
Curso
Trabalhar com a API da OpenAI
3 h
141.6K
Neste tutorial, criaremos um aplicativo classificador de qualidade da água do zero e o implantaremos na nuvem usando o Docker.
Começaremos explorando o modelo o1 da OpenAI e entendendo sua funcionalidade. Em seguida, acessaremos o modelo via API e ChatGPT, experimentando as versões o1-preview e o1-mini, antes de desenvolver prompts eficazes para criar um aplicativo classificador de qualidade da água.
Quando tivermos a saída, adicionaremos o código e os arquivos fornecidos pelo modelo o1 à pasta do projeto e, em seguida, carregaremos, pré-processaremos, treinaremos e avaliaremos executando o código Python localmente. Por fim, criaremos um aplicativo FastAPI e o implantaremos no Hugging Face usando o Docker.
Se você é novo em IA, os Fundamentos de IA é um ótimo lugar para você começar. Ele ajudará você a aprender sobre tópicos populares de IA, como ChatGPT e modelos de linguagem grandes.

Imagem do autor
A OpenAI apresentou o modelo o1, uma nova IA projetada para executar tarefas de raciocínio semelhantes às humanas, incluindo a solução de problemas de várias etapas, equações matemáticas complicadas e questões de codificação.
Antes de responder a uma pergunta difícil, o1 usa uma cadeia de pensamento ao tentar resolver um problema. Por meio da aprendizado por reforçoo1 aprimora sua cadeia de raciocínio e refina as estratégias que usa. Ela aprende a reconhecer e corrigir seus erros.
O modelo o1 está disponível em duas variantes: o1-preview e o1-mini.
O o1-preview é usado para perguntas de raciocínio profundo, enquanto o o1-mini é um modelo mais rápido, ideal para problemas de codificação e matemática. Ambos os modelos estão disponíveis para usuários do ChatGPT Plus e Team. Se você for uma organização de nível 5, também poderá acessá-los por meio da API da OpenAI.
A versão atual do modelo carece de recursos como navegação na Web, upload de arquivos e Python REPL, que a OpenAI planeja adicionar em atualizações futuras.
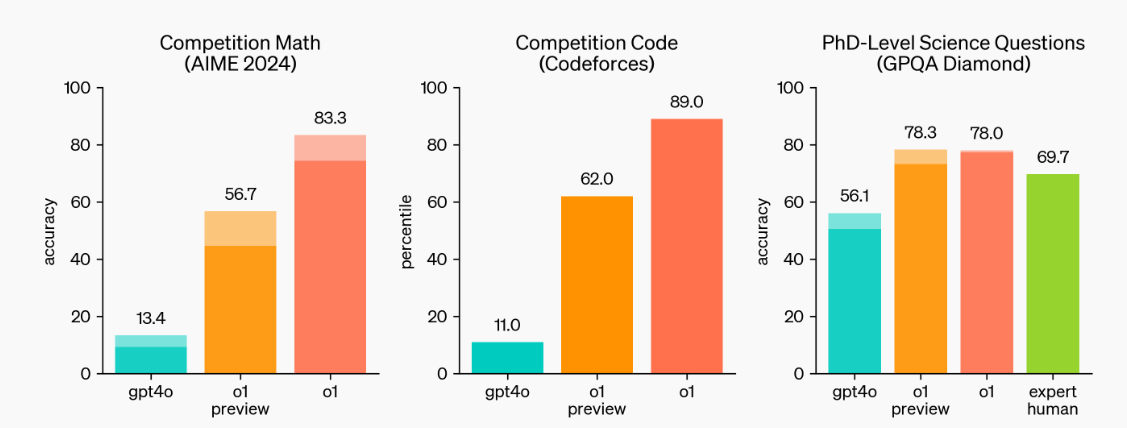
Fonte: Aprendendo a raciocinar com LLMs | OpenAI
Como podemos ver, os modelos o1-preview e o1 estão estabelecendo novos padrões de referência. Eles se destacaram em competições de matemática e codificação e podem lidar com as questões científicas dos alunos de doutorado.
Leia o guiaOpenAI o1: How It Works, Use Cases, API & More para uma análise aprofundada e para que você saiba como ele funciona e seus benchmarks em detalhes.
Há muitos modelos o1 de fácil acesso, mas os oficiais são obtidos por meio da API da OpenAI ou usando a assinatura do ChatGPT Plus ou Team.
Nesta seção, aprenderemos como podemos usá-los para resolver problemas complexos.
Se você estiver familiarizado com a API da OpenAI para conclusão de bate-papo, será necessário definir o nome do modelo como "o1-preview" e fornecer um prompt detalhado. É simples assim.
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": "Create an SQL database from scratch, including guides on usage and code everything in Python."
}
]
)
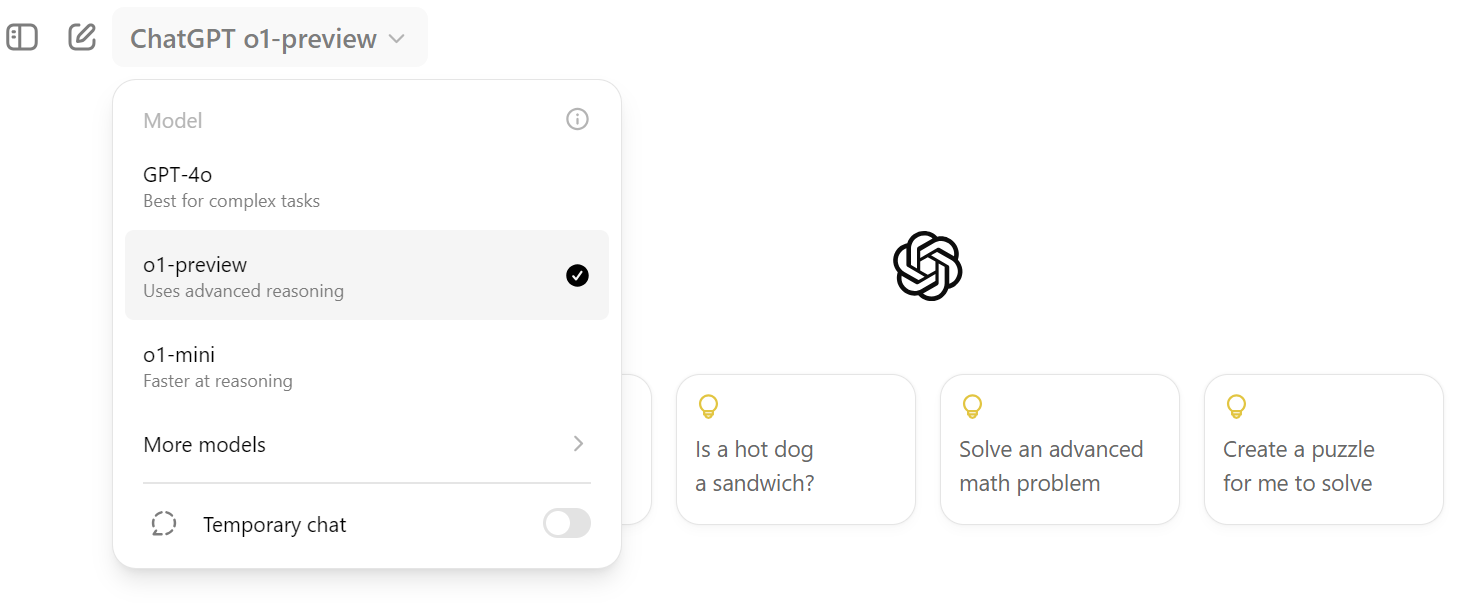
print(response.choices[0].message.content)Para acessá-lo no ChatGPT, você deve clicar na opção suspensa de seleção de modelo e selecionar o modelo "o1-preview", conforme mostrado abaixo.
