento y la inferencia.
Aunque no hemos utilizado el modelo Mixtral 8X22B en la sección, comprender las incrustaciones será importante cuando creemos una canalización RAG sencilla.
Como hemos dicho antes, si la distancia entre dos incrustaciones es próxima, entonces puede que su significado sea próximo. Ampliando esta idea, podemos construir un detector primitivo de paráfrasis, ya que si la distancia entre dos frases es corta, existe la posibilidad de que sean paráfrasis.
En primer lugar, crearemos una función que devuelva el vector de incrustación para una entrada dada:
def get_text_embedding(input, client):
embeddings_batch_response = client.embeddings(
model="mistral-embed", input=input
)
return embeddings_batch_response.data[0].embedding
A continuación, definiremos la lista de frases que queremos cotejar para parafrasear y obtendremos sus incrustaciones:
sentences = [
"What led to Zidane's ban from football?",
"This is a totally different sentence.",
"What caused Zidane to get banned from football?",
]
sentence_embeddings = [get_text_embedding(t, client) for t in sentences]
A continuación, crearemos todas las combinaciones posibles de dos pares de frases utilizando itertools:
import itertools
sentence_embeddings_pairs = list(itertools.combinations(sentence_embeddings, 2))
sentence_pairs = list(itertools.combinations(sentences, 2))
print(sentence_pairs[0])
("What led to Zidane's ban from football?", 'This is a totally different sentence.')A continuación, imprimiremos la distancia euclídea entre cada par de incrustación de frases e imprimiremos los resultados:
from sklearn.metrics.pairwise import euclidean_distances
for s, e in zip(sentence_pairs, sentence_embeddings_pairs):
distance = euclidean_distances([e[0]], [e[1]])
print(s, distance)
("What led to Zidane's ban from football?", 'This is a totally different sentence.') [[0.84503319]]
("What led to Zidane's ban from football?", 'What caused Zidane to get banned from football?') [[0.28662641]]
('This is a totally different sentence.', 'What caused Zidane to get banned from football?') [[0.83794058]]
La distancia entre el segundo par es estrecha, lo que indica que podrían ser paráfrasis el uno del otro.
Los LLM se forman con montones y montones de datos, pero no siempre están actualizados y no tienen acceso a tus conjuntos de datos privados. Afinarlos es demasiado caro si sólo quieres que el modelo responda a preguntas sobre otros conjuntos de datos existentes.
Por eso han ganado popularidad las canalizaciones de Generación Aumentada de Recuperación (RAG). Sin una costosa puesta a punto, puedes enseñar a un LLM a procesar información personalizada que no formaba parte de su formación y responder a preguntas sobre ella.
En esta sección, construiremos una canalización RAG básica que aprenda la información de las noticias de ayer en este artículo 1440. He guardado parte de las noticias en este archivo de texto, que puedes descargar de mi GitHub o simplemente copiar/pegar y guardar en un archivo llamado news_piece.txt.
Para leer el contenido del archivo, podemos utilizar la biblioteca pathlib:
from pathlib import Path
file = Path("news_piece.txt")
text = file.read_text()
A continuación, dividiremos el documento en trozos, ya que los sistemas RAG funcionan mejor cuando el texto está en trozos. En este ejemplo, dividiremos el texto en trozos de 512 caracteres cada uno:
chunk_size = 512
chunks = [text[i : i + chunk_size] for i in range(0, len(text), chunk_size)]
len(chunks)
4A continuación, obtendremos las incrustaciones de cada trozo utilizando la función get_text_embedding de la última sección:
text_embeddings = np.array([get_text_embedding(chunk, client) for chunk in chunks])Después, es práctica habitual almacenar las incrustaciones en una base de datos vectorial para procesarlas y recuperarlas con eficacia. Existen muchas opciones de bases de datos vectoriales. Utilizaremos faiss, una base de datos de código abierto para la búsqueda de similitudes.
import faiss # pip install faiss
d = text_embeddings.shape[1]
index = faiss.IndexFlatL2(d)
index.add(text_embeddings)
index es una instancia de una clase Index, que define la estructura de nuestra base de datos. d es para la dimensión del espacio de incrustación.
