
Programa
Desenvolvimento de aplicativos de IA
21 h
O o4-mini da OpenAI é a mais recente adição à série o de modelos de IA com foco em raciocínio. Neste tutorial, mostrarei a você como criar umrevisor de artigos de pesquisa usando a API o4-mini da OpenAI. A ferramenta irá:
Também aprimoraremos nosso assistente de revisão com suporte a ferramentas estatísticas, para que o modelo possa calcular valores de p, tamanhos de efeito e intervalos de confiança sob demanda.
Mantemos nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito de sexta-feira que detalha as principais histórias da semana. Inscreva-se e fique atento em apenas alguns minutos por semana:
O o4-mini da OpenAI é um modelo de raciocínio econômico e de alto desempenho capaz de realizar análises profundas em tarefas como codificação, matemática e raciocínio científico. Apesar de ser menor que o o3 ele alcança consistentemente resultados de última geração em benchmarks como AIME 2024/2025 e GPQA.
Graças à sua velocidade e preço acessível, ele é ideal para tarefas como revisão de artigos de pesquisa, geração de explicações de código ou auxílio em questões de matemática para concursos. Seus principais pontos fortes são:
Para saber mais, confira este blog introdutório sobre o4-mini.
Criaremos um revisor de artigos de pesquisa com base em Python que pode ajudar você a entender o que está acontecendo:
Esse projeto é totalmente local e usa a API da OpenAI.
Para usar o o4-mini, você precisará de uma chave de API da OpenAI. Veja como:
Agora, você está pronto para se autenticar e começar a chamar a API do Python.
Vamos começar com a instalação de algumas dependências e a configuração de uma variável de ambiente variável de ambiente para nossa chave de API.
pip install openai PyMuPDF tiktoken numpy
export OPENAI_API_KEY =” YOUR_KEY”Agora que nossas dependências estão organizadas, vamos passar para as funções auxiliares. Essas funções são invocadas pelo LLM usando chamadas de ferramentas quando necessário.
Essas importações são usadas para calcular testes t, erros padrão e intervalos de confiança.
from scipy.stats import ttest_ind, sem, t
import numpy as npEssa função executa o teste t de Welch entre dois grupos de amostras independentes. Ele testa a hipótese de que as médias dos dois grupos são estatisticamente diferentes.
def recalculate_p_value(group1, group2):
t_stat, p_value = ttest_ind(group1, group2, equal_var=False)
return {"p_value": round(p_value, 4)}A função recalculate_p_value() retorna o valor p, arredondado para quatro casas decimais, que indica a probabilidade de a diferença observada ter ocorrido por acaso. Isso ajuda o LLM a validar as afirmações de significância estatística no trabalho de pesquisa.
O d de Cohen é uma medida padronizada do tamanho do efeito entre dois grupos. Você começa calculando as médias e os desvios padrão de cada grupo. Em seguida, ele usa o desvio padrão agrupado para normalizar a diferença entre as médias.
def compute_cohens_d(group1, group2):
mean1, mean2 = np.mean(group1), np.mean(group2)
std1, std2 = np.std(group1, ddof=1), np.std(group2, ddof=1)
pooled_std = np.sqrt((std1**2 + std2**2) / 2)
d = (mean1 - mean2) / pooled_std
return {"cohens_d": round(d, 4)}A função retorna o valor d de Cohen, arredondado para quatro casas decimais. Isso ajuda o LLM a entender a importância prática (não apenas estatística) das diferenças de grupo. Ele é valioso principalmente quando o tamanho da amostra é grande e os valores de p sozinhos não são informativos.
Agora definimos um auxiliar para calcular o intervalo de confiança para um único grupo de amostras. Os intervalos de confiança são úteis para entender a confiabilidade de uma média estimada - em outras palavras, o grau de incerteza que cerca o valor médio.
def compute_confidence_interval(data, confidence=0.95):
data = np.array(data)
n = len(data)
mean = np.mean(data)
margin = sem(data) * t.ppf((1 + confidence) / 2., n-1)
return {
"mean": round(mean, 4),
"confidence_interval": [round(mean - margin, 4), round(mean + margin, 4)],
"confidence": confidence
}Aqui está o que essa função retorna:
mean: O valor médio dos dados de entrada.confidence_interval: Uma lista que representa os limites inferior e superior dentro dos quais a média verdadeira provavelmente se enquadra, com base no nível de confiança especificado.confidence: O nível de confiança usado para o intervalo.Concluímos as funções auxiliares com um auxiliar simples que resume a média, o desvio padrão e o tamanho da amostra.
def describe_group(data):
data = np.array(data)
return {
"mean": round(np.mean(data), 4),
"std_dev": round(np.std(data, ddof=1), 4),
"n": len(data)
}Isso ajuda o LLM a interpretar a distribuição de dados subjacente, fornecendo um contexto essencial para a avaliação dos resultados. Ao expor descritores estatísticos como média, desvio padrão e contagem, nossas ferramentas auxiliares fortalecem a capacidade do modelo de raciocinar por meio de experimentos e afirmações encontradas em artigos de pesquisa.
