
Curso
Trabajar con la API de OpenAI
3 h
141.6K
En este tutorial, crearemos una aplicación clasificadora de la calidad del agua desde cero y la desplegaremos en la nube utilizando Docker.
Empezaremos explorando el modelo OpenAI o1 y comprendiendo su funcionalidad. A continuación, accederemos al modelo mediante API y ChatGPT, experimentando con las versiones o1-preview y o1-mini, antes de desarrollar indicaciones eficaces para crear una aplicación clasificadora de la calidad del agua.
Una vez que tengamos la salida, añadiremos el código y los archivos proporcionados por el modelo o1 en la carpeta del proyecto y, a continuación, cargaremos, preprocesaremos, entrenaremos y evaluaremos ejecutando el código Python localmente. Por último, crearemos una aplicación FastAPI y la desplegaremos en Hugging Face utilizando Docker.
Si eres nuevo en la IA, los Fundamentos de la IA es un buen punto de partida. Te ayudará a aprender sobre temas populares de IA como ChatGPT y grandes modelos lingüísticos.

Imagen del autor
OpenAI ha presentado el modelo o1, una nueva IA diseñada para realizar tareas de razonamiento similares a las humanas, incluida la resolución de problemas de varios pasos, ecuaciones matemáticas complicadas y preguntas de codificación.
Antes de responder a una pregunta difícil, o1 utiliza una cadena de pensamiento cuando intenta resolver un problema. A través de aprendizaje por refuerzoo1 afina su cadena de pensamiento y refina las estrategias que utiliza. Aprende a reconocer y corregir sus errores.
El modelo o1 está disponible en dos variantes: o1-preview y o1-mini.
El o1-preview se utiliza para preguntas de razonamiento profundo, mientras que el o1-mini es un modelo más rápido ideal para problemas de codificación y matemáticas. Ambos modelos están disponibles para los usuarios de ChatGPT Plus y Team. Si eres una organización de nivel 5, también puedes acceder a ellos a través de la API OpenAI.
La versión actual del modelo carece de funciones como la navegación web, la carga de archivos y el REPL de Python, que OpenAI tiene previsto añadir en futuras actualizaciones.
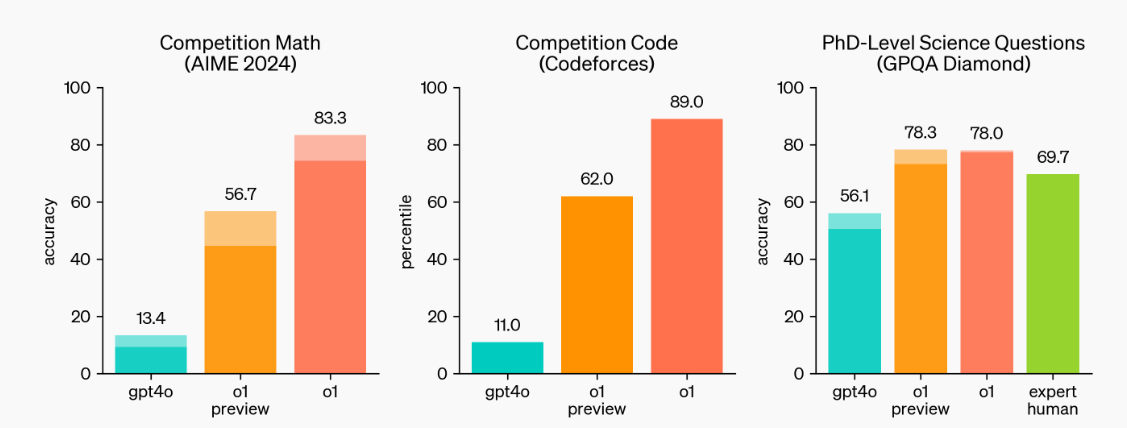
Fuente: Aprender a razonar con LLMs | OpenAI
Como podemos ver, los modelos o1-preview y o1 están estableciendo nuevos puntos de referencia. Destacaron en competiciones de matemáticas y codificación y pueden manejar las preguntas científicas de los estudiantes de doctorado.
Lee la GuíaOpenAI o1: Cómo funciona, casos de uso, API y más para analizarlo en profundidad y conocer en detalle cómo funciona y sus puntos de referencia.
Hay muchos modelos o1 de fácil acceso, pero los oficiales se obtienen a través de la API OpenAI o utilizando la suscripción ChatGPT Plus o Team.
En esta sección, aprenderemos cómo podemos utilizarlos para resolver problemas complejos.
Si estás familiarizado con la API de OpenAI para completar chats, tienes que establecer el nombre del modelo en "o1-preview" y proporcionar una indicación detallada. Es así de sencillo.
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": "Create an SQL database from scratch, including guides on usage and code everything in Python."
}
]
)
print(response.choices[0].message.content)Para acceder a ella en ChatGPT, tienes que hacer clic en la opción desplegable de selección de modelo y seleccionar el modelo "o1-preview", como se muestra a continuación.
