programa
Fundamentos de OOP
3 h
GPT-4o mini se deriva del modelo mayor GPT-4o mediante un proceso de destilación. Este proceso consiste en entrenar un modelo más pequeño para que imite el comportamiento y el rendimiento del modelo más grande y complejo, lo que da como resultado una versión rentable pero muy capaz del original.
GPT-4o mini compite con modelos como Llama 3 8B, Gemini 1.5 Flash y Claude Haiku, así como el propio GPT-3.5 Turbo de OpenAI. Estos modelos ofrecen funcionalidades similares, pero a menudo tienen un coste más elevado o unas métricas de rendimiento menos avanzadas.
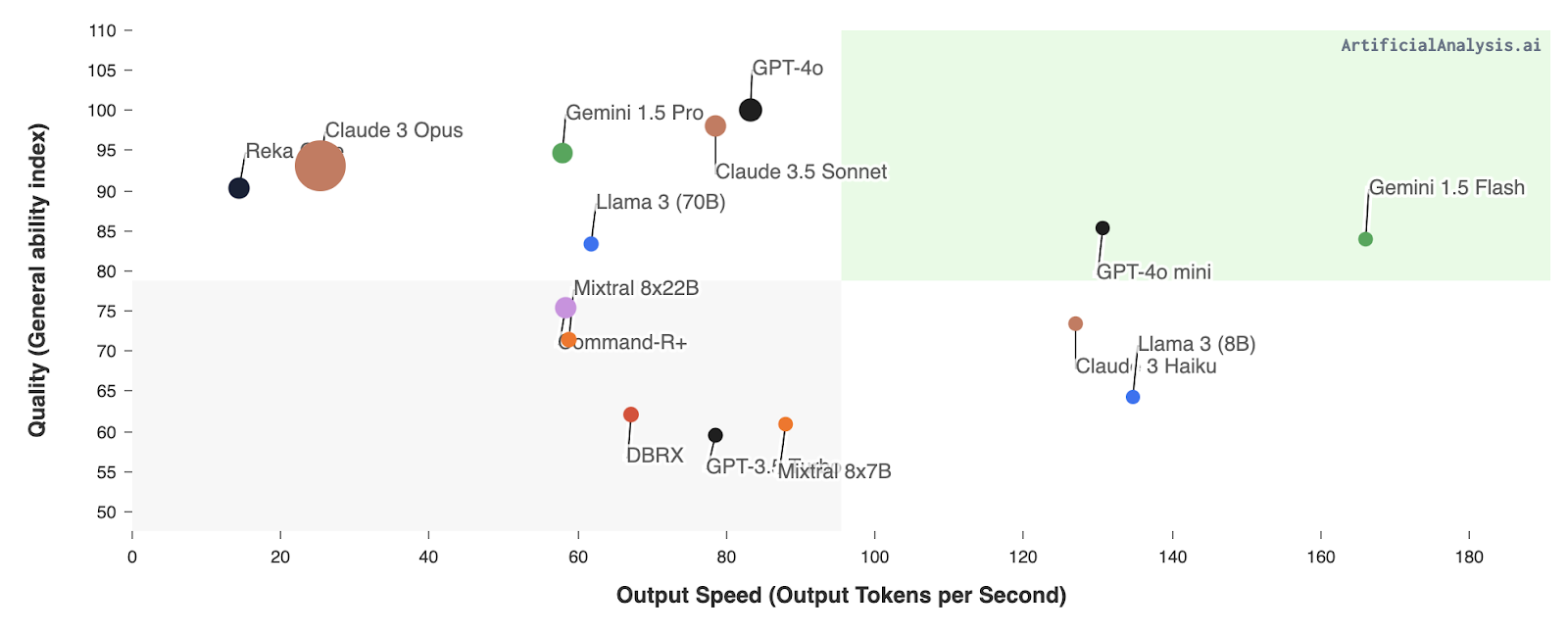
Fuente: Análisis Artificial
La GPT-4o mini consigue su equilibrio de rendimiento y eficacia mediante un proceso conocido como destilación modelo. En esencia, se trata de entrenar a un modelo más pequeño y simplificado (el "alumno") para que imite el comportamiento y los conocimientos de un modelo más grande y complejo (el "maestro").
El modelo mayor, en este caso, GPT-4o, ha sido preentrenado en grandes cantidades de datos y posee un profundo conocimiento de los patrones lingüísticos, la semántica e incluso la capacidad de razonamiento. Sin embargo, su gran tamaño hace que sea caro computacionalmente y menos adecuado para determinadas aplicaciones.
La destilación de modelos aborda este problema transfiriendo los conocimientos y capacidades del modelo GPT-4o más grande al GPT-4o mini más pequeño. Esto suele hacerse haciendo que el modelo más pequeño aprenda a predecir los resultados del modelo más grande con un conjunto diverso de datos de entrada. Mediante este proceso, el GPT-4o mini "destila" eficazmente los conocimientos y habilidades más importantes de su homólogo mayor.
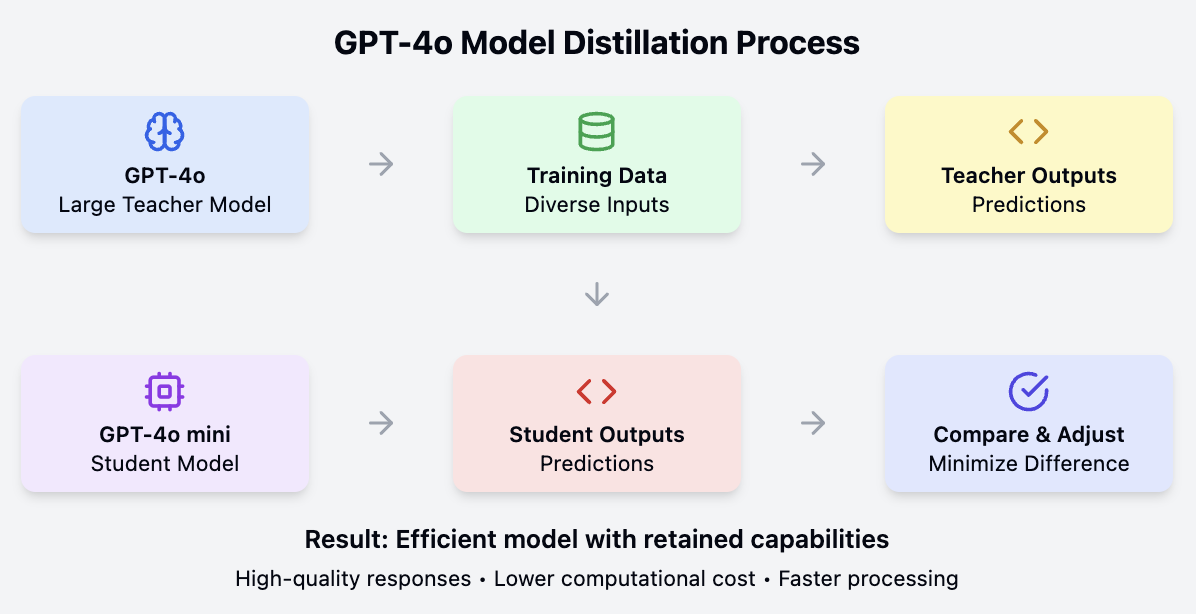
El resultado es un modelo que, aunque más pequeño y eficiente, conserva gran parte de las prestaciones y capacidades del original. GPT-4o mini puede manejar tareas lingüísticas complejas, comprender el contexto y generar respuestas de alta calidad, todo ello consumiendo menos recursos informáticos. Esto la convierte en una solución práctica y asequible para una amplia gama de aplicaciones, especialmente aquellas en las que la velocidad y la rentabilidad son importantes.
GPT-4o mini muestra un rendimiento impresionante en varios benchmarks. He creado Artefactos Claude para cada punto de referencia con el fin de explicar qué es cada punto de referencia LLM y qué mide.
Para las tareas de razonamiento, evaluamos GPT-4o mini en lo siguiente:
MMLU (Massive Multitask Language Understanding) es una prueba que evalúa modelos con preguntas de opción múltiple en 57 asignaturas diferentes, incluidas STEM, humanidades y ciencias sociales. La dificultad de las preguntas varía de básica a avanzada. Mide cuántas respuestas son correctas y requieren coincidencias exactas. GPT-4o Mini obtuvo un 82,0%, superando a competidores como Gemini Flash (77,9%) y Claude Haiku (73,8%).

