programa
Associate AI Engineer para desarrolladores
26 h
OpenAI ha lanzado recientemente su tan esperado modelo capaz de "razonamiento PhD", y no es el GPT-5, como muchos pensábamos, sino el OpenAI o1 de OpenAI.
El funcionamiento de OpenAI o1 marca un importante cambio de paradigma en la asignación de recursos computacionales, con más énfasis en las fases de entrenamiento e inferencia. Este enfoque hace que sea extraordinariamente bueno en tareas de razonamiento complejas, pero también muy lento en comparación con sus hermanos, GPT-4o y GPT-4o mini.
Dicho esto GPT-4o y GPT-4o mini siguen siendo las opciones preferidas para aplicaciones que requieran respuestas rápidas, manejo de imágenes o llamadas a funciones. Sin embargo, si tu proyecto exige capacidades de razonamiento avanzadas y puedes tolerar tiempos de respuesta ligeramente más largos, el modelo o1 es el camino a seguir.
He tenido la oportunidad de explorar o1 a través de la API de OpenAI y, en este blog, te guiaré paso a paso sobre cómo hacerlo. Te mostraré cómo conectarte a la API, gestionar los costes y, al final, compartiré algunos consejos para ayudarte a minimizar los gastos y obtener mejores respuestas.
Si buscas un artículo más introductorio, consulta esta Guía OpenAI o1.
Una de las primeras cosas que debes saber es que, por ahora, acceder a los modelos o1 a través de la API requiere un nivel de uso 5.
|
Nivel |
Cualificación |
Límites de uso |
|
Gratis |
El usuario debe estar en una geografía permitida |
100 $ / mes |
|
Nivel 1 |
5$ pagados |
100 $ / mes |
|
Nivel 2 |
50$ pagados y más de 7 días desde el primer pago con éxito |
500 $ / mes |
|
Nivel 3 |
100 $ pagados y más de 7 días desde el primer pago con éxito |
1.000 $ / mes |
|
Nivel 4 |
250 $ pagados y más de 14 días desde el primer pago con éxito |
5.000 $ / mes |
|
Nivel 5 |
1.000 $ pagados y más de 30 días desde el primer pago con éxito |
50.000 $ / mes |
Para comprobar tu nivel de uso, ve a la página de tu cuenta en la plataforma para desarrolladores de OpenAI y busca en la sección Límites, en Organización.
Cada nivel de uso tiene unos límites de tarifa específicos. En el momento de escribir este artículo, estos son los límites de tarifa del Nivel 5:
|
Modelo |
RPM (Peticiones por minuto) |
TPM (Fichas por minuto) |
Límite de la cola de lotes |
|
gpt-4o |
10,000 |
30,000,000 |
5,000,000,000 |
|
gpt-4o-mini |
30,000 |
150,000,000 |
15,000,000,000 |
|
o1-preview |
500 |
30,000,000 |
no se admite actualmente |
|
o1-mini |
1000 |
150,000,000 |
no se admite actualmente |
Los modelos O1 tardan mucho tiempo en procesarse durante la fase de inferencia, lo que explica los límites más bajos de RPM en comparación con los modelos GPT-4o. Ten en cuenta que actualmente los modelos o1 no admiten la agrupación por lotes, lo que significa que no puedes agrupar (agrupar) varias solicitudes al modelo al mismo tiempo.
El modelo O1 aún es nuevo, por lo que estos requisitos y límites de tarifa pueden cambiar en las próximas semanas. Por ejemplo, OpenAI anunció inicialmente que los límites de tarifa semanal serían de 30 mensajes para o1-preview y 50 para o1-mini. Sin embargo, sólo unos días después, actualizaron los límites de tarifa a 50 consultas a la semana para o1-preview y 50 consultas al día para o1-mini.
Pasaremos a la parte práctica dentro de un momento, pero antes aclaremos un nuevo concepto fundamental para utilizar o1 a través de la API: los tokens de razonamiento. Comprender este concepto es esencial para entender tu factura mensual de OpenAI.
