Programa
Associate AI Engineer para desenvolvedores
26 h
A OpenAI lançou recentemente seu tão esperado modelo capaz de "raciocínio PhD", e não é o GPT-5, como muitos de nós pensávamos - é o OpenAI o1 da OpenAI.
A forma como o OpenAI o1 opera marca uma importante mudança de paradigma na alocação de recursos de computação, com mais ênfase nas fases de treinamento e inferência. Essa abordagem o torna extraordinariamente bom em tarefas de raciocínio complexas, mas também muito lento em comparação com seus irmãos, GPT-4o e GPT-4o mini.
Dito isso, GPT-4o e GPT-4o mini continuam sendo as opções preferidas para aplicativos que exigem respostas rápidas, manipulação de imagens ou chamadas de funções. No entanto, se o seu projeto exigir recursos avançados de raciocínio e puder tolerar tempos de resposta um pouco mais longos, o modelo o1 é a melhor opção.
Tive a oportunidade de explorar o o1 por meio da API da OpenAI e, neste blog, fornecerei orientações passo a passo sobre como fazer exatamente isso. Mostrarei a você como se conectar à API, gerenciar os custos e, no final, compartilharei algumas dicas de solicitação para ajudá-lo a minimizar as despesas e obter melhores respostas.
Se você estiver procurando um artigo mais introdutório, confira este Guia do OpenAI o1.
Uma das primeiras coisas que você precisa saber é que, por enquanto, o acesso aos modelos o1 por meio da API exige um nível de uso Tier 5.
|
Nível |
Qualificação |
Limites de uso |
|
Grátis |
O usuário deve estar em uma área geográfica permitida |
$100 / mês |
|
Nível 1 |
US$ 5 pagos |
$100 / mês |
|
Nível 2 |
US$ 50 pagos e mais de 7 dias desde o primeiro pagamento bem-sucedido |
$500 / mês |
|
Nível 3 |
US$ 100 pagos e mais de 7 dias desde o primeiro pagamento bem-sucedido |
US$ 1.000 / mês |
|
Nível 4 |
US$ 250 pagos e mais de 14 dias desde o primeiro pagamento bem-sucedido |
US$ 5.000 / mês |
|
Nível 5 |
US$ 1.000 pagos e mais de 30 dias desde o primeiro pagamento bem-sucedido |
US$ 50.000 / mês |
Para verificar seu nível de uso, acesse a página da sua conta na plataforma de desenvolvedor da OpenAI e procure na seção Limits (Limites ) em Organization (Organização).
Cada nível de uso vem com limites de taxa específicos. No momento em que este artigo foi escrito, esses são os limites de tarifa da Categoria 5:
|
Modelo |
RPM (solicitações por minuto) |
TPM (Tokens por minuto) |
Limite de fila do lote |
|
gpt-4o |
10,000 |
30,000,000 |
5,000,000,000 |
|
gpt-4o-mini |
30,000 |
150,000,000 |
15,000,000,000 |
|
o1-preview |
500 |
30,000,000 |
não suportado atualmente |
|
o1-mini |
1000 |
150,000,000 |
não suportado atualmente |
Os modelos O1 levam um tempo considerável para serem processados durante a fase de inferência, o que explica os limites de RPM mais baixos em comparação com os modelos GPT-4o. Observe que, no momento, não há suporte para lotes nos modelos o1, o que significa que você não pode agrupar (batch) várias solicitações ao modelo ao mesmo tempo.
O modelo O1 ainda é novo, portanto, esses requisitos e limites de taxas podem mudar nas próximas semanas. Por exemplo, a OpenAI anunciou inicialmente que os limites de taxa semanal seriam de 30 mensagens para o o1-preview e 50 para o o1-mini. No entanto, apenas alguns dias depois, eles atualizaram os limites de taxa para 50 consultas por semana para o1-preview e 50 consultas por dia para o1-mini.
Em breve, você verá a parte prática, mas, antes disso, vamos esclarecer um novo conceito que é fundamental para usar o o1 por meio da API: tokens de raciocínio. Compreender esse conceito é essencial para que você entenda sua fatura mensal da OpenAI.
Se você tiver usado o o1-preview por meio do ChatGPT você viu que ele "pensa em voz alta" antes de gerar uma resposta.
Quando usamos o modelo o1 por meio da API, ele passa pelo mesmo processo de raciocínio. A única diferença é que, diferentemente da interface do ChatGPT, o raciocínio não é visível, e tudo o que você vê é a resposta final.
No entanto, o raciocínio ainda é tokenizado (daí o nome "tokens de raciocínio") e, como você deve ter adivinhado, é faturável. Os tokens de raciocínio são cobrados como tokens de saída, que são quatro vezes mais caros do que os tokens de entrada.
Em breve, aprenderemos como controlar o número de tokens e gerenciar os custos, mas, por enquanto, vamos nos concentrar na conexão com a API da OpenAI da OpenAI para usar os modelos o1.
Nesta seção, descreveremos uma série de etapas para ajudar você a se conectar ao modelo o1-preview por meio da API. Mais tarde, também abordaremos como se conectar ao modelo o1-mini.
Desde que tenha uma conta ativa, você pode obter sua chave secreta de API na página de chave de API da OpenAI página de chave de API da OpenAI.
Se você faz parte de uma organização, talvez também precise do ID da organização e de um ID do projeto, o que pode ajudar sua equipe a gerenciar os custos com mais eficiência. Não deixe de consultar a sua equipe sobre isso.
Não importa se você é novo em APIs ou um desenvolvedor experiente, é sempre uma boa ideia seguir as práticas recomendadas de API.
openai bibliotecaA OpenAI facilita a interação com sua API por meio da biblioteca Python openai. Você pode instalá-lo usando o seguinte comando:
pip install openaiDepois de instalada, importamos a classe OpenAI da biblioteca openai:
from openai import OpenAIPara interagir com a API da OpenAI, inicializamos um cliente usando nossa chave secreta da API:
client = OpenAI(api_key=’your-api-key’)Se você faz parte de uma organização, talvez também precise do ID da organização e de um ID do projeto:
client = OpenAI(
organization=’your-organization-id’,
project=’your-project-id’,
api_key=’your-api-key’
)Os únicos modelos o1 disponíveis no momento em que este artigo foi escrito são o-1 preview e o1-mini. Ambos estão disponíveis por meio do chat.completions endpoint. No código abaixo, observe que:
client.chat.completions.create().”o1-preview” para o parâmetro model.”content”.response.choices[0].message.content.response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": "Write a Python script that takes a matrix represented as a string with format '[1,2],[3,4],[5,6]' and prints the transpose in the same format."
}
]
)
print(response.choices[0].message.content)```python
import ast
# Read the input string
s = input()
# Add outer brackets to make it a valid list representation
input_str = '[' + s + ']'
# Safely evaluate the string to a list of lists
matrix = ast.literal_eval(input_str)
# Transpose the matrix
transposed = list(map(list, zip(*matrix)))
# Convert the transposed matrix back to the required string format
transposed_str = ','.join('[' + ','.join(map(str, row)) + ']' for row in transposed)
# Print the result
print(transposed_str)
```Conforme mencionado anteriormente, o raciocínio subjacente ainda conta como tokens faturáveis. Para o código que executamos acima, aqui está um detalhamento de todos os tokens usados:
print(response.usage)CompletionUsage(completion_tokens=1279, prompt_tokens=43, total_tokens=1322, completion_tokens_details={'reasoning_tokens': 1024})Ao examinar a saída, vemos que o número de tokens de raciocínio é 1024: completion_tokens_details={'reasoning_tokens': 1024}.
O modelo gerou uma conclusão usando 1.279 tokens (completion_tokens=1279), dos quais 1.024 eram tokens de raciocínio invisíveis - isso representa cerca de 80%!
O gerenciamento de custos se torna um pouco mais complicado com os novos modelos o1, portanto, vamos discutir isso com mais detalhes.
Nos modelos anteriores, usamos o parâmetro max_tokens para controlar o número de tokens de conclusão. As coisas eram bastante simples: o número de tokens gerados e o número de tokens visíveis eram sempre os mesmos.
No entanto, com os modelos o1, precisamos de um parâmetro que defina um limite superior para todos os tokens de conclusão, incluindo tokens de saída visíveis e tokens de raciocínio invisíveis. Por esse motivo, a OpenAI adicionou o parâmetro max_completion_tokens, ao mesmo tempo em que descontinuou o max_tokens e o tornou incompatível com os modelos o1.
Vamos tentar max_completion_tokens com nosso exemplo anterior. Vamos configurá-lo para 300 e veremos o que você obtém. Para usar esse novo parâmetro, observe que você pode precisar de uma atualização da biblioteca openai se estiver executando versões mais antigas.
response_with_limit = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": "Write a Python script that takes a matrix represented as a string with format '[1,2],[3,4],[5,6]' and prints the transpose in the same format."
}
],
max_completion_tokens=300
)
print(response_with_limit.choices[0].message.content) Observe que não recebemos nenhum resultado. Mas será que ainda estamos pagando? A resposta é sim.
print(response_with_limit.usage)CompletionUsage(completion_tokens=300, prompt_tokens=43, total_tokens=343, completion_tokens_details=CompletionTokensDetails(reasoning_tokens=300))Se o modelo o1 atingir o limite de tokens antes de chegar a uma resposta final, ele interromperá o processo de raciocínio e não retornará nenhum resultado. Por esse motivo, é importante definir max_completion_tokens como um valor que garanta a saída - caso contrário, seremos cobrados por tokens de raciocínio e tokens de entrada sem receber nada em troca.
Você precisará experimentar o valor exato de max_completion_tokens com base no seu caso de uso específico, mas a OpenAI aconselha reservar pelo menos 25.000 tokens para o número total de tokens de conclusão.
Para evitar uma saída truncada (ou nenhuma saída), você também precisará estar atento à janela de contexto se o seu caso de uso envolver um grande número de tokens. Os modelos o1-preview e o-1 mini têm uma janela de contexto de 128.000 tokens. Observe, no entanto, que os tokens de saída (visíveis e invisíveis) são limitados a 32.768 tokens para o o1-preview e 65.536 tokens para o o1-mini.