GPQA (Google-Proof Q&A Benchmark) es un duro conjunto de datos con preguntas elaboradas por expertos para desafiar a los no expertos, al tiempo que resultan manejables para los especialistas. Las preguntas se validan cuidadosamente tanto en dificultad como en precisión mediante rondas múltiples para reducir los riesgos de contaminación.

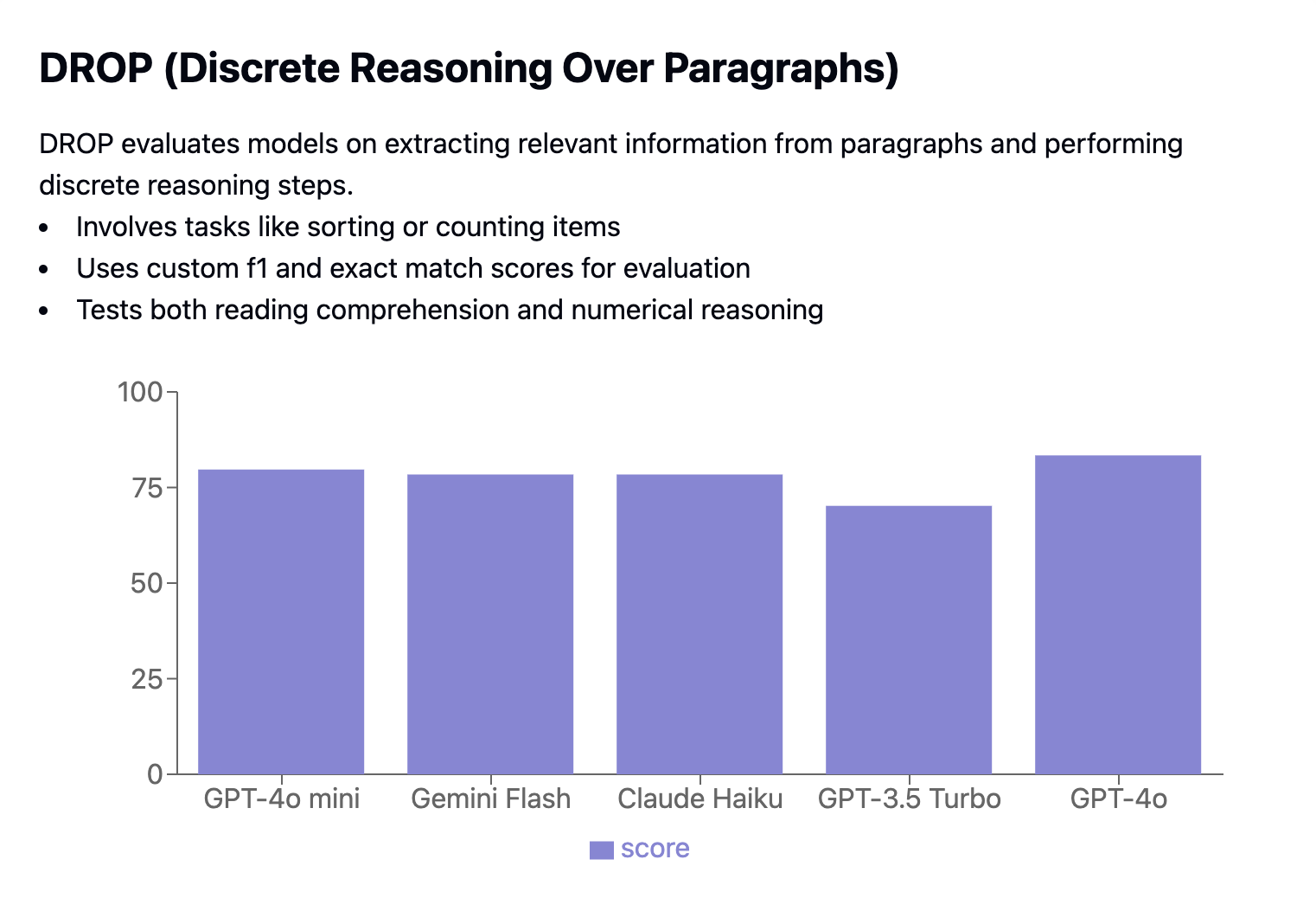
DROP (Discrete Reasoning Over Paragraphs) evalúa la capacidad de los modelos para extraer información relevante de los párrafos y realizar tareas de razonamiento como ordenar o contar. El rendimiento se evalúa utilizando puntuaciones F1 y de coincidencia exacta personalizadas.
