
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Daso4-mini von OpenAI ist das neueste Mitglied der o-Serie von KI-Modellen, die sich auf das Denken konzentrieren. In diesem Tutorial zeige ich dir, wie du mit der o4-mini-API von OpenAI einen research paper reviewer erstellen kannst. Das Tool wird:
Außerdem werden wir unseren Überprüfungsassistenten um statistische Werkzeuge erweitern, sodass das Modell bei Bedarf p-Werte, Effektgrößen und Konfidenzintervalle berechnen kann.
Wir halten unsere Leserinnen und Leser mit The Median auf dem Laufenden, unserem kostenlosen Freitags-Newsletter, der die wichtigsten Meldungen der Woche aufschlüsselt. Melde dich an und bleibe in nur ein paar Minuten pro Woche auf dem Laufenden:
OpenAIs o4-mini ist ein kostengünstiges, leistungsstarkes Denkmodell, das tiefgreifende Analysen für Aufgaben wie Codierung, Mathematik und wissenschaftliches Denken ermöglicht. Obwohl er kleiner ist als der o3 Modells, erzielt es bei Benchmarks wie AIME 2024/2025 und GPQA durchgängig die besten Ergebnisse.
Dank seiner Schnelligkeit und Erschwinglichkeit ist es ideal für Aufgaben wie die Überprüfung von Forschungsarbeiten, die Erstellung von Code-Erklärungen oder die Unterstützung bei Mathe-Wettbewerbsfragen. Seine wichtigsten Stärken sind:
Mehr darüber erfährst du in diesem einführenden Blog über o4-mini.
Wir entwickeln einen Python-basierten Reviewer für Forschungsarbeiten, mit dem du..:
Dieses Projekt ist vollständig lokal und nutzt die API von OpenAI.
Um o4-mini zu nutzen, brauchst du einen API-Schlüssel von OpenAI. Und so geht's:
Jetzt kannst du dich authentifizieren und die API von Python aus aufrufen.
Beginnen wir mit der Installation einiger Abhängigkeiten und dem Einrichten einer Umgebungsvariable für unseren API-Schlüssel einrichten.
pip install openai PyMuPDF tiktoken numpy
export OPENAI_API_KEY =” YOUR_KEY”Jetzt, da unsere Abhängigkeiten geklärt sind, können wir uns unseren Hilfsfunktionen zuwenden. Diese Funktionen werden bei Bedarf vom LLM über Tool-Aufrufe aufgerufen.
Diese Importe werden verwendet, um t-Tests, Standardfehler und Konfidenzintervalle zu berechnen.
from scipy.stats import ttest_ind, sem, t
import numpy as npDiese Funktion führt den Welch's t-Test zwischen zwei unabhängigen Stichprobengruppen durch. Sie testet die Hypothese, dass die Mittelwerte der beiden Gruppen statistisch unterschiedlich sind.
def recalculate_p_value(group1, group2):
t_stat, p_value = ttest_ind(group1, group2, equal_var=False)
return {"p_value": round(p_value, 4)}Die Funktion recalculate_p_value() gibt den auf vier Dezimalstellen gerundeten p-Wert zurück, der die Wahrscheinlichkeit angibt, dass der beobachtete Unterschied zufällig ist. Dies hilft dem LLM dabei, Behauptungen über statistische Signifikanz in der Forschungsarbeit zu überprüfen.
Cohens d ist ein standardisiertes Maß für die Effektgröße zwischen zwei Gruppen. Zunächst werden die Mittelwerte und Standardabweichungen der einzelnen Gruppen berechnet. Dann wird die gepoolte Standardabweichung verwendet, um die Differenz zwischen den Mittelwerten zu normalisieren.
def compute_cohens_d(group1, group2):
mean1, mean2 = np.mean(group1), np.mean(group2)
std1, std2 = np.std(group1, ddof=1), np.std(group2, ddof=1)
pooled_std = np.sqrt((std1**2 + std2**2) / 2)
d = (mean1 - mean2) / pooled_std
return {"cohens_d": round(d, 4)}Die Funktion gibt den Cohen's d-Wert zurück, gerundet auf vier Nachkommastellen. Das hilft dem LLM, die praktische Bedeutung (nicht nur die statistische) von Gruppenunterschieden zu verstehen. Sie ist vor allem dann wertvoll, wenn der Stichprobenumfang groß ist und die p-Werte allein nicht aussagekräftig sind.