Si has utilizado o1-preview a través de la función ChatGPT habrás visto que "piensa en voz alta" antes de generar una respuesta.
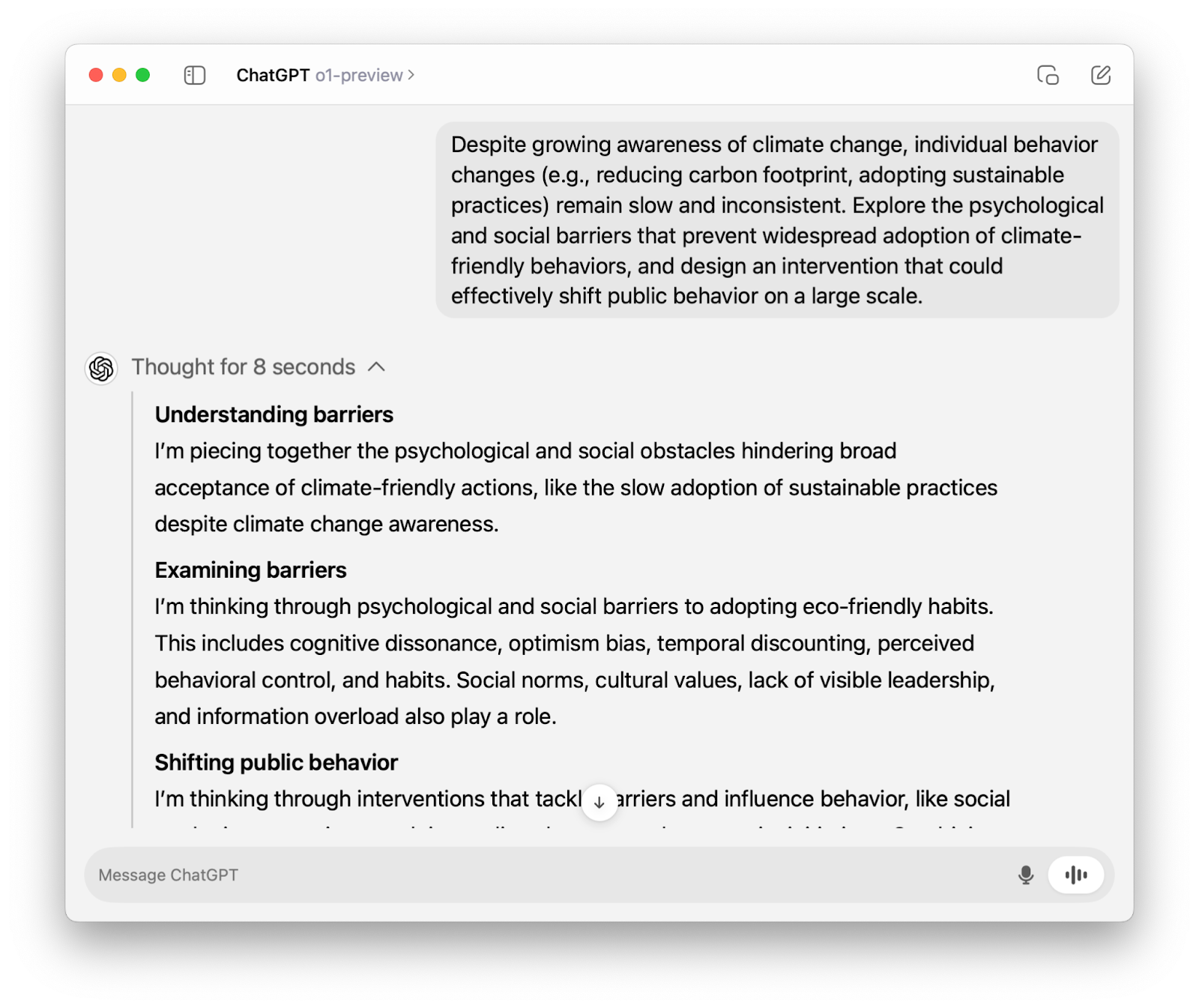
Cuando utilizamos el modelo o1 a través de la API, pasa por el mismo proceso de pensamiento. La única diferencia es que, a diferencia de la interfaz ChatGPT, el razonamiento no es visible, y lo único que vemos es la respuesta final.
