Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
100K
Quando a OpenAI lançou o ChatGPT em 2022, muitos se perguntaram se outras empresas poderiam competir com um produto tão bom apoiado por um gigante como a Microsoft. Quando todos já estavam concentrados em outras grandes empresas de tecnologia, como Google e Meta, surgiu a Mistral AI com seu modelo de 7B em 2023, que superou todos os LLMs de código aberto com quase o dobro do tamanho.
Desde então, a Mistral AI se tornou uma grande participante na corrida do LLM. Em abril de 2024, eles lançaram o Mixtral 8X22B, um modelo que superou facilmente o melhor LLM de código aberto da época, o Llama 2, em muitos benchmarks.
Neste tutorial, discutiremos o modelo Mixtral 8X22B em detalhes, desde sua arquitetura até a configuração de um pipeline RAG com ele.
O Mixtral 8X22B é o modelo mais recente lançado pela Mistral AI. Ele conta com uma arquitetura de mistura esparsa de especialistas (SMoE) com 141 bilhões de parâmetros. É essa arquitetura SMoE que oferece muitas de suas vantagens. O SMoE é um tipo de rede neural que usa diferentes modelos menores (especialistas) para diferentes tarefas, ativando apenas os necessários para economizar tempo e poder de computação.
Em primeiro lugar, o modelo oferece uma eficiência de custo inigualável para seu tamanho, proporcionando a melhor relação desempenho/custo na comunidade de código aberto:
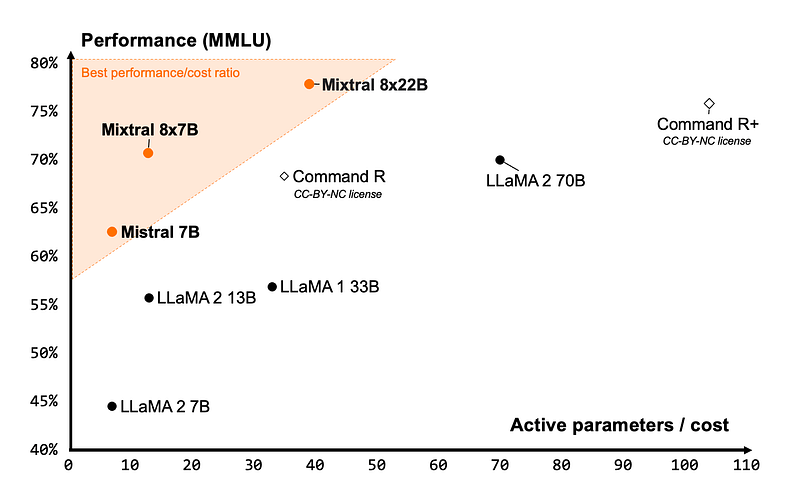
A imagem acima apresenta alguns dos principais LLMs de código aberto e o número de parâmetros ativos que eles exigem para atingir um determinado limite de desempenho. O Mixtral está bem no canto superior esquerdo, o que significa que ele usa significativamente menos parâmetros para atingir um desempenho de +75% do que um modelo no mesmo nível - Command R+.
Embora o Mixtral 8X22B tenha 141 bilhões de parâmetros, seu padrão de ativação esparso usa apenas 39 bilhões de parâmetros durante a inferência. Isso o torna mais rápido e de alto desempenho do que qualquer modelo com 70 bilhões de parâmetros, como o Llama 2 70B. Ele também apresenta uma janela de contexto de 64k-token, o que é muito raro nos LLMs de código aberto atuais.
O modelo também vem com a licença de código aberto mais permissiva - Apache 2.0. Combinado com o baixo custo necessário para operá-lo, o Mixtral 8X22B é uma excelente opção para cenários de ajuste fino.
