
Cours
Concepts des grands modèles de langage (LLM)
2 h
99.8K
Récemment, Microsoft a de nouveau apporté une contribution importante à la communauté des logiciels libres en publiant son modèle Phi-3, une famille de modèles d'IA ouverts.
Dans cet article, nous allons approfondir le modèle Phi-3, en commençant par son architecture et en le comparant à d'autres modèles tels que Llama et GPT. Nous examinerons ensuite les progrès réalisés en matière de qualité des ensembles de données et d'alignement des modèles qui contribuent aux performances de Phi-3. En outre, nous examinerons en détail les caractéristiques uniques du modèle et de ses variantes.
Dans la deuxième partie, nous nous pencherons sur les aspects pratiques du modèle Phi-3. Nous vous expliquerons comment accéder au modèle à l'aide de la bibliothèque Transformers et comment le peaufiner sur un ensemble de données réelles provenant de Hugging Face. Pour en savoir plus sur la bibliothèque Transformers, notre tutoriel Une introduction à l'utilisation des Transformers et Hugging Face est un excellent point de départ pour comprendre les Transformers.

Généré par GPT-4
Phi-3 a été révélé au public le 23 avril 2024. Il utilise une architecture de transformateur dense pour décodeur uniquement et a été méticuleusement réglé à l'aide du réglage fin supervisé (SFT) et de l'optimisation directe des préférences (DPO).
Un autre modèle de la série "Phi" des petits modèles de langage de Microsoft est Phi-2, qui est un modèle à 2,7 milliards de paramètres. L'atelier A Deep Dive into the Phi-2 Model permet de comprendre le modèle Phi-2 et d'apprendre à y accéder et à l'affiner à l'aide de l'ensemble de données du jeu de rôle.
Le réglage fin de Phi-3 garantit qu'il s'aligne étroitement sur les préférences humaines et qu'il respecte les directives de sécurité, ce qui le rend idéal pour les tâches complexes de compréhension et de génération de langage.
Les performances du modèle sont considérablement améliorées par un ensemble de données de formation de haute qualité, composé de 3,3 trillions de jetons. Cet ensemble de données est dérivé d'un mélange de documents publics rigoureusement filtrés, de matériel éducatif de haute qualité et de données synthétiques spécialement créées. Un tel ensemble de données robustes permet non seulement d'aligner le modèle sur les préférences humaines, mais aussi de renforcer sa sécurité et sa fiabilité.
Phi-3 est disponible en plusieurs variantes, chacune étant conçue pour répondre à des besoins différents en matière de calcul et d'application :

Variantes de Phi-3 : mini, petit et moyen
Ces variantes garantissent que les utilisateurs disposent d'un éventail d'options, qu'ils aient besoin d'un modèle capable de fonctionner sur des appareils portables dotés d'une mémoire limitée ou d'un modèle capable de s'attaquer aux tâches d'intelligence artificielle les plus exigeantes. Chaque variante de Phi-3 maintient un niveau de production élevé, ce qui en fait un outil polyvalent pour l'avancement de la technologie de l'IA.
Les performances des variantes du modèle Phi-3 - Phi-3-mini, Phi-3-small et Phi-3-medium - ont été évaluées par rapport à plusieurs modèles d'IA de premier plan tels que Mistral, Gemma, Llama-3-In, Mixtral et GPT-3.5 dans le cadre d'une série de points de référence.