Sin embargo, el razonamiento sigue siendo tokenizado (de ahí el nombre de "tokens de razonamiento"), y como habrás adivinado, es facturable. Las fichas de razonamiento se facturan como fichas de salida, que son cuatro veces más caras que las de entrada.
En breve aprenderemos a controlar el número de tokens y a gestionar los costes, pero por ahora vamos a centrarnos en conectarnos a la API de OpenAI para utilizar los modelos o1.
En esta sección, describiremos una serie de pasos que te ayudarán a conectarte al modelo o1-preview a través de la API. Más adelante, también veremos cómo conectar con el modelo o1-mini.
Siempre que tengas una cuenta activa, puedes obtener tu clave secreta de la API en la página de OpenAI de OpenAI.
Si formas parte de una organización, es posible que también necesites el ID de tu organización y un ID de proyecto, que pueden ayudar a tu equipo a gestionar los costes de forma más eficaz. Asegúrate de consultarlo con tu equipo.
Tanto si eres nuevo en las API como si eres un desarrollador experimentado, siempre es una buena idea seguir buenas prácticas de las API.
openai bibliotecaOpenAI facilita la interacción con su API a través de su biblioteca Python openai. Puedes instalarlo utilizando el siguiente comando:
pip install openaiUna vez instalada, importamos la clase OpenAI de la biblioteca openai:
from openai import OpenAIPara interactuar con la API de OpenAI, inicializamos un cliente utilizando nuestra clave secreta de API:
client = OpenAI(api_key=’your-api-key’)Si formas parte de una organización, es posible que también necesites el ID de tu organización y un ID de proyecto, así que este es el aspecto que podría tener este paso para ti:
client = OpenAI(
organization=’your-organization-id’,
project=’your-project-id’,
api_key=’your-api-key’
)Los únicos modelos o1 disponibles en el momento de escribir este artículo son o-1 preview y o1-mini. Ambos están disponibles a través del chat.completions punto final. En el código siguiente, observa que
client.chat.completions.create().”o1-preview” para el parámetro model.”content”.response.choices[0].message.content.response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": "Write a Python script that takes a matrix represented as a string with format '[1,2],[3,4],[5,6]' and prints the transpose in the same format."
}
]
)
print(response.choices[0].message.content)```python
import ast
# Read the input string
s = input()
# Add outer brackets to make it a valid list representation
input_str = '[' + s + ']'
# Safely evaluate the string to a list of lists
matrix = ast.literal_eval(input_str)
# Transpose the matrix
transposed = list(map(list, zip(*matrix)))
# Convert the transposed matrix back to the required string format
transposed_str = ','.join('[' + ','.join(map(str, row)) + ']' for row in transposed)
# Print the result
print(transposed_str)
```Como ya se ha dicho, el razonamiento bajo el capó sigue contando como fichas facturables. Para el código que hemos ejecutado anteriormente, aquí tienes un desglose de todos los tokens utilizados:
print(response.usage)CompletionUsage(completion_tokens=1279, prompt_tokens=43, total_tokens=1322, completion_tokens_details={'reasoning_tokens': 1024})Examinando la salida, vemos que el número de fichas de razonamiento es 1024: completion_tokens_details={'reasoning_tokens': 1024}.
El modelo generó una finalización utilizando 1279 tokens (completion_tokens=1279), de los cuales 1024 eran tokens de razonamiento invisibles: ¡esto supone alrededor del 80%!
La gestión de los costes se complica un poco con los nuevos modelos o1, así que vamos a hablar de ello con más detalle.