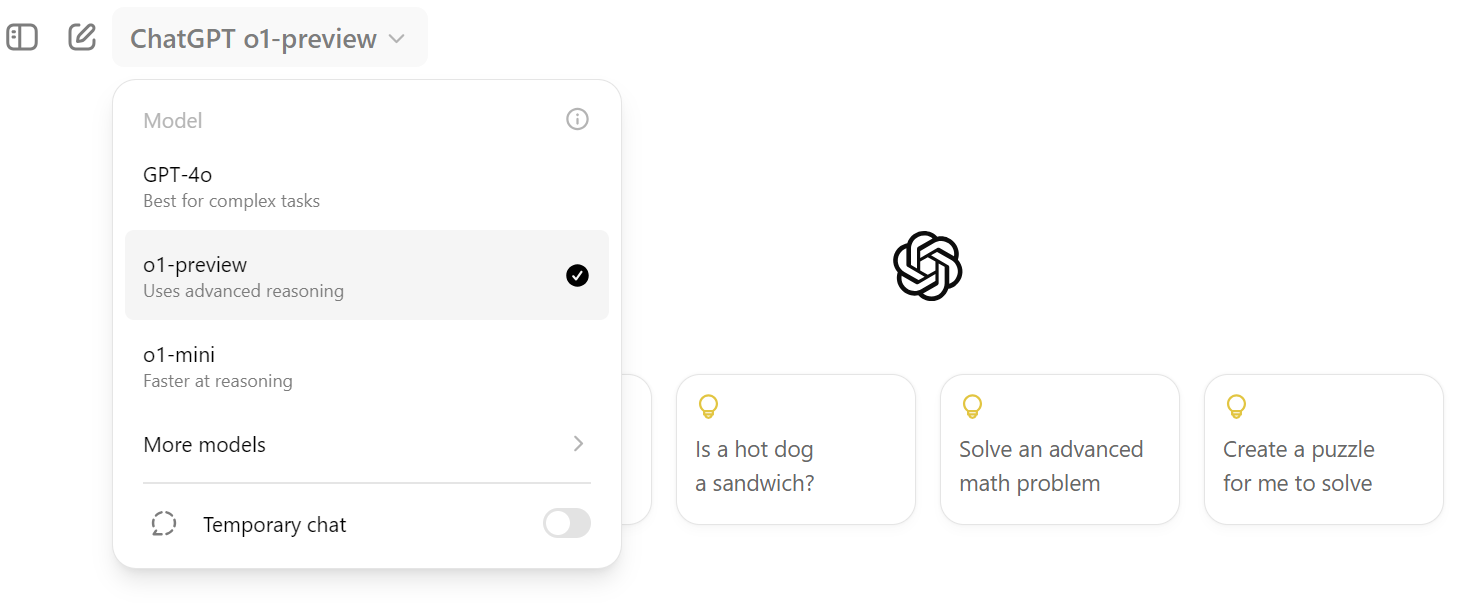
Las indicaciones del modelo o1 son diferentes. Tienes que proporcionarle múltiples instrucciones o preguntas detalladas para que se dé cuenta plenamente de su poder. Generar una respuesta óptima puede requerir una instrucción larga y compleja.
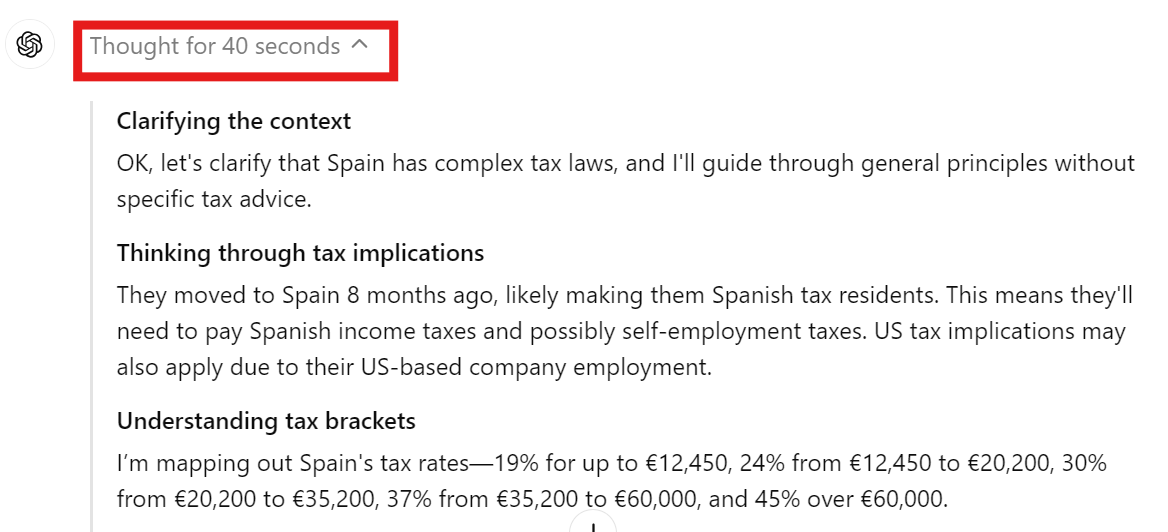
Calcular los impuestos de un negocio autónomo en Europa puede ser complejo. Utilizaremos el modelo o1 para determinar nuestra deuda tributaria con el gobierno español.
Prompt: "Soy un autónomo en España que trabaja para una empresa con sede en EE.UU.. Durante el año pasado, he ganado 120.000 USD, y necesito calcular la cantidad de impuestos que debo. Ten en cuenta que me mudé a España hace 8 meses."
Tardó casi 30 segundos en responder, pero la respuesta fue detallada. Incluía ecuaciones matemáticas, información fiscal y todos los detalles necesarios para determinar cuánto debíamos al gobierno español.
