
Kurs
Konzepte großer Sprachmodelle (LLMs)
2 Std.
99.8K
When OpenAI released ChatGPT in 2022, many wondered if other companies could compete with such a good product backed by a behemoth like Microsoft. When everyone had their attention on other large techies such as Google and Meta to deliver, out came Mistral AI with their 7B model in 2023, which outperformed all open-source LLMs with almost twice the size.
Since then, Mistral AI has become a big player in the LLM race. In April 2024, they released Mixtral 8X22B, a model that easily outperformed then-best open-source LLM, Llama 2, on many benchmarks.
In this tutorial, we will discuss the Mixtral 8X22B model in detail, from its architecture to setting up a RAG pipeline with it.
Mixtral 8X22B is the latest model released by Mistral AI. It boasts a sparse mixture of experts (SMoE) architecture with 141 billion parameters. It is this SMoE architecture that gives many of its advantages. SMoE is a type of neural network that uses different smaller models (experts) for different tasks, turning on only the needed ones to save time and computing power.
First of all, the model offers an unmatched cost efficiency for its size, delivering the best performance-to-cost ratio in the open-source community:
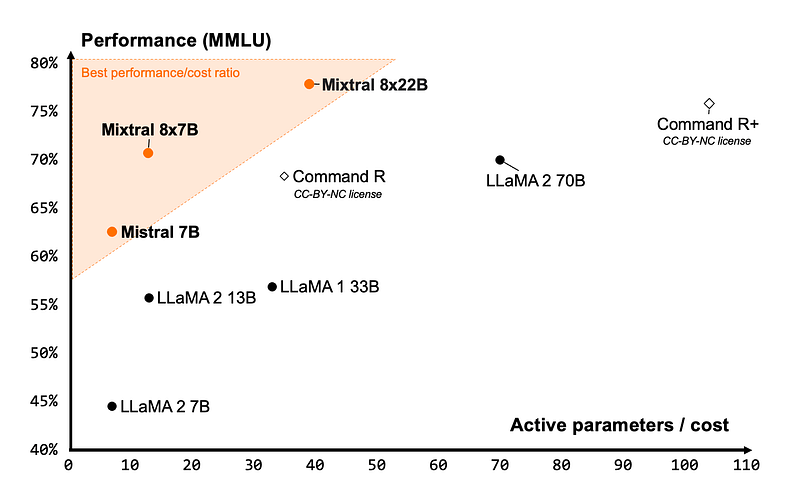
The image above features some of the leading open-source LLMs and the number of active parameters they require to reach a certain performance threshold. Mixtral is right in the top left corner, which means it uses significantly fewer parameters to reach +75% performance than a model in the same ballpark — Command R+.
Even though Mixtral 8X22B has 141 billion parameters, its sparse activation pattern uses only 39 billion parameters during inference. This makes it high-performant and faster than any 70-billion parameter-dense model like Llama 2 70B. It also features a 64k-token context window, which is very rare for today’s open-source LLMs.
The model also comes with the most permissive open-source license — Apache 2.0. Combined with the low cost required to run it, Mixtral 8X22B is an excellent choice for fine-tuning scenarios.
Mixtral 8x22B passes standard industry benchmarks with flying colors. In most of the benchmarks, the emphasis was given on how well the model had performed compared to its main similar alternatives:
For example, Mixtral 8X22B is fluent in five languages: English, German, French, Spanish and Italian. The proof can be seen in the following table:
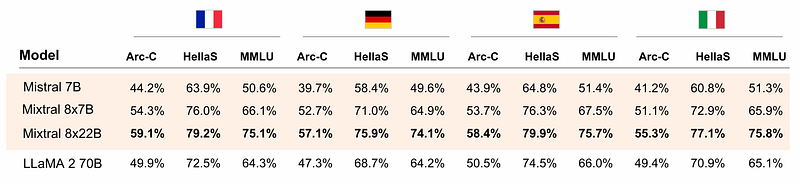
It beats Llama 2 70B on language tasks across three benchmarks:
As for pure common sense reasoning and knowledge questions in English, Mixtral performs admirably again:
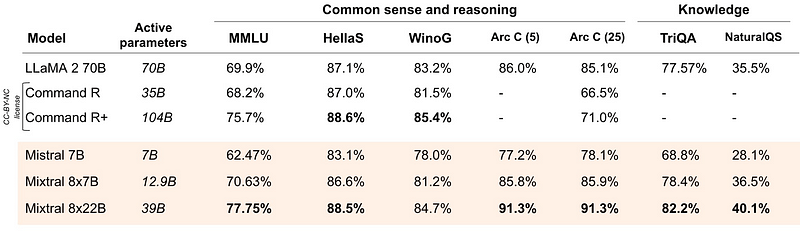
It is slightly worse than Command R+ in two benchmarks but in others, it is significantly better.