Ejecutar el método add añade la información de nuestro documento a la base de datos de vectores, lo que significa que podemos hacer preguntas sobre él. Pero antes de hacer eso, cualquier pregunta que tengamos debe convertirse también en una incrustación:
import numpy as np
questions = [
"How much is Microsoft going to spend for its new data center?",
"When did FTX collapse?",
]
question_embeddings = np.array([get_text_embedding(q, client) for q in questions])
A continuación, podemos introducir la matriz question_embeddings en el método search del objeto Index:
D, I = index.search(question_embeddings, k=4) # distance, index
retrieved_chunk = [chunks[i] for i in I.tolist()[0]]
El método search devuelve los vectores que más probablemente contengan la respuesta a nuestras preguntas (utilizando la búsqueda por similitud):
len(retrieved_chunk)
4print(retrieved_chunk[2])
ay defrauded investors in full and provide the vast majority with interest. The failed cryptocurrency exchange platform filed its proposal late Tuesday to a federal bankruptcy court for approval.
Since FTX collapsed in 2022, CEO John Ray III (see previous write-up) has worked to track down more than $8B in missing assets to repay an estimated $11.2B owed to creditors. This week, Ray said the company has recovered between $14.5B and $16.3B, with much of the funds tied to government-seized FTX properties or
Ahora, podemos pasar este texto como contexto para el modelo Mixtral 8X22B y hacer nuestras preguntas sobre él. Construyamos el aviso:
prompt = f"""
Context information is below.
---------------------
{retrieved_chunk}
---------------------
Given the context information and not prior knowledge, answer the query.
Query: {questions}
Answer:
"""
Ahora, podemos pasarlo al modelo utilizando la dirección client:
chat_response = client.chat(
model=model, # Mixtral 8x22B
messages=[ChatMessage(role="user", content=prompt)],
)
print(chat_response.choices[0].message.content)
Microsoft will spend $3 billion for its new data center in Racine, Wisconsin. FTX collapsed in 2022.
¡Las respuestas son correctas!
Hemos construido un conducto RAG muy básico. En la práctica, las tuberías RAG son muy potentes: pueden manejar una gran variedad de entradas (texto, imagen, audio, vídeo) y pueden trabajar a escala masiva, en comparación con nuestra versión que manejaba un único archivo de texto.
Si quieres aprender a construir potentes pipelines RAG, consulta nuestro Tutorial Cómo construir aplicaciones LLM con LangChain.
Una de las capacidades nativas del modelo Mixtral 8X22B es la llamada a funciones. En el contexto de los LLM, la llamada a funciones es una técnica que permite a los LLM comprender y responder a las indicaciones de forma que se desencadene la ejecución de funciones específicas. Aquí tienes un desglose de lo que eso significa:
Demostrar cómo funciona la llamada a funciones está fuera del alcance de este artículo. Sin embargo, puedes consultar esta página de documentación sobre la IA de Mistral para verla en acción.
En este artículo, hemos conocido el modelo Mixtral 8X22B lanzado por Mistral AI en abril de 2024. Debido a sus ventajas arquitectónicas, ahora es uno de los principales LLM de código abierto, superando a modelos populares como Llama 2 y Command R+ en muchos benchmarks.
Aparte de los detalles de su arquitectura, hemos aprendido a utilizarlo en algunos escenarios prácticos, como la generación de textos, la detección de paráfrasis y la creación de un pipeline RAG. Si quieres liberar todo el potencial del modelo Mixtral 8X22B, consulta estos recursos relacionados:
¡Continúa hoy tu viaje de aprendizaje de la IA!
Curso
Curso
Curso