Os prompts do modelo o1 são diferentes. Você precisa fornecer várias instruções ou perguntas detalhadas para que ele perceba totalmente seu poder. Pode ser necessária uma instrução longa e complexa para gerar uma resposta ideal.
O cálculo de impostos para uma empresa autônoma na Europa pode ser complexo. Usaremos o modelo o1 para determinar nossa obrigação fiscal com o governo espanhol.
Sugestão: "Sou freelancer na Espanha e trabalho para uma empresa sediada nos EUA. No último ano, ganhei US$ 120.000 e preciso calcular o valor dos impostos que devo. Leve em consideração que me mudei para a Espanha há 8 meses."
Você levou quase 30 segundos para responder, mas a resposta foi detalhada. Ele incluía equações matemáticas, informações fiscais e todos os detalhes necessários para determinar quanto devemos ao governo espanhol.
A resposta foi dividida nas seguintes partes:
A revisão da seção de resumo nos fornece o valor aproximado do imposto devido ao governo, o que é bastante útil.

Você pode clicar no menu suspenso na resposta do bate-papo para visualizar a cadeia de pensamento e a tomada de decisões.
Podemos verificar se o modelo entende o contexto, as implicações fiscais e a faixa de imposto antes de responder à sua pergunta.
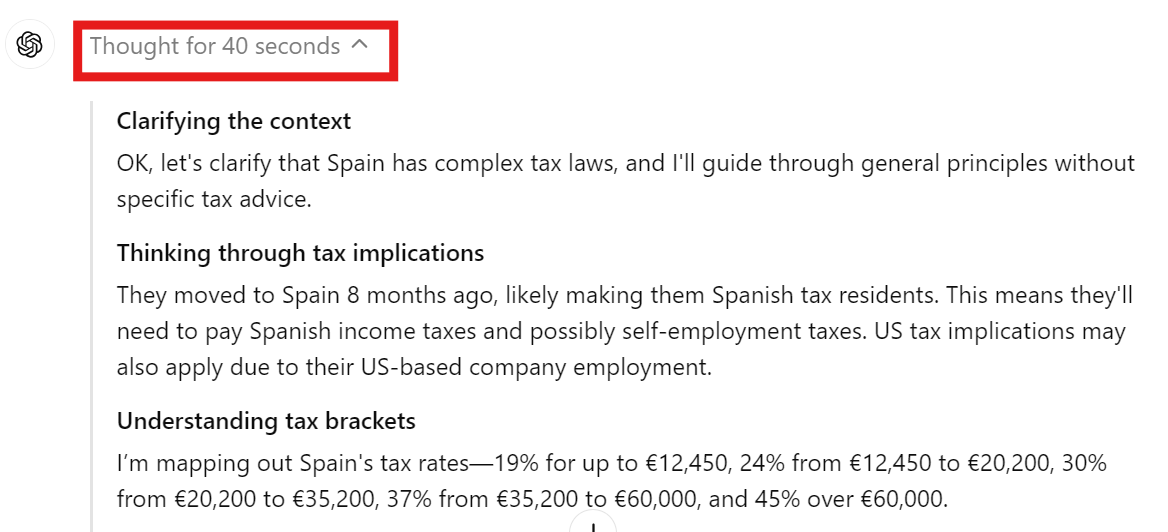
O modelo o1-mini é menos preciso, mas mais rápido do que o modelo o1-preview. No nosso caso, usaremos esse modelo para criar um site estático para currículos de ciência de dados.
Sugestão: "Por favor, crie um site estático para meu currículo de ciência de dados usando uma estrutura Python."