And its most defining point - Mixtral 8X22B crushes all its alternatives in math and coding tasks:
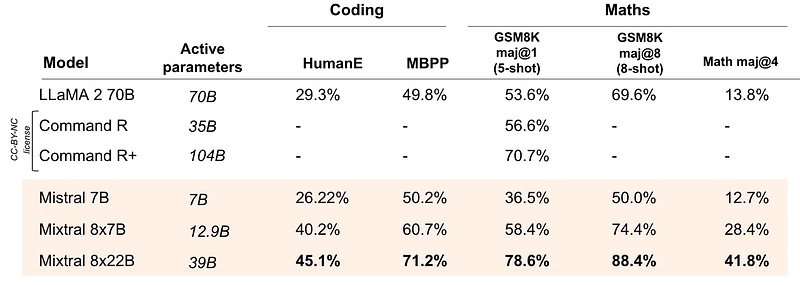
Now, let’s take a look at how the model achieves its state-of-the-art performance.
To understand the sparse mixture of experts (SMoE) architecture better, we will use a simple analogy. Let’s say 100 people are working on a project.
SMoE models have the following key components:
This type of model structure has many benefits:
However, since they are new, SMoE models present unique challenges that aren’t effectively tackled yet:
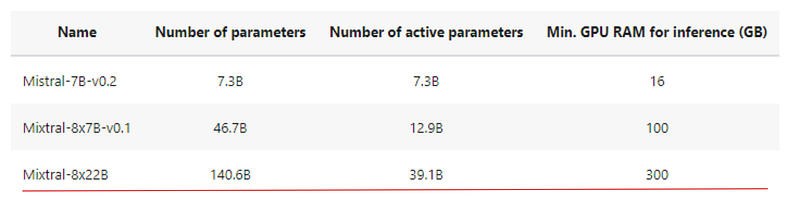
In summary, since the scale of the model is one of the most important factors for better model quality, reducing the number of active parameters makes models significantly cheaper and faster to train. Training a larger model for fewer steps is better than training a small model for more steps when the compute budget is constrained.
The mixture of experts architectures allows models to be trained with far less compute, which allows you to scale up model size dramatically under the same budget as a dense model. Any SMoE model should achieve the same quality as its dense counterpart much faster during pre-training.
In this section, we will learn how to start using the Mixtral 8X22B model using the Mistral API. Since the model is about 80 gigabytes in size and requires a 300 gigabyte GPU, it will be a bit hard and expensive to run it on any cloud provider, let alone on consumer hardware.
Mistral AI requires you to create an account and enter billing information to get your API key. So, please head over to mistral.ai to create your account. Once you log in with your credentials, you will be directed to your Mistral console at console.mistral.ai.
Next, head over to “Billing” and add your payment information:

Then, add some credits:
This will allow you to generate an API key from the “API KEYS” section:
When you create a key, it will be displayed only once, so save it somewhere safe. We will use it in the next section.
Now, let’s set up a virtual environment to run Mistral API. We will use Conda:
$ conda init # Run if your Conda executable is new
$ conda env create -n mistral python==3.8 -y
$ conda activate mistral
Then, we can install mistralai Python package along with a couple of other essentials:
$ pip install mistralai
$ pip install python-dotenv ipykernel
$ ipython kernel install --user --name=mistral
The last command adds the newly installed Conda environment as a Jupyter kernel.
We will use the python-dotenv package to safely read our Mistral API key from a notebook. To do so, create a .env file in your working directory:
$ touch .envThen, edit the file so that it lists your key in the following syntax:
MISTRAL_API_KEY=YOUR_KEY_HEREAlso, make sure to add the .env file to .gitignore so that it isn't accidentally leaked to GitHub:
$ echo ".env" >> .gitignore
Now, to read the key we just saved, we can use the load_dotenv function along with the os library:
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.getenv("MISTRAL_API_KEY")
Finally, to interact with any Mistral model, we will use the MistralClient object:
from mistralai.client import MistralClient
client = MistralClient(api_key=api_key)
The client requires our API key to connect to Mistral servers. Then, we will import the ChatMessage class to hold dialogues with Mistral models:
from mistralai.models.chat_completion import ChatMessage
model = "open-mixtral-8x22b"
message = "Who is the best French football player of all time?"
chat_response = client.chat(
model=model,
messages=[ChatMessage(role="user", content=message)],
)
print(chat_response.choices[0].message.content[:300])
Determining the "best" French football player of all time can be subjective and depends on personal opinion. However, one player who is often mentioned in this context is Zinedine Zidane. He had an impressive career both for the French national team and at club level. He was a key player in France'sWe got a response — so, everything is set up correctly.