O Mixtral 8x22B supera com louvor os padrões de referência do setor. Na maioria dos benchmarks, a ênfase foi dada ao desempenho do modelo em comparação com suas principais alternativas semelhantes:
Por exemplo, o Mixtral 8X22B é fluente em cinco idiomas: Inglês, alemão, francês, espanhol e italiano. A prova pode ser vista na tabela a seguir:
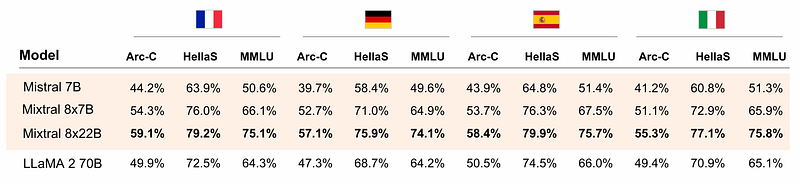
Ele supera o Llama 2 70B em tarefas de linguagem em três benchmarks:
Quanto ao raciocínio de senso comum puro e às perguntas de conhecimento em inglês, o Mixtral teve um desempenho admirável novamente:
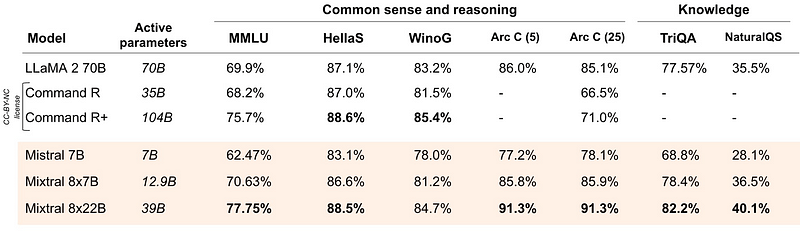
Ele é um pouco pior que o Command R+ em dois benchmarks, mas em outros é significativamente melhor.
E seu ponto mais marcante - o Mixtral 8X22B supera todas as suas alternativas em tarefas de matemática e codificação:
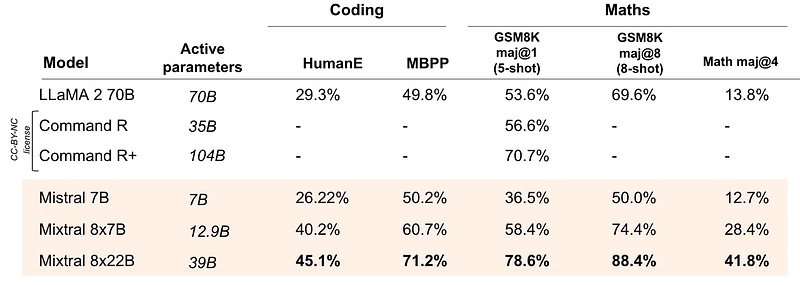
Agora, vamos dar uma olhada em como o modelo atinge seu desempenho de última geração.
Para entender melhor a arquitetura da mistura esparsa de especialistas (SMoE), usaremos uma analogia simples. Digamos que 100 pessoas estejam trabalhando em um projeto.
Os modelos SMoE têm os seguintes componentes principais:
Esse tipo de estrutura de modelo tem muitos benefícios:
No entanto, como são novos, os modelos de SMoE apresentam desafios únicos que ainda não foram abordados com eficácia:
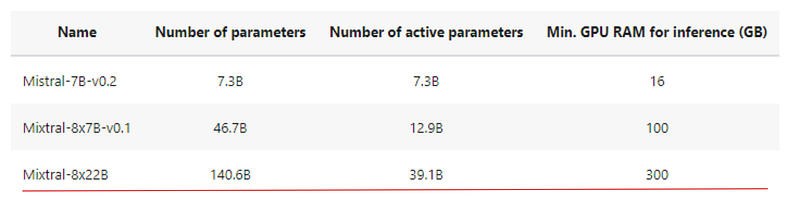
Em resumo, como a escala do modelo é um dos fatores mais importantes para melhorar a qualidade do modelo, a redução do número de parâmetros ativos torna os modelos significativamente mais baratos e mais rápidos de treinar. Treinar um modelo maior para menos etapas é melhor do que treinar um modelo pequeno para mais etapas quando o orçamento de computação é limitado.
