
Cursus
Développer des applications d'IA
21 h
OpenAI 's o4-mini est le dernier né de la série o de modèles d'intelligence artificielle axés sur le raisonnement. Dans ce tutoriel, je vous expliquerai comment créer unévaluateur d'articles de recherche à l'aide de l'API o4-mini d'OpenAI. L'outil permettra :
Nous améliorerons également notre assistant d'examen avec un support d'outils statistiques, de sorte que le modèle puisse calculer les valeurs p, les tailles d'effet et les intervalles de confiance à la demande.
Nous tenons nos lecteurs informés des dernières nouveautés en matière d'IA en leur envoyant The Median, notre lettre d'information gratuite du vendredi qui analyse les principaux sujets de la semaine. Abonnez-vous et restez à la pointe de la technologie en quelques minutes par semaine :
L'o4-mini d'OpenAI est un modèle de raisonnement rentable et performant, capable d'analyser en profondeur des tâches telles que le codage, les mathématiques et le raisonnement scientifique. Bien qu'il soit plus petit que le o3 il obtient régulièrement des résultats de pointe dans des tests de référence tels que AIME 2024/2025 et GPQA.
Grâce à sa vitesse et à son prix abordable, il est idéal pour des tâches telles que l'examen de documents de recherche, la génération d'explications de code ou l'assistance aux questions de mathématiques des concours. Ses principaux atouts sont les suivants :
Pour en savoir plus, consultez ce blog d'introduction sur o4-mini.
Nous allons construire un évaluateur de documents de recherche basé sur Python qui peut :
Ce projet est entièrement local et utilise l'API d'OpenAI.
Pour utiliser o4-mini, vous aurez besoin d'une clé API d'OpenAI. Voici comment :
Vous êtes maintenant prêt à vous authentifier et à appeler l'API depuis Python.
Commençons par installer quelques dépendances et configurer une variable d'environnement variable d'environnement pour notre clé API.
pip install openai PyMuPDF tiktoken numpy
export OPENAI_API_KEY =” YOUR_KEY”Maintenant que nos dépendances sont triées, passons à nos fonctions d'aide. Ces fonctions sont invoquées par le LLM à l'aide d'appels d'outils lorsque cela est nécessaire.
Ces importations sont utilisées pour calculer les tests t, les erreurs standard et les intervalles de confiance.
from scipy.stats import ttest_ind, sem, t
import numpy as npCette fonction permet d'effectuer le test t de Welch entre deux groupes d'échantillons indépendants. Il teste l'hypothèse selon laquelle les moyennes des deux groupes sont statistiquement différentes.
def recalculate_p_value(group1, group2):
t_stat, p_value = ttest_ind(group1, group2, equal_var=False)
return {"p_value": round(p_value, 4)}La fonction recalculate_p_value() renvoie la valeur p, arrondie à la quatrième décimale, qui indique la probabilité que la différence observée soit due au hasard. Cela permet au LLM de valider les affirmations de signification statistique dans le document de recherche.
Le d de Cohen est une mesure standardisée de l'ampleur de l'effet entre deux groupes. Il commence par calculer les moyennes et les écarts types de chaque groupe. Il utilise ensuite l'écart-type regroupé pour normaliser la différence entre les moyennes.
def compute_cohens_d(group1, group2):
mean1, mean2 = np.mean(group1), np.mean(group2)
std1, std2 = np.std(group1, ddof=1), np.std(group2, ddof=1)
pooled_std = np.sqrt((std1**2 + std2**2) / 2)
d = (mean1 - mean2) / pooled_std
return {"cohens_d": round(d, 4)}La fonction renvoie la valeur du d de Cohen, arrondie à quatre décimales. Cela aide le LLM à comprendre l'importance pratique (et pas seulement statistique) des différences entre les groupes. Elle est particulièrement utile lorsque la taille de l'échantillon est importante et que les valeurs p seules ne sont pas informatives.