Nesta seção, criaremos o revisor de artigos de pesquisa baseado em Python que usa a API o4-mini da OpenAI e inclui suporte de ferramentas para análise estatística, permitindo que o modelo realize avaliações rigorosas e críticas com base em dados.
Iniciamos nosso código principal com algumas bibliotecas essenciais para extrair o conteúdo do PDF, tokenizá-lo e conversar com a API da OpenAI.
import os
import fitz
import openai
import json
import tiktoken
from statistics_helper import (
recalculate_p_value,
compute_cohens_d,
compute_confidence_interval,
describe_group
)
openai.api_key = os.getenv("OPENAI_API_KEY")Agora, vamos criar o pipeline completo passo a passo.
Começamos com a leitura do texto bruto do trabalho de pesquisa. A biblioteca fitz nos permite iterar em todas as páginas e concatenar o texto extraído em uma única string.
def extract_text_from_pdf(path):
doc = fitz.open(path)
full_text = "\n".join(page.get_text() for page in doc)
return full_textIsso estabelece a base. Agora, vamos tokenizar e dividir o texto bruto em partes antes de enviá-lo ao modelo.
Observação: Eu gerei um artigo de pesquisa falso para fins de demonstração que contém intencionalmente falhas na lógica e no projeto experimental.
Os LLMs têm limites de contexto, portanto, dividimos documentos longos em partes gerenciáveis. Usamos o Tiktoken para tokenizar o texto com base no esquema de codificação do modelo.
def chunk_text(text, max_tokens=12000, model="o4-mini"):
encoding = tiktoken.get_encoding("cl100k_base")
tokens = encoding.encode(text)
chunks = []
for i in range(0, len(tokens), max_tokens):
chunk = tokens[i:i + max_tokens]
chunk_text = encoding.decode(chunk)
chunks.append(chunk_text)
return chunksVeja como isso funciona:
tiktoken para tokenizar o texto completo do documento usando o cl100k_base tokenizer, que é compatível com os modelos modernos da OpenAI, como GPT-4, GPT-4o e o4-mini.max_tokens comprimento. Isso garante que cada bloco permaneça dentro do tamanho máximo de entrada permitido pelo modelo, o que é essencial para evitar erros de estouro de token durante a inferência.encoding.decode(). Isso preserva o fraseado e a formatação naturais para que o modelo receba um contexto coerente durante o processamento.Essa etapa de fragmentação é essencial para evitar erros de corte durante a inferência e garante que nenhum texto importante seja descartado devido ao estouro.
Antes que o modelo possa invocar qualquer função externa, precisamos definir um mapeamento entre os nomes das funções (conforme visto pelo modelo) e as funções Python reais que serão executadas. Esse mapeamento funciona como uma ponte entre as chamadas de ferramentas do modelo e nossa base de código local.
tool_function_map = {
"recalculate_p_value": recalculate_p_value,
"compute_cohens_d": compute_cohens_d,
"compute_confidence_interval": compute_confidence_interval,
"describe_group": describe_group,
}Cada chave nesse dicionário corresponde a um nome de função que o modelo pode referenciar durante a invocação da ferramenta, e cada valor é a função Python real importada do módulo statistics_helper.
Para aprimorar o raciocínio do modelo, registramos ferramentas que o LLM pode chamar por meio de chamada de função. Essas ferramentas lidam com análises estatísticas, como recálculo do valor p, intervalos de confiança e tamanhos de efeito.