En los modelos anteriores, utilizábamos el parámetro max_tokens para controlar el número de fichas de finalización. Las cosas eran bastante sencillas: el número de fichas generadas y el número de fichas visibles eran siempre los mismos.
Con los modelos o1, sin embargo, necesitamos un parámetro que establezca un límite superior para todas las fichas de finalización, incluidas las fichas de salida visibles y las fichas de razonamiento invisibles. Por esta razón, OpenAI añadió el parámetro max_completion_tokens, al tiempo que desaprobó max_tokens y lo hizo incompatible con los modelos o1.
Probemos max_completion_tokens con nuestro ejemplo anterior. Lo pondremos en 300 y veremos qué obtenemos. Para utilizar este nuevo parámetro, ten en cuenta que puedes necesitar una actualización de la biblioteca openai si utilizas versiones anteriores.
response_with_limit = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": "Write a Python script that takes a matrix represented as a string with format '[1,2],[3,4],[5,6]' and prints the transpose in the same format."
}
],
max_completion_tokens=300
)
print(response_with_limit.choices[0].message.content) Observa que no hemos obtenido ninguna salida. ¿Pero seguimos pagando? La respuesta es sí.
print(response_with_limit.usage)CompletionUsage(completion_tokens=300, prompt_tokens=43, total_tokens=343, completion_tokens_details=CompletionTokensDetails(reasoning_tokens=300))Si el modelo o1 alcanza el límite de fichas antes de llegar a una respuesta final, detiene su proceso de razonamiento y no devuelve ninguna salida. Por esta razón, es importante establecer max_completion_tokens en un valor que garantice la salida; de lo contrario, se nos facturarán tanto los tokens de razonamiento como los de entrada sin obtener nada a cambio.
Tendrás que experimentar con el valor exacto de max_completion_tokens en función de tu caso de uso específico, pero OpenAI aconseja reservar al menos 25.000 tokens para el número total de tokens de finalización.
Para evitar una salida truncada (o ninguna salida), también tendrás que tener en cuenta la ventana contextual si tu caso de uso implica un gran número de tokens. Los modelos o1-preview y o-1 mini tienen una ventana de contexto de 128.000 fichas. Ten en cuenta, sin embargo, que los tokens de salida (visibles e invisibles) tienen un límite de 32.768 tokens para o1-preview y de 65.536 tokens para o1-mini.