Nous allons maintenant définir un assistant permettant de calculer l'intervalle de confiance pour un seul groupe d'échantillons. Les intervalles de confiance sont utiles pour comprendre la fiabilité d'une moyenne estimée - en d'autres termes, le degré d'incertitude qui entoure la valeur moyenne.
def compute_confidence_interval(data, confidence=0.95):
data = np.array(data)
n = len(data)
mean = np.mean(data)
margin = sem(data) * t.ppf((1 + confidence) / 2., n-1)
return {
"mean": round(mean, 4),
"confidence_interval": [round(mean - margin, 4), round(mean + margin, 4)],
"confidence": confidence
}Voici ce que cette fonction renvoie :
mean: La valeur moyenne des données d'entrée.confidence_interval: Une liste représentant les limites inférieures et supérieures à l'intérieur desquelles la moyenne réelle se situe probablement, sur la base du niveau de confiance spécifié.confidence: Le niveau de confiance utilisé pour l'intervalle.Nous concluons les fonctions d'aide par une aide simple qui résume la moyenne, l'écart type et la taille de l'échantillon.
def describe_group(data):
data = np.array(data)
return {
"mean": round(np.mean(data), 4),
"std_dev": round(np.std(data, ddof=1), 4),
"n": len(data)
}Cela permet au LLM d'interpréter la distribution des données sous-jacentes et de fournir un contexte essentiel pour l'évaluation des résultats. En exposant des descripteurs statistiques tels que la moyenne, l'écart-type et le nombre, nos outils d'aide renforcent la capacité du modèle à raisonner à partir d'expériences et d'affirmations trouvées dans des documents de recherche.
Dans cette section, nous allons construire l'évaluateur d'articles de recherche basé sur Python qui utilise l'API o4-mini d'OpenAI et inclut le support d'outils pour l'analyse statistique, permettant au modèle d'effectuer des évaluations rigoureuses et des critiques soutenues par des données.
Nous commençons notre code principal avec quelques bibliothèques essentielles pour extraire le contenu du PDF, le tokeniser et communiquer avec l'API OpenAI.
import os
import fitz
import openai
import json
import tiktoken
from statistics_helper import (
recalculate_p_value,
compute_cohens_d,
compute_confidence_interval,
describe_group
)
openai.api_key = os.getenv("OPENAI_API_KEY")Construisons maintenant la filière complète, étape par étape.
Nous commençons par lire le texte brut du document de recherche. La bibliothèque fitz nous permet de parcourir toutes les pages et de concaténer le texte extrait en une seule chaîne.
def extract_text_from_pdf(path):
doc = fitz.open(path)
full_text = "\n".join(page.get_text() for page in doc)
return full_textC'est le point de départ. Nous allons maintenant symboliser et découper le texte brut avant de l'envoyer au modèle.
Note : J'ai généré un faux document de recherche à des fins de démonstration qui contient intentionnellement des failles dans la logique et la conception expérimentale.
Les LLM ont des limites contextuelles, c'est pourquoi nous découpons les longs documents en morceaux faciles à gérer. Nous utilisons Tiktoken pour symboliser le texte en fonction du schéma d'encodage du modèle.
def chunk_text(text, max_tokens=12000, model="o4-mini"):
encoding = tiktoken.get_encoding("cl100k_base")
tokens = encoding.encode(text)
chunks = []
for i in range(0, len(tokens), max_tokens):
chunk = tokens[i:i + max_tokens]
chunk_text = encoding.decode(chunk)
chunks.append(chunk_text)
return chunksVoici comment cela fonctionne :
tiktoken pour tokeniser le texte complet du document en utilisant cl100k_base tokenizer, qui est compatible avec les modèles OpenAI modernes tels que GPT-4, GPT-4o et o4-mini.max_tokens. Cela permet de s'assurer que chaque morceau reste dans la limite de la taille d'entrée maximale autorisée par le modèle, ce qui est essentiel pour éviter les erreurs de débordement de jeton pendant l'inférence.encoding.decode(). Cela permet de préserver la formulation et le formatage naturels afin que le modèle reçoive un contexte cohérent lors du traitement.Cette étape de découpage est essentielle pour éviter les erreurs de coupure lors de l'inférence et garantit qu'aucun texte important n'est supprimé en raison d'un débordement.