tools = [
{
"type": "function",
"name": "recalculate_p_value",
"description": "Calculate p-value between two sample groups",
"parameters": {
"type": "object",
"properties": {
"group1": {"type": "array", "items": {"type": "number"}},
"group2": {"type": "array", "items": {"type": "number"}}
},
"required": ["group1", "group2"]
}
},
{
"type": "function",
"name": "compute_cohens_d",
"description": "Compute effect size (Cohen's d) between two groups",
"parameters": {
"type": "object",
"properties": {
"group1": {"type": "array", "items": {"type": "number"}},
"group2": {"type": "array", "items": {"type": "number"}}
},
"required": ["group1", "group2"]
}
},
{
"type": "function",
"name": "compute_confidence_interval",
"description": "Compute confidence interval for a sample group",
"parameters": {
"type": "object",
"properties": {
"data": {"type": "array", "items": {"type": "number"}},
"confidence": {"type": "number", "default": 0.95}
},
"required": ["data"]
}
},
{
"type": "function",
"name": "describe_group",
"description": "Summarize sample mean, std deviation, and count",
"parameters": {
"type": "object",
"properties": {
"data": {"type": "array", "items": {"type": "number"}}
},
"required": ["data"]
}
}
]A definição de ferramenta acima permite que o LLM compreenda:
description)name)O LLM decide de forma inteligente quando invocar uma ferramenta, como recalcular um valor de p, com base no contexto da análise. Ao encontrar uma afirmação estatística ou um resultado questionável, ele pode chamar a função auxiliar apropriada, receber o resultado e continuar seu raciocínio usando esse resultado. Isso permite uma análise mais rigorosa e fundamentada, em que o modelo não apenas critica, mas também verifica os dados subjacentes.
Agora definimos a lógica central que envia cada bloco de texto para o modelo o4-mini. Se ele chamar uma ferramenta, nós tratamos a chamada da função e continuamos a conversa.
def review_text_chunk(chunk):
try:
response = client.responses.create(
model="o4-mini",
reasoning={"effort": "high"},
input=[
{
"role": "system",
"content": (
"You are an expert AI research reviewer. Read the given chunk of a research paper and highlight weak arguments."
"unsupported claims, or flawed methodology. You can request tools to: Recalculate p-values, Compute confidence intervals, "
"Estimate effect size (Cohen's d), Describe sample statistics. Be rigorous and explain your reasoning. "
"Conclude with suggestions and a verdict."
)
},
{
"role": "user",
"content": chunk
}
],
tools = tools,
)
# Check for tool calls
for item in response.output:
if getattr(item, "type", None) == "function_call":
fn_call = getattr(item, "function_call", {})
fn_name = getattr(fn_call, "name", "")
args = getattr(fn_call, "arguments", {})
if fn_name in tool_function_map:
tool_result = tool_function_map[fn_name](**args)
# Send back tool result as continuation input
tool_response = client.responses.create(
model="o4-mini",
reasoning={"effort": "high"},
input=[
*response.output,
{
"role": "tool",
"name": fn_name,
"content": str(tool_result)
}
],
max_output_tokens=3000
)
if hasattr(tool_response, "output_text") and tool_response.output_text:
return tool_response.output_text.strip()
# If no tool was called, return original response
if hasattr(response, "output_text") and response.output_text:
return response.output_text.strip()
if response.status == "incomplete":
reason = getattr(response.incomplete_details, "reason", "unknown")
return f" Incomplete response: {reason}"
return " No valid output returned by the model."
except Exception as e:
return f" Error during chunk review: {e}"A função review_text_chunk é responsável por enviar cada parte do documento de pesquisa para o LLM, juntamente com um prompt do sistema e o registro da ferramenta. Veja a seguir como funciona passo a passo:
client.responses.create() que usa o Responses API para raciocínio. Nesta chamada:
"o4-mini" e o sinalizadorreasoning={"effort": "high"} é definido como alto, o que incentiva o raciocínio interno detalhado em várias etapas. Essa configuração informa ao modelo o quão profundamente ele deve "pensar" antes de gerar uma resposta final. Ele ajusta o número de tokens de raciocínio interno que o modelo tem permissão para usar.tool_choice="auto" explícito, pois a API de respostas decide o uso da ferramenta automaticamente.responses.create, anexando o resultado da ferramenta como uma mensagem de função "tool". Isso simula uma continuação do processo de raciocínio.Esse mecanismo de raciocínio e verificação em várias etapas é o que confere ao modelo a capacidade de revisão rigorosa. Ele imita a forma como um revisor humano pode identificar um problema, fazer um cálculo rápido e ajustar o feedback de acordo
Quando todos os componentes estiverem prontos, usaremos essa função para processar um PDF inteiro. Isso une tudo.
def review_full_pdf(pdf_path):
raw_text = extract_text_from_pdf(pdf_path)
chunks = chunk_text(raw_text)
print(f"\n Extracted {len(chunks)} chunks from PDF\n")
all_reviews = []
for idx, chunk in enumerate(chunks):
print(f"\n Reviewing Chunk {idx + 1}/{len(chunks)}...")
review = review_text_chunk(chunk)
all_reviews.append(f"### Chunk {idx + 1} Review\n{review}")
full_review = "\n\n".join(all_reviews)
return full_reviewEssa função funciona como um invólucro para revisar um trabalho de pesquisa inteiro:
Agora definimos o ponto de entrada do script. Isso permite que o programa seja executado diretamente do terminal com um caminho de arquivo PDF como entrada.