A ChatResponse object usually holds more than one answer, so we are selecting the first one and printing a subtext.
Beyond plain text generation, you can do much more with Mixtral:
and so on. We will look at each of these scenarios one by one.
In the previous section, we were able to generate a large bulk of text from the chat client. In some cases, when we guess that the answer might be longer, it makes sense to stream the output just like in ChatGPT. We can do that with Mixtral too
messages = [ChatMessage(role="user", content="What led to Zidane's ban from football?")]
# With streaming
stream_response = client.chat_stream(model=model, messages=messages)
for chunk in stream_response:
print(chunk.choices[0].delta.content, end="")
Instead of the chat method, we can use chat_stream which gives the answer on demand, in chunks:
Embeddings are key components of LLM applications. An embedding is a vector representation of text that captures its semantic meaning through its position in a high-dimensional vector space. If the distance between two embeddings is close, that means they are similar in meaning. For example, the word apple will be closer to orange than it is to keyboard in the embedding space.
Mistral API offers state-of-the-art embedding models for text. Let’s briefly look at how they work:
to_embed = ["Is Messi better than Zidane?", "How about Ronaldo?"]
embeddings_batch_response = client.embeddings(
model="mistral-embed",
input=to_embed,
)
type(embeddings_batch_response)
mistralai.models.embeddings.EmbeddingResponse
First, we create a list of sentences to be embedded in to_embed. Then, we will pass them to embeddings method along with an embedding model name - mistral-embed. The result is an EmbeddingResponse object. When we print the length of its data attribute, we will see that it has two vectors for the two embedded sentences:
len(embeddings_batch_response.data)2We can also get the dimensions of the vectors:
first_sentence = embeddings_batch_response.data[0]
len(first_sentence.embedding) # Embedding dimension
1024We have got a result of 1024, which means Mistral embeds any text, regardless of its length, into a 1024-dimensional vector.
Note that higher dimensional embeddings might better capture text information and improve performance, but they require more compute for hosting and inference.
Although we didn’t use the Mixtral 8X22B model in the section, understanding embeddings will be important when we create a simple RAG pipeline.
As we stated earlier, if the distance between two embeddings is close, then they might be close in meaning. Extending this idea, we can build a primitive paraphrase detector because if the distance between two sentences is short, there is a chance they are paraphrases.
First, we will create a function that returns the embedding vector for a given input:
def get_text_embedding(input, client):
embeddings_batch_response = client.embeddings(
model="mistral-embed", input=input
)
return embeddings_batch_response.data[0].embedding
Then, we will define the list of sentences we want to check against each other for paraphrasing and get their embeddings:
sentences = [
"What led to Zidane's ban from football?",
"This is a totally different sentence.",
"What caused Zidane to get banned from football?",
]
sentence_embeddings = [get_text_embedding(t, client) for t in sentences]
Then, we will create all possible two-pair combinations of the sentences using itertools:
import itertools
sentence_embeddings_pairs = list(itertools.combinations(sentence_embeddings, 2))
sentence_pairs = list(itertools.combinations(sentences, 2))
print(sentence_pairs[0])
("What led to Zidane's ban from football?", 'This is a totally different sentence.')Then, we will print the Euclidean distance between each sentence embedding pair and print the results:
from sklearn.metrics.pairwise import euclidean_distances
for s, e in zip(sentence_pairs, sentence_embeddings_pairs):
distance = euclidean_distances([e[0]], [e[1]])
print(s, distance)
("What led to Zidane's ban from football?", 'This is a totally different sentence.') [[0.84503319]]
("What led to Zidane's ban from football?", 'What caused Zidane to get banned from football?') [[0.28662641]]
('This is a totally different sentence.', 'What caused Zidane to get banned from football?') [[0.83794058]]
The distance between the second pair is close, which indicates they might be paraphrases of each other.
LLMs are trained on mounds and mounds of data, but they aren’t always up-to-date and don’t have access to your private datasets. Fine-tuning them is too expensive if you just want the model to answer questions on other existing datasets.
That’s why Retrieval Augmented Generation (RAG) pipelines have surged in popularity. Without costly fine-tuning, you can teach an LLM to process custom information that wasn’t part of its training and answer questions about it.
In this section, we will build a basic RAG pipeline that learns the information from yesterday’s news in this 1440 article. I’ve saved part of the news to this text file, which you can download from my GitHub or just copy/paste and save into a file named news_piece.txt.
To read the contents of the file, we can use the pathlib library:
from pathlib import Path
file = Path("news_piece.txt")
text = file.read_text()
Then, we will split the document into chunks as RAG systems perform better when text is in chunks. In this example, we will split the text into chunks of 512 characters each:
chunk_size = 512
chunks = [text[i : i + chunk_size] for i in range(0, len(text), chunk_size)]
len(chunks)
4Then, we will get the embeddings of each chunk using the get_text_embedding function from the last section:
text_embeddings = np.array([get_text_embedding(chunk, client) for chunk in chunks])Next, it is common practice to store embeddings in a vector database for efficient processing and retrieval. There are many options out there for vector databases. We will use faiss - an open-source database for similarity search.
import faiss # pip install faiss
d = text_embeddings.shape[1]
index = faiss.IndexFlatL2(d)
index.add(text_embeddings)
index is an instance of an Index class, which defines the structure of our database. d is for the dimension of the embedding space.
Running the add method adds the information from our document to the vector database, which means we can ask questions about it. But before we do that, any questions we have must be converted to an embedding as well:
import numpy as np
questions = [
"How much is Microsoft going to spend for its new data center?",
"When did FTX collapse?",
]
question_embeddings = np.array([get_text_embedding(q, client) for q in questions])
Then, we can feed the question_embeddings array to the search method of the Index object:
D, I = index.search(question_embeddings, k=4) # distance, index
retrieved_chunk = [chunks[i] for i in I.tolist()[0]]
The search method returns the vectors that most likely hold the answer to our questions (using similarity search):
len(retrieved_chunk)
4print(retrieved_chunk[2])
ay defrauded investors in full and provide the vast majority with interest. The failed cryptocurrency exchange platform filed its proposal late Tuesday to a federal bankruptcy court for approval.
Since FTX collapsed in 2022, CEO John Ray III (see previous write-up) has worked to track down more than $8B in missing assets to repay an estimated $11.2B owed to creditors. This week, Ray said the company has recovered between $14.5B and $16.3B, with much of the funds tied to government-seized FTX properties or
Now, we can pass this text as context for the Mixtral 8X22B model and ask our questions about it. Let’s build the prompt:
prompt = f"""
Context information is below.
---------------------
{retrieved_chunk}
---------------------
Given the context information and not prior knowledge, answer the query.
Query: {questions}
Answer:
"""
Now, we can pass it to the model using the client:
chat_response = client.chat(
model=model, # Mixtral 8x22B
messages=[ChatMessage(role="user", content=prompt)],
)
print(chat_response.choices[0].message.content)
Microsoft will spend $3 billion for its new data center in Racine, Wisconsin. FTX collapsed in 2022.
The answers are correct!
We’ve built a very basic RAG pipeline. In practice, RAG pipelines are very powerful — they can handle a variety of inputs (text, image, audio, video) and can work on a massive scale as compared to our version that handled a single text file.
If you want to learn how to build powerful RAG pipelines, check out our How to Build LLM Applications with LangChain Tutorial.
One of the native capabilities of the Mixtral 8X22B model is function calling. In the context of LLMs, function calling is a technique that allows LLMs to understand and respond to prompts in a way that triggers the execution of specific functions. Here’s a breakdown of what that means:
Demonstrating how function calling works is beyond the scope of this article. However, you can check out this page of Mistral AI docs to see it in action.
In this article, we have learned about the Mixtral 8X22B model released by Mistral AI in April 2024. Due to its architectural advantages, it is now one of the leading open-source LLMs, beating popular models such as Llama 2 and Command R+ across many benchmarks.
Apart from its architecture details, we have learned how to use it in a few practical scenarios, such as text generation, paraphrase detection, and creating a RAG pipeline. If you want to unlock the Mixtral 8X22B model’s full potential, check out these related resources:
Continue Your AI Learning Journey Today!
Kurs
Kurs
Kurs
Blog
Zoumana Keita
13 Min.
Blog
Ryan Ong
8 Min.
Blog
Nisha Arya Ahmed
12 Min.
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
code-along
Josep Ferrer