El punto de referencia MGSM incluye 250 problemas matemáticos de primaria traducidos a 10 idiomas, que ponen a prueba la capacidad de razonamiento multilingüe.

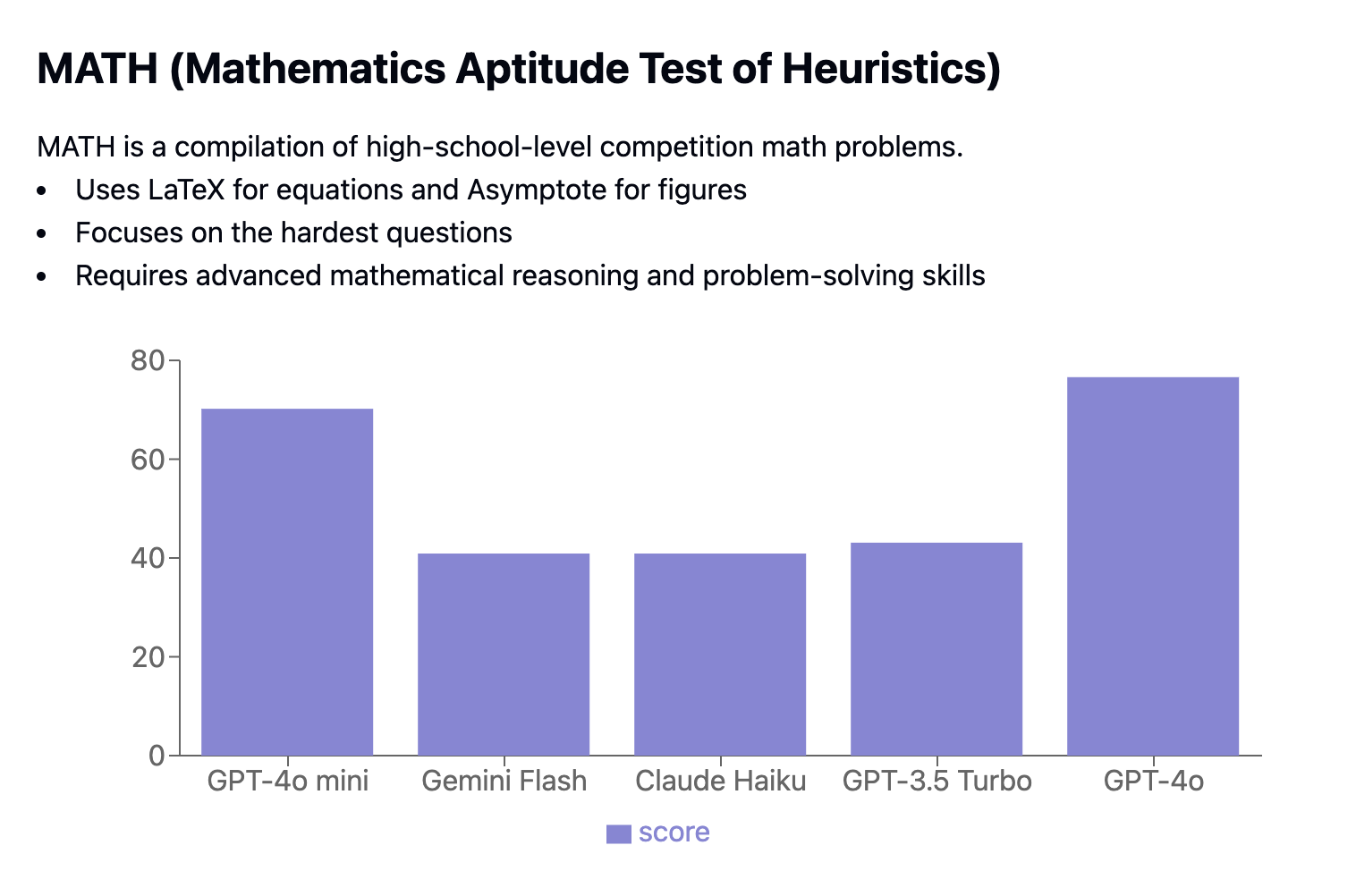
La Prueba de Aptitud Matemática Heurística (MATH) presenta problemas de competición de nivel de enseñanza secundaria. Evalúa los modelos en función de su capacidad para resolver problemas matemáticos complejos formateados en Latex y Asymptote, centrándose en las preguntas más difíciles.
El punto de referencia HumanEval mide el rendimiento de la generación de código evaluando si el código generado supera pruebas unitarias específicas. Utiliza la métrica pass@k para determinar la probabilidad de que al menos una de las k soluciones de un problema de codificación supere las pruebas.

La prueba de referencia Comprensión Lingüística Multitarea Masiva (MMLU) pone a prueba la amplitud de conocimientos, la profundidad de comprensión del lenguaje natural y la capacidad de resolución de problemas de un modelo. Contiene más de 15.000 preguntas de opción múltiple que abarcan 57 temas, desde conocimientos generales hasta campos especializados. La MMLU evalúa los modelos en configuraciones de pocos disparos y cero disparos, midiendo la precisión entre sujetos y promediando los resultados para obtener una puntuación final.

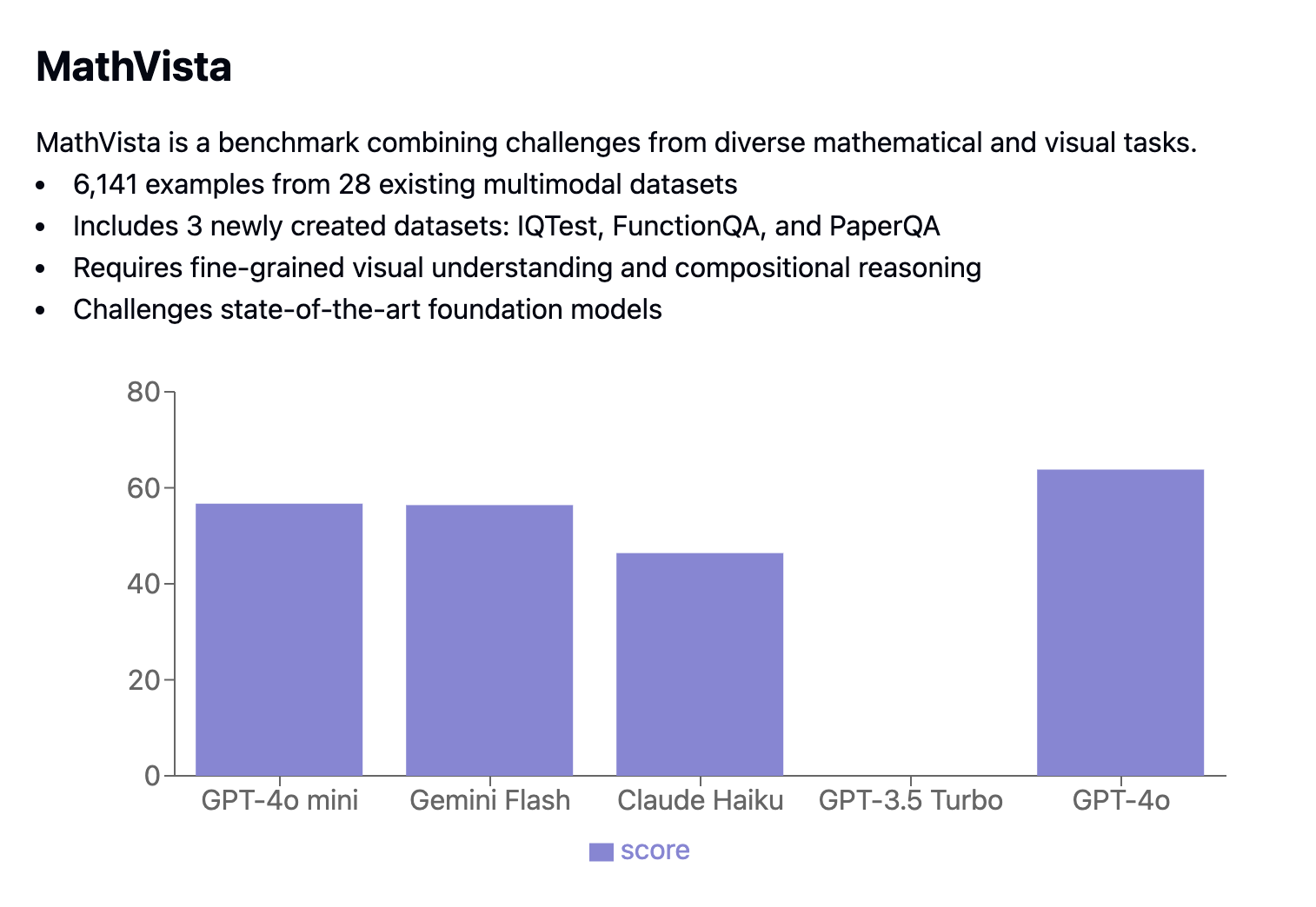
El punto de referencia MathVista combina tareas matemáticas y visuales, con 6.141 ejemplos extraídos de 28 conjuntos de datos multimodales existentes y 3 conjuntos de datos de nueva creación (IQTest, FunctionQA y PaperQA). Desafía a los modelos con tareas que requieren una comprensión visual avanzada y un razonamiento compositivo complejo.
El pequeño tamaño, el bajo coste y el gran rendimiento de GPT-4o mini lo hacen perfecto para su uso en dispositivos personales, la creación rápida de prototipos y en entornos con recursos limitados. Además, su capacidad de respuesta en tiempo real mejora las aplicaciones interactivas. He aquí cómo puede utilizarse eficazmente el GPT-4o mini:
|
Categoría de caso de uso |
Beneficios |
Ejemplos de aplicaciones |
|
IA en el dispositivo |
Su menor tamaño permite el procesamiento local en ordenadores portátiles, teléfonos inteligentes y servidores de borde, reduciendo la latencia y mejorando la privacidad. |