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="Review an academic paper PDF for weak arguments.")
parser.add_argument("pdf_path", type=str, help="Path to the research paper PDF")
args = parser.parse_args()
review_output = review_full_pdf(args.pdf_path)
print("\n Final Aggregated Review:\n")
print(review_output)
with open("paper_review_output.md", "w") as f:
f.write(review_output)
print("\n Review saved to paper_review_output.md")Esse bloco faz o seguinte:
argparse para aceitar o caminho para um PDF como um argumento de linha de comando.review_full_pdf() para gerar a análise completa.paper_review_output.md) para uso ou integração futura.Para executar esse código, digite o seguinte comando no terminal:
python pdf_reviewer_assistant.py Fake_paper.pdf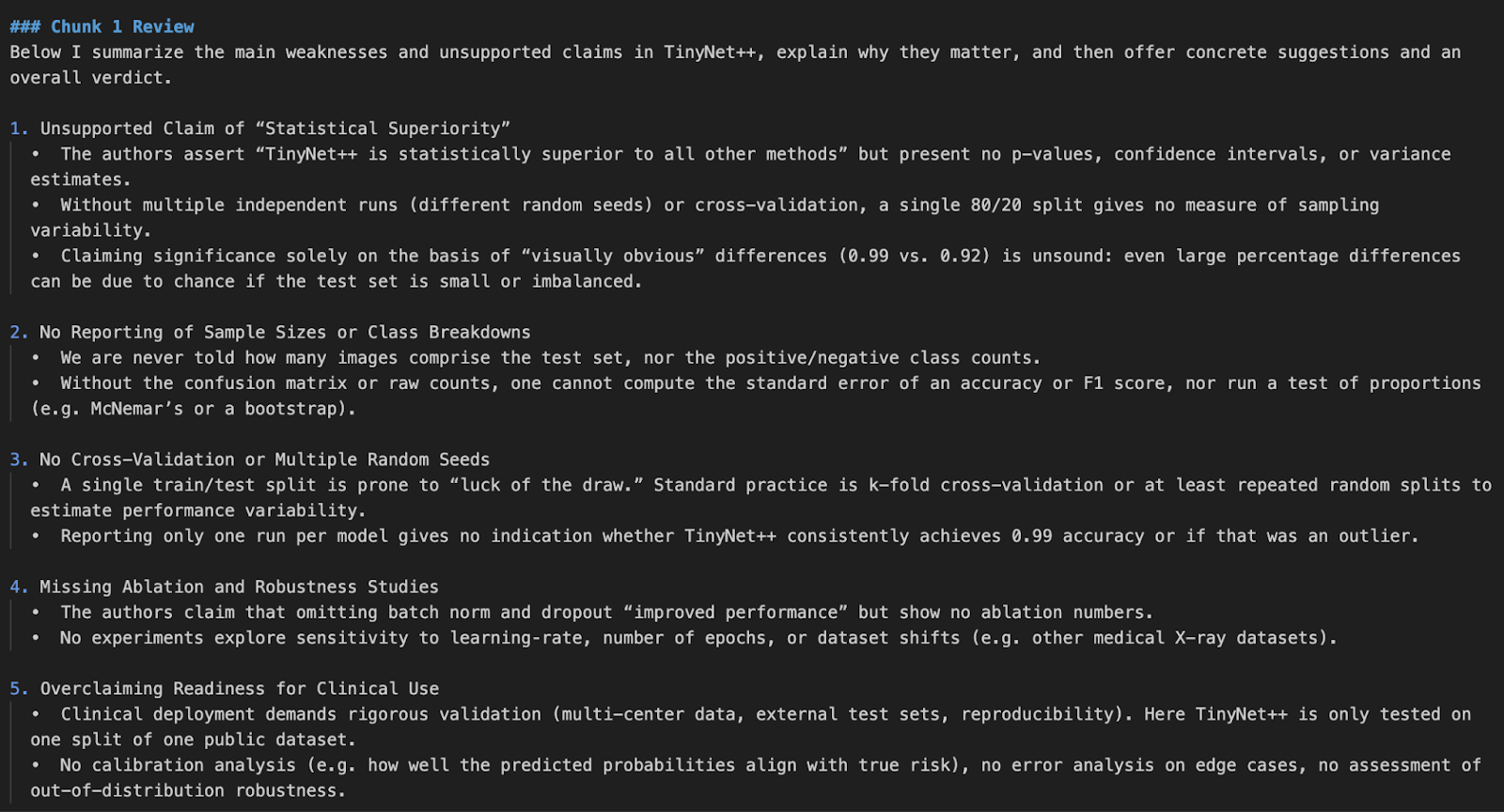
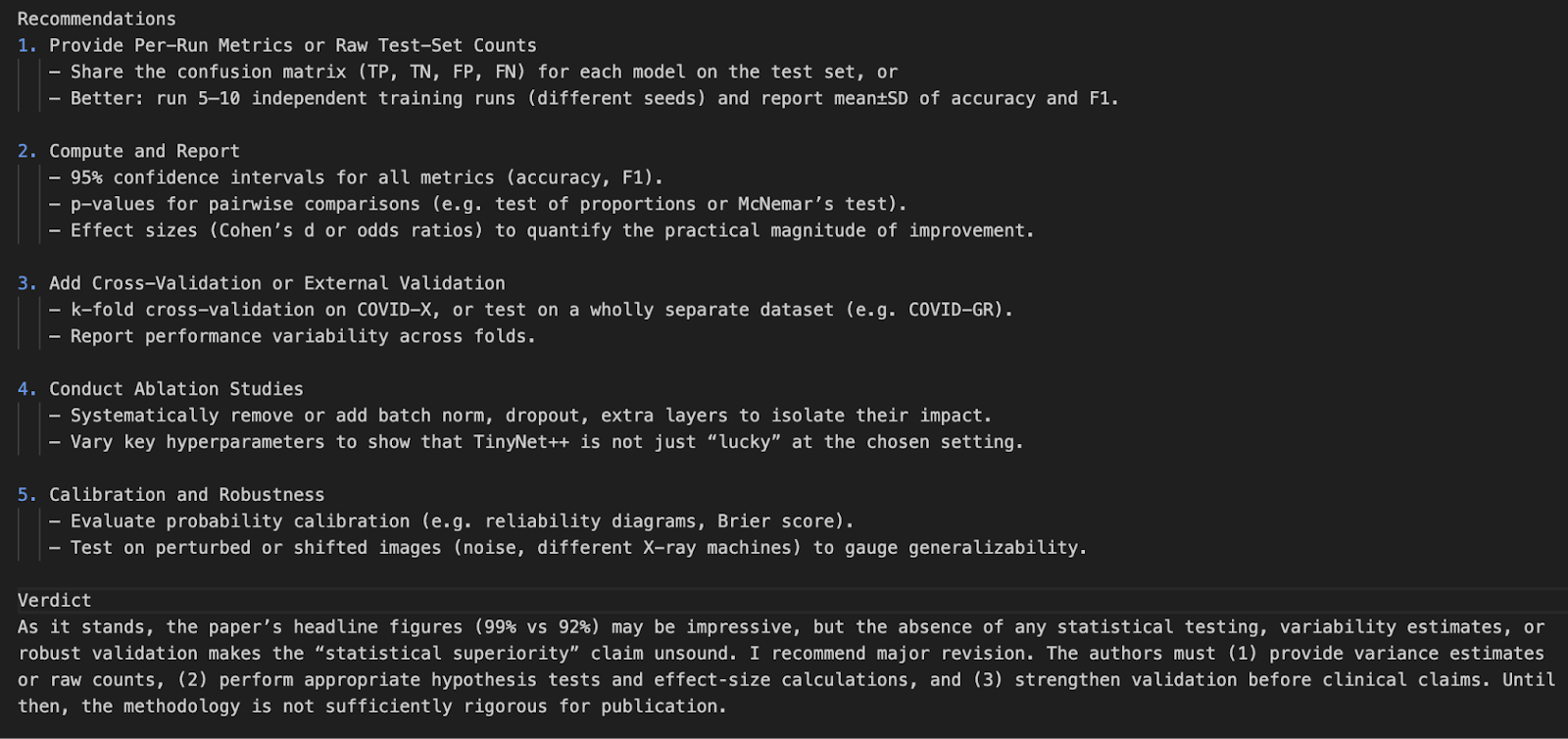
Neste projeto, criamos um revisor de artigos de pesquisa usando a API de modelo o4-mini da OpenAI. Aprimoramos a capacidade do modelo integrando ferramentas estatísticas em tempo real, permitindo que ele reanalisasse valores de p, intervalos de confiança e tamanhos de efeito.
Essa demonstração prepara o terreno para futuras integrações com UIs de PDF, verificadores de citações ou até mesmo ferramentas de assistente de pesquisa multimodal.
Para saber mais sobre os lançamentos recentes da OpenAI, confira estes blogs:
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Richie Cotton
7 min
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Josep Ferrer