Wir definieren nun einen Helfer, um das Konfidenzintervall für eine einzelne Stichprobengruppe zu berechnen. Konfidenzintervalle sind nützlich, um die Zuverlässigkeit eines geschätzten Mittelwerts zu verstehen - mit anderen Worten, wie viel Unsicherheit den Durchschnittswert umgibt.
def compute_confidence_interval(data, confidence=0.95):
data = np.array(data)
n = len(data)
mean = np.mean(data)
margin = sem(data) * t.ppf((1 + confidence) / 2., n-1)
return {
"mean": round(mean, 4),
"confidence_interval": [round(mean - margin, 4), round(mean + margin, 4)],
"confidence": confidence
}Das gibt diese Funktion zurück:
mean: Der Durchschnittswert der Eingabedaten.confidence_interval: Eine Liste mit den unteren und oberen Grenzen, innerhalb derer der wahre Mittelwert wahrscheinlich liegt, basierend auf dem angegebenen Konfidenzniveau.confidence: Das Konfidenzniveau, das für das Intervall verwendet wird.Wir schließen die Hilfsfunktionen mit einem einfachen Hilfsmittel ab, das den Mittelwert, die Standardabweichung und den Stichprobenumfang zusammenfasst.
def describe_group(data):
data = np.array(data)
return {
"mean": round(np.mean(data), 4),
"std_dev": round(np.std(data, ddof=1), 4),
"n": len(data)
}Dies hilft dem LLM, die zugrunde liegende Datenverteilung zu interpretieren und liefert einen wichtigen Kontext für die Auswertung der Ergebnisse. Indem wir statistische Deskriptoren wie Mittelwert, Standardabweichung und Anzahl offenlegen, stärken unsere Hilfsmittel die Fähigkeit des Modells, Experimente und Behauptungen in Forschungsunterlagen zu verstehen.
In diesem Abschnitt bauen wir einen Python-basierten Reviewer für Forschungsarbeiten, der die o4-mini-API von OpenAI nutzt und Werkzeuge für die statistische Analyse enthält, damit das Modell strenge Bewertungen und datengestützte Kritiken durchführen kann.
Wir beginnen unseren Hauptcode mit einigen wichtigen Bibliotheken, um PDF-Inhalte zu extrahieren, sie zu tokenisieren und mit der OpenAI API zu kommunizieren.
import os
import fitz
import openai
import json
import tiktoken
from statistics_helper import (
recalculate_p_value,
compute_cohens_d,
compute_confidence_interval,
describe_group
)
openai.api_key = os.getenv("OPENAI_API_KEY")Lass uns nun die komplette Pipeline Schritt für Schritt aufbauen.
Wir beginnen mit dem Lesen des Rohtextes aus der Forschungsarbeit. Mit der Bibliothek fitz können wir über alle Seiten iterieren und den extrahierten Text zu einem String verketten.
def extract_text_from_pdf(path):
doc = fitz.open(path)
full_text = "\n".join(page.get_text() for page in doc)
return full_textDamit ist der Grundstein gelegt. Wir werden den Rohtext nun tokenisieren und chunkern, bevor wir ihn an das Modell senden.
Hinweis: Ich habe eine gefälschte Forschungsarbeit zu Demonstrationszwecken erstellt, die absichtlich Fehler in der Logik und im Versuchsaufbau enthält.
LLMs haben eine Kontextbegrenzung, deshalb unterteilen wir lange Dokumente in überschaubare Abschnitte. Wir verwenden Tiktoken um den Text basierend auf dem Kodierungsschema des Modells zu tokenisieren.