Avant que le modèle puisse invoquer des fonctions externes, nous devons définir une correspondance entre les noms de fonctions (tels qu'ils sont perçus par le modèle) et les fonctions Python réelles qui seront exécutées. Ce mappage sert de pont entre les appels d'outils du modèle et notre base de code locale.
tool_function_map = {
"recalculate_p_value": recalculate_p_value,
"compute_cohens_d": compute_cohens_d,
"compute_confidence_interval": compute_confidence_interval,
"describe_group": describe_group,
}Chaque clé de ce dictionnaire correspond à un nom de fonction que le modèle pourrait référencer lors de l'invocation de son outil, et chaque valeur est la fonction Python réelle importée du module statistics_helper.
Pour améliorer le raisonnement sur les modèles, nous enregistrons des outils que le LLM peut appeler par l'intermédiaire de appel de fonction. Ces outils gèrent les analyses statistiques telles que le recalcul de la valeur p, les intervalles de confiance et les tailles d'effet.
tools = [
{
"type": "function",
"name": "recalculate_p_value",
"description": "Calculate p-value between two sample groups",
"parameters": {
"type": "object",
"properties": {
"group1": {"type": "array", "items": {"type": "number"}},
"group2": {"type": "array", "items": {"type": "number"}}
},
"required": ["group1", "group2"]
}
},
{
"type": "function",
"name": "compute_cohens_d",
"description": "Compute effect size (Cohen's d) between two groups",
"parameters": {
"type": "object",
"properties": {
"group1": {"type": "array", "items": {"type": "number"}},
"group2": {"type": "array", "items": {"type": "number"}}
},
"required": ["group1", "group2"]
}
},
{
"type": "function",
"name": "compute_confidence_interval",
"description": "Compute confidence interval for a sample group",
"parameters": {
"type": "object",
"properties": {
"data": {"type": "array", "items": {"type": "number"}},
"confidence": {"type": "number", "default": 0.95}
},
"required": ["data"]
}
},
{
"type": "function",
"name": "describe_group",
"description": "Summarize sample mean, std deviation, and count",
"parameters": {
"type": "object",
"properties": {
"data": {"type": "array", "items": {"type": "number"}}
},
"required": ["data"]
}
}
]La définition de l'outil ci-dessus permet au LLM de comprendre :
description)name)Le LLM décide intelligemment quand invoquer un outil, tel que le recalcul d'une valeur p, en fonction du contexte de l'examen. Lorsqu'il rencontre une affirmation statistique ou un résultat douteux, il peut appeler la fonction d'aide appropriée, recevoir le résultat et poursuivre son raisonnement sur la base de ce résultat. Cela permet une analyse plus rigoureuse et mieux fondée, dans laquelle le modèle ne se contente pas de critiquer les données sous-jacentes, mais les vérifie également.
Nous allons maintenant définir la logique de base qui envoie chaque morceau de texte au modèle o4-mini. S'il fait appel à un outil, nous traitons l'appel de fonction et poursuivons la conversation.
def review_text_chunk(chunk):
try:
response = client.responses.create(
model="o4-mini",
reasoning={"effort": "high"},
input=[
{
"role": "system",
"content": (
"You are an expert AI research reviewer. Read the given chunk of a research paper and highlight weak arguments."
"unsupported claims, or flawed methodology. You can request tools to: Recalculate p-values, Compute confidence intervals, "
"Estimate effect size (Cohen's d), Describe sample statistics. Be rigorous and explain your reasoning. "
"Conclude with suggestions and a verdict."
)
},
{
"role": "user",
"content": chunk
}
],
tools = tools,
)
# Check for tool calls
for item in response.output:
if getattr(item, "type", None) == "function_call":
fn_call = getattr(item, "function_call", {})
fn_name = getattr(fn_call, "name", "")
args = getattr(fn_call, "arguments", {})
if fn_name in tool_function_map:
tool_result = tool_function_map[fn_name](**args)
# Send back tool result as continuation input
tool_response = client.responses.create(
model="o4-mini",
reasoning={"effort": "high"},
input=[
*response.output,
{
"role": "tool",
"name": fn_name,
"content": str(tool_result)
}
],
max_output_tokens=3000
)
if hasattr(tool_response, "output_text") and tool_response.output_text:
return tool_response.output_text.strip()
# If no tool was called, return original response
if hasattr(response, "output_text") and response.output_text:
return response.output_text.strip()
if response.status == "incomplete":
reason = getattr(response.incomplete_details, "reason", "unknown")
return f" Incomplete response: {reason}"
return " No valid output returned by the model."
except Exception as e:
return f" Error during chunk review: {e}"La fonction review_text_chunk est chargée d'envoyer chaque morceau du document de recherche au LLM, ainsi qu'une invite système et un registre d'outils. Voici comment cela fonctionne, étape par étape :
client.responses.create() qui utilise le site Responses API pour le raisonnement. Dans cet appel :
"o4-mini", et l'indicateurreasoning={"effort": "high"} est réglé sur élevé, ce qui encourage un raisonnement interne détaillé en plusieurs étapes. Ce paramètre indique au modèle à quel point il doit "réfléchir" avant de générer une réponse finale. Il ajuste le nombre de jetons de raisonnement interne que le modèle est autorisé à utiliser.tool_choice="auto" explicite n' est nécessaire, car l'API Responses décide automatiquement de l'utilisation de l'outil.responses.create, en ajoutant le résultat de l'outil en tant que message de rôle "outil". Cela simule la poursuite du processus de raisonnement.Ce mécanisme de raisonnement et de vérification en plusieurs étapes est ce qui donne au modèle une capacité de révision rigoureuse. Il imite la manière dont un évaluateur humain peut repérer un problème, effectuer un calcul rapide et ajuster ses commentaires en conséquence
Une fois que tous les composants sont en place, nous utilisons cette fonction pour traiter un PDF entier. Il fait le lien entre tous les éléments.
def review_full_pdf(pdf_path):
raw_text = extract_text_from_pdf(pdf_path)
chunks = chunk_text(raw_text)
print(f"\n Extracted {len(chunks)} chunks from PDF\n")
all_reviews = []
for idx, chunk in enumerate(chunks):
print(f"\n Reviewing Chunk {idx + 1}/{len(chunks)}...")
review = review_text_chunk(chunk)
all_reviews.append(f"### Chunk {idx + 1} Review\n{review}")
full_review = "\n\n".join(all_reviews)
return full_reviewCette fonction sert d'enveloppe à l'examen d'un document de recherche complet :
Nous définissons maintenant le point d'entrée du script. Cela permet d'exécuter le programme directement à partir du terminal avec un chemin d'accès au fichier PDF en entrée.
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="Review an academic paper PDF for weak arguments.")
parser.add_argument("pdf_path", type=str, help="Path to the research paper PDF")
args = parser.parse_args()
review_output = review_full_pdf(args.pdf_path)
print("\n Final Aggregated Review:\n")
print(review_output)
with open("paper_review_output.md", "w") as f:
f.write(review_output)
print("\n Review saved to paper_review_output.md")Ce bloc a les fonctions suivantes :
argparse pour accepter le chemin d'accès à un PDF en tant qu'argument de ligne de commande.review_full_pdf() pour générer l'examen complet.paper_review_output.md) en vue d'une utilisation ou d'une intégration ultérieure.Pour exécuter ce code, tapez la commande suivante dans le terminal :
python pdf_reviewer_assistant.py Fake_paper.pdf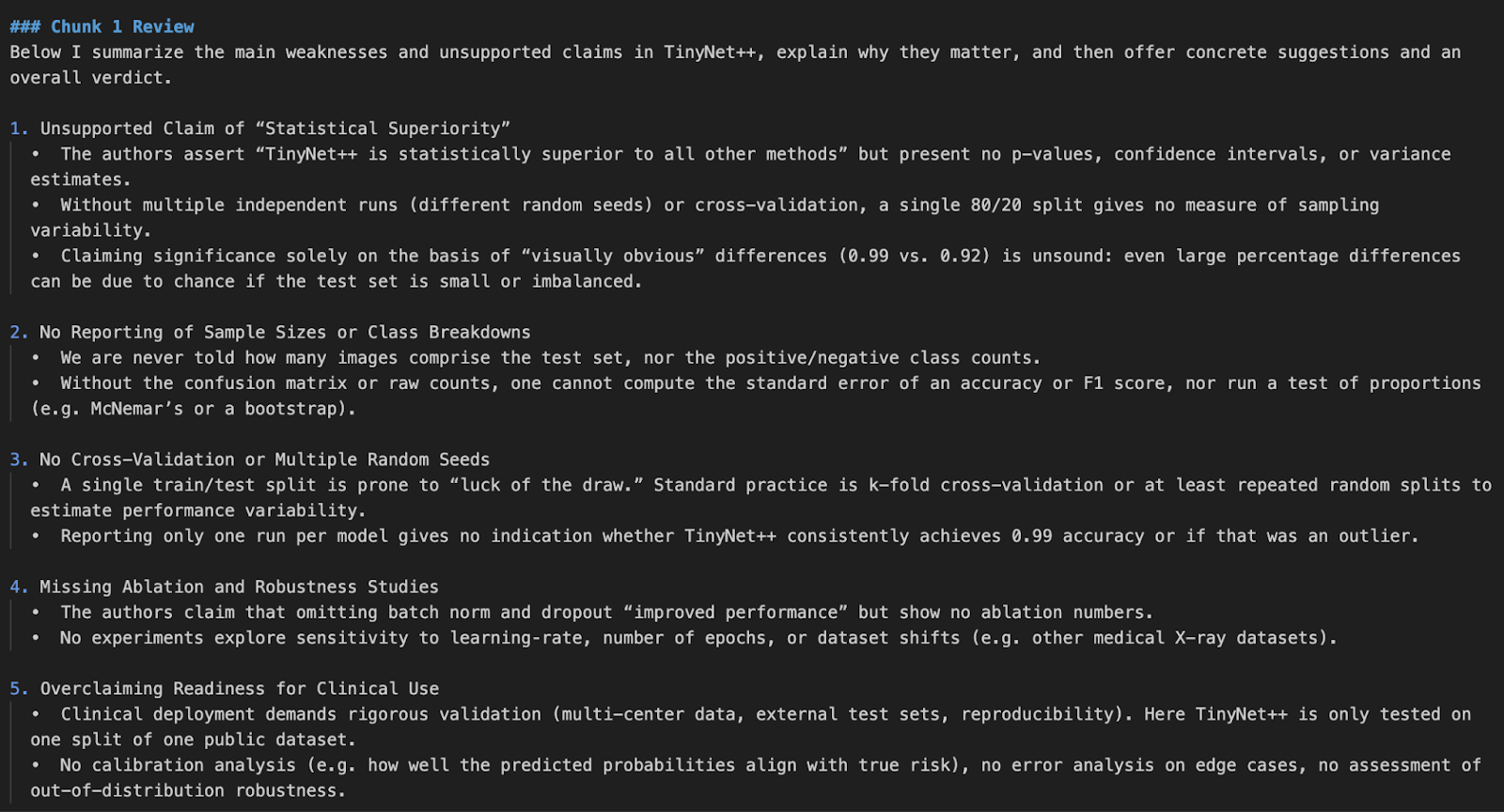