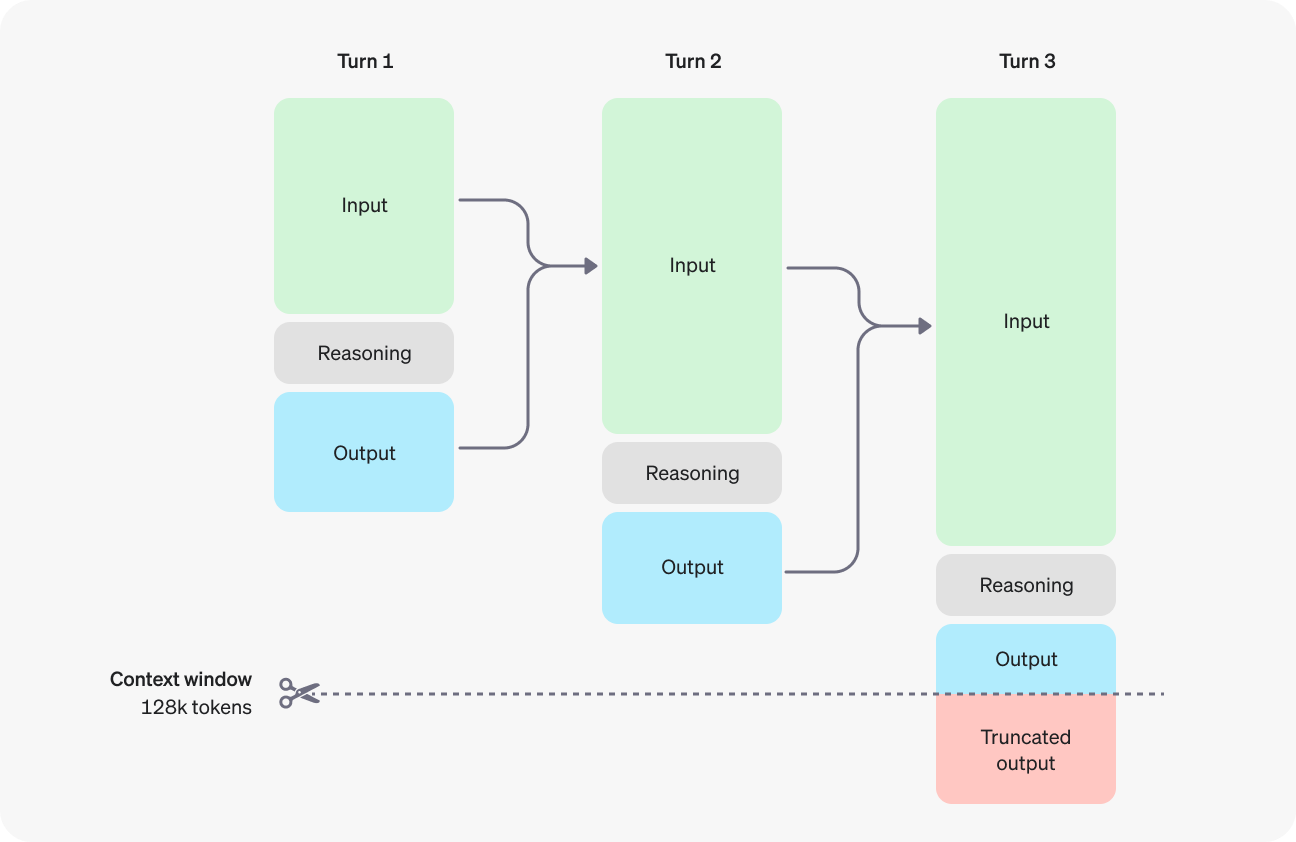
Fuente: OpenAI
El gran modelo o1 es potente en el razonamiento avanzado, pero también es muy lento. Si necesitas tiempos de respuesta más rápidos para tus aplicaciones y estás dispuesto a hacer un pequeño compromiso en el rendimiento del razonamiento, entonces el modelo o1-mini podría ser una mejor elección.
Para conectarte al modelo o1-mini a través de la API, sigue todos los pasos que hemos seguido para el modelo o1-preview, excepto el parámetro model, en el que debes utilizar la cadena ”o1-mini”.
Utilizaremos el mismo indicador que en nuestro último ejemplo, para poder comparar el uso de tokens:
response_mini = client.chat.completions.create(
model="o1-mini",
messages=[
{
"role": "user",
"content": "Write a Python script that takes a matrix represented as a string with format '[1,2],[3,4],[5,6]' and prints the transpose in the same format."
}
]
)
print(response_mini.choices[0].message.content)Certainly! Below is a Python script that takes a matrix represented as a string in the format `'[1,2],[3,4],[5,6]'`, computes its transpose, and prints the transposed matrix in the same string format.
```python
def parse_matrix(matrix_str):
"""
Parses a matrix string like '[1,2],[3,4],[5,6]' into a list of lists.
"""
# Split the string by '],[' to separate the rows
rows = matrix_str.strip().split('],[')
# Clean the first and last elements by removing any leading '[' or trailing ']'
rows[0] = rows[0].lstrip('[')
rows[-1] = rows[-1].rstrip(']')
# Convert each row into a list of integers
matrix = []
for row in rows:
# Split each row by ',' and convert each element to integer
matrix.append([int(num) for num in row.split(',')])
return matrix
def transpose_matrix(matrix):
"""
Transposes a given matrix (list of lists).
"""
# Use zip with unpacking to transpose the matrix
transposed = list(zip(*matrix))
# Convert each tuple in the transposed matrix back to a list
transposed = [list(row) for row in transposed]
return transposed
def matrix_to_string(matrix):
"""
Converts a list of lists into a string format like '[1,3,5],[2,4,6]'.
"""
# Convert each row to a string
row_strings = []
for row in matrix:
# Convert each number to string and join with commas
row_str = ','.join(str(num) for num in row)
# Enclose the row in brackets
row_strings.append(f'[{row_str}]')
# Join all rows with commas
return ','.join(row_strings)
def main():
# Example input
input_str = '[1,2],[3,4],[5,6]'
# Parse the input string into a matrix
matrix = parse_matrix(input_str)
# Compute the transpose of the matrix
transposed = transpose_matrix(matrix)
# Convert the transposed matrix back to string format
output_str = matrix_to_string(transposed)
# Print the result
print(output_str)
if __name__ == "__main__":
main()
```
### How It Works:
1. **Parsing the Input String:**
- The `parse_matrix` function takes the input string and splits it into individual rows by looking for the pattern `"],["`.
- It cleans the first and last rows by removing any leading `[` or trailing `]`.
- Each row string is then split by `,` to extract individual numbers, which are converted to integers and stored in a nested list.
2. **Transposing the Matrix:**
- The `transpose_matrix` function uses the `zip` function along with unpacking (`*`) to transpose the matrix. This effectively switches rows with columns.
- Since `zip` returns tuples, each transposed row is converted back into a list.
3. **Converting Back to String:**
- The `matrix_to_string` function takes the transposed matrix and converts each row back into a string in the desired format.
- It joins the elements of each row with commas and encloses them in brackets.
- Finally, all row strings are joined together with commas to form the final output string.
4. **Main Execution:**
- The `main` function demonstrates the usage with an example input. You can modify `input_str` to test with different matrices.
- It prints the transposed matrix in the specified string format.
### Example:
Given the input string:
```
'[1,2],[3,4],[5,6]'
```
The script will output:
```
[1,3,5],[2,4,6]
```
### Handling User Input:
If you'd like the script to accept user input instead of having a hardcoded string, you can modify the `main` function as follows:
```python
def main():
# Take user input
input_str = input("Enter the matrix string (e.g., '[1,2],[3,4],[5,6]'): ").strip()
# Parse the input string into a matrix
matrix = parse_matrix(input_str)
# Compute the transpose of the matrix
transposed = transpose_matrix(matrix)
# Convert the transposed matrix back to string format
output_str = matrix_to_string(transposed)
# Print the result
print(output_str)
```
With this modification, when you run the script, it will prompt you to enter the matrix string:
```
Enter the matrix string (e.g., '[1,2],[3,4],[5,6]'): [1,2],[3,4],[5,6]
[1,3,5],[2,4,6]
```
### Notes:
- **Error Handling:** The current script assumes that the input string is well-formatted. For production code, you might want to add error handling to manage malformed inputs.
- **Non-integer Elements:** If your matrix contains non-integer elements (e.g., floats or strings), you'll need to adjust the parsing logic accordingly.
### Running the Script:
1. **Save the Script:** Save the above code to a file, say `transpose_matrix.py`.
2. **Run the Script:** Open a terminal or command prompt, navigate to the directory containing the script, and execute:
```bash
python transpose_matrix.py
```
3. **Provide Input:** If you've modified it to accept user input, enter the matrix string when prompted.
This script provides a straightforward way to transpose a matrix represented as a string and can be easily adapted or extended based on specific requirements.La salida visible es mucho más verbosa que la salida de o1-preview: comparemos el uso:
print(response_mini.usage) # o1-mini
print(response.usage) # o1-previewCompletionUsage(completion_tokens=1511, prompt_tokens=43, total_tokens=1554, completion_tokens_details=CompletionTokensDetails(reasoning_tokens=256))
CompletionUsage(completion_tokens=1279, prompt_tokens=43, total_tokens=1322, completion_tokens_details={'reasoning_tokens': 1024})El modelo o1-mini razona cuatro veces menos en comparación con el modelo o1 (256 vs. 256). 1024 fichas de razonamiento). Sin embargo, debido a su respuesta verbosa, el número total de fichas de finalización es en realidad mayor. Aunque o1-mini es bastante más barato que o1-preview, sigue sin ser lo ideal.