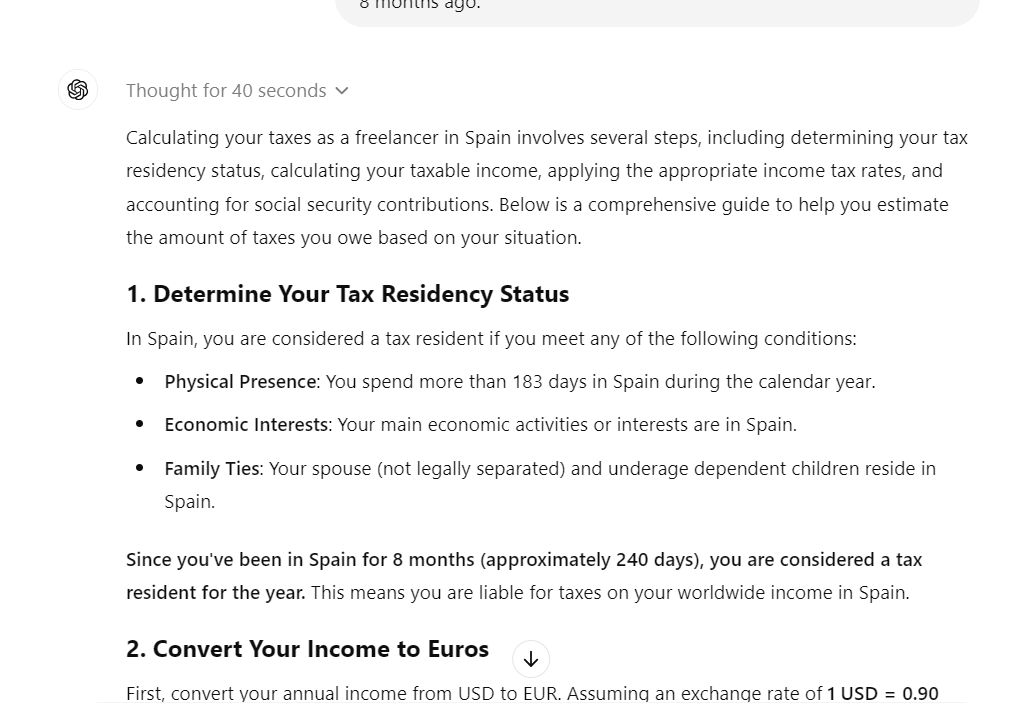
La respuesta se dividió en las siguientes partes:
Revisar la sección de resumen nos proporciona la cantidad aproximada de impuestos que debemos al gobierno, lo cual es bastante útil.

Puedes hacer clic en el menú desplegable de la respuesta del chat para ver la cadena de pensamiento y la toma de decisiones.
Podemos comprobar que el modelo entiende el contexto, las implicaciones fiscales y el tramo impositivo antes de responder a tu pregunta.
El modelo o1-mini es menos preciso pero más rápido que el modelo o1-preview. En nuestro caso, utilizaremos este modelo para crear un sitio web estático para currículos de ciencias de datos.
Prompt: "Por favor, crea un sitio web estático para mi currículum de ciencia de datos utilizando un framework de Python".
No sólo creó un sitio web de currículum adecuado, sino que también nos orientó sobre cómo publicarlo en páginas de GitHub de forma gratuita.
La respuesta se dividió en las siguientes partes:
Es una función fantástica para mostrar la cadena de pensamiento en la respuesta. Podemos ver claramente que el modelo está considerando utilizar Pelican, Flask o Hugo como marco web. Al final, ha seleccionado la mejor solución posible.
En este proyecto, utilizaremos el modelo o1-preview para construir y desplegar una aplicación de clasificación de la calidad del agua. Se trata de un proyecto bastante complejo, ya que le proporcionaremos una descripción detallada de lo que buscamos.
Si estás interesado en crear un proyecto de ciencia de datos utilizando ChatGPT, consulta Guía para utilizar ChatGPT en proyectos de ciencia de datos. Aprenderás a utilizar ChatGPT para la planificación de proyectos, el análisis de datos, el preprocesamiento de datos, la selección de modelos, el ajuste de hiperparámetros, el desarrollo de una aplicación web y su despliegue.
Dedicaremos más tiempo a la ingeniería rápida, ya que queremos asegurarnos de que todas las directrices del proyecto se proporcionan al modelo.
El aviso se divide en tres partes:
Lee Guía para principiantes sobre la ingeniería de instrucciones de ChatGPT para aprender a escribir prompts adecuados en ChatGPT y generar los resultados requeridos. La ingeniería rápida es un arte, y con la introducción del modelo o1, se ha hecho más necesario aprenderlo.