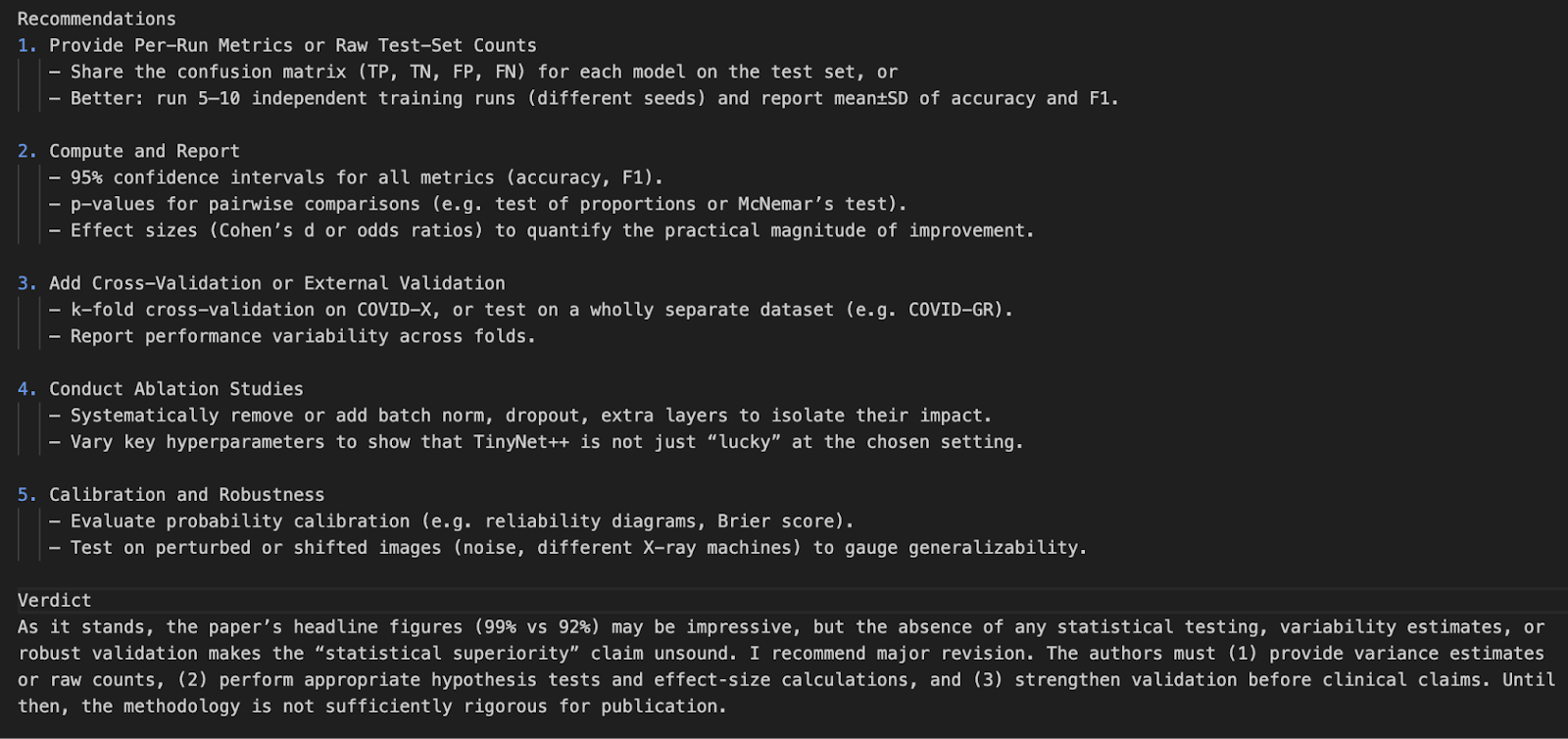
Dans ce projet, nous avons créé un évaluateur d'articles de recherche en utilisant l'API de modèle o4-mini d'OpenAI. Nous avons amélioré la capacité du modèle en intégrant des outils statistiques en temps réel, lui permettant de réanalyser les valeurs p, les intervalles de confiance et les tailles d'effet.
Cette démonstration ouvre la voie à de futures intégrations avec des interfaces PDF, des vérificateurs de citations ou même des outils d'aide à la recherche multimodale.
Pour en savoir plus sur les dernières versions d'OpenAI, consultez ces blogs :
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Fereshteh Forough
4 min