def chunk_text(text, max_tokens=12000, model="o4-mini"):
encoding = tiktoken.get_encoding("cl100k_base")
tokens = encoding.encode(text)
chunks = []
for i in range(0, len(tokens), max_tokens):
chunk = tokens[i:i + max_tokens]
chunk_text = encoding.decode(chunk)
chunks.append(chunk_text)
return chunksSo funktioniert es:
tiktoken, um den gesamten Dokumententext mit Hilfe des cl100k_base tokenizer zu tokenisieren, das mit modernen OpenAI-Modellen wie GPT-4, GPT-4o und o4-mini kompatibel ist.max_tokens aufgeteilt. Dadurch wird sichergestellt, dass jeder Chunk innerhalb der maximal zulässigen Eingabegröße des Modells bleibt, was wichtig ist, um Token-Überlauffehler während der Inferenz zu vermeiden.encoding.decode() wieder in menschenlesbaren Text dekodiert. Auf diese Weise bleiben natürliche Formulierungen und Formatierungen erhalten, sodass das Modell bei der Verarbeitung einen kohärenten Kontext erhält.Dieser Chunking-Schritt ist wichtig, um Abschneidefehler bei der Inferenz zu verhindern und garantiert, dass kein wichtiger Text wegen Überlaufs ausgelassen wird.
Bevor das Modell externe Funktionen aufrufen kann, müssen wir eine Zuordnung zwischen den Funktionsnamen (aus Sicht des Modells) und den tatsächlichen Python-Funktionen, die ausgeführt werden sollen, definieren. Dieses Mapping fungiert als Brücke zwischen den Tool-Aufrufen des Modells und unserer lokalen Codebase.
tool_function_map = {
"recalculate_p_value": recalculate_p_value,
"compute_cohens_d": compute_cohens_d,
"compute_confidence_interval": compute_confidence_interval,
"describe_group": describe_group,
}Jeder Schlüssel in diesem Wörterbuch entspricht einem Funktionsnamen, den das Modell beim Aufruf des Werkzeugs referenzieren könnte, und jeder Wert ist die tatsächliche Python-Funktion, die aus dem Modul statistics_helper importiert wird.
Um das Model Reasoning zu verbessern, registrieren wir Tools, die der LLM über Funktionsaufruf. Mit diesen Tools kannst du statistische Analysen wie die Neuberechnung von p-Werten, Konfidenzintervallen und Effektgrößen durchführen.
tools = [
{
"type": "function",
"name": "recalculate_p_value",
"description": "Calculate p-value between two sample groups",
"parameters": {
"type": "object",
"properties": {
"group1": {"type": "array", "items": {"type": "number"}},
"group2": {"type": "array", "items": {"type": "number"}}
},
"required": ["group1", "group2"]
}
},
{
"type": "function",
"name": "compute_cohens_d",
"description": "Compute effect size (Cohen's d) between two groups",
"parameters": {
"type": "object",
"properties": {
"group1": {"type": "array", "items": {"type": "number"}},
"group2": {"type": "array", "items": {"type": "number"}}
},
"required": ["group1", "group2"]
}
},
{
"type": "function",
"name": "compute_confidence_interval",
"description": "Compute confidence interval for a sample group",
"parameters": {
"type": "object",
"properties": {
"data": {"type": "array", "items": {"type": "number"}},
"confidence": {"type": "number", "default": 0.95}
},
"required": ["data"]
}
},
{
"type": "function",
"name": "describe_group",
"description": "Summarize sample mean, std deviation, and count",
"parameters": {
"type": "object",
"properties": {
"data": {"type": "array", "items": {"type": "number"}}
},
"required": ["data"]
}
}
]Die obige Tool-Definition ermöglicht es dem LLM zu verstehen:
description)name)Der LLM entscheidet auf intelligente Weise, wann er ein Hilfsmittel, wie z. B. die Neuberechnung eines p-Wertes, auf der Grundlage des Kontextes der Überprüfung anwendet. Wenn er auf eine statistische Behauptung oder ein fragwürdiges Ergebnis stößt, kann er die entsprechende Hilfsfunktion aufrufen, die Ausgabe erhalten und mit diesem Ergebnis seine Überlegungen fortsetzen. Dies ermöglicht eine strengere und fundiertere Analyse, bei der das Modell die zugrunde liegenden Daten nicht nur kritisiert, sondern auch verifiziert.
Wir definieren nun die Kernlogik, die jeden Textchunk an das o4-mini-Modell sendet. Wenn es ein Tool aufruft, behandeln wir den Funktionsaufruf und setzen die Konversation fort.
def review_text_chunk(chunk):
try:
response = client.responses.create(
model="o4-mini",
reasoning={"effort": "high"},
input=[
{
"role": "system",
"content": (
"You are an expert AI research reviewer. Read the given chunk of a research paper and highlight weak arguments."
"unsupported claims, or flawed methodology. You can request tools to: Recalculate p-values, Compute confidence intervals, "
"Estimate effect size (Cohen's d), Describe sample statistics. Be rigorous and explain your reasoning. "
"Conclude with suggestions and a verdict."
)
},
{
"role": "user",
"content": chunk
}
],
tools = tools,
)
# Check for tool calls
for item in response.output:
if getattr(item, "type", None) == "function_call":
fn_call = getattr(item, "function_call", {})
fn_name = getattr(fn_call, "name", "")
args = getattr(fn_call, "arguments", {})
if fn_name in tool_function_map:
tool_result = tool_function_map[fn_name](**args)
# Send back tool result as continuation input
tool_response = client.responses.create(
model="o4-mini",
reasoning={"effort": "high"},
input=[
*response.output,
{
"role": "tool",
"name": fn_name,
"content": str(tool_result)
}
],
max_output_tokens=3000
)
if hasattr(tool_response, "output_text") and tool_response.output_text:
return tool_response.output_text.strip()
# If no tool was called, return original response
if hasattr(response, "output_text") and response.output_text:
return response.output_text.strip()
if response.status == "incomplete":
reason = getattr(response.incomplete_details, "reason", "unknown")
return f" Incomplete response: {reason}"
return " No valid output returned by the model."
except Exception as e:
return f" Error during chunk review: {e}"Die Funktion review_text_chunk ist dafür verantwortlich, dass die einzelnen Teile der Forschungsarbeit an den LLM gesendet werden, zusammen mit einer Systemabfrage und einer Werkzeugregistrierung. Hier erfährst du Schritt für Schritt, wie es funktioniert:
client.responses.create() an das Modell gesendet, das die Responses API für die Argumentation verwendet. In diesem Aufruf:
"o4-mini" eingestellt und das reasoning={"effort": "high"} Flag ist auf hoch gesetzt, was zu detaillierten, mehrstufigen internen Überlegungen anregt. Diese Einstellung teilt dem Modell mit, wie tief es "nachdenken" soll, bevor es eine endgültige Antwort gibt. Sie passt die Anzahl der internen Argumentations-Token an, die das Modell verwenden darf.tool_choice="auto" erforderlich, da die Responses API die Verwendung des Tools automatisch entscheidet.responses.create an das Modell zurück und fügen das Ergebnis des Werkzeugs als Rollenmeldung "Werkzeug" hinzu. Dies simuliert eine Fortsetzung des Denkprozesses.Dieser mehrstufige Argumentations- und Überprüfungsmechanismus verleiht dem Modell eine strenge Überprüfungsfähigkeit. Es ahmt nach, wie ein menschlicher Prüfer ein Problem erkennen, eine schnelle Berechnung durchführen und sein Feedback entsprechend anpassen könnte.
Sobald alle Komponenten vorhanden sind, verwenden wir diese Funktion, um ein ganzes PDF zu verarbeiten. Es verbindet alles miteinander.
def review_full_pdf(pdf_path):
raw_text = extract_text_from_pdf(pdf_path)
chunks = chunk_text(raw_text)
print(f"\n Extracted {len(chunks)} chunks from PDF\n")
all_reviews = []
for idx, chunk in enumerate(chunks):
print(f"\n Reviewing Chunk {idx + 1}/{len(chunks)}...")
review = review_text_chunk(chunk)
all_reviews.append(f"### Chunk {idx + 1} Review\n{review}")
full_review = "\n\n".join(all_reviews)
return full_reviewDiese Funktion dient als Wrapper, um eine ganze Forschungsarbeit zu überprüfen:
Wir definieren nun den Einstiegspunkt des Skripts. So kann das Programm direkt vom Terminal aus mit einem PDF-Dateipfad als Eingabe gestartet werden.