A mistura de arquiteturas de especialistas permite que os modelos sejam treinados com muito menos computação, o que permite que você aumente drasticamente o tamanho do modelo com o mesmo orçamento de um modelo denso. Qualquer modelo SMoE deve atingir a mesma qualidade de sua contraparte densa muito mais rapidamente durante o pré-treinamento.
Nesta seção, aprenderemos como começar a usar o modelo Mixtral 8X22B usando a API Mistral. Como o modelo tem cerca de 80 gigabytes de tamanho e requer uma GPU de 300 gigabytes, será um pouco difícil e caro executá-lo em qualquer provedor de nuvem, muito menos no hardware do consumidor.
A Mistral AI exige que você crie uma conta e insira informações de faturamento para obter sua chave de API. Portanto, acesse mistral.ai para criar sua conta. Depois de fazer login com suas credenciais, você será direcionado para o console da Mistral em console.mistral.ai.
Em seguida, vá para "Billing" (Faturamento) e adicione suas informações de pagamento:

Em seguida, adicione alguns créditos:
Isso permitirá que você gere uma chave de API na seção "CHAVES DE API":
Quando você criar uma chave, ela será exibida apenas uma vez, portanto, salve-a em um local seguro. Vamos usá-lo na próxima seção.
Agora, vamos configurar um ambiente virtual para executar a API Mistral. Usaremos o Conda:
$ conda init # Run if your Conda executable is new
$ conda env create -n mistral python==3.8 -y
$ conda activate mistral
Em seguida, podemos instalar o pacote mistralai Python junto com alguns outros itens essenciais:
$ pip install mistralai
$ pip install python-dotenv ipykernel
$ ipython kernel install --user --name=mistral
O último comando adiciona o ambiente Conda recém-instalado como um kernel Jupyter.
Usaremos o pacote Python-dotenv para ler com segurança nossa chave de API Mistral de um notebook. Para isso, crie um arquivo .env em seu diretório de trabalho:
$ touch .envEm seguida, edite o arquivo para que ele liste sua chave na seguinte sintaxe:
MISTRAL_API_KEY=YOUR_KEY_HEREAlém disso, certifique-se de adicionar o arquivo .env a .gitignore para que ele não vaze acidentalmente para o GitHub:
$ echo ".env" >> .gitignore
Agora, para ler a chave que acabamos de salvar, podemos usar a função load_dotenv junto com a biblioteca os:
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.getenv("MISTRAL_API_KEY")
Por fim, para interagir com qualquer modelo Mistral, usaremos o objeto MistralClient:
from mistralai.client import MistralClient
client = MistralClient(api_key=api_key)
O cliente requer nossa chave de API para se conectar aos servidores da Mistral. Em seguida, importaremos a classe ChatMessage para manter diálogos com os modelos Mistral:
from mistralai.models.chat_completion import ChatMessage
model = "open-mixtral-8x22b"
message = "Who is the best French football player of all time?"