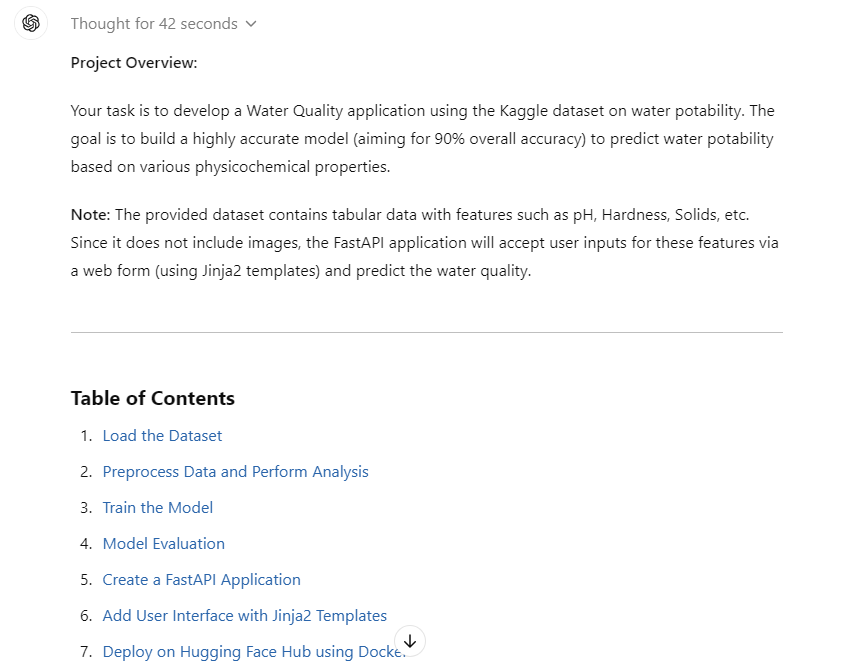
Prompt: "Mi jefe de proyecto nos ha encargado que desarrollemos una aplicación sobre la calidad del agua utilizando el conjunto de datos de Kaggle disponible en https://www.kaggle.com/datasets/adityakadiwal/water-potability. Facilítanos toda la información necesaria sobre los archivos, los paquetes Python y el código para que podamos construir un modelo de gran precisión.
El objetivo es alcanzar una precisión global del 90%.
Sigue los pasos para construir el proyecto:
1. Carga el conjunto de datos desde Kaggle utilizando la API y descomprímelo en la carpeta de datos.
2. Preprocesa los datos y realiza algunos análisis de datos. Guarda las cifras y archivos del análisis en la carpeta de métricas.
3. Entrena el modelo utilizando el marco scikit-learn. Asegúrate de hacer un seguimiento de los experimentos y de guardar los archivos del modelo y los metadatos. Guarda el modelo utilizando la biblioteca skops.
4. Realiza una evaluación detallada del modelo y guarda los resultados.
5. Crea una aplicación FastAPI que tome una imagen del usuario y prediga la calidad del agua.
6. Asegúrate de añadir la interfaz de usuario utilizando plantillas Jinja2.
7. Despliega la app en el hub Hugging Face utilizando la opción Docker."
La respuesta generada nos ha proporcionado toda la información que necesitamos para cargar los datos, preprocesarlos, entrenar y evaluar el modelo, crear la aplicación FastAPI, crear una interfaz de usuario y desplegarla.
La cuestión es que está fragmentado y queremos que cree archivos Python y HTML para que nos baste con copiar y pegar el código.
Ahora convertiremos todo el código en archivos Python y HTML, lo que nos facilitará aún más la vida.
Pregunta de seguimiento: "Por favor, convierte el código en los archivos Python" .
Como podemos ver, tenemos una estructura de proyecto con todos los archivos y el código en ella. Todo lo que tenemos que hacer es crear carpetas y archivos y copiar y pegar el código.
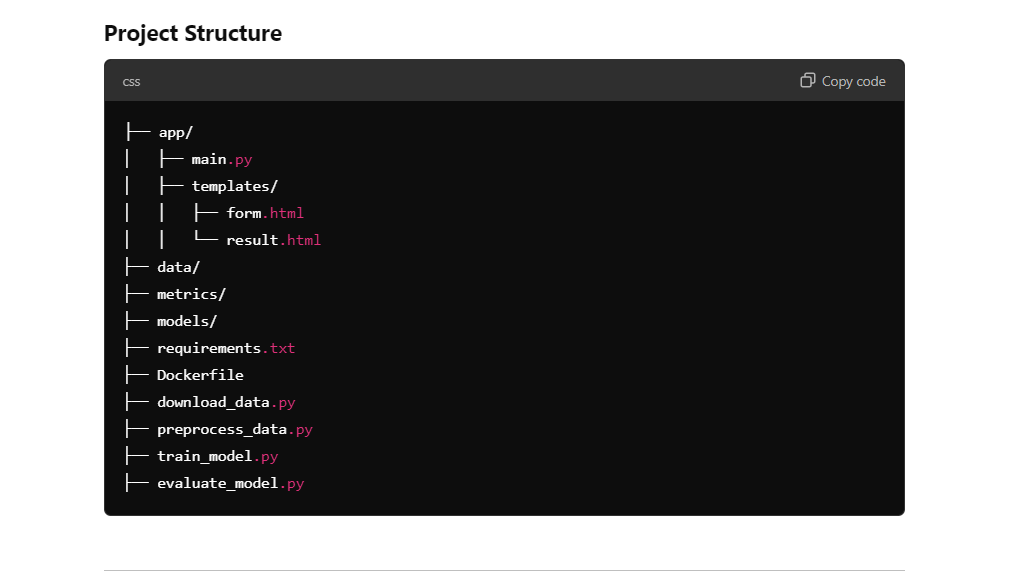
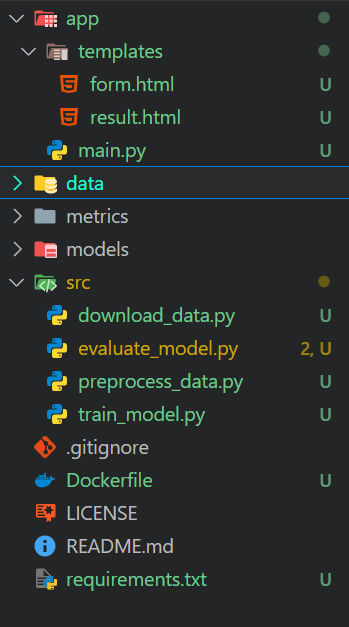
El modelo o1 proporciona toda la información necesaria para crear un directorio de proyecto. Simplemente tenemos que crear carpetas y archivos dentro del directorio del proyecto utilizando el editor de código.