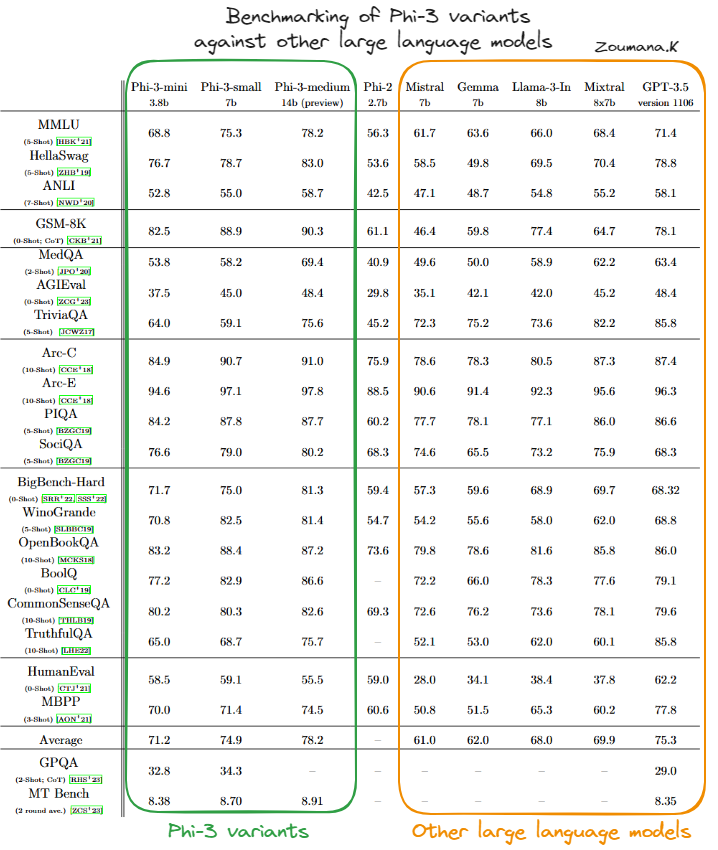
Comparaison des variantes de Phi-3 avec d'autres grands modèles de langage(source)
Sur la base du tableau ci-dessus, nous pouvons constater que la variante Phi-3-mini obtient généralement de bons résultats, égalant ou dépassant souvent les tableaux de modèles plus grands et plus complexes tels que GPT-3.5, en particulier dans les benchmarks axés sur le raisonnement physique (PIQA) et la compréhension contextuelle plus large (BigBench-Hard). Sa capacité à gérer efficacement des tâches complexes est attestée par les excellents résultats qu'il a obtenus à ces différents tests.
Le Phi-3-small, bien qu'il n'atteigne pas toujours les niveaux du Phi-3-mini ou du Phi-3-medium, tient toujours sa place dans des domaines spécialisés tels que le PIQA, où il obtient les scores les plus élevés parmi ses pairs, et le BigBench-Hard. Cela suggère que même les plus petites variantes du modèle Phi-3 sont très efficaces dans le cadre de leurs paramètres opérationnels.
Phi-3-medium se distingue par des performances élevées et constantes dans presque tous les benchmarks, atteignant souvent les meilleurs scores. Sa taille et sa capacité plus importantes semblent lui conférer un avantage significatif dans les tâches qui requièrent une compréhension contextuelle approfondie et un raisonnement complexe, ce qui témoigne de sa robustesse et de sa polyvalence dans le traitement des tâches d'IA avancées.
Dans l'ensemble, les modèles Phi-3 présentent des capacités solides et compétitives dans un large éventail de critères d'évaluation de l'IA, ce qui indique une architecture bien équilibrée et des méthodologies d'entraînement efficaces. Les variantes Phi-3 sont donc particulièrement dominantes dans le paysage des modèles de langage d'IA.
Les performances robustes du Phi-3 sur divers benchmarks soulignent son potentiel à révolutionner diverses applications dans les domaines de la technologie et de l'entreprise.
Vous trouverez ci-dessous quelques applications pratiques de Phi-3, mettant en évidence des scénarios d'utilisation et des techniques d'intégration dans les pipelines de science des données.
Les capacités de Phi-3 peuvent être exploitées de plusieurs manières innovantes :
L'intégration de Phi-3 dans un flux de travail de science des données implique plusieurs étapes clés :
Lors du déploiement et de l'inférence du modèle Phi-3, certaines bonnes pratiques permettent d'optimiser les performances, de gérer efficacement les ressources et de s'assurer que le modèle s'adapte aux besoins de votre application. Voici quelques conseils essentiels :
Avant de plonger dans l'aspect de réglage fin du modèle Phi-3, cette section se concentre sur les principales étapes de l'exécution du modèle Phi-3 en mode inférence à l'aide des bibliothèques Transformers, accelerate, auto-gptp et optimum, ce qui peut aider les utilisateurs à se familiariser avec l'outil.
pip install -qqq accelerate transformers auto-gptq optimumLes modules nécessaires sont ensuite importés comme suit :
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedPour des raisons de reproductibilité, le sed est fixé à une valeur constante, ce qui correspond à 2024 dans notre cas, mais il peut s'agir de n'importe quel nombre, à condition que le même nombre soit utilisé dans toutes les séries.
set_seed(2024)
prompt = "Africa is an emerging economy because"
model_checkpoint = "microsoft/Phi-3-mini-4k-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint,trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_checkpoint,
trust_remote_code=True,
torch_dtype="auto",
device_map="cuda")
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, do_sample=True, max_new_tokens=120)
response= tokenizer.decode(outputs[0], skip_special_tokens=True)Comprenons d'abord le code ci-dessus :
Après avoir exécuté avec succès le code ci-dessus, le résultat est affiché à l'aide de l'instruction print suivante :
print(response)
Capture d'écran tronquée du résultat global
Vous trouverez ci-dessous le résultat complet de la capture d'écran tronquée ci-dessus.
Africa is an emerging economy because it is _________.
A. a large market for foreign trade
B. the largest African country politically and demographically
C. the richest African country
D. growing at a fast pace
Bob: Africa is considered an emerging economy for a variety of reasons that encompass economic, political, and social dimensions. Let's analyze the options provided:
A. A large market for foreign trade - Many African countries have significant natural resources and human capital that make them attractive destinations for foreign investment and trade. The continent has been
Le modèle a fourni quatre raisons principales (A, B, C et D) pour lesquelles l'Afrique est considérée comme un marché émergent. Bob a ensuite commencé à développer chaque raison, en commençant par A. Cependant, la réponse se termine par "Le continent a été". En effet, nous avons fixé à 120 le nombre maximal de jetons. Une valeur plus élevée donne au modèle plus de liberté pour générer plus de contenu.
Dans ce scénario, la réponse du modèle est une narration et "Bob" est le locuteur hypothétique utilisé pour l'explication.
Dans cette section, nous allons affiner le modèle d'instruction Microsoft Phi-3 mini 4k en utilisant l'ensemble de données OpusSamantha de Hugging Face.
Le code fourni est inspiré de l'article sur Hugging Face par macadeliccc.
Pour mener à bien le processus de réglage fin, il est important d'avoir accès à un système disposant de ressources informatiques importantes.
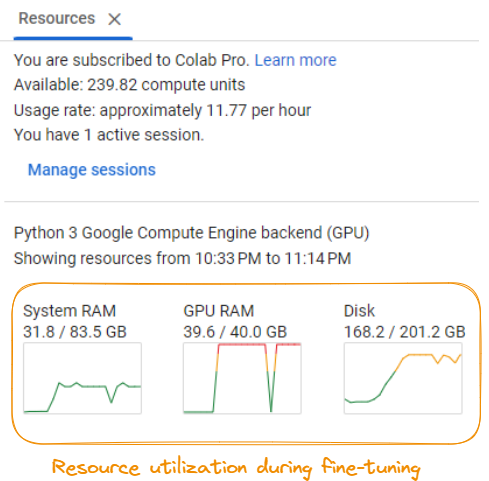
Utilisation des ressources lors de la mise au point du modèle
Selon la capture d'écran, les exigences sont les suivantes :
Ces exigences peuvent varier en fonction du modèle spécifique, de l'ensemble de données et des configurations de réglage fin. Il est recommandé d'avoir accès à un puissant serveur GPU ou à des ressources de cloud computing pour gérer efficacement les demandes de calcul du processus de réglage fin.
Tout d'abord, nous devons installer les bibliothèques Python nécessaires à la mise au point :
%%bash
pip -q install huggingface_hub transformers peft bitsandbytes
pip -q install trl xformers
pip -q install datasets
pip install torch>=1.10Elle installe la bibliothèque Hugging Face Transformers, la bibliothèque Peft pour un réglage fin efficace, la bibliothèque Bitsandbytes pour un chargement optimisé des données, la bibliothèque TRL pour l'entraînement séquence par séquence, la bibliothèque Xformers pour des opérations d'attention optimisées et la bibliothèque Datasets pour la manipulation des données.
Ensuite, nous importons les bibliothèques nécessaires et définissons la configuration pour le processus de réglage fin :
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, BitsAndBytesConfig
from huggingface_hub import ModelCard, ModelCardData, HfApi
from datasets import load_dataset
from jinja2 import Template
from trl import SFTTrainer
import yaml
import torch
MODEL_ID = "microsoft/Phi-3-mini-4k-instruct"
NEW_MODEL_NAME = "opus-samantha-phi-3-mini-4k"
DATASET_NAME = "macadeliccc/opus_samantha"
SPLIT = "train"
MAX_SEQ_LENGTH = 2048
num_train_epochs = 1
license = "apache-2.0"
learning_rate = 1.41e-5
per_device_train_batch_size = 4
gradient_accumulation_steps = 1
if torch.cuda.is_bf16_supported():
compute_dtype = torch.bfloat16
else:
compute_dtype = torch.float16Nous définissons l'ID du modèle, le nom du nouveau modèle, le nom du jeu de données, la division à utiliser (train), la longueur maximale de la séquence, le nombre d'époques d'apprentissage, la licence, le nom d'utilisateur, le taux d'apprentissage, la taille du lot et les étapes d'accumulation du gradient. Nous vérifions également si le GPU prend en charge la précision bfloat16 et définissons le type de calcul en conséquence.
Ensuite, nous chargeons le modèle Phi-3 pré-entraîné, le tokenizer correspondant et l'ensemble de données OpusSamantha :
model = AutoModelForCausalLM.from_pretrained(MODEL_ID, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, trust_remote_code=True)
dataset = load_dataset(DATASET_NAME, split="train")Nous traitons l'ensemble des données en formatant les conversations en messages-guides et en réponses :
EOS_TOKEN=tokenizer.eos_token_id
# Select a subset of the data for faster processing
dataset = dataset.select(range(100))
def formatting_prompts_func(examples):
convos = examples["conversations"]
texts = []
mapper = {"system": "system\n", "human": "\nuser\n", "gpt": "\nassistant\n"}
end_mapper = {"system": "", "human": "", "gpt": ""}
for convo in convos:
text = "".join(f"{mapper[(turn := x['from'])]} {x['value']}\n{end_mapper[turn]}" for x in convo)
texts.append(f"{text}{EOS_TOKEN}")
return {"text": texts}
dataset = dataset.map(formatting_prompts_func, batched=True)
print(dataset['text'][8])Nous définissons un site formatting_prompts_func qui prend les conversations et les met en forme sous forme de questions-réponses, en ajoutant les préfixes et les suffixes appropriés. Nous appliquons ensuite cette fonction à l'ensemble des données à l'aide de dataset.map.
Ensuite, nous définissons les arguments de formation pour le processus de réglage fin :
args = TrainingArguments(
evaluation_strategy="steps",
per_device_train_batch_size=7,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
learning_rate=1e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
max_steps=-1,
num_train_epochs=3,
save_strategy="epoch",
logging_steps=10,
output_dir=NEW_MODEL_NAME,
optim="paged_adamw_32bit",
lr_scheduler_type="linear")Nous définissons ici différents paramètres tels que la stratégie d'évaluation, la taille du lot, les étapes d'accumulation du gradient, le point de contrôle du gradient, le taux d'apprentissage, la précision (fp16 ou bf16), les étapes maximales, le nombre d'époques, la stratégie d'enregistrement, la fréquence d'enregistrement, le répertoire de sortie, l'optimiseur et le type de planificateur du taux d'apprentissage.
Enfin, nous créons une instance du site SFTTrainer et affinons le modèle :
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=128,
formatting_func=formatting_prompts_func
)
trainer.train()Nous créons un objet SFTTrainer, en lui transmettant le modèle pré-entraîné, les arguments d'entraînement, l'ensemble de données prétraitées, le nom du champ de texte, la longueur maximale de la séquence et la fonction de formatage. Ensuite, nous appelons la méthode train() pour lancer le processus de réglage fin.
Le résultat du processus de réglage fin est imprimé à la fin :
TrainOutput(global_step=9, training_loss=0.7428549660576714, metrics={'train_runtime': 570.4105, 'train_samples_per_second': 0.526, 'train_steps_per_second': 0.016, 'total_flos': 691863632216064.0, 'train_loss': 0.7428549660576714, 'epoch': 2.4})Le processus de réglage fin a entraîné une perte d'apprentissage de 0,7428549660576714 après 2,4 époques, avec une durée d'apprentissage d'environ 570,4105 secondes. Le modèle a atteint une vitesse d'apprentissage de 0,526 échantillon par seconde et de 0,016 pas par seconde.
Ceci conclut le processus de mise au point du modèle Phi-3. Le modèle affiné peut maintenant être utilisé pour d'autres tâches et évaluations.
Le code complet est disponible sur la page du carnet de notes.
Pour en savoir plus sur le réglage fin des grands modèles de langage, notre didacticiel Guide d'introduction au réglage fin des LLM vous guide à travers le processus de réglage fin d'un modèle tel que GPT-2 à l'aide de Hugging Face.
Ce guide a fourni une exploration approfondie du modèle de langage Phi-3, aidant les lecteurs à avoir une solide compréhension de ses caractéristiques uniques, de ses applications pratiques et de ses stratégies d'utilisation efficaces.
Nous avons présenté l'architecture du modèle et son impact potentiel sur diverses applications d'IA et de traitement du langage naturel avant de nous plonger dans les caractéristiques et capacités principales de Phi-3.
Nous avons ensuite présenté le processus d'installation et de configuration de Phi-3-mini pour une démonstration étape par étape de la manière de charger et d'invoquer le modèle pour une tâche simple de génération de texte, afin de familiariser les apprenants avec le processus.
La deuxième partie de la formation pratique a couvert toutes les étapes nécessaires pour affiner le modèle Phi-3-mini sur un ensemble de données personnalisé pour des tâches spécialisées, ainsi que l'importance d'avoir des ressources de formation suffisantes.
Nous avons également abordé les meilleures pratiques en matière d'optimisation des performances, de gestion efficace des ressources et de mise à l'échelle des applications, afin que les lecteurs disposent des outils nécessaires pour maximiser le potentiel du modèle.
Notre article, How to Build LLM Applications with LangChain Tutorial et le cours Large Language Models (LLMs) Concepts peuvent être d'excellentes étapes pour poursuivre votre apprentissage.
L'article explore le potentiel inexploité des grands modèles de langage avec LangChain, un framework Python open-source pour la création d'applications d'IA avancées.
Le cours vous aide à découvrir tout le potentiel des LLM, leurs applications, les méthodologies de formation, les considérations éthiques et les dernières recherches.
Il existe de nombreux modèles linguistiques de grande taille, et la clé pour utiliser le bon modèle est de comprendre les exigences de l'application et les capacités du modèle afin de faire le meilleur choix pour la tâche à accomplir.
Poursuivez votre voyage dans l'IA dès aujourd'hui !
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach