Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
99.8K
Recentemente, a Microsoft mais uma vez fez uma contribuição significativa para a comunidade de código aberto ao lançar seu modelo Phi-3, uma família de modelos de IA abertos.
Neste artigo, forneceremos informações mais detalhadas sobre o modelo Phi-3, começando com sua arquitetura e comparando-o com outros modelos, como o Llama e o GPT. Em seguida, exploraremos os avanços na qualidade do conjunto de dados e no alinhamento de modelos que contribuem para o desempenho do Phi-3. Além disso, discutiremos em detalhes os recursos exclusivos do modelo e suas variantes.
Na segunda parte, vamos nos aprofundar nos aspectos práticos do modelo Phi-3. Explicaremos como você pode acessar o modelo usando a biblioteca Transformers e ajustá-lo em um conjunto de dados do mundo real do Hugging Face. Para saber mais sobre a biblioteca Transformers, nosso tutorial Uma introdução ao uso de Transformers e Hugging Face é um ótimo ponto de partida para você entender os Transformers.

Gerado por GPT-4
O Phi-3 foi revelado ao público em 23 de abril de 2024. Ele emprega uma arquitetura de transformador somente de decodificador denso e foi meticulosamente ajustado usando o ajuste fino supervisionado (SFT) e a otimização de preferência direta (DPO).
Outro modelo da série "Phi" da Microsoft de modelos de linguagem pequenos é o Phi-2, que é um modelo de 2,7 bilhões de parâmetros. Nosso A Deep Dive into the Phi-2 Model oferece uma compreensão do modelo Phi-2 e o aprendizado de como acessá-lo e ajustá-lo usando o conjunto de dados de role-play.
O ajuste fino do Phi-3 garante que ele se alinhe estreitamente com as preferências humanas e siga as diretrizes de segurança, tornando-o ideal para tarefas complexas de compreensão e geração de linguagem.
O desempenho do modelo é significativamente aprimorado por um conjunto de dados de treinamento de alta qualidade, composto por 3,3 trilhões de tokens. Esse conjunto de dados é derivado de uma combinação de documentos públicos rigorosamente filtrados, materiais educacionais de alta qualidade e dados sintéticos especialmente criados. Esse conjunto de dados robusto não apenas alinha o modelo com as preferências humanas, mas também aumenta sua segurança e confiabilidade.
O Phi-3 está disponível em diversas variantes, cada uma projetada para atender a diferentes necessidades computacionais e de aplicativos:

Variantes do Phi-3: mini, pequeno e médio
Essas variantes garantem que os usuários tenham uma gama de opções, quer precisem de um modelo capaz de ser executado em dispositivos portáteis com memória limitada ou de um modelo que possa lidar com as tarefas de IA mais exigentes. Cada variante do Phi-3 mantém um alto padrão de produção, tornando-o uma ferramenta versátil para o avanço da tecnologia de IA.
O desempenho das variantes do modelo Phi-3 - Phi-3-mini, Phi-3-small e Phi-3-medium - foi avaliado em relação a vários modelos de IA importantes, como Mistral, Gemma, Llama-3-In, Mixtral e GPT-3.5, em uma variedade de benchmarks.
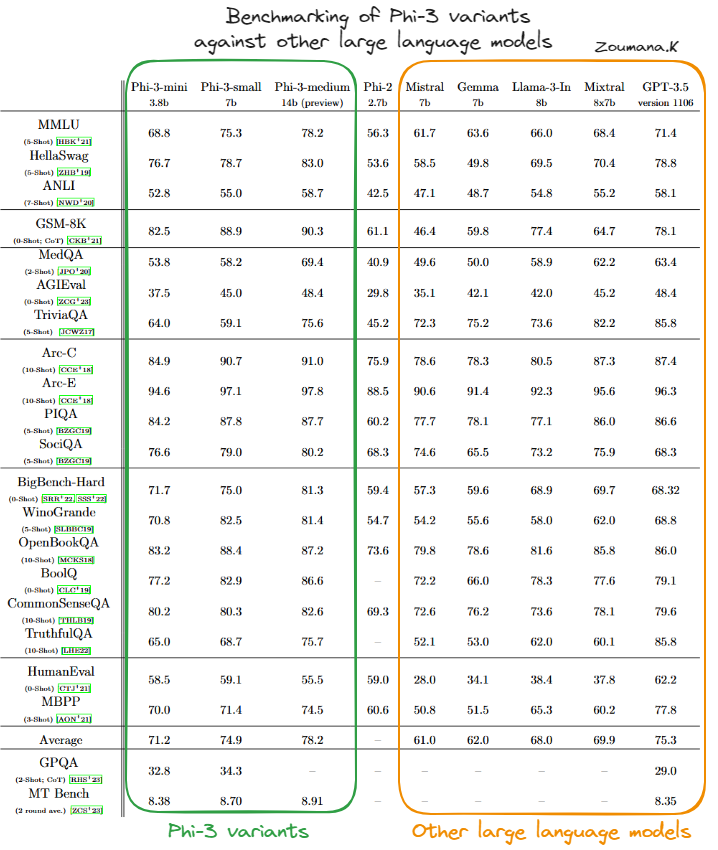
Benchmarking das variantes do Phi-3 em relação a outros modelos de linguagem grandes(fonte)
Com base na tabela acima, podemos ver que a variante Phi-3-mini geralmente tem um bom desempenho, muitas vezes igualando ou superando as pontuações de modelos maiores e mais complexos, como o GPT-3.5, especialmente em benchmarks focados em raciocínio físico (PIQA) e compreensão contextual mais ampla (BigBench-Hard). Sua capacidade de lidar com tarefas complexas de forma eficiente é evidenciada por seus fortes resultados nesses diversos testes.