Crearemos las siguientes carpetas:
Además, el directorio principal contendrá el archivo Dockerfile, README y requirements.txt.
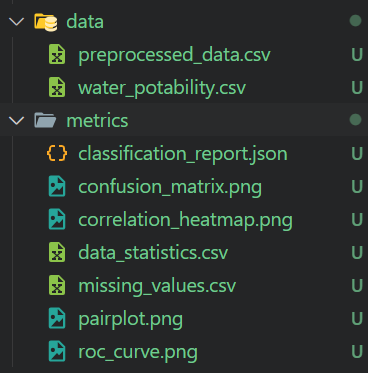
Cargaremos la Calidad del agua mediante la API de Kaggle y lo descomprimiremos en la carpeta de datos.
data\download_data.py:
import os
# Ensure the data directory exists
os.makedirs("data", exist_ok=True)
# Download the dataset
os.system("kaggle datasets download -d adityakadiwal/water-potability -p data --unzip")Al ejecutar el archivo Python se descargará el conjunto de datos, se descomprimirá y se eliminará el archivo zip.
$ python .\src\download_data.py
Dataset URL: https://www.kaggle.com/datasets/adityakadiwal/water-potability
License(s): CC0-1.0
Downloading water-potability.zip to data
100%|████████████████████████████████████████████████████████████████████████████████| 251k/251k [00:00<00:00, 304kB/s]
100%|████████████████████████████████████████████████████████████████████████████████| 251k/251k [00:00<00:00, 303kB/s]El archivo Python de preprocesamiento cargará los datos, los limpiará, tratará los datos que falten, los escalará y, a continuación, guardará el escalador y el conjunto de datos preprocesado. También realizará el análisis de los datos y guardará las métricas y la visualización de los datos.
data\preprocess_data.py:
import os
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
import joblib
# Create directories if they don't exist
os.makedirs("metrics", exist_ok=True)
os.makedirs("models", exist_ok=True)
# Load the dataset
data = pd.read_csv("data/water_potability.csv")
# Check for missing values and save the summary
missing_values = data.isnull().sum()
missing_values.to_csv("metrics/missing_values.csv")
# Statistical summary
stats = data.describe()
stats.to_csv("metrics/data_statistics.csv")
# Pair plot
sns.pairplot(data, hue="Potability")
plt.savefig("metrics/pairplot.png")
# Correlation heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(data.corr(), annot=True)
plt.savefig("metrics/correlation_heatmap.png")
# Handle missing values
imputer = SimpleImputer(strategy="mean")
data_imputed = pd.DataFrame(imputer.fit_transform(data), columns=data.columns)
# Feature scaling
scaler = StandardScaler()
features = data_imputed.drop("Potability", axis=1)
target = data_imputed["Potability"]
features_scaled = scaler.fit_transform(features)
# Save the scaler
joblib.dump(scaler, "models/scaler.joblib")
# Save preprocessed data
preprocessed_data = pd.DataFrame(features_scaled, columns=features.columns)
preprocessed_data["Potability"] = target
preprocessed_data.to_csv("metrics/preprocessed_data.csv", index=False)$ python .\src\preprocess_data.py Obtuvimos datos preprocesados y todos los informes de análisis de datos con cifras.
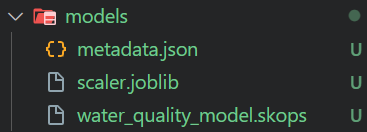
El script de entrenamiento carga los datos preprocesados y los utiliza para entrenar un clasificador Random Forest. A continuación, se utiliza Skope para guardar el modelo, seguir el experimento manualmente y guardar los metadatos del modelo como un archivo JSON.
src\train_model.py:
import os
import json
import skops.io as sio
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# Load preprocessed data
data = pd.read_csv("metrics/preprocessed_data.csv")
features = data.drop("Potability", axis=1)
target = data["Potability"]
# Split the data
X_train, X_test, y_train, y_test = train_test_split(
features, target, test_size=0.2, random_state=42, stratify=target
)
# Train the model
model = RandomForestClassifier(n_estimators=200, random_state=42)
model.fit(X_train, y_train)
# Save the model using skops
os.makedirs("models", exist_ok=True)
sio.dump(model, "models/water_quality_model.skops")
# Track experiments and save metadata
metadata = {
"model_name": "RandomForestClassifier",
"parameters": model.get_params(),
"training_score": model.score(X_train, y_train),
}
with open("models/metadata.json", "w") as f:
json.dump(metadata, f, indent=4)$ python .\src\train_model.py El script de entrenamiento generará un archivo de modelo y metadatos, como se muestra a continuación.
El script de evaluación del modelo carga los datos procesados y el modelo guardado para generar un informe de clasificación, una matriz de confusión, una curva ROC, un AUC y una precisión global. Todas las métricas y cifras se guardan en la carpeta de métricas.
src\evaluate_model.py :
import os
import json
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import (
classification_report,
confusion_matrix,
roc_auc_score,
roc_curve,
)
import skops.io as sio
from sklearn.model_selection import train_test_split
# Load preprocessed data
data = pd.read_csv("metrics/preprocessed_data.csv")
features = data.drop("Potability", axis=1)
target = data["Potability"]
# Split the data
X_train, X_test, y_train, y_test = train_test_split(
features, target, test_size=0.2, random_state=42, stratify=target
)
# Load the model
model = sio.load("models/water_quality_model.skops")
# Predictions
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1]
# Classification report
report = classification_report(y_test, y_pred, output_dict=True)
with open("metrics/classification_report.json", "w") as f:
json.dump(report, f, indent=4)
# Confusion matrix
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt="d")
plt.title("Confusion Matrix")
plt.ylabel("Actual Label")
plt.xlabel("Predicted Label")
plt.savefig("metrics/confusion_matrix.png")
# ROC curve and AUC
fpr, tpr, _ = roc_curve(y_test, y_pred_proba)
roc_auc = roc_auc_score(y_test, y_pred_proba)
plt.figure()
plt.plot(fpr, tpr, label="AUC = %0.2f" % roc_auc)
plt.plot([0, 1], [0, 1], "k--")
plt.legend(loc="lower right")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("Receiver Operating Characteristic")
plt.savefig("metrics/roc_curve.png")
# Overall accuracy
accuracy = model.score(X_test, y_test)
print(f"Overall Accuracy: {accuracy * 100:.2f}%")$ python .\src\evaluate_model.py La precisión general no es muy buena. Sin embargo, siempre podemos pedir al modelo o1 que mejore la precisión.
Overall Accuracy: 65.55%La carpeta de métricas contiene todas las cifras y métricas guardadas de la evaluación del modelo. Podemos revisarlo manualmente para comprender en detalle el rendimiento del modelo.
Para crear una interfaz de usuario para la aplicación FastAPI, tenemos que crear las páginas índice y de resultados. Esto puede hacerse creando una carpeta de plantillas dentro del directorio de la app y añadiendo dos archivos HTML: uno para la página principal y otro para la página de resultados.
Consulta el tutorial FastAPI de: Introducción al uso de FastAPI para conocer en detalle el marco FastAPI y cómo puedes implementarlo en tu proyecto .
Si no estás familiarizado con HTML, no te preocupes. Sólo tienes que copiar y pegar el código y confiar en el modelo o1.
app\templates\form.html:
<!DOCTYPE html>
<html>
<head>
<title>Water Quality Prediction</title>
</head>
<body>
<h2>Enter Water Parameters</h2>
<form action="/predict" method="post">
{% for feature in ['ph', 'Hardness', 'Solids', 'Chloramines', 'Sulfate', 'Conductivity', 'Organic_carbon', 'Trihalomethanes', 'Turbidity'] %}
<label for="{{ feature }}">{{ feature.replace('_', ' ').title() }}:</label><br>
<input type="number" step="any" id="{{ feature }}" name="{{ feature }}" required><br><br>
{% endfor %}
<input type="submit" value="Predict">
</form>
</body>
</html>app\templates\result.html:
<!DOCTYPE html>
<html>
<head>
<title>Prediction Result</title>
</head>
<body>
<h2>Prediction Result</h2>
<p>The water is predicted to be: <strong>{{ result }}</strong></p>
<a href="/">Try Again</a>
</body>
</html>El archivo Python de la aplicación principal tiene dos funciones Python: inicio y predecir. La función "inicio" muestra la página de bienvenida con casillas de entrada y un botón. La función "predecir" transforma la entrada del usuario, la hace pasar por el modelo y muestra el resultado indicando si el agua es potable o no.
app\templates\main.py:
from fastapi import FastAPI, Request, Form
from fastapi.responses import HTMLResponse
from fastapi.templating import Jinja2Templates
import numpy as np
import skops.io as sio
import joblib
app = FastAPI()
templates = Jinja2Templates(directory="app/templates")
# Load the saved model and preprocessing pipeline
model = sio.load("models/water_quality_model.skops", trusted=True)
preprocessing_pipeline = joblib.load("models/preprocessing_pipeline.joblib")
@app.get("/", response_class=HTMLResponse)
async def home(request: Request):
return templates.TemplateResponse("form.html", {"request": request})
@app.post("/predict", response_class=HTMLResponse)
async def predict(
request: Request,
ph: float = Form(...),
Hardness: float = Form(...),
Solids: float = Form(...),
Chloramines: float = Form(...),
Sulfate: float = Form(...),
Conductivity: float = Form(...),
Organic_carbon: float = Form(...),
Trihalomethanes: float = Form(...),
Turbidity: float = Form(...),
):
input_data = np.array(
[
[
ph,
Hardness,
Solids,
Chloramines,
Sulfate,
Conductivity,
Organic_carbon,
Trihalomethanes,
Turbidity,
]
]
)
# Preprocess input data
input_preprocessed = preprocessing_pipeline.transform(input_data)
prediction = model.predict(input_preprocessed)
result = "Potable" if prediction[0] == 1 else "Not Potable"
return templates.TemplateResponse(
"result.html", {"request": request, "result": result}
)Primero probaremos la aplicación localmente para comprobar si funciona.
$ uvicorn app.main:app --reload Ejecutando el archivo Python mediante uvicorn, obtenemos la dirección local que podemos copiar y pegar en nuestro navegador.
Nota: El modelo o1 también proporciona toda la información sobre cómo ejecutar los archivos.
INFO: Will watch for changes in these directories: ['C:\\Repository\\GitHub\\Water-Quality-App']
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [34792] using StatReloadComo podemos ver, la aplicación funciona correctamente.
Proporcionémosle los valores aleatorios para comprobar la calidad del agua y pulsemos el botón predecir.
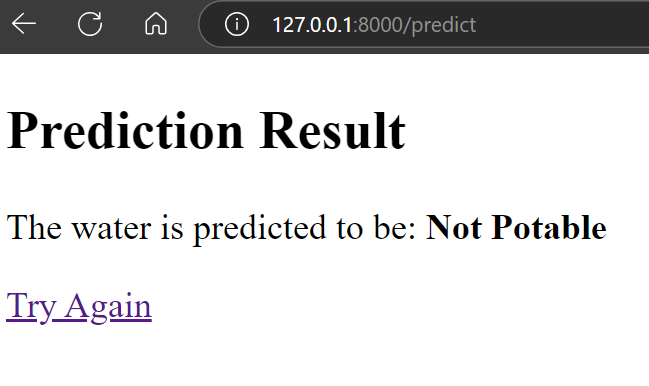
El resultado es asombroso. Demuestra que el agua no es potable.
Incluso puedes acceder a la Swagger UI de FastAPI escribiendo "/docs" después de la URL para probar la API y generar los resultados.
El modelo OpenAI o1 ha generado el código Docker, una guía y enlaces de referencia para que aprendamos con éxito a desplegar la aplicación en Hugging Face.
Lee Docker para la Ciencia de Datos: Una introducción tutorial para aprender cómo funciona Docker. Aprenderás a configurar Docker, a utilizar comandos Docker, a dockerizar aplicaciones de aprendizaje automático y a seguir las mejores prácticas del sector.
En primer lugar, crea un nuevo Espacio haciendo clic en la foto de perfil del sitio web de Cara Abrazada y, a continuación, en el botón "Nuevo Espacio". Escribe el nombre de la app, selecciona el tipo de SDK (Docker), elige el tipo de licencia y pulsa "Crear espacio".
Fuente: Cara de abrazo
Todas las instrucciones para desplegar la aplicación utilizando Docker se proporcionan en la página principal.
Fuente: Clasificador de calidad del agua
A continuación, tenemos que clonar el repositorio.
git clone https://huggingface.co/spaces/kingabzpro/Water-Quality-ClassifierDentro del repositorio, mueve las carpetas app y modelo. Crea un Dockerfile y escribe el siguiente comando. El modelo o1 nos ha proporcionado el código; sólo tenemos que cambiar el número de puerto a 7860.
Dockerfile:
# Use an official Python runtime as a parent image
FROM python:3.9-slim
# Set the working directory
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
# Install any needed packages specified in requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Expose port 7860
EXPOSE 7860
# Run the application
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "7860"]Crea el archivo requirements.txt que contiene información sobre los paquetes de Python. Utilizaremos este archivo para descargar e instalar todos los paquetes de Python necesarios en el servidor de la nube.
requisitos.txt:
fastapi
uvicorn
jinja2
pydantic
skops
joblib
numpy
pandas
scikit-learn==1.5.1
matplotlib
seaborn
kaggle
imbalanced-learn
python-multipartEste es el aspecto que debería tener nuestro repositorio de aplicaciones:
Nuestro modelo es un archivo grande (> 10MB), por lo que necesitamos utilizar Git LFS para rastrearlo. Instala Git LFS y rastrea todos los archivos con la extensión ".skops".
git lfs install
git lfs track "*.skops" Etapa todos los cambios, confirma con el mensaje y envíalo al servidor remoto.
git add .
git commit -m "pushing all the files"
git pushVe a la página de tu aplicación en Hugging Face, y verás que está construyendo el contenedor e instalando todos los paquetes necesarios.
Fuente: Clasificador de calidad del agua
Tras unos minutos, la aplicación estará lista para usar. Su aspecto es similar al de la aplicación local. Intentemos proporcionarle los valores de muestra y generar los resultados.