chat_response = client.chat(
model=model,
messages=[ChatMessage(role="user", content=message)],
)
print(chat_response.choices[0].message.content[:300])
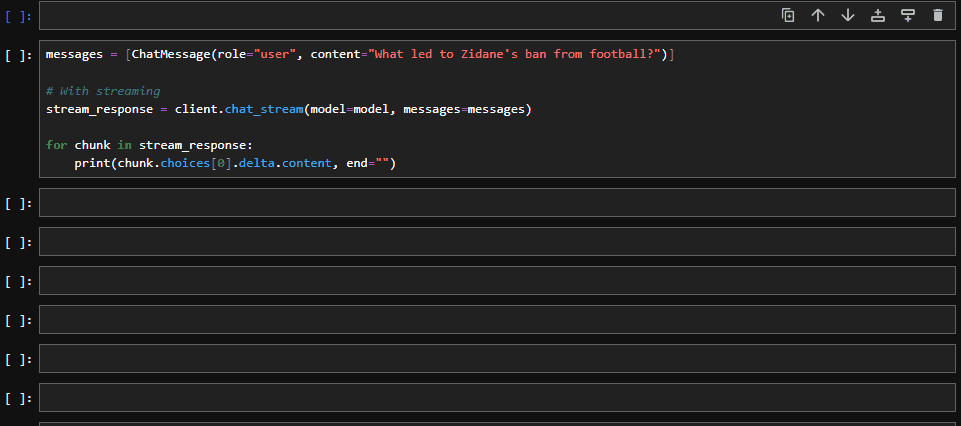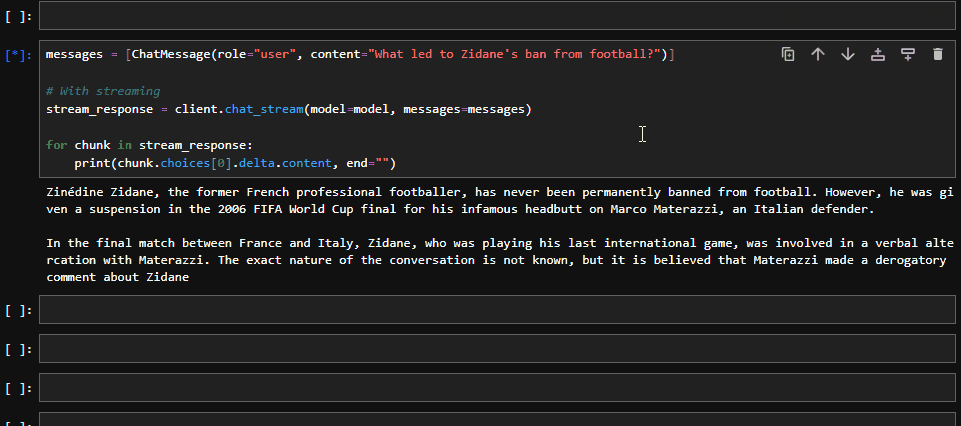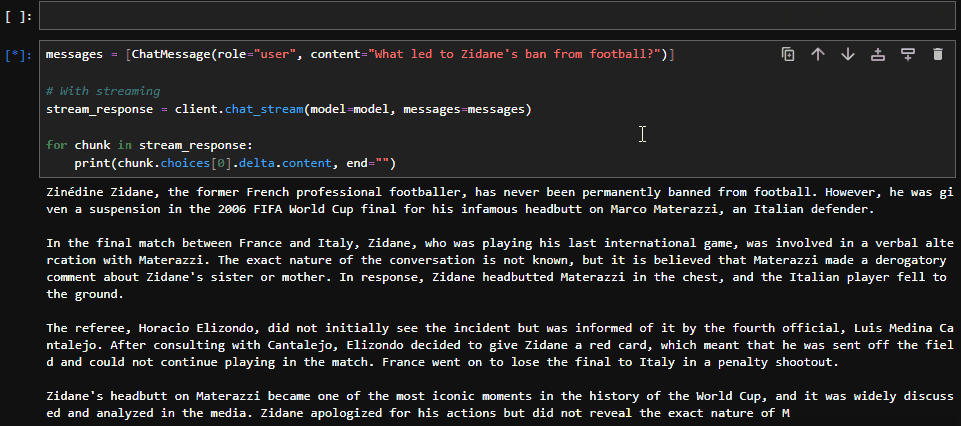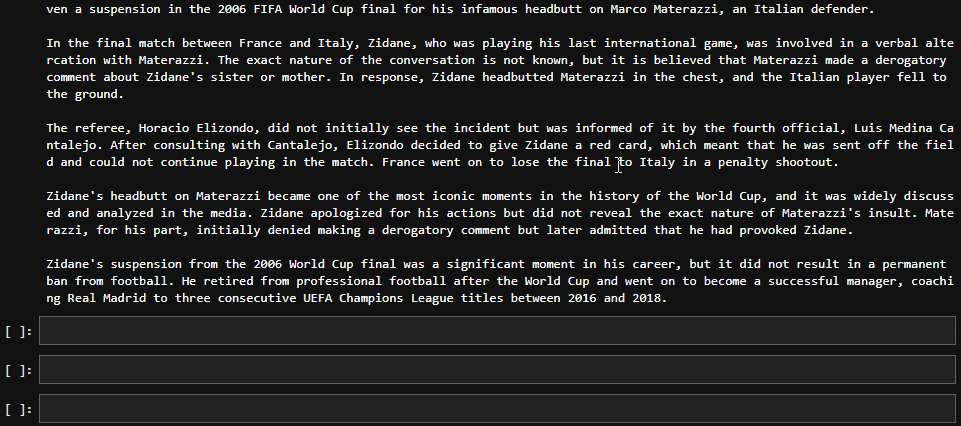
Determining the "best" French football player of all time can be subjective and depends on personal opinion. However, one player who is often mentioned in this context is Zinedine Zidane. He had an impressive career both for the French national team and at club level. He was a key player in France'sRecebemos uma resposta - portanto, tudo está configurado corretamente.
Um objeto ChatResponse geralmente contém mais de uma resposta, portanto, estamos selecionando a primeira e imprimindo um subtexto.
Além da geração de texto simples, você pode fazer muito mais com o Mixtral:
e assim por diante. Examinaremos cada um desses cenários, um a um.
Na seção anterior, conseguimos gerar um grande volume de texto a partir do cliente de bate-papo. Em alguns casos, quando você acha que a resposta pode ser mais longa, faz sentido transmitir a saída como no ChatGPT. Você também pode fazer isso com o Mixtral
messages = [ChatMessage(role="user", content="What led to Zidane's ban from football?")]
# With streaming
stream_response = client.chat_stream(model=model, messages=messages)
for chunk in stream_response:
print(chunk.choices[0].delta.content, end="")
Em vez do método chat, podemos usar o chat_stream, que fornece a resposta sob demanda, em partes:
Os embeddings são componentes essenciais dos aplicativos LLM. Uma incorporação é uma representação vetorial do texto que captura seu significado semântico por meio de sua posição em um espaço vetorial de alta dimensão. Se a distância entre duas incorporações for próxima, isso significa que elas são semelhantes em termos de significado. Por exemplo, a palavra maçã estará mais próxima de laranja do que de teclado no espaço de incorporação.
A API Mistral oferece modelos de incorporação de última geração para texto. Vamos dar uma breve olhada em como eles funcionam:
to_embed = ["Is Messi better than Zidane?", "How about Ronaldo?"]
embeddings_batch_response = client.embeddings(
model="mistral-embed",
input=to_embed,
)
type(embeddings_batch_response)
mistralai.models.embeddings.EmbeddingResponse
Primeiro, criamos uma lista de frases a serem incorporadas em to_embed. Em seguida, você os passará para o método embeddings juntamente com um nome de modelo de incorporação - mistral-embed. O resultado é um objeto EmbeddingResponse. Quando imprimirmos o comprimento de seu atributo data, veremos que ele tem dois vetores para as duas frases incorporadas:
len(embeddings_batch_response.data)2Também podemos obter as dimensões dos vetores:
first_sentence = embeddings_batch_response.data[0]
len(first_sentence.embedding) # Embedding dimension
1024Obtivemos um resultado de 1024, o que significa que o Mistral incorpora qualquer texto, independentemente de seu comprimento, em um vetor de 1024 dimensões.
Observe que os embeddings de maior dimensão podem capturar melhor as informações do texto e melhorar o desempenho, mas exigem mais computação para hospedagem e inferência.
Embora não tenhamos usado o modelo Mixtral 8X22B na seção, a compreensão dos embeddings será importante quando criarmos um pipeline RAG simples.
Como dissemos anteriormente, se a distância entre duas incorporações for próxima, então elas podem ter um significado próximo. Ampliando essa ideia, podemos criar um detector de paráfrase primitivo porque, se a distância entre duas frases for pequena, há uma chance de que sejam paráfrases.
Primeiro, criaremos uma função que retorna o vetor de incorporação para uma determinada entrada:
def get_text_embedding(input, client):
embeddings_batch_response = client.embeddings(
model="mistral-embed", input=input
)
return embeddings_batch_response.data[0].embedding
Em seguida, definiremos a lista de frases que queremos comparar entre si para parafrasear e obter seus embeddings:
sentences = [
"What led to Zidane's ban from football?",
"This is a totally different sentence.",
"What caused Zidane to get banned from football?",
]
sentence_embeddings = [get_text_embedding(t, client) for t in sentences]
Em seguida, criaremos todas as combinações possíveis de dois pares de frases usando itertools:
import itertools
sentence_embeddings_pairs = list(itertools.combinations(sentence_embeddings, 2))
sentence_pairs = list(itertools.combinations(sentences, 2))
print(sentence_pairs[0])
("What led to Zidane's ban from football?", 'This is a totally different sentence.')Em seguida, imprimiremos a distância euclidiana entre cada par de incorporação de frases e imprimiremos os resultados:
from sklearn.metrics.pairwise import euclidean_distances
for s, e in zip(sentence_pairs, sentence_embeddings_pairs):
distance = euclidean_distances([e[0]], [e[1]])
print(s, distance)
("What led to Zidane's ban from football?", 'This is a totally different sentence.') [[0.84503319]]
("What led to Zidane's ban from football?", 'What caused Zidane to get banned from football?') [[0.28662641]]
('This is a totally different sentence.', 'What caused Zidane to get banned from football?') [[0.83794058]]
A distância entre o segundo par é pequena, o que indica que eles podem ser paráfrases um do outro.
Os LLMs são treinados com base em muitos dados, mas nem sempre estão atualizados e não têm acesso aos seus conjuntos de dados privados. O ajuste fino deles é muito caro se você quiser apenas que o modelo responda a perguntas sobre outros conjuntos de dados existentes.
É por isso que os pipelines RAG (Retrieval Augmented Generation ) ganharam popularidade. Sem um ajuste fino dispendioso, você pode ensinar um LLM a processar informações personalizadas que não faziam parte de seu treinamento e responder a perguntas sobre elas.
Nesta seção, criaremos um pipeline RAG básico que aprende as informações das notícias de ontem neste artigo do 1440. Salvei parte das notícias neste arquivo de texto, que você pode baixar do meu GitHub ou simplesmente copiar/colar e salvar em um arquivo chamado news_piece.txt.
Para ler o conteúdo do arquivo, podemos usar a biblioteca pathlib:
from pathlib import Path
file = Path("news_piece.txt")
text = file.read_text()
Em seguida, dividiremos o documento em partes, pois os sistemas RAG têm melhor desempenho quando o texto está em partes. Neste exemplo, dividiremos o texto em partes de 512 caracteres cada:
chunk_size = 512
chunks = [text[i : i + chunk_size] for i in range(0, len(text), chunk_size)]
len(chunks)
4Em seguida, obteremos os embeddings de cada pedaço usando a função get_text_embedding da última seção:
text_embeddings = np.array([get_text_embedding(chunk, client) for chunk in chunks])Em seguida, é prática comum armazenar embeddings em um banco de dados vetorial para processamento e recuperação eficientes. Há muitas opções disponíveis para bancos de dados vetoriais. Usaremos o faiss, um banco de dados de código aberto para pesquisa de similaridade.
import faiss # pip install faiss
d = text_embeddings.shape[1]
index = faiss.IndexFlatL2(d)
index.add(text_embeddings)
index é uma instância de uma classe Index, que define a estrutura do nosso banco de dados. d é a dimensão do espaço de incorporação.
A execução do método add adiciona as informações do nosso documento ao banco de dados de vetores, o que significa que podemos fazer perguntas sobre ele. Mas, antes de fazer isso, todas as perguntas que temos devem ser convertidas em uma incorporação também:
import numpy as np
questions = [
"How much is Microsoft going to spend for its new data center?",
"When did FTX collapse?",
]
question_embeddings = np.array([get_text_embedding(q, client) for q in questions])
Em seguida, podemos alimentar a matriz question_embeddings com o método search do objeto Index:
D, I = index.search(question_embeddings, k=4) # distance, index
retrieved_chunk = [chunks[i] for i in I.tolist()[0]]
O método search retorna os vetores que mais provavelmente contêm a resposta às nossas perguntas (usando a pesquisa de similaridade):
len(retrieved_chunk)
4print(retrieved_chunk[2])
ay defrauded investors in full and provide the vast majority with interest. The failed cryptocurrency exchange platform filed its proposal late Tuesday to a federal bankruptcy court for approval.
Since FTX collapsed in 2022, CEO John Ray III (see previous write-up) has worked to track down more than $8B in missing assets to repay an estimated $11.2B owed to creditors. This week, Ray said the company has recovered between $14.5B and $16.3B, with much of the funds tied to government-seized FTX properties or
Agora, podemos passar esse texto como contexto para o modelo Mixtral 8X22B e fazer nossas perguntas sobre ele. Vamos criar o prompt:
prompt = f"""
Context information is below.
---------------------
{retrieved_chunk}
---------------------
Given the context information and not prior knowledge, answer the query.
Query: {questions}
Answer:
"""
Agora, podemos passá-lo para o modelo usando o client:
chat_response = client.chat(
model=model, # Mixtral 8x22B
messages=[ChatMessage(role="user", content=prompt)],
)
print(chat_response.choices[0].message.content)
Microsoft will spend $3 billion for its new data center in Racine, Wisconsin. FTX collapsed in 2022.
As respostas estão corretas!
Criamos um pipeline RAG muito básico. Na prática, os pipelines RAG são muito avançados, pois podem lidar com uma variedade de entradas (texto, imagem, áudio, vídeo) e trabalhar em grande escala, em comparação com a nossa versão que lidava com um único arquivo de texto.
Se você quiser saber como criar pipelines RAG avançados, confira nosso tutorial Como criar aplicativos LLM com LangChain.
Um dos recursos nativos do modelo Mixtral 8X22B é a chamada de função. No contexto dos LLMs, a chamada de função é uma técnica que permite que os LLMs entendam e respondam aos prompts de forma a acionar a execução de funções específicas. Aqui está um detalhamento do que isso significa:
Demonstrar como funciona a chamada de função está além do escopo deste artigo. No entanto, você pode conferir esta página de documentos do Mistral AI para vê-lo em ação.
Neste artigo, aprendemos sobre o modelo Mixtral 8X22B lançado pela Mistral AI em abril de 2024. Devido às suas vantagens arquitetônicas, ele é agora um dos principais LLMs de código aberto, superando modelos populares como o Llama 2 e o Command R+ em muitos benchmarks.
Além dos detalhes de sua arquitetura, aprendemos a usá-lo em alguns cenários práticos, como geração de texto, detecção de paráfrase e criação de um pipeline RAG. Se você quiser desbloquear todo o potencial do modelo Mixtral 8X22B, confira estes recursos relacionados:
Continue sua jornada de aprendizado de IA hoje mesmo!
Curso
Curso
Curso
blog
Ryan Ong
8 min
blog
Javier Canales Luna
8 min
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Dimitri Didmanidze
Tutorial
Zoumana Keita