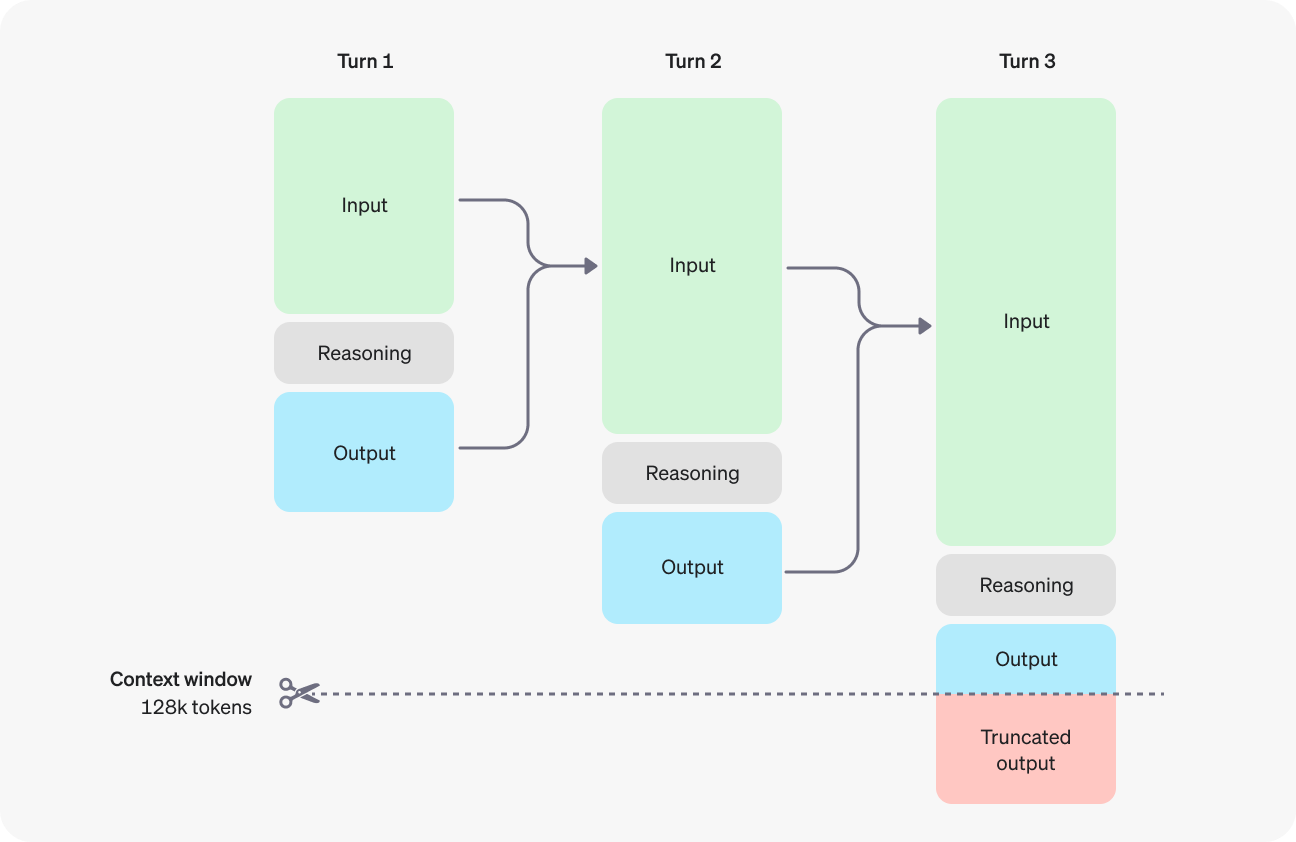
Fonte: OpenAI
O modelo o1 grande é poderoso em raciocínio avançado, mas também é muito lento. Se você precisar de tempos de resposta mais rápidos para seus aplicativos e estiver disposto a fazer um pequeno comprometimento no desempenho do raciocínio, o modelo o1-mini poderá ser a melhor opção.
Para se conectar ao modelo o1-mini por meio da API, siga todas as etapas que abordamos para o modelo o1-preview, exceto o parâmetro model, no qual você precisa usar a string ”o1-mini”.
Usaremos o mesmo prompt do último exemplo, para que você possa comparar o uso do token:
response_mini = client.chat.completions.create(
model="o1-mini",
messages=[
{
"role": "user",
"content": "Write a Python script that takes a matrix represented as a string with format '[1,2],[3,4],[5,6]' and prints the transpose in the same format."
}
]
)
print(response_mini.choices[0].message.content)Certainly! Below is a Python script that takes a matrix represented as a string in the format `'[1,2],[3,4],[5,6]'`, computes its transpose, and prints the transposed matrix in the same string format.
```python
def parse_matrix(matrix_str):
"""
Parses a matrix string like '[1,2],[3,4],[5,6]' into a list of lists.
"""
# Split the string by '],[' to separate the rows
rows = matrix_str.strip().split('],[')
# Clean the first and last elements by removing any leading '[' or trailing ']'
rows[0] = rows[0].lstrip('[')
rows[-1] = rows[-1].rstrip(']')
# Convert each row into a list of integers
matrix = []
for row in rows:
# Split each row by ',' and convert each element to integer
matrix.append([int(num) for num in row.split(',')])
return matrix
def transpose_matrix(matrix):
"""
Transposes a given matrix (list of lists).
"""
# Use zip with unpacking to transpose the matrix
transposed = list(zip(*matrix))
# Convert each tuple in the transposed matrix back to a list
transposed = [list(row) for row in transposed]
return transposed
def matrix_to_string(matrix):
"""
Converts a list of lists into a string format like '[1,3,5],[2,4,6]'.
"""
# Convert each row to a string
row_strings = []
for row in matrix:
# Convert each number to string and join with commas
row_str = ','.join(str(num) for num in row)
# Enclose the row in brackets
row_strings.append(f'[{row_str}]')
# Join all rows with commas
return ','.join(row_strings)
def main():
# Example input
input_str = '[1,2],[3,4],[5,6]'
# Parse the input string into a matrix
matrix = parse_matrix(input_str)
# Compute the transpose of the matrix
transposed = transpose_matrix(matrix)
# Convert the transposed matrix back to string format
output_str = matrix_to_string(transposed)
# Print the result
print(output_str)
if __name__ == "__main__":
main()
```
### How It Works:
1. **Parsing the Input String:**
- The `parse_matrix` function takes the input string and splits it into individual rows by looking for the pattern `"],["`.
- It cleans the first and last rows by removing any leading `[` or trailing `]`.
- Each row string is then split by `,` to extract individual numbers, which are converted to integers and stored in a nested list.
2. **Transposing the Matrix:**
- The `transpose_matrix` function uses the `zip` function along with unpacking (`*`) to transpose the matrix. This effectively switches rows with columns.
- Since `zip` returns tuples, each transposed row is converted back into a list.
3. **Converting Back to String:**
- The `matrix_to_string` function takes the transposed matrix and converts each row back into a string in the desired format.
- It joins the elements of each row with commas and encloses them in brackets.
- Finally, all row strings are joined together with commas to form the final output string.
4. **Main Execution:**
- The `main` function demonstrates the usage with an example input. You can modify `input_str` to test with different matrices.
- It prints the transposed matrix in the specified string format.
### Example:
Given the input string:
```
'[1,2],[3,4],[5,6]'
```
The script will output:
```
[1,3,5],[2,4,6]
```
### Handling User Input:
If you'd like the script to accept user input instead of having a hardcoded string, you can modify the `main` function as follows:
```python
def main():
# Take user input
input_str = input("Enter the matrix string (e.g., '[1,2],[3,4],[5,6]'): ").strip()
# Parse the input string into a matrix
matrix = parse_matrix(input_str)
# Compute the transpose of the matrix
transposed = transpose_matrix(matrix)
# Convert the transposed matrix back to string format
output_str = matrix_to_string(transposed)
# Print the result
print(output_str)
```
With this modification, when you run the script, it will prompt you to enter the matrix string:
```
Enter the matrix string (e.g., '[1,2],[3,4],[5,6]'): [1,2],[3,4],[5,6]
[1,3,5],[2,4,6]
```
### Notes:
- **Error Handling:** The current script assumes that the input string is well-formatted. For production code, you might want to add error handling to manage malformed inputs.
- **Non-integer Elements:** If your matrix contains non-integer elements (e.g., floats or strings), you'll need to adjust the parsing logic accordingly.
### Running the Script:
1. **Save the Script:** Save the above code to a file, say `transpose_matrix.py`.
2. **Run the Script:** Open a terminal or command prompt, navigate to the directory containing the script, and execute:
```bash
python transpose_matrix.py
```
3. **Provide Input:** If you've modified it to accept user input, enter the matrix string when prompted.
This script provides a straightforward way to transpose a matrix represented as a string and can be easily adapted or extended based on specific requirements.A saída visível é muito mais detalhada em comparação com a saída do o1-preview - vamos comparar o uso:
print(response_mini.usage) # o1-mini
print(response.usage) # o1-previewCompletionUsage(completion_tokens=1511, prompt_tokens=43, total_tokens=1554, completion_tokens_details=CompletionTokensDetails(reasoning_tokens=256))
CompletionUsage(completion_tokens=1279, prompt_tokens=43, total_tokens=1322, completion_tokens_details={'reasoning_tokens': 1024})O modelo o1-mini tem quatro vezes menos motivos em comparação com o modelo o1 (256 vs. 1024 tokens de raciocínio). No entanto, devido à sua resposta detalhada, o número total de tokens de conclusão é, na verdade, maior. Embora o o1-mini seja significativamente mais barato que o o1-preview, isso ainda não é o ideal.
Uma maneira de mitigar isso é por meio de engenharia imediata-instruiremos o modelo a evitar explicações e introduções e limitaremos seu resultado apenas à resposta.
response_mini_2 = client.chat.completions.create(
model="o1-mini",
messages=[
{
"role": "user",
"content": "Write a Python script that takes a matrix represented as a string with format '[1,2],[3,4],[5,6]' and prints the transpose in the same format. Limit yourself to the answer and don't add explanations or introductions."
}
]
)
print(response_mini_2.choices[0].message.content)```python
import ast
def parse_matrix(matrix_str):
rows = matrix_str.split('],[')
rows[0] = rows[0].lstrip('[')
rows[-1] = rows[-1].rstrip(']')
matrix = [ast.literal_eval(f'[{row}]') for row in rows]
return matrix
def transpose(matrix):
return list(zip(*matrix))
def format_matrix(transposed):
return ','.join([f'[{",".join(map(str, row))}]' for row in transposed])
input_str = '[1,2],[3,4],[5,6]'
matrix = parse_matrix(input_str)
transposed = transpose(matrix)
output_str = format_matrix(transposed)
print(output_str)
```Muito melhor! O número total de tokens de conclusão é cerca de três vezes menor:
print(response_mini_2.usage)CompletionUsage(completion_tokens=487, prompt_tokens=55, total_tokens=542, completion_tokens_details=CompletionTokensDetails(reasoning_tokens=320))No momento em que este tutorial foi escrito, os modelos o1 ainda estavam na versão beta. Embora a OpenAI tenha anunciado planos para recursos adicionais e limites de taxa mais amigáveis nas próximas semanas, aqui estão as limitações que você encontrará ao usar os modelos beta o1:
temperature, top_p, e n são fixados em 1, enquanto presence_penalty e frequency_penalty são definidos como 0.No momento, a OpenAI não parece ter muita concorrência na área de raciocínio avançado. Por isso, os preços talvez estejam um pouco inflacionados e, como você pode ver, são significativamente mais altos em comparação com os modelos GPT-4o:
|
Modelo |
Preços |
|
o1-preview |
US$ 15,00 / 1 milhão de tokens de entrada |
|
US$ 60,00 / 1 milhão de tokens de saída |
|
|
o1-mini |
US$ 3,00 / 1 milhão de tokens de entrada |
|
US$ 12,00 / 1 milhão de tokens de saída |
|
|
gpt-4o |
US$ 5,00 / 1 milhão de tokens de entrada |
|
US$ 15,00 / 1 milhão de tokens de saída |
|
|
gpt-4o-mini |
US$ 0,150 / 1 milhão de tokens de entrada |
|
US$ 0,600 / 1 milhão de tokens de saída |
Os modelos o1 são significativamente diferentes dos modelos com os quais estamos acostumados, como o GPT-4o ou o Claude 3.5 Sonnet. Como os modelos o1 já se envolvem em cadeia de raciocínio eles funcionam melhor com solicitações diretas. Usando estímulos de poucos disparos ou pedir ao modelo que pense "passo a passo" pode, na verdade, degradar seu desempenho.
Aqui estão algumas práticas recomendadas pelos desenvolvedores da OpenAI:
Ao longo deste blog, compartilhei orientações passo a passo sobre a conexão com os modelos o1 por meio da API da OpenAI.
Se o seu projeto exigir recursos avançados de raciocínio e puder acomodar tempos de resposta um pouco mais longos, os modelos o1 são excelentes opções.
Para aplicativos que exigem respostas rápidas, processamento de imagens ou chamadas de funções, o GPT-4o e o GPT-4o mini continuam sendo as escolhas preferidas.
Para continuar aprendendo, recomendo estes recursos:
Aprenda IA com estes cursos!
Programa
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Matt Crabtree