Aplicaciones de aprendizaje de idiomas, asistentes personales, herramientas de traducción offline |
|
Prototipado rápido |
Una iteración más rápida y unos costes más bajos permiten experimentar y perfeccionar antes de escalar a modelos más grandes. |
Probar nuevas ideas de chatbot, desarrollar prototipos impulsados por IA, experimentar con diferentes funciones de IA de forma rentable |
|
Aplicaciones en tiempo real |
Un tiempo de respuesta rápido mejora las experiencias interactivas. |
Chatbots, asistentes virtuales, traducción de idiomas en tiempo real, narración interactiva en juegos y realidad virtual |
|
Uso educativo |
Asequible y accesible para las instituciones educativas, proporciona experiencia práctica con la IA. |
Sistemas de tutoría basados en IA, plataformas de aprendizaje de idiomas, herramientas de práctica de codificación |
Puedes utilizar GPT-4o Mini a través de la API OpenAIque incluye opciones como la API de Asistentes, la API de Completaciones de Chat y la API de Lotes. Aquí tienes una guía sencilla sobre cómo utilizar GPT-4o Mini con la API OpenAI.
En primer lugar, tendrás que autenticarte utilizando tu clave de API: sustituye your_api_key_here por tu clave de API real. Una vez configurado, puedes empezar a generar texto con GPT-4o Mini:
from openai import OpenAI
MODEL="gpt-4o-mini"
## Set the API key
client = OpenAI(api_key="your_api_key_here")
completion = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful assistant that helps me with my math homework!"},
{"role": "user", "content": "Hello! Could you solve 20 x 5?"}
]
)Para más detalles sobre la configuración y el uso de la API OpenAI, consulta el tutorial de la API GPT-4o.
Más información sobre GPT
programa
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
9 min
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali
Tutorial
Zoumana Keita