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="Review an academic paper PDF for weak arguments.")
parser.add_argument("pdf_path", type=str, help="Path to the research paper PDF")
args = parser.parse_args()
review_output = review_full_pdf(args.pdf_path)
print("\n Final Aggregated Review:\n")
print(review_output)
with open("paper_review_output.md", "w") as f:
f.write(review_output)
print("\n Review saved to paper_review_output.md")Dieser Block macht Folgendes:
argparse, um den Pfad zu einer PDF-Datei als Kommandozeilenargument zu akzeptieren.review_full_pdf() auf, um den vollständigen Bericht zu erstellen.paper_review_output.md) gespeichert, damit er später verwendet oder integriert werden kann.Um diesen Code auszuführen, gibst du den folgenden Befehl in das Terminal ein:
python pdf_reviewer_assistant.py Fake_paper.pdf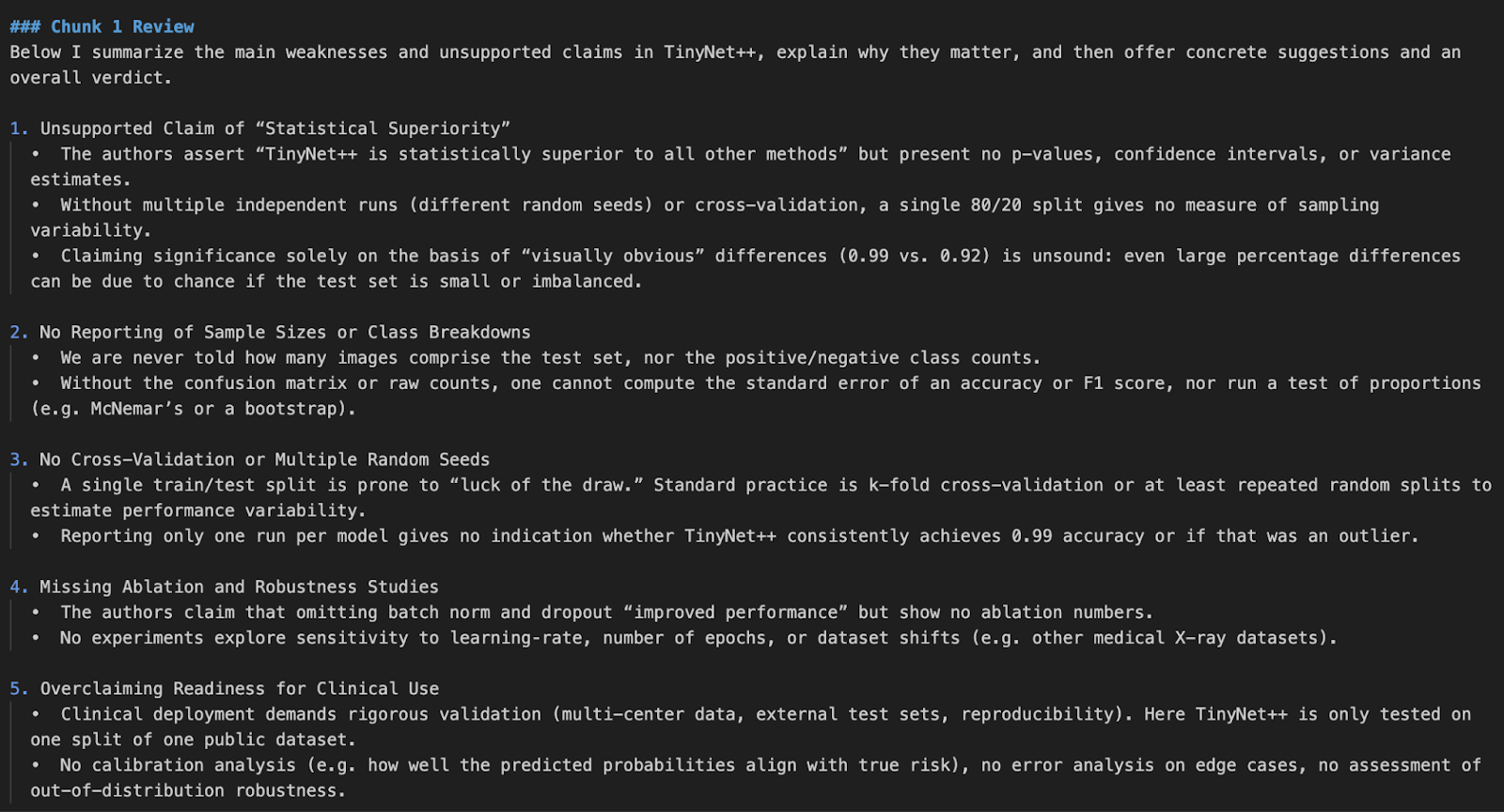
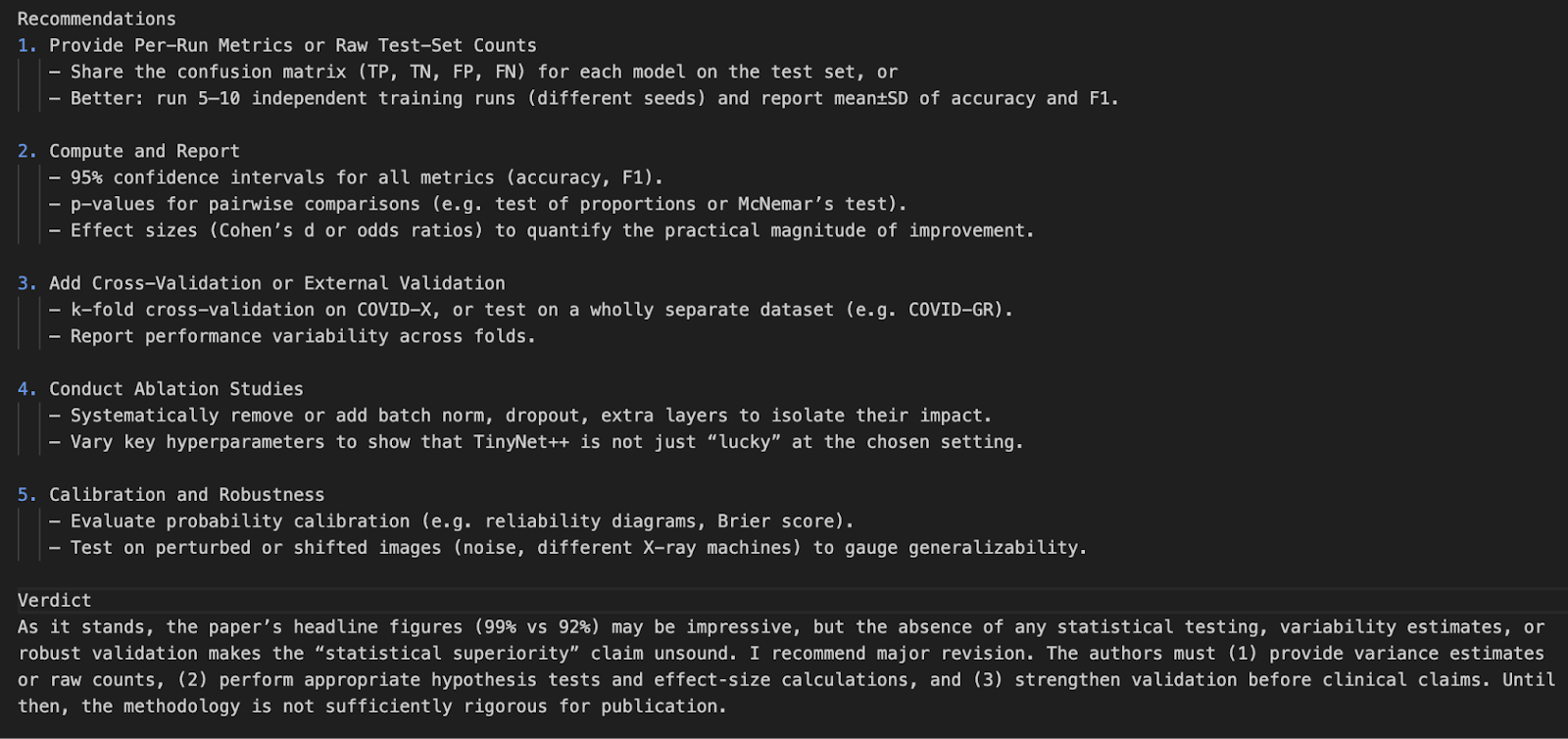
In diesem Projekt haben wir mit der o4-mini Model API von OpenAI einen Reviewer für Forschungsarbeiten erstellt. Wir haben die Fähigkeiten des Modells verbessert, indem wir statistische Werkzeuge in Echtzeit integriert haben, mit denen es p-Werte, Konfidenzintervalle und Effektgrößen neu analysieren kann.
Diese Demo schafft die Voraussetzungen für künftige Integrationen mit PDF-UIs, Zitierhilfen oder sogar multimodalen Recherchetools.
Wenn du mehr über die neuesten OpenAI-Versionen erfahren möchtest, schau dir diese Blogs an:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