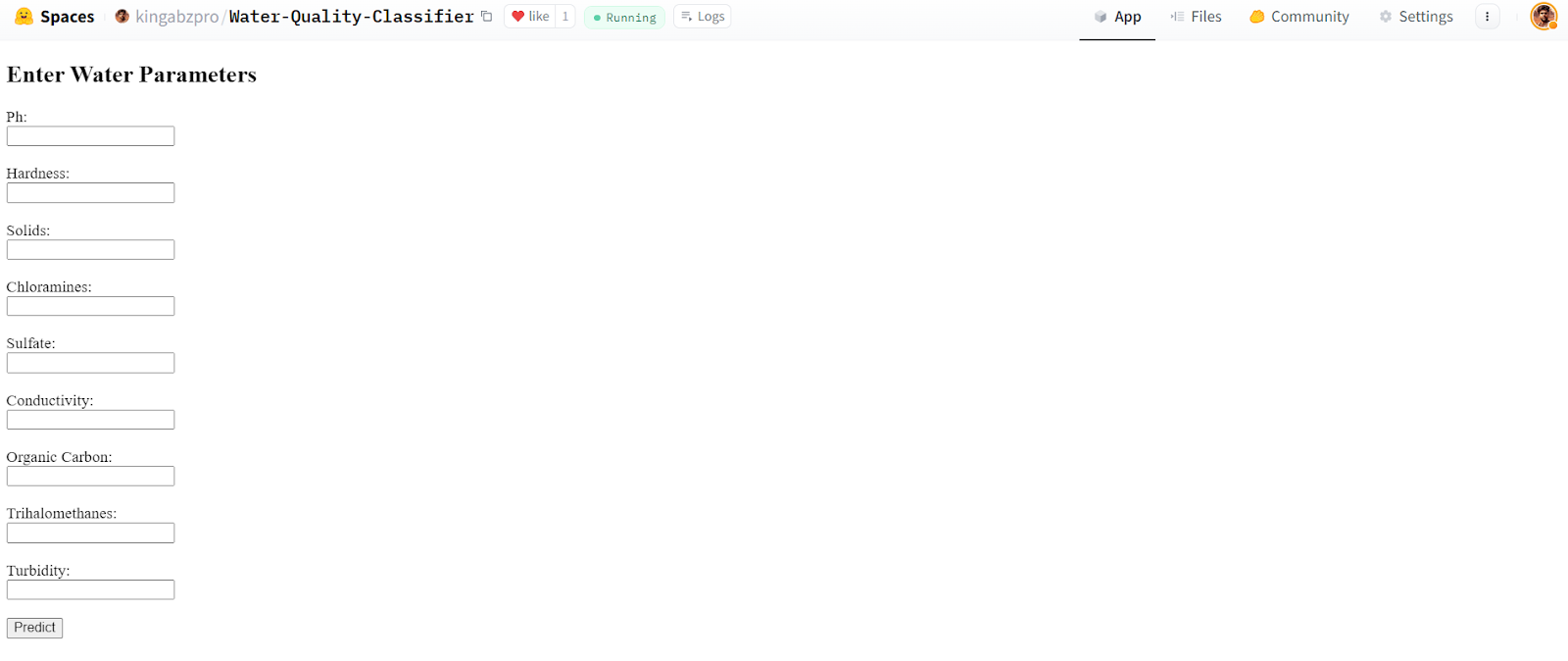
Fuente: Clasificador de calidad del agua
Nuestra aplicación funciona perfectamente y ha producido los resultados esperados.
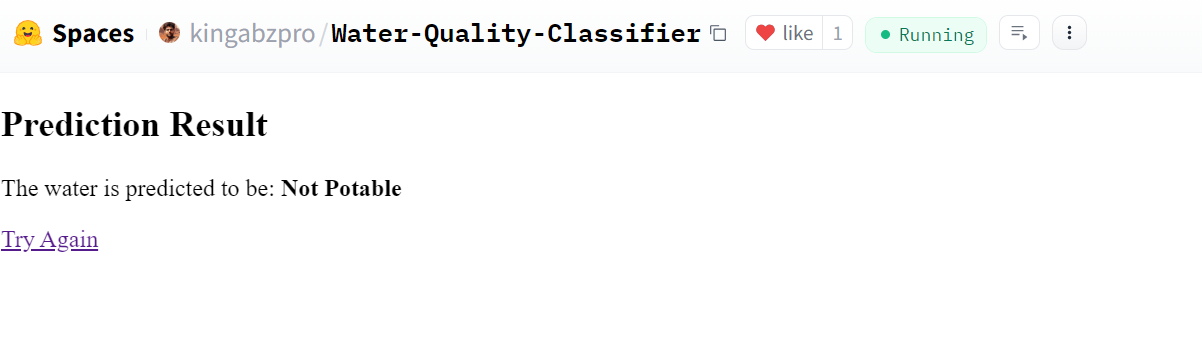
Fuente: Clasificador de calidad del agua
Esta aplicación Hugging Face Space está disponible para que cualquiera pueda utilizarla, lo que significa que podemos acceder a ella utilizando el comando curl en el terminal.
curl -X 'POST' \
'https://kingabzpro-water-quality-classifier.hf.space/predict' \
-H 'accept: text/html' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'Organic_carbon=10&Hardness=200&Turbidity=4&Solids=10000&Chloramines=7&Trihalomethanes=80&Sulfate=300&ph=7&Conductivity=400' \
| grep -oP '(?<=<strong>).*(?=</strong>)'Salida:
Not PotableTodos los archivos del proyecto, datos, modelos y metadatos están disponibles en la página web kingabzpro/Aplicación de Calidad del Agua repositorio de GitHub.
El modelo o1-preview es muy superior al GPT-4o. Sigue perfectamente las instrucciones y no tiene errores, por lo que el código que genera está listo para usar. Al construir la aplicación de aprendizaje automático, sólo tuve que hacer cambios menores, en torno al 5%. Lo mejor es que también aprendí de la toma de decisiones del modelo de IA, comprendiendo por qué tomaba determinadas decisiones.
Abid Ali Awan
Los mejores cursos de OpenAI
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Arunn Thevapalan
Tutorial
Zoumana Keita