Una forma de mitigarlo es mediante ingeniería de avisos-daremos instrucciones al modelo para que evite explicaciones e introducciones y limite su salida a sólo la respuesta.
response_mini_2 = client.chat.completions.create(
model="o1-mini",
messages=[
{
"role": "user",
"content": "Write a Python script that takes a matrix represented as a string with format '[1,2],[3,4],[5,6]' and prints the transpose in the same format. Limit yourself to the answer and don't add explanations or introductions."
}
]
)
print(response_mini_2.choices[0].message.content)```python
import ast
def parse_matrix(matrix_str):
rows = matrix_str.split('],[')
rows[0] = rows[0].lstrip('[')
rows[-1] = rows[-1].rstrip(']')
matrix = [ast.literal_eval(f'[{row}]') for row in rows]
return matrix
def transpose(matrix):
return list(zip(*matrix))
def format_matrix(transposed):
return ','.join([f'[{",".join(map(str, row))}]' for row in transposed])
input_str = '[1,2],[3,4],[5,6]'
matrix = parse_matrix(input_str)
transposed = transpose(matrix)
output_str = format_matrix(transposed)
print(output_str)
```¡Mucho mejor! El número total de fichas de finalización es unas tres veces menor:
print(response_mini_2.usage)CompletionUsage(completion_tokens=487, prompt_tokens=55, total_tokens=542, completion_tokens_details=CompletionTokensDetails(reasoning_tokens=320))En el momento de escribir este tutorial, los modelos o1 aún están en fase beta. Aunque OpenAI ha anunciado planes de funciones adicionales y límites de velocidad más amigables en las próximas semanas, éstas son las limitaciones que encontrarás al utilizar los modelos beta o1:
temperature, top_p, y n se fijan en 1, mientras que presence_penalty y frequency_penalty se fijan en 0.De momento, OpenAI no parece tener mucha competencia en el campo del razonamiento avanzado. De ahí que los precios estén quizá un poco inflados, y como puedes ver, son significativamente más altos en comparación con los modelos GPT-4o:
|
Modelo |
Precios |
|
o1-preview |
15,00 $ / 1M de fichas de entrada |
|
60,00 $ / 1M de fichas de salida |
|
|
o1-mini |
3,00 $ / 1M de fichas de entrada |
|
12,00 $ / 1M de fichas de salida |
|
|
gpt-4o |
5,00 $ / 1M de fichas de entrada |
|
15,00 $ / 1M de fichas de salida |
|
|
gpt-4o-mini |
0,150 $ / 1M de fichas de entrada |
|
0,600 $ / 1M de fichas de salida |
Los modelos o1 son significativamente diferentes de los modelos a los que estamos acostumbrados, como GPT-4o o Claude 3.5 Sonnet. Dado que los modelos o1 ya participan en cadena de pensamiento razonamiento, funcionan mejor con indicaciones directas. Utilizando pocas indicaciones o pedir al modelo que piense "paso a paso" puede, en realidad, degradar su rendimiento.
Estas son algunas de las mejores prácticas recomendadas por los desarrolladores de OpenAI:
A lo largo de este blog, he compartido una guía paso a paso para conectarse a los modelos o1 a través de la API de OpenAI.
Si tu proyecto requiere capacidades de razonamiento avanzadas y puedes acomodar tiempos de respuesta ligeramente más largos, los modelos o1 son opciones excelentes.
Para aplicaciones que requieren respuestas rápidas, procesamiento de imágenes o llamada a funciones, GPT-4o y GPT-4o mini siguen siendo las opciones preferidas.
Para seguir aprendiendo, te recomiendo estos recursos:
Aprende IA con estos cursos
programa
Curso
Curso
Tutorial
Arunn Thevapalan
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes