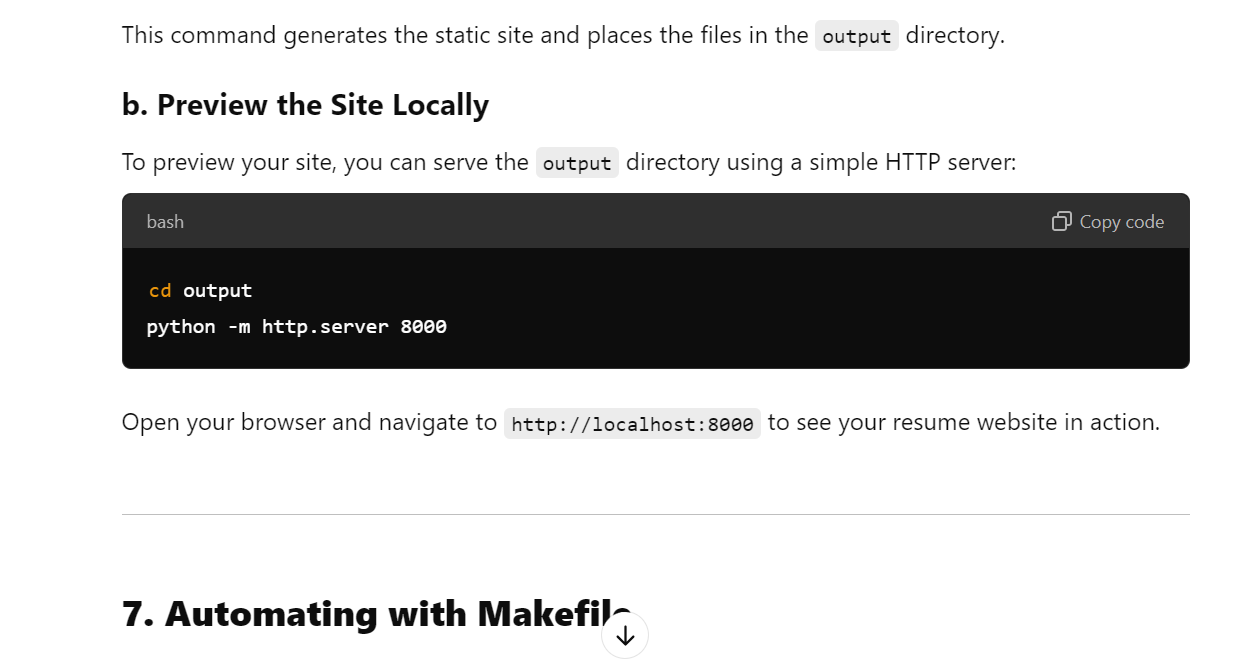
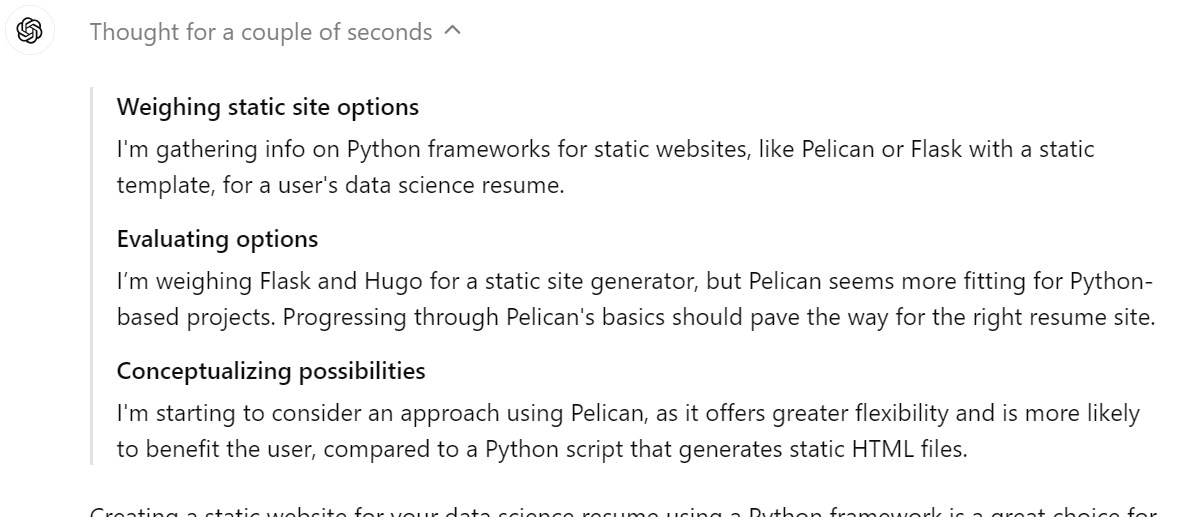
Ele não apenas criou um site de currículo adequado, mas também nos forneceu orientação sobre como publicá-lo nas páginas do GitHub gratuitamente.
A resposta foi dividida nas seguintes partes:
É um recurso fantástico para exibir a cadeia de pensamento na resposta. Podemos ver claramente que o modelo está considerando o uso do Pelican, do Flask ou do Hugo como uma estrutura da Web. No final, ele selecionou a melhor solução possível.
Neste projeto, usaremos o modelo o1-preview para criar e implantar um aplicativo de classificação da qualidade da água. Este é um projeto bastante complexo, pois forneceremos uma descrição detalhada do que estamos procurando.
Se você estiver interessado em criar um projeto de ciência de dados usando o ChatGPT, confira Um guia para usar o ChatGPT em projetos de ciência de dados. Você aprenderá a usar o ChatGPT para planejamento de projetos, análise de dados, pré-processamento de dados, seleção de modelos, ajuste de hiperparâmetros, desenvolvimento e implantação de um aplicativo da Web.
Dedicaremos mais tempo à engenharia imediata, pois queremos garantir que todas as diretrizes do projeto sejam fornecidas ao modelo.
O prompt é dividido em três partes:
Ler Guia para iniciantes em engenharia de prompts do ChatGPT para saber como escrever prompts adequados no ChatGPT e gerar os resultados necessários. A engenharia imediata é uma arte e, com a introdução do modelo o1, tornou-se mais necessário aprender.
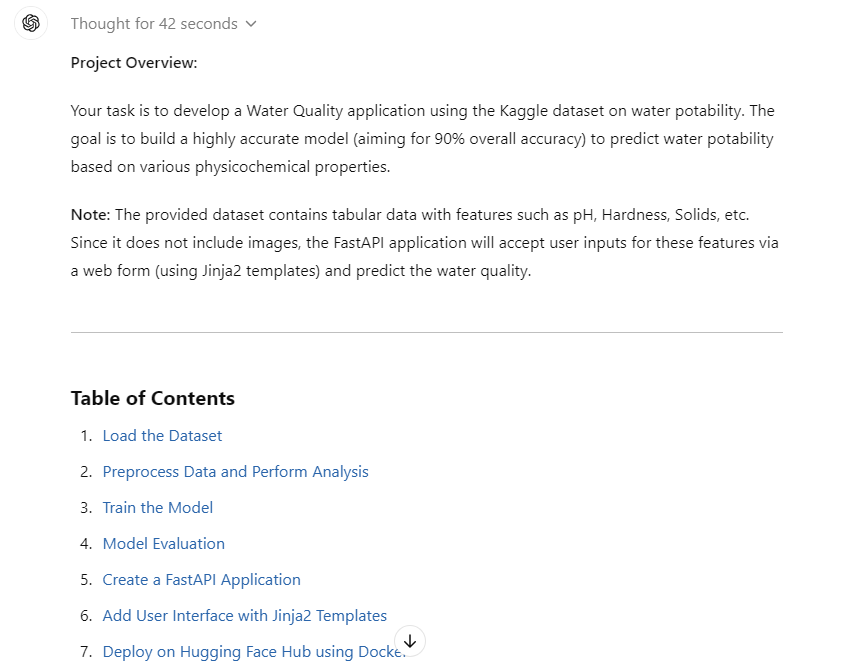
Sugestão: "Meu gerente de projeto nos encarregou de desenvolver um aplicativo de qualidade da água usando o conjunto de dados do Kaggle disponível em https://www.kaggle.com/datasets/adityakadiwal/water-potability. Forneça todas as informações necessárias sobre os arquivos, os pacotes Python e o código para que possamos criar um modelo altamente preciso.
A meta é atingir 90% de precisão geral.
Siga as etapas para criar o projeto:
1. Carregue o conjunto de dados do Kaggle usando a API e descompacte-o na pasta de dados.
2. Pré-processar os dados e realizar algumas análises de dados. Salve as figuras e os arquivos de análise na pasta de métricas.
3. Treine o modelo usando a estrutura do scikit-learn. Certifique-se de que você rastreie os experimentos e salve os arquivos de modelo e os metadados. Salve o modelo usando a biblioteca skops.
4. Realize a avaliação detalhada do modelo e salve os resultados.
5. Crie um aplicativo FastAPI que pegue uma imagem do usuário e preveja a qualidade da água.
6. Certifique-se de adicionar a interface do usuário usando modelos Jinja2.
7. Implemente o aplicativo no hub Hugging Face usando a opção do Docker."
A resposta gerada nos forneceu todas as informações de que precisamos para carregar os dados, pré-processá-los, treinar e avaliar o modelo, criar o aplicativo FastAPI, criar uma interface de usuário e implantá-lo.
O problema é que ele está fragmentado e queremos que ele crie arquivos Python e HTML para que possamos simplesmente copiar e colar o código.
Agora, converteremos todo o código em arquivos Python e HTML, facilitando ainda mais nossa vida.
Solicitação de acompanhamento: "Converta o código em arquivos Python."
Como podemos ver, temos uma estrutura de projeto com todos os arquivos e códigos nela. Tudo o que você precisa fazer é criar pastas e arquivos e copiar e colar o código.
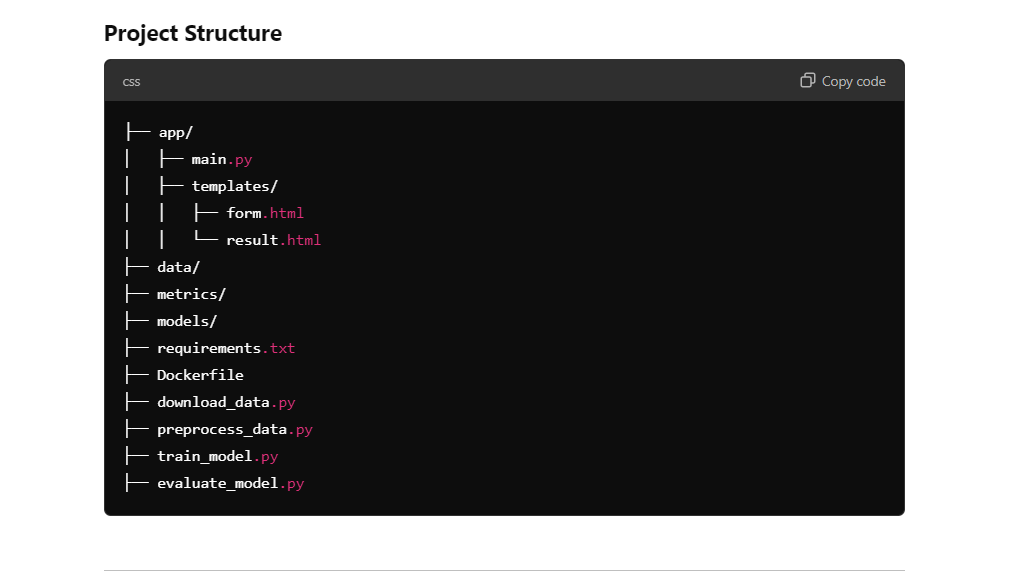
O modelo o1 fornece todas as informações necessárias para configurar um diretório de projeto. Você só precisa criar pastas e arquivos no diretório do projeto usando o editor de código.
Criaremos as seguintes pastas:
Além disso, o diretório principal conterá o Dockerfile, o README e o arquivo requirements.txt.
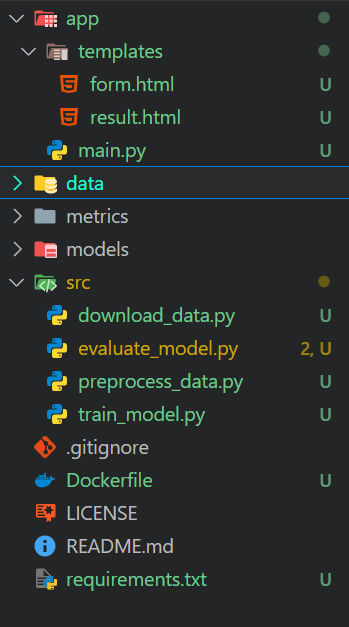
Carregaremos o Qualidade da água do Kaggle usando a API do Kaggle e descompactando-o na pasta de dados.
data\download_data.py:
import os
# Ensure the data directory exists
os.makedirs("data", exist_ok=True)
# Download the dataset
os.system("kaggle datasets download -d adityakadiwal/water-potability -p data --unzip")Ao executar o arquivo Python, você fará o download do conjunto de dados, descompactará e removerá o arquivo zip.
$ python .\src\download_data.py
Dataset URL: https://www.kaggle.com/datasets/adityakadiwal/water-potability
License(s): CC0-1.0
Downloading water-potability.zip to data
100%|████████████████████████████████████████████████████████████████████████████████| 251k/251k [00:00<00:00, 304kB/s]
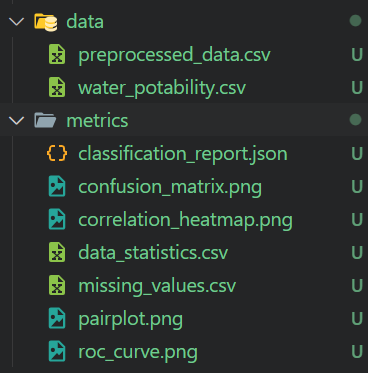
100%|████████████████████████████████████████████████████████████████████████████████| 251k/251k [00:00<00:00, 303kB/s]O arquivo Python de pré-processamento carregará os dados, os limpará, tratará os dados ausentes, os dimensionará e, em seguida, salvará o dimensionador e o conjunto de dados pré-processados. Ele também realizará a análise de dados e salvará as métricas e a visualização de dados.
data\preprocess_data.py:
import os
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
import joblib
# Create directories if they don't exist
os.makedirs("metrics", exist_ok=True)
os.makedirs("models", exist_ok=True)
# Load the dataset
data = pd.read_csv("data/water_potability.csv")
# Check for missing values and save the summary
missing_values = data.isnull().sum()
missing_values.to_csv("metrics/missing_values.csv")
# Statistical summary
stats = data.describe()
stats.to_csv("metrics/data_statistics.csv")
# Pair plot
sns.pairplot(data, hue="Potability")
plt.savefig("metrics/pairplot.png")
# Correlation heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(data.corr(), annot=True)
plt.savefig("metrics/correlation_heatmap.png")
# Handle missing values
imputer = SimpleImputer(strategy="mean")
data_imputed = pd.DataFrame(imputer.fit_transform(data), columns=data.columns)
# Feature scaling
scaler = StandardScaler()
features = data_imputed.drop("Potability", axis=1)
target = data_imputed["Potability"]
features_scaled = scaler.fit_transform(features)
# Save the scaler
joblib.dump(scaler, "models/scaler.joblib")
# Save preprocessed data
preprocessed_data = pd.DataFrame(features_scaled, columns=features.columns)
preprocessed_data["Potability"] = target
preprocessed_data.to_csv("metrics/preprocessed_data.csv", index=False)$ python .\src\preprocess_data.py Recebemos dados pré-processados e todos os relatórios de análise de dados com figuras.
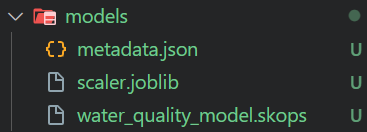
O script de treinamento carrega os dados pré-processados e os usa para treinar um classificador Random Forest. Em seguida, o Skope é usado para salvar o modelo, rastrear o experimento manualmente e salvar os metadados do modelo como um arquivo JSON.
src\train_model.py:
import os
import json
import skops.io as sio
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# Load preprocessed data
data = pd.read_csv("metrics/preprocessed_data.csv")
features = data.drop("Potability", axis=1)
target = data["Potability"]
# Split the data
X_train, X_test, y_train, y_test = train_test_split(
features, target, test_size=0.2, random_state=42, stratify=target
)
# Train the model
model = RandomForestClassifier(n_estimators=200, random_state=42)
model.fit(X_train, y_train)
# Save the model using skops
os.makedirs("models", exist_ok=True)
sio.dump(model, "models/water_quality_model.skops")
# Track experiments and save metadata
metadata = {
"model_name": "RandomForestClassifier",
"parameters": model.get_params(),
"training_score": model.score(X_train, y_train),
}
with open("models/metadata.json", "w") as f:
json.dump(metadata, f, indent=4)$ python .\src\train_model.py O script de treinamento gerará um arquivo de modelo e metadados, conforme mostrado abaixo.
O script de avaliação do modelo carrega os dados processados e o modelo salvo para gerar um relatório de classificação, matriz de confusão, curva ROC, AUC e precisão geral. Todas as métricas e números são salvos na pasta de métricas.
src\evaluate_model.py :
import os
import json
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import (
classification_report,
confusion_matrix,
roc_auc_score,
roc_curve,
)
import skops.io as sio
from sklearn.model_selection import train_test_split
# Load preprocessed data
data = pd.read_csv("metrics/preprocessed_data.csv")
features = data.drop("Potability", axis=1)
target = data["Potability"]
# Split the data
X_train, X_test, y_train, y_test = train_test_split(
features, target, test_size=0.2, random_state=42, stratify=target
)
# Load the model
model = sio.load("models/water_quality_model.skops")
# Predictions
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1]
# Classification report
report = classification_report(y_test, y_pred, output_dict=True)
with open("metrics/classification_report.json", "w") as f:
json.dump(report, f, indent=4)
# Confusion matrix
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt="d")
plt.title("Confusion Matrix")
plt.ylabel("Actual Label")
plt.xlabel("Predicted Label")
plt.savefig("metrics/confusion_matrix.png")
# ROC curve and AUC
fpr, tpr, _ = roc_curve(y_test, y_pred_proba)
roc_auc = roc_auc_score(y_test, y_pred_proba)
plt.figure()
plt.plot(fpr, tpr, label="AUC = %0.2f" % roc_auc)
plt.plot([0, 1], [0, 1], "k--")
plt.legend(loc="lower right")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("Receiver Operating Characteristic")
plt.savefig("metrics/roc_curve.png")
# Overall accuracy
accuracy = model.score(X_test, y_test)
print(f"Overall Accuracy: {accuracy * 100:.2f}%")$ python .\src\evaluate_model.py A precisão geral não é tão boa. No entanto, sempre podemos pedir ao modelo o1 para melhorar a precisão.
Overall Accuracy: 65.55%A pasta de métricas contém todas as figuras e métricas de avaliação de modelo salvas. Podemos revisá-lo manualmente para entender o desempenho do modelo em detalhes.
Para criar uma interface de usuário para o aplicativo FastAPI, precisamos criar as páginas de índice e de resultados. Você pode fazer isso criando uma pasta de modelos no diretório do aplicativo e adicionando dois arquivos HTML: um para a página principal e outro para a página de resultados.
Confira o tutorialFastAPI: An Introduction to Using FastAPI para saber em detalhes sobre a estrutura FastAPI e como você pode implementá-la em seu projeto .
Se você não estiver familiarizado com HTML, não se preocupe. Você só precisa copiar e colar o código e confiar no modelo o1.
app\templates\form.html:
<!DOCTYPE html>
<html>
<head>
<title>Water Quality Prediction</title>
</head>
<body>
<h2>Enter Water Parameters</h2>
<form action="/predict" method="post">
{% for feature in ['ph', 'Hardness', 'Solids', 'Chloramines', 'Sulfate', 'Conductivity', 'Organic_carbon', 'Trihalomethanes', 'Turbidity'] %}
<label for="{{ feature }}">{{ feature.replace('_', ' ').title() }}:</label><br>
<input type="number" step="any" id="{{ feature }}" name="{{ feature }}" required><br><br>
{% endfor %}
<input type="submit" value="Predict">
</form>
</body>
</html>app\templates\result.html:
<!DOCTYPE html>
<html>
<head>
<title>Prediction Result</title>
</head>
<body>
<h2>Prediction Result</h2>
<p>The water is predicted to be: <strong>{{ result }}</strong></p>
<a href="/">Try Again</a>
</body>
</html>O arquivo Python do aplicativo principal tem duas funções Python: home e predict. A função "home" exibe a página de boas-vindas com caixas de entrada e um botão. A função "predict" transforma a entrada do usuário, executa-a no modelo e exibe o resultado indicando se a água é potável ou não.
app\templates\main.py:
from fastapi import FastAPI, Request, Form
from fastapi.responses import HTMLResponse
from fastapi.templating import Jinja2Templates
import numpy as np
import skops.io as sio
import joblib
app = FastAPI()
templates = Jinja2Templates(directory="app/templates")
# Load the saved model and preprocessing pipeline
model = sio.load("models/water_quality_model.skops", trusted=True)
preprocessing_pipeline = joblib.load("models/preprocessing_pipeline.joblib")
@app.get("/", response_class=HTMLResponse)
async def home(request: Request):
return templates.TemplateResponse("form.html", {"request": request})
@app.post("/predict", response_class=HTMLResponse)
async def predict(
request: Request,
ph: float = Form(...),
Hardness: float = Form(...),
Solids: float = Form(...),
Chloramines: float = Form(...),
Sulfate: float = Form(...),
Conductivity: float = Form(...),
Organic_carbon: float = Form(...),
Trihalomethanes: float = Form(...),
Turbidity: float = Form(...),
):
input_data = np.array(
[
[
ph,
Hardness,
Solids,
Chloramines,
Sulfate,
Conductivity,
Organic_carbon,
Trihalomethanes,
Turbidity,
]
]
)
# Preprocess input data
input_preprocessed = preprocessing_pipeline.transform(input_data)
prediction = model.predict(input_preprocessed)
result = "Potable" if prediction[0] == 1 else "Not Potable"
return templates.TemplateResponse(
"result.html", {"request": request, "result": result}
)Primeiro, testaremos o aplicativo localmente para verificar se ele está sendo executado.
$ uvicorn app.main:app --reload Ao executar o arquivo Python usando uvicorn, obtemos o endereço local que pode ser copiado e colado em nosso navegador.
Observação: Todas as informações sobre como executar os arquivos também são fornecidas pelo modelo o1.
INFO: Will watch for changes in these directories: ['C:\\Repository\\GitHub\\Water-Quality-App']
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [34792] using StatReloadComo você pode ver, o aplicativo está funcionando bem.
Vamos fornecer a ele os valores aleatórios para verificar a qualidade da água e pressionar o botão de previsão.
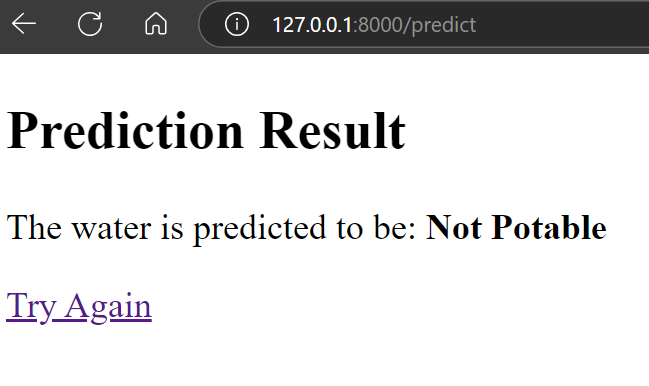
O resultado é incrível. Isso mostra que a água não é potável.
Você pode até mesmo acessar a FastAPI Swagger UI digitando "/docs" após o URL para testar a API e gerar os resultados.
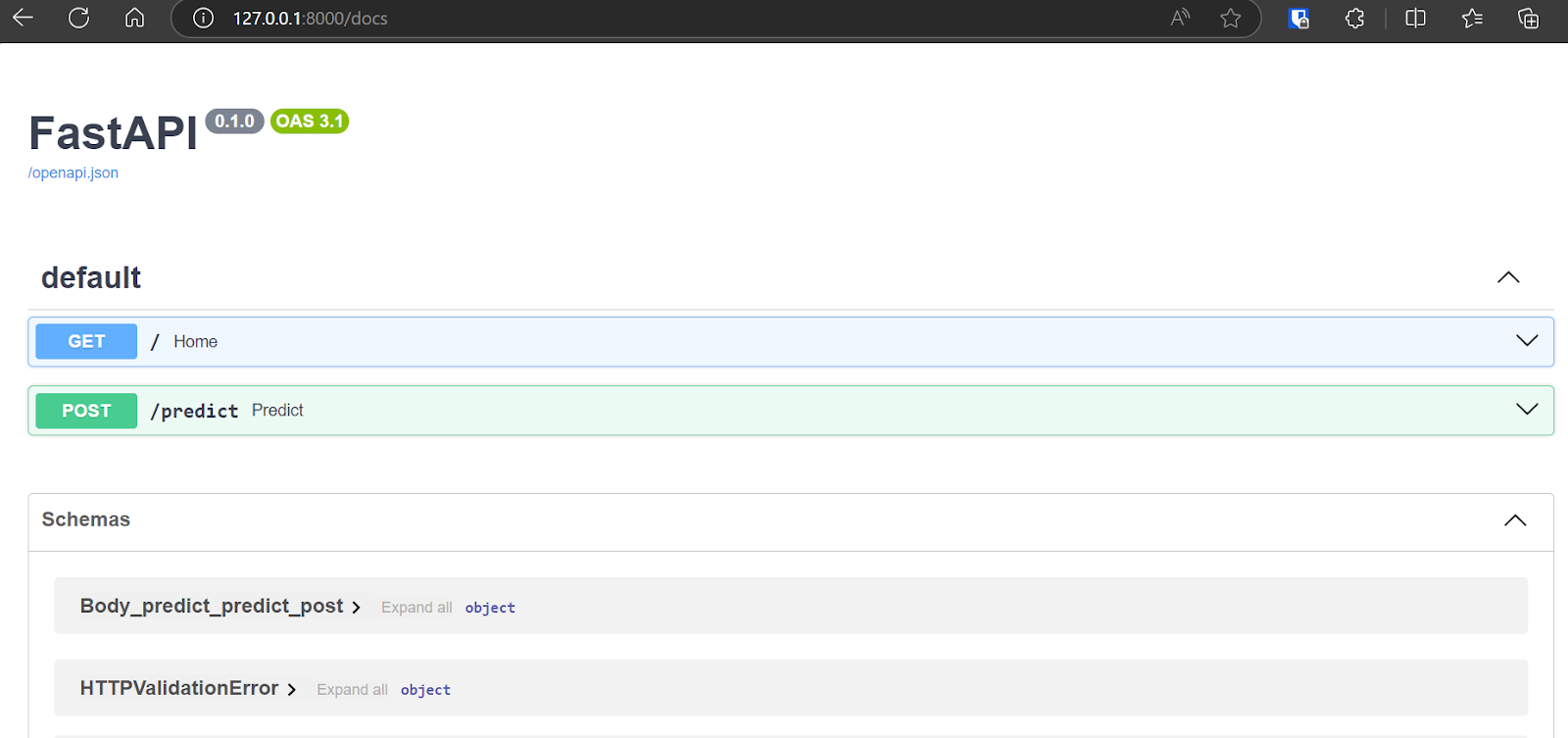
O modelo o1 da OpenAI gerou o código do Docker, um guia e links de referência para que você aprenda a implantar o aplicativo no Hugging Face.
Leia Docker para ciência de dados: Uma introdução tutorial para você aprender como o Docker funciona. Você aprenderá a configurar o Docker, usar comandos do Docker, dockerizar aplicativos de aprendizado de máquina e seguir as práticas recomendadas de todo o setor.
Primeiro, crie um novo espaço clicando na foto do perfil no site do Hugging Face e, em seguida, clicando no botão "New Space" (Novo espaço). Digite o nome do aplicativo, selecione o tipo de SDK (Docker), escolha o tipo de licença e pressione "Create Space".
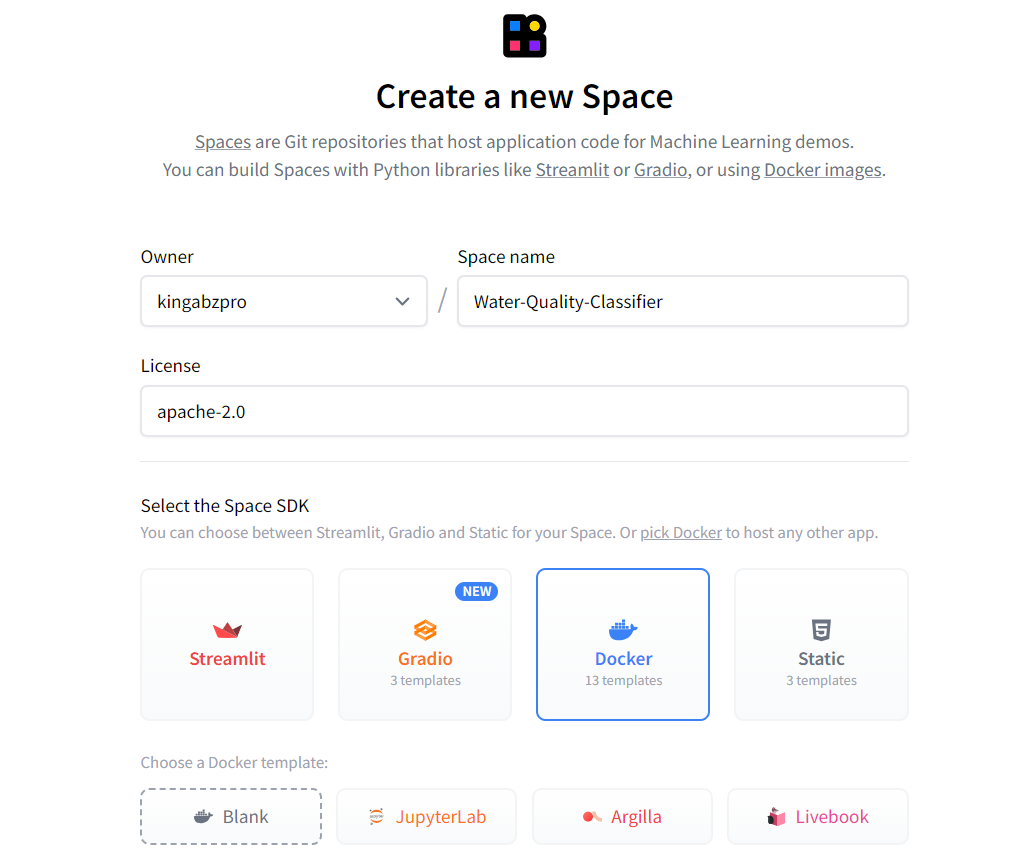
Fonte: Cara de abraço
Todas as instruções para implantar o aplicativo usando o Docker são fornecidas na página principal.
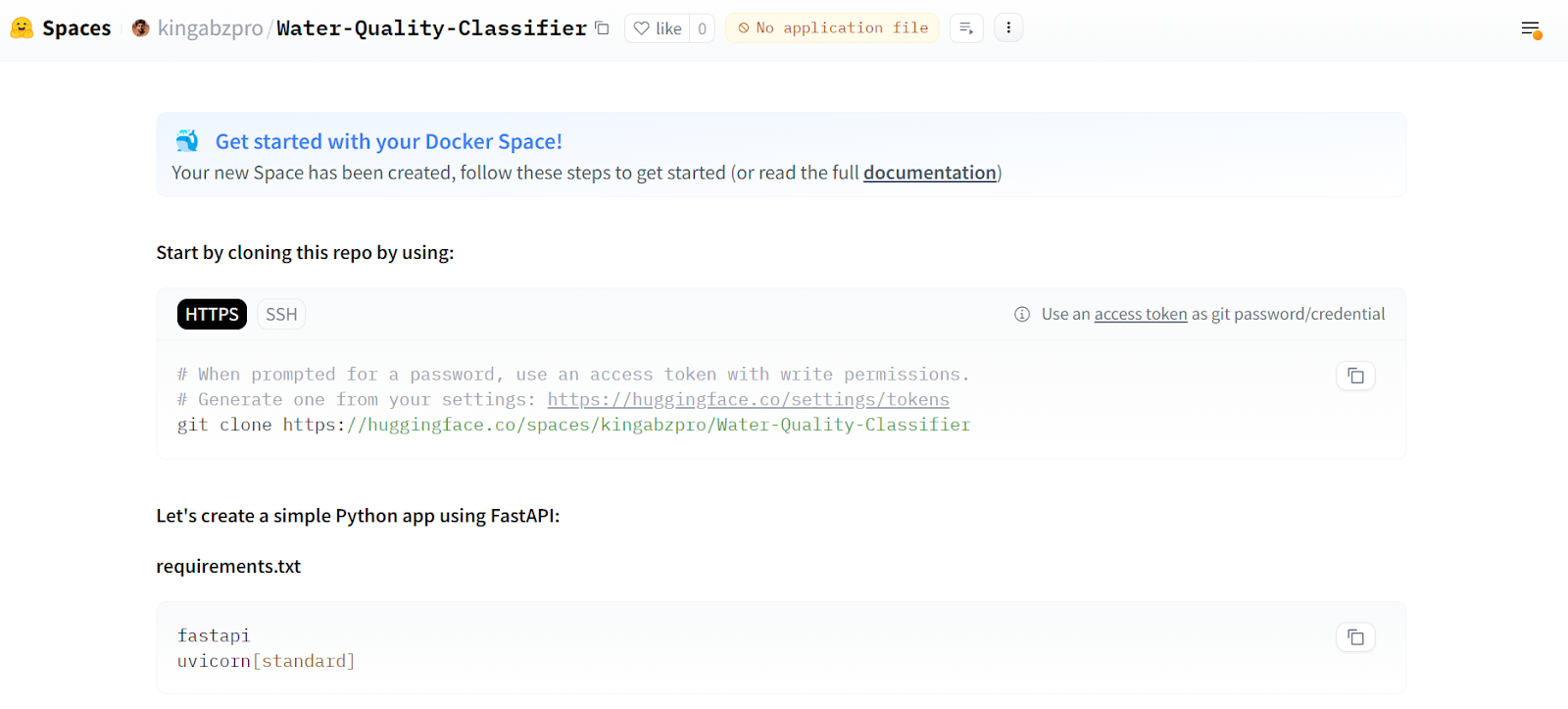
Fonte: Classificador de qualidade da água
Em seguida, temos que clonar o repositório.
git clone https://huggingface.co/spaces/kingabzpro/Water-Quality-ClassifierNo repositório, mova as pastas do aplicativo e do modelo. Crie um Dockerfile e digite o seguinte comando. O modelo o1 nos forneceu o código; só precisamos alterar o número da porta para 7860.
Dockerfile:
# Use an official Python runtime as a parent image
FROM python:3.9-slim
# Set the working directory
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
# Install any needed packages specified in requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Expose port 7860
EXPOSE 7860
# Run the application
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "7860"]Crie o arquivo requirements.txt que contém informações sobre os pacotes Python. Usaremos esse arquivo para baixar e instalar todos os pacotes Python necessários no servidor de nuvem.
requisitos.txt:
fastapi
uvicorn
jinja2
pydantic
skops
joblib
numpy
pandas
scikit-learn==1.5.1
matplotlib
seaborn
kaggle
imbalanced-learn
python-multipartÉ assim que o nosso repositório de aplicativos deve ficar:
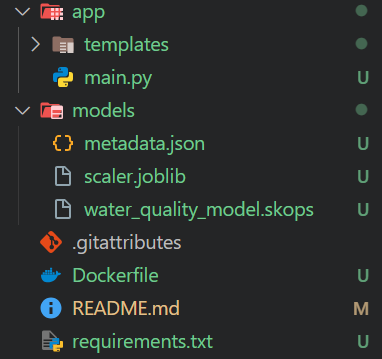
Nosso modelo é um arquivo grande (> 10 MB), portanto, precisamos usar o Git LFS para rastreá-lo. Instale o Git LFS e rastreie todos os arquivos com a extensão ".skops".
git lfs install
git lfs track "*.skops" Prepare todas as alterações, faça o commit com a mensagem e envie-a para o servidor remoto.
git add .
git commit -m "pushing all the files"
git pushVá para a página do aplicativo no Hugging Face e você verá que ele está criando o contêiner e instalando todos os pacotes necessários.
Fonte: Classificador de qualidade da água
Após alguns minutos, o aplicativo estará pronto para ser usado. Ele é semelhante ao aplicativo local. Vamos tentar fornecê-lo com os valores de amostra e gerar os resultados.
Fonte: Classificador de qualidade da água
Nosso aplicativo está funcionando perfeitamente e produziu os resultados esperados.
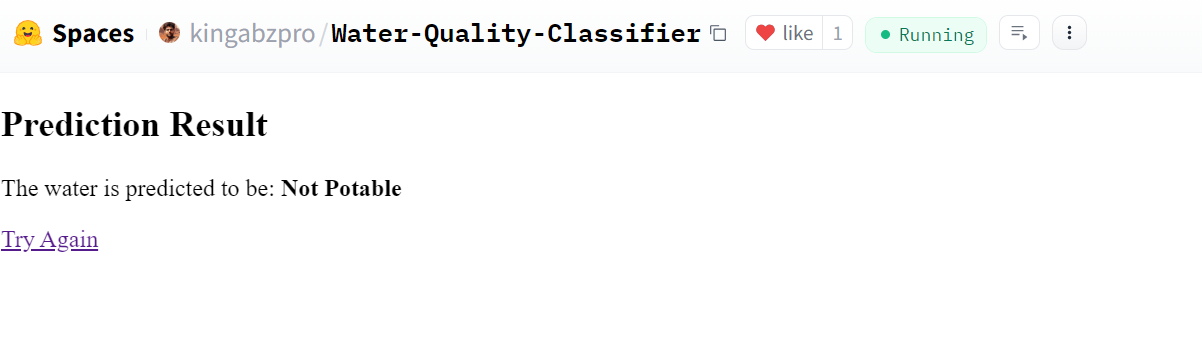
Fonte: Classificador de qualidade da água
Esse aplicativo Hugging Face Space está disponível para uso de qualquer pessoa, o que significa que podemos acessá-lo usando o comando curl no terminal.
curl -X 'POST' \
'https://kingabzpro-water-quality-classifier.hf.space/predict' \
-H 'accept: text/html' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'Organic_carbon=10&Hardness=200&Turbidity=4&Solids=10000&Chloramines=7&Trihalomethanes=80&Sulfate=300&ph=7&Conductivity=400' \
| grep -oP '(?<=<strong>).*(?=</strong>)'Saída:
Not PotableTodos os arquivos, dados, modelos e metadados do projeto estão disponíveis no site kingabzpro/Water-Quality-App no repositório do GitHub.
O modelo o1-preview é muito superior ao GPT-4o. Ele segue as instruções perfeitamente e não tem erros, portanto, o código gerado está pronto para ser usado. Ao criar o aplicativo de aprendizado de máquina, só precisei fazer pequenas alterações, cerca de 5%. A melhor parte é que eu também aprendi com a tomada de decisões do modelo de IA, entendendo por que ele fez determinadas escolhas.
Abid Ali Awan
Principais cursos da OpenAI
Curso
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes
Tutorial
Matt Crabtree
Tutorial
Zoumana Keita