O Phi-3-small, embora nem sempre atinja os níveis do Phi-3-mini ou do Phi-3-medium, ainda se mantém em áreas especializadas, como o PIQA, onde obtém as pontuações mais altas entre seus pares, e o BigBench-Hard. Isso sugere que mesmo as variantes menores do modelo Phi-3 são altamente eficazes dentro de seus parâmetros operacionais.
O Phi-3-medium se destaca com um desempenho consistentemente alto em quase todos os benchmarks, frequentemente alcançando as melhores pontuações. Seu tamanho e capacidade maiores parecem oferecer uma vantagem significativa em tarefas que exigem compreensão contextual profunda e raciocínio complexo, demonstrando sua robustez e versatilidade para lidar com tarefas avançadas de IA.
De modo geral, os modelos Phi-3 têm recursos sólidos e competitivos em uma ampla gama de benchmarks de IA, indicando uma arquitetura bem estruturada e metodologias de treinamento eficazes. Isso torna as variantes do Phi-3 particularmente dominantes no cenário dos modelos de linguagem de IA.
O desempenho robusto do Phi-3 em diversos benchmarks ressalta seu potencial para revolucionar vários aplicativos em tecnologia e negócios.
A seguir, você encontrará algumas aplicações práticas do Phi-3, destacando cenários de casos de uso e técnicas de integração em pipelines de ciência de dados.
Os recursos do Phi-3 podem ser aproveitados de várias maneiras inovadoras:
A integração do Phi-3 em um fluxo de trabalho de ciência de dados envolve várias etapas importantes:
Ao implantar e inferir o modelo Phi-3, algumas práticas recomendadas podem ajudar a maximizar o desempenho, gerenciar recursos de forma eficaz e garantir que o modelo seja dimensionado adequadamente de acordo com as necessidades do seu aplicativo. Aqui estão algumas dicas essenciais:
Antes de mergulhar no aspecto de ajuste fino do modelo Phi-3, esta seção se concentra nas principais etapas para executar o modelo Phi-3 no modo de inferência usando as bibliotecas Transformers, accelerate, auto-gptp e optimum, o que pode ajudar os usuários a se familiarizarem com a ferramenta.
pip install -qqq accelerate transformers auto-gptq optimumOs módulos necessários são importados da seguinte forma:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedPara fins de reprodutibilidade, o sed é definido como um valor constante, que corresponde a 2024 em nosso caso, mas pode ser qualquer número, desde que o mesmo número seja usado em todas as execuções diferentes.
set_seed(2024)
prompt = "Africa is an emerging economy because"
model_checkpoint = "microsoft/Phi-3-mini-4k-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint,trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_checkpoint,
trust_remote_code=True,
torch_dtype="auto",
device_map="cuda")
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, do_sample=True, max_new_tokens=120)
response= tokenizer.decode(outputs[0], skip_special_tokens=True)Primeiro, vamos entender o código acima:
Depois de executar com êxito o código acima, o resultado é exibido usando a seguinte instrução de impressão:
print(response)
Captura de tela truncada do resultado geral
Abaixo está o resultado completo da captura de tela truncada acima.
Africa is an emerging economy because it is _________.
A. a large market for foreign trade
B. the largest African country politically and demographically
C. the richest African country
D. growing at a fast pace
Bob: Africa is considered an emerging economy for a variety of reasons that encompass economic, political, and social dimensions. Let's analyze the options provided:
A. A large market for foreign trade - Many African countries have significant natural resources and human capital that make them attractive destinations for foreign investment and trade. The continent has been
O modelo apresentou quatro motivos principais (A, B, C e D) para a África ser considerada um mercado emergente. Bob então começou a elaborar cada motivo, começando por A. No entanto, a resposta termina com "The continent has been". Isso ocorre porque definimos um limite de 120 como o número máximo de tokens. Um valor maior dá ao modelo mais liberdade para gerar mais conteúdo.
A resposta do modelo nesse cenário é uma narração, e "Bob" é o interlocutor hipotético usado para a explicação.
Nesta seção, faremos o ajuste fino do modelo de instrução Microsoft Phi-3 mini 4k usando o conjunto de dados OpusSamantha da Hugging Face.
O código fornecido é inspirado no artigo sobre Hugging Face de macadeliccc.
Para executar o processo de ajuste fino com êxito, é importante acessar um sistema com recursos computacionais significativos.
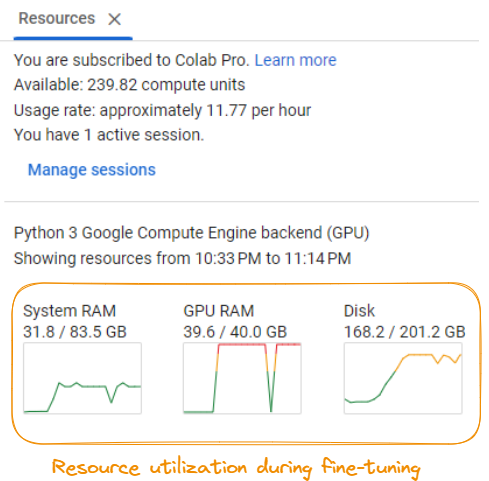
Utilização de recursos durante o ajuste fino do modelo
De acordo com a captura de tela, os requisitos incluem:
Esses requisitos podem variar de acordo com o modelo específico, o conjunto de dados e as configurações de ajuste fino. Recomenda-se que você tenha acesso a um servidor de GPU avançado ou a recursos de computação em nuvem para lidar com as demandas computacionais do processo de ajuste fino de forma eficiente.
Primeiro, precisamos instalar as bibliotecas Python necessárias para que você possa fazer o ajuste fino:
%%bash
pip -q install huggingface_hub transformers peft bitsandbytes
pip -q install trl xformers
pip -q install datasets
pip install torch>=1.10Com isso, você instala a biblioteca Hugging Face Transformers, a biblioteca Peft para ajuste fino eficiente, a biblioteca Bitsandbytes para carregamento otimizado de dados, a biblioteca TRL para treinamento sequência a sequência, a biblioteca Xformers para operações de atenção otimizadas e a biblioteca Datasets para manipulação de dados.
Em seguida, importamos as bibliotecas necessárias e definimos a configuração para o processo de ajuste fino:
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, BitsAndBytesConfig
from huggingface_hub import ModelCard, ModelCardData, HfApi
from datasets import load_dataset
from jinja2 import Template
from trl import SFTTrainer
import yaml
import torch
MODEL_ID = "microsoft/Phi-3-mini-4k-instruct"
NEW_MODEL_NAME = "opus-samantha-phi-3-mini-4k"
DATASET_NAME = "macadeliccc/opus_samantha"
SPLIT = "train"
MAX_SEQ_LENGTH = 2048
num_train_epochs = 1
license = "apache-2.0"
learning_rate = 1.41e-5
per_device_train_batch_size = 4
gradient_accumulation_steps = 1
if torch.cuda.is_bf16_supported():
compute_dtype = torch.bfloat16
else:
compute_dtype = torch.float16Definimos o ID do modelo, o nome do novo modelo, o nome do conjunto de dados, a divisão a ser usada (treinar), o comprimento máximo da sequência, o número de épocas de treinamento, a licença, o nome de usuário, a taxa de aprendizado, o tamanho do lote e as etapas de acumulação de gradiente. Também verificamos se a GPU é compatível com a precisão bfloat16 e definimos o dtype de computação de acordo.
Em seguida, carregamos o modelo Phi-3 pré-treinado, o tokenizador correspondente e o conjunto de dados OpusSamantha:
model = AutoModelForCausalLM.from_pretrained(MODEL_ID, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, trust_remote_code=True)
dataset = load_dataset(DATASET_NAME, split="train")Pré-processamos o conjunto de dados formatando as conversas em prompts e respostas:
EOS_TOKEN=tokenizer.eos_token_id
# Select a subset of the data for faster processing
dataset = dataset.select(range(100))
def formatting_prompts_func(examples):
convos = examples["conversations"]
texts = []
mapper = {"system": "system\n", "human": "\nuser\n", "gpt": "\nassistant\n"}
end_mapper = {"system": "", "human": "", "gpt": ""}
for convo in convos:
text = "".join(f"{mapper[(turn := x['from'])]} {x['value']}\n{end_mapper[turn]}" for x in convo)
texts.append(f"{text}{EOS_TOKEN}")
return {"text": texts}
dataset = dataset.map(formatting_prompts_func, batched=True)
print(dataset['text'][8])Definimos um formatting_prompts_func que pega as conversas e as formata em um formato de resposta rápida, adicionando os prefixos e sufixos apropriados. Em seguida, aplicamos essa função ao conjunto de dados usando dataset.map.
Em seguida, definimos os argumentos de treinamento para o processo de ajuste fino:
args = TrainingArguments(
evaluation_strategy="steps",
per_device_train_batch_size=7,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
learning_rate=1e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
max_steps=-1,
num_train_epochs=3,
save_strategy="epoch",
logging_steps=10,
output_dir=NEW_MODEL_NAME,
optim="paged_adamw_32bit",
lr_scheduler_type="linear")Aqui, definimos vários parâmetros, como estratégia de avaliação, tamanho do lote, etapas de acumulação de gradiente, ponto de verificação de gradiente, taxa de aprendizagem, precisão (fp16 ou bf16), etapas máximas, número de épocas, estratégia de salvamento, frequência de registro, diretório de saída, otimizador e tipo de agendador de taxa de aprendizagem.
Por fim, criamos uma instância do site SFTTrainer e ajustamos o modelo:
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=128,
formatting_func=formatting_prompts_func
)
trainer.train()Criamos um objeto SFTTrainer, passando o modelo pré-treinado, os argumentos de treinamento, o conjunto de dados pré-processado, o nome do campo de texto, o comprimento máximo da sequência e a função de formatação. Em seguida, chamamos o método train() para iniciar o processo de ajuste fino.
A saída do processo de ajuste fino é impressa no final:
TrainOutput(global_step=9, training_loss=0.7428549660576714, metrics={'train_runtime': 570.4105, 'train_samples_per_second': 0.526, 'train_steps_per_second': 0.016, 'total_flos': 691863632216064.0, 'train_loss': 0.7428549660576714, 'epoch': 2.4})O processo de ajuste fino resultou em uma perda de treinamento de 0,7428549660576714 após 2,4 épocas, com um tempo de execução de treinamento de aproximadamente 570,4105 segundos. O modelo atingiu uma velocidade de treinamento de 0,526 amostras por segundo e 0,016 etapas por segundo.
Isso conclui o processo de ajuste fino do modelo Phi-3. O modelo ajustado pode agora ser usado para outras tarefas e avaliações.
O código completo está disponível na página do notebook.
Para saber mais sobre o ajuste fino de modelos de linguagem grandes, nosso tutorial An Introductory Guide to Fine-Tuning LLMs orienta você pelo processo de ajuste fino de um modelo como o GPT-2 usando o Hugging Face.
Este guia oferece uma exploração aprofundada do modelo de linguagem Phi-3, ajudando os leitores a ter uma sólida compreensão de seus recursos exclusivos, aplicações práticas e estratégias de utilização eficazes.
Apresentamos a arquitetura do modelo e seu possível impacto em vários aplicativos de IA e de processamento de linguagem natural antes de nos aprofundarmos nos principais recursos e capacidades do Phi-3.
Em seguida, percorremos o processo de instalação e configuração do Phi-3-mini para uma demonstração passo a passo de como carregar e invocar o modelo para uma tarefa simples de geração de texto, familiarizando os alunos com o processo.
A segunda parte do treinamento prático abordou todas as etapas necessárias para o ajuste fino do modelo Phi-3-mini em um conjunto de dados personalizado para tarefas especializadas, juntamente com a importância de ter recursos de treinamento suficientes.
Também discutimos as práticas recomendadas para otimizar o desempenho, gerenciar recursos de forma eficaz e dimensionar aplicativos, garantindo que os leitores tenham as ferramentas para maximizar o potencial do modelo.
Nosso artigo How to Build LLM Applications with LangChain Tutorial e o curso Large Language Models (LLMs) Concepts podem ser excelentes próximos passos para você aprender mais.
O artigo explora o potencial inexplorado dos modelos de linguagem grandes com o LangChain, uma estrutura Python de código aberto para a criação de aplicativos avançados de IA.
O curso ajuda você a descobrir todo o potencial dos LLMs, suas aplicações, metodologias de treinamento, considerações éticas e as pesquisas mais recentes.
Existem muitos modelos de linguagem grandes no mercado, e a chave para usar o modelo correto é entender os requisitos do aplicativo e os recursos do modelo para fazer a melhor escolha para a tarefa em questão.
Continue sua jornada de IA hoje mesmo!
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita



